NCache パフォーマンスベンチマーク
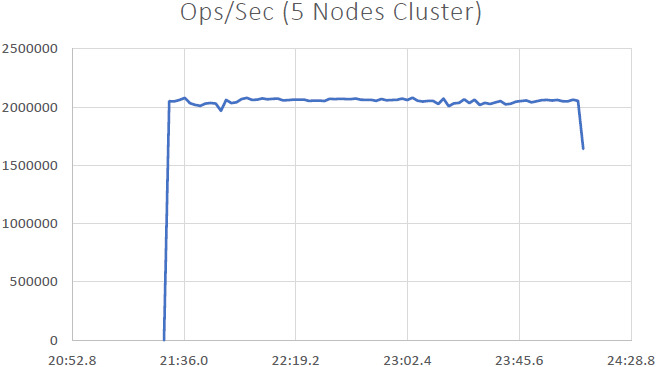
2万Ops/秒
(5ノードクラスター)
エグゼクティブサマリー
NCache 線形にスケーリングし、パフォーマンスを簡単かつコスト効率よく向上させるのに役立ちます。 世界中のフォーチュン500企業が信頼しています NCache 13年以上にわたり、データストレージとデータベースに関連するパフォーマンスのボトルネックを取り除き、.NETアプリケーションを極端なトランザクション処理(XTP)に拡張しました。
このドキュメントでは NCache 最新のAPIといくつかの新機能を備えた5.0は、.NETアプリケーションで実現できる線形スケーラビリティと卓越したパフォーマンスを実証します。 この実験では、モデムをバンドルしました NCache パイプライニングが有効になっているパーティション化されたキャッシュトポロジを備えたAPI。 データはすべてのキャッシングサーバーに完全に分散され、クライアントは読み取りおよび書き込み要求のためにすべてのサーバーに接続します。
このベンチマークでは、 NCache クラスターは線形にスケーリングでき、達成しました 2つのキャッシュサーバーノードのみを使用した5秒あたりXNUMX万トランザクション。 また、次のことを示します NCache 大規模なクラスターでもサブマイクロ秒の遅延を実現できます。 このホワイトペーパーでは、ベンチマーク設定、ベンチマークを実行するための手順、構成のテスト、構成のロード、および結果について説明します。 これで実際のベンチマーク実験を見ることができます ビデオ.
ベンチマーク設定の概要
ベンチマークの設定を確認しましょう。 このテストでは、AWSm4.10xlargeサーバーを使用します。 これらのうちXNUMXつがあります NCache キャッシュクラスターを構成するサーバー。 15台のクライアントサーバーがあり、そこからアプリケーションを実行してこのキャッシュクラスターに接続します。
オペレーティングシステムとしてWindowsServer2016を使用します– Data Center Edition、64ビット。 The NCache 使用されているバージョンは5.0Enterpriseです。 このベンチマーク設定では、 パーティション化されたキャッシュトポロジ。 