À l'ère du traitement rapide et fiable des applications, tout le monde opte pour la mise en cache distribuée afin d'obtenir les meilleures performances de son application. Si vos applications Web attirent un trafic élevé entraînant des transactions extrêmement élevées, vous avez certainement besoin NCache.
NCache est une solution de mise en cache distribuée en mémoire qui fournit évolutivité linéaire aux applications .NET et Java. Parmi divers topologies qui NCache vous offre, le plus populaire est Réplique partitionnée topologie. La topologie de réplique partitionnée vous offre le meilleur des deux mondes, une évolutivité linéaire et une haute disponibilité.
Dans le cluster Partitioned-Replica, les données sont partitionnées et répliquées sur tous les nœuds. Par conséquent, si un nœud de serveur tombe en panne, ses clients peuvent poursuivre leurs opérations en interagissant avec son homologue de réplique. Dès qu'un nœud tombe en panne, le processus de transfert d'état est déclenché pour rééquilibrer automatiquement les données orphelines. Supposons maintenant que vous ayez un cluster Partitioned-Replica et que vous ayez besoin que l'un des nœuds soit arrêté pour maintenance tout en sachant que vous redémarrerez ce nœud peu de temps après ? Voyons ce qu'est ce comportement et comment cela pourrait être un défi pour vous.
NCache Détails Réplique partitionnée NCache Docs Mode de maintenance NCache Docs
Défis de rééquilibrage automatique pendant la maintenance
Chaque fois qu'un nœud est arrêté dans un cluster Partitioned-Replica ; le transfert d'état est déclenché pour rééquilibrer les données dans tout le cluster. Ce processus peut prendre plus de temps que prévu, ce qui affecte les performances de votre application, en particulier lorsque les nœuds contiennent des dizaines de gigaoctets de données.
La figure suivante explique le comportement du cluster Partitioned-Replica lorsqu'un nœud est arrêté.
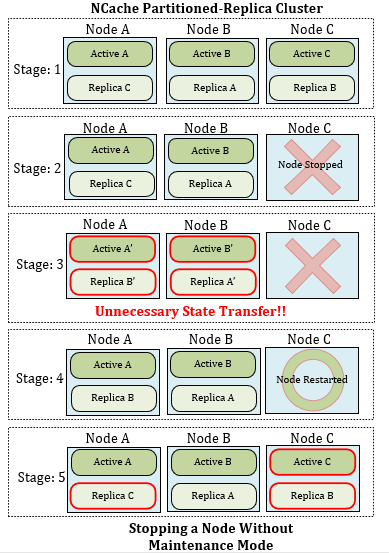
Figure 1 : Arrêt d'un nœud sans mode de maintenance
Dans cette figure, vous avez un NCache Cluster de réplica partitionné avec trois nœuds. Ici, cinq étapes ont été introduites pour expliquer ce qui se passe lorsqu'un nœud est arrêté dans un cluster.
- Stage 1: NCacheRéplique partitionnée de avec trois nœuds, A, B et C, chacun ayant un nœud actif et un nœud de réplique.
- Étape 2 : le nœud C est brièvement arrêté pour maintenance. Son actif et son réplica ne font plus partie du cluster et le transfert d'état est déclenché.
- Étape 3 : Données rediscontribution dans le cluster (totalement inutile). Ici, les données orphelines du nœud C sont divisées entre les nœuds restants A et B après l'arrêt du transfert d'état. Selon cette division, leurs nœuds de réplique sont également mis à jour. Ce transfert d'état est totalement inutile car le nœud arrêté va bientôt redémarrer.
- Étape 4 : le nœud C redémarre. Le cluster, à ce stade, se comporte comme si le nœud C avait quitté le cluster. Après les données redistribution, le nœud C est redémarré.
- Étape 5 : le nœud C rejoint le cluster et traite à nouveau les données rediscontribution. Comme ses données avaient déjà été distribuées entre A et B, donc lorsque C rejoint, le transfert d'état est à nouveau déclenché dans tout le cluster pour affecter de nouvelles données aux nœuds.
Idéalement, cela semble être la solution parfaite. Vous arrêtez un nœud, le transfert d'état se produit. Vous réparez ce que vous vouliez réparer et redémarrez ce nœud. Le transfert d'état est à nouveau déclenché pour équilibrer tous les compartiments.
Mais pourquoi n'est-ce pas la solution idéale ? Qu'est-ce qui ne va pas ici?
Il y a plusieurs inconvénients à provoquer inutilement un transfert d'État. Ils sont:
- Coût élevé en raison des multiples appels réseau et de la surcharge de traitement.
- Complexité temporelle élevée lorsque les nœuds contiennent une grande quantité de données.
- Comportement erroné lorsqu'un nœud redémarre pendant le transfert d'état et conduit à un transfert d'état dans le transfert d'état.
NCache Détails Réplique partitionnée NCache Docs Mode de Maintenance-NCache Docs
La solution : une réplique partitionnée compatible avec le mode de maintenance
En tenant compte de tous ces revers de transfert d'état inutiles qui se produisent chaque fois qu'un nœud quitte et rejoint un cluster, NCache met à votre Mode de maintenance.
Le mode maintenance vous permet d'arrêter un nœud pendant une période spécifique et de le démarrer lorsque sa maintenance est terminée. Ce mode garantit que pendant la période de maintenance d'un nœud, le thread de transfert d'état n'est pas déclenché dans le cluster. En outre, il est extrêmement avantageux lorsque le cluster comprend une grande quantité de données.
