Da Daten als „die neue Währung“ geprägt wurden, hat Apache Lucene als beliebte Volltextsuchmaschine an Bedeutung gewonnen, die in Anwendungen weit verbreitet ist, um eine flexible Textsuche über große Mengen von Textdaten zu integrieren. Lucene verwendet invertierte Indizierung, wodurch die Zeit für die Suche nach Dokumenten zu einem bestimmten Begriff drastisch verkürzt wird.
NCache Details Verteiltes Lucene NCache Docs
Es handelt sich jedoch um eine eigenständige Lösung, die nicht mit dem Wachstum Ihrer Daten skaliert – Sie müssen ganze Lucene-Indizes neu erstellen, um Daten zu durchsuchen, was eine teure und langsame Aufgabe ist und zu einem Leistungsengpass wird. Während es mittlerweile einige Java- und REST-basierte Lösungen für die skalierbare Volltextsuche gibt, fehlt noch eine skalierbare Volltextsuchlösung, die natürlich in den .NET-Stack passt.
Verwenden von Distributed Lucene mit NCache für .NET
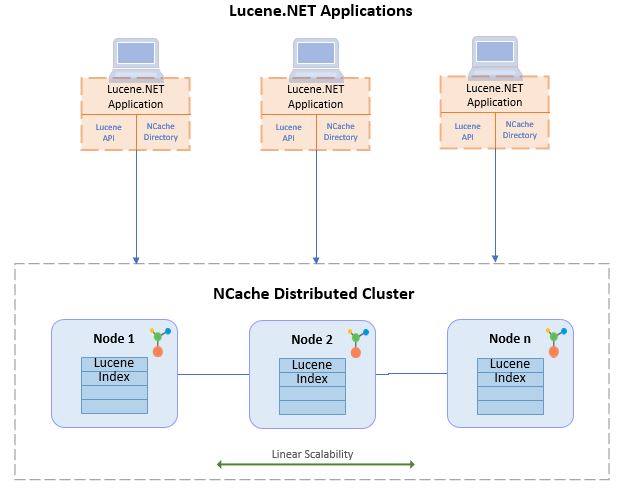
NCache, ein leistungsstarker und beliebter .NET In-Memory-Datenspeicher, hat die native Lucene.NET-API über seine verteilte Architektur implementiert. Da es sich um die Standard-Lucene.NET-API handelt, ist keine Codeänderung erforderlich, um sie skalierbar zu verwenden NCache.
NCache Dabei nutzt Lucene.NET auch, um Indizes in einer dynamisch skalierbaren Umgebung erstellen zu können verteilte Volltextsuche. Die Ergebnisse dieser Suchen werden zusammengeführt, bevor sie an Ihre Anwendung zurückgesendet werden.
NCache Details Funktionsweise von Distributed Lucene Lucene-Komponenten und Übersicht
Damit wird das eigenständige Lucene zu einer schnellen und linear skalierbaren Volltextsuchlösung erweitert.
NCache Details Verteiltes Lucene für Enterprise Search Verteiltes Lucene
Verwenden von Lucene in .NET-Apps
Stellen wir uns eine E-Commerce-Website vor, die Informationen für Tausende von Produkten, Bestellungen und Kundendaten enthält. Daher ist die Indizierung aller Attribute, insbesondere nicht textueller Felder (die bei der Suche nicht verwendet werden), kein kluger Ansatz, da dies den Cache-Speicher erschöpft.
Unser Dokument für ein Produkt sieht beispielsweise so aus:
|
1 2 3 4 5 6 7 8 9 |
{ “ID”: “ABC34”, “Name”: “Tupperware”, “Description”: “Microwaveable, dishwasher-friendly, reusable Tupperware in three sizes”, “RetailPrice”: 15.00, “Discount”: 3.00 } |
Jetzt wissen wir, dass unsere Kunden Volltextsuchen in der Produktbeschreibung durchführen, die ein Feld des Dokuments ist. Was also, wenn wir nur die Felder indizieren, die durchsucht werden können und einen Schlüssel haben, der auf das entsprechende Dokument im Persistenzspeicher verweist, z. B. Datenbank oder Dateisystem? Auf diese Weise werden bei einer Abfrage nach einem bestimmten Produkttyp, z. B. „spülmaschinengeeignete Tupperware“, alle Produkte mit einer Beschreibung, die diesen Begriffen entspricht, mit ihrer ProductID als Dokumentschlüssel angezeigt, und das gesamte Dokument kann dann abgerufen werden der persistente Index.
Um verteiltes Lucene in Ihren bestehenden Anwendungen zu verwenden, müssen Sie lediglich angeben NCacheVerzeichnis beim Öffnen eines Verzeichnisses. Dies erfordert die NCache Cache-Name und den Indexnamen. Das folgende Code-Snippet öffnet ein Verzeichnis in einem Cache, in dem sich LuceneCache befindet NCache und einen Index namens ProductIndex.
|
1 2 3 4 5 6 7 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string index = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, index); |
Lucene liefert eine umfangreiche Abfragesprache aus, die eine gegebene Zeichenfolge in eine Lucene-Abfrage interpretiert. Dies kann entweder für einen Begriff, mehrere Begriffe, Platzhalter oder sogar unscharfe Wörter erfolgen. Um mehr über Lucene-Abfragen zu erfahren, lesen Sie Lucene-Abfragedokumentation.
