Topologías de partición-réplica y caché de partición
En un clúster, si todos los nodos del servidor tienen la misma copia de datos, se obtiene una alta disponibilidad de esos datos. Eso significa que el clúster puede sobrevivir a algunas fallas de nodos sin experimentar ninguna pérdida de datos. Sin embargo, esto no le proporciona escalabilidad. Cuando los datos comienzan a crecer enormemente, el diseño debe reducir el alcance de la replicación y comenzar a particionar los datos.
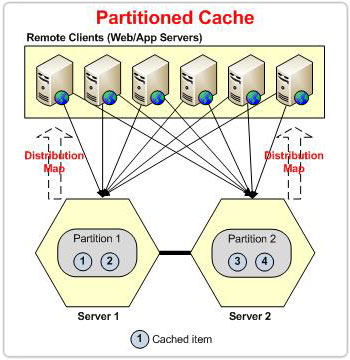
Particionar significa que necesita distribuir sus datos entre varios nodos para que se distribuya la carga de datos de lectura y escritura. A medida que sus datos crecen, puede agregar más nodos de servidor en el clúster para almacenar más datos. Cada nodo de servidor en un clúster se denomina partición.
Al particionar los datos, se puede lograr escalabilidad, pero ahora la pregunta es ¿cómo se particionan esos datos? Una solución simple podría ser asignar datos a una partición mediante un método de operación por turnos, pero ¿cómo vamos a encontrar un dato en particular una vez que se ha agregado al almacén?
A través del round robin, perderemos la capacidad de rastrear la ubicación de los datos. Necesitamos una mejor manera de distribuir los datos, asegurando no sólo la distribución equitativa de los datos sino también la capacidad de buscarlos rápidamente.
Note
La topología particionada también es compatible con NCache Professional.
Note
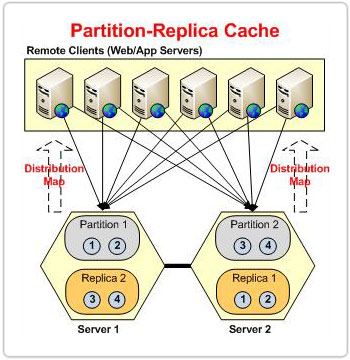
La única diferencia entre las topologías Partitioned y Partition-Replica es que la primera no tiene cachés de réplica, lo que la hace propensa a la pérdida de datos.
Partición de datos basada en hash para cachés de particiones
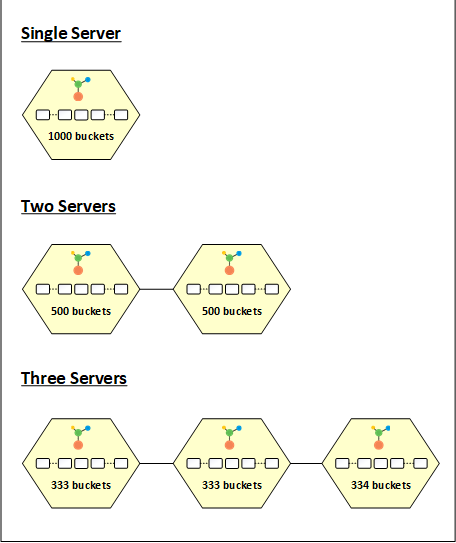
NCache divide los datos en varios fragmentos y los coloca en diferentes particiones. Estos trozos se llaman cubos. Hay un total de 1000 depósitos que se dividen en partes iguales entre los nodos del clúster. La idea aquí es aplicar una función hash en la clave del elemento y modelarla según el número total de depósitos (1000 en este caso) para obtener un depósito de propietario para estos datos.
