Twin Cities Code Camp
Scaling .NET Applications with Distributed Caching
By Iqbal Khan
President & Technology Evangelist
See this hands-on demo of a distributed cache and learn best practices for using a .NET cache in various environments. This talk covers:
- Quick overview of scalability bottlenecks in .NET applications
- Description of distributed caching and how it solves performance issues
- Where can you use distributed caching in your application(s)
- Some important features in a distributed cache
- Hands-on examples using a distributed cache
Overview
Thank you everybody for coming. My name is Iqbal Khan. It’s a beautiful day outside. I’m here from Tampa. So, much nicer temperature here. I was expecting much cooler weather than what we have here. So, thank you for staying indoors. I am a technology evangelist at this company called Alachisoft. We are the makers of NCache. Just the next one or two minutes is going to be a marketing statement. So, we have two products for the .NET space. One is our main flagship product called NCache which is a distributed cache for .NET. That’s the expertise that we have. So, we've been in this space for about 10 years and that's how we've built expertise in this specific topic.
We have another product called NosDB which is a something that we launched late last year. It's an open source NoSQL database for .NET. It's like a MongoDB level features but native .NET and again all open source. NCache is also open source and, so is NosDB. Please do take a look at our products.
So, I would prefer to have a more interactive discussion. We're going to go through a combination of some architectural conceptual discussion and some source code. So, we can actually see how you would go about using a cache for your application. So, let's get started.
Scalability
Let’s get a few definitions out of the way. Number one is; what is scalability. Scalability is not performance. So, if your application performs fast with 5 users, it's not scalable unless you can have the same good performance under 5000, 50,000 or 500,000 users. Of course, if your application does not perform fast with 5 users then you need to look at other aspects than what we're going to talk about.
Linear Scalability
Linear scalability is more of a deployment architecture terminology. If your application is architected in such a way that you can add more servers to increment your capacity, your transaction capacity, by the way when I use the word scalability I’m mainly talking about transaction capacity, I’m not talking about a lot of data. So, we're not talking about terabytes of data in terms of scalability. We're talking about can you handle a lot of transactions, a lot of activity. So, a linear scalability means that you can grow your transaction capacity just by adding servers and there are no bottlenecks and that is what we want to achieve.
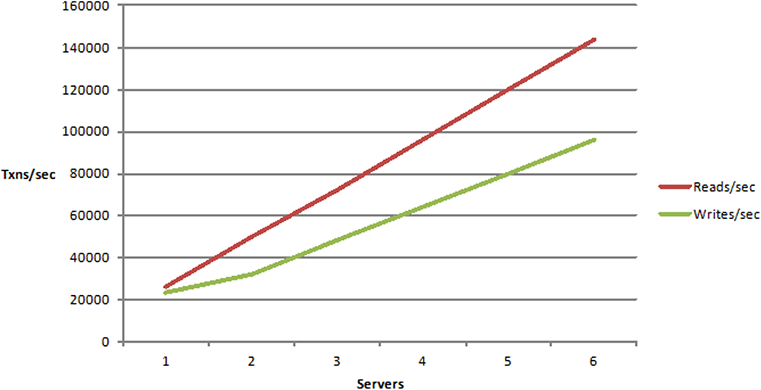
Non-Linear Scalability
Non-linear of course is not something that we want to achieve. This means that it doesn't matter how many servers you add your performance is going to go down after a certain point, because there's some fundamental bottleneck in your application architecture in your deployment, that is preventing you from being able to scale.
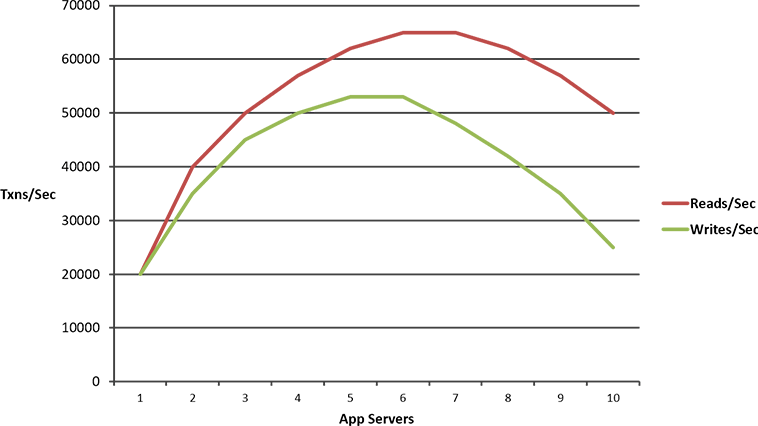
Which Applications Need Scalability?
What type of applications need scalability? These are usually server type of applications, ASP.NET, ASP.NET Core now, Web Services which are usually WCF, IoT backend which is usually web services, although they don't have to be. Big data processing applications. These are generally done in Java but if you were to do it in .NET you would have the same issue as you do in Java and any other server application that needs to process a lot of transactions. You could be, for example, you could be a bank or a financial services company with millions of customers. They're calling you to change address, maybe transfer funds and at night you have to process all of this for either compliance or for other SLA reasons. So, even though you have, you know, those are more batch processing, back-end processing, those are your other server apps that will still need to be able to process that much information and if they're not able to then, you know, you're in a lot of trouble.
The Scalability Problem
If you have these applications, most likely they will need scalability. So, let's now talk about where is this problem? Where is the scalability problem, that we're going to try to address? Scalability problem really is not in the application tier. Your application, all those that I talked about, generally are architected in a way that you can add more servers and there's no problem at all. The problem is with your data storage. What I mean by that is where your application data resides, your relational databases. This could be SQL server, Oracle, MySQL. It's not any one specific vendor. The concept of relational databases by design cannot scale. Actually, they can’t scale also in terms of amount of data also. That's why NoSQL databases have become so popular, but, especially on transaction side and, the same if you have a mainframe legacy data. Many applications have to access legacy data. So, that's where the bottleneck occurs and, if you have that bottleneck, then it doesn't matter if this tier is scalable, you won't be able to scale.
