Caché distribuida con persistencia
NCache proporciona una caché distribuida clave-valor, con un almacén persistente en la memoria, para recuperar datos valiosos de manera confiable según sea necesario. Mantiene una copia de los datos de caché en el almacén de persistencia y luego carga los datos persistentes en el reinicio de caché (planeado o no planeado). Almacena y carga tantos datos como los servidores de caché pueden contener. La persistencia garantiza una alta disponibilidad de datos y, al mismo tiempo, los datos en memoria proporcionan un alto rendimiento. En este documento, una caché distribuida con persistencia también se denomina caché persistente.
Note
Caché distribuida solo con soporte de persistencia Topologías con particiones y Cachés locales (OutProc).
Puede crear un caché distribuido con persistencia usando un NoSQL Document Store como almacén de persistencia para copias de seguridad de datos. El caché persistirá en todas las API de escritura, metainformación, corrientes, estructuras de datosy índices dinámicos a la tienda backend.
Note
Los mensajes de Pub/Sub no se conservan, pero NCache apoya API de publicación/suscripción y le permite crear un Caché de mensajería Pub/Sub.
Tenga en cuenta que los datos eliminados del caché debido a cualquier invalidación de datos o eliminación explícita también se eliminarán del almacén de persistencia subyacente. Se admite la adición de elementos con caducidad y dependencia de clave. Sin embargo, no recomendamos este enfoque ya que los datos almacenados dentro de un caché tan persistente son datos permanentes. Mientras tanto, los datos con dependencia de la base de datos y la dependencia de fuentes externas no va a persistir.
Note
Similar a una caché distribuida volátil, se admite una fuente de respaldo para una caché distribuida con persistencia.
Por qué persistir datos
NCache almacena datos en RAM para un acceso más rápido. Dado que la memoria caché es volátil, la pérdida de datos es inevitable en los siguientes escenarios:
- Nodo abajo en topología particionada.
- Más de un nodo inactivo simultáneamente en la topología Partición-Réplica.
- Agrupar hacia abajo ya sea por razones de mantenimiento o por fallas catastróficas.
Con un caché persistente, puede lograr lo siguiente:
Alta disponibilidad de datos: En caso de falla de la memoria debido a cualquiera de las razones mencionadas anteriormente, NCache recupera rápidamente los datos cargándolos desde el almacén de persistencia subyacente. La memoria caché se vuelve operativa sin afectar las operaciones del cliente incluso después de una falla catastrófica.
Tolerancia a fallos: El mantenimiento de una copia en tiempo real de los datos de la memoria caché minimiza el tiempo de inactividad y proporciona tolerancia a fallas cuando los nodos únicos o múltiples abandonan el clúster.
Importante:
Para la persistencia, la longitud de la clave no debe exceder los 1023 bytes.
¿Cómo funciona?
Aquí describimos el funcionamiento y el comportamiento de un caché distribuido con persistencia. El siguiente diagrama muestra la arquitectura básica. Puede crear una memoria caché distribuida con persistencia con un almacén de persistencia en el backend. La tienda está centralizada y accesible para todos los nodos. NCache escribe los datos agregados a la memoria caché en el almacén de back-end en intervalos de tiempo mantenibles. En el reinicio de la memoria caché o en la salida/unión del nodo, los datos persistentes se cargan en la memoria tanto como los servidores de la memoria caché pueden contener.
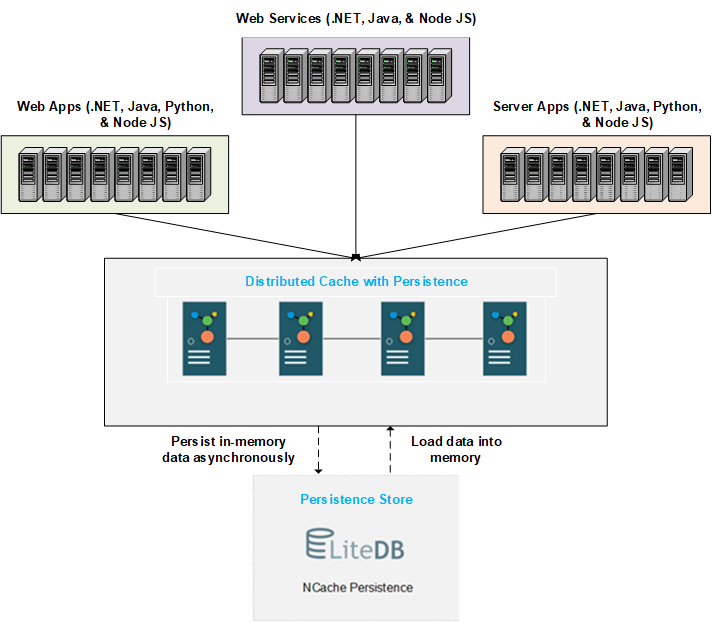
Discutimos el proceso detallado de persistencia y carga de datos a continuación.