Mapa de distribución
El servidor coordinador en el clúster tiene la responsabilidad de generar un mapa que contenga la distribución del depósito. Este mapa se llama mapa de distribución. El servidor coordinador comparte este mapa de distribución con el resto de particiones del clúster y con los clientes conectados. Este método siempre le proporciona la misma dirección de depósito para un elemento, independientemente de la cantidad de servidores en el clúster. Aunque el depósito puede moverse de una partición a otra en cualquier momento, el depósito de un artículo nunca puede cambiar. Eso significa que cuando un cubo se mueve, se lleva todos sus datos consigo.
Distribución de datos según el mapa de distribución
Cuando inicia un clúster de caché con una sola partición, los 1000 depósitos se asignan a este nodo. Eso significa que todos los datos van a esta partición. Cuando inicia otro nodo en el clúster, los cubos se distribuyen por igual entre las dos particiones con 500 cubos cada una. De manera similar, al agregar un tercer nodo al clúster, los cubos se vuelven a redistributado. En este caso, los tres nodos tendrán 333, 333 y 334 depósitos respectivamente.
De manera similar, cuando una partición abandona el clúster, la distribución del depósito cambia. Por ejemplo, cuando una partición sale de un clúster de tres nodos, los 333 o 334 depósitos que posee esa partición son redistributado entre los dos nodos restantes. Siempre que hay un cambio en la distribución, se activa una transferencia de estado para reequilibrar los datos entre los nodos, de acuerdo con la distribución del depósito.
Distribución aleatoria de datos
Este método de partición le brinda una buena cantidad de aleatoriedad para garantizar que los datos se dividan equitativamente entre los depósitos y las particiones. Sin embargo, con este método de partición, usted pierde el control sobre qué datos deben asignarse a qué partición. En general, no le importará adónde van sus datos. Pero, en algunos casos, es posible que desee que los datos relacionados estén ubicados en el mismo lugar. Para esto, puede usar Location Affinity, donde se aplica una función hash en una parte de la clave en lugar de en toda la clave.
Distribución equilibrada de datos
Siempre que los cubos son redistributado entre los nodos, NCache asegura que los baldes estén redistributado de tal manera que el tamaño de los datos que recibe cada partición es casi el mismo. Cada partición comparte las estadísticas de los depósitos que posee, en un intervalo configurable, con otras particiones del clúster. Esto ayuda a generar un mapa de distribución equilibrado cuando sea necesario, lo cual es justo en términos de los datos que recibe cada partición. El equilibrio se basa en el tamaño de los datos en lugar del número de elementos. Este equilibrio suele estar garantizado en el momento del cucharón. redisatribución como resultado de la salida o incorporación de un nodo.
Equilibrio de carga de datos automático y manual
Sin embargo, existe una pequeña posibilidad de que observe que una o más particiones en un clúster están sesgadas y reciben más carga que el resto. En este caso, tiene la opción de equilibrar manualmente los datos de un nodo en particular, lo que garantiza que los datos de ese nodo sean iguales al tamaño promedio de los datos que recibe cada partición. Luego, también hay una función llamada 'Equilibrio automático de carga de datos' que hace el trabajo automáticamente en segundo plano. Esta función está deshabilitada de forma predeterminada porque, si se usa sin precaución, puede causar un depósito frecuente. redistribución y, por lo tanto, transferencias de estado no deseadas entre las particiones.
Tamaño de datos por partición
El tamaño de los datos que puede contener cada partición es igual al tamaño de la caché configurada. Por ejemplo, si el tamaño de caché configurado es de 2 GB y el tamaño del clúster es de tres particiones, la cantidad total de tamaño de caché en este clúster es de 6 GB.
Entonces, con esta topología, no solo está distribuyendo la carga de lectura y escritura entre los servidores, sino que también está aumentando la capacidad con cada servidor nuevo que se agrega al clúster.
