Dado que los datos se han acuñado como "la nueva moneda", Apache Lucene ha ganado terreno como un popular motor de búsqueda de texto completo, ampliamente utilizado en aplicaciones para incorporar búsquedas de texto flexibles en cantidades significativas de datos textuales. usos lucene indexación invertida, reduciendo drásticamente el tiempo para encontrar documentos relacionados con un término en particular.
NCache Detalles Lucene distribuido NCache Docs
Sin embargo, es una solución independiente que no se escala a medida que crecen sus datos; necesita reconstruir índices completos de Lucene para buscar datos, lo cual es una tarea costosa y lenta, que se convierte en un cuello de botella en el rendimiento. Si bien ahora existen algunas soluciones basadas en Java y REST para atender la búsqueda de texto completo escalable, todavía falta una solución de búsqueda de texto completo escalable que pueda encajar naturalmente en la pila de .NET.
Uso de Lucene distribuido con NCache para .NET
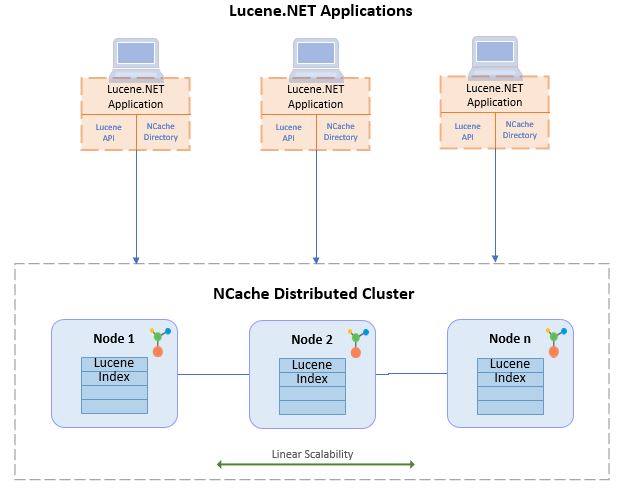
NCache, un potente y popular almacén de datos en memoria .NET, ha implementado la API nativa de Lucene.NET sobre su arquitectura distribuida. Como es la API estándar de Lucene.NET, no se requiere ningún cambio de código para usarla de manera escalable con NCache.
NCache también utiliza este Lucene.NET para crear índices en un entorno dinámicamente escalable para permitir búsquedas distribuidas de texto completo. Los resultados de estas búsquedas se fusionan antes de enviarse de vuelta a su aplicación.
NCache Detalles Funcionamiento de Distributed Lucene Componentes y descripción general de Lucene
Esto mejora el Lucene independiente en una solución de búsqueda de texto completo rápida y linealmente escalable.
NCache Detalles Lucene distribuido para la búsqueda empresarial Lucene distribuido
Uso de Lucene en aplicaciones .NET
Consideremos un sitio de comercio electrónico que contiene información de miles de productos, pedidos y detalles de clientes. Por lo tanto, indexar todos los atributos, especialmente los campos no textuales (que no se usan durante la búsqueda), no es un enfoque inteligente, ya que agota la memoria caché.
Por ejemplo, nuestro documento para un producto se ve así:
|
1 2 3 4 5 6 7 8 9 |
{ “ID”: “ABC34”, “Name”: “Tupperware”, “Description”: “Microwaveable, dishwasher-friendly, reusable Tupperware in three sizes”, “RetailPrice”: 15.00, “Discount”: 3.00 } |
Ahora, sabemos que nuestros clientes realizan búsquedas de texto completo en la descripción del producto, que es un campo del documento. Entonces, ¿qué pasa si indexamos solo aquellos campos en los que se puede buscar y tenemos una clave que hace referencia a su documento correspondiente en el almacén persistente, por ejemplo, base de datos o sistema de archivos? De esta manera, una vez que busque un tipo específico de producto, digamos "Tupperware apto para lavavajillas", todos los productos con una descripción que coincida con estos términos aparecerán con su ProductID como clave de documento, y luego se podrá obtener el documento completo de el índice persistente.
Para usar Lucene distribuido en sus aplicaciones existentes, todo lo que necesita es especificar NCacheDirectorio al abrir un directorio. Esto requiere la NCache el nombre de caché y el nombre del índice. El siguiente fragmento de código abre un directorio en un caché LuceneCache en NCache y un índice llamado ProductIndex.
|
1 2 3 4 5 6 7 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string index = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, index); |
Lucene incluye un extenso lenguaje de consulta, que interpreta una cadena determinada en una consulta de Lucene. Esto se puede hacer en un término, varios términos, comodines o incluso palabras confusas. Para obtener más información sobre las consultas de Lucene, lea Documentos de consulta de Lucene.