Der folgende Codeausschnitt erstellt einen IndexReader für das Verzeichnis, der von IndexSearcher verwendet wird. Die Daten werden auf Basis von StandardAnalyzer analysiert und tokenisiert. Die ersten 50 Treffer des Ergebnisses werden an die Anwendung zurückgegeben. Beachten Sie, dass der Analysator derselbe sein muss, der während der Indexerstellung verwendet wurde.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// The 'applyAllDeletes' is true so all enqueued deletes are applied on writer IndexReader reader = DirectoryReader.Open(indexWriter, true); // A searcher is opened to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify the searchTerm, fieldName and analyzer string searchTerm = "Beverages"; string fieldName = "Category"; // Note that the analyzer should be same as the one used during index creation Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); // Create a query parser to parse the query QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, fieldName, analyzer); Query query = parser.Parse(searchTerm); // Returns the top 50 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 50).ScoreDocs; reader.Dispose(); |
Laden Sie Daten, um einen verteilten Index zu erstellen
Mit Lucene können Sie nach Bedarf Indizes erstellen und Daten in diese laden. Indizes erfordern einen Analysator, der die Daten nach Ihren Bedürfnissen analysiert und tokenisiert – es können Leerzeichen, Nicht-Buchstaben, Satzzeichen und so weiter sein. Nachdem Sie einen Writer für Ihren Lucene-Index erstellt haben, können Sie Dokumente erstellen und ihm Felder hinzufügen. Dieses Dokument wird dann indiziert NCache als verteilter Index, sobald Sie Commit() aufrufen. Weitere Einzelheiten zu Lucene-Analysatoren finden Sie unter Lucene Analyzer-Dokumentation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string indexPath = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, indexPath); // The same analyzer is used as for the reader Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); // Create indexWriter on NCache directory IndexWriter indexWriter = new IndexWriter(directory, config); Product[] products = FetchProductsToIndex(); foreach (var product in products) { Document doc = new Document { new StoredField("id", product.ID), new TextField("name", product.Name, Field.Store.YES), new TextField("description", product.Description, Field.Store.YES), new StringField("category", product.Category, Field.Store.No), new StoredField("retail_price", product.RetailPrice), }; indexWriter.AddDocument(doc); } indexWriter.Commit(); </code><br /><br /><a href="/ncache/">NCache Details</a> <a href="/resources/docs/ncache/prog-guide/lucene-ncache.html#working-of-distributed-lucene">Working of Distributed Lucene</a> <a href="/blogs/geospatial-indexes-for-distributed-lucene-with-ncache/">GeoSpatial Indexes for Distributed Lucene</a> |
Warum NCache für verteiltes Lucene?
Die richtigen NCache für verteiltes Lucene bietet Ihnen die folgenden Vorteile:
- Extrem schnell und linear skalierbar: NCache ist ein verteilter In-Memory-Datenspeicher, also Gebäude verteilt Lucene bietet obendrein die gleiche optimale Performance für Ihre Volltextsuche. Außerdem wegen NCacheAufgrund der verteilten Architektur von wird der Lucene-Index über alle Server des Clusters verteilt. Dies macht es skalierbar, da Sie unterwegs weitere Server hinzufügen können, wenn Ihre Datenlast zunimmt, und Lucene-Indizes automatisch erstellt werden redisohne Eingreifen des Kunden verteilt.
- Datenreplikation für Zuverlässigkeit und Hochverfügbarkeit: Mit der NCache's Partition-of-Replica-Topologie wird der Lucene-Index nicht nur über alle Server partitioniert, sondern jede Partition wird auch auf einen anderen Server des Clusters repliziert. Wenn also ein Server ausfällt, bedient die Replik der Partition alle Abfragen für t/resources/docs/ncache/admin-guide/distributed-lucene-counters.htmldieser Index, um Zuverlässigkeit zu gewährleisten. Wenn ein Serverknoten ausfällt, NCache heilt sich dynamisch selbst indem Sie die Daten innerhalb der verbleibenden Knoten ohne Ausfallzeiten oder Auswirkungen auf Ihren Lucene-Index neu anpassen, um eine hohe Verfügbarkeit sicherzustellen.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass die Volltextsuche dank der leistungsstarken Suchmaschine Lucene mittlerweile in fast jedem Unternehmen grundlegend geworden ist. Aber wenn die Datenmenge wächst, kann die Neuerstellung von Indizes mehr Schaden als Gewinn anrichten, und hier ist eine verteilte In-Memory-.NET-Lösung wie z NCache Es ist lediglich eine einzeilige Codeänderung in Ihrer bestehenden Lucene-Anwendung erforderlich, und voila, Sie haben das Beste aus beiden Welten als speicherinternen, verteilten Volltextsuchmechanismus.