NoSQL databases have become popular for exact this reason that they provide scalability. And, you know, and we also have a NoSQL database product, but a lot of the time they don't address the issue. They cannot address the issue because for a combination of technical and business reasons you cannot use them. To use a NoSQL database you have to put data in them and not in your relational database. Some data you can do. You can definitely put in the NoSQL database but a lot of your traditional business data is going to stay in relational databases. So, if you can't move your data to NoSQL databases, they're no good. So, you have to solve this problem, keeping in mind that you're going to continue living with relational databases, even if you put a NoSQL database in the mix, that is only a subset of the data. It's not usually a replacement of relational databases. And, being a NoSQL database company, you know, I’m being very honest with you, when we talk to our customers, we don't say stop using relational, that's never going to happen. We say, use it as an augmentation of relational. So, if you have to stay with the relational, you have to solve that problem with, you know, with that in the in the mix and that's where a distributed cache comes into the picture, that's why we're having this conversation.
Distributed Cache Deployment (NCache)
A distributed cache, let me, define that a little bit. A distributed cache is distributed. It lives on two or more servers, here. It's a separate caching tier, logically speaking. Physically can be on the same box as the application but logically it's a separate caching tier. Two or more servers and a distributed cache usually forms a cluster. So, it is usually a cluster of these, TCP based clusters is the most common. NCache definitely uses TCP for clustering. And, this cluster means that the, all the resources, all these servers, the CPU, the memory, the network cards, are all pooled together. And that's how this becomes scalable. Because, you can add more servers, as you need to increase capacity.
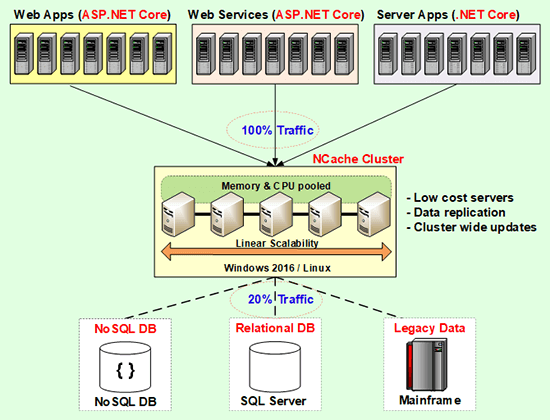
This is something that you can do here also. But, you cannot do here. As I said, you can add another SQL database in the mix, but, you know, you need to have this in the picture. As soon as you have this in the picture, you will need something like this in your mix.
A distributed cache lives on inexpensive servers. These are not high-end database typical web server type of configurations. Most of our customers have an 8 core box, is like it used to be a dual CPU, now we just use the word 8 cores and a 64 bit with just lots of memory. Lots means 16 to 32 gig is pretty much the average per server that we see. We don't even recommend more than 64 gig on each box. Because, if you have more than 64 gig of memory, .NET requires garbage collection. The GC itself is a pretty time consuming task and starts to become a bottleneck by itself. So, it's better to have more servers than to have really high ends few. Because, you know, even though the cache is distributed by design, now the bottleneck starts to become a garbage collection. And, we've learned this through a lot of painful experiences over the years. You know, we had customers who went up to 128 gig and suddenly there was a lot of pressure on the CPU. So, they had to bump their processing power quite a bit and it started to look more like a database. So, then you know, we recommended that bring it down.
You cache data that is residing in the database. And, 80% of the time you will basically be going to the caching tier, 20% of the time you go to the database. Cache is in-memory super-fast, much faster than any database including NoSQL database, including faster than our own NoSQL database. NCache is at least an order of magnitude faster than any database. Because, of the fact that, you know, databases have to go to the disk. But, all the updates of course have to go to the actual database. So, that's where the 20% comes plus of course some of the reads.
Now, if you do that, suddenly all the pressure is taken off of the database. Now it performs. Your reads are much faster and the updates are also much faster. So, you are able to achieve that scalability but you're also able, not only is the application scalable now, it's suddenly faster. Although, the main reason for using a cache is not to improve performance, which is again kind of opposite to what people have traditionally thought, you know, that cache is there to improve performance. That’s, in a standalone situation, yes, that is the case. Even the databases use in-memory caching. Our NosDB also uses caching built-in but it's really for scalability, where you need to be able to because, that's a problem that you cannot buy yourself out of. You cannot buy more expensive hardware to get scalability. You have to architect the application and use the right infrastructure, or the right components as part of your architecture, if you're going to have a scalable application.
On the Java side, this is called an in-memory data grid. On the .NET side it is called a distributed cache. Another word for this is an in-memory NoSQL key value store. So, I mean there are three different ways to look at it. This is not a NoSQL database it is a NoSQL key value in-memory store. Because, it does not do any persistence, it does not have a permanent store.
So, when you have a picture like this, architecturally I want you to be convinced that you will now have an application that will never have bottlenecks. If you architect your application to use this as for your infrastructure. Any questions, so far before I move to the more depth.
I guess it's up to the details how do you know, whether the cache is stale or if you update something out of the case? Let me come to that. Good question.
Common Uses of Distributed Cache
So, let's say, that we're convinced that we need to have a distributed cache as part of our application architecture, the next question that comes to mind is how do you use it? Where do you use the cache and what are the issues related to each type of use? So, as a .NET developer, and again my focus is .NET but the same concepts apply to other applications too.
Application Data Caching
The most common use case is application data caching, that's what I was talking about up until now, where you have a database and you just cache data here. So, the goal is to not go to the database as frequently. And, you get all the benefits that I talked about. As soon as you do that, there's a problem that occurs, which is what you just talked about. The data now exists in two places. One is the permanent master store, which is your database, where always must and the second is the cache. And, in fact within the cache it exists in more than one place and I will talk about that too.
So, when the data exists in more than one place what could go wrong? You know, it could get out of sync. So, if a distributed cache cannot handle that situation you're forced to cache read-only data. In fact most people, when they think about cache the knee jerk reaction is, it's only for read-only data. Because, if I cache data that changes, what I’m calling transactional data. Then it's going to go out of sync. And, if you know, that that classic problem of withdrawing one million dollars twice from the same bank account, it comes here. So, you know, if a cache does not address this problem then you're limited to a very small subset. About 10% to 15% of the data is all you can cache and that is not sufficient. So, a good distributed cache must address this problem and I’ll talk about that.
