NCache ヘルスおよびパフォーマンスの監視
録画されたウェビナー
ロン・フセイン
このビデオウェビナーは、実行中のアプリケーションの最適な状態に利用できるオプションとツールの包括的な紹介です。 NCache.
両方のヘルス アラートとパフォーマンス オプションについて学習します。 NCache サーバーと NCache クライアント (アプリケーション側)、具体的には次のとおりです。
- NCache ヘルス アラート機能: 概要と使用方法
- NCache パフォーマンス監視: 概要と機能
- 健全性とパフォーマンスを監視するための組み込みツール
- NCache オペレーティング システム (Windows) リソースを介した監視
- NCache サードパーティツールによる監視
- デバッグ方法 NCache 健康とパフォーマンスの問題
今日私たちが選んだトピックは、 NCache 健康状態とパフォーマンスのモニタリング。 したがって、基本的には、以下のさまざまな監視オプションについて説明します。 NCache この特定のウェビナーでは、XNUMX つの異なる方法でこれに取り組みます。 利用できるヘルス関連のオプションと、アプリケーションのパフォーマンスとパフォーマンスの監視について説明します。 NCache サーバー側のパフォーマンス。 これは NCache ベースのトピックなので、すでにいくつかの詳細を知っていると思います NCache 基本的な詳細もいくつか共有しますが、今日のウェビナーの議題は、特定のトピックを用意していることです。 それは約です NCache そして暴露します NCache ヘルスおよびパフォーマンスの監視に関する機能。
NCache 展開
大丈夫! したがって、まず出発点は NCache 展開。 先ほども言ったように、私は次のように仮定します NCache はすでにセットアップされていますが、セットアップされていない場合、これは典型的な展開です。 NCache.
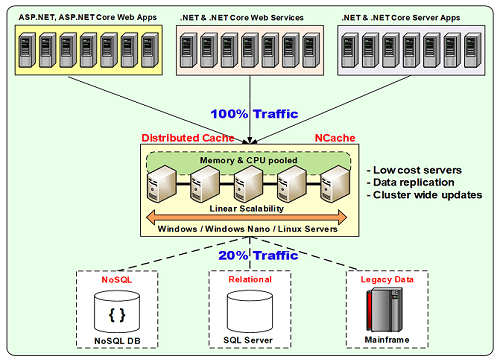
複数のサーバーが常駐するサーバー層があり、次にクライアント/サーバー モデルで実際にこれに接続するアプリケーション層があります。 したがって、サーバーがキャッシュ専用となる別のキャッシュ層を使用し、アプリケーションをそれぞれの層で実行できます。 これらは、ASP.NET Web アプリケーション、Web フォームまたは MVC、ASP.NET Web サービスまたは Java Web サービス、WCF またはその他、またはすべてに接続しているバックエンド サーバー アプリケーションである可能性があります。 NCache。 したがって、このようなデプロイメントを手元に持っているときはいつでも、どこからキャッシュを取得できるか NCache そしてあなたのアプリケーションはに接続しています NCache、何がキャッシュされるかに関して複数の質問があるかもしれません。 スループットとは何ですか? パフォーマンス マトリックスとは何ですか? オブジェクトのサイズが異なる場合のパフォーマンスの向上はどの程度ですか、また問題はありますか。 それをデバッグするにはどうすればよいでしょうか?
今日説明するのはこれだけです。 ここでは、さまざまなログ、キャプチャできるさまざまな健康関連イベント、および健康に関する監視機能について説明します。 セットアップできるさまざまなデバッグ ログについて説明し、それに加えてパフォーマンスの比較も行うため、これらすべてがこのウェビナーにまとめられています。 これからたくさんのことが起こりますが、すべては実践的です。
NCache サーバー要件
これ以上遅らせることなく、実際に始めましょう。これは NCache サーバー要件。 通常、これについては定期的なデモやウェビナーで取り上げます。 つまり、8 コア以上であり、これが最小推奨セットアップです。 NCache ただし、より多くのコアを使用することもできます。 RAM はユースケースに応じて 16 GB 以上です。 すべての Windows 環境でサポートされています。 NCache サーバー部分に関しては、2012 または 2016 を使用することをお勧めしますが、2008 オペレーティング システム、.NET 4.0 以降、4.6.1、4.6.2、または 4.5 などの古いバージョンでも動作します。 それが最も一般的に使用されます。 と、 remote clients は、任意の Windows 環境の任意のフレームワークに再度使用できます。 32 ビットと 64 ビットのすべての環境もサポートされています。
セットアップ環境
さて、そうは言っても、すぐにこれを始めましょう。 すぐにデモ環境を作成します。そのために、XNUMX つのノードといくつかのクライアントを使用してそれに接続します。 そして、ここでも、キャッシュの作成方法、構成、トポロジーについては多くの詳細を共有しないことを前提としています。 その詳細についてはすでにご存知かと思います。 そうでない場合は、建築のウェビナーまたは建築のデモを見つけてください。 NCache または、当社が実施するテクノロジーウェビナーの一環として。
したがって、ASP.NET Web アプリケーションと、インストールに付属するコンソール アプリケーションを使用します。 NCache それが私が考えていることです。 基本的には、これを始めるためにすぐに行うことです。 開発環境にログオンします。 すでに構成したキャッシュがあるので、新しいプロジェクトを作成してからキャッシュを作成します。 そこで、デモ キャッシュを作成します。これは、パフォーマンスと正常性に関するすべての監視側面に使用するキャッシュです。 NCache。 ここでは最も人気のあるパーティション レプリカ キャッシュを選択します。そのため、これを選択し、次にサーバー間のレプリケーション モードである非同期と、再びデモ 1 とデモ 2 を選択することをお勧めします。
これらすべての手順は、当社の既存のウェビナーやデモに詳しく文書化されており、当社の Web サイトで参照できます。 したがって、これは通信用のサーバーの TCP ポートを指定し、次にキャッシュ クラスターのサイズを指定する方法です。 キャッシュがいっぱいになったときに通知を受け取ることと、それにどのように対応するかについて考えていることがあります。当面はエビクションをオフにするか、オンのままにすることにします。 実際には、キャッシュがどのようにしていっぱいになるか、そのシナリオで何が必要になるかを実際に紹介するので、これをオフにしましょう。 エビクションは、キャッシュがいっぱいになったときに、キャッシュからいくつかのアイテムを削除することで、新しいアイテムのためのスペースを自動的に確保する方法です。 したがって、それはやめて、「終了」を選択してください。これでキャッシュが作成されました。
すぐに私のボックスをクライアントとして追加します。これはここにある私のパーソナル コンピューターです。 かどうかを確認する必要があります NCache サービスが開始されているかどうか。 環境をいじってますので、ご了承ください。 それはあるかも知れません.. はい、始まったので、それも追加されたと思います、それで、わかりました! それでは、実際に始めてみましょう。 これで環境は整いました。 テストキャッシュはちょっといじってみたので、今のところ無視してください。 デモのキャッシュに注目してください。 クリックしてしまいました。 右側のペインに表示されます。 これらはすべて、この特定のキャッシュの設定です。 まだ始まっていません。 したがって、両方のサーバーが起動するように、すぐにこれを起動します。 ここまたはここから開始ボタンを使用すると、実際にはすべてのキャッシュ サーバーでキャッシュが開始されます。 そして、次に実際にいくつかの基本的なステップから始めます。 キャッシュが開始されたことを確認するにはどうすればよいですか? それが健康であるかどうか、そして活動を示しているかどうかをどうやって知るか? したがって、これらは今すぐ実行するいくつかの基本的な手順であり、その後、その上に構築していきます。 私たちは、それをいくつかの広範なレベル、いくつかの高度なレベルへと進めていきます。
