Para aplicaciones de muchas transacciones con arquitecturas complejas, el intercambio continuo de datos provoca una carga no uniforme y un retraso en el rendimiento. El refinado de datos es un gran desafío cuando se trata de aplicaciones comerciales grandes y complejas. Para atender esto, el procesamiento de flujo se utiliza para definir un flujo de datos en particular mediante la creación de flujos de datos. Una aplicación de transmisión típica consta de varios productores que generan nuevos eventos y un conjunto de consumidores que procesan estos eventos.
Una de estas aplicaciones populares es Pub/Sub, donde los editores ingresan mensajes y los suscriptores reciben los mensajes a los que se suscribieron. Sin embargo, en el procesamiento de transmisión, Pub/Sub enfrenta algunas limitaciones, como que una vez que el suscriptor recibe el mensaje, la aplicación ya no lo retiene. Entonces, si luego otro suscriptor quiere los mensajes del editor, los mensajes anteriores no existen. Además, para el flujo de datos entrantes, la filtración de datos se lleva a cabo en el extremo del cliente (suscriptor) y no en el servidor, lo que hace que la arquitectura de la aplicación sea compleja.
Para superar estas limitaciones de Pub/Sub, NCache viene con un mecanismo eficiente de procesamiento de datos en el lado del servidor usando consultas continuas. Las Consultas Continuas permiten que las aplicaciones sean notificadas de todos los cambios que ocurren en los datos que residen en el caché, cumpliendo ciertos criterios. Este blog lo ayuda a comprender las ventajas de usar Consultas continuas en el procesamiento de transmisiones con la ayuda de una solución creada para el procesamiento de transmisiones en GitHub.
Uso de consultas continuas para el procesamiento de secuencias
La solución explica una aplicación de comercio electrónico, que procesa miles de clientes cada día para sus compras en línea. Si observa el diagrama a continuación, los clientes de todo tipo y categoría se agregan en la aplicación. Para que el procesamiento de los clientes sea eficiente, los clientes sin filtrar se clasifican y filtran como clientes "Oro", "Plata" y "Bronce" en función del número de sus pedidos, mediante consultas continuas.
Consulta continua permite que las aplicaciones reciban notificaciones cuando los datos que cumplen ciertos criterios cambian dentro de la memoria caché y los criterios se especifican mediante comandos SQL. Por ejemplo, si una aplicación desea etiquetar a los clientes con la mayor cantidad de pedidos como "Clientes Gold", todo lo que necesita hacer es registrar un criterio de comando SQL y, por lo tanto, proporcionar una devolución de llamada. Esta devolución de llamada se activa ante cualquier cambio que se produzca en el conjunto de resultados que cumpla los criterios. Una vez que se invoca la devolución de llamada, la aplicación puede categorizar a estos clientes como "clientes dorados" usando etiquetas.
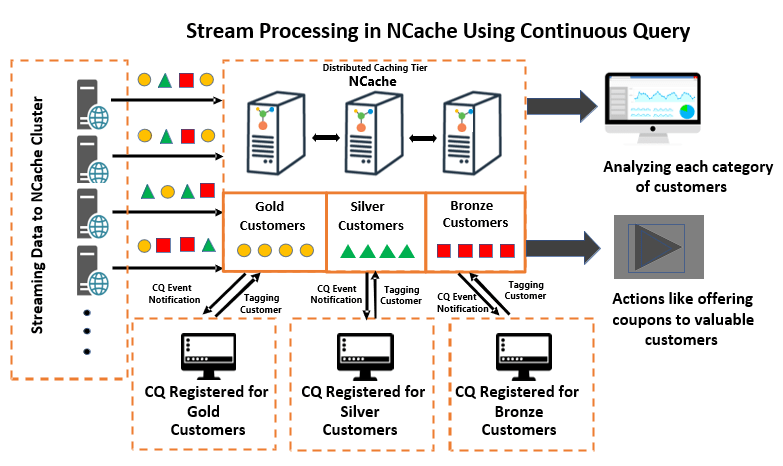
Figura 1: Procesamiento de secuencias mediante consulta continua
De manera similar, la aplicación puede crear varias categorías registrando varios CQ, cada uno con sus propios criterios y una devolución de llamada. De esta forma, la aplicación solo obtiene los datos filtrados que le interesan. Luego, los datos filtrados pueden analizarse más de acuerdo con los requisitos comerciales, como ofrecer descuentos a los clientes de alto nivel según la categoría del cliente.
Los eventos se desencadenan si alguna de las siguientes acciones de modificación de datos tiene lugar en la memoria caché:
- Añadir: Agregar un nuevo elemento al caché que cumpla con los criterios de consulta
- Actualizar: Actualización de un elemento existente en el conjunto de resultados de la consulta.
- Retirar: Quitar un elemento de la memoria caché o actualizar cualquier elemento existente en la memoria caché de manera que provoque la eliminación del elemento del conjunto de resultados de la consulta.
Veamos un ejemplo de código rápido del uso del procesamiento de secuencias en la memoria caché con consulta continua. En este ejemplo se ejecuta una consulta continua sobre los datos donde los pedidos que son mayores a 10 se agregan a la categoría “Clientes Oro”. Además, se desencadena un evento en cada elemento agregado al conjunto de resultados de la consulta.
|
1 2 3 4 5 6 7 8 9 10 11 |
string query = SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery (queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification (new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
NCache Detalles Consulta continua y Pub/Sub
Consulta continua conserva los datos que Pub/Sub no
Ahora los datos filtrados a través de consultas continuas (para clientes con pedidos >10) se etiquetan como "Clientes Gold" y se actualizan en la memoria caché. Mire el código a continuación para ver cómo se hace.
|
1 2 3 4 5 6 7 8 9 10 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.None); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
La consulta continua mantiene los datos conservados en la memoria caché incluso después del procesamiento. De esta manera, resuelve el problema que enfrenta Pub/Sub para los datos que surgen continuamente, es decir, múltiples aplicaciones que publican los datos en NCache capa de mensajería. Por lo tanto, varios suscriptores reciben los datos y no tienen un almacenamiento de datos fiable, ya que los mensajes se eliminan del bus de mensajes una vez recibidos. Los datos son almacenados por la aplicación o agregando una nueva fuente de datos que es un escenario mucho más complejo. La consulta continua, por otro lado, se asegura de que no haya pérdida de datos, lo que le ahorra todo el esfuerzo adicional de conservar manualmente sus datos.
