Cache distribuita con persistenza
NCache fornisce una cache distribuita chiave-valore, con un archivio di persistenza in memoria, per recuperare in modo affidabile dati preziosi come richiesto. Mantiene una copia dei dati della cache nell'archivio di persistenza e successivamente carica i dati persistenti al riavvio della cache (pianificato o non pianificato). Memorizza e carica tutti i dati che i server della cache possono contenere. La persistenza garantisce un'elevata disponibilità dei dati e, contemporaneamente, i dati in memoria forniscono prestazioni elevate. In questo documento, una cache distribuita con persistenza è chiamata anche cache persistente.
Note:
Supporta solo la cache distribuita con persistenza Topologie partizionate ed Cache locali (OutProc)..
È possibile creare una cache distribuita con persistenza utilizzando a NoSQL Archivio documenti come archivio di persistenza per il backup dei dati. La cache persisterà tutte le API di scrittura, meta-informazioni, flussi, strutture di datie indici dinamici al negozio di backend.
Note:
I messaggi Pub/Sub non sono persistenti, ma NCache supporta API Pub/Sub e ti consente di creare un apposito Cache di messaggistica Pub/Sub.
Tieni presente che i dati rimossi dalla cache a causa di qualsiasi annullamento o rimozione esplicita dei dati verranno rimossi anche dall'archivio di persistenza sottostante. È supportata l'aggiunta di elementi con scadenza e dipendenza dalla chiave. Tuttavia, non consigliamo questo approccio poiché i dati archiviati all'interno di una tale cache persistente sono dati permanenti. Nel frattempo, i dati con dipendenza dal database e la dipendenza da fonti esterne non è destinata a persistere.
Note:
Analogamente a una cache distribuita volatile, un'origine di backup è supportata per una cache distribuita con persistenza.
Perché persistere i dati
NCache memorizza i dati nella RAM per un accesso più rapido. Poiché la memoria cache è volatile, la perdita di dati è inevitabile nei seguenti scenari:
- Nodo in basso nella topologia partizionata.
- Più di un nodo inattivo contemporaneamente nella topologia Partition-Replica.
- Disattivare il cluster per motivi di manutenzione o per un guasto irreversibile.
Con una cache persistente, puoi ottenere quanto segue:
Alta disponibilità dei dati: In caso di errore di memoria dovuto a uno dei motivi menzionati in precedenza, NCache recupera rapidamente i dati caricandoli dall'archivio di persistenza sottostante. La cache diventa operativa senza influire sulle operazioni del client anche dopo un errore catastrofico.
Tolleranza di errore: Il mantenimento di una copia in tempo reale dei dati della cache riduce al minimo i tempi di inattività e fornisce tolleranza agli errori quando uno o più nodi lasciano il cluster.
Consigli
Per la persistenza, la lunghezza della chiave non deve superare i 1023 byte.
Come Funziona?
Qui descriviamo il funzionamento e il comportamento di una cache distribuita con persistenza. Il diagramma seguente mostra l'architettura di base. Puoi creare una cache distribuita con persistenza con un archivio di persistenza nel back-end. Il negozio è centralizzato e accessibile a tutti i nodi. NCache scrive i dati aggiunti alla cache nell'archivio back-end a intervalli di tempo gestibili. Al riavvio della cache o all'uscita/aggiunta del nodo, i dati persistenti vengono caricati nella memoria tanto quanto i server della cache possono contenere.
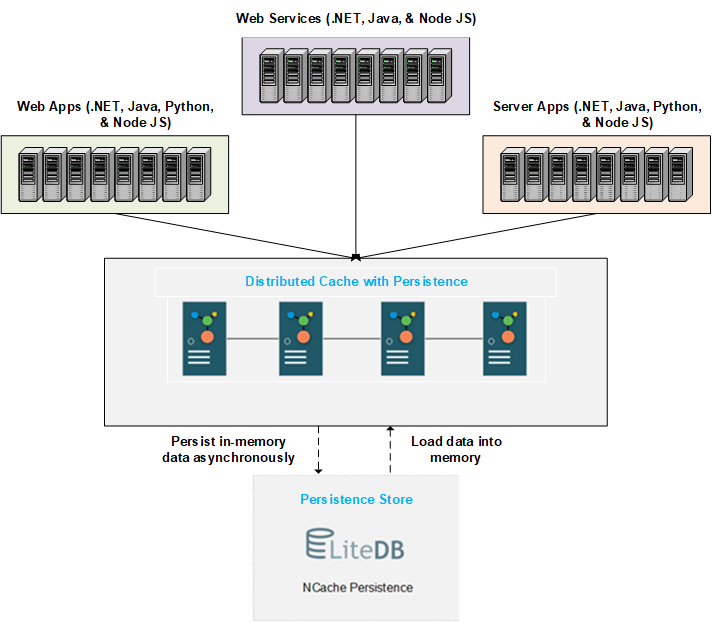
Discutiamo il processo dettagliato di persistenza e caricamento dei dati di seguito.