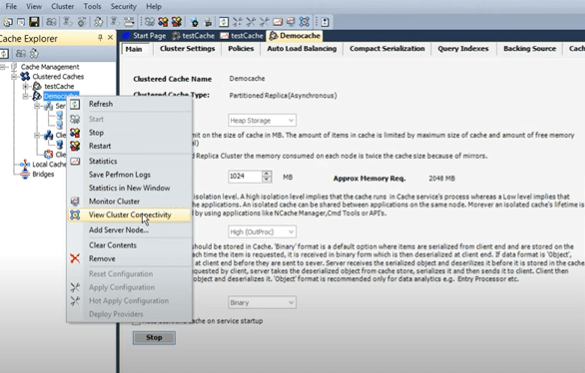
これで、キャッシュが開始されました。最初のステップとして、マネージャーまたはコマンド ラインから使用できます。ちなみに、これらはすべてコマンド ラインからも実行できるため、GUI ツールだけではありません。 GUI と比較して同等の機能を備えたコマンドライン ツールがあります。 キャッシュ クラスターの健全性を確認するために、右クリックしてクラスター接続の表示ボックスを開きます。
これにより、完全に接続された状態についてのアイデアが得られます。 各サーバーにはアクティブとバックアップがあります。 その図を簡単にお見せしましょう。 このパーティション レプリカ キャッシュが存在するようにトポロジを選択したため、アーキテクチャでは、存在するアクティブ パーティションと、別のサービスのレプリカが維持されるパッシブ パーティションが存在します。
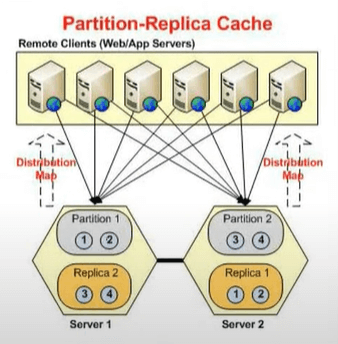
したがって、サーバー XNUMX のアクティブ バックはサーバー XNUMX にオープンされ、サーバー XNUMX のアクティブ バックアップはサーバー XNUMX にあります。 これらはアクティブであり、これらはパッシブです。 これらはアクティブになるだけで、これはダウンしますよね? したがって、これがダウンすると、これがアクティブになり、これがダウンすると、バックアップがアクティブになります。 したがって、各サーバーには XNUMX つのパーティションがあります。 XNUMX つのサーバーがあり、XNUMX つのパーティションがあり、これがまさにここで表示されているものです。
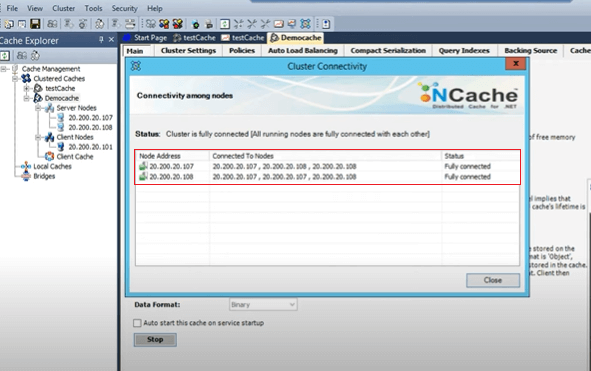
したがって、107 つは独自のバックアップに接続され、他のサーバーはアクティブになり、もう XNUMX つのサービスはバックアップに接続されます。 そして、サーバー XNUMX は、他のサーバー、他のサーバーのバックアップ、および自身のバックアップである自身の XNUMX に接続されています。 それは増加パターンにあり、完全につながっていることもわかります。 ご存知の場合は、詳細をいくつか共有させてください。 ステータス メッセージが接続できていないか、部分的に接続されているか、キャッシュ サービスが開始されていません。 したがって、これらはすべて、キャッシュ クラスターに何らかの問題があり、完全に接続されたステータスが表示されるまで、キャッシュが正しく開始されていないことを意味します。 これが最初の構築ポイントです。キャッシュの作成を開始するときは、完全に接続されたキャッシュのステータスを必ず確認してください。
また、この出力はリスト キャッシュを通じても使用できます。 それは来るツールです、ここに持ってきてみましょう、これはキャッシュです。 また、/a を付けてリスト キャッシュを実行すると、デモ キャッシュが開始されたというローカル情報が得られるだけです。 ただし、このキャッシュ (たとえば A スイッチ) を使用してこれを実行すると、実際には 107 ポートのクラスター サイズ (バックアップの場合は 107:7802) が得られます。 108:7807と708と数えます。
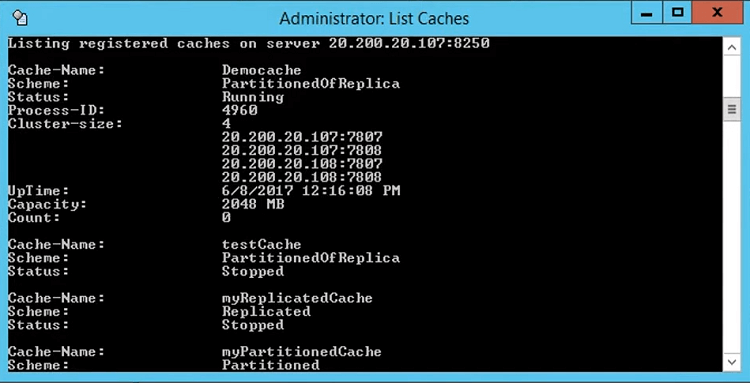
したがって、これはこれを健全に示しています。 したがって、リスト キャッシュを使用する場合は、この情報を検索する必要があります。それ以外の場合は、クラスター接続を表示すると、GUI でこれが得られます。
各キャッシュにはキャッシュ ホスト プロセスがあるため、デモ キャッシュとデモ キャッシュ XNUMX のキャッシュ フロー プロセスがあります。 そして、たとえば、この説明内に詳細を追加すると、関連するキャッシュも実際に確認できるようになります。 コマンドラインにあると思いますが、ここにコマンドライン列を追加すると、実際にキャッシュ名が表示される可能性があります。 ただし、プロセス ID が重要であるため、通常はプロセス ID に依存します。これについては今後のスライドで詳しく説明します。 そうは言っても、キャッシュは稼働しているようですので、これが最初の構築ポイントになります。
次に、キャッシュ上のアクティビティ、つまりキャッシュがリクエストを受け付けているかどうかの基本的なアクティビティを確認する方法です。 したがって、そのためには、右クリックして統計を選択するだけです。 これにより、perf-mon カウンターが開きます。これらは、 NCache マネージャーだけでなく、クライアント側のカウンターも見ることができます。これについては後ほど詳しく説明します。 さまざまなオブジェクト サイズを示すシナリオがあり、クライアント側の平均とそれらがどのような影響を受けるかを示します。 それで、それがこのウェビナーの終わりに向けて私が並べたものです。 ということで、それも出てきます。 しかし、物事の基本的な側面を示すために、ここでそれをそのまま紹介しましょう。デモ キャッシュとレプリカがあります。デモ キャッシュとレプリカがあります。 テストを実行していないため、この時点ではアクティビティは生成されていません。テストを実行する必要があります。そのためには、ボックスをクライアントとして追加したので、コマンドラインを実行します。これを始めるためのツール。
さまざまなパラメーターも取ることができますが、今のところはいくつかの基本的な値を使用することにします。これで、XNUMX 秒あたりのリクエストがすでに受信されていることがわかります。 つまり、サーバー XNUMX がリクエストを受け付けており、バックアップはリクエストを受け付けていませんが、カウントは更新されていますが、サーバー XNUMX がリクエストを受け付けているため、ここで確認できます。そして、実際にはバックアップであるサーバー XNUMX のバックアップがあります。 ということで、バックアップパーティションがXNUMXつ並んでいます。 つまり、これにより、実際にキャッシュが正常に実行されていることを再度確認できます。
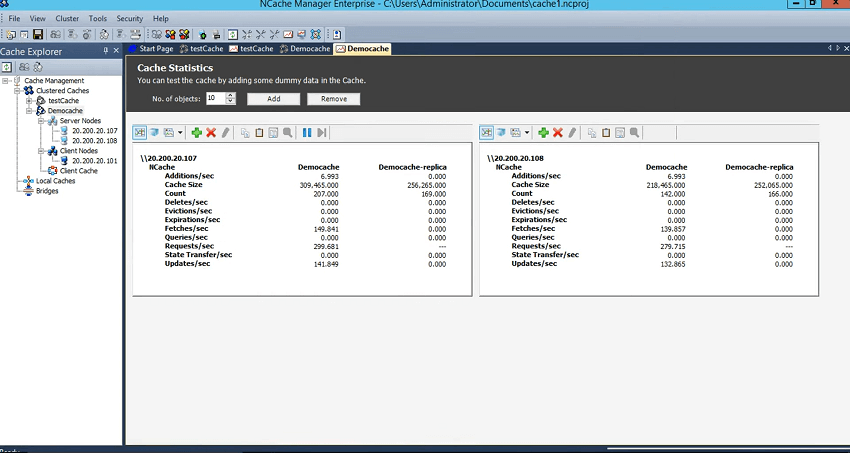
リクエストは均等に分散されます。 ここで、XNUMX 秒あたりのリクエストのカウンターを確認できます。 また、バックアップも更新されています。
したがって、最初のステップである健全性に関する基本的な監視は、この周囲の壁を乗り越えて行うものであり、その後、この時点から先に進み、キャッシュで何が起こっているかを確認できます。 通知を受け取ることができるので、それについて詳しくお話します。
監視オプション
すぐに先に進み、以下の監視オプションを開始します。 NCache。 ということで、並べてみたのがこれです。 昨日、これらの説明に多くの時間を費やしましたが、実践的な部分、実践的な部分にもっと焦点を当てるべきであるというフィードバックを受け取りました。 ということで、今日はこれでやります。 先ほども言いましたが、今日はこのウェビナーで別の解釈をしてみます。
PerfMon Counter を使用した監視
そこで、PerfMon カウンターを用意しました。 サーバー側とクライアント側がありますので、それらについて説明します。 イベント ログ エントリがあり、これらのイベント ログ エントリを使用してアラートを提供する監視ツールがあります。 電子メール関連のアラートを提供する電子メール アラートがあります。 また、サードパーティのツールを使用して、これらのイベント ログに接続することもできます。 したがって、これらはかなり広範であり、監視の側面に関しては最も重要な要素であると言えます。 NCache.