パーティション化されたキャッシュトポロジでは、すべてのデータがすべてのキャッシュサーバー上のパーティションに完全に分散されます。 また、すべてのクライアントは、すべてのサーバーを同時に利用するための読み取りおよび書き込み要求のためにすべてのサーバーに接続されます。 このトポロジではレプリケーションがオンになっていませんが、次のような他のトポロジがあります。 パーティション化されたレプリカトポロジ レプリケーションサポートが装備されています。
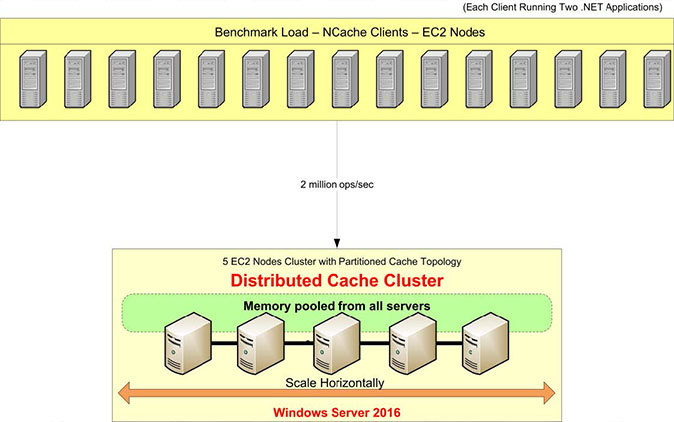
私たちは パイプライン の新機能である有効 NCache 5.0。 これは、クライアント側で実行時に発生するすべての要求を蓄積し、それらの要求をサーバー側で一度に適用するように機能します。 蓄積はマイクロ秒単位で行われるため、非常に最適化されており、トランザクション負荷が高い場合に推奨される構成です。
これは、ハードウェア、ソフトウェア、および負荷構成を含むベンチマーク設定の概要です。
ハードウェア構成:
| クライアントとサーバーの詳細 (仮想マシン) |
AWS m4.10xlarge:40コア、160 GBメモリ、ネットワーク-10Gbpsイーサネット |
| サーバーノードの数 | 5 |
| クライアントノードの数 | 15 |
ソフトウェア構成:
| オペレーティングシステム | Windows Serverの2016 データセンターエディション– x64 |
| NCache | 5.0 |
| クラスタートポロジ | パーティション化されたキャッシュ構成 |
ロード設定:
| キャッシュサイズ | 4 GB |
| データサイズ | サイズ100のバイト配列 |
| Total Items | 1,000,000 |
| パイプライン | 使用可能 |
| 取得/更新比率 | 80:20 |
| スレッド | 1280 |
| アプリケーションインスタンス | クライアントマシンあたり2インスタンス、合計30インスタンス |
データ人口
ベンチマーク環境のセットアップ後、キャッシュクラスター内の1万アイテムのデータ母集団から始めます。 接続してキャッシュに1万アイテムを追加するクライアントアプリケーション(キャッシュアイテムローダー)を実行します。 1つのクライアントがすべてのキャッシングサーバーに接続し、キャッシュクラスターにXNUMX万個のアイテムを追加します。その後、読み取りおよび書き込み要求を開始できます。
