複雑なアーキテクチャを備えた高トランザクション アプリケーションの場合、継続的にデータを交換すると、不均一な負荷とスループットの遅延が発生します。 大規模で複雑なビジネス アプリケーションに関しては、データの洗練は大きな課題です。 これに対応するために、ストリーム処理を使用してデータ ストリームを作成し、特定のデータ フローを定義します。 一般的なストリーム アプリケーションは、新しいイベントを生成する複数のプロデューサーと、これらのイベントを処理する一連のコンシューマーで構成されます。
このような人気のあるアプリケーションの XNUMX つは Pub/Sub で、パブリッシャーはメッセージを入力し、サブスクライバーは購読しているメッセージを受信します。 ただし、ストリーム処理では、サブスクライバーがメッセージを取得すると、アプリケーションはメッセージを保持しなくなるなど、Pub/Sub にはいくつかの制限があります。 そのため、後で別のサブスクライバーがパブリッシャーからのメッセージを要求した場合、以前のメッセージは存在しません。 さらに、受信ストリーム データの場合、データのフィルタリングはサーバーではなくクライアント側 (サブスクライバー) で行われるため、アプリケーション アーキテクチャが複雑になります。
Pub/Sub のこれらの制限を克服するには、 NCache には、継続的クエリを使用してサーバー側でデータを処理する効率的なメカニズムが付属しています。 継続的クエリを使用すると、キャッシュ内に存在するデータで発生し、特定の基準を満たすすべての変更をアプリケーションに通知できます。 このブログは、ストリーム処理用に作成されたソリューションを活用して、ストリーム処理で連続クエリを使用する利点を理解するのに役立ちます。 GitHubの.
ストリーム処理に連続クエリを使用する
このソリューションでは、毎日何千人もの顧客のオンライン購入を処理する e コマース アプリケーションについて説明します。 下の図を見ると、あらゆる種類とカテゴリの顧客がアプリケーションに追加されています。 顧客の処理を効率化するために、フィルタリングされていない顧客は、連続クエリを使用して注文数に基づいて「ゴールド」、「シルバー」、「ブロンズ」の顧客として分類およびフィルタリングされます。
連続クエリ 特定の基準を満たすデータがキャッシュ内で変更され、その基準が SQL コマンドを使用して指定されたときに、アプリケーションが通知を受信できるようにします。 たとえば、アプリケーションが注文数の多い顧客を「ゴールド顧客」としてタグ付けしたい場合、必要なのは SQL コマンド基準を登録してコールバックを提供することだけです。 このコールバックは、基準を満たす結果セットに変更が発生すると起動されます。 コールバックが呼び出されると、アプリケーションはタグを使用してこれらの顧客を「ゴールド顧客」として分類できます。
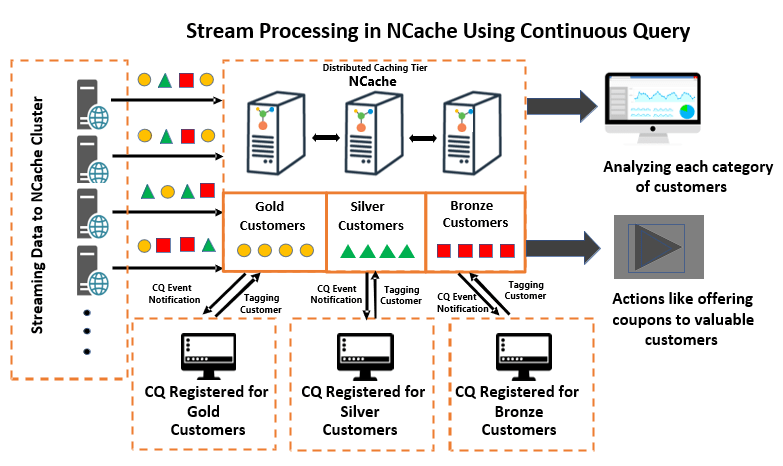
図 1: 連続クエリを使用したストリーム処理
同様に、アプリケーションは、それぞれに独自の基準とコールバックを持つ複数の CQ を登録することで、複数のカテゴリを作成できます。 このようにして、アプリケーションは関心のあるフィルタリングされたデータのみを取得します。その後、フィルタリングされたデータは、顧客のカテゴリに基づいてハイエンド顧客に割引を提供するなどのビジネス要件に従ってさらに分析できます。
次のデータ変更アクションのいずれかがキャッシュ内で発生すると、イベントがトリガーされます。
- 追加: クエリ基準を満たす新しいアイテムをキャッシュに追加する
- アップデート: クエリ結果セット内の既存の項目を更新します。
- 削除: キャッシュから項目を削除するか、クエリ結果セットから項目が削除されるように既存のキャッシュされた項目を更新します。
連続クエリでキャッシュ内のストリーム処理を使用する簡単なコード例を見てみましょう。 この例では、10 を超える注文が「ゴールド顧客」カテゴリに追加されるデータに対して継続クエリが実行されます。 さらに、クエリ結果セットに追加されたすべての項目でイベントがトリガーされます。
|
1 2 3 4 5 6 7 8 9 10 11 |
string query = SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery (queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification (new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
継続的クエリでは、Pub/Sub では保持されないデータが保持されます。
継続的なクエリによってフィルタリングされたデータ (注文数が 10 を超える顧客の場合) は「ゴールド顧客」としてタグ付けされ、キャッシュ内で更新されます。 それがどのように行われるかを確認するには、以下のコードを見てください。
|
1 2 3 4 5 6 7 8 9 10 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.None); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
