분산 캐시에서 관계형 데이터 처리
녹화된 웨비나
론 후세인과 아담 J. 켈러
이 비디오 웨비나에서는 분산 캐싱을 위해 기존 데이터 관계를 캐시 개체에 적용하는 방법을 알아봅니다.
다음에 대해 듣게 될 것입니다.
- 관계형 데이터베이스 및 분산 캐시용 데이터 스토리지 모델
- 개체 관계 매핑의 장점 – 개체 수준에서 데이터 관계를 관리하는 방법
- '일대일', '일대다' 및 '다대다' 관계 매핑
- 사용 NCache 관계형 데이터 동작을 모방하기 위해 개체 간의 관계를 구축하는 기능
- 키 기반 종속성, 개체 쿼리 언어, 그룹, 그룹 API, 컬렉션 및 태그 사용
- 관계형 데이터를 위한 기타 중요한 분산 캐싱 기능
분산 캐싱을 사용하는 방법에 대해 이야기하겠습니다. 관계형 데이터베이스가 있는 경우 몇 가지 문제, 성능 문제, 확장성 문제가 있으며 관계형 데이터베이스와 함께 분산 캐시를 사용하도록 전환합니다. 어떤 문제가 있고 이러한 문제를 관리하는 방법은 무엇입니까? 이것이 오늘 웨비나의 안건입니다.
꽤 손이 많이 갈 것입니다. 몇 가지 코드 예제를 보여드리고 싶습니다. 몇 가지 실제 사례에 대해 이야기하겠습니다. 실제로 이것을 시연하기 위해 사용할 몇 가지 예가 준비되어 있습니다. 그리고 마지막에는 몇 가지 기본 사항을 살펴보는 실습 부분도 있습니다. NCache 구성.
NCache, 이것이 주요 분산 캐싱 제품입니다. 이 특정 웨비나의 예제 제품으로 사용할 것입니다. 그러나 전반적으로 일반적인 주제 웨비나입니다. 데이터베이스에 관계형 데이터가 있고 분산 캐시가 있습니다. 관계가 있고 구조화된 데이터인 관계형 데이터 내에서 분산 캐시를 전환하고 사용을 시작하는 방법. 자, 이것을 살펴봅시다.
확장성이란 무엇입니까?
그래서 먼저 확장성의 개념인 확장성에 대해 말씀드리겠습니다. 확장성은 트랜잭션 부하를 증가시킬 수 있는 애플리케이션 내의 기능입니다. 애플리케이션 아키텍처에서 점점 더 많은 요청을 처리할 수 있는 곳. 그리고 성능과 타협하지 않습니다. 따라서 높은 처리량과 짧은 대기 시간이 있는 경우 해당 기능을 확장성이라고 합니다. 따라서 엄청난 양의 요청 로드를 처리할 수 있으며 개별 요청 성능이 저하되지 않습니다. 똑같다! 그리고 더 많은 리소스를 사용하면 이를 늘릴 수도 있으며 선형 확장성은 더 많은 서버를 추가하여 시스템에 더 많은 요청 로드 처리 용량이 도입된 곳에서 실제로 확장할 수 있는 관련 용어입니다. 그리고 대부분의 경우 성능이 저하되지 않습니다.
따라서 대기 시간이 짧고 요청 부하가 선형적으로 개선된 경우 이전에는 초당 10,000개의 요청을 처리했거나 XNUMX명의 사용자에 대해 일정량의 대기 시간이 있는 경우 XNUMX명의 사용자에 대해 몇 밀리초 또는 밀리초 미만의 응답 시간이 있습니다. ; XNUMX명의 사용자 또는 XNUMX명의 사용자에 대해 동일한 종류의 응답과 동일한 종류의 대기 시간을 수행해야 합니다. 그리고 사용자 로드 및 관련 요청 로드를 계속 증가시키는 기능을 선형 확장성이라고 합니다.
어떤 앱에 확장성이 필요합니까?
따라서 확장성이 필요한 일반적인 응용 프로그램은 무엇입니까?