あなたはこれを使用することができます Nugetパッケージ– NCache SDK クライアントマシンにSDKをインストールし、クライアントサーバー間のパイプラインを構成し、負荷生成アプリケーション(GitHub)をデプロイして、キャッシュクラスターに1万のキャッシュアイテムを配置します。
トランザクション負荷の構築
次に、アプリケーションを実行して、80%の読み取り操作と20%の書き込み操作で、このキャッシュクラスターにトランザクション負荷を構築します。 Perfmonカウンターを使用してすべてのアクティビティを監視できます。 最初に、10個のクライアントインスタンスをそれぞれに接続します NCache フェッチおよびXNUMX秒あたりの更新に関するアクティビティを備えたサーバー。
ステージ1 1万Ops/秒のトランザクション負荷
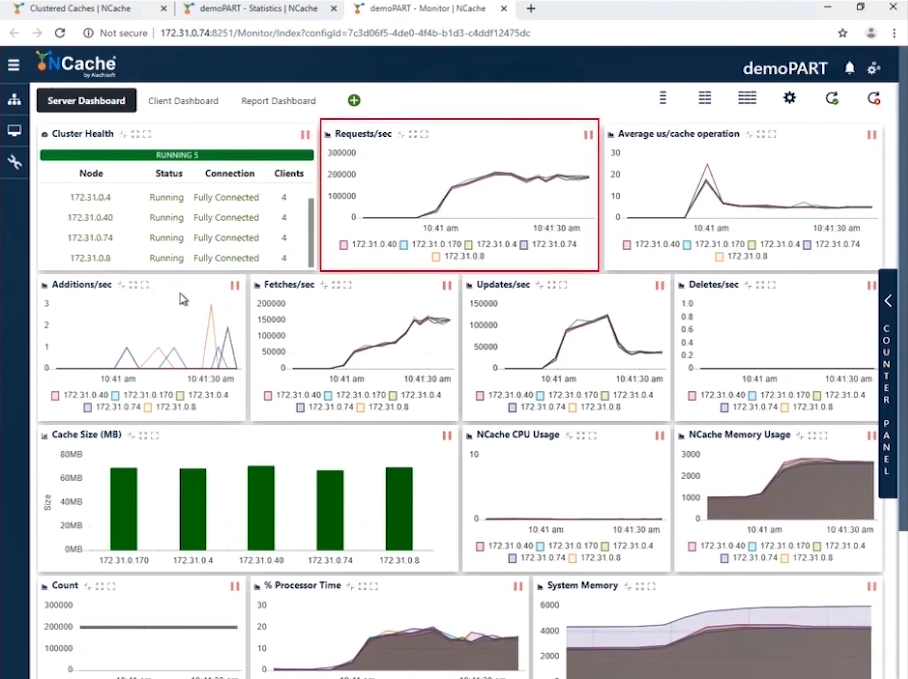
スクリーンショットを見ると、10ノードのクラスターに接続している5個のクライアントインスタンスで、180,000秒あたりのリクエスト数が190,000〜5であることがわかります。 そして私達はXNUMXを持っているので NCache 並行して動作しているサーバーは、これらのリクエストを蓄積すると、このキャッシュクラスターによって1秒あたりXNUMX万リクエストになります。
効率的なメモリとCPUの使用率があり、平均マイクロ秒/キャッシュ操作は操作あたり10マイクロ秒弱です。 ステージ1は、キャッシュクラスターからXNUMX秒あたりXNUMX万回の操作を達成したところで完了します。
| ステージ1-要約データシート | |
| クラスター内の合計キャッシュサーバー | 5 |
| 接続されているクライアントインスタンスの総数 | 10 |
| XNUMX秒あたりのリクエスト数/ノード | 180,0000〜190,000 |
| リクエストの総数-キャッシュクラスター | 950,000〜1,000,000 |
| %プロセッサ時間(最大) | 視聴者の38%が |
| システムメモリ | 4.2 GB |
| レイテンシー(マイクロ秒/キャッシュ操作) | 10マイクロ秒/操作 |
ステージ2 1.5万Ops/秒のトランザクション負荷