継続的クエリでは、処理後もデータがキャッシュに保持されます。 このようにして、複数のアプリケーションがデータをパブリッシュするという、継続的に生成されるデータに対する Pub/Sub が直面する問題を解決します。 NCache メッセージング層。 したがって、複数のサブスクライバがデータを受信しますが、メッセージは受信後にメッセージ バスから削除されるため、信頼できるデータ ストレージがありません。 データは、アプリケーションによって保存されるか、またはより複雑なシナリオである新しいデータ ソースの追加によって保存されます。 一方、継続的クエリでは、データの損失がないことが保証されるため、データを手動で永続化するための余分な労力がすべて節約されます。
NCache 詳細 ダウンロード NCache エディションの比較
継続的クエリにより、強力なフィルタリングによるアプリケーションの分離が可能になります
大規模で複雑なアプリケーションは、そのアーキテクチャに基づいてさまざまなグループに分けることができます。たとえば、10 個のアプリケーションが実行されている場合、そのうちの XNUMX つはゴールド顧客のデータセットを処理し、残りの XNUMX つはシルバー顧客のデータセットを処理する可能性があります。 このような場合、各アプリケーションのストリーム処理のニーズに応じてデータがフィルターされる、データセットごとに個別のビジネス ロジックが必要になります。 したがって、アプリケーションの相互依存性がパフォーマンスの大きなボトルネックを引き起こし、アプリケーションの複雑さが増大するため、このような大規模で複雑なアプリケーションは分離する必要があります。
継続的クエリは、非常に高度な SQL ステートメントを使用してアプリケーションのデータを非常に効率的にフィルタリングするため、他のアプリケーションと重複するアプリケーションはありません。 この分離は、各サービスが個別のアプリケーション スタックで実行されているマイクロサービス アーキテクチャで非常に役立ちます。 すべてのマイクロサービスは、依存関係を引き起こすことなく独自のデータを取得して処理します。 このレベルのデータ フィルタリングとアプリケーションの分離は、Pub/Sub を使用して実現することはできません。
図 2 は、分離されたアーキテクチャでそれぞれのデータセットを処理するさまざまなクライアント アプリケーションを示しています。 NCache 継続的なクエリ。
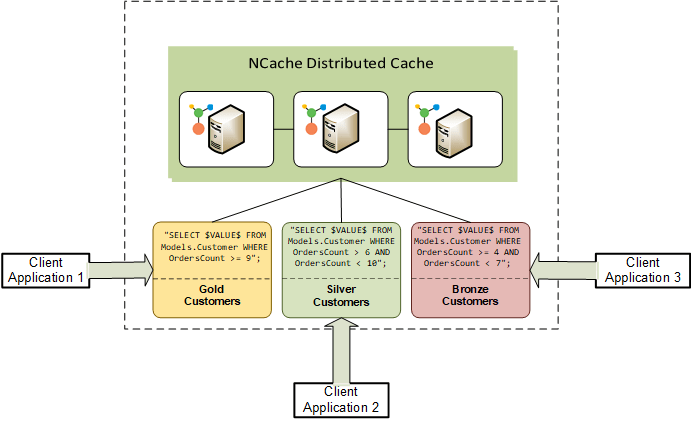
図 2: アプリケーション間の分離
タグを使用したデータの取得
タグ in NCache に基づいてデータを分類するために使用されるデータの追加修飾子です。 前述のシナリオのような大規模なデータ セットの場合、タグはキャッシュ全体でデータを検索するのではなく、関連するデータをフェッチするのに非常に役立ちます。 顧客が「ゴールド顧客」のカテゴリに該当する場合は、すぐに検索できるようにタグが追加されます。 これらのカテゴリに基づいて、割引やクーポンなどの追加の特典を顧客に提供できます。 NCache さまざまな タグを使用してデータを取得する柔軟な方法、ドキュメントで徹底的に説明されています。
次に、「ゴールド顧客」に関連付けられたタグのコード例を見てみましょう。 これらの顧客には、クーポンやプレミアム サービスが提供される場合があります。
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
キャッシュデータの有効期限切れ
NCache ことができます キャッシュデータの有効期限 これは、特定の間隔の後にデータを無効にし、クリーンな間隔でキャッシュからデータを削除します。
NCache には XNUMX 種類の有効期限があります。
顧客の場合、ゴールド、シルバー、ブロンズの4つのカテゴリのいずれにも該当しないアイテムには有効期限が追加されます。 注文数が 15 件未満の他のすべての顧客は有効期限を設けて追加され、それ以上の分析は行われないためにキャッシュから削除されます。 ただし、いずれかのカテゴリに属する顧客の有効期限は [なし] に設定され、手動で削除しない限りデータがキャッシュに保持されます。 これは、注文が 4 件未満の顧客に XNUMX 秒の有効期限を追加する方法です。
|
1 2 3 4 5 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, new TimeSpan(0, 0, 15)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
使用する理由 NCache?
NCache is 100% .NET/.NET コアとなるインメモリ分散キャッシュ ソリューションであり、長年にわたって市場をリードしてきました。 これは非常に高速で直線的に拡張可能であり、データをキャッシュすることでアプリケーションのパフォーマンスのボトルネックを効率的に除去します。 高価なネットワーク接続を削減することで、ネットワーク コストを節約します。 NCache は、データ分析を非常に高速かつ効率的に行う連続クエリなどの豊富な機能セットと、アプリケーションのスムーズなフローを促進するその他の機能を提供します。