ログによる監視
そして、ログが得られます。 ログを構成するには複数の方法があります。 サーバー側のログとクライアント側のログがあり、ログ アナライザーと呼ばれる別のツールがあります。 次に、リンク パッド統合を利用したデータ アナライザー ツールがあり、個々の呼び出しにどれくらいの時間がかかっているかを実際に示すことができる API ログもあり、これは単なるプラグアンドプレイ オプションです。 そして、先ほども言ったように、SCOM を使用してこれらのログに接続したり、イベント ログ エントリに接続したりできるサードパーティの統合があり、さらに AppDynamics またはその他のサードパーティ ツールがあり、その後で使用できます。 NCache そのために。
NCache 監視ツール – デモ
今日は、さまざまな方法の実際のデモを使用するだけなので、まず始めましょう。 NCache 付属の監視ツール NCache。 リクエストを設定したので、別のクライアントに移動して、実際にサーバー ボックスを使用してみましょう。 サーバーはクライアントを使用することもできるので、実際にそれを確認できます。 ここからストレス テスト ツールを実行してから、ここからもストレス テスト ツールを実行して、XNUMX 秒あたりのリクエストに関する限り、かなりの負荷 (かなりの負荷と呼んでもいいでしょう) が得られるようにしましょう。 また、サーバー XNUMX とサーバー XNUMX では、XNUMX 秒あたり約 XNUMX のリクエストが確認され、現在は XNUMX を超えるリクエストがあり、XNUMX 秒あたり XNUMX ~ XNUMX のリクエストが発生しています。
ここで、リアルタイムおよびロギングの基本的な監視要件は、監視ツールを通じてカバーできます。 他の場所を探す必要も、ログを確認する必要も、イベント ログを調べたり、サードパーティのツールを利用したりする必要もありません。 インストールされているツールがあります NCache そのため、このツールをそのまま使用することをお勧めします。その特定のツールの簡単なデモを紹介します。
事前設定された監視ダッシュボード
右クリックして「モニター・クラスター」を選択すると、 NCache インストールに付属する監視ツール NCache。 これの優れた点は、クライアントだけでなくサーバーも監視し、サーバーやクライアントのいずれかである必要はなく、ネットワーク内の XNUMX 番目のボックスとしてもよいことです。 キャッシュ デプロイメントである必要はありません。
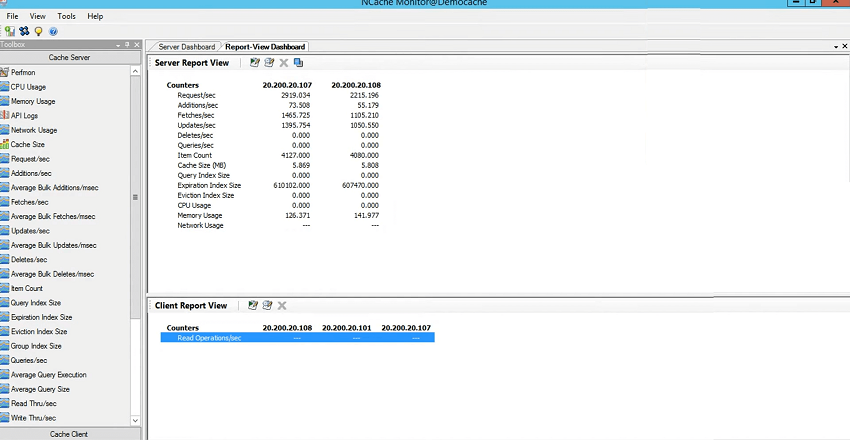
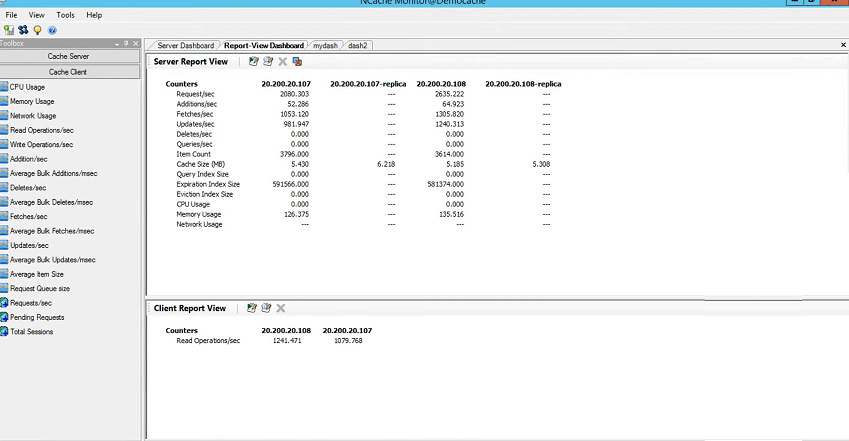
つまり、クライアントは 107、108、3 つあります。 私のボックスにはいくつかのルールがあるため、リモート監視は許可されていませんが、108 と 107 のカウンターが表示されるので、ビューに移動して、これらのサーバーとクライアントのダッシュボードがチェックされていることを確認するだけです。 私のボックスでは予想どおりのエラーが発生します。 ただし、同じ接続ボックスに完全に接続されたステータスが表示され、変更があればリアルタイムで変更されます。 この監視ツールの利点は、すべてのステータスをリアルタイムで表示できることです。
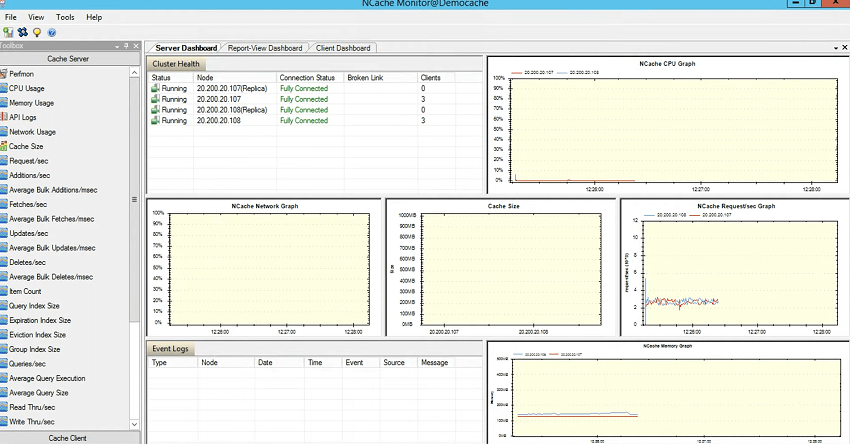
CPU サーバー 1 とサーバー 2 の CPU グラフがここにリストされます。 ネットワーク グラフ。ネットワーク アクティビティがある場合は、ここに表示されます。 キャッシュ サイズのグラフと 3,000 秒あたりのリクエストのグラフ。 したがって、サイズとネットワークに関する限り、現時点では大規模なアクティビティは発生していないため、ほぼゼロの値が表示されますが、108 秒あたりのリクエストを見る限り、それは数千倍であることがわかり、約 107 になります。サーバー XNUMX およびサーバー XNUMX ごとの XNUMX 秒あたりのリクエスト数。 そして、記憶力も上がっています。 つまり、これは実際には、サーバー XNUMX とサーバー XNUMX が利用されていて、それに接続されている XNUMX つのクライアントがあり、クライアント ダッシュボードも表示されることを示しています。 つまり、XNUMX と XNUMX はクライアントであり、読み取りリクエストを送信しており、アクティビティも存在することがわかります。
カスタム監視ダッシュボード
したがって、これは、一部の事前構成されたダッシュボードのリアルタイム監視の側面をカバーしています。 ただし、これらに依存する必要はありません。 実際に一歩進んで、独自のダッシュボードを作成することもできます。そこから楽しみが始まります。 ダッシュさん、実際にもっと堅牢にするために、XNUMX つだけやらせてください。モニター ツールを開く別の方法を紹介しましょう。 ここから直接監視ツールを開くこともできます。 必要なのは、サーバーを選択することだけです。サーバーはリモート サーバーでもあり、キャッシュの名前を指定するだけです。 これは、実際に指定する別の方法であり、同じことが表示され、XNUMX つのクライアントを閉じたので、クライアントが XNUMX つになりました。 サーバーとクライアントが XNUMX つしかないため、CPU リクエストに関しては実際により多くのアクティビティが表示されることになります。
戻って、独自のダッシュボードを作成できます。 NCache 監視ツール。 ちなみに、これらはすべて Perf-mon カウンターです。 実際に、Windows パフォーマンス監視を使用して実際に同じことを実現できるパフォーマンス監視ツールも紹介します。 したがって、それに慣れている場合は、それを使用してください。 単に使いたい場合 NCache 付属のモニターツール NCache、これも素晴らしい選択です。 ちなみに、これはリアルタイムの表示です。 このダッシュを作成しましょう。 したがって、独自のダッシュボードを作成するということは、空のパネルがあることを意味します。2 x 2 列を使用しましょう。これは、画面の左側に表示される perf-mon カウンターのいずれかに利用されます。 サーバー側の CPU 使用率、イベント ログ、クラスターの健全性、書き込み操作、アイテム数など、これまでのところ良好な結果が得られます。 ここにはすべてがリストされており、クライアント側のカウンターもあります。
したがって、サーバー側とクライアント側でパーソナライズされた監視が可能になり、さらに、実際にここにドラッグ アンド ドロップできる perf-mon コントロールも提供されます。 したがって、任意のパフォーマンス カウンターを追加できます。 Windows パフォーマンス カウンター、メモリ、.NET セルラー メモリ、CPU、あらゆる種類のパフォーマンス関連カウンター、またはヘルス関連カウンターの可能性があります。 NCache ここに追加できます。 そして、それらについてもう少し詳しく話します。 わかった! そこで、別のダッシュを作成して、2 つのダッシュボードを作成します。 これをダッシュ 2 と呼び、XNUMX x XNUMX がサイズだとしましょう。 それが標準です。
わかった! それで、作業中に、最初のダッシュボードと、それに接続されているクライアント プロセスを簡単に示します。 したがって、これにより、現在キャッシュに接続されているすべてのクライアント プロセスの概要が得られます。 したがって、ここに来て、このウィンドウを使用し、クライアント IP、プロセス ID、接続されているポート、接続されているサーバー IP、送受信されたバイト数を使用できます。 したがって、クライアント アプリケーションの 4016 つで重いアクティビティが発生した場合、実際にはここでも接続が確認される可能性があります。 接続が切断されている可能性があります。 すべてのサーバーに接続されている 107 つのプロセス ID が常に表示されるため、4016 は 108 に接続され、3 も XNUMX に接続されます。したがって、接続に問題がある場合、たとえば、ワーカー プロセスが開始された場合、キャッシュ内に XNUMX つのサーバーが存在します。ワーカー プロセスの XNUMX つがサーバー XNUMX に接続できませんでした。それを知るにはどうすればよいでしょうか?