Persistencia de datos
Una vez que crea un caché distribuido con persistencia, todas las operaciones de escritura se realizan primero en la memoria y luego se conservan en el almacén de back-end. Ya que NCache tiene una arquitectura distribuida, cada nodo del servidor conserva sus datos mientras que todos los nodos del servidor pueden acceder a la tienda. Además, dado que la distribución de datos se basa en depósitos debido a las particiones, los datos también persisten.
Persistencia asíncrona
NCache persiste los datos en la memoria en el almacén de persistencia mediante persistencia asíncrona. Aquí te explicamos cómo funciona. Cada partición tiene una cola de persistencia para registrar las operaciones realizadas por el cliente. Cualquier operación de escritura realizada por el cliente se pone en cola una vez exitosa. Dado que la persistencia funciona de forma asincrónica, el cliente no espera después de poner en cola la operación. Las operaciones en cola se verifican periódicamente en un nivel configurable. persistence-interval y finalmente replicado en el almacén de back-end por un subproceso de persistencia. Cada cola se escribe de forma independiente.
Note
El valor predeterminado de persistence-interval is 1 seg y es configurable en el NCache Centro de gestion.
Normalmente, el lote se aplica después persistence-interval, pero si el lote de persistencia falla consecutivamente, luego persistence-retries el intervalo de lote se cambia a persistence-interval-longer. Una vez que tenga éxito, el intervalo del lote se restablecerá a persistence-interval.
Importante:
El rendimiento de la memoria caché no se degrada, ya que las operaciones del cliente se realizan normalmente debido a la replicación asíncrona.
Si el caché no puede conservar datos dentro de la cola de persistencia debido a algún problema, seguirá realizando operaciones de escritura hasta que esté lleno. Si las operaciones en cola no persisten, la información sobre los depósitos fallidos se registra en los registros de caché.
Note
La topología Partición-Réplica se recupera de un error en la cola a través de la cola de la réplica. Sin embargo, la pérdida de datos es inevitable si un nodo y su réplica fallan simultáneamente.
Carga de datos
Una vez que los datos están en el almacén, la memoria caché vuelve a cargar automáticamente los datos persistentes en la RAM al reiniciar la memoria caché. El almacén persistente debe estar disponible para los nodos en caché todo el tiempo. Si no pueden acceder a la tienda, el caché no se iniciará. La carga de datos se produce de forma distribuida. Dado que el almacenamiento de datos es un procedimiento basado en depósitos, cada nodo puede acceder al almacén centralizado para cargar sus depósitos asignados según el mapa de distribución de datos. Además, si ha configurado índices para consultar datos en la memoria caché, los índices de consulta se regeneran al reiniciar la memoria caché.
Importante:
El almacén persistente debe estar disponible para todos los nodos de caché en todo momento.
Comportamiento de la operación durante la carga de datos
Los procesos de carga y persistencia de datos se ejecutan simultáneamente. Mientras tanto, las recuperaciones basadas en claves se sirven desde la memoria caché si se cargan los datos solicitados. Si no está en la memoria caché, dichas operaciones se realizan directamente desde la tienda a través de la carga diferida. En ese caso, el rendimiento de la Get la operación se verá afectada.
Tenga en cuenta que las operaciones de búsqueda no basadas en claves o basadas en criterios, como GetGroupKeys, GetKeysByTagy las consultas SQL no se atenderán hasta que los datos se carguen por completo desde el almacén a la memoria.
advertencia
Si se produce una operación de búsqueda no basada en claves durante la carga de datos y los datos solicitados no se cargan por completo, la aplicación generará una excepción que indica los datos no se cargaron completamente desde el almacén de persistencia.
