Boston Code Camp 27
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
Your .NET applications may experience database or storage bottlenecks due to growth in transaction load. Learn how to remove bottlenecks and scale your .NET applications using distributed caching. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
My name is Iqbal Khan. I'm a technology evangelist at Alachisoft. We are a software company based in San Francisco Bay Area. I'm personally based in Tampa but we have this product called NCache. It's a .NET distributed cache. Today I'm going to talk about how you can scale .NET applications with distributed caching. This is not a talk about NCache, it's about the problem of scalability and how you can resolve it with distributed caching. What should you do? How should you use it? What are some of the best practices? If you have any questions, please feel free to stop me. So, that we can have more interactive discussion. Let me get started.
What is Scalability?
So, let's get a few definitions out of the way. Number one is scalability. Scalability is not performance. You may have an application that performs really well with five users but it is only scalable if it's going to perform the same way with 5,000 or 50,000 or 500,000 users. So, scalability is really high performance under peak loads. If your application is not performing well with 5 users, then you need to attend some other talks.
Linear Scalability & Non-Linear Scalability
Linear scalability is more of application deployment concept. When you deploy your application, if you can add more servers to the deployment and by adding more servers if you can increase the transaction capacity in a linear fashion, then your application architecture is linearly scalable, otherwise it is non-linear scalable.
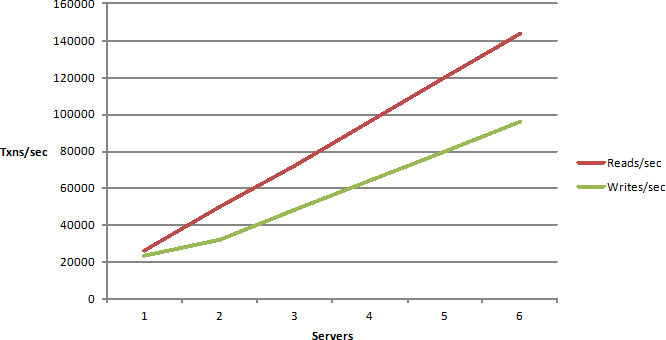
What that means is, that after a certain number of servers, adding more servers actually makes matters worse, that means there's some bottlenecks somewhere in your application which are not being resolved just by adding more servers. You definitely don't want nonlinear scalability and you definitely want linear scalability in your application.
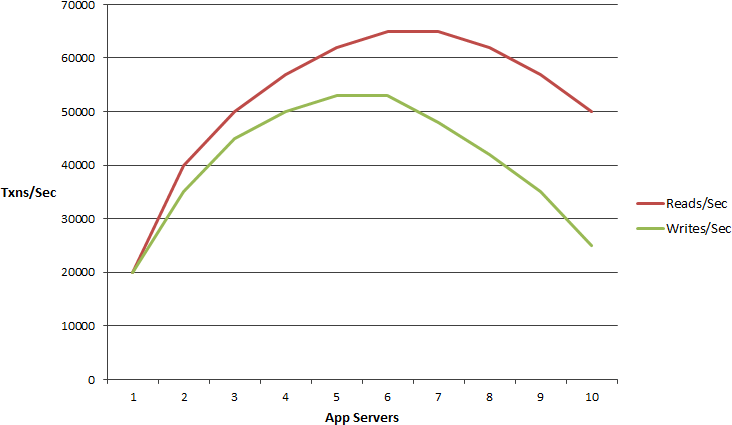
What type of applications need scalability?
What type of applications need scalability? These are ASP.NET applications. These are web services. These are IOT back-end which are again mostly web services. These are big data processing applications, which are not that common in .NET, more and more of them are being done in Java but nonetheless these are the applications that also need scalability and any other server application. For example, you may have, you may be working for a large bank that has millions of customers and they, you know, customers call in to make address changes or maybe they want a new card issued or maybe they're transferring funds from one account to the other and all of those transactions need to be processed within some predetermined time frame for compliance purposes. So, you again have to handle millions of requests within a time frame that you may not be able to do from a single computer. So, you need to be able to scale even in that case. So, if you have any of these applications that need scalability then this is a right talk, that you've come to.
The Scalability Problem
So, let's define the scalability problem also. What is the scalability problem? Well the application tier scales in a linear fashion. You may have a web application ASP.NET or web services. You'll have a load balancer in front of it which will route traffic evenly to all the servers. You can add more servers, no problem. Everything works perfectly fine. I was talking to somebody earlier about the database becoming a bottleneck and they were not agreeing with me. So, I think this is a good opportunity to have that discussion.
So, database itself performs super-fast. There’s no issue with performance. Databases are very smart, they do a lot of in memory caching in their own server but scalability is something that they by design cannot achieve because you can add, for example, you can add 10, 20, 30, 40, 50 servers at this tier. We have customers with 50 or more servers in their application tier because they have so many users. Imagine you're a large bank or you're an airline. You have millions of people who are coming to your website. You've done this major promotion for a ticket to Hawaii or something. Everybody's gonna come, they'll do the flight search, they want to buy the tickets. You can add more servers here no problem. The database was performing super-fast and the software is great but by design database is not a distributed database. It is kept in one place. Maybe you can have a cluster of two servers, active–active, active-passive but they're more for reliability than for scalability, really.
So, you can't really have 10 servers here, unless it is a NoSQL database, then you can. But, for a relational database any of them it could be SQL server, Oracle, Db2, MySQL, they're super-fast. They may be even doing a lot of in memory processing but they will become the bottleneck as you need to scale more and more. And basically, when you have thousand or more simultaneous or concurrent users, you start to notice performance issues and as you grow more of 1,000 to 5,000, 5,000 to 10,000, that's where you start to see more. So, what we've seen is, you know, when if you have a 1000 users you may or may not use caching but as you grow to 5,000, 10,000, 15,000 users, you definitely feel the pain and you end up with these scalability bottlenecks.
Now relational databases or mainframe legacy databases have this problem. It is one of the reasons NoSQL databases movement started was because of that. Although, it also has other benefits and we have a product. Let me just come quickly for reference purposes. So, we have a caching product but we also have a NoSQL document database. Just like document DB it's an open source database.
So, NoSQL database definitely does not have the scalability problems. But, it is not always the answer. Why is that? Because for it to be an answer, a NoSQL database wants you to store all the data in it. So, unless you store your data in a NoSQL database which means you stop using relational database for at least that part of the data, it is not going to solve your problem. So, in many cases you can move some of the data, a lot of the data into a NoSQL database and that's what's driving the NoSQL movement. But, relational databases, legacy mainframe data, they're here to stay. They're not something that you can just wish away for both technical and business reasons. So, whatever scalability problems you have to solve, you have to solve them with relational databases in the picture. That's why NoSQL database is not always the answer.