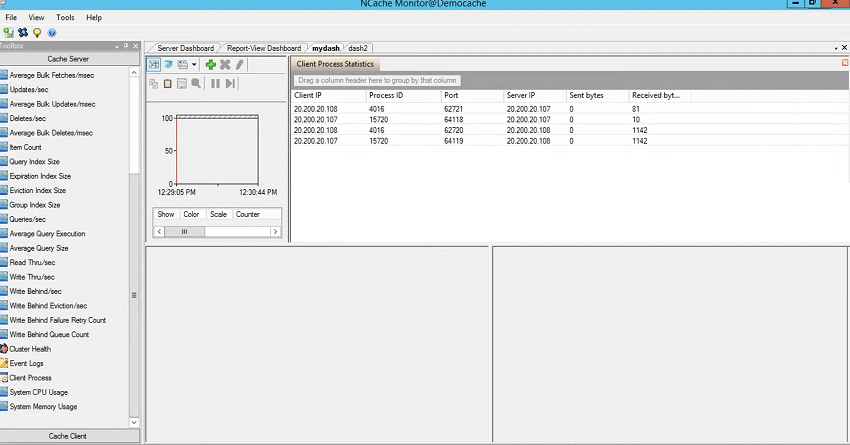
まず、トリガーされるイベントがあり、それについては後ほど説明します。これは、通知を受け取る明示的な方法です。 ただし、異常な動作があるかどうか、速度が遅いか、または大量のリクエストがあるかどうかはわかります。これは、サーバーがクライアントによって接続されていない場合、クライアントはリクエストを他のサーバーに送信し、それらのサーバーがそのリクエストを再ルーティングするためです。他のサーバーに送信するため、時間がかかる場合があります。 したがって、この画面に来て IP を選択し、プロセス ID で起動して、ここにリストされていない接続があるかどうかを確認できます。
もう XNUMX つはクライアントの数です。 したがって、ここにあるサーバーの XNUMX つは、他のサーバーと比較して、このウィンドウにリストされるクライアントの数が少なくなります。 これは私が見せたかった重要なツールの XNUMX つで、パーソナライズされた XNUMX 秒あたりのフェッチが実行され、XNUMX 秒あたりの追加が実行されるのがわかります。その後、ダッシュ XNUMX でクライアント側にアクセスすると、ネットワークの使用状況が表示されます。事前構成されたダッシュボードには通常表示されない、クライアントのクライアント CPU 使用率。
ということで、これもリアルタイムモニタリングです。 過去のデータはどうなるのでしょうか? ログ記録についてはどうですか? したがって、それもこのツールに組み込まれています。 したがって、実際にここに来てログを開始することができ、実際にログをスケジュールすることもできます。また、要件である場合は、ここでレプリカを表示することも選択できます。その後、いくつかのオプションを試すことができます。 。 たとえば、サンプル レートを選択し、グラフを使用してから、キャッシュ内で実際に確認したいイベント ログを使用します。 したがって、これにより、前述したようにリアルタイム監視が可能になります。 リクエストの読み込みが入ってくると、これらが表示されます。 次に、この特定の時間を拡張できます。 データの入力にかかる時間と、これらの個々のダッシュボードのウィンドウも変更可能であり、前述したように、それに伴うログインのサポートもあります。
以上で、基本的なデモについて説明しました。 NCache 監視ツールを使用し、健全性のチェック、クライアント接続のチェック、リクエストなどのいくつかのユースケースについて詳しく説明しました。 リクエストもここに追加され、サーバー上のアクティビティも表示されます。 つまり、これがクライアントであり、これがリクエストの負荷を示すサーバーであり、その上に接続クライアント プロセスの統計と接続があり、さらにネットワークと NCP の使用状況に関するクライアント アクティビティもあります。 現時点ではネットワークをあまり集中的に使用していないか、このダッシュボードが公開されていないという権限の問題が発生している可能性があるため、ネットワークの使用率はそれほど高くありませんが、それについては調査していきます。 しかし、これまでのところ、すべてが順調に見えています。 何らかのアクティビティがあり、クライアントとサーバーが健全な方法で相互に通信しています。 ここまでで何か質問はありますか? これで完了です NCache インストールされているモニターツールのデモ NCache.
わかった! したがって、監視ツールを閉じて、ストレス テスト ツールを実行したままにします。 Web アプリケーションも使用する必要がありますが、それは後の段階で行います。
イベント ログと電子メール アラート – デモ
次に、健康関連のアラートをいくつか紹介します。そのためには、システムの一部となり、イベントが発生するたびに定期的に更新されるイベント ログ エントリについて説明する必要があります。 それでは、Windows イベント ログに行きましょう。 NCache.. それは実際には大いに権利があり、それはどのイベントにも特有のものです。 たとえば、キャッシュを開始しました。システムの各イベント ログは、独自のサーバー、キャッシュのビュー、システムのイベントに固有です。 NCache サービスまたはそのサーバーのキャッシュ ホストを指定してキャッシュを開始したので、最初に別のプロセスが開始され、それがここで起こったことです。
Windows イベント ビューアのログ記録
次のイベント ログは、これがレプリカ ジョイントであるため開始され、このレプリカ ジョイントが実行されると、デモ キャッシュもキャッシュ上で正常に開始されたことを示しています。 そして、108 がキャッシュに結合され、108 のレプリカがキャッシュに結合されます。これらはスキップできるいくつかの構成メッセージであり、それだけです。 これらは関係ありません NCache ただし、これらのメッセージに関する限り、イベント ログに関する完全な情報が得られるはずです。 ここで実際にテスト キャッシュを使用するシナリオを簡単にシミュレートしてみましょう。そのため、キャッシュの 107 つを開始します。 私は 107 を使用しているので、XNUMX を開始するだけです。これに関連していくつかのイベント ログが伝播されているのがわかります。 それでは、これが完了したら待ちましょう。 それで、始まりました。 もう一度、クラスター接続の表示を使用すると、開始されていないサービスが XNUMX つだけあることがわかりますが、そのサービスにはステータスがなく、キャッシュが停止しているため接続されていません。 したがって、必要に応じて、モニター クラスターを使用して個別に監視することもできます。
さて、イベントログに戻ります。 したがって、テスト キャッシュを開始する必要があることが完了しましたが、そのテスト キャッシュ プロセスが開始される前に、107 個のレプリカができました。 つまり、キャッシュを開始するたびにキャッシュ プロセスが開始され、そのイベント ログ エントリが作成され、実際のボックスが実際にキャッシュを開始するレプリカが作成され、そのレプリカがキャッシュ クラスターに参加します。 そして、情報の一部として追加された情報があり、実際に開始されるデータ コレクター セットがありますが、現在私のマシンではオフにしています。そのため、そこに到達し、テスト キャッシュが正常に開始されたのがこのイベントです。あなたはあなたのアプリケーションに興味を持っているはずです、そしてその後あなたのアプリケーション。 次に、フックして他のツールを使用したり、 NCache それを監視するか、それに関する通知を受け取るツールを監視します。 つまり、これらはイベント ログです。
これらは Windows に公開されているため、キャッシュが開始されるたびに停止され、それに別のノードを追加することを示します。 イベント ログを介して通知を受け取ることはなく、キャッシュを停止するとイベント ログを介して通知を受け取ることになります。 キャッシュがいっぱいになると通知が届きます。 状態転送が開始されると、ネットワーク障害が発生し、107 つのサービスが接続を切断すると、そのたびにこれらの更新イベントが発生し、実際にはそこからイベントを取得することになります。 ということで、また108が加わりました。 キャッシュは正常に開始され、現在 108 がテスト キャッシュに参加し、XNUMX のレプリカがテスト キャッシュに参加しています。 つまり、これらのイベントは再びログに記録され、イベント ID は同じままですが、メッセージは重要です。 それで、通知が届きます。 そして、すぐにキャッシュを停止すると、イベント ログが再び入力されるのがわかります。
したがって、サードパーティによる監視のほとんどはこれらに関するものです。 キャッシュを停止したので、もう一度更新してみます。そうすると、いくつかの情報が表示されますが、これは警告ですよね。 レプリカが結合した後、ノード XNUMX または XNUMX がテスト キャッシュから出たためです。 つまり、これは憂慮すべき状況です。なぜなら、あなたがそれを止めたか、あるいは自然にダウンする何かである可能性があるからです。 したがって、その場合には通知が届きます。
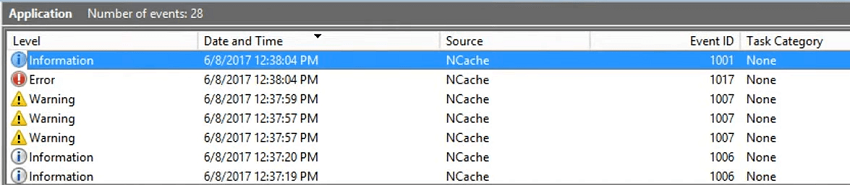
そして、別の 108 レプリカがダウンし、その後、メインの 107 レプリカがダウンしました。 そして、これも無視して、キャッシュの停止が成功するかテストする必要があるもう XNUMX つのエントリです。 したがって、通常のシナリオでは、停止すると、この安全なイベントも発生します。 ただし、警告はありますが、警告が低下すると冗長レベルが表示されますが、エラー レベルはエラーに変わりません。 それは警告ではなく、もはや情報ではありません。 テストキャッシュの別のプロセスも停止されました。
したがって、これらは、Windows イベント ロックの使用と、サードパーティの監視があるかどうかを調べる必要がある情報です。 たとえば、アプリ ダイナミクスを使用している顧客がいて、これらのイベントを有効にするのを支援しました。 したがって、彼らが行う必要があるのは、イベント ID を使用してイベント ログを回転してキャッシュすることだけでした。そうすれば、私たちに連絡することができます。 すべてのイベントのリストを提供します。 NCache ログを取得し、そこから取得します。 サードパーティの監視ツールを使用して監視およびキャッシュも行います。 それでは、これで閉めさせていただきます。
メールアラート