NCache Detalles Descargar NCache Comparación de ediciones
La consulta continua permite el desacoplamiento de aplicaciones a través de una potente filtración
Las aplicaciones grandes y complejas pueden tener varias agrupaciones en función de sus arquitecturas, por ejemplo, con 10 aplicaciones en ejecución, dos de ellas podrían tratar con el conjunto de datos de los clientes Gold, mientras que las otras dos podrían tratar con el conjunto de datos de los clientes Silver. En tales casos, querrá una lógica de negocios separada para cada conjunto de datos donde los datos se filtren de acuerdo con las necesidades de procesamiento de flujo de cada aplicación. Por lo tanto, tales aplicaciones grandes y complejas necesitan desacoplarse, ya que la dependencia de las aplicaciones entre sí provoca enormes cuellos de botella en el rendimiento, así como una mayor complejidad de las aplicaciones.
La consulta continua filtra de manera muy eficiente los datos de sus aplicaciones con la ayuda de declaraciones SQL bastante sofisticadas, por lo que ninguna aplicación se superpone con las demás aplicaciones. Este desacoplamiento se vuelve de gran utilidad en una arquitectura de microservicios donde cada servicio se ejecuta en una pila de aplicaciones separada. Cada microservicio obtiene y procesa sus propios datos sin generar ninguna dependencia. Este nivel de filtración de datos y desacoplamiento de aplicaciones no se puede lograr con Pub/Sub.
La Figura 2 muestra varias aplicaciones cliente que manejan sus respectivos conjuntos de datos en una arquitectura desacoplada usando NCache consultas continuas.
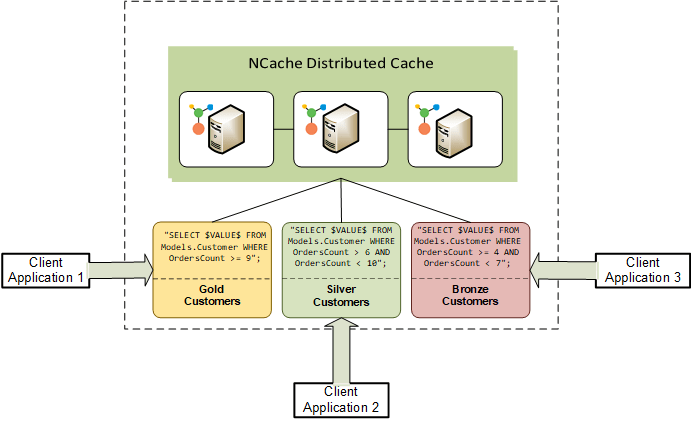
Figura 2: Desacoplamiento entre Aplicaciones
Obtención de datos mediante etiquetas
Etiquetas in NCache se agregan calificadores para los datos que se utilizan para categorizar los datos en función de ellos. Para grandes conjuntos de datos como el escenario mencionado, las etiquetas son realmente útiles para obtener datos relevantes en lugar de buscar los datos en todo el caché. Si un cliente pertenece a la categoría de "Clientes Gold", se agrega una etiqueta para una recuperación rápida. Según estas categorías, los clientes pueden recibir beneficios adicionales, como descuentos, cupones, etc. NCache proporciona varios formas flexibles de obtener datos mediante etiquetas, explicado detalladamente en la documentación.
Ahora veamos el ejemplo de código de las etiquetas asociadas con los "Clientes Gold". A estos clientes se les pueden ofrecer cupones o servicios premium.
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
Datos de caché que caducan
NCache permite caducidad de datos de caché que invalida los datos después de un intervalo específico y luego los elimina del caché en un intervalo limpio.
NCache proporciona dos tipos de vencimientos:
En el caso de los clientes, se agrega la caducidad a los artículos que no pertenecen a ninguna de las tres categorías, es decir, Oro, Plata o Bronce. Todos los demás clientes con pedidos inferiores a 4 se agregan con un intervalo de tiempo de caducidad y se eliminan de la memoria caché para que no se realicen más análisis. Sin embargo, la caducidad de cualquier cliente que pertenezca a cualquiera de las categorías se establece en Ninguno para conservar los datos en la memoria caché a menos que se eliminen manualmente. Así es como puedes agregar 15 segundos de caducidad a un cliente con menos de 4 pedidos.
|
1 2 3 4 5 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, new TimeSpan(0, 0, 15)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
Por qué utilizar NCache?
NCache is 100% .NET/.NET Solución central de almacenamiento en caché distribuido en memoria y ha sido líder en el mercado durante mucho tiempo. Es extremadamente rápido y linealmente escalable, y elimina de manera eficiente los cuellos de botella de rendimiento de su aplicación mediante el almacenamiento en caché de los datos. Le ahorra el costo de la red al reducir los costosos viajes de red. NCache le proporciona un amplio conjunto de funciones, como Consulta continua, que hace que el análisis de datos sea muy rápido y eficiente, junto con otras funciones para facilitar el flujo fluido de su aplicación.





