Split Brain Recovery in NCache for 100% Uptime
NCache is an extremely fast and scalable In-Memory Distributed Cache for .NET / .NET Core. Majority of the time, NCache runs in production environments for mission-critical applications. As a result, high availability and 100% uptime is a very important requirement for NCache. And, NCache excels in this area very well through a variety of features.
One of those high available features is Split Brain Detection and Recovery to prevent any downtime from it.
What is a Split Brain in Cache Cluster?
NCache creates a self-healing dynamic cache cluster consisting of multiple servers that talk to each other through TCP. All cache servers are interconnected in cluster and cluster membership is maintained at runtime and propagated not only to all the cache servers but also to all the cache clients.
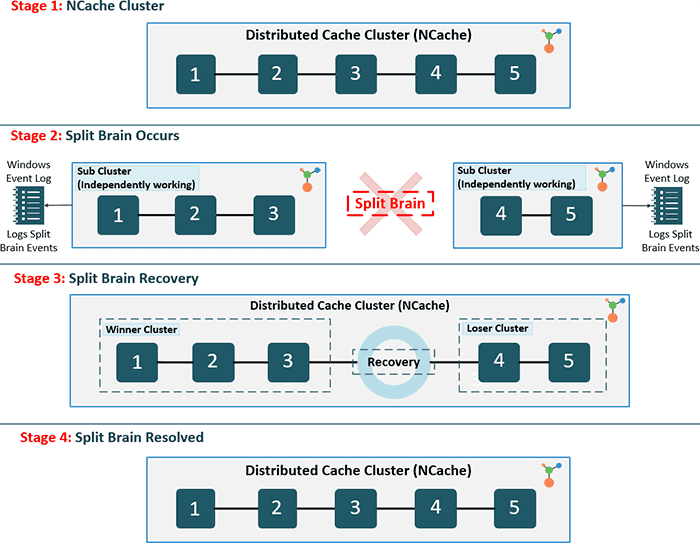
However, like any distributed system, NCache cluster can face a situation where one or more cache servers are disconnected from rest of the servers in the cluster but both set of servers are continuing to run. This usually occurs due to network glitches or problems.
When this happens, each set of cache servers considers itself as the surviving servers of the original cache cluster and assumes that the other set of cache servers have gone down (hence the term split brain which in medical terms means that left side of the brain doesn’t know about right side of the brain). The cache clients may also be split in similar fashion or they may continue to talk to all the cache servers based on the original cluster membership.
Split Brain in Cache Cluster

This is obviously not a healthy and normal condition and leads to errors in cache operations and most importantly to data integrity problems. Each “split cluster” now has its own copy of data that is being independently updated by the clients. And, you end up with two or more copies of the same data being updated without any synchronization.
How is Split Brain Detected?
NCache has the ability to automatically detect when a split brain occurs. Cluster membership is maintained on all cache servers in the cluster. So, whenever a cluster is broken up into two or more sub-clusters due to the split-brain situation, each sub-cluster thinks it is the surviving cluster and continues working with its data.
But, at the same time, it knows that there are other cache servers who have left the cluster in an abnormal manner. A normal manner is when the cache administrator uses an NCache tool to remove a cache server from the cluster. So, each sub-cluster keeps trying to reconnect with the “lost servers”. At the same time, each sub-cluster logs events to the Windows Event Log indicating that some of its original members have left. So, in case of a split-brain, the NCache administrator sees “node left” events for almost all the cache servers.
It is only when the network connection between the split sub-clusters is restored that they find out about the fact that a split-brain actually occurred. Until this time, they keep believing that some of their members had left the cluster.
Upon realizing that a split-brain has occurred, each sub-cluster logs events in the Windows Event Log and can also notify the cache admin through Email Notification that a Split Brain has occurred.
How Split Brain Auto-Recovery Works?
NCache allows you to configure auto-recovery from the split brain. If you do then whenever NCache detects a split brain, it automatically recovers from it. Enable split brain recovery through config.ncconf by adding the <split-brain-recovery> tag under the <cache-settings> tag. You can then change the enable flag to true and set the detection interval for split brain in seconds.
<cache-settings...>
<split-brain-recovery enable="True" detection-interval="60"/>
</cache-settings>When a cluster is split into two or more sub-cluster and afterwards their network connection is restored, they finally realize that a split-brain has occurred. At this point, if the user has configured auto-recovery, then all the sub-clusters negotiate with each other to figure out which one sub-cluster should become the “master cluster” and rest of the sub-clusters then join this “master cluster” by throwing away their data and acting as if they’re new nodes joining an existing cluster.
The rules used to determine which sub-cluster should become “master” is simple. It is the sub-cluster with the largest number of member nodes. And, if multiple sub-clusters have an equal number of member nodes, then the one whose coordinator’s IP address is smallest wins and becomes the “master cluster”. And, rest of the sub-cluster joins it and the end result is one large cluster equivalent to the size of the original cluster.