ASP.NET Specific Caching
Second use case is, if you have an ASP.NET application, there are three different things that you can store in it. Of course this is changing as new frameworks are coming. So, the most common is the ASP.NET session state, which is there in both the ASP.NET core and the traditional ASP framework. Sessions are something that by default you store either In-Proc or you store them in SQL server. Both have scalability problems. SQL also has performance problems. And, because relational databases were not designed for storing blobs and sessions are stored as blobs. And secondly, you know, the same reason that you'd want to cache application data and not go to the database you don't want to keep sessions in the database either. So, this is a very very ideal use case for ASP.NET applications. And, you know, that's the first thing most of our customers use. You know, if you have an existing application and you want to incorporate distributed cache, the least effort required to incorporate it is sessions. Because, ASP.NET framework allows a third party cache to plug in. There's no programming needed. You just make a change to the web.config. In fact, let me, quickly show you that. I will just jump back and forth.
So, for example, I have this small ASP.NET application and I have a web.config here and I’m going to of course use NCache as the example but, let's say, to use NCache as the session state provider you need to put this assemblies. So, “add assembly” tag. So, this assembly of NCache has implemented the ASP.NET session state provider interface.
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<system.web>
<machineKey validationKey="A01D6E0D1A5D2A22E0854CA612FE5C5EC4AECF24" decryptionKey="ACD8EBF87C4C8937" validation="SHA1" />
<compilation defaultLanguage="c#" debug="true" targetFramework="4.0">
<compilers>
<compiler language="c#" type="Microsoft.CSharp.CSharpCodeProvider, System, Version=2.0.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089" extension=".cs" compilerOptions="/d:DEBUG;TRACE" />
</compilers>
<assemblies>
<add assembly="Alachisoft.NCache.SessionStoreProvider, Version=4.6.0.0, Culture=neutral, PublicKeyToken=CFF5926ED6A53769" />
</assemblies>
</compilation>
<customErrors mode="RemoteOnly" />
<authentication mode="None" />
<authorization>
<allow users="*" />
</authorization>
<trace enabled="false" requestLimit="10" pageOutput="false" traceMode="SortByTime" localOnly="true" />
<!-- For NCache Developer Edition replace 'myPartitionedCache' with 'myCache' or any other local-cache-->
<sessionState cookieless="false" regenerateExpiredSessionId="true" mode="Custom" customProvider="NCacheSessionProvider" timeout="1">
<providers>
<add name="NCacheSessionProvider" type="Alachisoft.NCache.Web.SessionState.NSessionStoreProvider" exceptionsEnabled="true" enableSessionLocking="true" emptySessionWhenLocked="false" sessionLockingRetry="-1" sessionAppId="NCacheTest" useInProc="false" enableLogs="false" cacheName="myPartitionedCache" writeExceptionsToEventLog="false" AsyncSession="false" />
</providers>
</sessionState>
<!-- GLOBALIZATION
This section sets the globalization settings of the application.
-->
<globalization requestEncoding="utf-8" responseEncoding="utf-8" />
<xhtmlConformance mode="Legacy" />
<pages controlRenderingCompatibilityVersion="3.5" clientIDMode="AutoID" />
</system.web>
<system.webServer>
<directoryBrowse enabled="true" showFlags="Date, Time, Size, Extension, LongDate" />
</system.webServer>
</configuration>So, that's how it is complying with the ASP.NET framework spec to be a third-party cache. So, that's the first thing that you do and second you change the name space. Actually, you just use this tag. So, you make sure that the mode is custom and the timeout is definitely not one minute. It should be 20. And, I’ll come back to this. That’s the cache name.
In case of NCache, all caches are named. I’ll come back to this. So, that's all you do and your application start storing the sessions in a cache. And, you'll immediately see a performance boost, because it's in-memory, much faster than SQL. Not faster than In-Proc but faster than SQL but more scalable in both cases.
The second use case for ASP.NET is view state and that is if you are not using the MVC framework, if it's still in legacy ASP.NET you have a view state, which you may or may not know. A view state, for those of you who don't know, it’s an encrypted string that is sent by the web server to the browser only to come back when there's a post back. So, this could get to hundreds of kilobytes in size. Multiply that by millions of requests that your application has to process and there are two bad things that are happening, one it is consuming a lot of bandwidth and bandwidth is not free. When you host your application, you have to pay for bandwidth. Second, the response time is slower because it's a much heavier payload. So, if you could cache that on a server end, it would just eliminate all that and make the application faster.
Output cache is an asp.NET framework which allows you to cache page output, so that, if the page output doesn't change it will just take it from the last execution. So again, there it's better to plug in a distributed cache in a web farm than to keep separate copies of that output cache in each web server. What you want to do actually is, make these web servers totally stateless from application management perspective. If they are stateless you can do all the patches, you can, you know, all the bug fixes, any upgrades to your application, are a lot more frequent than any upgrades to the cache in terms of software upgrades. So, if there's no state being maintained here, you could drop any of that box from the web farm, the user won't even notice. Because, all the state is being maintained here or in the database and these are again not something that you touch that frequently, so again, cache that.
Now in case of ASP.NET specific caching, there's one good thing that that all these require no programming. So, you just plug them in immediately without any effort. The only thing you do of course is some sanity testing. For example, ASP.NET session state, if you plug it in and you were using In-Proc sessions, you might discover that not all of your objects are serializable. And, you didn't know and suddenly your application will start throwing exceptions. So, I mean, you know, that level of testing that you need to do. But, now there's another peculiar problem, unlike this one where you have two copies of the data, now the data exists only in the cache.
So, when an in-memory store is your master store, what could go wrong? Machine goes down. Yeah, you know, if any server goes down you lose data and you don't want to lose any of this data, especially not the sessions. So, a good distributed cache must address this and this is usually done through replication that the same data exists at least in two places and if that does not happen then please don't put any sessions in that cache, unless you don't, it's not really… it doesn't matter if your users use this session, which is not the case in most situations.
