The sole purpose of NCache is to provide optimum performance for your application. And to hit these performance numbers, you need your caching environment to be able to scale easily and cost-efficiently.
As NCache is an in-memory datastore, the first concern is the limited memory that has been allotted to it on one physical box. The second is the computational limit. We all know that NCache, on top of providing basic CRUD operations, also supports many advanced features like Pub/Sub, Queries, criteria-based fetch calls, etc. And when client requests on these features become a lot, the need for more processing power increases. This means that sooner or later, your cache server will reach its max processing limit. When this happens, NCache does not abandon you. Instead, there is a solution to this and I’m here to explain that to you.
NCache Details Distributed Caching in .NET Highly Available NCache
Linear Scalability in NCache
When your environment hits the above-mentioned limits, NCache allows you to add a new server node (or multiple nodes) to your cache cluster. Adding a new server is basically you adding a new physical node to the cluster through NCache Web Manager or NCache PowerShell Tool that enhances overall memory and provides you with another resource to address excess incoming requests.
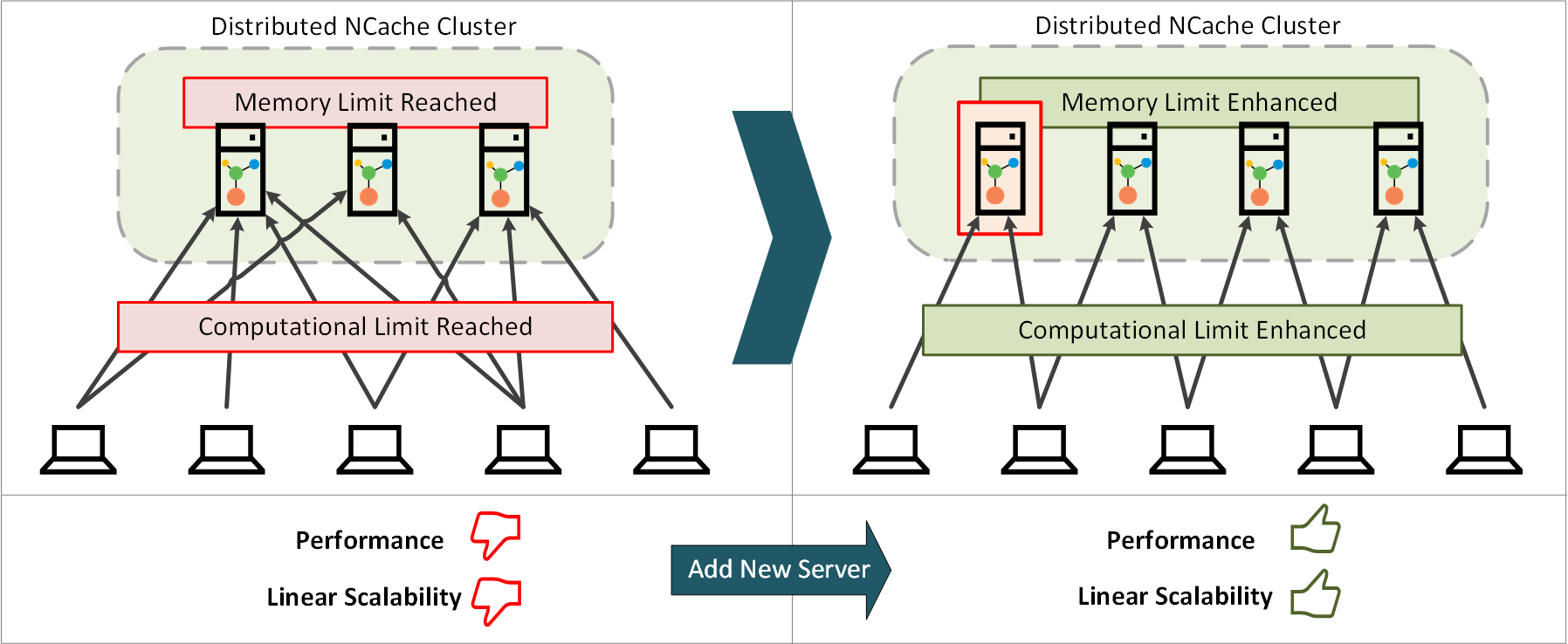
Figure 1: Scaling NCache Cluster to Achieve Scalability
This ensures Linear Scalability. How? Because the more nodes you add, the better performance you are going to get. In NCache, adding additional nodes to the cluster does not induce any overhead that causes the consistent throughput to falter. And according to the recently done performance benchmarks, NCache achieved 2 million operations/second with 5 server nodes! If that isn’t a win, then I don’t know what is.