Escenarios de carga de datos
Los datos se cargan desde el almacén persistente en los siguientes escenarios:
Al inicio de caché: En el inicio de la memoria caché, el nodo coordinador carga todos los cubos. Tan pronto como otros nodos se unen al clúster, se actualiza la distribución de depósitos. Cada nodo busca sus cubos asignados en el entorno local. Los cubos cargados en el caché se extraen transferencia de estado. Si los cubos asignados a un nodo no se cargan por completo, ese nodo los carga directamente desde la tienda. Cada nodo puede acceder a la tienda para cargar sus cubos asignados si están presentes en el caché.
Cuando se inicia por primera vez una caché distribuida con persistencia, se puede completar configurando Cargador de inicio de caché ya que el almacén de persistencia no tiene datos en ese momento. Una vez que se llena el almacén, los datos siempre se cargan desde el almacén al iniciarse la memoria caché, incluso si ha configurado el Cargador de memoria caché. Sin embargo, si necesita agregar más datos periódicamente, puede usar Actualización de caché. La actualización de la memoria caché se ejecuta a intervalos periódicos, independientemente de si la memoria caché y el almacén ya tienen los datos.
En la unión del nodo: Cuando un nuevo nodo se une al clúster, obtiene los depósitos asignados de los nodos del clúster existentes a través de la transferencia de estado si ya están cargados. Si los cubos asignados no se cargan por completo en la memoria caché, el nuevo nodo los carga desde el almacén.
En licencia de nodo: Los datos se cargan desde el almacén para evitar la pérdida de datos cuando un nodo o nodos abandonan el clúster. El comportamiento de carga en la salida del nodo varía según las diferentes topologías.
Topología particionada: Cuando un nodo se va, sus cubos se distribuyen entre los nodos del clúster existentes y los nuevos propietarios los cargan desde el almacén persistente.
Topología de partición-réplica: Partition-Replica tolera fallas de nodo hasta un nivel mediante la recuperación de depósitos perdidos mediante la transferencia de estado desde la réplica. Sin embargo, cuando un nodo y su réplica están inactivos simultáneamente, los datos perdidos aún se pueden recuperar desde el almacén de respaldo.
Importante:
La memoria caché debe tener la capacidad de acomodar los datos en caso de que el nodo se caiga o abandone.
Gestión de capacidad para una caché distribuida con persistencia
Una caché persistente puede recuperarse de la pérdida de datos al salir o caer el nodo solo cuando la caché tiene suficiente espacio para acomodar los datos del nodo o nodos abandonados. Si la memoria caché no puede acomodar todos los datos en el almacén de persistencia debido a que está llena o por cualquier otro motivo, las operaciones de agregar o actualizar comenzarán a fallar. Mientras tanto, algunos de los depósitos no tendrán datos completos. Estos depósitos incompletos se recargan desde la tienda en dos casos:
- Un nuevo nodo se une al clúster.
- El tamaño de la caché aumenta mediante la aplicación en caliente.
Note
Si una memoria caché está llena pero está sincronizada al 100 % con el almacén persistente, solo se bloquean las nuevas adiciones. Todas las demás operaciones pueden ocurrir en el caché sin ningún problema.
Cuando el caché está lleno con datos parciales en la memoria, es posible que el caché no sirva operaciones basadas en criterios o no basadas en claves (como GetGroupKeys, GetKeysByTagy consultas SQL). Por otro lado, las recuperaciones basadas en claves siempre se realizarán a través de la memoria caché o de la tienda. Específicamente, el caché intentará cargar de forma diferida todas las adquisiciones basadas en claves para los cubos incompletos en caso de fallas en el caché.
advertencia
Si se realiza una operación de búsqueda basada en criterios en la memoria caché llena y los datos solicitados no están en la memoria caché, se generará una excepción. La operación no puede ocurrir porque el caché no tiene todos los datos en la memoria.
Planificación de capacidad para caché llena
Para evitar los problemas que surgen cuando la caché está llena, debe planificar la capacidad de su caché persistente antes de comenzar a usarla. Al planificar la capacidad de una memoria caché distribuida con persistencia, le recomendamos que planifique el tamaño de la memoria caché por nodo para que, si un nodo deja de funcionar, los nodos restantes puedan acomodar todos los datos del nodo perdido.
Expansión del tamaño de la memoria caché cuando la memoria caché está llena
Importante:
NCache intenta garantizar una alta disponibilidad de datos en la salida de un solo nodo en una caché distribuida basada en partición-réplica con persistencia a través de la expansión de tamaño. Sin embargo, no se promete ni garantiza una alta disponibilidad de datos.