The Solution: In-Memory Distributed Cache
And, the way you solve that problem is, it's a new best practice that has emerged over the last five to ten years or so, which is the in-memory distributed cache. Some people also call that in-memory data grid. Microsoft used to call the data fabric. Although, they keep changing their definitions. But, it's an in-memory distributed key-value store and it is an essential part of your architecture now. If you want a scalable application, you need to program, you need to develop your applications with a distributed cache in mind. So, that you can make sure that the application will never become a bottleneck.
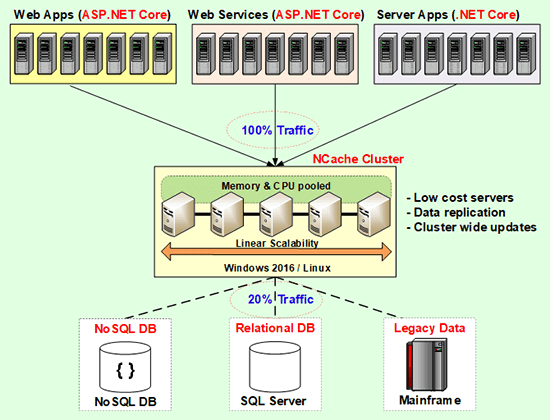
Now what is a distributed cache? It is essentially two or more low cost servers. These are not high-end database servers, these are web server type of boxes. Usually a dual CPU, 8 core configuration is pretty typical. 16 gig of RAM is pretty much average. We see 16 to 32 gig is like the sweet spot of memory. More than 64 gig, we don't even recommend to our customers. We say add another box instead of making this box more stronger. Because, if you add more than 64 gig, a .NET application has this thing called garbage collector which takes a lot of processing power. So, the more memory you have, the faster the CPU has to be for the garbage collector to be able to collect all that memory.
So, it is better to have more servers than to have really high-end few servers. Minimum of 2 of course, because you want reliability. In case anyone server goes down but then after that 4 to 1 or 5 to 1 ratio, so, usually you would have, let's say, 2, 3, 4, or 5 servers in the application tier. The most common we see is between 4 and 10 and then of course there are many customers who use more than 10 but 4 and 10 is pretty much what we see as this sweet spot. And, for that you use a 2 server cluster. As, you grow more than 10 or 12 you add a third one or fourth one and so and so forth. And, because a distributed cache is a key value store, its distributed. It replicates data across multiple servers in an intelligent fashion, so that you get reliability but at the same time you don't spend a lot of time replicating. For example, if every piece of data had to be replicated to all the servers, that's a lot of extra processing that you don't need. So, it's that type of intelligent replication that it needs to do. Sometimes, you do need to have replication in that way but those are specialized cases. So, a distributed cache when you have that in place, you will go to it about 80% of the time. All the reads are going to be done from it and all the updates and some of the reads are going to be done to the database and also the cache. So, if you can trap about 80% of your database traffic to your cache, suddenly your database is very light. It doesn't have a lot to do. So, whatever it has to do, it will do much faster. So, performance will improve as well as scalability.
This in-memory distribute cache, whether that is NCache, whether that is Redis on the .NET side, on the Java side there are more players, whichever product you choose distributed cache pretty much is a given best practice now. You have to incorporate this into your architecture.
Any questions on this so far, before I move on? So, yes, one logical cache can span multiple servers. In case of NCache you can have multiple caches on the same servers. So, each cache becomes its own container for isolation purposes but any one cache can span all five servers. When I say span, it means some data is on one server, some on the others, you know, and then replication is a separate part of it that may or may not be done depending on your preferences. But, yes, all servers are used for storing that cache and the cache has to be coherent. It has to be always correct or you can say it has to be eventually correct but pretty close to being always correct. Whatever you store in the cache, if you update, you don't care where the data is, you probably don't even know where the data is. All you know is that this cluster has my data and whenever I fetch, I might have stored it from this server and I'm trying to read it here immediately afterwards and I should be able to get the same copy. If I can do that then this becomes a consistent or a coherent cache. So, that much data integrity for updates it always ensures.
That is your preference and I'll go into that in more detail in terms of how you actually use the cache. So, one thing that you should … I mean the main goal of up until now is to convince you that if you want scalability you need to have this as part of your architecture.
Common Uses of Distributed Cache
So, now that we've, let's say, we agree that you need a distributed cache, the first question that comes to mind is how do you use it? Where do you use it? What do you use it for? What data is kept in it and all the issues related to that data.
Application Data Caching
So, there are three high level use cases. Number one is, the Application Data Caching which is what I was just talking about, which is you have data in the database, you fetch it and you cache it. So, in the application data caching the goal is… but I just mentioned that you don't want to go to the database as much, you want to reduce that database traffic so that your application will scale. But, the data now exists in two places. It exists in the cache and it exists in the database. So, whenever data exists in two places what's the first concern that comes to mind? Synchronization between the two. So, is it consistent? Because, if the data is not going to be consistent, then you will be limited to using the cache for read only data. In fact most people when you ask them, what do you use a cache for? The knee-jerk reaction is read-only data. You know, I don't feel comfortable using the cache for any data that's going to really change in, you know, real time or at runtime. But, if you can't use the cache for transactional data which I use the term for data that changes frequently that data is probably 80% to 90% of your data. So, that means well 80% to 90% of the time you can't even use the cache and if you can't even use the cache then it becomes just like a NoSQL database. It's not always the answer, you know. And, you want it to be the answer, so you know, so a good distributed cache has to give you the confidence that whatever you cache will be consistent with the database. If it is not then that cache is not the right cache for you. So, that's the first thing, that's the first use case.
ASP.NET Specific Caching
The second use case is, if you have ASP.NET Applications.
- ASP.NET Session Caching
You can store your sessions in the cache. You know, sessions are something that almost all ASP.NET applications have. They're either kept in an In-Proc mode or in the SQL server mode. SQL server is not a right place to keep sessions for two reasons, one of course that, that first reason which is the more you keep data in the database, the more of a scalability bottleneck you have. The second is that sessions are kept as blobs and relational databases were not really designed for blobs. They were designed for more structured data that you can index and search. Whereas, a distributed cache the key value, the value is a blob always. So, these sessions fit in very nicely with a distributed cache.