1万TPSを達成したので、トランザクションの負荷を増やすために、より多くのアプリケーションインスタンスの形で負荷を増やす時が来ました。 そして、これらのアプリケーションが実行されるとすぐに、20秒あたりのリクエスト数の増加が見られます。 クライアントの数を300,000に増やします。この構成では、下のスクリーンショットで、インスタンスごとに1.5秒あたりXNUMXのリクエストが表示されていることがわかります。 このキャッシュクラスターからXNUMX秒あたりXNUMX万件のリクエストを正常に達成しました。
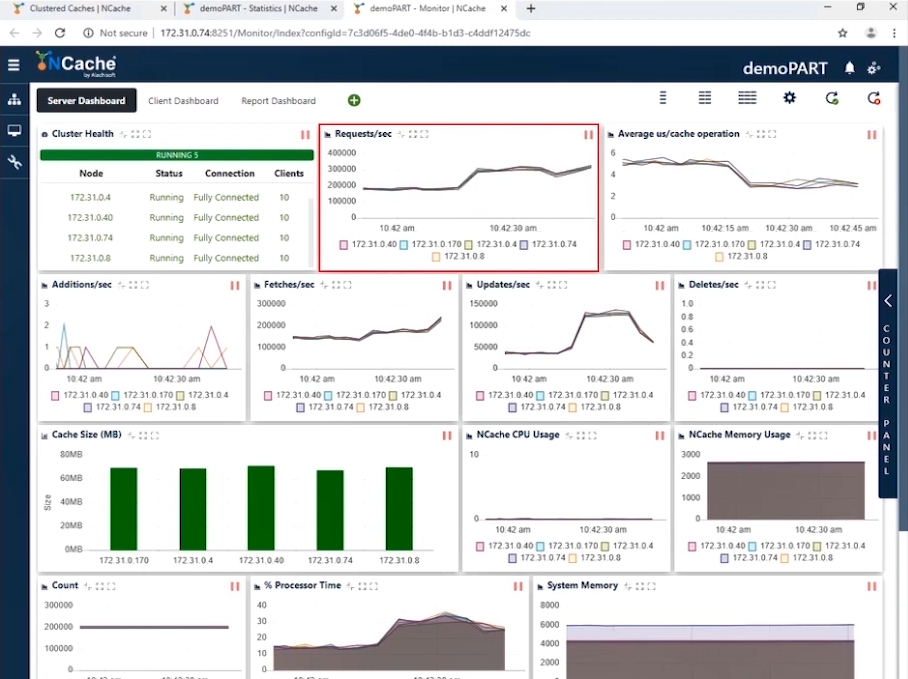
各サーバーによる300,000秒あたりのリクエスト数は200,000であることがわかります。 フェッチは50,000秒あたり100,000を少し超え、更新は4〜3であり、キャッシュ操作あたりの平均マイクロ秒は4マイクロ秒未満であることがわかります。 パイプラインの影響に加えてレイテンシーが非常に低いため、これは驚くべきことです。 クライアント側からのトランザクション負荷が高い場合、パイプライン処理はレイテンシーを大幅に削減し、スループットを向上させます。 これが、これをオンにすることをお勧めする理由です。 さらに、キャッシュ操作あたりの平均マイクロ秒は、キャッシュ操作あたり約XNUMX〜XNUMXマイクロ秒になりました。
| ステージ2-要約データシート | |
| クラスター内の合計キャッシュサーバー | 5 |
| 接続されているクライアントインスタンスの総数 | 20 |
| 平均XNUMX秒あたりのリクエスト数/ノード | 300,000 |
| リクエストの総数-キャッシュクラスター | 1,500,000 |
| %プロセッサ時間(最大) | 視聴者の38%が |
| システムメモリ | 6 GB |
| レイテンシー(マイクロ秒/キャッシュ操作) | 3〜4マイクロ秒/操作 |
ステージ3 2万Ops/秒のトランザクション負荷
さらにいくつかのアプリケーションインスタンスを実行して負荷をさらに増やしましょう。これにより、30秒あたりのリクエスト数もさらに増加します。 XNUMXのクライアントのインスタンスをすべてに接続します NCache サーバー。