El siguiente fragmento de código crea un IndexReader en el directorio, que usa IndexSearcher. Los datos se analizan y tokenizan sobre la base de StandardAnalyzer. Los primeros 50 resultados del resultado se devuelven a la aplicación. Tenga en cuenta que el analizador debe ser el mismo que se utilizó durante la creación del índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// The 'applyAllDeletes' is true so all enqueued deletes are applied on writer IndexReader reader = DirectoryReader.Open(indexWriter, true); // A searcher is opened to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify the searchTerm, fieldName and analyzer string searchTerm = "Beverages"; string fieldName = "Category"; // Note that the analyzer should be same as the one used during index creation Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); // Create a query parser to parse the query QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, fieldName, analyzer); Query query = parser.Parse(searchTerm); // Returns the top 50 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 50).ScoreDocs; reader.Dispose(); |
Cargar datos para crear un índice distribuido
Con Lucene, puede crear índices y cargar datos en ellos según sea necesario. Los índices requieren un analizador, que analice y tokenice los datos según sus necesidades: pueden ser espacios en blanco, no letras, puntuación, etc. Una vez que crea un escritor para su índice de Lucene, puede crear documentos y agregarle campos. Este documento luego se indexa en NCache como un índice distribuido una vez que llame a Commit(). Para obtener más detalles sobre los analizadores Lucene, consulte Documentos de Lucene Analyzer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string indexPath = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, indexPath); // The same analyzer is used as for the reader Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); // Create indexWriter on NCache directory IndexWriter indexWriter = new IndexWriter(directory, config); Product[] products = FetchProductsToIndex(); foreach (var product in products) { Document doc = new Document { new StoredField("id", product.ID), new TextField("name", product.Name, Field.Store.YES), new TextField("description", product.Description, Field.Store.YES), new StringField("category", product.Category, Field.Store.No), new StoredField("retail_price", product.RetailPrice), }; indexWriter.AddDocument(doc); } indexWriter.Commit(); </code><br /><br /><a href="/ncache/">NCache Details</a> <a href="/resources/docs/ncache/prog-guide/lucene-ncache.html#working-of-distributed-lucene">Working of Distributed Lucene</a> <a href="/blogs/geospatial-indexes-for-distributed-lucene-with-ncache/">GeoSpatial Indexes for Distributed Lucene</a> |
¿Por qué NCache para Distributed Lucene?
Usar NCache para Lucene distribuido le proporciona los siguientes beneficios:
- Extremadamente rápido y linealmente escalable: NCache es un almacén de datos distribuidos en memoria, por lo que construir distribuido Lucene además, proporciona el mismo rendimiento óptimo para sus búsquedas de texto completo. Además, debido a NCacheEn la arquitectura distribuida de Lucene, el índice de Lucene se divide en todos los servidores del clúster. Esto lo hace escalable, ya que puede agregar más servidores sobre la marcha a medida que aumenta la carga de datos, y los índices de Lucene se actualizan automáticamente. redistributado sin intervención del cliente.
- Replicación de datos para confiabilidad y alta disponibilidad: Con NCacheEn la topología Partición de réplica de Lucene, el índice de Lucene no solo se divide en todos los servidores, sino que cada partición también se replica en otro servidor del clúster. Por lo tanto, si algún servidor deja de funcionar, la réplica de la partición atiende todas las consultas para t/resources/docs/ncache/admin-guide/distributed-lucene-counters.htmlhat index, lo que garantiza la fiabilidad. Del mismo modo, si un nodo del servidor deja de funcionar, NCache autocura dinámicamente reajustando los datos dentro de los nodos restantes, sin tiempo de inactividad ni impacto en su índice de Lucene, lo que garantiza una alta disponibilidad.
Conclusión
En resumen, la búsqueda de texto completo se ha vuelto fundamental en casi todos los negocios, gracias al poderoso motor de búsqueda Lucene. Pero a medida que crecen los datos, la reconstrucción de los índices puede causar más daño que ganancia y aquí donde una solución .NET distribuida en memoria, como NCache interviene. Todo lo que requiere es un cambio de código de una línea en su aplicación Lucene existente, y listo, tiene lo mejor de ambos mundos como un mecanismo de búsqueda de texto completo distribuido en memoria.




