Partition-Replica & Partition Cache Topologies
In un cluster, se tutti i nodi del server hanno la stessa copia dei dati, si ottiene un'elevata disponibilità di tali dati. Ciò significa che il cluster può sopravvivere ad alcuni guasti dei nodi senza subire alcuna perdita di dati. Tuttavia, questo non ti dà scalabilità. Quando i dati iniziano a crescere enormemente, il progetto deve ridurre l'entità della replica e iniziare a partizionare i dati.
Il partizionamento significa che è necessario distribuire i dati tra più nodi in modo che sia distribuito il caricamento dei dati in lettura e in scrittura. Man mano che i tuoi dati crescono, puoi aggiungere più nodi server nel cluster per contenere più dati. Ogni nodo del server in un cluster è chiamato partizione.
Con il partizionamento dei dati è possibile ottenere la scalabilità, ma ora la domanda è: come vengono partizionati i dati? Una soluzione semplice potrebbe essere quella di assegnare i dati a una partizione in modo round-robin, ma come troveremo un particolare dato una volta aggiunto allo store?
Attraverso il round robin perderemo la capacità di tracciare la posizione dei dati. Abbiamo bisogno di un modo migliore di distribuire i dati, garantendo non solo l’equa distribuzione dei dati ma anche la possibilità di consultarli rapidamente.
Note:
È supportata anche la topologia partizionata NCache Professional.
Note:
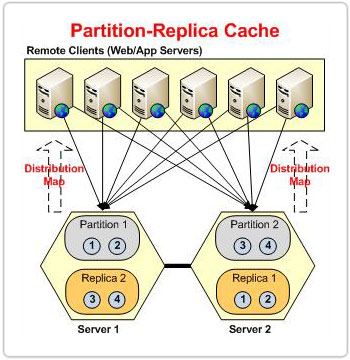
L'unica differenza tra le topologie Partitioned e Partition-Replica è che la prima non dispone di cache di replica, il che la rende soggetta alla perdita di dati.
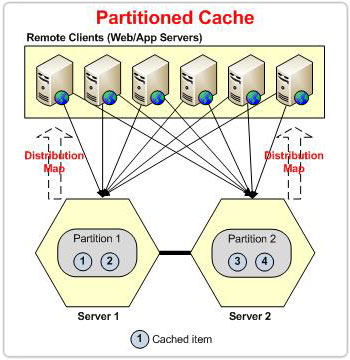
Hash-Based Data Partitioning for Partition Caches
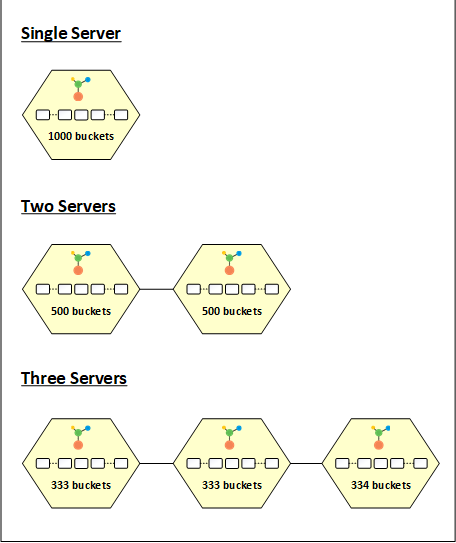
NCache divide i dati in più blocchi e inserisce questi blocchi in partizioni diverse. Questi pezzi sono chiamati bucket. Sono presenti un totale di 1000 bucket divisi equamente tra i nodi del cluster. L'idea qui è quella di applicare una funzione hash sulla chiave dell'elemento e modellarla in base al numero di bucket totali (1000 in questo caso) per ottenere un bucket proprietario per questi dati.