Runtime Data Sharing
The third use case is runtime data sharing through events. This is something that typically people did with message queues, which you know, they have their own place and a distributed cache is not here to replace them but a distributed cache is much faster more scalable and if the messages or if there's the data sharing is being done in the same location, in the same datacenter then you can use a distributed cache in a Pub/Sub manner, you can do that. There are also other types of events you can, you know, show interest in certain items. Say, if this item changes please notify me. Or in case of NCache there's a feature called continuous query where you could also do a SQL statement and say, 'SELECT CUSTOMERS WHERE CUSTOMER.CITY = NEW YORK'. If this dataset is ever updated, deleted, or if a new object is added, updated, or deleted, please notify me. So, if that type of monitoring that the application can do and that's how the consumers can be a lot smarter about what is it that they want to be notified about. And, the producers can keep on updating the cache.
So, that's the third use case that a lot of people don't know but now it's becoming more and more obvious that cache is a very good place to do this. Because, you're already using the cache for these two reasons. So, why not put this in and this is very simple to incorporate in your application. Any questions, before I go into the details of these?
Demo
So, I’m going to first show you what a cache looks like. So, that then we can put that into the context of everything that we're talking about. I will use NCache as the example. So, I have a bunch of VMs in Azure. So, I’ve got a demo1, demo2 and a demo client. Demo1 and Demo2 are my cache server VMs. Demo client is the application server box. So, that's the cache client. So, I’ve got all of that.
I’m going to go and I’m logged in, let's say, I’m logged into the demo client. I’m going to go ahead and create a cache. So, I’m going to use NCache manager, the graphical tool. I’ll go ahead and say ‘Create a New Cluster Cache’.
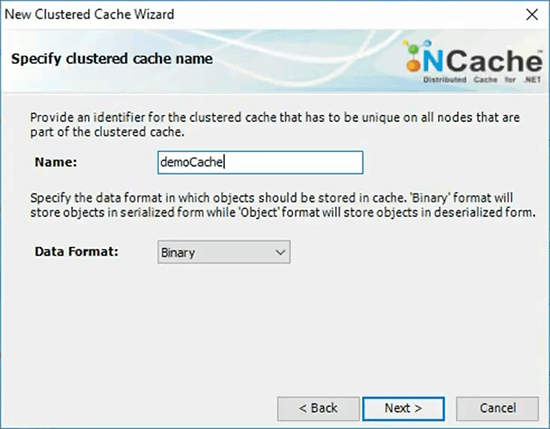
In case of NCache, all caches are named. I’m not going to explain all the detail. I’ll just give each cache a name.
I will pick a topology of the cache. Topology is actually a storage and replication strategy. So, a topology, in case of NCache, let's say, there's a topology called partition replica. So, these two are cache servers here and each server has one partition. So, let's say in case of NCache, NCache creates one partition for each server and each server contains a replica of another server's partition. Each partition contains one nth of the number of total buckets. In case of NCache there's 1000 buckets per cache.
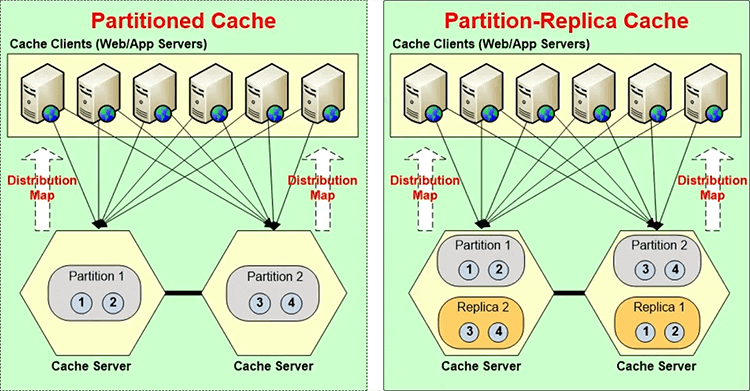
So, let's say, if it's a two node cluster, it’s the 500 buckets each, if it's a three node cluster that's one third, one third, one third.
Partition replica, the partitions are active, the replicas are not active, they're passive. So, the client only talks to the partitions and let's say if a client goes and updates an item here, the partition goes ahead and replicates it to the replica and that replication by default is asynchronous. Because, to get true scalability, you need to go to this eventual consistency model. But, in some cases, your data is very sensitive. You know, you have a lot of financial services company like banks that use NCache and their data is actually money. So, they can't do eventual consistency in that case. So, there you have to do synchronous replication, which means that the application waits until the data is updated in both places. If a server goes down, let's say, if you had a three node cluster and server 3 went down, partition 3 is down, replica 3 will immediately become active.
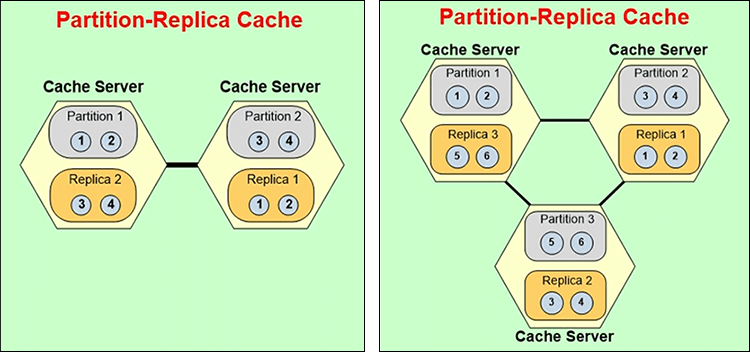
So, that's how you get the high availability and now once it is active, it will now realize there are only two servers and then three partitions, which is not how it should be. So, it will merge itself with partition 1 and 2 and once that is done, then a replica for partition 2 will be created here.
All of that in case of NCache is done at runtime without your application even realizing that that's happening. Similarly, you could have a 2 node cluster and add a third server and again the whole map will change from here to here automatically. So, that's what that choice meant.
So, I’m just going to pick partition replica as the topology.
I’ll keep the asynchronous replication.
I’ll pick my first server which is demo 1, second server which is demo 2.
I’ll take all the defaults. I’m going to specify, I’ll say, it's only 1 Gig, I’m going to specify partition size.
In your case if you have a 16 Gig machine, you should leave about 2 to 2.5 Gig for the OS and other processes and consume everything else for the cache and whatever the memory that you have left, half of it should be active partition, half of it is for the replica.
When you're doing your capacity planning, it's really important that you allocate enough memory that in case of sessions, the sessions have enough memories to stay, otherwise when the cache has used up all this memory, then the cache is considered full and, then only one of two things will happen, either the cache will reject any new entries or it will evict some of the existing entries. NCache provides you three algorithm. You know, the most common is least recently used.
