ルセン は、フルテキストインデックスを作成し、高度で正確な検索テクノロジをプログラムに実装するための強力なAPIを含む.NETフルテキスト検索エンジンライブラリです。 Luceneは、ユーザーに与えられる選択肢が複数あるため、他のテキスト検索エンジンに期待するものよりもはるかに多くのものを提供します。 強力な検索アルゴリズムを備えており、検索のための幅広いクエリをサポートしています。
Lucene自体は強力ですが、制限がないわけではありません。 Luceneはクライアントアプリケーションでインプロセスで実行され、Luceneアプリケーションは通常、データをファイルに書き込んでディスクに保存するため、大量のメモリが割り当てられます。 ただし、これはスタンドアロンソリューションであり、データの増加に応じて拡張することはできません。Luceneインデックス全体を再構築してデータを検索する必要があります。これは、コストがかかり、時間がかかるため、パフォーマンスのボトルネックになる可能性があります。 これは、Luceneがスケーラブルではなく、単一障害点があることを意味します。
NCache 詳細 ダウンロード NCache NCache ドキュメント
分散Luceneがどのように役立つか
NCache LuceneアプリケーションをスケーラブルにするLuceneの分散実装を提供します。 NCache Luceneを使用して本質的に分散されると、アプリケーションによってインデックスが作成されたドキュメントがキャッシュノード間で自動的に分散され、個別にインデックスが作成されるため、線形の書き込みスケーラビリティが提供されます。
同様に、分散Luceneは、クエリが各パーティションで伝播され、結果がマージされるため、線形読み取りスケーラビリティも提供します。 パーティションの数が多いほど、読み取りと書き込みのスケーラビリティーが高くなります。 Luceneインデックスは物理ドライブに保持されます。 ノードが多いほど、多数のLuceneドキュメントとインデックス付きデータに対応するためのスケーラビリティ、パフォーマンス、およびストレージ容量が高くなります。
NCache 詳細 ダウンロード NCache 分散Luceneドキュメント
分散Luceneのしくみ
分散Lucene 複数のサーバーノードが含まれ、各サーバーは NCache 専用のLuceneモジュールがあります。 LuceneとDistributedLuceneの動作と動作は、いくつかの変更点を除けば類似しています。
次の図は、DistributedLuceneモデルがどのように機能するかを示しています。
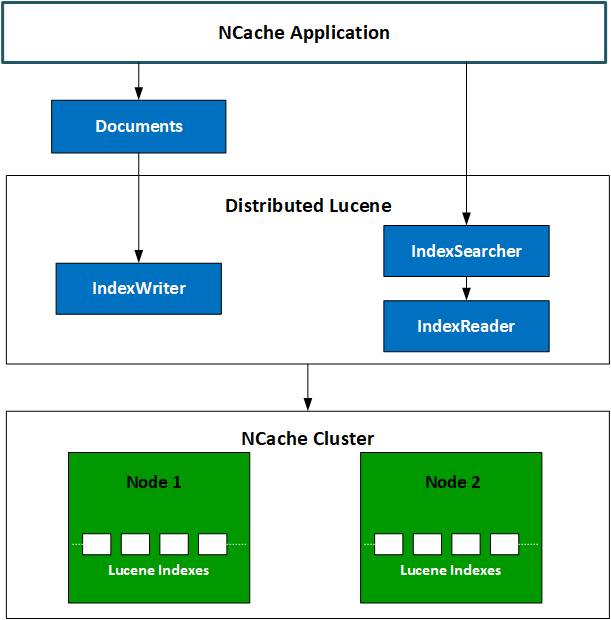
NCache 分散Luceneアーキテクチャ
クライアントアプリケーションは、Lucene APIを使用して、ドキュメントにインデックスを付けたり、既存のインデックス付きドキュメントにクエリを実行したりする場合があります。 APIとのこれらの相互作用は、クライアントとサーバー間のリモートプロシージャコール(RPC)のように機能します。 API呼び出しは、各サーバーノードに接続されているLuceneモジュールに直接転送されます。 Luceneモジュールはこれらの呼び出しを実行し、呼び出しの性質に応じて、次のいずれかのアクションが実行されます。
- クエリ呼び出しの場合、Distributed Luceneモジュールは結果をクライアント側に返し、そこですべての結果がマージされて処理されます。
- ドキュメントのインデックスを作成するための呼び出しであった場合、分散Luceneモジュールはそのドキュメントをディスクドライブに保持します。
NCache 詳細 分散Luceneドキュメント 分散Luceneキャッシュ
データ配信
分布マップは、に対して生成されます NCache 分散Luceneのクラスター。 このマップには、キャッシュノードに対するバケットの分布に関する情報が含まれています。 これらのバケット(マップには100個のバケットが存在します)は、特定の戦略を使用してクラスターに分散されます。 クラスターからノードを追加または削除すると、分散マップが変更され、実行中のサーバーノードの状態転送がトリガーされます。サーバーノードは、それぞれのノードでインデックス付きデータを使用してバケットを転送します。
100個のバケットがあるということは、Luceneインデックスが全体で100個のサブインデックスに分割されることを意味します。 NCache 集まる。 単一のバケットには、Lucene.NetのLuceneインデックスと同じサブインデックスが含まれています。 サーバーノードには複数のインデックスを含めることができ、そのサーバーノード内の各インデックスには、クラスターの分散戦略に従って割り当てられたバケットが含まれます。 インデックス内のデータは、これらのバケットを介して均等に分散されます。
分散Luceneを開始する方法
分散Luceneは、Luceneと同じように機能します。 分散Luceneを使用する主な利点のXNUMXつは、と同じAPIを提供することです。 ルセン。 Luceneユーザーは、XNUMX行のコード変更のアドオンを使用して、必要なスケーラビリティーを得ることができます。 あなたはただ使用する必要があります NCache ディレクトリとアプリケーションは問題ありません。 分散Luceneには、動作とAPIの変更がほとんどありません。 ドキュメント.