- ASP.NET View State Caching
The second type of ASP.NET data is, if you're not using the MVC framework which a lot of the existing ASP.NET applications still aren't, then you have this thing called a View State and, a view state is nothing but an encrypted string that is kept and is sent from the web server to the browser, only to come back to the web server and it can get pretty big. It can be 100s of kilobytes easily and so it consumes a lot of extra bandwidth. It takes more time to travel. When you multiply that by millions of requests that you're processing, your bandwidth consumption cost also goes up quite a bit. So, it's an ideal case for caching on the server side and only send a small key. So, then the next time when the View State is supposed to be used, the key is sent back and the View State is fetched from the cache.
- ASP.NET Output Caching
The third example of ASP.NET specific caching is page output. It is part of the ASP.NET framework is called an output cache which allows you to cache the output of a page if it's not going to change and you can use a distributed cache to cache it instead of keeping it in every webserver separately which then becomes multiple copies that need to be synchronized. So, these three use cases or three examples are for the ASP.NET specific caching use case.
Now, unlike application data caching here the nature of the problem is very different. Here the data exists only in the cache. I mean all this data no longer gets stored anywhere else. So, it's not being stored in the database. So, you no longer have that synchronization issue between the database and the cache. But, you have another issue now. If you have an in-memory cache, that's the only store of your data. What's the biggest concern? What could go wrong with that? It disappears. Yeah, it can go away. If any one server goes down and servers do go down, windows including. So, when a server goes down you lose data and especially some of the, I mean for View State and Session State, I mean output cache sure even if you lose it, you just re-execute the page but these two. For example, Session State, you just had this airline customer who did all sorts of flight searches and he's about to place the order and the server crashes and his session is lost, he has to real login. You know, you may lose that customer. So, you definitely don't want to lose. So, you don't want this data to go away. So, in this, synchronization was the big issue here it's reliability.
So, reliability is handled through replication. Any cache that does not do replication you cannot store sessions in it. The nice thing about the ASP.NET specific caching by the way is there's no programming needed. It fits in completely within the ASP.NET framework. Unfortunately you have to do programming for the application data caching. On the Java side you don't have to or actually they're more standards emerging. There's a standard called JCache which if you program that then any of the third-party caches just plug in to it and then you don't have to stick to any one cache. Even more so, if you use an OR mapping engine like Hibernate or in case of .NET NHibernate, you can plug in a cache. Entity Framework until the EF core or until before EF core it did not allow a third party cache to plug in automatically. Although we had implemented an ADO .NET provider for EF6. That was more of ADO.NET level caching, so, you were caching queries which is better than not caching but it's not as powerful as caching at the entity level where you can also keep track of updates.
Entity Framework or EFCore Caching
The new EF7 or EF Core has a much more flexible architecture. It allows you to plug in a third party cache. So, when you move to EF Core you'll be able to plug in a distributed cache like NCache without any programming. So, you were just doing your standard programming and cache plugs in. But other than that you have to. But, even in that plugin you can't use all the features that I'll talk about. In ASP.NET specific at least this is the easiest win. When you bring in a cache, since there's no programming involved you just need to do some basic sanity testing and your application suddenly sees a major boost in performance and scalability.
Any questions, before I move on? In terms of the application or in terms of the cache? In terms of cache. A cache is just like a database. Just like you make calls to the database and then you have exception handling. If something goes wrong in the cache, the cache will throw an exception, you catch it and then you have to take the appropriate actions. However, unlike a database where an update can fail on data integrity because you may have check constraints or other referential integrity constraints, none of those constraints exist in the cache. A cache will accept all data that you give it. The only time a cache update or operation will fail is when something goes wrong with the system. Yeah, something catastrophic. So, you don't have to worry about the cache not updating your stuff in a normal operation.
Security
So, that depends on which cache product you use. NCache has all of those features built in. You can turn on security, so, that every user that uses the cache has to be authenticated / authorized. It also has a lot of other security like encryption built in. So, if the application that you have is very sensitive, you can encrypt the data before it gets cached and all that's just done automatically by the cache without you doing any extra effort. Because, as I said, one of the biggest users of NCache is the financial services industry. Because they have a lot of online banking. A lot of e-business happens there and their data is very sensitive. So, that depends on which product you pick.
Runtime Data Sharing Through Events
The third use case is runtime data sharing through events. Just like you use message queues, MSMQ is one, RabbitMQ it is another. They have a lot more features in terms of messaging for a distributed environment in a more than one location. If your application is all in one datacenter and you need to do Pub/Sub type of data sharing, a distributed cache is much more scalable than any other message queues. It may not have as many features as they do but you may not need all those features. But, it is much faster and much more scalable and that is true for NCache that is also true for other distributed caches that provide this feature. Because, again this whole cluster becomes a message bus. So, you have, you know, if you're doing a lot of activity the events propagate very quickly because they are more than one server to handle those events and, you can add more servers as the load grows.
So, a lot of these server applications these days they have built-in workflows, you know. Where one application does something and once that's done then other applications do something else. So that's where the Pub/Sub or the producer/consumer concept comes. There's an event notification features. NCache has this feature called continuous query which is a very powerful feature, which is also in the Java side exists but none of the other .NET caches have it.
So, runtime data sharing is also something that you should strongly consider doing through a distributed cache, makes your life much simpler then instead of incorporating multiple other products. Even here, the nature of the problem is usually the same as this, which is that the data that you're trying to share exist only in the cache. It might exist in the database but in a different form, because you've constructed it, you've produced it, you know, you've brought a lot of data together and in this final or intermediate form you're sharing with somebody else. So, if you lose that data you have to redo the whole thing. So, although it's not as bad as sessions but it still has a lot of performance implications. So, you don't want to lose that data. So, again here the concern is to make sure that the cache is reliable.
So, those are the three high-level use cases that a distributed cache provides. As I said, a distributed cache is essentially a distributed in-memory database, a key value store.
Hands-on Demo
Before I jump into more specifics about how you can do these, I'm just going to quickly show you what a distributed cache looks like? So, that you can see how it will be if you were to use it in your application. I'm going to of course use NCache as the example. NCache is an open source cache. So, you can use it without buying it if you don't have the money or you don't have the budget. If your project is more business sensitive then of course buy the Enterprise Edition. So, I have set up some VMs in Azure that I'm going to use. I'm going to use a 2 node cache cluster, so, I have ‘demo1’ and ‘demo2’ as my cache servers and ‘demo-client’ is my application server box. So, that's your ASP.NET server box. So, an NCache client is your application server really.