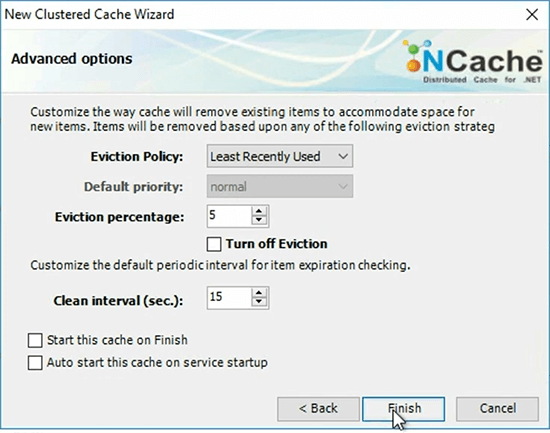
So, NCache will immediately evict 5% of the cache, when the cache is considered full. So, now that I’ve created this I’m going to go ahead and add a client node which in this case is demo client and I’ll go ahead and say start the cache.
So, when I’m starting the cache, a lot is happening behind the scenes. A new cluster is being formed. The cluster membership is being formed that is being propagated to the client. So, that the client knows what the cluster membership is? What the distribution map is? So, once all of that is done then everything is up. So, now I’m going to say statistics. I want to see some PerfMon. And, I want to quickly just run this tool called stress test tool, which quickly runs. It quickly tests the cache in your environment.
So, that way you do not have to do any programming to do this. So, this is how cache looks like. You will install something like this. Let's say you install NCache. It takes only this much time to get a 2 node cluster with an application server configured. In your case you'll have more than one client of course. The most common configuration is about 5 to 8 clients and 2 to 3 node cache cluster. And then, you know, as you add more clients, you add more servers.
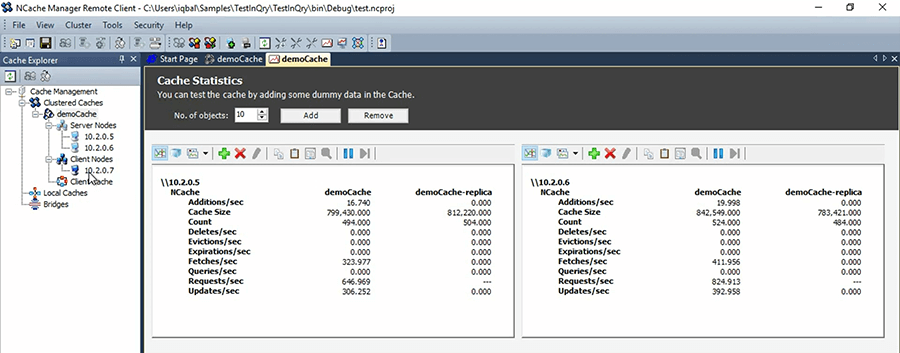
So, now that you have this cache running, now let's go back into our actual topics. So, now everything that we do you need to keep that in mind how we had this named cache created. And I’ve shown you the ASP.NET specific session state already.
Application Data Caching Overview (API)
So, now let's go into the application data caching which is the wealth of my talk today. So, in case of an application data caching, there's an API that you have to program to. Because, ASP.NET core now has an interface called IDistributed Cache which you can call that API and then behind the scene you can plug-in a third-party cache. On the Java side they have a very powerful API as a standard called JCache, but on the .NET side there is nothing. So, in most cases you will actually need to program the actual cache API itself. But, the API is very straightforward.
- Cache Connection
ICache cache = CacheManager.GetCache("myCache"); cache.Dispose(); - Fetching Data
Employee employee = cache.Get<Employee>("Employee:1000"); bool isPresent = cache.Contains("Employee:1000"); - Writing Data
cache.Add("Employee:1000", employee); cache.AddAsync("Employee:1000", employee); cache.Insert("Employee:1000", employee); cache.InsertAsync("Employee:1000", employee); Employee employee = (Employee) cache.Remove("Employee:1000"); cache.RemoveAsync("Employee:1000");
In case of NCache this looks very much like the ASP.NET cache object, if you notice. So, what you're doing basically is, you do a cache.Get, you get the object, you know, cache dot Add, Insert, Remove or and there are also async versions of it. Async means don't wait for the cache to be updated just, you know, return the control and you can specify call back in that case.
Let me quickly show you what an application looks like. So, I’ve got this very simple console application that uses NCache.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("demoCache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...
So, the first thing you need to do is make sure that you reference the cache assemblies which in case of NCache are two. There is NCache.Runtime, NCache.Web and then you need to use the name spaces which again are two in case of NCache. NCache.Runtime, NCache.Web.Caching. And, then at the beginning of your application, which in case of console is right there. In case of ASP.NET application this is probably your global.asax. You need to connect to the cache and this is where your cache name comes in, whatever you named your cache. That’s what comes in here. And, now that you have a cache handle, you can go ahead with the application, you can create your objects and you can do cache.Add. You specify a string based key and the key has to be unique. This is not a good key by the way. Your key needs to be much more specific and here's your object. And, I mean, this is how and then later on you can do cache.Get and you can get your object from the cache.
Now, this call that you made actually resulted in case of NCache, so, when you did cache.Add, it basically went, from here it went to your whichever partition that data was supposed to go into. So, it did cache.Add there and this partition then replicated that data to the it's replica. If that was an asynchronous application then only this partition was updated and the control came back. If you made an async call then even this partition and even you didn't even wait for the partition to be updated. But, just that one cache.Add call resulted in all this work being done.
And, similarly when you do a cache.Get the client goes directly where the data is. So, it uses the distribution map underneath to know where the data is and goes directly where and gets that. Let's say, if you wanted item number 3 you would go and get it straight away from there.
So, this code is behind the scene, that's what's really happening. To the database. What is your. It’s just the cache. Actually, I’ll talk about that in a bit too. So, you automatically serialized / de-serialized data? Yes, in fact even more than that. So, before the data is sent from here to here, the object has to be serialized. In case of NCache, NCache keeps it in a serialized form, in the cache. And, when you do a cache.Get it comes back and then gets de-serialized in the client itself. And, by the time you get it, it's all de-serialized. So, the API looks very straight forward to you but there's a lot of work being done.