La différence entre le mode de maintenance et l'arrêt normal d'un nœud est expliquée dans la figure suivante.
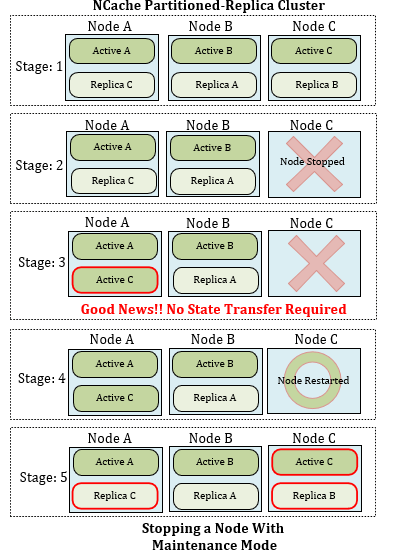
Figure 2 : Arrêt d'un nœud sans mode de maintenance
- Étape 1 : la structure de la topologie de réplique partitionnée of NCache est montré où un cluster POR comprend trois nœuds de serveur qui contiennent une énorme quantité de données.
- Étape 2 : nœud C arrêté. Le nœud C est arrêté pour maintenance via le mode maintenance.
- Étape 3 : Données redisattribution. Ici, la réplique de C devient active et commence à adresser les clients du nœud C. Cela élimine le besoin de déclencher le transfert d'état, par conséquent, le thread de transfert d'état est arrêté tant que le cluster est en maintenance. Cela résout le problème rencontré lorsqu'un transfert d'état inutile équilibre les données dans le cluster après l'arrêt du nœud C.
- Étape 4 : le nœud C a redémarré. Après avoir été arrêté à des fins de maintenance, le nœud C attend d'être redémarré. Chaque fois que le cluster quitte le mode de maintenance, le nœud C démarre.
- Étape 5 : Transfert de données. C'est cette phase du cluster où le nœud C reçoit toutes les données de sa partie réplique et met à jour l'ensemble du nœud (c'est-à-dire Active C et réplique B) via le transfert d'état.
NCache Détails Réplique partitionnée NCache Docs Mode de Maintenance-NCache Docs
Comment arrêter un nœud pour maintenance
Vous pouvez arrêter un nœud pour maintenance en utilisant Web Manager ou PowerShell. Voici comment vous pouvez arrêter un nœud pour maintenance à partir de votre Web Manager. Lors de l'arrêt d'un nœud, il vous est demandé de mentionner la durée de maintenance pendant laquelle vous souhaitez maintenir ce nœud en maintenance. Ce timeout est considéré comme une période pendant laquelle aucun transfert d'état ne peut être déclenché.
Les étapes suivantes vous permettent d'arrêter le nœud que vous souhaitez arrêter pour maintenance.
- Accédez à votre NCache Web Manager
- Accédez à Clustered Caches et sélectionnez le cluster qui nécessite une maintenance
- Parmi ses différents nœuds, sélectionnez celui qui nécessite une maintenance.
Accédez à ses paramètres et sélectionnez l'option Arrêt pour maintenance.
Comment quitter un nœud du mode maintenance
Une fois qu'un cluster entre en mode maintenance, Web Manager est utilisé pour en sortir ce cluster. Voici les étapes à suivre :
- De ton NCache Web Manager, accédez à Caches en cluster
- Sélectionnez le cluster en cours de maintenance.
- Accédez à ses paramètres et sélectionnez Quitter le mode d'entretien.
Outre le gestionnaire Web, il existe plusieurs façons pour un nœud de sortir du mode de maintenance. Ces scénarios doivent être pris en considération car certains peuvent affecter les performances de votre application.
Un nœud peut quitter le mode maintenance dans les cas suivants :
- Lorsque le nœud en maintenance est démarré : Si le nœud en cours de maintenance est démarré manuellement, soit via le gestionnaire, soit via la commande PowerShell, ce nœud quitte le mode maintenance.
- Lorsque le délai expire : Lorsque le délai d'attente prévu pour la maintenance expire, le transfert d'état est déclenché et le cluster quitte automatiquement le mode maintenance.
- Lorsqu'un nœud quitte le cluster : Aucun nœud ne peut quitter un cluster normalement tant qu'il est en maintenance. Mais si l'un des nœuds de ce cluster quitte avec force, ce cluster sort inévitablement du mode de maintenance, bien qu'il soit toujours sous le processus de maintenance. Ici, le point auquel vous devez faire attention est que si le nœud même qui était en maintenance part, il y a de fortes chances de perte de données.
Quelle que soit la méthode que vous utilisez pour quitter le mode de maintenance, ce signal seul est le signal permettant au thread de transfert d'état de déclencher le processus d'équilibrage automatique dans tout le cluster.
résumant
Si vous souhaitez trouver un moyen d'adapter les correctifs dans votre cache clusterisé de réplique partitionnée sans compromettre les performances de l'application, consultez NCache Mode de Maintenance. Le mode maintenance vous permet de corriger un bogue, d'ajouter un correctif, de mettre à niveau un logiciel ou du matériel, sans introduire de temps d'arrêt de l'application. Tout ce que vous avez à faire est de suivre les étapes mentionnées ci-dessus et de constater par vous-même à quel point NCache Le mode d'entretien est.