I'm logged in to, let's say, demo client. So, the first thing I'm going to do is create a new cache. So, I'm going to use this tool called NCache manager. So, it's an explorer style tool. I'm just going to say create a new clustered cache. In NCache all caches are named.
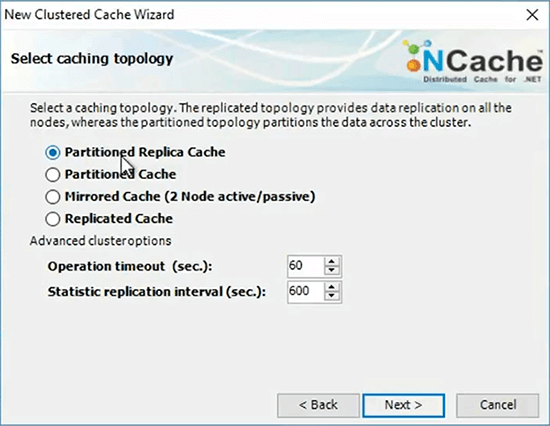
I will pick a storage or a replication strategy.
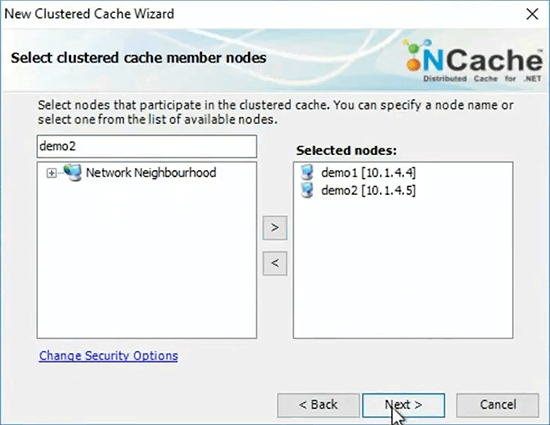
I'm just going to go ahead and specify my first cache server here. Specify my second one.
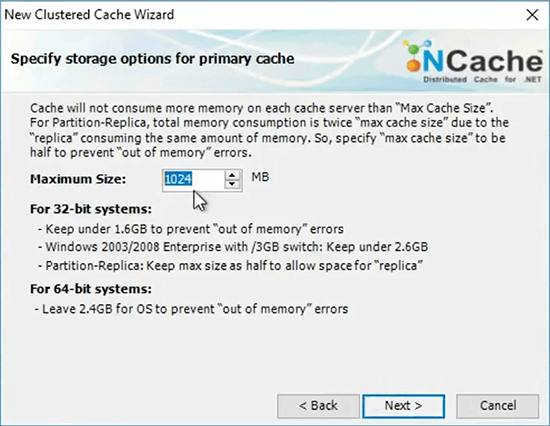
I'm just going to continue and I will say here is how much memory my server should consume. In your case, it's going to be a lot more. I’ve just specified one gig.
So, then if that memory is consumed, you can specify eviction policies. So, let's say, at least recently used policy means evict some of the items that are least recently used.
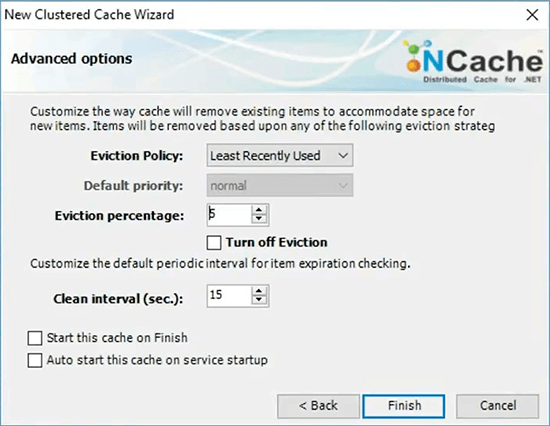
So, I've just gotten that. I'm going to go ahead and add a client node, which is my box and I will just go ahead and start the cache.
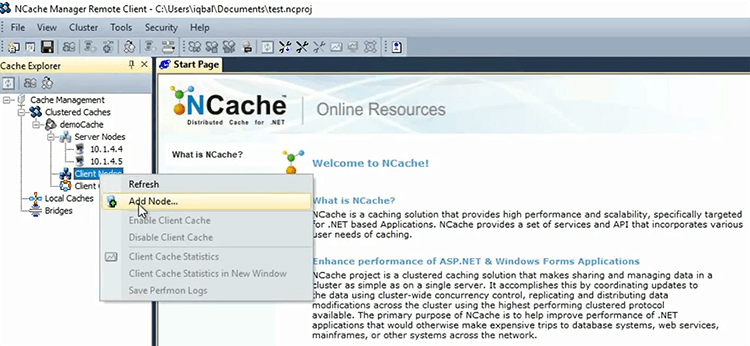
So, what machine are you setting this up to? This is an Azure. So, these two are my demo1 and demo2. So, I am actually logged into this box and I'm using NCache manager here and I'm creating a cluster of demo1 and demo2 here.
So, now that I've started this, I can go ahead and I can view statistics. So, I can see some PerfMon counter activity. I can also launch this monitoring tool of NCache that lets me see things and then I'm going to just quickly run this tool called Stress Test Tool. It lets you quickly test the cache in your environment to see how it's going to operate.
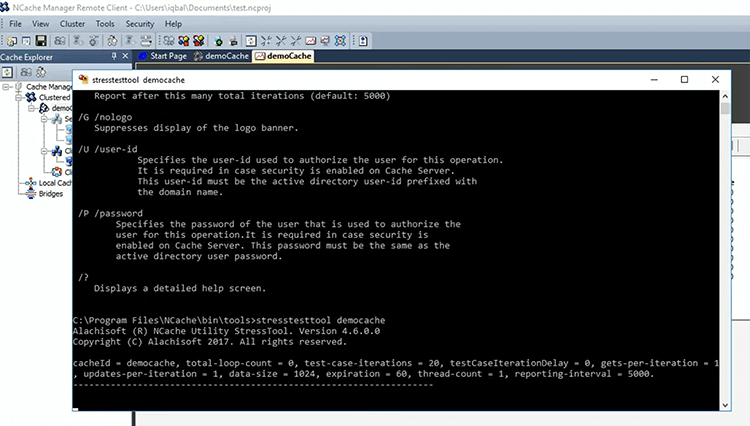
So, that tool is like your application. You can you can use it to simulate different types of load, different types of operations. For example, I'm doing about 600 some requests per second here and about, well, 700 to 800 each.