Persistenza dei dati
Dopo aver creato una cache distribuita con persistenza, tutte le operazioni di scrittura vengono prima eseguite in memoria e quindi rese persistenti nell'archivio back-end. Da NCache ha un'architettura distribuita, ogni nodo del server mantiene i propri dati mentre tutti i nodi del server possono accedere allo store. Inoltre, poiché la distribuzione dei dati è basata su bucket a causa delle partizioni, anche i dati vengono persistenti.
Persistenza asincrona
NCache mantiene i dati in memoria nell'archivio di persistenza tramite la persistenza asincrona. Qui spieghiamo come funziona. Ogni partizione dispone di una coda di persistenza per registrare le operazioni client eseguite. Qualsiasi operazione di scrittura eseguita dal client viene accodata una volta completata con successo. Poiché la persistenza funziona in modo asincrono, il client non attende dopo aver accodato l'operazione. Le operazioni in coda vengono controllate periodicamente in modo configurabile persistence-interval e infine replicato nell'archivio back-end da un thread di persistenza. Ogni coda viene scritta in modo indipendente.
Note:
Il valore predefinito di persistence-interval is 1 secondi ed è configurabile in NCache Centro di gestione.
Normalmente, il lotto viene applicato dopo persistence-interval, ma se il batch di persistenza ha esito negativo consecutivamente, dopo persistence-retries l'intervallo batch viene spostato su persistence-interval-longer. Una volta che ha esito positivo, l'intervallo batch verrà reimpostato su persistence-interval.
Consigli
Le prestazioni della cache non diminuiscono poiché le operazioni del client si verificano normalmente a causa della replica asincrona.
Se la cache non può persistere i dati all'interno della coda di persistenza a causa di qualsiasi problema, continuerà ad eseguire operazioni di scrittura finché non sarà piena. Se le operazioni in coda non persistono, le informazioni sui bucket non riusciti vengono registrate nei log della cache.
Note:
La topologia Partition-Replica viene ripristinata in caso di errore della coda tramite la coda della replica. Tuttavia, la perdita di dati è inevitabile se un nodo e la sua replica sono inattivi contemporaneamente.
Caricamento dei dati
Una volta che i dati sono nell'archivio, la cache ricarica automaticamente i dati persistenti nella RAM al riavvio della cache. L'archivio persistente deve essere sempre disponibile per memorizzare nella cache i nodi. Se non possono accedere al negozio, la cache non si avvierà. Il caricamento dei dati avviene in modo distribuito. Poiché l'archiviazione dei dati è una procedura basata su bucket, ciascun nodo può accedere all'archivio centralizzato per caricare i propri bucket assegnati in base alla mappa di distribuzione dei dati. Inoltre, se sono stati configurati indici per interrogare i dati nella cache, gli indici di query si rigenerano al riavvio della cache.
Consigli
L'archivio di persistenza deve essere sempre disponibile per tutti i nodi della cache.
Comportamento operativo durante il caricamento dei dati
I processi di caricamento e persistenza dei dati vengono eseguiti simultaneamente. Nel frattempo, i recuperi basati su chiave vengono serviti dalla cache se i dati richiesti vengono caricati. Se non è nella cache, tali operazioni vengono servite direttamente dallo store tramite caricamento lento. In tal caso, l'esecuzione del Get l'operazione ne risentirà.
Si noti che le operazioni di ricerca non basate su chiavi o basate su criteri, ad esempio GetGroupKeys, GetKeysByTage le query SQL non verranno servite fino a quando i dati non verranno caricati completamente dall'archivio nella memoria.
avvertimento
Se si verifica un'operazione di ricerca non basata su chiave durante il caricamento dei dati e i dati richiesti non vengono caricati completamente, l'applicazione genererà un'eccezione che indica dati non completamente caricati dall'archivio di persistenza.