Réplica de partición
Ahora que hemos cubierto cómo la topología Partition-Replica escala la carga de transacciones y la capacidad de almacenamiento. Hablemos de cómo maneja la alta disponibilidad. Cada nodo del clúster tiene una copia de seguridad de otra partición que actúa como una partición pasiva denominada réplica. En caso de que falle un nodo, el clúster de caché sabe que los datos que pertenecen a la partición perdida todavía están disponibles en su réplica. Por lo tanto, las aplicaciones cliente continúan ejecutándose sin problemas, ya que el clúster sigue sirviendo los datos que pertenecen a la partición perdida a través de esta réplica.
Las aplicaciones cliente se comunican directamente solo con las particiones activas. Luego, cada partición es responsable de replicar sus datos en su réplica respectiva.
Aunque el grado de replicación en esta topología no es tanto como en la Topología replicada, tener al menos una copia de seguridad le garantiza que, en caso de falla de un nodo, sus datos aún estarán seguros. Siempre que no haya fallas simultáneas en los nodos, los datos en esta topología están seguros, lo que cubre la mayoría de los escenarios.
Cada nodo de clúster tiene un activo y una réplica, y existen instancias tanto activas como de réplica en el mismo proceso de caché en cada nodo de clúster.
Debido a la existencia de la instancia de réplica en cada nodo de caché, requiere el mismo tamaño de memoria que la instancia de caché activa. Esto significa que cada nodo de caché de Partición-Replica requiere el doble de memoria en comparación con su tamaño de caché configurado.
Todos los datos agregados del cliente se almacenan en el nodo activo, desde donde luego se replican en su réplica dedicada, que se encuentra en algún otro nodo del clúster. Esta disposición de nodos de réplica garantiza que los datos no se pierdan cuando un nodo activo deja de funcionar.
Estrategia de selección de réplicas
NCache selecciona automáticamente el nodo de réplica en función del orden en que los nodos se unen al clúster de caché. La réplica del primer nodo está presente en el nodo del servidor que se unió al clúster después del primer nodo, y así sucesivamente. Y, la réplica del último nodo se coloca en el primer nodo del servidor (servidor coordinador) del clúster de caché.
Todo este proceso de selección de réplicas es automático. Cada vez que un nodo de servidor abandona el clúster de caché o un nuevo nodo se une al clúster de caché, las réplicas también se reasignan de acuerdo con el mapa de membresía actualizado.
Consumo de memoria de un solo nodo
Cada nodo del servidor (activo y réplica) mantiene un registro del tamaño de caché configurado y garantiza que los datos almacenados nunca excedan el límite de memoria especificado. Hay dos escenarios especiales en los que esta verificación de límite de memoria funciona de manera diferente. Se explican a continuación:
- Solo un nodo está en estado de ejecución y se le están agregando datos. La instancia de caché activa puede utilizar el doble del tamaño de caché especificado para contener los datos, ya que su réplica no sirve de nada.
- En un clúster de varios nodos, cuando todos los demás nodos abandonan el clúster y solo un nodo permanece vivo, los datos de su instancia de caché de réplica se transfieren a la instancia de caché activa. La memoria caché activa luego consume la memoria libre de la réplica para acomodar los datos recibidos de la réplica.
Estrategias de replicación
La topología Réplica de partición tiene dos estrategias de replicación para replicar los datos del nodo del servidor activo al nodo de réplica:
Replicación asíncrona: En este modo, las colas en segundo plano se utilizan para replicar los datos sin bloquear las operaciones del cliente. Cada operación de escritura se pone en cola y los subprocesos en segundo plano dedicados seleccionan los datos de esta cola en fragmentos y los replican en la instancia de réplica. Esta estrategia de replicación es adecuada para aplicaciones que tienden a realizar escrituras frecuentes pero que no quieren esperar a que se completen las replicaciones antes de la siguiente operación de caché. Sin embargo, existe la posibilidad de que se pierdan datos si un nodo se abandona abruptamente. En este caso, se perderán las operaciones en cola que no se replicaron.