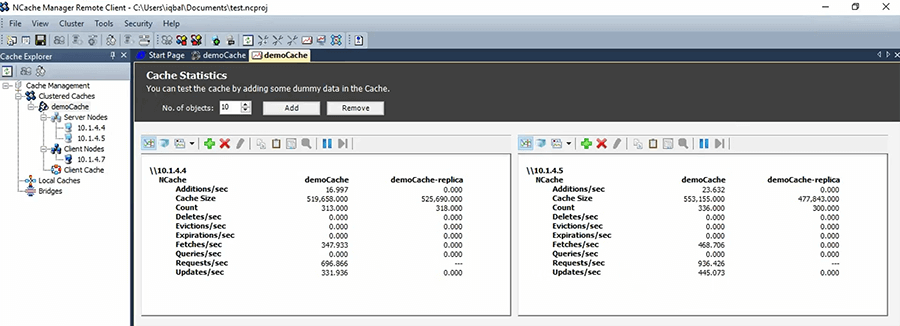
Let me run one more instance of Stress Test Tool, right here. So, you'll see that that load will just double. So, as I keep adding more and more instances of the application the load on the cache will increase until such a point where these two servers are going to max out and then you just add a third one.
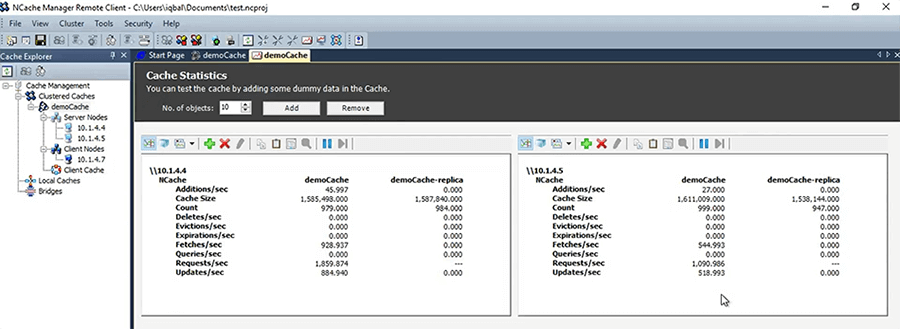
And, you can do that all at runtime without stopping anything. So, suddenly your infrastructure … Just think about this, if your database started to choke, can you really add another server and get out of that problem? You can't. Because, of the nature of that and that's not about any specific database, it's all relational databases. But, in case of a cache just add another server and now the cache is working.
So, this is what a cache looks like. It's that easy to use and configure as you can see. I mean the only thing that I didn't do is it install. Which was just a Windows installer which, you know, it doesn't take that long. So, other than that to figure a two node cluster it took me about five minutes.
And, now that I have all this thing configured, I can actually specify this cache name on the applications running on this box. So, if I had more client boxes, I would just keep adding them here.
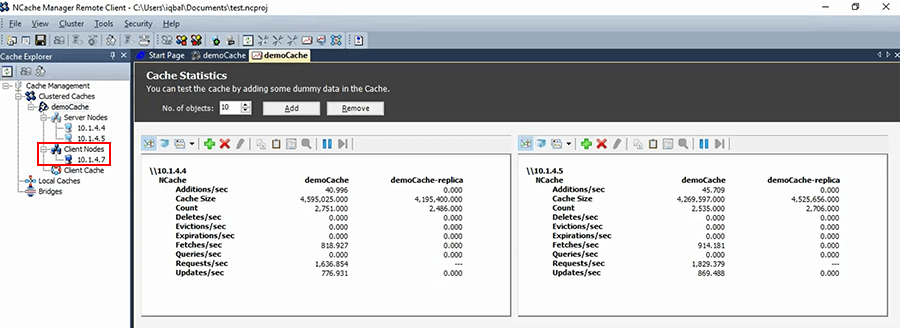
In your case for these two you probably have 8 or 10 of these. So, you would add them all and then once you do this cache demo cache is available there and then you just go and update your thing.
So, now that we know what a cache looks like, let me quickly now move to the next topic. So, as I said, the easiest way to use the cache is to use it for sessions. How do I do that? So, I have the ASP.NET application. I would go in and I open the web.config and I'll do two things. First I will go and add the assembly.
...
<compilation defaultLanguage="c#" debug="true" targetFramework="4.0">
<compilers>
<compiler language="c#" type="Microsoft.CSharp.CSharpCodeProvider, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089" extension=".cs" compilerOptions="/d:DEBUG;TRACE" />
</compilers>
<assemblies>
<add assembly="Alachisoft.NCache.SessionStoreProvider, Version=4.6.0.0, Culture=neutral, PublicKeyToken=1448e8d1123e9096" />
</assemblies>
</compilation>
...In case of NCache that's the assembly that implements the ASP.NET Session State Provider. So, that's how NCache plugs into the ASP.NET framework. Any third party cache would have to do that. So, you just add that line in the assemblies and secondly you just go to the sessions tag and you specify this specific to the distributed cache that you pick.
...
<sessionState cookieless="false" regenerateExpiredSessionId="true" mode="Custom" customProvider="NCacheSessionProvider" timeout="20">
<providers>
<add name="NCacheSessionProvider" type="Alachisoft.NCache.Web.SessionState.NSessionStoreProvider" sessionAppId="WebF1" cacheName="democache" writeExceptionsToEventLog="false" enableLogs="false" />
</providers>
</sessionState>
...In case of NCache you just copy this and there are a couple things that you need to make sure. First you need to make sure that the mode is 'custom'. So, because custom means third party storage. And, then 'timeout' make sure it is what you want it to be and everything else you can keep as default and just specify a cache name here, right there. So, it should be just 'demoCache'. As soon as you make this change and you run the application again or actually as soon as you save this, you know, that ASP.NET worker process recycles. It'll pick up NCache configuration and suddenly you'll see that every session will be one count. So, all those, you know, that count that we were seeing in NCache in this PerfMon here.