さて、話に戻りますが、 NCache 私たちは実際に情報をイベント ログにプッシュしますが、そこで待つことなく、実際に独自のアラート システムも実装しました。これはこれらの機能に基づいており、電子メール アラートと呼ばれています。 あとは、キャッシュで電子メール アラートを有効にするだけです。実行中のキャッシュでも同様に実行できます。 そして、ここに私の詳細を入力できます。たとえば、Ron@alachisoft.com。 ここから確認する必要があります。smtp.gmail.com です。 私は個人的なものを使用しているだけです…そしてポートも提供します。 この情報は保管しておきます。 そして、私は自分のログインを使用するだけです。 受信者を使用します。
自分自身にメールを送信し、キャッシュの開始またはキャッシュの停止を伝えるだけです。 サイズはフルになります。 クラスターは分裂し、壊れてしまいます。 状態転送。これは、ノードが他のサーバーに参加または離脱するたびに、次のいずれかを実行する必要があるプロセスです。 redisそれを称賛するか、バックアップをアクティブにしてください。 それで、それがシナリオです。 ノードが参加したこともノードが離脱したこともありませんね? したがって、通知を受け取ることができ、ここに来て構成を適用するだけで済みます。
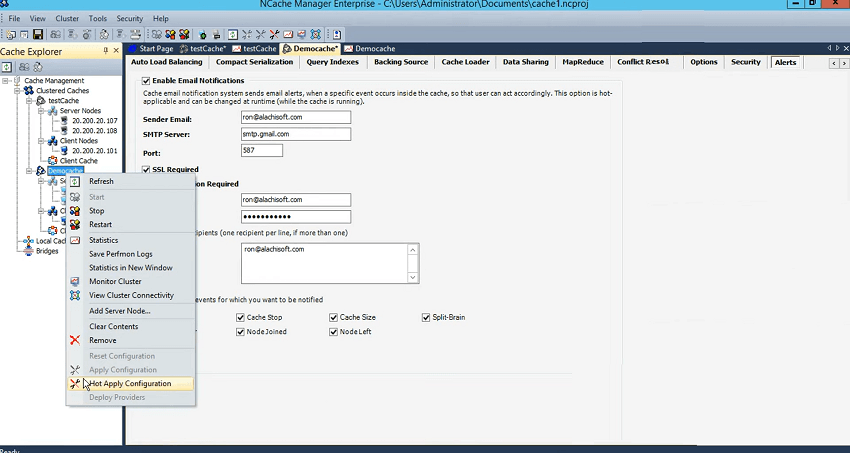
実際にはキャッシュに対してこれを行うつもりはありません。 このキャッシュはここにあります。 テストキャッシュとすべてのイベントのセットアップについてはすでに完了しています。 「構成を適用する」とだけ言って、例を使ってこれを示します。 それで、これを始めますね? 107 を起動したばかりなので、イベント ログを戻して更新すると、いくつかの情報があるので、正常に起動しました。 107が参加しました。 テスト キャッシュが正常に開始されました。 また、エラー メッセージは無視してかまいません。
では、電子メールアラートについてはどうでしょうか? そのためには、ここで自分のマシンに戻る必要があり、電子メールが起動されるはずです。 これは無視してください。 したがって、同じイベントが電子メールアラートの形式で受信されますが、今回は NCache はこれらのイベントを消費し、購読している受信者に電子メール アラートを送信します。 最初のアラート、実際にはたくさんのアラートがあります。 107 がテスト キャッシュに参加したので、ここでこのウィンドウを使用します。 開ける必要はありません。 正常に起動しました。 108名が参加しました。 実際、これらはいくつかの古いイベントなので、1133 を使用させてください。はい、これらはアラートがオープンされていたため、それに基づいてテストを行っていたものです。
わかった! それでは、1133 に注目してみましょう。つまり、107 レプリカが結合され、テスト キャッシュが正常に開始されました。 そこで、ここに戻り、すぐに 108 を起動して、これが実際に電子メール アラートとイベント ログ エントリを並べてトリガーすることを示します。 これは独自に実装された SMTP ですが、舞台裏ではイベント ログを使用していますよね。 それで、あなたもそれをすることができます。 もう一度、ここでリフレッシュします。 エントリーがあるじゃないですか。 したがって、106 と 106 が再び 108 回ログに記録され、ここに戻って送受信を行うと、状態転送やその他のイベントもあるので、さらに 108 通またはそれ以上の電子メールを受信できるはずです。 キャッシュにデータがあれば、それらのイベントも発生します。 それでは、どうぞ。 それで、XNUMX テスト キャッシュが開始されました テスト キャッシュが正常に開始されました。これは XNUMX 用ですよね? したがって、もう一度送受信を実行して、これ以上メールがないことを確認します。
したがって、問題が発生した場合はシステム管理者に通知し、実際に問題をシミュレートしてみましょう。 ノード 107 がダウンしたらどうなるでしょうか? または、接続が切断された場合。 ここでは接続の切断を実際にシミュレートすることはできませんが、ノードのダウンをシミュレートすることはできます。私はそれを実行しました。 したがって、まず、実際にイベント ログにイベントが表示されます。 警告が出ていますよね? そして、電子メール警告がからかいを拾うかどうかを見てみましょう。 それが非常に簡単であることを願っています。 ここでは、健康に関する限り、環境モニターを使用して入手できる基本的な機能のいくつかを強調しているだけです。 したがって、実際にノードが離脱し、107, XNUMX イベント ログが生成されたことがわかります。 したがって、必要に応じて受信者のリストをここに入力することも、グループにすることもできますが、必ず XNUMX 行に XNUMX 人の受信者を指定してください。 わかった?
したがって、もう一方は次のようにする必要があります support@alachisoft.com あるいはkal@かもしれませんalachisoft.com。 それで、実際にそこから取ることができます。 このように、電子メール アラートを使い始めるのは非常に簡単です。 NCache モニターツール。 イベントログについては説明しました。 カバーしました NCache 電子メールアラート。
NCache ログ - デモ
次は NCache ログについては、少し高度なトピックですが、できるだけ多くの時間をログに費やして、そこから取り上げていきます。
テスト キャッシュは私が使用してきたものなので、このキャッシュを停止します。これが停止している間は、アプリケーションを開かせてください。 フォルダ構成がおかしくてごめんなさい。 別の環境からコピーしたので...よし! それでは、ビジュアル スタジオを開いてみましょう。 このセクションでは必要ありませんが、キャッシュが停止されるのを待っている間準備ができるように、開いたままにし、内部のロギング機能を示します。 NCache。 Web サイトを開きます。 これは何らかの理由で非常に遅いです。 それまで待ってます、またここに来させてください。 それはビジュアルスタジオがそんなことをすべきではなかったからだと思います。 とにかく、閉じられるかどうか見てみましょう。 わかった! さて、話に戻りますが、テスト キャッシュは停止していますよね。
そこで、そのロギング機能を紹介します。 NCache。 したがって、ログが維持され、これがキャッシュ ログとなります。 少なくともこれらは取り除くことができます。 停止されているキャッシュ、開始されたキャッシュは実際に削除できるようになります。 したがって、最初からやり直します。これらは実行中のキャッシュです。ログ ファイルは削除しないでください。 この特定のデモのためにそれを行っただけです。 ここで XNUMX つのノードを開始し、サーバー側で作成されるログ ファイルとその詳細を示します。 ログ ファイルを理解するには、クラスタリングとそのフレームワークに関する高度な情報が必要になります。 NCache。 そこで、いくつかの基本的なことについてお話します。
LogViewerツールを使用したログ分析
キャッシュを作成し、テスト キャッシュとレプリカを開始したので、この機会を利用して実際にログ ビューアでもログを開きます。 したがって、ビン、ツール、GUI に移動すると、このログ ビューア ツールがインストールされています。 NCache。 メモ帳、ワードパッド、メモ帳 ++ を使用することもできますが、これは読み取り、タイムスタンプ、ロガー レベルで並べ替え、メッセージを正確に特定するのに実際に役立ちます。 それでは、さっそく開けていきます。 同じディレクトリに移動します。 ここでテスト キャッシュを開くと、そこにあるすべてのログが表示されます。 さて、これは非常に興味深いツールです。 さまざまなフィールドやノードを使用できますよね? そして、それに基づいてフィルターを提供できます。 したがって、ここでフィルターを指定します。
サーバー側のログ
そこで、基本的な詳細をいくつか紹介します。 動作パラメータは 107、7805 です。レプリカは常に 7806 になります。どのポートを指定しても、次はレプリカ用です。 したがって、これが最初のサーバーであるビューをインストールします。 したがって、サーバーは 7805 だけです。 したがって、サーバーが起動するたびに、クラスタリング層と通信してビューを取得します。 つまり、それ自体をコーディネーターとして使用してインストールされ、7805 107 が独自のビューを使用していることがわかります。 ビュー ID が 0 の場合、メンバーがイベントに参加しました。 これらも関連するイベント ログです。 そして、ここに多くの情報メッセージが表示され、レプリカがここに参加しているはずです。 7805 が 107 と 7806 に結合していることがわかります。つまり、レプリカが結合しました。
したがって、各サーバーは起動し、他のどのサーバーが利用可能であるかを調べようとします。 使用可能なサーバーがない場合は、最初のサーバーとして起動し、次にそのレプリカを起動して 108 ノードのキャッシュ クラスターを作成します。 そして、キャッシュ、状態転送イベント、そしてキャッシュの初期化が表示されます。 無事に起動しました。 したがって、このイベントの前に、次のようなエラー メッセージが表示されても、心配する必要はありません。他のサーバーに接続しようとしていますが、XNUMX がまだ開始されていないため、他のサーバーはまだ存在していない可能性があります。 それで、接続しようとしましたが、応答がありませんでした。この時点で、すぐにここに来て、ストレス テスト ツール、その新しいインスタンスを使用します。 クライアント接続イベントについても説明します。 ちなみに、設定したすべてのイベント ログ、すべてのウィンドウ、電子メール アラートはそのまま残っていますよね?