Scenari di caricamento dei dati
I dati vengono caricati dall'archivio di persistenza nei seguenti scenari:
All'avvio della cache: All'avvio della cache, il nodo coordinatore carica tutti i bucket. Non appena altri nodi si uniscono al cluster, la distribuzione del bucket viene aggiornata. Ogni nodo cerca i bucket assegnati nell'ambiente locale. I bucket caricati nella cache vengono sottoposti a pull through trasferimento statale. Se i bucket assegnati a un nodo non vengono caricati completamente, tali bucket vengono caricati direttamente dallo store da quel nodo. Ogni nodo può accedere allo store per caricare i propri bucket assegnati se presenti nella cache.
Quando una cache distribuita con persistenza viene avviata per la prima volta, può essere popolata configurando Caricatore di avvio della cache poiché l'archivio di persistenza non ha dati in quel momento. Una volta popolato l'archivio, i dati vengono sempre caricati dall'archivio all'avvio della cache, anche se è stato configurato il Cache Loader. Tuttavia, se è necessario aggiungere periodicamente più dati, è possibile utilizzare Aggiornamento della cache. L'aggiornamento della cache viene eseguito a intervalli periodici indipendentemente dal fatto che la cache e l'archivio dispongano già dei dati.
Su Nodo Join: Quando un nuovo nodo si unisce al cluster, ottiene i bucket assegnati dai nodi del cluster esistenti tramite trasferimento di stato se sono già stati caricati. Se i bucket assegnati non vengono caricati completamente nella cache, vengono caricati dallo store dal nuovo nodo.
In congedo nodo: I dati vengono caricati dall'archivio per evitare la perdita di dati quando uno o più nodi lasciano il cluster. Il comportamento di caricamento all'uscita del nodo varia per le diverse topologie.
Topologia partizionata: Quando un nodo esce, i suoi bucket vengono distribuiti tra i nodi del cluster esistenti e caricati dall'archivio di persistenza dai nuovi proprietari.
Topologia di replica delle partizioni: Partition-Replica tollera il guasto del nodo fino a un livello recuperando i bucket persi tramite il trasferimento dello stato dalla replica. Tuttavia, quando un nodo e la sua replica sono inattivi contemporaneamente, i dati persi sono ancora recuperabili dall'archivio di backup.
Consigli
La cache dovrebbe avere la capacità di ospitare i dati in caso di nodo inattivo/abbandonato.
Gestione della capacità per una cache distribuita con persistenza
Una cache persistente può riprendersi dalla perdita di dati in caso di abbandono o inattività del nodo solo quando la cache dispone di un margine sufficiente per accogliere i dati del nodo o dei nodi abbandonati. Se la cache non può contenere tutti i dati nell'archivio di persistenza perché è piena o per qualsiasi altro motivo, le operazioni di aggiunta o aggiornamento inizieranno a fallire. Nel frattempo, alcuni bucket non disporranno di dati completi. Questi bucket incompleti vengono ricaricati dal negozio in due casi:
- Un nuovo nodo si unisce al cluster.
- La dimensione della cache aumenta tramite l'applicazione a caldo.
Note:
Se una cache è piena ma sincronizzata al 100% con l'archivio di persistenza, vengono bloccate solo le nuove aggiunte. Tutte le altre operazioni possono avvenire sulla cache senza problemi.
Quando la cache è piena con dati parziali in memoria, la cache potrebbe non servire operazioni non basate su chiavi o basate su criteri (come GetGroupKeys, GetKeysByTage query SQL). D'altra parte, i recuperi basati su chiave verranno sempre serviti tramite la cache o tramite lo store. In particolare, la cache tenterà di eseguire il lazy-load di tutti i get basati su chiave per i bucket incompleti in caso di cache miss.
avvertimento
Se un'operazione di ricerca basata su criteri viene eseguita con la cache piena e i dati richiesti non sono nella cache, verrà generata un'eccezione L'operazione non può essere eseguita perché la cache non ha tutti i dati in memoria.
Pianificazione della capacità per la cache piena
Per evitare i problemi sollevati dalla cache piena, è necessario pianificare la capacità della cache persistente prima di iniziare a utilizzarla. Quando si esegue la pianificazione della capacità per una cache distribuita con persistenza, si consiglia di pianificare la dimensione della cache per nodo in modo che, se un nodo si interrompe, i nodi rimanenti possano contenere tutti i dati del nodo perso.
Espansione della dimensione della cache sulla cache piena
Consigli
NCache tenta di garantire un'elevata disponibilità dei dati in uscita da un singolo nodo in una cache distribuita basata su Partition-Replica con persistenza attraverso l'espansione delle dimensioni. Tuttavia, un’elevata disponibilità dei dati non è promessa né garantita.