Mappa di distribuzione
Il server coordinatore nel cluster ha la responsabilità di generare una mappa che contiene la distribuzione del bucket. Questa mappa è chiamata mappa di distribuzione. Il server coordinatore condivide questa mappa di distribuzione con il resto delle partizioni nel cluster e con i client connessi. Questo metodo fornisce sempre lo stesso indirizzo bucket per un elemento, indipendentemente dal numero di server nel cluster. Anche se il contenitore può spostarsi da una partizione all'altra in qualsiasi momento, il contenitore di un articolo non può mai cambiare. Ciò significa che quando un bucket si sposta, porta con sé tutti i suoi dati.
Distribuzione dei dati secondo la mappa di distribuzione
Quando avvii un cluster di cache con una singola partizione, tutti i 1000 bucket vengono assegnati a questo nodo. Ciò significa che tutti i dati vanno a questa partizione. Quando avvii un altro nodo nel cluster, i bucket vengono equamente distribuiti tra le due partizioni con 500 bucket ciascuna. Allo stesso modo, con l'aggiunta di un terzo nodo al cluster, i bucket sono di nuovo redistributato. In questo caso, i tre nodi avranno rispettivamente 333, 333 e 334 bucket.
Allo stesso modo, quando una partizione lascia il cluster, la distribuzione del bucket cambia. Ad esempio, quando una partizione lascia un cluster a tre nodi, i bucket 333 o 334 di proprietà di quella partizione vengono redistributato tra i restanti due nodi. Ogni volta che si verifica un cambiamento nella distribuzione, si attiva un trasferimento di stato per riequilibrare i dati tra i nodi, secondo la distribuzione del bucket.
Distribuzione casuale dei dati
Questo metodo di partizionamento offre una discreta quantità di casualità per garantire che i dati siano suddivisi equamente tra bucket e partizioni. Tuttavia, con questo metodo di partizionamento, si perde il controllo su quali dati assegnare a quale partizione. Per lo più, non ti importerebbe dove vanno i tuoi dati. Ma, in alcuni casi, potresti voler co-localizzare i dati correlati. Per questo, puoi utilizzare Affinità di posizione, dove una funzione hash viene applicata su una parte della chiave anziché sull'intera chiave.
Distribuzione equilibrata dei dati
Ogni volta che ci sono i secchi redistributato tra i nodi, NCache assicura che i secchi siano redistributato in modo tale che la dimensione dei dati ricevuti da ciascuna partizione sia quasi la stessa. Ogni partizione condivide le statistiche dei bucket di sua proprietà, a intervalli configurabili, con le altre partizioni nel cluster. Ciò aiuta a generare una mappa di distribuzione equilibrata quando necessario, il che è giusto in termini di dati ottenuti da ciascuna partizione. Il bilanciamento si basa sulla dimensione dei dati anziché sul numero di elementi. Questo bilanciamento viene solitamente assicurato al momento del bucket redistribuzione come risultato dell'uscita o dell'unione di un nodo.
Bilanciamento automatico e manuale del carico dei dati
Tuttavia, esiste una leggera possibilità che una o più partizioni in un cluster siano inclinate e ricevano più carico rispetto alle altre. In questo caso, hai un'opzione per bilanciare manualmente i dati di un particolare nodo che garantisce che i dati su quel nodo siano uguali alla dimensione media dei dati che riceve ciascuna partizione. Poi c'è anche una funzione chiamata 'Auto Data Load Balancing' che fa il lavoro automaticamente in background. Questa funzione è disabilitata per impostazione predefinita perché, se utilizzata senza cautela, può causare frequenti bucket redistribuzione e, quindi, trasferimenti di stato indesiderati tra le partizioni.
Dimensione dei dati per partizione
La dimensione dei dati che ciascuna partizione può contenere è uguale alla dimensione della cache configurata. Ad esempio, se la dimensione della cache configurata è 2 GB e la dimensione del cluster è di tre partizioni, la quantità totale di dimensione della cache su questo cluster sarà 6 GB.
Quindi, con questa topologia, non stai solo distribuendo il carico di lettura e scrittura tra i server, ma stai anche aumentando la capacità con ogni nuovo server aggiunto al cluster.
