En esta era de procesamiento de aplicaciones rápido y confiable, todos optan por el almacenamiento en caché distribuido para obtener el mejor rendimiento de su aplicación. Si sus aplicaciones web atraen mucho tráfico y causan transacciones extremadamente altas, entonces definitivamente necesita NCache.
NCache es una solución de almacenamiento en caché distribuida en memoria que proporciona escalabilidad lineal a aplicaciones .NET y Java. Entre varios topologías esa NCache te proporciona, el más popular es Réplica con particiones topología La topología de réplica particionada le ofrece lo mejor de ambos mundos, escalabilidad lineal y alta disponibilidad.
En el clúster Partitioned-Replica, los datos se particionan y se replican en todos los nodos. Por lo tanto, si un nodo del servidor deja de funcionar, sus clientes pueden continuar con sus operaciones interactuando con su contraparte de réplica. Tan pronto como un nodo deja de funcionar, se activa el proceso de transferencia de estado para volver a equilibrar automáticamente los datos huérfanos. Ahora suponga que tiene un clúster de réplica con particiones y necesita que uno de los nodos se detenga para realizar el mantenimiento sabiendo que reiniciará ese nodo poco tiempo después. Veamos qué es este comportamiento y cómo podría ser un desafío para usted.
NCache Detalles Réplica con particiones NCache Docs Modo de mantenimiento NCache Docs
Desafíos de reequilibrio automático durante el mantenimiento
Cada vez que se detiene un nodo en un clúster de réplicas con particiones; se activa la transferencia de estado para reequilibrar los datos en todo el clúster. Este proceso puede llevar más tiempo del previsto, lo que afecta el rendimiento de su aplicación, especialmente cuando los nodos contienen decenas de gigabytes de datos.
La siguiente figura explica el comportamiento del clúster de réplicas con particiones cuando se detiene un nodo.
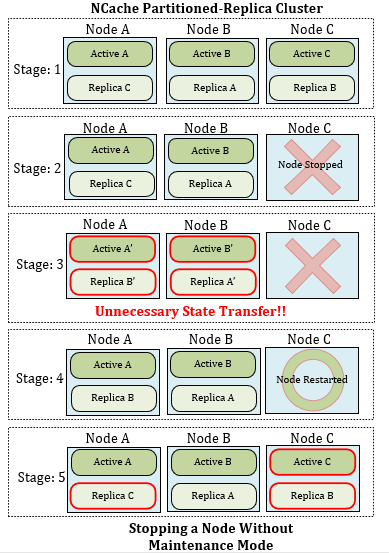
Figura 1: Detención de un nodo sin modo de mantenimiento
En esta figura, tienes un NCache Clúster de réplica con particiones con tres nodos. Aquí, se han introducido cinco etapas para explicar qué sucede cuando se detiene un nodo en un clúster.
- Etapa 1: NCacheRéplica con particiones con tres nodos, A, B y C, cada uno con un nodo activo y uno de réplica.
- Etapa 2: el nodo C se detiene brevemente para mantenimiento. Su activo y su réplica ya no forman parte del clúster y se activa la transferencia de estado.
- Etapa 3: Datos redistribución en el racimo (totalmente innecesaria). Aquí, los datos huérfanos del nodo C se dividen entre los nodos restantes A y B después de que se detiene la transferencia de estado. Según esta división, sus nodos de réplica también se actualizan. Esta transferencia de estado es totalmente innecesaria porque el nodo detenido se reiniciará pronto.
- Etapa 4: el nodo C se reinicia. El clúster, en esta etapa, se comporta como si el nodo C hubiera dejado el clúster. Después de los datos redistribution, el nodo C se inicia de nuevo.
- Etapa 5: el nodo C vuelve a unirse al clúster y vuelve a generar datos rediscontribución. Como sus datos ya se habían distribuido entre A y B, por lo tanto, cuando C se reincorpora, la transferencia de estado se activa nuevamente en todo el clúster para asignar nuevos datos a los nodos.
Idealmente, esto parece ser la solución perfecta. Detienes un nodo, se produce una transferencia de estado. Arreglas lo que quieras arreglar y vuelves a iniciar ese nodo. La transferencia de estado se activa nuevamente para equilibrar todos los cubos.
Pero, ¿por qué no es esta la solución ideal? ¿Qué va mal aquí?
Hay varios inconvenientes de provocar la transferencia de estado innecesariamente. Ellos son:
- Alto costo debido a múltiples llamadas de red y sobrecarga de procesamiento.
- Alta complejidad temporal cuando los nodos contienen una gran cantidad de datos.
- Comportamiento erróneo cuando un nodo se reinicia durante la transferencia de estado y conduce a la transferencia de estado dentro de la transferencia de estado.
NCache Detalles Réplica con particiones NCache Docs Modo de mantenimiento-NCache Docs
La solución: Réplica particionada consciente del modo de mantenimiento
Teniendo en cuenta todos estos contratiempos de transferencia de estado innecesaria que ocurre cada vez que un nodo sale y se une a un clúster, NCache le proporciona Modo de mantenimiento.
El modo de mantenimiento le permite detener un nodo durante un período específico e iniciarlo cuando finaliza su mantenimiento. Este modo garantiza que durante el tiempo que un nodo está en mantenimiento, el subproceso de transferencia de estado no se activa dentro del clúster. Además, es extremadamente beneficioso cuando el clúster comprende una gran cantidad de datos.