それで、それを閉じて戻ってみましょう。先ほど言ったように、notepad++ から開くこともできます。 メモ帳で同じツールを開くだけです。 ここで、同じログ ファイルが開きますが、今回はクライアントも開始したため、最後の方ではクライアント接続ボックスも表示されます。 ちょっとここに持ってきてみましょう。 そのため、ボックスの IP、ボックスの名前、GUI、およびプロセス ID がキャッシュに接続されるデモがあります。 したがって、XNUMX つのサーバーとクライアントが接続されていることがわかります。 ここで、シナリオとしては、キャッシュに問題があるかどうかを確認する方法が考えられます。 したがって、この時点の後にエラー メッセージが表示されますが、これはエラー メッセージを示しています。 これより前のエラー メッセージは単なる発見です。 したがって、このようなエラー メッセージが大量に表示されるまで、または表示されない限り、これらは非常に正常です。 いくつかのエラーが表示されますが、それらは単なる検出メッセージです。
ここで、このキャッシュを開始して、このサーバーのログとサーバーのログを表示し、それがどのように変化するかを示します。 これで、これは開始されたので、あとはここに戻ってきて、更新されるかどうかを確認してみましょう。更新されなかったため、ここに戻ってこのサーバーのログを見てみましょう。 ということで、108がスタートしました。 したがって、さらにアクティビティが表示されることになります。 最後のエントリはどこにありましたか? ちょっとそれを見てみましょう。 わかった! ということは、損失エントリーとしてこれを持っていたんですよね? ここで、108 の参加許可があり、参加が開始されました。 107 は、107、107、および 108 を含むビューをインストールしました。そして、今度は 108 レプリカも参加し、107、107 レプリカ 108、を含む別のビューができます。 108のレプリカです。 そして、状態転送の開始と終了が表示されるため、これですべてがスムーズに進みました。 したがって、新しいサーバーが参加し、これらすべてが前に示したようにイベント ログに記録されます。
ここで、サーバー 2 のログ ファイルを示して、その詳細を説明します。 他のサーバーはどうなったのか…他のサーバーが起動し、サーバーがすでにそこにあったためです。 そこで、ログ ファイルは通常、最新のファイルが先頭に来るように変更された日付で開始されることを示します。 そうなることを願っています。 テストキャッシュはどこにありますか? さあ! このボックスでは他のキャッシュも実行されています。 時間が合わないと思いますが、見てください。 大丈夫! とにかく、時間がないので、これを例として使用しましょう。 したがって、時間がかかります。 それで、108がスタートして、このときに実際にお願いしたんです。 つまり、単一のノードとして存在していたはずですよね? ただし、この場合、実際には参加許可が表示されます。 したがって、実際にはこれを使用しません。 ログ ファイルを見ることができません。わかりました。
何が起こっているかはわかっています。 ローカルのログ ファイル フォルダーを見ているので、発生したログ ファイルがあるはずです。 それで、変更日を見てください。これが実際のログ ファイルです。 お詫び申し上げます。 大丈夫! これで 108 が開始され、実際に試行したが失敗したことがわかり、ここで実際にいくつかのエラー メッセージが表示されます。 このエラーが発生したのは、それが最初のエラーではなく、そのレプリカが存在しないため、最初のエラーではないためです。 ご覧のとおり、107 はすでに開始されているため、ビューが与えられ、状態転送が開始されました。 これらはいくつかのバケット情報であり、その後メンバーがキャッシュ クラスターに参加します。わかりました。
ログ ファイルを確認するのは非常に簡単ですが、前述したように、これらはユースケースやシームしている問題に基づいて複雑になる可能性があり、レプリカ ログ ファイルもあります。 したがって、彼女が実際に間違いを私たちに共有するのは良いことですし、私たちは実際にあなたがそれをより深く理解できるよう手助けすることができます。 したがって、各サーバーのタイムラインでは、ログ ファイルに記録された問題を確認できます。 すぐに戻ってきます。 もう少し時間が残っているので、実際に別のシナリオを示して、監視ツールを開くことができるかどうかを確認させてください。
APIログ
さて、監視ツール内には別の種類のログ ファイルがあるので、この特定のキャッシュにはそれを使用しましょう。 新しいダッシュボードを作成しましょう。
わかった! サーバーが一部のリクエストを完了するのにさらに時間がかかったり、速度が低下したりするシナリオがある場合、どのように対処すればよいでしょうか? したがって、XNUMX つの方法は、アプリケーションのパフォーマンス カウンターと、 NCache 正直に言うと、perf-mon カウンターは次のセクションの最後のセクションです。 ただし、このログ ファイルは実際に、この API ログがあることを正確に特定するのに役立ちます。 したがって、監視ツールを開いて API ログをドラッグ アンド ドロップすると、設定が使用され、実際にここに情報が記録されるので、ファイル ログを有効にしてオンにし、実行してみようと思います。
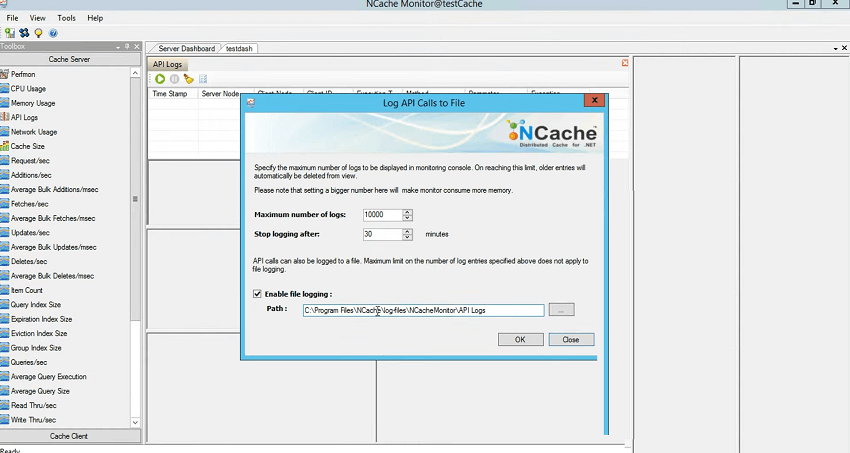
したがって、テストをシミュレートする必要があります。たとえば、テストに 15 分かかり、問題を再現するか、特定の時間に速度が低下する場合や、どのアプリケーションが速度の低下を引き起こしているのか、どの呼び出しが原因であるかがわからない場合は、運用環境で問題を再現する必要があります。速度の低下の原因となっているアプリケーション内のメソッドは何ですか。API ログを使用すると、実際にそれを特定できます。 したがって、これを実行するだけです。 すべての情報をダンプし、問題が再現したら停止し、これを通じてタイムスタンプを確認して確認します。 サーバーノード。 リクエストの送信元のクライアント、クライアントの ID、および実行時間。 したがって、ここではこの実行時間が最も重要な要素となります。 この時点ではミリ秒未満ですが、負荷をシミュレートし、/ M 1 024 のキャッシュをテストするシナリオを使用してストレス テスト ツールを再度使用するとどうなるでしょうか。これは間違いなく、より大きな値を使用することになります。 0.03が見えますよね? 0.07 なので…他の応力ツールを閉じさせてください。 うん! 時間が経ったのがわかりますよね? 0.02ですよね? また、サーバー側でログに記録されているエラーを実際に確認することもできます。
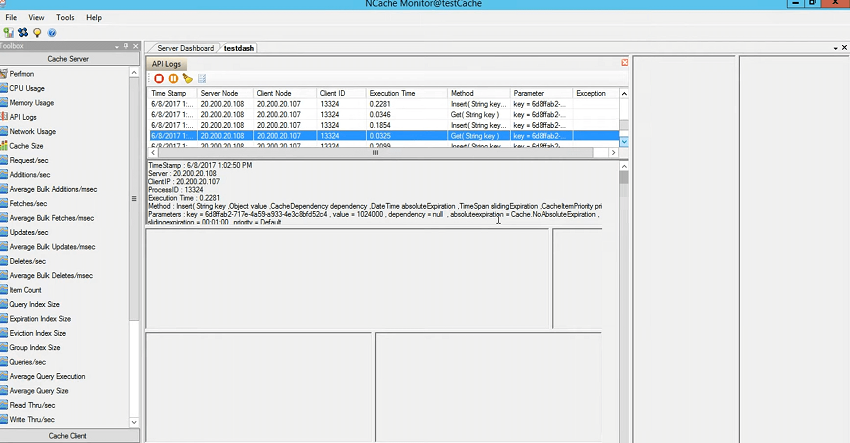
つまり、あらゆる障害、つまり障害はログ ファイルに記録できる明らかなものですが、この機能を使用すると遅さをマッピングできます。 そして、ここに戻って、このフォルダー API ログには、データの履歴追跡を保持するログ ファイルがあります。 つまり、最初の数回の平均は 0.02、0.01 で、最後に近づくにつれて値が増加していることがわかりますね。 これにより、この特定の通話が遅い時間を示すことができます。 メソッドを確認してから、アプリケーション内でそのメソッドと関連付ける必要があります。 したがって、これは顧客環境のデバッグに常に使用できるものだと思います。 時間を確認し、目の前で問題を再現してもらい、ログを有効にして、さらにクライアント側のログと組み合わせることができます。 クライアント インストール内で、ログを指定できます。たとえば、次のようにログを指定できます。 NCache Web サーバーが存在するクライアント マシンには、この有効化ログがありますよね?