Partizione-Replica
Ora che abbiamo spiegato come la topologia Partition-Replica ridimensiona il carico delle transazioni e la capacità di archiviazione. Parliamo di come gestisce l'alta disponibilità. Ciascun nodo del cluster dispone di un backup di un'altra partizione che funge da partizione passiva denominata replica. In caso di errore del nodo, il cluster di cache sa che i dati di proprietà della partizione persa sono ancora disponibili nella sua replica. Pertanto, le applicazioni client continuano a funzionare senza problemi poiché i dati di proprietà della partizione persa sono ancora serviti dal cluster tramite questa replica.
Le applicazioni client comunicano direttamente solo con le partizioni attive. Ogni partizione è quindi responsabile della replica dei propri dati nella rispettiva replica.
Anche se il grado di replica in questa topologia non è tanto quanto in Topologia replicata, avere almeno un backup ti garantisce che, in caso di guasto del nodo, i tuoi dati siano ancora al sicuro. Finché non si verificano guasti simultanei dei nodi, i dati in questa topologia sono sicuri, il che copre la maggior parte degli scenari.
Ogni nodo del cluster ha un attivo e una replica e nello stesso processo di cache su ogni nodo del cluster esistono istanze sia attive che di replica.
A causa dell'esistenza dell'istanza di replica su ogni nodo della cache, richiede la stessa dimensione di memoria di quella dell'istanza della cache attiva. Ciò significa che ogni nodo della cache Partition-Replica richiede memoria doppia rispetto alla dimensione della cache configurata.
Tutti i dati aggiunti del client vengono archiviati nel nodo attivo, da dove vengono quindi replicati nella sua replica dedicata, che si trova su un altro nodo del cluster. Questa disposizione dei nodi di replica garantisce che i dati non vadano persi quando un nodo attivo si interrompe.
Strategia di selezione delle repliche
NCache seleziona automaticamente il nodo di replica in base all'ordine in cui i nodi si uniscono al cluster di cache. La replica del primo nodo è presente sul nodo server che è entrato a far parte del cluster dopo il primo nodo e così via. Inoltre, la replica dell'ultimo nodo viene posizionata sul primo nodo server (server coordinatore) del cluster di cache.
L'intero processo di selezione delle repliche è automatico. Ogni volta che un nodo del server lascia il cluster di cache o un nuovo nodo si unisce al cluster di cache, anche le repliche vengono riassegnate in base alla mappa di appartenenza aggiornata.
Consumo di memoria a nodo singolo
Ciascun nodo del server (attivo e di replica) conserva un record della dimensione della cache configurata e garantisce che i dati archiviati non superino mai il limite di memoria specificato. Esistono due scenari speciali in cui questo controllo del limite di memoria funziona in modo diverso. Sono spiegati di seguito:
- Solo un nodo è in stato di esecuzione e i dati vengono aggiunti ad esso. L'istanza della cache attiva può utilizzare il doppio della dimensione della cache specificata per conservare i dati poiché la sua replica non è utile.
- In un cluster multinodo, quando tutti gli altri nodi lasciano il cluster e solo un nodo rimane attivo, i dati dalla relativa istanza della cache di replica vengono trasferiti all'istanza della cache attiva. La memoria libera dalla replica viene quindi utilizzata dalla cache attiva per ospitare i dati ricevuti dalla replica.
Strategie di replica
La topologia Partition-Replica ha due strategie di replica per replicare i dati dal nodo server attivo al nodo di replica:
Replica asincrona: In questa modalità, le code in background vengono utilizzate per replicare i dati senza bloccare le operazioni del client. Ogni operazione di scrittura viene accodata e thread in background dedicati prelevano i dati da questa coda in blocchi e li replicano nell'istanza di replica. Questa strategia di replica è adatta all'applicazione che tende a eseguire scritture frequenti ma non vuole attendere il completamento delle repliche prima della successiva operazione di cache. Tuttavia, esiste la possibilità di perdita di dati se un nodo abbandona improvvisamente. In questo caso, le operazioni in coda che non sono state replicate andranno perse.