En qué se diferencia el modo de mantenimiento de la parada normal de un nodo en la siguiente figura.
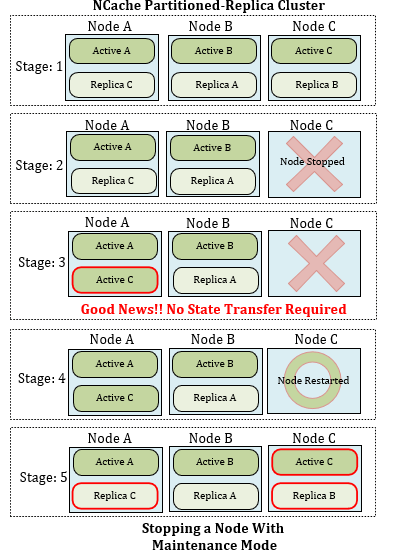
Figura 2: Detención de un nodo sin modo de mantenimiento
- Etapa 1: la estructura de la topología de réplica con particiones of NCache se muestra donde un clúster POR consta de tres nodos de servidor que contienen una gran cantidad de datos.
- Etapa 2: Nodo C detenido. El nodo C se detiene para mantenimiento a través del modo de mantenimiento.
- Etapa 3: Datos redisContribución. Aquí, la réplica de C se activa y comienza a dirigirse a los clientes del nodo C. Esto elimina la necesidad de activar la transferencia de estado, por lo tanto, el subproceso de transferencia de estado se detiene mientras el clúster esté en mantenimiento. Esto resuelve el problema que se enfrenta cuando la transferencia de estado innecesaria equilibra los datos en el clúster después de que se detiene el nodo C.
- Etapa 4: Nodo C reiniciado. Después de detenerse por motivos de mantenimiento, el nodo C espera a reiniciarse. Cada vez que el clúster sale del modo de mantenimiento, se inicia el nodo C.
- Etapa 5: Transferencia de datos. Es esa fase del clúster en la que el nodo C recibe todos los datos de su parte réplica y actualiza todo el nodo (es decir, el activo C y la réplica B) a través de la transferencia de estado.
NCache Detalles Réplica con particiones NCache Docs Modo de mantenimiento-NCache Docs
Cómo detener un nodo para mantenimiento
Puede detener un nodo para realizar tareas de mantenimiento mediante Web Manager o PowerShell. Así es como puede detener un nodo para mantenimiento desde su Web Manager. Al detener un nodo, se le solicita que mencione el tiempo de mantenimiento durante el cual desea mantener ese nodo en mantenimiento. Este tiempo de espera se considera como un período durante el cual no se puede activar ninguna transferencia de estado.
Los siguientes pasos le permiten detener cualquier nodo que desee para el mantenimiento.
- Acceda a su NCache Web Manager
- Vaya a Cachés en clúster y seleccione el clúster que necesita mantenimiento
- Entre sus diversos nodos, seleccione el que requiere mantenimiento.
Ve a su configuración y selecciona la opción Parada por mantenimiento.
Cómo salir de un nodo del modo de mantenimiento
Una vez que un clúster ingresa al modo de mantenimiento, se utiliza Web Manager para salir de ese clúster. Los siguientes son los pasos que deben seguirse:
- De tu NCache Web Manager, vaya a Cachés en clúster
- Seleccione el clúster que está en mantenimiento.
- Vaya a su Configuración y seleccione Salir del modo de mantenimiento.
Aparte de Web Manager, hay varias formas a través de las cuales un nodo puede salir del modo de mantenimiento. Estos escenarios deben tenerse en cuenta, ya que algunos pueden afectar el rendimiento de su aplicación.
Un nodo puede salir del modo de mantenimiento en los siguientes casos:
- Cuando se inicia el nodo en mantenimiento: Si el nodo que está en mantenimiento se inicia manualmente, ya sea a través del administrador o mediante el comando de PowerShell, ese nodo sale del modo de mantenimiento.
- Cuando expira el tiempo de espera: Cuando expira el tiempo de espera proporcionado para el mantenimiento, se activa la transferencia de estado y el clúster sale automáticamente del modo de mantenimiento.
- Cuando un nodo abandona el clúster: Ningún nodo puede abandonar un clúster sin problemas mientras esté en mantenimiento. Pero si uno de los nodos de ese clúster sale a la fuerza, ese clúster inevitablemente sale del modo de mantenimiento, a pesar de que todavía está en proceso de mantenimiento. Aquí, el punto al que debe prestar atención es que si el mismo nodo que estaba en mantenimiento se va, existen altas posibilidades de pérdida de datos.
Independientemente del método que utilice para salir del modo de mantenimiento, esa señal por sí sola es la señal para que el subproceso de transferencia de estado desencadene el proceso de autoequilibrio en todo el clúster.
Resumiendo
Si desea una manera de acomodar la aplicación de parches en su caché agrupada de réplicas con particiones sin comprometer el rendimiento de la aplicación, consulte NCache Modo de mantenimiento. El modo de mantenimiento le permite corregir un error, agregar un parche, actualizar software o hardware, sin introducir ningún tiempo de inactividad de la aplicación. Todo lo que tienes que hacer es seguir los pasos mencionados anteriormente y comprobar por ti mismo lo extraordinario NCache El modo de mantenimiento es.