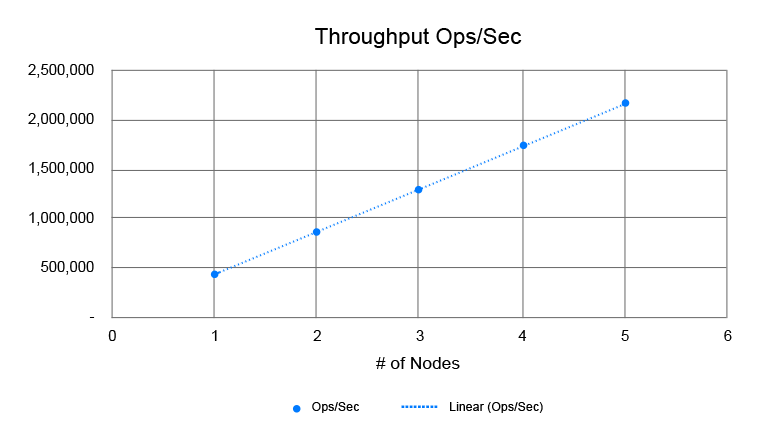
Figure 2: Linear Scalability in NCache Graph
And the best part about all of this comes with the dynamic nature of NCache clustering. This means that you do not have to stop existing processes, applications, or any nodes simply to add a new node to the cluster.
NCache Details NCache Performance Benchmarks NCache Performance Benchmarks – Video
Let’s dig a little deeper and illuminate what NCache features bring to the scalability table.
Client Operations for Scalability
NCache client has this built-in feature that it automatically connects with every server node directly. And NCache distribution map allows the client to know which node has the data it requires. So, the operation coming from the client does not go through multiple hops and nodes. Instead, it takes one straight hop to the server that has the specific data. This simple yet clever functionality helps scale your environment.
Parallelism for Scalability in Operations
NCache supports various advanced operations like Queries, Bulk operations, Tags, and many other operations that need to be performed on multiple nodes. Instead of sending these operations to every node in a Round Robin fashion, NCache allows you to send every operation to every node in parallel.
For example, a client wants to query data stored in the cache, so it sends that query to all nodes of the cluster. Every node is going to execute that query locally on the dataset that it has stored and shares the result with the client. The client merges all results coming from all server nodes and returns one single result to all end applications. Every node runs the same query in parallel which induces scalability and speeds up the system.
Pipelining for Scaling Operations
NCache uses Pipelining to create chunks of operations that need to be sent over a network in single TCP call. This technique reduces the overhead of sending multiple requests one by one and waiting for their acknowledgment.
Let’s take an example here. Say that the NCache client is sending 100 operations to the server which typically means that the client will be performing 100 I/O operations. For these operations’ success, every transaction from user to kernel mode is going to consume a whole lot of CPU power. Too much CPU consumption is expensive and it will bring down my application’s performance.
Here, what client-side pipelining does is combine all the operations that are going to one server and sends that chunk in one dedicated I/O call. Server-side pipelining is making sure the server receives multiple I/O calls in one simple call. The responses servers send back are received together as well. Not only this, but the server also tries to generate maximum responses to those incoming operations in one go.
So, the 100 operations that were sent to the server in dedicated calls are received by the server in one call. And the results of the operations it got, are sent in one call by the server. This technique helps to scale the system tremendously.
NCache Details Client-Side Operations Pipelining in NCache
Scalable Background Replication in Partition-Replica
Whatever update operation the client performs on a server node needs to be replicated for fault tolerance and high availability to the replica server. NCache server does this replication in the background without any client involvement. On top of being a background process, this replication is done in bulks to save maximum cost. This process induces scalability as all operations are being scaled through background replication, and it also makes your cache highly available. Win-win.
Write-Behind Caching for Scalability
If the client wants to write data in the database, the same request sent to the server will write that data in the cache and the database.
An asynchronous implementation of this feature is Write-Behind that allows your server access to the database without any computational delay. This way your database and cache stay in sync while keeping the same performance you wanted from an in-memory cache.
If the NCache client sends the cache server a request with Write-behind enabled, the server writes that data in the cache, returns the control to the client, and uses a batching system in the background to make sure that data gets stored in the database as well. This mechanism is what makes your application scalable.
Scalability through Object Pooling in Memory Management
In the .NET environment, when the automatic Garbage Collector (GC) activates, all activities going on in the application are halted which creates pauses in in-memory data computation. These pauses cause a great hit on your application’s performance. The greater objects you create, the more the GC will kick in and the greater this hit will be.
To avoid these long GC pauses, NCache being a native .NET cache uses Object Pooling technique as its own memory management. In this mechanism, NCache server pools objects and reuses them instead of creating new ones which results in lesser need to invoke GC. The lesser this need is, the more performance you will get out of your application, hence more scalability.
NCache Details Server-Side Operations Pipelining in NCache
Client Cache to Induce Scalability
Concerning scalability, Client Cache proves itself to be one of the most important features of NCache.
Client cache stores the most frequently used data of your clustered cache on the same machine where your application is running. Using Client Cache between your application and clustered cache provides you with a local cache resource that resides close to your application. This cache will entertain most of your application’s read requests which inevitably results in I/O cost reduction. So, not only do you get fast access to updated data, but your application also scales up.
This scalability chart can be further optimized if you move from OutProc client cache to InProc client cache by reducing the cost to access the local node.
Concluding Scalability in NCache
While getting the best out of your application, you can encounter two major setbacks. Either the computational load on your cache increases or you reach the set bounds of data storage, both of which can be significantly improved by scaling NCache. You have full control over NCache that is rich with features ready to bring scalability in your environment. So, what are you waiting for? Get NCaching!
NCache Details Download NCache Edition Comparison