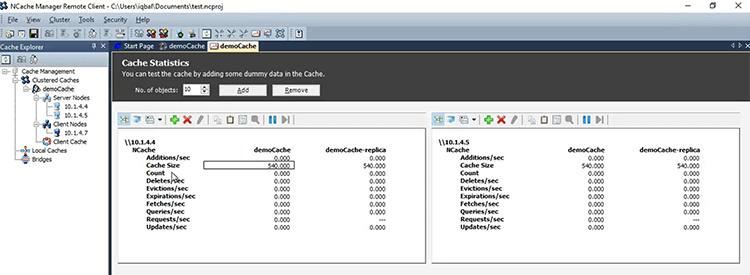
So, these would be 540 sessions being stored and of course as you add more sessions it's going to increase the count.
So, with this little effort you can immediately give your application a major boost. Same thing goes with the View State. With the output cache there is a little bit more configuration involved but the view state and the session you can do them in a matter of minutes, without any effort and suddenly the applications use a huge boost.
Application Data Caching Overview (API)
So now, let's move to the application data caching which is what the bulk of this talk is about. So, if you need to use the cache for application data caching, you have to program to its API. That's because, there's no standard API is still. So, what we did is, we picked our API to be as close to the ASP.NET cache object.
Cache ConnectionCache cache = NCache.InitializeCache("myCache");
cache.Dispose();Employee employee = (Employee) cache.Get("Employee:1000");
Employee employee = (Employee) cache["Employee:1000"];
bool isPresent = cache.Contains("Employee:1000");cache.Add("Employee:1000", employee);
cache.AddAsync("Employee:1000", employee);
cache.Insert("Employee:1000", employee);
cache.InsertAsync("Employee:1000", employee);
cache["Employee:1000"] = employee;
Employee employee = (Employee) cache.Remove("Employee:1000");
cache.RemoveAsync("Employee:1000");NCache has been in around since 2005, so, it's like almost 11 and a half years now. But, it looks very similar to the ASP.NET cache object. There is some extra stuff, so let's say, you connect to the cache by a cache name. You get a cache handle. Then that cache handle is what you use to do cache.Get. Get contains Add, Insert, Remove and there's an Async version of it, which means don't wait for the cache to be updated and, then of course when you call the Async then you can specify a callback. So, your callback gets called in case something goes wrong.
Let me show you how this looks like in a visuals, like in a proper application. So, if you were to have a … This is a standard console application. You would need to reference the Assembly of your cache. In case of NCache, it's just these two assemblies, Alachisoft.NCache.Runtime, Alachisoft.NCache.Web. You specify the same namespaces here and then beginning of the application which in case of ASP.NET this will probably be in the global.asax in the Init method or the application start method. But, here let’s say, you connect with the cache based on the cache name and the cache name, as you know, that's how, at least in NCache that's how cache is recognized and you get a cache handle. Then you create your objects and you do a cache.Add. You specify key. This is not a good key. it should have more uniqueness in it. But, let's say, that you specify key and here's your value the actual object.
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("demoCache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Data Expiration
And, in this case NCache is doing this thing called absolute expiration. So let me, come to that. So, we talked about the application data caching wanting to keep the cache fresh. So, if you can't keep the cache fresh then you force to use it for read-only data. So, how do you keep the cache fresh? There are more than one way. The first way which is pretty much every cache has it is called the absolute expiration. This is where you specify how long you want to keep this in the cache. So, you say to the cache I feel comfortable only for one minute that I don't think this data should stay in the cache for more than one minute because, I think if it was kept in the cache for more than one minute somebody else is going to update it and the cache will go stale. So, you're making an educated guess about how long the cache should have your data. And, of course every data that you cache, you should have some sort of expiration for it. Pretty much… I mean some data you can pretty much assume it's never going to be expired so, you can say no expiration. But, 99% of the data or something more than 90% of the data needs to have expirations. So, absolute expiration is what keeps the cache fresh based on an educated guess.
There's another expiration called sliding expiration. Its purpose is totally different. Although it uses the same name call expiration. The sliding expiration says expire this if nobody touches this object for this long, let's say for 10 minutes, for 20 minutes. And, this is used for more of a transient data. So, this is used for more of ASP.NET specific data, where you're actually just doing clean up. You’re saying, you know, nobody else needs it anymore. So, if a user no longer uses the session for 20 minutes, you're saying this users logged out anyway so, remove the session. So, that's a clean-up expiration. Then absolute expiration which is a synchronization purpose. The purpose of absolute expiration is synchronization. And again you can do it, you can expire things in 10 seconds, 15 seconds, 1 minute, 5 minutes, 10 minutes. The most common expiration will probably be a minute or two minutes.
But, there's a problem with expiration. It is that you are making a guess. You are saying I think it's okay to cache it for this long. But, there's no guarantee. In some cases there may be but in many cases there's no guarantee. What if there's another application that is also accessing the same database and they go and update that data. There may be some scripts running. So, whenever something like that happens expirations are not sufficient. And, that's where you need the cache to have this ability to monitor changes in the database.
If you can specify a association between whatever is in the cache versus whatever it's corresponding data is in the database and you can say to the cache please monitor this data set. If this dataset changes, go ahead and remove that item from the cache.
Database Dependency
Let me show you how that is done. So, there's a feature called SQL dependency in ADO.NET that NCache uses. Which allows NCache to become a client of your database. And, this could be a SQL database, this could be Oracle. And, then NCache tells the database to notify it when that data set changes and that data set is an SQL statement that you specified. Most of the time it will correspond to either one or more rows in a table that were used to construct this object that you cached. So, for example, here, so, if I were to go to the SQL dependency thing, again same thing. You have a cache handle and then when you're adding, this cache.Add, you're now specifying, in case of NCache this thing called cache item which is sort of a structure that contains the value plus some other metadata. One of the metadata that contains is called a SQL cache dependency, which is an NCache class that maps to the ADO.NET SQL cache dependency on the server end. You pass it a connection string and you pass it a SQL statement.
private static void AddProductToCacheWithDependency(Product product)
{
// Any change to the resultset of the query will cause cache to invalidate the dependent data
string queryText = String.Format("SELECT ProductID, ProductName, QuantityPerUnit, UnitPrice FROM dbo.PRODUCTS WHERE PRODUCTID = {0}", product.Id);
// Let's create SQL depdenency
CacheDependency sqlServerDependency = new SqlCacheDependency(_connectionString, queryText);
CacheItem cacheItem = new CacheItem(product);
cacheItem.Dependency = sqlServerDependency;
// Inserting Loaded product into cache with key: [item:1]
string cacheKey = GenerateCacheKey(product);
_cache.Add(cacheKey, cacheItem);
}So, you say something like 'Select some columns from the Products where the Product Id is whatever the value is'. So, this is one product that you're mapping this to. So, you're saying to NCache use this SQL statement, use this connection string and monitor that data set or ask SQL server to monitor that data set. Actually, this code is running here, right. Because, that's where the NCache is.