App Data Caching Features
Now, about application data caching, the biggest concern was that the data exists in two places, right? And, if a cache does not address that concern it's going to really limit its benefit. So, how does a cache address that concern?
Absolute Expirations
Number one is called Expirations and there is the Absolute Expiration which means expire this object let’s say 10 minutes from now. So, you make it an educated guess for every object in terms of how long is it safe to keep that object in the cache. And, at the end of that time the cache automatically removes that object.
Let me show you how that looks like in the code. So, in case of NCache if you look at the same cache.Add call, the third argument is a date time argument which has the value of one minute from now.
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("demoCache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...So, it is basically saying to the cache expire this object one minute from now. It doesn't matter whether you need it or not after one minute that object will be removed from the cache. Why? Because you don't feel comfortable keeping it in the cache longer than one minute. And, why don't you feel comfortable? Because, you think it's going to change in the database. It's not safe to keep it in the cache.
Sliding Expirations
There's another type of expiration called Sliding Expiration, which serves a totally different purpose. It is not for keeping the cache fresh, it's more for cleanup. So, in case of sessions, for example, NCache uses a sliding expiration, which says basically, you specify an interval and say 10 minutes, 20 minutes, 5 minutes, you say. So, for that long if nobody touches that object NCache removes that item from the cache.
So, sliding expiration, although the name still is expiration, it serves a totally different purpose. It's the absolute expiration that you need for application data caching to keep the cache fresh. Almost every cache has the absolute expiration. Including Redis, everybody has it.
Synchronize Cache with Database
But, the problem with absolute expiration is that you're only making a guess. What if that guess is wrong and, the data actually changes in the database. Then what happens? We have to come up with a mechanism. So, you know, if you have the ability to synchronize the cache with the database where you can tell the cache to monitor the database for changes for this very specific data set whatever that is.
NCache, for example, uses this ADO.NET SQL cache dependency feature. Where, if you specify, if you use this feature, let me show you how it is used. If you use this feature then NCache monitors the database and it asks the database to notify NCache when that data changes. So, let's say, I’ve got the SQL dependency example. So, again I’m doing the same cache.Add, here. So, I’m doing the same cache.Add. I’ve got a key. Now instead of having the object I have a cache item which is a structure which contains the actual object plus a few other things. So, for example, it contains a SQL statement of a single row in the product table. Since, I’m caching a product in a Northwind database, this SQL statement, NCache then use it.
private static void AddProductToCacheWithDependency(Product product)
{
// Any change to the resultset of the query will cause cache to invalidate the dependent data
string queryText = String.Format("SELECT ProductID, ProductName, QuantityPerUnit, UnitPrice FROM dbo.PRODUCTS WHERE PRODUCTID = {0}", product.Id);
// Let's create SQL depdenency
CacheDependency sqlServerDependency = new SqlCacheDependency(_connectionString, queryText);
CacheItem cacheItem = new CacheItem(product);
cacheItem.Dependency = sqlServerDependency;
// Inserting Loaded product into cache with key: [item:1]
string cacheKey = GenerateCacheKey(product);
_cache.Add(cacheKey, cacheItem);
}So, there is a SQLCacheDependency class in NCache which is our own class but behind the scenes it then maps to the ADO.NET SQL cache dependency. Now, you're making this call on the actual and so, you're making the call, you need to call here. And, that call is coming to the cache servers and the cache server now makes the ADO.NET call against your SQL server database. And, now the cache server becomes a client of your database. And, it tells the database, it says, please notify me if this data set changes.
And, SQL server has the database notification mechanism sort of oracle. At least against these two databases you can use this feature. And, SQL cache dependency allows you to essentially make sure that if you can't guess you, can still rest assured that your data is going to stay consistent with the database.
Any questions on this? So, you’ve any framework components. So, NCache also has a plugin for EF, EF6 and now EF Core also, up until EF Core. Before EF Core, EF did not really have a pluggable architecture. So, we had to implement a custom ADO.NET provider and cache SQL queries.
SQL Core is a much more flexible architecture. So, now we're able to provide an L2 cache. NHibernate, which is something that it has existed for a long time. NHibernate has had that architecture for a very long time. NCache provided the L2 cache for NHibernate and also for Hibernate for the Java client. But, now EF Core has that architecture. So, the benefit of EF Core is that you don't have to make these calls. The downside is of course that it's a very small subset of the cache that you use, in terms of the features. Because all these other things, for example, the SQL dependency part is something that NCache provides and you can configure that through the config files but, also a lot of other features that I’ll talk about that you need to use which if you just go through a pluggable architecture they have to go over the least common denominator approach. So, their API, whatever they use, cannot use a lot of the sophisticated features but now all caches provide them. So, and they need to be flexible for everybody. Whereas, if you want to benefit, for example, on the Java side almost all caches have all these features that I’m talking about. On the .NET side almost none of them have other than NCache. So, it's not really a NCache’s thing, it's the fact that, you know, .NET is not as advanced or as mature as the Java community is in using these best practices. So, it's becoming more and more. The fact that now .NET Core has gone through such a big change, is a pretty good indication of how things are going to get improve.
But, as of today, if you want to keep the cache synchronized with the database expirations is not sufficient. You have to go beyond expirations. You have to synchronize the cache with the database. And, if the database does not support notifications, then you can go over the polling approach which is something that NCache has implemented.
There's a third approach which is that you can use a CLR stored procedure to directly add the data from the database to the cache. So, just like you're reversing the whole paradigm. Now, the database is feeding the cache. So, you know, for example, you have a trigger that can make the… I’m going to speed up, otherwise I won’t be able to complete all the topics. So, this is a very important feature without which you really can't benefit and you can synchronize the cache against non-relational data sources also. For example, in case of NCache there's a custom dependency feature which is your code that can make calls. Let's say, your data sources is a cloud and it's a web method called every time, to actually know what the data is. Then none of that works and this custom dependency is something that works. So, custom dependency is your code that lives on the cache and is called by the cache to check the data source.