以下のスクリーンショットのように、400,000秒あたりXNUMX万件のリクエストに正常にアクセスしたことがわかります。 NCache サーバ; 5つあります NCache これにより、XNUMX秒あたり最大XNUMX万トランザクションの数になるサーバー NCache キャッシュクラスター。 また、キャッシュ操作あたりの平均マイクロ秒数は3マイクロ秒未満です。 また、システムメモリとプロセッサ時間は制限をはるかに下回り、両方の面で40〜50%の使用率があります。
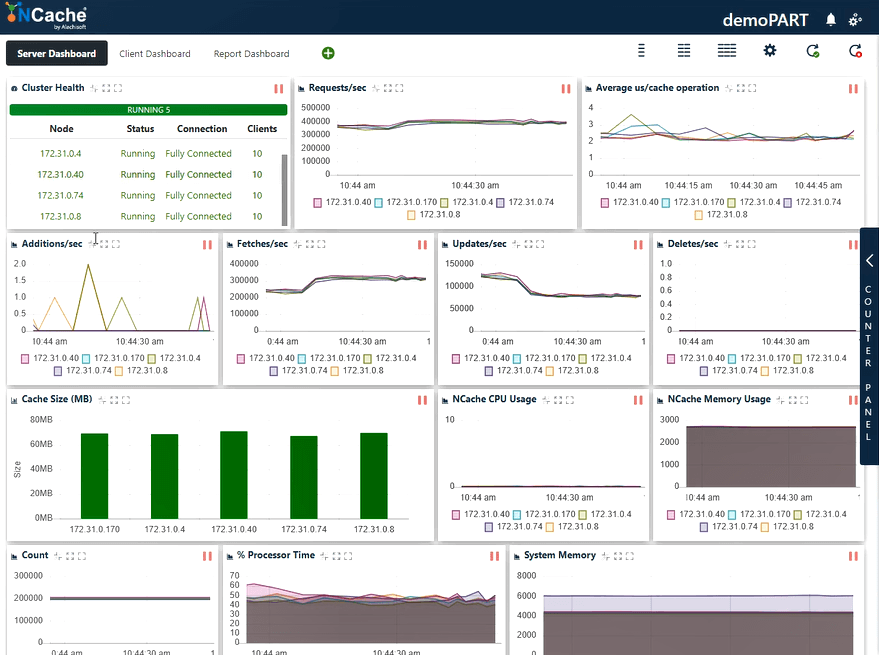
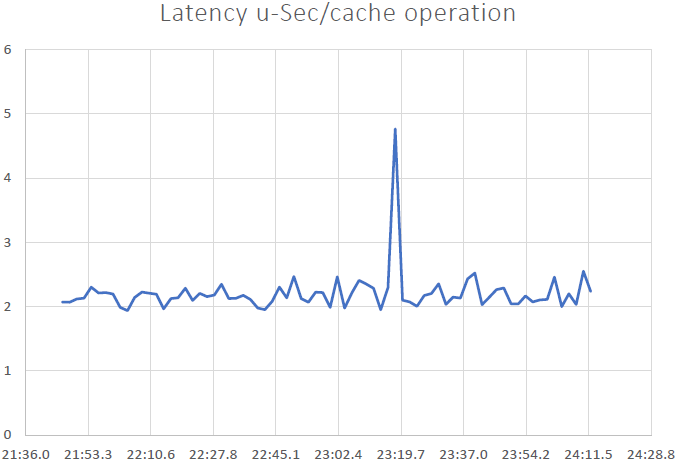
これで、2〜3 us /操作のレイテンシーが得られ、以前の結果から改善されました。 フェッチ、更新、およびCPUとメモリリソースの効率的な使用の組み合わせをもう一度確認できます。 ここで、次のように結論付けることができます。 NCache 線形にスケーラブルです。 それでは、スケーラビリティの数値を確認しましょう。
| ステージ3-要約データシート | |
| クラスター内の合計キャッシュサーバー | 5 |
| 接続されているクライアントインスタンスの総数 | 30 |
| 平均XNUMX秒あたりのリクエスト数/ノード | 400,000 |
| リクエストの総数-キャッシュクラスター | 2,000,000 |
| %プロセッサ時間(最大) | 視聴者の38%が |
| システムメモリ | 6 GB |
| レイテンシー(マイクロ秒/キャッシュ操作) | 2〜3マイクロ秒/操作 |
ベンチマーク結果
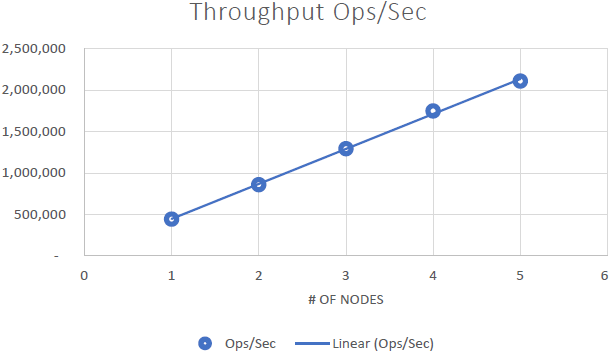
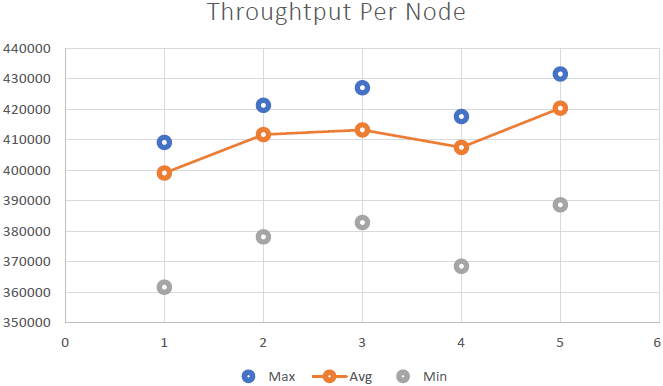
私たちはそれを実証することができました NCache は線形にスケーラブルであり、ベンチマークを実行した後、次の結果を達成することができました。
結論
- 線形スケーラビリティ: 5で NCache サーバーでは、2秒あたりXNUMX万件のリクエストを達成できました。 サーバーを追加するということは、 NCache.
- 低レイテンシと高スループット: NCache クラスターサイズが大きい場合でも、サブマイクロ秒(2.5〜3マイクロ秒)の遅延を実現します。 NCache 大規模な場合でも、低遅延と高スループットの要件を満たすのに役立ちます。 レイテンシーは非常に低く、パイプラインによる影響があります。 クライアント側からのトランザクション負荷が高い場合、パイプライン処理はレイテンシーを大幅に削減し、スループットを向上させます。