Sincronizza replica: Con la modalità di replica sincrona, ogni operazione di scrittura dal client viene replicata nella replica prima di restituire il controllo all'applicazione client. Questa modalità di replica garantisce che le istanze della cache di replica e attiva abbiano la stessa copia dei dati dell'utente. Se la replica non riesce sull'istanza di replica, l'elemento viene rimosso dalle istanze attive e della cache di replica.
Comportamento operativo
Sfratti, Scadenze, dipendenze, writeThru/writeBehind, ecc sono controllati dal nodo attivo. Ogni volta che un nodo attivo rimuove un elemento da esso sulla base di una qualsiasi delle funzionalità menzionate, lo replica nella sua replica per rimuovere da esso i dati precedentemente archiviati. Allo stesso modo, writeThru/writeBehind le operazioni vengono eseguite solo dalla cache attiva.
Nella topologia Partition-Replica, i client sono direttamente connessi a ciascun nodo del server, ma solo alle sue partizioni/istanze attive. Tuttavia, esistono alcune situazioni in cui i client interagiscono temporaneamente con le istanze di replica tramite chiamate cluster. Sono spiegati di seguito:
- Durante il trasferimento di stato, quando un nodo lascia il cluster, le operazioni client destinate al nodo uscente vengono servite dalla sua replica.
- Quando un cluster è in modalità di manutenzione, tutte le operazioni destinate al nodo in manutenzione vengono servite dalla sua replica durante il periodo di manutenzione.
Trasferimento di Stato
Il trasferimento di stato è un processo per trasferire/copiare automaticamente i dati tra i nodi della cache. Il trasferimento di stato viene attivato quando un nuovo nodo si unisce al cluster o qualsiasi nodo corrente lascia il cluster. Node leave/join provoca anche la modifica dell'appartenenza al cluster.
Quando un nodo riceve l'aggiornamento mappa di distribuzione, verifica l'esistenza dei bucket (che gli sono stati assegnati) nel suo ambiente locale. I bucket assegnati che non esistono nell'ambiente locale del nodo vengono estratti uno per uno da altri nodi. Pertanto, a seconda del numero di nodi server nel cluster di cache, vengono trasferiti più bucket durante il trasferimento dello stato.
Il trasferimento statale viene attivato nei seguenti tre scenari principali:
Su Nodo Join
Quando un nuovo nodo si unisce al cluster di cache, il server coordinatore genera una nuova mappa di distribuzione per distribuire i bucket dai nodi correnti al nodo appena unito. E, dopo aver ricevuto la mappa di distribuzione, il nodo appena unito estrae i bucket dai nodi correnti. Durante questo trasferimento di stato, il nodo appena unito estrae un bucket alla volta. Dopo aver ricevuto un bucket, estrae il bucket successivo e così via, finché non recupera tutti i bucket assegnati dagli altri nodi, in base alla sua mappa di distribuzione.
In Congedo Nodo
Allo stesso modo, il trasferimento di stato viene attivato quando un nodo cache lascia il cluster di cache. Il server coordinatore redistributa i suoi bucket tra i nodi attivi del cluster. In questo caso, i nodi attivi estraggono i dati dalla replica del nodo uscente.
Note:
Se più di un nodo lascia il cluster contemporaneamente o uno dopo l'altro mentre è già in corso un trasferimento di stato, potrebbe causare la perdita di dati
Sul bilanciamento automatico del carico dati
La topologia Partition-Replica ha una caratteristica di Bilanciamento automatico del carico dati in cui monitora continuamente la distribuzione dei dati tra i nodi del cluster. Inoltre, se la distribuzione dei dati non rientra nell'intervallo di distribuzione previsto (dal 60% al 40%), si attiva automaticamente il bilanciamento automatico del carico dei dati. In questo caso, il server coordinatore rigenera una nuova mappa di distribuzione e redistributa i bucket in modo tale che tutti i nodi del cluster dispongano di dati di dimensioni uguali.
Note:
È anche possibile eseguire il bilanciamento del carico dei dati manualmente dal NCache Centro Direzionale.