クライアント側のログ
したがって、各キャッシュには、オンにできるクライアント ログ有効化フラグがあります。 したがって、これにより、実際にはクライアント側のログ ファイルも作成されます。これは、これまでに見たものと同様のログ ファイルです。 したがって、これはロギングの面で役立つと思います。 あと 10 分ほど時間をとって、パフォーマンス カウンターについて結論を述べたいと思います。これは、このセクションで最も重要なセクションだからです。
NCache パフォーマンス監視 (シナリオ)
を使用してパフォーマンス監視を行う方法 NCache? あまり情報が多すぎないことを祈ります。 基本的な内容にとどめましたが、シナリオは日常のユースケースに合わせたものになっています。
PerfMon によるリアルタイム監視
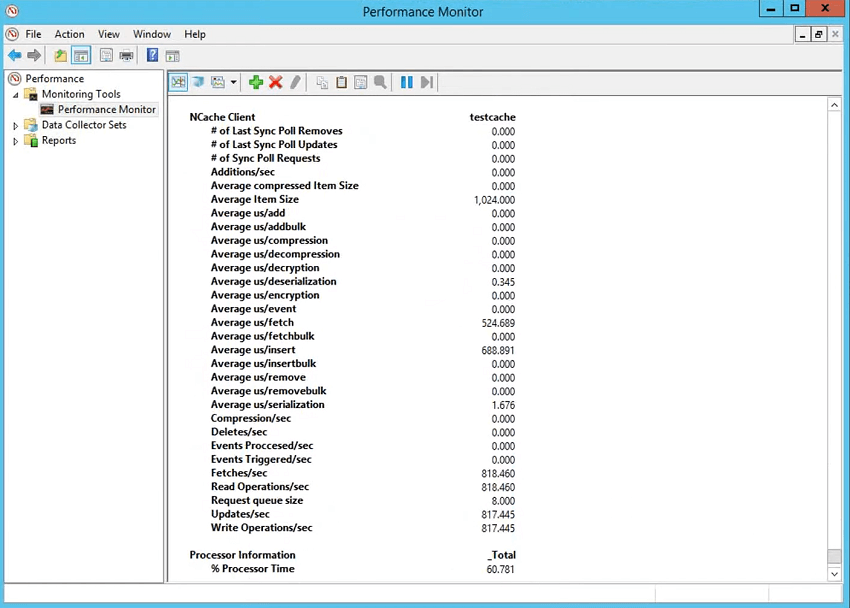
さて、パフォーマンス監視の話に戻りますが、 NCache XNUMX 種類のカウンターが表示されます。 これらは PerfMon カウンターなので、単に PerfMon と言って内部のパフォーマンス モニターを期待することもできます。 NCache ここでこれを閉じて、このツールをすぐに実行して時間を節約しましょう。 したがって、パフォーマンス カウンターを開くと、次のようになります。 NCache カテゴリーですよね? 下 NCache カテゴリには、必要なカウンターがすべて揃っています。 平均値は非常に重要です。 これにより、キャッシュへの追加、フェッチ、挿入にかかる平均時間がわかります。 じゃあ、全部使ってみますね? そして、[追加] を選択して [OK] を選択すると、これらのパフォーマンスの平均が表示されます。
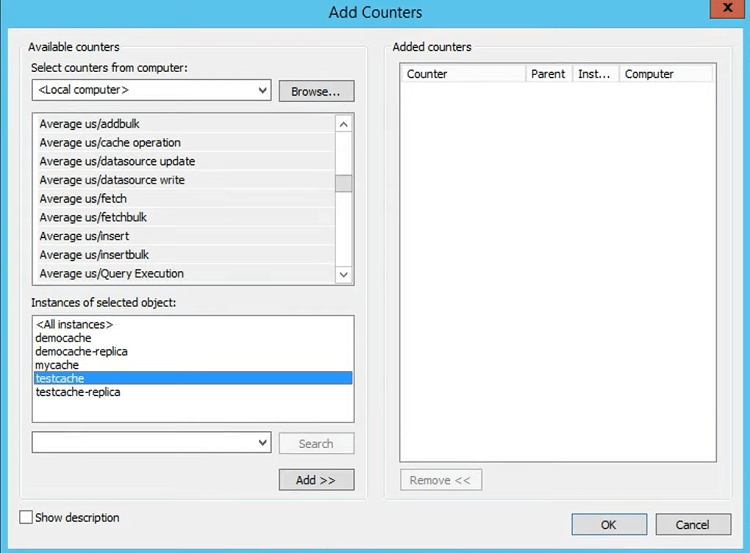
つまり、フェッチの平均マイクロ秒は 27 マイクロ秒、挿入の平均マイクロ秒は約 65 マイクロ秒であることがわかります。 しかし、クライアントはどうでしょうか?
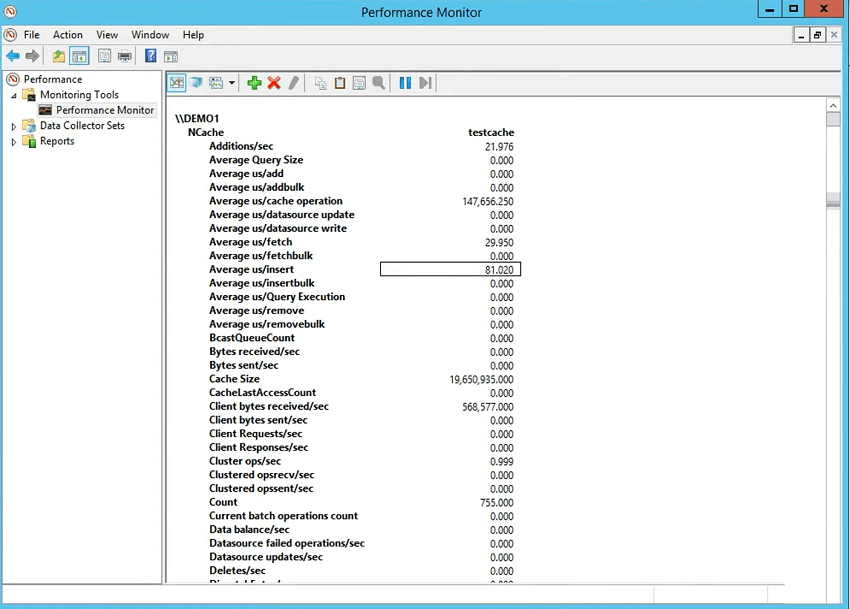
そこで、クライアント側のカウンターを見て、操作が完了するまでにどれくらいの時間がかかるかを見てみましょう。 それで、あなたが選択します NCache クライアント カテゴリで、クライアントのテスト キャッシュを選択し、追加を選択します。 ここの下に、次のようになります。 NCache client セクションも同様です。これが最も重要です。これにより、 NCache クライアント側の実行者の推定。 アイテムのサイズが得られるので、1024 になります。フェッチあたりの平均マイクロ秒は 718 です。これは、圧縮がオンになっている場合は圧縮し、暗号化がオンになっている場合は暗号化して送信するためにアプリケーション内でシリアル化に要した全体の時間です。ワイヤーはそこに保存されているため、サーバー時間が含まれ、その後戻ってきてシリアル化が解除されます。 ということで、手術の時間です。 フェッチの場合は、単なる逆シリアル化です。 挿入の場合もこのシリアル化であり、挿入の場合はシリアル化あたりの平均マイクロ秒、フェッチの場合は逆シリアル化あたりの平均マイクロ秒が実際に確認できます。
また、これらに関するログを有効にすることもできます。それが今の私が実際に行うことです。 何らかの理由であなたが私に打ちひしがれた場合は、開けられるかどうか見てみましょう。でも、それができるかどうか見てみましょう。 そして、この特定のシナリオで私が念頭に置いているのは、次のような Web アプリケーションがあるということです… わかりました! これは何かをしているので… 期待していた Web アプリケーションがあります… OK! 質問があります。 これらはできますか NCache カウンターはリモートからアクセスできますか? もちろん! 私は常にサーバーからもクライアントからもカウンターにアクセスするため、これらのサーバーにリモートでアクセスできる場合は、perf-mon アクセスが許可されます。 実際にそれができます。 問題ありません。 したがって、通常は、これらすべてのタスクを処理する監視サーバーとして XNUMX つのサーバーが使用されます。 事前にビジュアルスタジオを開いてアプリケーションを生成する必要がありましたが、そうしなかったため、それが問題の原因となっています。 今度はこれがうまくいくことを願っています。 さあ! 実際にはそこにはいないと思います。 それで、私のプロジェクトのディレクトリを置いておきます…ご容赦ください。 ちょっとお時間をいただきます。 これは非常に興味深い部分です。 これはぜひ披露したいと思います。 これが拾われるかどうか見てみましょう。 さあ!
PerfMon データ コレクター セットのログ記録
さて、このアプリケーションは、さまざまなオブジェクト サイズを実験できるように設計されていますね。 そして、それに基づいて、パフォーマンス カウンターをログに記録し、オブジェクト サイズがどのように増加してパフォーマンスが低下するかを示します。 したがって、これは実際にアプリケーションでの使用例、通知を受け取る方法、またはアプリケーションの問題が発生したことを知る方法を示しています。 それで、私がやるべきことは、ログ記録を開始することですよね? したがって、ストレス ツールを使用して、キャッシュに接続できるかどうかを確認します。 あとXNUMX分ほどお時間をいただきますので、時間でよろしければお知らせください。 何か問題がございましたら、いつでも対応させていただきます。 それで、私たちはそれについては大丈夫だと思います。 これを実行したところ…つまり、これで実際にアプリケーションが開始されるはずです。 さあ! そして、今度はここで私のマシンを使います。 そして、perf-mon カウンターのログを開始します。そのためには、実際にユーザー コレクター セットを使用できます。 リアルタイム監視のために、perf-mon カウンターがありますよね? 実際にここをクリックして、生活に追加してください。 しかし、それは問題に取り組むためにはまったく役に立ちません。 アプリケーションのパフォーマンスが遅い場合、どう対処すればよいでしょうか?