Replicación sincronizada: Con el modo de replicación síncrona, cada operación de escritura del cliente se replica en la réplica antes de devolver el control a la aplicación cliente. Este modo de replicación garantiza que tanto la instancia de caché activa como la de réplica tengan la misma copia de los datos del usuario. Si la replicación falla en la instancia de réplica, ese elemento se elimina de las instancias de caché activa y de réplica.
Comportamiento de la operación
Desalojos, vencimientos, dependencias, escribir a través/escribir detrás, etc. son controlados por el nodo activo. Cada vez que un nodo activo elimina un elemento de él en función de cualquiera de las características mencionadas, lo replica en su réplica para eliminar los datos almacenados previamente. Similarmente, escribir a través/escribir detrás las operaciones solo se realizan desde la memoria caché activa.
En la topología Partición-Réplica, los clientes están conectados directamente con cada nodo del servidor, pero solo con sus particiones/instancias activas. Sin embargo, hay algunas situaciones en las que los clientes interactúan temporalmente con las instancias de réplica a través de llamadas de clúster. Se explican a continuación:
- Durante la transferencia de estado, cuando un nodo abandona el clúster, las operaciones del cliente destinadas al nodo saliente se realizan desde su réplica.
- Cuando un clúster está en modo de mantenimiento, todas las operaciones destinadas al nodo en mantenimiento se realizan desde su réplica durante el período de mantenimiento.
Transferencia de estado
La transferencia de estado es un proceso para transferir/copiar automáticamente los datos entre los nodos de caché. La transferencia de estado se activa cuando un nuevo nodo se une al clúster o cualquier nodo actual abandona el clúster. Abandonar/unirse a un nodo también provoca un cambio de membresía en el clúster.
Cuando un nodo recibe la actualización mapa de distribucion, verifica la existencia de los depósitos (que le fueron asignados) en su entorno local. Los depósitos asignados que no existen en el entorno local del nodo se extraen uno por uno de otros nodos. Entonces, dependiendo de la cantidad de nodos de servidor en el clúster de caché, se transfieren varios depósitos durante la transferencia de estado.
La transferencia de estado se activa en los siguientes tres escenarios principales:
En unión de nodo
Cuando un nuevo nodo se une al clúster de caché, el servidor coordinador genera un nuevo mapa de distribución para distribuir los depósitos desde los nodos actuales al nodo recién unido. Y, después de recibir el mapa de distribución, el nodo recién incorporado extrae los cubos de los nodos actuales. Durante esta transferencia de estado, el nodo recién incorporado extrae un cubo a la vez. Después de recibir un depósito, extrae el siguiente depósito, y así sucesivamente, hasta que obtiene todos los depósitos asignados de otros nodos, de acuerdo con su mapa de distribución.
En licencia de nodo
De manera similar, la transferencia de estado se activa cuando un nodo de caché abandona el clúster de caché. El servidor coordinador redistributa sus cubos entre los nodos activos del clúster. En este caso, los nodos activos extraen los datos de la réplica del nodo saliente.
Note
Si más de un nodo abandona el clúster al mismo tiempo o uno tras otro mientras ya hay una transferencia de estado en curso, podría provocar la pérdida de datos.
Equilibrio automático de carga de datos
La topología Partition-Replica tiene una característica de Equilibrio automático de carga de datos en el que monitorea continuamente la distribución de datos entre los nodos del clúster. Y, si la distribución de datos no está dentro del rango de distribución esperado (60 % a 40 %), se activa automáticamente el equilibrio automático de carga de datos. En este caso, el servidor coordinador regenera un nuevo mapa de distribución y redistributa los cubos de tal manera que todos los nodos del clúster tendrán datos del mismo tamaño.
Note
También se puede realizar el equilibrio de carga de datos a mano del desplegable NCache Centro de Gestión.