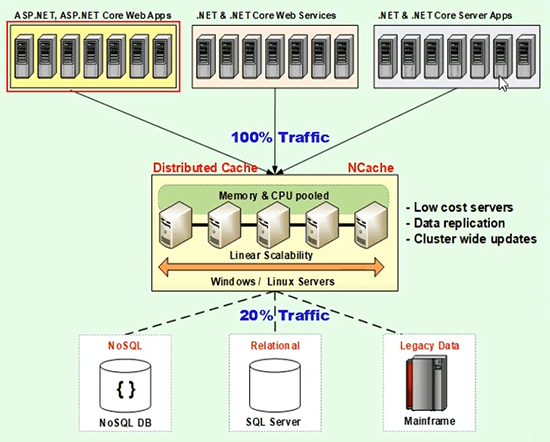
So, this then talked to the cache cluster and the cache server then actually makes the ADO.NET call and the cache server now talks to the database and becomes a client. And, the cache server is the one that receives the notification. And, cache server is the one that actually removes that item from the cache, if the database notifies it that this data changed. So, by having that feature built in, you suddenly have the flexibility that you can keep data in the cache that you can't even predict when it might change, you know. But, you just know that it might change in an unpredictable fashion, so, you can use specify SQL dependency.
This is a really powerful feature. This is the feature that allows a cache to let you cache transactional data. Even when you don't have control over the updates all the time and because of that you will cache all sorts of data because of that cache will become actually useful. And, this can be done in a number of ways if the underlying database supports database notification which is the case in case of SQL server and Oracle then it will use the SQL dependency or the Oracle dependency feature, if not, the NCache at least has a built-in polling mechanism where it can also let you specify it. … There's a mechanism where you specify a special table NCache monitors it and any rows that change in it there's a corresponding cache item that it then removes.
And, a third option is that you actually make cache calls from within a CLR procedure. So, whenever a data changes, there's a database trigger that calls the procedure, which calls the cache. And, that can add data, update data, or remove data from the cache. The only thing with the CLR procedure is that you don't want to make … I mean you want to make Async calls. Because, whatever you called, it's actually your database has now become a client of the cache like the backward, right. So, it's trying to update something which will go in here and then it might replicated. So, all of that's happening within a database transaction and as you know, database transactions time out fairly quickly. So, by making async calls you can immediately make the cache call and then return the control.
So, those are the three ways that you can ensure that a cache is kept synchronized with your relational database. Of course the same logic applies to non-relational. What if your data is in a cloud, somewhere? Or it's in mainframe. You know, you have a web method call to go and fetch it always. Then, in case of NCache at least, you can have a custom dependency feature where your code is registered on the cache cluster, NCache calls it every, let's say, 15 seconds and says go ahead and please check your data source and see if that data has changed. If it has, fire an event and then the same logic kicks in.
So, again keep the cache fresh is the most important thing in a distributed cache. If you can't keep the cache fresh it's then very limiting in its use.
Read-Through and Write-Through
There's another feature called Read-Through and Write-Through. Read-Through is a feature that is again a very useful, very powerful feature. It is essentially again your code that runs on the cache server. Where is it? Here. So, let's say, you implement a read-through interface in case of NCache. Now read-through / write-through is a concept that is implemented by NCache. It's also implemented by many of the Java players but on the .NET side NCache is the only one that has it. So, read-through interface essentially is your code. It has an Init method, a Dispose method, so Connect and Disconnect and then Load method.
...
// Perform tasks like allocating resources or acquiring connections
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect(connString == null ? "" : connString.ToString());
}
// Perform tasks associated with freeing, releasing, or resetting resources.
public void Dispose()
{
sqlDatasource.DisConnect();
}
// Responsible for loading an object from the external data source.
public ProviderCacheItem LoadFromSource (string key)
{
ProviderCacheItem cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncOptions.ResyncOnExpiration = true;
// Resync provider name will be picked from default provider.
return cacheItem;
}
...It gives you a key and based on the key you're supposed to figure out where to go and get the data. And, you not only return the data, but you also return some of the metadata, like expirations and other things with it. What is the value of read-through? So, again this code is something that you implement and you register on the … So, it’s this code that runs here on the cache server. So, we've talked about a custom dependency. So, if you have a custom data source, that's a code that runs on the cache server and the read-through is also something that runs on the cache server.
What is the read-through good for? Why should you use a read-through? There are two or three benefits. Number one, you're consolidating all your persistence code into one place. So, if you have multiple applications using the cache, let's say, you have multiple applications, you know, they don't have to all implement that code over and over again. So, it is kept within the cache server itself. That's the first benefit. Number two benefit is that when you expire something, let's say, you expire something because of expirations or because of database synchronization, instead of removing that item from the cache why not just reload it. Because, if you remove it, next time the application wants it, it's going to reload it anyway. So, you can have the read-through mapped with this and say where the cache says okay if this item expires or if it gets … if it's auto sync and I need to remove it I’ll instead just call the read-through. So, why is it good to call the read-through? I mean what's the big deal? Why not just reload it by the application? Well, if you have a high traffic application, the chances are that a lot of users are going to be asking for that same data. You have hundreds of thousands of these items and they all keep expiring at their own time. So, for every time an item expires, you'd have hundreds if not thousands of requests hitting the database for the same item. And the will all go and update the cache again. So, a lot of unnecessary traffic is going to the database. Which, if you had a read-through, it would never leave the cache. It will always stay in the cache and at some point it will just get updated. So, the traffic to the database never occurs.
The second feature is write-through which works exactly as read-through except of course it's for writing. So, let me show you that. For example, here again, you have the Init, you have the Dispose, but now you have a Write and gives you the actual object and then the write could be either add, update, or remove, right. So, all three of them are called write. So, based on whatever that operation type is you go and update your database or your data source.
#region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result = sqlDatasource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Now, write-through has another benefit. It has the same benefit as read-through in terms of commonality of code. The second benefit that write-through has is called write-behind. Which is that, you can update. So, there's a feature called write-behind where you can update the cache immediately in a synchronous fashion but the database updates happen in an asynchronous fashion. Why is that a good thing? Well, because that database is slow. So, if you know, if you're confident that the database update is going to be done in a timely… it's predictable why not just queue it up. It gets queued up and the cache actually performs this operation in the background. That queue also gets replicated to more than one server. So, if any one server goes down the queue is not lost.