Qualunque sia la ragione del trasferimento statale, l’intero processo è automatico e senza soluzione di continuità. Inoltre, durante il trasferimento di stato, soprattutto quando un nodo server lascia il cluster di cache, tutte le operazioni client destinate al nodo uscente vengono servite dalla sua replica tramite operazioni cluster.
Le repliche eseguono anche il trasferimento dello stato dai rispettivi nodi attivi proprio come gli altri nodi attivi. Le repliche estraggono i bucket assegnati dai nodi attivi per recuperare la copia dei dati al momento del trasferimento dello stato. Tuttavia, questo trasferimento di stato avviene solo in caso di riassegnazione del bucket. In caso contrario, i dati vengono replicati nelle repliche tramite il meccanismo di replica.
Diversi modi per monitorare il trasferimento di stato
NCache fornisce diversi modi per monitorare il trasferimento di stato nel cluster di cache. Sono spiegati di seguito:
- Log della cache: ogni volta che il trasferimento dello stato viene attivato e interrotto, viene registrato nei log della cache del cluster. I registri della cache esistono sotto il file %NCHOME%/bin/log cartella.
- Contatori personalizzati: NCache pubblica anche contatori personalizzati visualizzabili su Windows e Linux.
- Contatori basati su Perfmon: Su Windows, NCache pubblica anche i contatori di trasferimento dello stato tramite lo strumento Windows Perfmon.
- Registri eventi di Windows: Le informazioni/eventi relativi al trasferimento di stato vengono pubblicati anche nei registri eventi di Windows.
- Avvisi e-mail: È possibile configurare avvisi e-mail specifici per i trasferimenti di stato al momento dell'avvio e dell'interruzione.
Connettività client
Come spiegato nel partizionamento, i dati vengono distribuiti tra tutti i server nel cluster. A differenza di altre topologie, il client per le topologie partizionate deve connettersi a tutte le partizioni, dove ogni partizione contiene un sottoinsieme dei dati totali.
Il client riceve una mappa di distribuzione sulla chiamata di connessione, che informa il client sui nodi del server in esecuzione e sui relativi distribuzioni basate su hash. Il client si connette a tutti i nodi del server per ottenere dati completi dalla cache. Il cliente ottiene un mappa aggiornata su ogni modifica dell'appartenenza al cluster per mantenere la connettività. Il client riceve anche una notifica sul congedo/ingresso dei membri e ripristina la connettività in base a quanto ricevuto carta geografica.
Il client esegue in modo intelligente le operazioni di lettura/scrittura direttamente sul nodo server contenente la chiave secondo il mappa di distribuzione basata su hash riceve. Per tutte le operazioni in cui la chiave non è nota, come Ricerca SQL, GetByTags, ecc., il client trasmette la richiesta a tutti i nodi del server e combina le rispettive risposte.
Se, in ogni caso, il client non riesce a connettersi a qualsiasi nodo server del cluster, ciò non significa che non riesca a scrivere e recuperare informazioni da quel nodo server. A tale scopo utilizza gli altri nodi server a cui è connesso, che per suo conto richiede al nodo server irraggiungibile di eseguire operazioni. Ad esempio, se il client non riesce a connettersi al nodo1 e desidera ottenere una chiave che risiede nel nodo1, invia la richiesta al nodo2, che reindirizza al nodo1 e restituisce la risposta.
Modalità di manutenzione
Quando è necessario applicare patch o aggiornare hardware/software su un NCache server, è possibile che non si verifichino tempi di inattività dell'applicazione. Tuttavia, si attiva l'arresto di un nodo cache trasferimento statale all'interno dell'intero cluster di cache con conseguente uso eccessivo di risorse come rete, CPU e memoria. Questo trasferimento statale Il processo può essere costoso a seconda della dimensione dei dati della cache e del cluster. Un tipico flusso di lavoro di aggiornamento prevede il riavvio del nodo della cache alla volta, il che richiede due trasferimenti di stato, uno all'uscita del nodo e l'altro all'unione del nodo.
