Una pesadilla común entre los desarrolladores y arquitectos de software es que su única fuente de datos/servidor web se bloquee, perdiendo miles de clientes, aplicaciones y datos valiosos conectados. Con la ayuda de una capa de almacenamiento en caché distribuida y con equilibrio de carga, como NCache puede hacer que su nivel de aplicación sea altamente escalable y esté disponible. Con el aumento de la carga de transacciones, puede agregar más servidores. La arquitectura distribuida garantiza que no haya un único punto de falla.
NCache es un recuerdo distribuidos almacén de datos que proporciona un rendimiento óptimo para sus aplicaciones. los NCache el racimo es la auto-sanación y dinámico. Contiene nodos que equilibran automáticamente la carga entre ellos sin la intervención del usuario en cada actualización del clúster.
NCache Detalles NCache Docs Réplica con particiones
Este blog le ofrece un recorrido rápido de cómo NCache ofrece escalabilidad y rendimiento mientras se mantiene el 100 % de tiempo de actividad. Para entender NCache arquitectura en detalle, puedes ver este video:
Mantener alta disponibilidad en NCache Médico
NCacheLa arquitectura distribuida y replicada de asegura el 100% el tiempo de actividad incluso si un nodo se cae inesperadamente. NCacheLa arquitectura de igual a igual y el descubrimiento en tiempo de ejecución de clústeres y clientes sin intervención del usuario garantizan una disponibilidad tan alta. Es más, NCache proporciona soporte de conmutación por error inteligente, por lo que el clúster siempre permanece disponible para todos los clientes conectados.
Arquitectura punto a punto
NCache proporciona un agrupamiento dinámico de caché con un arquitectura punto a punto donde no hay un solo punto de falla. Un clúster de caché tiene servidores interconectados y contiene un coordinador (el nodo de servidor más importante) que administra las membresías del clúster. Si el coordinador deja de funcionar, la función pasa al siguiente servidor con más antigüedad en el clúster. Garantiza que no haya ningún punto único de falla en la administración de membresía del clúster.
Detección en tiempo de ejecución dentro del clúster y los clientes
Racimo:
Una vez que se inicia un servidor, debe conocer al menos otro servidor en el clúster. El servidor contiene una lista de varios servidores de caché e intenta conectarse a cualquiera de ellos. Una vez que se conecta a un servidor, le pregunta a ese servidor sobre el coordinador del clúster y le pide al coordinador que lo agregue a la lista de miembros del clúster.
El coordinador agrega este nuevo servidor al clúster en tiempo de ejecución e informa a los otros servidores conectados que un nuevo servidor se ha unido al clúster. También informa al nuevo servidor sobre todos los miembros del clúster. A continuación, el nuevo servidor establece una conexión TCP con todos los servidores del clúster.
Cliente:
Una vez que el cliente se conecta a un servidor de caché, recibe la siguiente información de ese servidor en tiempo de ejecución:
- Información de membresía del clúster
- Almacenamiento en caché de información de topología
- Mapa de distribución de datos
El cliente usa esta información para ayudar a determinar a qué servidores de caché conectarse y cómo acceder a la caché en función de la topología de almacenamiento en caché.
Detección en tiempo de ejecución dentro del clúster y los clientes
In NCache, el descubrimiento del clúster y el cliente durante el tiempo de ejecución se realiza de las siguientes formas:
Racimo:
Como un clúster es una colección de nodos, una vez que se inicia un servidor, debe conocer al menos otro servidor en el clúster. El servidor contiene una lista de varios servidores de caché e intenta conectarse a cualquiera de ellos. Una vez que se conecta a un servidor, le pregunta a ese servidor sobre el coordinador del clúster y le pide al nodo coordinador que lo agregue a la lista de miembros del clúster.
El coordinador agrega este nuevo servidor al clúster en tiempo de ejecución e informa a los otros servidores conectados que un nuevo servidor se ha unido al clúster. También actualiza el nuevo servidor sobre todos los miembros del clúster. El nuevo servidor entonces establece un Conexión TCP con todos los servidores del clúster.
Cliente:
Una vez que el cliente se conecta a un servidor de caché, recibe la siguiente información de ese servidor en tiempo de ejecución:
- Información de membresía del clúster
- Almacenamiento en caché de información de topología
- Mapa de distribución de datos
El cliente usa esta información para ayudar a determinar a qué servidores de caché conectarse y cómo acceder al caché en función de la topología de almacenamiento en caché.
Soporte de conmutación por error
A este tenor, NCache El clúster se repara automáticamente, proporciona soporte de conmutación por error dentro del clúster y para los clientes si se agrega o elimina un servidor en tiempo de ejecución.
- Soporte de conmutación por error de clúster: El clúster se reorganiza automáticamente actualizando sus conexiones con los otros servidores en cada actualización del clúster.
- Soporte de conmutación por error del cliente: Los clientes se conectan automáticamente a otro servidor en el clúster si hay una desconexión del servidor. De manera similar, si se agrega un servidor, los clientes se actualizan y pueden conectarse al nuevo servidor.