Cualquiera que sea el motivo de la transferencia de estado, todo este proceso es automático y fluido. Y, durante la transferencia de estado, especialmente cuando un nodo servidor abandona el clúster de caché, todas las operaciones del cliente que estaban destinadas al nodo saliente se realizan desde su réplica a través de operaciones del clúster.
Las réplicas también realizan transferencias de estado desde sus nodos activos al igual que otros nodos activos. Las réplicas extraen sus depósitos asignados de sus nodos activos para recuperar la copia de los datos en el momento de la transferencia de estado. Sin embargo, esta transferencia de estado solo tiene lugar en la reasignación del depósito. De lo contrario, los datos se replican en las réplicas mediante el mecanismo de replicación.
Diferentes formas de monitorear la transferencia de estado
NCache proporciona múltiples formas de monitorear la transferencia de estado en el clúster de caché. Se explican a continuación:
- Registros de caché: cada vez que se activa y detiene la transferencia de estado, se registra en los registros de caché del clúster. Los registros de caché existen bajo el %NCHOME%/bin/registro carpeta.
- Contadores personalizados: NCache también publica contadores personalizados que se pueden ver en Windows y Linux.
- Contadores basados en Perfmon: En Windows, NCache también publica los contadores de transferencias de estado a través de la herramienta Windows Perfmon.
- Registros de eventos de Windows: La información y los eventos relacionados con la transferencia de estado también se publican en los registros de eventos de Windows.
- Alertas de correo electrónico: Se pueden configurar alertas por correo electrónico específicas de transferencias de estado en su inicio y detención.
Conectividad del cliente
Como se explica en el particionamiento, los datos se distribuyen entre todos los servidores del clúster. A diferencia de otras topologías, el cliente para topologías con particiones necesita conectarse con todas las particiones, donde cada partición contiene un subconjunto de los datos totales.
El cliente recibe un mapa de distribución en la llamada de conexión, que informa al cliente sobre los nodos del servidor en ejecución y su distribuciones basadas en hash. El cliente se conecta a todos los nodos del servidor para obtener datos completos del caché. El cliente obtiene un mapa actualizado en cada cambio de membresía del clúster para mantener la conectividad. El cliente también recibe una notificación sobre la salida/reunión de un miembro y restablece la conectividad de acuerdo con la información recibida. mapa.
El cliente realiza de forma inteligente las operaciones de lectura/escritura directamente en el nodo del servidor que contiene la clave de acuerdo con el mapa de distribución basado en hash recibe Para todas las operaciones en las que no se conoce la clave, como búsqueda SQL, Obtener por etiquetas, etc., el cliente transmite la solicitud a todos los nodos del servidor y combina sus respectivas respuestas.
Si, en cualquier caso, el cliente no puede conectarse a ningún nodo de servidor del clúster, no significa que no pueda escribir y recuperar información de ese nodo de servidor. Para ello, utiliza los otros nodos del servidor a los que está conectado, que en su nombre solicita el nodo del servidor inalcanzable para realizar operaciones. Por ejemplo, si el cliente no puede conectarse con el nodo 1 y quiere obtener una clave que reside en el nodo 1, envía la solicitud al nodo 2, que se redirige al nodo 1 y devuelve la respuesta.
Modo de mantenimiento
Cuando se requiere parchear o actualizar hardware/software en un NCache servidor, es posible que no encuentre tiempo de inactividad de la aplicación. Sin embargo, detener un nodo de caché activa transferencia de estado dentro de todo el clúster de caché, lo que resulta en un uso excesivo de recursos como la red, la CPU y la memoria. Este transferencia de estado El proceso puede ser costoso dependiendo del tamaño de los datos de la caché y del clúster. Un flujo de trabajo típico de actualización implica reiniciar el nodo de caché a la vez, lo que requiere dos transferencias de estado, una al salir del nodo y la otra al unirse al nodo.