Modalità di manutenzione viene introdotto per evitare questi costosi trasferimenti di stato durante la manutenzione sui server cache. Una volta che un server cache viene arrestato per manutenzione per un periodo di tempo specificato, la replica del nodo in manutenzione diventa temporaneamente attiva e inizia a ricevere le richieste del client. Quando il nodo (che era in manutenzione) si ricongiunge dopo che la sua manutenzione si è conclusa entro il tempo specificato, il file trasferimento statale viene avviato affinché questo nodo lo sincronizzi con il cluster di cache.
Il cluster esce da modalità di manutenzione in tre stati diversi. Se il nodo di manutenzione si unisce al cluster di cache entro il tempo specificato, trasferimento statale viene avviato per sincronizzare lo stato del cluster e il cluster esce dal modalità di manutenzione. Se il nodo di manutenzione non riesce a ricongiungersi al cache cluster entro il tempo specificato, il cluster considera il nodo inattivo ed esce dal modalità di manutenzione, genera un nuovo carta geografica, e avvia il trasferimento statale. A parte il successo e il fallimento, c'è un'altra anomalia che esce dal modalità di manutenzione, cioè, quando un nodo lascia. Se il cluster è nel file modalità di manutenzione e qualsiasi nodo diverso da quello di manutenzione lascia, il cluster esce da modalità di manutenzionee potrebbe causare la perdita di dati.
Recupero del cervello diviso
Il termine Cervello diviso fa riferimento a uno stato in cui un cluster di cache si divide in più subcluster. I server di cache in un cluster comunicano tramite TCP. Pertanto, qualsiasi problema o problema di rete può causare una perdita di comunicazione tra i server presenti in un cluster. Se la perdita di comunicazione tra i server si estende oltre un certo tempo, la mappa di appartenenza cambierà in base alla connettività tra i server. Ciò si traduce nella formazione di più sub-cluster. Questi sottogruppi sono chiamati suddivisioni. Noi lo chiamiamo cervello diviso poiché i sottogruppi non possono comunicare tra loro, in modo simile a come le metà del cervello non possono comunicare tra loro nella sindrome del cervello diviso.
Tutti i sub-cluster sono integri ed elaborano i dati in essi contenuti. Inoltre, i client possono connettersi a questi subcluster per ulteriori operazioni di lettura/scrittura. Il client riceve una mappa di appartenenza dai server del cluster per aggiornare la connettività. Qui, il client può connettersi a qualsiasi sub-cluster a seconda della prima mappa ricevuta.
Cervello diviso viene rilevato solo quando riprende la comunicazione tra i server e viene rilevato che tutti i server sono attivi e in esecuzione ma non fanno parte di un singolo cluster. Sono possibili due o più divisioni a seconda della perdita di comunicazione tra i server. Una volta cervello diviso viene rilevato, viene avviato il processo di ripristino. Tutte le divisioni vengono ripristinate una per una finché tutti i sottogruppi non si uniscono.
I cervello diviso il processo di recupero inizia subito dopo il suo rilevamento. Richiede due suddivisioni sane, identifica i relativi server coordinatori, decide la suddivisione del vincitore e quella del perdente in base alla dimensione del cluster, acquisisce un blocco sulla suddivisione del perdente per limitare l'attività del client su quel cluster e le modifiche dell'appartenenza al cluster. Successivamente, tutti i client vengono reindirizzati alla divisione del cluster vincitore e tutti i nodi della divisione perdente vengono riavviati uno per uno per unirsi al cluster vincitore. Tutte le divisioni dei perdenti si fondono con la divisione del cluster vincitore nello stesso modo e il cluster ritorna integro.
La perdita di dati è prevista in cervello diviso ripristino quando il cluster si divide in più subcluster, si verifica una perdita di dati perché più nodi in un cluster escono contemporaneamente. I sub-cluster possono intrattenere le richieste dei clienti in uno stato di cervello diviso, queste operazioni potrebbero andare perse se la divisione a cui è connesso il client è una divisione perdente che viene riavviata per unirsi al cluster principale.
Vedere anche
Topologia replicata
Topologia specchiata
Cluster di cache
Cache locale