Para obtener más detalles sobre las funciones de alta disponibilidad, diríjase a nuestro blog Alta disponibilidad prometida con NCache.
Topologías de almacenamiento en caché Agrupación dinámica de recuperación automática NCache Arquitectura
Modo de mantenimiento
NCache admite el modo de mantenimiento para su Partición de réplica topología Aunque la propia topología POR asegura una alta disponibilidad con una réplica de cada nodo. Sin embargo, en caso de que necesite ejecutar una actualización o realizar una actualización de parche en la memoria caché, debe detener cada nodo del clúster uno por uno. Sin embargo, detener un nodo de caché desencadena una transferencia de estado dentro de todo el clúster de caché, lo que genera un uso excesivo de recursos como la red y la CPU, lo que afecta drásticamente la disponibilidad de la caché.
El NCache el modo de mantenimiento resuelve este problema dándole la opción de detener un nodo para mantenimiento. Una vez que un nodo es detenido, informa al clúster que detenga cualquier transferencia de estado durante un período de tiempo de espera específico. Cuando un clúster se somete a mantenimiento, la réplica de este nodo actuará como el nodo activo y atenderá las solicitudes de datos del cliente. Una vez que el nodo vuelve a unirse al clúster, solicita datos de su nodo de réplica. Básicamente, el modo de mantenimiento le ahorra a su clúster el costo de un costoso proceso de transferencia de estado.
NCache Detalles NCache Docs Modo de mantenimiento NCache Docs
Alcanzar la escalabilidad del tiempo de ejecución de NCache Médico
Como NCache almacena sus datos junto con funciones avanzadas como Mensajes de publicación/suscripción y ejecución de consultas, puede esperar encontrarse con un límite de memoria o computacional si todas sus transacciones están en un solo servidor. Esta es la razón por NCache proporciona un escalado lineal continuo para manejar el aumento de solicitudes por segundo y almacenar más datos.
NCache Web Manager hace que escalar su entorno sea tan simple como hacer clic en los botones y listo, tiene un clúster dinámico con nodos adicionales sin detener a sus clientes. El siguiente GIF muestra lo simple que es escalar su clúster dinámicamente en NCache:
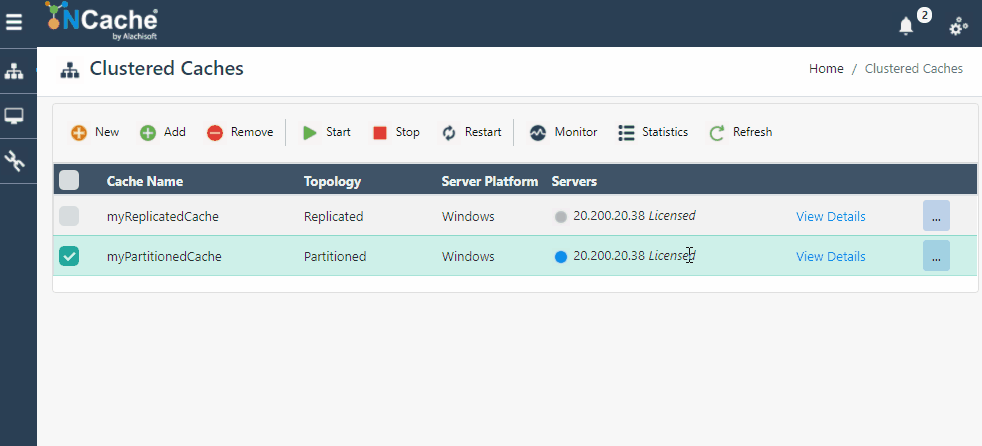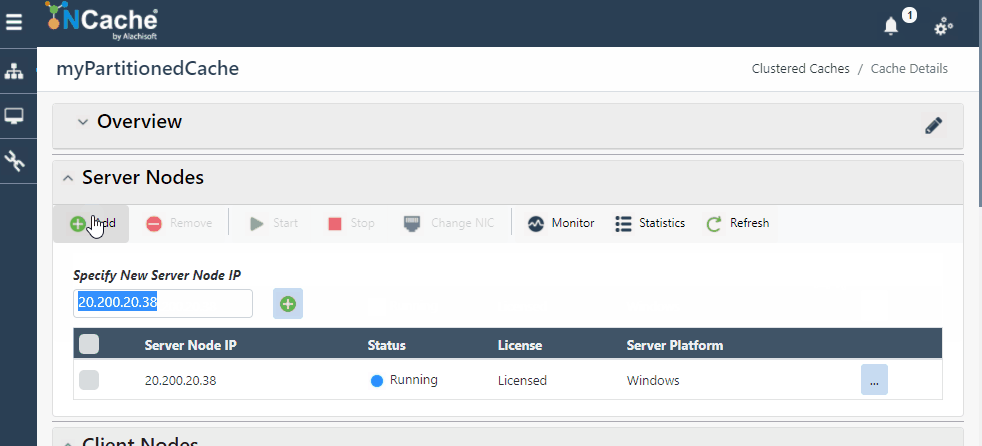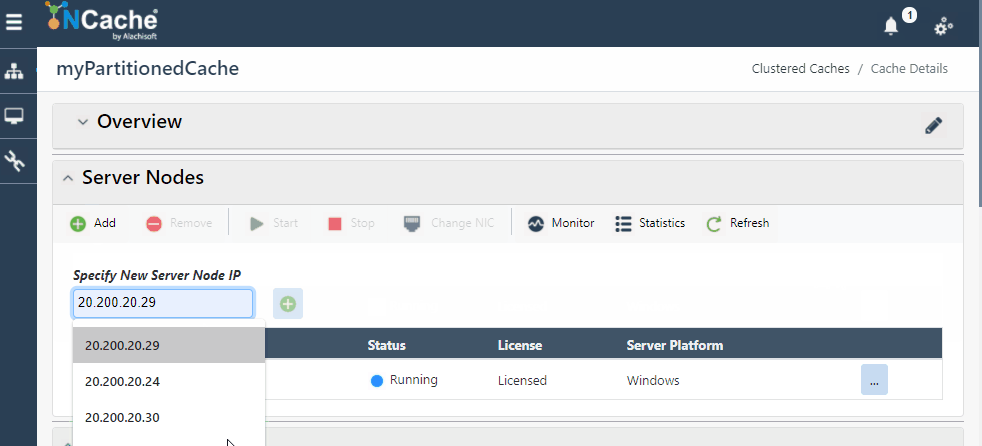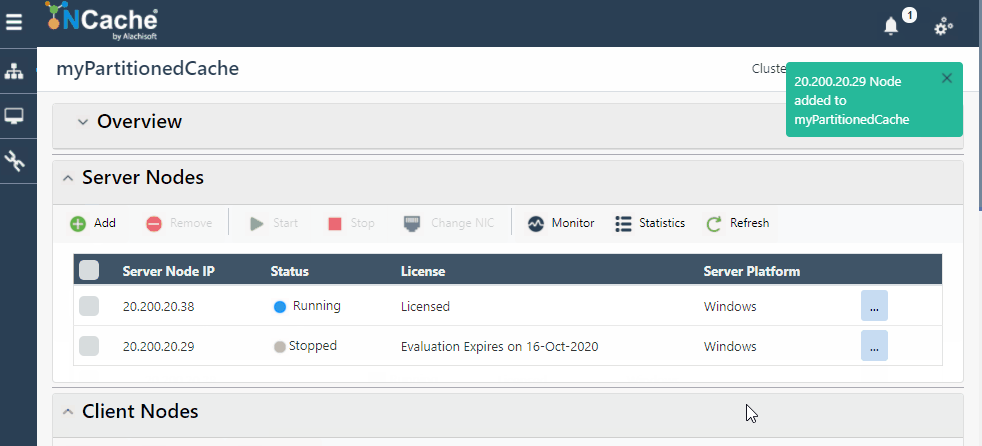
Figura 1: Agregar nodo de servidor en NCache Médico
Operaciones paralelas
NCache tiene un clúster dinámico eso permite que los clientes reciban los datos requeridos en un solo salto porque los clientes se manejan de manera efectiva dentro del clúster sin la intervención del usuario. Además, las operaciones del cliente se envían y ejecutan en paralelo en todos los nodos. Los resultados de cada nodo se compilan en un solo resultado, lo que hace que las operaciones sean escalables. También mejora el rendimiento de las transacciones debido al paralelismo.
Tubería
Con tubería, NCache reduce la sobrecarga de la red al combinar múltiples operaciones de clientes enviadas en una llamada TCP al servidor. De manera similar, el cliente recibe los resultados de la operación en un solo fragmento en una llamada. Ayuda a escalar las operaciones.
Agrupación de objetos
Con la agrupación de objetos, el NCache El servidor agrupa los objetos y los reutiliza para evitar invocar al recolector de basura una y otra vez. La recolección de elementos no utilizados es una tarea de rendimiento intensivo, por lo tanto, al disminuir la necesidad de llamar al GC, se obtiene un mayor rendimiento y escalabilidad de su entorno.
Caché de cliente
NCache ofrece caché del cliente, un caché encima del caché, que reside donde reside la aplicación. Como la memoria caché del cliente se encuentra entre la aplicación y la memoria caché en clúster, se sincroniza automáticamente y aumenta el rendimiento, especialmente para las operaciones de lectura. El uso de un caché de cliente reduce la sobrecarga de la red.
Para más detalles, puedes consultar el blog: Arquitectura de escalabilidad en NCache - Una visión
NCache Detalles Operaciones del lado del cliente Canalización en NCache
Conclusión
NCache, siendo nativo de .NET almacenamiento en caché distribuido solución, se adapta perfectamente a su pila de aplicaciones. Aumenta enormemente el rendimiento debido a la agrupación de objetos, las operaciones paralelas y la memoria caché del cliente que se encuentra junto a su aplicación. Además de ser escalable, también mantiene un 100% de tiempo de actividad en todo momento para garantizar la alta disponibilidad de datos y clientes.