So, once you've achieved this goal you can start to cache more and more data and really benefit. DB dependency, because I am working with the mainframe right now, SQL dependency or Oracle dependency does not work. So, how often a polling should be, because, I am working with production data with multiple million records transactions going around in a minute. So, how often. So, how do you know, like how often do you poll it? The polling is a configurable interval and it's your code that will be called. So, you then determine in each poll, how much data are you going to look at. Because, in case of custom dependency, you're going to actually go and check against a specific key and see if that key was updated in your legacy mainframe or not. So, it's basically for each key when it goes like okay check this key, check this key. In case of custom dependency. In case of DB dependency it's not one key, it's the entire data set and we have another feature in NCache called data updater. There's a cache loader, it's a cache updater which is another service where your code lives. So, there's a feature called cache loader in NCache, which I didn't actually mentioned all those features here, but, there's a feature called cache loader which is your code that can when you start the cache it can go and load the cache, pre-load the cache from your data source. So, that could your mainframe. But, there is also a feature called cache updater which automatically calls your code every configurable interval and that code can then go and check the entire data source and look for any updates based on your custom logic and whatever data is changed or whatever new data has occurred or whatever data was deleted that's something that you can also update the cache. So, the cache stays synchronized with your data source. By default, these are called at about 15 second intervals. But, it can be faster. It can be more frequent or it can be less frequent, that depends on your needs. Did I answer your question? I have more but I’ll skip that. We can talk about that later on.
Read-through and Write-through
So, once you achieve that goal you'll start to cache more and more data. Then the next thing is, okay, now you've got, what other benefits can you achieve? The next most important thing is the read-through, write-through. What is read-through? It’s again your code that sits on the cache server. So, when you do a cache.Get, So, let's say, a read-through is your code, in case of NCache you implement this interface called IReadThruProvider. It has three methods.
...
// Perform tasks like allocating resources or acquiring connections
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect(connString == null ? "" : connString.ToString());
}
// Perform tasks associated with freeing, releasing, or resetting resources.
public void Dispose()
{
sqlDatasource.DisConnect();
}
// Responsible for loading an object from the external data source.
public ProviderCacheItem LoadFromSource (string key)
{
ProviderCacheItem cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncOptions.ResyncOnExpiration = true;
// Resync provider name will be picked from default provider.
return cacheItem;
}
...There's an Init which gets called when the cache is started, disposed when the cache stops, but, the most important is this load. So, load is called it passes. So, the cache calls you this method. NCache calls this method and passes your key. And, based on that key you go to your database and you fetch that item. So, when you do that now the net effect to the client, the application is, every time you do a cache.Get, the cache always has the data. Of course if you don't want the read-thru to be called you can do that too, you can have specifics. But, the cache always has the data. So, that's one benefit. So, you're consolidating your persistence layer in a caching tier. So, if you have multiple applications using the same caching tier, you know, the application is becoming simpler because they don't have to keep the same persistence code. They just do a cache.Get and they get the domain object or the entity object from the cache. So, the cache is looking a lot more like an EF now. The read-through itself can be the EF based.
The other thing that you can do with the read-through is that you can combine this with expirations and database synchronization. So, that when those two things happen instead of removing that data from the cache why not reload it? Because, when you remove it, the application will have to reload it anyway, the next time it wants it. And ,in many cases that data may be very very frequently used. So, you really want to reload it back into the cache. So, a read-through not only consolidates the code but also improves your performance because your database is not being hit. In many of the e-commerce situations, the same data might be accessed so frequently that as soon as you remove it from the cache thousands of requests will now hit the database for the same data and we've seen customers complain about that. That keeps happening so frequently because there are millions of data items as each data item expires the database gets hit. So, overall even after having the cache, they were seeing a lot of hits on the database. So, the answer to that was reload instead of expire. So, the reload means the data never leaves the cache, it just gets updated. So, the database is never touched except by one database call that the cache makes. So, the read through is super important in that way.
The other is the write-through which works just like read-through except it does the writing. And, the write means it can be either add, update or, delete. Now, the write has another feature. One benefit of the write-thru is the same as read-thru, which is consolidation of the code.
Write-behind
The second benefit is called write-behind. You know, database updates, just like database reads are not fast. Database updates are also not fast. So, if your data is not that sensitive, if it's not something that you have to wait for the database to be updated, you can just update the cache. So, that all the application instances have the same data now and let the cache update the data to the database in an asynchronous fashion. And, suddenly your application's performance improves because, you're not waiting for the cache to be updated. So, write-behind has this added benefit. So, it builds the queue. In case of NCache that queue is replicated to multiple servers but again read-thru write-thru it's very important feature. And, this is also something that is your code that lives on the cache server.
I want you to keep this in mind all this cache loader, the updater, the custom dependency, the read-through, write-through, all that is server code that lives on it. Which is something that … again these features exist on the Java side also. So, it's not just something that NCache invented but you will not get these features in any of the other .NET basic caches.
So, once you start, once you have all of this, once you do this, now you put in a lot of data in the cache. Really starting to benefit. And, if a cache is only key value access, you know, it's not very very friendly. So, a cache must accommodate friendly ways of fetching data.
Data Grouping
So, in case of NCache there's a lot of data that you can do you can do group and sub group, tags, name tags. You can also search based on SQL or LINQ. So, you can do something like, 'SELECT CUSTOMERS WHERE CUSTOMER.CITY = NEW YORK'. And, now suddenly a lot of your data sets, especially the reference data that you need to read over and over again in a more filtered way, you can fetch it straight from the cache. And, now you have the benefit that data you want to do.
One thing keep in mind, anytime you do a SQL search, the entire data set must exist in the cache. Because, this will not go to the database. So, it will only search the cache. Let's say, if you said give me all the customers based in New York. If all the customers are not in the cache, if all the New York customers are not in the cache the NCache or any cache will not give you the correct data set back. So, that's an important thing to keep in mind that people often confuse that well if I search, if I expect, if it's not in the cache we'll go and get it from the database. But, the SQL queries are not the database SQL queries. These are cache’s own queries.
Now a lot of data, you can keep the entire data set in the cache, especially reference data and, that's where you would use these. But, at least within the transactional data also, there's subsets that can be entirely kept in the cache. So, that's how you wait. So, by keeping all of that in mind, now you're starting to benefit from the cache.