これらの手順を技術的な観点から詳しく見ていきましょう。主な手順は、ライブラリのLucene.NETNugetパッケージをDistributedLuceneNugetパッケージに置き換えることです。 Lucene.Net。NCache.
に接続しています NCache ディレクトリ
NCache ディレクトリは、その名前が示すように、インデックスをスケーラブルにするためのインデックスを格納するための基本クラスです。 したがって、最初のステップは と接続する NCache ディレクトリ.
以下に示すのは、という名前のキャッシュに接続するコードです。 ルシーンキャッシュ 提供されたディレクトリをすべてのサーバーで開きます。
|
1 2 3 4 5 6 7 8 9 |
// Specify the cache name that is used for Lucene string cache = "LuceneCache"; // Specify the index name to create the indexes string indexName = "ProductIndex"; // Create a directory and open it on the cache and the index path NCacheDirectory ncacheDirectory = NCacheDirectory.Open(cache, indexName); |
NCache 詳細 分散LuceneGeo-SpatialAPI 分散Luceneを初期化する
分散Luceneのインデックスデータ
ディレクトリが初期化されると、 IndexWriter ドキュメントを作成します Lucene.NETと同じメカニズムでインデックス上で AddDocument 方法。 文書が書かれるとき、 IndexWriter.Commit ドキュメントを永続化して検索可能にするために呼び出されます。
分散Luceneを使用すると、同じディレクトリで複数のライターを開いて並列インデックスを作成できます。 以下のコードサンプルは、DistributedLuceneを使用してドキュメントにインデックスを付ける方法を示しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// Create an instance of the writer IndexWriter indexWriter = new IndexWriter(ncacheDirectory, new IndexWriterConfig(LuceneVersion.LUCENE_48, new WhitespaceAnalyzer(LuceneVersion.LUCENE_48))); // Indexing // Add the products information that is to be indexed Product[] products = FetchProductsFromDB(); foreach (var prod in products) { // Create a document and add fields to it Document doc = new Document(); doc.Add(new TextField("ProductID", prod.ProductID, Field.Store.YES)); doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO)); doc.Add(new TextField("Category", prod.Category, Field.Store.YES)); doc.Add(new TextField("Description", prod.Description, Field.Store.YES)); // Writer is created previously indexWriter.AddDocument(doc); } // Calling commit on the writer saves all the write operations indexWriter.Commit(); // Dispose the objects after indexing indexWriter?.Dispose(); ncacheDirectory?.Dispose(); |
NCache 詳細 分散Luceneファセット 分散Luceneインデックス作成
分散Luceneでの検索
検索 データにインデックスを付けた後に実行できます。 ザ IndexSearcher 使用 IndexReader 結果を取得するため。 ザ IndexSearcher 与えられたクエリに従ってデータを検索する責任があります。 Luceneは幅広いクエリを提供し、DistributedLuceneはすべてのLuceneクエリをサポートします。
以下のコードサンプルは、DistributedLuceneを使用してインデックス付きドキュメントを検索する方法を示しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Open a new reader instance IndexReader reader = DirectoryReader.Open(ncacheDirectory); // A searcher is open to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify analyzer type Analyzer analyzer = new WhitespaceAnalyzer(version); // Create a query parser and parse the query with the parser //Specify the searchTerm and the fieldName QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, "Category", analyzer); Query query = parser.Parse("Beverages"); // Returns the top 10000 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs; indexSearcher?.Dispose(); reader?.Dispose(); |
NCache 詳細 分散Luceneカウンター 分散Lucene検索
分散LuceneでネイティブLuceneインデックスを使用する
Luceneを使用する.NETアプリケーションがすでにある場合は、大きなLuceneインデックスが作成されている可能性があります。 NCache 提供する インポート-LuceneIndex コマンドレット。これにより、ユーザーは既存のLuceneインデックスをにインポートできます。 NCache インデックスを再構築する必要なしにLuceneを分散しました。
このサンプルコマンドは、ネイティブのLuceneインデックスをからロードします C:\ Index 分散Luceneストアへ demoCache。
|
1 |
Import-LuceneIndex -CacheName demoCache -Path C:\Index -Server 20.200.21.11 |
NCache 詳細 分散Luceneドキュメント Luceneインデックスのインポート
まとめ
Luceneは、データに対して全文検索を実行するための非常に効率的な検索エンジンですが、スケーラビリティに欠けています。 NCache Luceneと一緒に使用すると、わずかな労力でスケーラブルにできます。 スケーラブルな分散Luceneを使用すると、アプリケーションが高速になるだけでなく、単一障害点の大きな後退に対処するのにも役立ちます。 NCache XNUMX行のコード変更で.NETアプリケーションに簡単にプラグインできるため、スケーラブルなLuceneアプリケーションに最適なオプションと考えてください。