Modo de mantenimiento se introduce para evitar estas costosas transferencias de estado durante el mantenimiento de los servidores de caché. Una vez que un servidor de caché se detiene por mantenimiento durante un tiempo específico, la réplica del nodo en mantenimiento se activa temporalmente y comienza a atender las solicitudes de los clientes. Cuando el nodo (que estaba en mantenimiento) se reincorpora después de que su mantenimiento haya concluido dentro del tiempo especificado, el transferencia de estado se inicia para que este nodo lo sincronice con el clúster de caché.
El cluster sale del modo de mantenimiento en tres estados diferentes. Si el nodo de mantenimiento se une al clúster de caché dentro del tiempo especificado, transferencia de estado se inicia para sincronizar el estado del clúster y el clúster sale del modo de mantenimiento. Si el nodo de mantenimiento no puede volver a unirse al clúster de caché dentro del tiempo especificado, el clúster considera que el nodo está inactivo y sale del modo de mantenimiento, genera una nueva mapay comienza el transferencia de estado. Aparte del éxito y el fracaso, hay otra anomalía que sale del modo de mantenimiento, es decir, cuando un nodo sale. Si el cluster está en el modo de mantenimiento y cualquier nodo que no sea el nodo de mantenimiento sale, el clúster sale del modo de mantenimientoy puede conducir a la pérdida de datos.
Recuperación de cerebro dividido
El término Cerebro dividido hace referencia a un estado en el que un clúster de caché se divide en varios subclústeres. Los servidores de caché en un clúster se comunican a través de TCP. Por lo tanto, cualquier falla o problema en la red puede causar una pérdida de comunicación entre los servidores presentes en un clúster. Si la pérdida de comunicación entre los servidores se extiende más allá de un tiempo determinado, el mapa de miembros cambiará según la conectividad entre los servidores. Esto da como resultado la formación de múltiples subgrupos. Estos subgrupos se denominan divisiones. lo llamamos cerebro dividido ya que los subgrupos no pueden comunicarse entre sí, de manera similar a cómo las mitades del cerebro no pueden comunicarse entre sí en el síndrome de cerebro dividido.
Todos los subclústeres están en buen estado y procesan los datos que contienen. Además, los clientes pueden conectarse a estos subgrupos para realizar más operaciones de lectura/escritura. El cliente recibe un mapa de membresía de los servidores del clúster para actualizar la conectividad. Aquí, el cliente puede conectarse a cualquier subclúster según el primer mapa recibido.
Cerebro dividido se detecta solo cuando se reanuda la comunicación entre los servidores y se descubre que todos los servidores están en funcionamiento pero no forman parte de un único clúster. Son posibles dos o más divisiones dependiendo de la pérdida de comunicación entre los servidores. Una vez cerebro dividido se detecta, se inicia el proceso de recuperación. Todas las divisiones se recuperan una por una hasta que todos los subgrupos se fusionan.
El cerebro dividido El proceso de recuperación se inicia inmediatamente después de su detección. Se necesitan dos divisiones saludables, identifica sus servidores coordinadores, decide la división ganadora y perdedora según el tamaño del clúster, adquiere un bloqueo en la división perdedora para restringir la actividad del cliente en ese clúster y cambia la membresía del clúster. Después de esto, todos los clientes son redirigidos a la división del clúster ganador y todos los nodos de la división perdedora se reinician uno por uno para unirse al clúster ganador. Todas las divisiones perdedoras se fusionan con la división del grupo ganador de la misma manera y el grupo vuelve a estar sano.
Se espera pérdida de datos en cerebro dividido recuperación a medida que el clúster se divide en múltiples subclústeres, la pérdida de datos ocurre porque varios nodos en un clúster se van simultáneamente. Los subgrupos pueden atender las solicitudes de los clientes en un estado de cerebro dividido, estas operaciones pueden perderse si la división a la que está conectado el cliente es una división perdedora que se reinicia para unirse al clúster principal.
Vea también
Topología replicada
Topología duplicada
Clúster de caché
Caché local