つまり、データ コレクター セットを作成するだけですよね? テスト11ですよね? 手動で作成し、パフォーマンス カウンターを使用し、サンプリング間隔を XNUMX 秒にして追加します。 NCache これは私のアプリケーションボックスなので、正確にはクライアントカウンターです。 他のものを使用することもできます。 ちょっと付け加えさせてください NCache カウンター、 NCache クライアント。 このテスト キャッシュを開始するために、ストレス ツールをもう一度使用してみましょう。 さあ! 追加すると、応力ツールを閉じて [OK] を選択します。それまでの間、そう願っています... わかりました! これで何かがうまくいきました。
ともかく! したがって、この参照ですぐに「次へ」を選択し、選択できるわかりやすい場所を選択します。たとえば、これを使用して、「OK」、「次へ」、「保存して閉じる」を選択します。 そして、テスト 11 が作成されました。 実際にここに来てコレクター セットを開始することもできますが、その間、何らかの理由で Web アプリケーションが実行されませんでした。 ということで、もう一度だけ実行してみます。 興味深いですね…わかりました! 何が起こったのかを見せようとしています。 実際に実行すべきでした。 それは私が昨日やったことです、そしてそれは完全にうまくいきましたので、一度試してみます。 パイプライン モードに問題があると思うので、これでは実行されないので、これはスキップします。 私にできることは、昨日から使用しているこれのデータをお見せすることです。 それで、ここに来ますと、これは三種類のテストができるような設計になっているんですよね。 10 KB、50 KB、100 KB、および 10 500 KB なので、10 KB オブジェクトを通過すると、実際には 10 KB の Get および Insert の負荷がシミュレートされるため、10 KB、50 KB、100 KB、500 KB、およびそれからカウンターを記録しますね? したがって、E 内で XNUMX つをテストします。
わかった! さあ! そこで、このテストを実行しました。問題を明らかにしたかったので、Ctrl+A を押して、選択したカウンターを非表示にしてからテスト キャッシュを実行すると、実際には他のすべてのカウンターも消費されます。 そこで、まずアイテムの平均サイズを確認します。最初に 1 キロバイト、10 キロバイト、再度 10 キロバイト、次に 50 キロバイト、次に 400 キロバイト、そして最後に向かって 500 キロバイトでテストを実行しました。 それで、アイテムのサイズについて説明します。
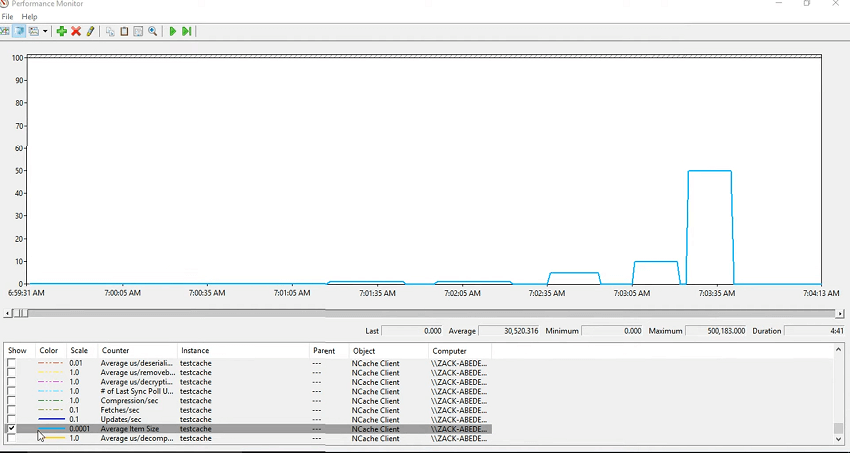
次に、取得に要した平均時間を見てみましょう。 したがって、フェッチあたりの平均マイクロ秒と呼ばれるカウンターがあります。 つまり、一定期間にわたって増加するのに時間がかかったことがわかりますよね? したがって、これは同じであるため、これらをフェッチして同じにし、追加するとアイテムのサイズが増加します。 そのアイテムを取得するのにかかる時間もそれに伴って増加します。 しかし、フェッチしているので、シリアル化解除のオーバーヘッドが発生するはずです。 したがって、それについてはここで説明します。 したがって、ほとんどの時間は実際にはその逆シリアル化に費やされるため、実際に逆シリアル化を並行してプロットすることができます。 したがって、これらはほとんどの時間を逆シリアル化に費やしており、それが遅い理由です。
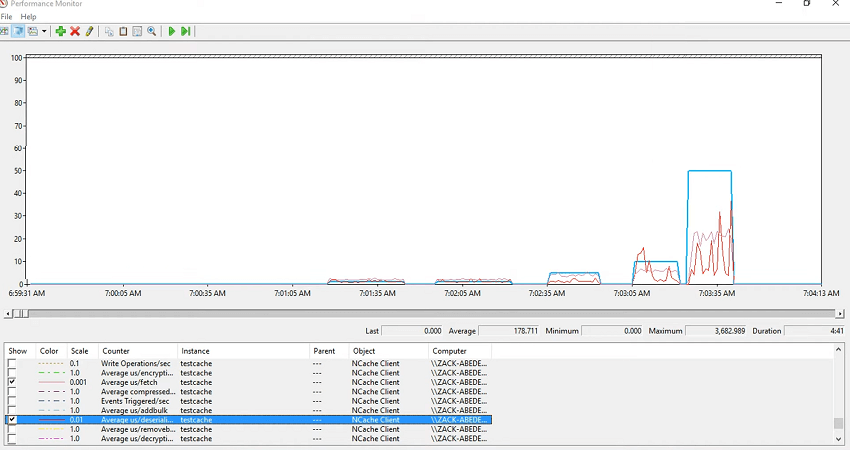
ここで、挿入の平均、挿入あたりの平均マイクロ秒を見てみましょう。これも状況によって変化することがわかります。 そのため、挿入には時間がかかりますが、アイテムのサイズが増加したため、挿入に時間がかかりました。 では、アプリケーションで、アプリケーションの速度が低下していることがわかったら、そうでしょう? したがって、これらのカウンターをログに記録し、シリアル化なのか、逆シリアル化なのか、フェッチなのか、挿入なのか、削除なのか、それとも実際に増加しているリクエスト キュー サイズなのかを確認するだけです。 したがって、アクティビティが発生するたびに、リクエスト キュー サイズにいくつかのアイテムが存在し、それらは処理するたびにクリアされることがわかります。 そこで、挿入の場合、シリアル化あたりの平均マイクロ秒を見てみましょう。これがオーバーヘッドです。 赤く色付けしてみましょう。実際に平均に影響を与えているのは連載であることがわかります。
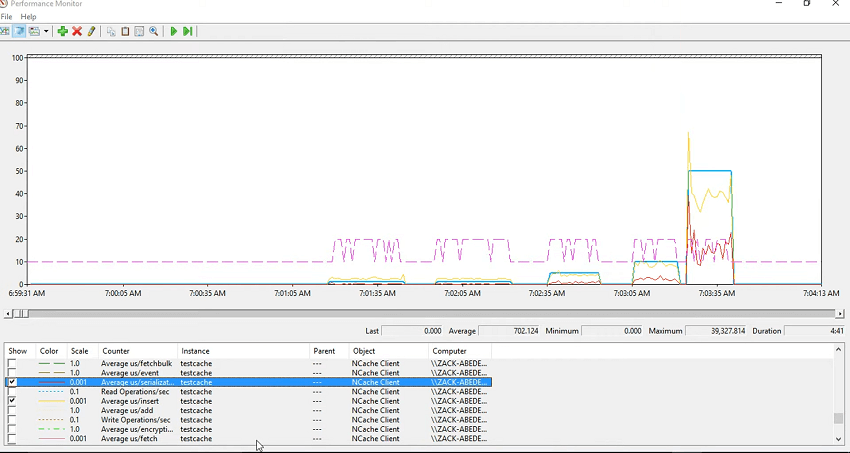
したがって、クライアント側での挿入、フェッチ、削除あたりの全体的な平均マイクロ秒から、アプリケーションが示しているパフォーマンスの推定値が得られ、同時にこれらのカウンターをログに記録してそれを確認することもできます。 残念ながらアプリケーションを実行できませんでしたが、これは昨日のことです。 昨日ウェビナーを開催し、無事に実行できました。また 10 KB、10 KB、50 KB、100 キロバイトで実行しました。 したがって、パフォーマンス間のさまざまな違いがわかります。これは、カウンターをチェックしてキャッシュするパフォーマンスの問題に対処する方法です。これはアプリケーションカウンターと組み合わせる必要があるため、アプリケーションカウンターも常に一緒に選択する必要があります。
たとえば、Web アプリケーションの ASP.NET カウンターを確認できますよね。 ASP.NET アプリケーション。 通常、.NET CLR メモリの場合は、アプリケーションがダウンする可能性のあるメモリ競合があるかどうかも確認します。 したがって、システムカウンターをログに記録してから、 NCache 私と同じようにカウンターを作成し、そこからそれを取得することで、パフォーマンス監視セクションは完了です。
まとめ
通常のタイムマークを約 XNUMX 分上回っています。 問題があるので大丈夫だと思います。 これは実践的なウェビナーであるため、このような問題が発生することが予想されますが、要約すると、キャッシュの作成について説明しました。 NCache 監視ツール、健全性、イベント ログ エントリ、電子メール アラート、 NCache ログ、ログ アナライザー ツール、クライアント側 API ログ、そしてサーバー側で利用できる perf-mon カウンターも紹介しました。 サーバー側のカウンターはサーバー側の統計のために存在し、クライアント側のカウンターはクライアント側の統計のために存在します。 これらのカウンターの説明にはあまり時間を費やしませんでした。 そうすべきでしたが、同じトピックに関する次回のウェビナーでそれを行うつもりです。
そして、最後のほうでは、スパイクを使用するか、perf-mon カウンターのロギングを使用して、問題を特定する方法を説明しました。 NCache。 有益だったのでよかったと思います、面白かったです。