I think everything you have to see in the context of scalability. Whatever is fast, even if it's an in-memory database, it's all on one server. So, the more updates are sent, the more reads are sent to it, the more load gets put in the database is, the slower it becomes. Just like single point of failure. That's it. That's the real reason, why all of this exists and then within the context of all of this existing you get all the additional benefits. If you had a write-behind feature, suddenly your application only has to update the cache in a synchronous fashion. Because, once the cache is updated, the cache will take care of the database update in an asynchronous fashion. And, that queue has its own optimization. It can do bulk updates, it can replicate. So, write-behind has the performance, the speed part that you talked about is more relevant to write-through and write-behind then to the read-through.
Read-through is also something that, you know, it might be faster in some cases then application accessing it but in write-behind it's definitely always faster.
Any questions? I've got only a few minutes left. I'm going to talk about one more feature and then I'll go to the end. So, people who are used to doing standalone In-Proc in-memory caching, like ASP.NET cache object, when they move to a distributed cache, many of our customers call us and say, you know, you were promising the cache will actually improve my performance. My performance actually went down. Why is that? Can anybody guess? Why does that actually slow down, as soon as you move to a distributed cache versus an In-Proc cache. Network latency. Network latency is one. A bigger problem is the serialization and deserialization which is a huge cost.
Client Cache or Near Cache
So, what some of the distributed cache is doing including NCache, they implement this thing called a client cache, some call it near cache. It's a subset of this cache, that is kept within the application server. It may even be In-Proc or it can be OutProc. But, a lot of time it's In-Proc. So, it gives you the same benefit of a standalone In-Proc cache except that it is synchronized with this.
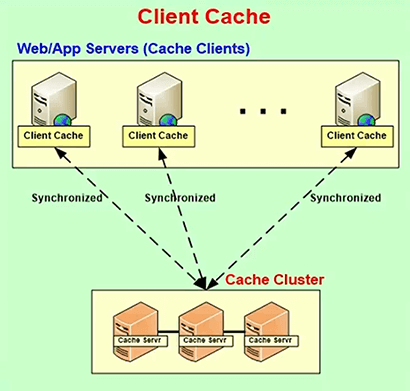
And, this is a smaller subset, so let's say, this might be 16 gig each server, this might be just one gig. And, it's a moving window, right? So, whatever you’re caching is kept and then as you move on that the older items either expire or they get evicted and then new data gets cached.
So, a client cache gives you the real performance. It keeps data in an object form within the application process. So, if you're fetching it hundreds of times or tens of times, the first time of course you need to fetch it from the distributed cache. Maybe, the first time you'll fetch it from the database. It goes to the distributed cache then goes to the client cache but once that is done all further reads are being done within your own heap which is super-fast. So, this is a feature that's really powerful. You definitely want to take advantage of this.
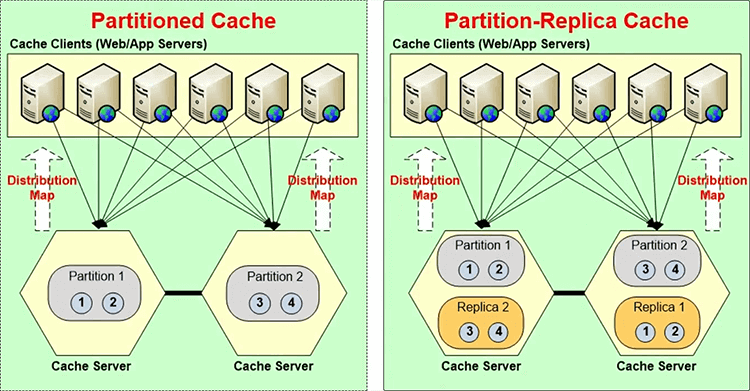
So, there are a few things you need to make sure. A distributed cache, just like a database runs in your datacenter in your production environment. So, it must meet some of the architectural requirements. It must have high availability. It must give data reliability and scalability. So, it must do intelligent replication.
I'm not going to go into the details of this. You can look in to it. You can do the research online. For example, if you have multiple datacenters, you expect your database to replicate, why not the cache? You know. Why shouldn't the cache also be available in a synchronized fashion across multiple… So, yes a good cache should be.
.NET Distributed Caching Options
If you're doing .NET applications, at this time, you know, there are pretty much two options that you have for caching. One is Redis that Microsoft has put on Azure. The other is NCache. On the Java side, as I said, there are a number of players who are pretty good.
So, I just want to do a really high-level comparison.

NCache is the oldest .NET Cache. It's been in the market since 2005. It's native .NET. It is also open source, just like Redis. It is also available on Azure or an Amazon both. Redis … So, there are two versions of Redis, one that is developed by Redis Labs, which only runs on Linux. In fact Microsoft uses that version in Azure. And, the version that Microsoft ported to Windows, they don't even use it themselves. Actually, we've heard a lot of complaints from customers. It’s not very stable. But, outside of Azure the only version that you have for Windows is the one that Microsoft ported, the MS Open Tech. But, other than that if you go to Redis they'll only give you the Linux version. On Azure itself there are two differences between NCache and Azure which is that NCache actually gives you a cache server as a VM. So, you can run all that server-side code yourself, monitor things. Redis gives you cache as a service. So, the cache is a black box. You only have a very simple API that you call. And, the limitation of that is that you don't get all the features that we just talked about. How do you do database synchronization? Read-through write-through. Actually, I didn't even go into SQL searching, because, we didn't have time. So, these are the two ways that you can do this. If you want to learn more about this you can come to our website and we have a fully detailed comparison document. So, if I were to go into Redis vs NCache here, you can you can see a full-blown document. You can also download it. It's a feature by feature comparison based on their documentation and ours and then you can see which one meets your need. Any questions? That's the end of my talk. Thank you.
Is there any dependency on .NET Core Framework or can you use it with .NET 4.0? Good question. So, NCache server supports .NET frameworks. It's 4.0 or later. The NCache Client by default is .NET framework of course. We are about to release the .NET …. So, we support ASP.NET Core. So, the .NET Core that can run on Linux, we don't support yet because it has limitations. But, the .NET Core that runs on ASP.NET framework, underneath only on Windows, especially ASP.NET Core NCache will support it. Thank you very much guys.