Client Cache
I’m going to go into one more thing which is this feature called Client Cache. One of the things that people are really shocked when they start to use a distributed cache is that if they were especially if they're using an In-Proc cache before, that's standalone, is that their performance actually drops. So, many customers call us and say, you know, you were saying this, performance is going to increase, scalability will improve, our performance actually dropped. And, the reason is because initially they only had a standalone cache. It was limited in size but the cache was in object form, the objects were kept on your heap and now they have to go to a cache cluster, there's a serialization, de-serialization, there was a network trip, it's much slower.
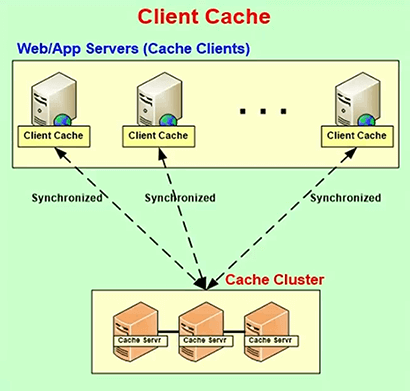
So, to work to fix that problem, many of the caches, again I use the word many because all the Java side caches have it, the .NET side NCache has it. They have this feature called client cache. On the Java side it's called near cache. This is the same standalone cache that you had previously, same means similar but, this is now aware of the fact that it's part of this clustered cache. So, whatever data it's keeping it's keeping it synchronized with it with the cache cluster. So, it just plugs in without you doing any programming.
So, with the help of a client cache you can achieve that In-Proc standalone cache performance and it's really good for a lot of the data where you're doing a lot more reads than writes. You don't want to use this for something like sessions. Because, in sessions you do one read and one write. So, you have to be doing a lot more reads then writes to benefit.
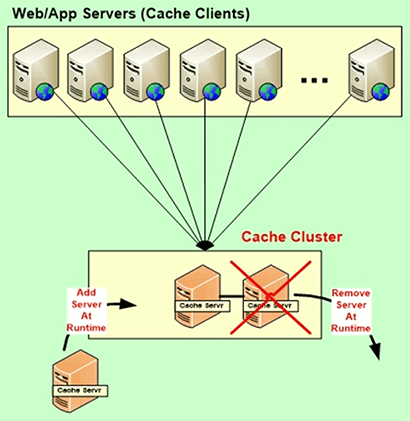
Dynamic Cache Cluster
So, architecturally, you know, you need to see that cache is like the database now. It lives in your datacenter, your production environment and if your application has a high availability need then the cache must also be highly available, otherwise you know, you have a problem. And, the only way to do that is if the cache ensures that it is 100% uptime. So, a good cache, in case of NCache it has a dynamic cache cluster. It’s a peer-to-peer architectured. You can add or drop any server and everything is fine, nothing stops. The cache does not stop, the application does not stop.
Linear Scalability with Replication
So, we talked about the partition and then the topologies already. The replication has to be done intelligently. So, in case of partition replica it only makes one copy. So, the data exists only in two places and not more than two because every time you make copies it costs more time or effort. It slows down things.
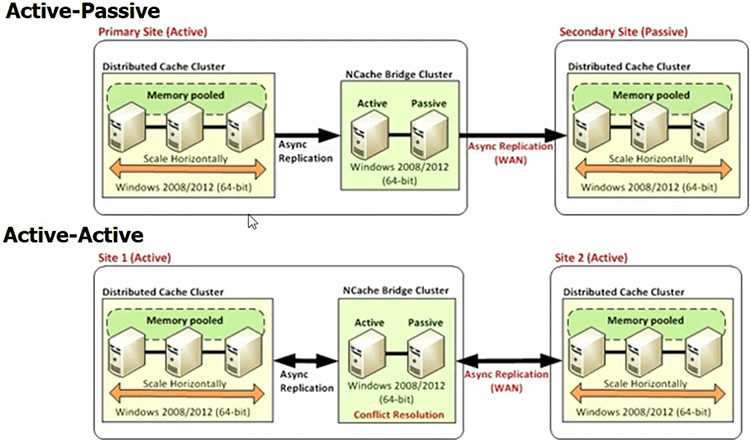
WAN Replication of Distributed Cache
There’s also a feature called WAN Replication. Many people have multiple datacenters now. If you expect your database to be able to handle multiple datacenters, why not the cache? This is a feature most Java caches have it, NCache has it too but only on .NET side.
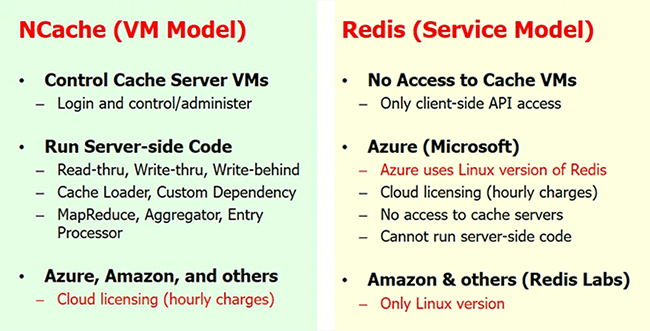
NCache vs. Redis
Just quickly one last thing which is, since, on the .NET side, you know, there are really only two options. One is NCache, one is Redis. Redis actually is more from a Linux based cache but, since Microsoft partnered with them on Azure they have certainly, you know, become a lot more popular. So, I wanted to give like a fair comparison.
By the way, if you just go to our website and you go to the comparisons page and go to detailed feature by feature comparison based on their documentation and our documentation and see all the stuff. And, this is not a, you know, we're not spitting this at all and you can be a good judge of that yourself. It’s just to make your job easier to prepare.
But, they're both open source but NCache is native .NET for .NET people, you know, your whole stack is .NET. NCache allows you to have .NET code on the server side that you cannot do with Redis. And, you know, if you're on Azure, Redis is available only as a cache as a service, whereas, we have intentionally not chosen that model. Because, in cache as a service, the cache is a black box. So, you don't have any of the server side features that we just talked about. And with the VM model you have total control.

Most of our customers are high-end companies that really don't want to let go of their control. It’s like SQL database versus SQL server. So, with NCache, you know, you will control your entire environment and it's as you saw, it's pretty straightforward to do. But, you get all these server side features with NCache, which you don't because with Redis because you don't have any access.
So, again make up your own mind but at the minimum do use a distributed cache in your architecture. Make sure that it is ready to scale. That's the whole goal. Thank you very much.