En el caso de Partition-Replica, si un nodo abandona un clúster, los nodos restantes del clúster alojan los datos propiedad del nodo saliente. Sin embargo, existe la posibilidad de que los datos del nodo que sale no tengan espacio debido a problemas de tamaño. NCache admite la expansión automática del tamaño de la caché cuando un nodo abandona la caché distribuida basada en réplica de partición con persistencia. El modo de expansión solo se admite para un solo nodo inactivo. El propósito es evitar datos parciales en el caché y realizar operaciones basadas en criterios en el caché completo.
El proceso de expansión ocurre internamente. El modo de expansión se activa cuando un solo nodo abandona el clúster mientras los nodos en ejecución son iguales o mayores que los nodos configurados. El tamaño ampliado se calcula en función de los nodos configurados o los nodos en ejecución en el clúster (el que sea mayor). Cuando la memoria caché está en modo expandido, cada nodo del clúster aumenta su tamaño automáticamente para acomodar los datos recibidos a través de la transferencia de estado al dejar el nodo.
Importante:
La expansión ocurre solo cuando el número de nodos restantes (después del nodo inactivo) es máximo de {nodos configurados/nodos en ejecución}-1. El tamaño ampliado se calcula en función de los nodos configurados o los nodos en ejecución en el clúster (el que sea mayor).
En el modo ampliado, se sirven tanto las operaciones basadas en criterios como las claves. Sin embargo, seguirá bloqueando las operaciones de adición si el tamaño de la memoria caché ha superado una vez el tamaño de la memoria caché configurado.
El caché sale del modo expandido cuando un nuevo nodo se une al clúster o el tamaño del caché aumenta a través de la aplicación en caliente. Luego se actualiza el mapa de distribución y se activa la transferencia de estado. Una vez que se completa la transferencia de estado, cada nodo sale del modo expandido y el tamaño de caché se reduce al tamaño de caché configurado.
Note
Se registra una entrada tanto en los registros de caché como en los registros de eventos cuando el caché ingresa y existe en el modo expandido.
Comportamientos de inaccesibilidad
Los datos se cargan desde el almacén de persistencia al inicio del caché, por lo que el almacén debe estar disponible para los nodos de caché de manera constante. Aquí, discutimos los comportamientos cuando el almacén de persistencia es inaccesible;
- En el momento de la creación del caché: La conexión a la tienda se verifica en el momento de la creación del caché. Si es inaccesible, no podrá crear el caché y recibirá una notificación de error. Del mismo modo, una memoria caché no se iniciará si el almacén no está disponible para ningún nodo del clúster.
advertencia
La memoria caché no se iniciará hasta que todos los nodos del servidor puedan acceder al almacén persistente en el momento de la creación de la memoria caché.
En el momento de la carga de datos: La tienda puede volverse inaccesible durante la carga de datos debido a una falla en la red. En ese caso, la memoria caché volverá a intentar cargar los depósitos de datos restantes en el estado de carga. Mientras tanto, las operaciones de búsqueda no basadas en claves fallarán. Puedes configurar reintentos de carga de datos en el archivo de configuración del servicio.
En el momento de ejecutar el caché: La tienda puede volverse inaccesible para un caché en ejecución debido a una falla en la red, ya sea por un breve período o por un tiempo infinito. En tal pérdida de conexión, el caché seguirá aceptando y poniendo en cola operaciones de escritura. Mientras tanto, NCache seguirá intentando conservar las operaciones en cola en intervalos por lotes hasta que se restablezca la conexión con el almacén persistente.
Si pierde la conexión infinitamente, las operaciones de escritura ocurren hasta que la memoria caché está llena. Una vez que la memoria caché esté llena, las operaciones de escritura posteriores fallarán. Sin embargo, las operaciones de recuperación basadas en claves se servirán como se discutió anteriormente.
Supervisión y creación de caché persistente
Note
Solo se admite la memoria caché serializada JSON para una memoria caché distribuida con persistencia.
Puede crear una caché distribuida con persistencia especificando una nueva tienda o una existente (creada usando NCache) ya sea a través del NCache Centro de gestion o a través de herramienta PowerShell.
NCache proporciona diferentes contadores de rendimiento para monitorear las estadísticas de un caché distribuido con persistencia. Además, puedes monitorear un caché distribuido con persistencia a través de NCache Monitor, PowerShell y herramienta PerfMon.
Vea también
Crear una caché distribuida con persistencia
Introducción a la caché distribuida con persistencia