Lucene es una biblioteca de motor de búsqueda de texto completo .NET que contiene potentes API para crear índices de texto completo e implementar tecnologías de búsqueda precisas y avanzadas en sus programas. Lucene ofrece mucho más de lo que esperaría de otros motores de búsqueda de texto, ya que las opciones que se ofrecen al usuario son múltiples. Tiene un potente algoritmo de búsqueda y admite una amplia gama de consultas para la búsqueda.
Aunque tan poderoso como Lucene es por sí solo, no está exento de limitaciones. Lucene se ejecuta en proceso en la aplicación cliente y las aplicaciones de Lucene normalmente escriben datos en un archivo y los almacenan en el disco, lo que genera una gran asignación de memoria. Sin embargo, es una solución independiente que no se escala a medida que crecen sus datos, necesita reconstruir índices completos de Lucene para buscar datos, lo cual es una tarea costosa y lenta, que puede resultar en un cuello de botella en el rendimiento. Esto significa que Lucene no es escalable y tiene un único punto de falla.
NCache Detalles Descargar NCache NCache Docs
Cómo le ayuda Distributed Lucene
NCache proporciona una implementación distribuida de Lucene que hace que las aplicaciones de Lucene sean escalables. NCache ser distribuido en la naturaleza con Lucene proporciona escalabilidad de escritura lineal ya que los documentos indexados por las aplicaciones se distribuyen automáticamente entre los nodos de caché donde se indexan por separado.
De manera similar, Distributed Lucene también proporciona escalabilidad de lectura lineal, ya que las consultas se propagan en cada partición y los resultados se fusionan. Un mayor número de particiones proporciona una mayor cantidad de escalabilidad de lectura y escritura. Los índices de Lucene se conservan en la unidad física. Cuantos más nodos haya, mayor será la escalabilidad, el rendimiento y la capacidad de almacenamiento para acomodar una gran cantidad de documentos y datos indexados de Lucene.
NCache Detalles Descargar NCache Documentos de Lucene distribuidos
Cómo funciona Distributed Lucene
Lucene distribuido contiene múltiples nodos de servidor, cada servidor de NCache tiene un módulo Lucene dedicado. Los comportamientos y el funcionamiento de Lucene y Distributed Lucene son similares, aparte de algunos cambios.
El siguiente diagrama muestra cómo funciona el modelo Distributed Lucene.
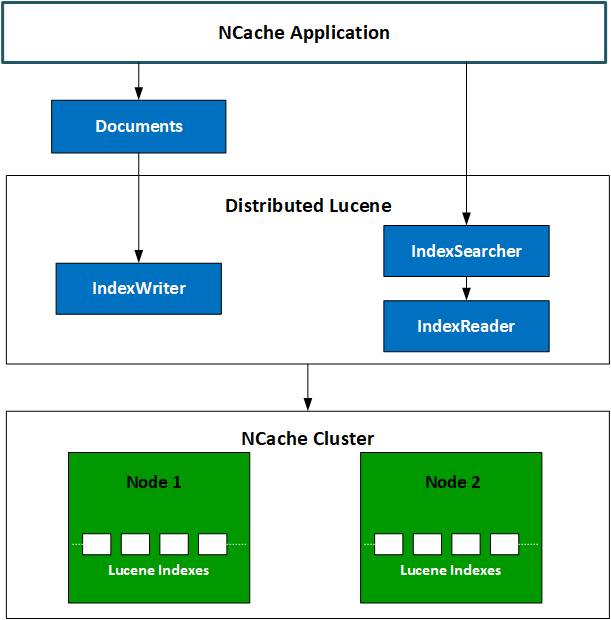
NCache Arquitectura distribuida de Lucene
La aplicación cliente puede querer indexar documentos o consultar documentos indexados existentes utilizando la API de Lucene. Estas interacciones con la API actúan como llamadas a procedimientos remotos (RPC) entre el cliente y el servidor. Las llamadas a la API se reenvían directamente a los módulos de Lucene adjuntos a cada nodo del servidor. Los módulos de Lucene ejecutan estas llamadas y, según la naturaleza de las llamadas, se lleva a cabo cualquiera de las siguientes acciones:
- En caso de que fuera una llamada de consulta, los módulos Distributed Lucene devuelven resultados al lado del cliente, donde todos estos resultados se fusionan y procesan.
- En caso de que se tratara de una llamada para indexar un documento, los Módulos de Lucene distribuidos conservan ese documento en una unidad de disco.
NCache Detalles Documentos de Lucene distribuidos Caché de Lucene distribuida
Distribución de datos
Se genera un mapa de distribución contra el NCache clúster para Distributed Lucene. Este mapa contiene información sobre la distribución del depósito en los nodos de caché. Estos cubos (existen 100 cubos en el mapa) se distribuyen en el clúster utilizando una estrategia específica. La adición o eliminación de un nodo del clúster cambiará el mapa de distribución y activará la transferencia de estado para los nodos del servidor en ejecución, que transfieren depósitos con datos indexados en el nodo respectivo.
Tener 100 cubos significa que un índice de Lucene se divide en 100 subíndices en todo el NCache grupo. Un único cubo contiene un subíndice, que es lo mismo que un índice de Lucene en Lucene.Net. Un nodo de servidor puede contener varios índices, y cada índice dentro de ese nodo de servidor contiene depósitos que se le asignan de acuerdo con la estrategia de distribución del clúster. Los datos dentro de los índices se distribuyen uniformemente a través de estos cubos.