Nel caso di Partition-Replica, se un nodo lascia un cluster, i restanti nodi del cluster ospitano i dati di proprietà del nodo uscente. Tuttavia, esiste la possibilità che i dati in uscita dal nodo non abbiano spazio a causa di problemi di dimensionamento. NCache supporta l'espansione automatica della dimensione della cache quando un nodo lascia la cache distribuita basata su Partition-Replica con persistenza. La modalità di espansione è supportata solo per un singolo nodo inattivo. Lo scopo è evitare dati parziali nella cache e servire le operazioni basate su criteri sulla cache completa.
Il processo di espansione avviene internamente. La modalità di espansione si attiva quando un singolo nodo lascia il cluster mentre i nodi in esecuzione sono uguali o maggiori dei nodi configurati. La dimensione espansa viene calcolata in base ai nodi configurati o ai nodi in esecuzione nel cluster (qualunque sia il più alto). Quando la cache è in modalità espansa, ogni nodo nel cluster aumenta automaticamente le proprie dimensioni per accogliere i dati ricevuti tramite il trasferimento di stato all'uscita dal nodo.
Consigli
L'espansione si verifica solo quando il numero di nodi rimanenti (dopo il nodo inattivo) è max di {nodi configurati/nodi in esecuzione}-1. La dimensione espansa viene calcolata in base ai nodi configurati o ai nodi in esecuzione nel cluster (a seconda di quale sia il valore maggiore).
Nella modalità espansa, vengono servite sia operazioni basate su chiavi che basate su criteri. Tuttavia, bloccherà comunque le operazioni di aggiunta se la dimensione della cache ha superato una volta la dimensione della cache configurata.
La cache esce dalla modalità espansa quando un nuovo nodo si unisce al cluster o le dimensioni della cache aumentano tramite hot apply. Quindi la mappa di distribuzione viene aggiornata e viene attivato il trasferimento di stato. Una volta completato il trasferimento dello stato, ogni nodo esce dalla modalità espansa e la dimensione della cache si riduce alla dimensione della cache configurata.
Note:
Viene registrata una voce sia nei registri della cache che nei registri eventi quando la cache entra ed esiste in modalità espansa.
Comportamenti di inaccessibilità
I dati vengono caricati dall'archivio di persistenza all'avvio della cache, quindi l'archivio deve essere disponibile per memorizzare nella cache i nodi in modo coerente. Qui, discutiamo i comportamenti quando l'archivio di persistenza è inaccessibile;
- Al momento della creazione della cache: La connessione allo store viene verificata al momento della creazione della cache. Se è inaccessibile, non sarai in grado di creare la cache e riceverai una notifica di errore. Analogamente, una cache non verrà avviata se l'archivio non è disponibile per alcun nodo del cluster.
avvertimento
La cache non si avvierà finché l'archivio di persistenza non sarà accessibile a tutti i nodi del server al momento della creazione della cache.
Al momento del caricamento dei dati: L'archivio potrebbe diventare inaccessibile durante il caricamento dei dati a causa di un errore di rete. In tal caso, la cache riproverà a caricare i restanti bucket di dati nello stato di caricamento. Nel frattempo, le operazioni di ricerca non basate su chiavi falliranno. Puoi configurare i tentativi di caricamento dei dati nel file di configurazione del servizio.
Al momento dell'esecuzione della cache: L'archivio può diventare inaccessibile per una cache in esecuzione a causa di un errore di rete per un breve periodo o per un tempo infinito. In caso di tale perdita di connessione, la cache continuerà ad accettare e ad accodare le operazioni di scrittura. Nel frattempo, NCache continuerà a provare a rendere persistenti le operazioni in coda a intervalli batch finché non viene ristabilita la connessione all'archivio di persistenza.
Se si perde la connessione all'infinito, le operazioni di scrittura si verificano fino a quando la memoria cache non è piena. Una volta che la cache è piena, le successive operazioni di scrittura falliranno. Tuttavia, le operazioni di recupero basate su chiave verranno servite come discusso in precedenza.
Creazione e monitoraggio della cache persistente
Note:
Solo la cache serializzata JSON è supportata per una cache distribuita con persistenza.
Puoi creare una cache distribuita con persistenza specificando un nuovo negozio o uno esistente (creato utilizzando NCache) o attraverso il NCache Centro di gestione o attraverso Strumento PowerShell.
NCache fornisce diverso contatori di prestazioni per monitorare le statistiche di una cache distribuita con persistenza. Inoltre, puoi monitorare una cache distribuita con persistenza tramite la NCache Strumento Monitor, PowerShell e PerfMon.
Vedere anche
Crea una cache distribuita con persistenza
Guida introduttiva alla cache distribuita con persistenza