Cómo comenzar con Lucene distribuido
Lucene distribuido funciona igual que Lucene. Una gran comodidad de usar Lucene distribuido es que le brinda la misma API que Lucene. Como usuario de Lucene, obtiene la escalabilidad que desea con un complemento de cambio de código de una sola línea. solo tienes que usar NCache Directory y su aplicación está lista para funcionar. Hay muy pocos cambios de comportamiento y API en Lucene distribuido que se enumeran en el documentación.
Echemos un vistazo más de cerca a estos pasos desde un aspecto técnico, y el paso principal es reemplazar el paquete Lucene.NET Nuget de su biblioteca con el paquete Distributed Lucene Nuget. Lucene.Net.NCache.
Conectado a NCache Directorio
NCache El directorio, como sugiere el nombre, es una clase base para almacenar los índices para hacer que los índices sean escalables. Entonces, el primer paso es conéctate con el NCache Directorio.
A continuación se muestra el código que lo conecta a un caché llamado lucenecaché y abre el directorio proporcionado en todos los servidores.
|
1 2 3 4 5 6 7 8 9 |
// Specify the cache name that is used for Lucene string cache = "LuceneCache"; // Specify the index name to create the indexes string indexName = "ProductIndex"; // Create a directory and open it on the cache and the index path NCacheDirectory ncacheDirectory = NCacheDirectory.Open(cache, indexName); |
NCache Detalles API geoespacial distribuida de Lucene Inicializar Lucene distribuido
Índice de datos en Lucene distribuido
Una vez inicializado el directorio, IndexWriter crea documentos en el índice con el mismo mecanismo que en Lucene.NET usando AddDocument método. Cuando el documento está escrito, IndexWriter.Commit se llama para persistir el documento y hacer que se pueda buscar.
Distributed Lucene le permite abrir varios escritores en el mismo directorio para la indexación paralela. El ejemplo de código a continuación demuestra cómo puede indexar sus documentos con Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// Create an instance of the writer IndexWriter indexWriter = new IndexWriter(ncacheDirectory, new IndexWriterConfig(LuceneVersion.LUCENE_48, new WhitespaceAnalyzer(LuceneVersion.LUCENE_48))); // Indexing // Add the products information that is to be indexed Product[] products = FetchProductsFromDB(); foreach (var prod in products) { // Create a document and add fields to it Document doc = new Document(); doc.Add(new TextField("ProductID", prod.ProductID, Field.Store.YES)); doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO)); doc.Add(new TextField("Category", prod.Category, Field.Store.YES)); doc.Add(new TextField("Description", prod.Description, Field.Store.YES)); // Writer is created previously indexWriter.AddDocument(doc); } // Calling commit on the writer saves all the write operations indexWriter.Commit(); // Dispose the objects after indexing indexWriter?.Dispose(); ncacheDirectory?.Dispose(); |
NCache Detalles Facetas de Lucene distribuidas Indexación distribuida de Lucene
Búsqueda en Distributed Lucene
Búsqueda se puede realizar después de indexar los datos. los IndexSearcher utiliza el IndexReader para obtener los resultados. los IndexSearcher es responsable de buscar los datos de acuerdo con las consultas dadas. Lucene proporciona una amplia gama de consultas y Distributed Lucene admite todas las consultas de Lucene.
El ejemplo de código a continuación demuestra cómo puede buscar sus documentos indexados con Distributed Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Open a new reader instance IndexReader reader = DirectoryReader.Open(ncacheDirectory); // A searcher is open to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify analyzer type Analyzer analyzer = new WhitespaceAnalyzer(version); // Create a query parser and parse the query with the parser //Specify the searchTerm and the fieldName QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, "Category", analyzer); Query query = parser.Parse("Beverages"); // Returns the top 10000 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs; indexSearcher?.Dispose(); reader?.Dispose(); |
NCache Detalles Contadores de Lucene distribuidos Búsqueda distribuida de Lucene
Usar índices de Native Lucene con Distributed Lucene
Si ya tiene una aplicación .NET que utiliza Lucene, lo más probable es que tenga un gran índice de Lucene creado. NCache proporciona Importar-LuceneIndex cmdlet, que permite a los usuarios importar un índice Lucene existente en NCache Distribuyó Lucene sin necesidad de reconstruir índices.
Este comando de ejemplo carga el índice nativo de Lucene desde C:\Índice a una tienda Distributed Lucene caché de demostración.
|
1 |
Import-LuceneIndex -CacheName demoCache -Path C:\Index -Server 20.200.21.11 |
NCache Detalles Documentos de Lucene distribuidos Importar índices de Lucene
Conclusión
Lucene es un motor de búsqueda altamente eficiente para realizar búsquedas de texto completo en sus datos, pero carece de escalabilidad. NCache se puede usar con Lucene para hacerlo escalable con muy poco esfuerzo. Lucene distribuido escalable hace que su aplicación no solo sea más rápida, sino que también lo ayuda a lidiar con el gran contratiempo de un único punto de falla. NCache se puede conectar fácilmente a su aplicación .NET con un cambio de código de una sola línea, así que considérelo como la mejor opción posible para su aplicación Lucene escalable.