이는 ASP.NET 웹 응용 프로그램, Java 웹 응용 프로그램 또는 공용인 .NET 일반 웹 응용 프로그램이 될 것입니다. 그것은 전자 상거래 시스템일 수도 있고, 항공권 발권 시스템, 예약 시스템일 수도 있고, 많은 사용자가 실제로 공공 서비스를 사용하는 금융 서비스나 의료 서비스일 수도 있습니다. 웹 서비스 WCF 또는 일부 데이터 액세스 계층과 상호 작용하거나 일부 프런트 엔드 애플리케이션을 처리하는 다른 통신 서비스일 수 있습니다. 그러나 특정 시점에 수백만 건의 요청을 처리할 수 있습니다. 사물 인터넷, 일부 작업이 해당 장치에 대해 데이터를 처리할 수 있는 일부 백엔드 장치일 수 있습니다. 따라서 많은 요청이 로드될 수 있습니다. 요즘 유행하는 빅 데이터 처리는 작고 저렴한 컴퓨팅 서버가 많고 여러 서버에 데이터를 배포하여 실제로 엄청난 양의 데이터 로드를 처리합니다.
마찬가지로 해당 특정 데이터에 대한 엄청난 모델 요청 로드가 있을 것입니다. 그런 다음 수백만 건의 요청, 많은 사용자를 처리할 수 있는 다른 일반 서버 응용 프로그램 및 계층 응용 프로그램이 확장성의 주요 후보가 될 수 있습니다. 아키텍처 내에서 확장성이 필요한 애플리케이션입니다.
확장성 병목 현상
이것은 일반적인 다이어그램입니다. 확장성 병목 현상은 무엇입니까?
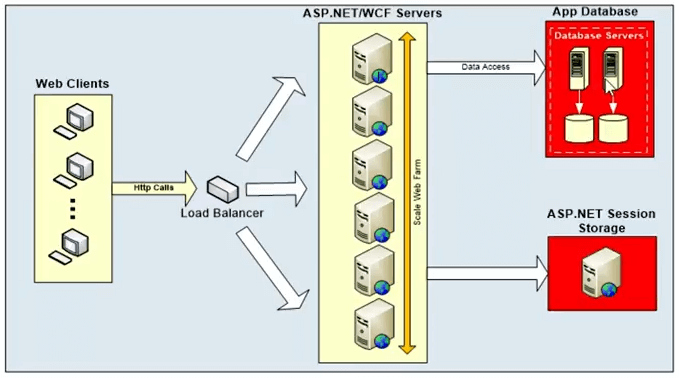
그래서 이것들은 응용 프로그램입니다. 설계상 이러한 프레임워크는 매우 확장 가능합니다. ASP.NET 웹 양식 또는 WCF 양식에는 이러한 시스템을 확장하는 데 사용할 수 있는 옵션이 있습니다. 그러나 그들은 모두 백엔드 데이터베이스와 통신하며 일반적으로 관계형 데이터베이스입니다. 또한 ASP.NET 세션 저장소, 메인프레임 또는 파일 시스템일 수도 있지만 오늘 웨비나에서 다루는 내용은 아닙니다. 오늘의 웨비나는 관계형 데이터에 더 중점을 둡니다. 따라서 관계형 데이터는 단일 소스입니다. 바로 여기에 매우 확장 가능한 플랫폼이 있지만. 이 계층에 점점 더 많은 서버를 추가할 수 있습니다. 로드 밸런서를 앞에 배치하여 확장할 수 있으며 해당 로드 밸런서는 다른 서버 간에 요청을 라우팅할 수 있습니다. 그러나 이러한 모든 웹 서버는 결국 확장성이 없는 데이터베이스 계층과 통신하게 됩니다.
그래서 그것은 논쟁의 원천이 될 것입니다. 시작 속도가 느리고 확장할 수 없습니다. 요청 용량을 늘리기 위해 점점 더 많은 데이터베이스 서버를 추가하는 옵션이 없는 단일 소스입니다. 따라서 요청 용량이 최대가 되어 대기 시간이 길어질 수 있습니다. 따라서 요청 처리에 대한 용량 문제이며 대기 시간 문제로 끝날 수 있으므로 요청 로드가 많을 때 시스템을 질식시킬 수 있습니다.
솔루션
이것이 관계형 데이터 소스의 주요 문제이며 이에 대한 솔루션은 분산 캐시를 사용하기 시작하는 것이 매우 간단합니다.
다음과 같은 분산 캐싱 시스템 NCache 비교할 때 인 메모리이기 때문에 초고속이며 선형 확장이 가능합니다. 단일 서버가 아닙니다. 서버 팀이 하나의 용량으로 결합된 다중 서버 환경입니다. 메모리 용량과 트랜잭션 용량을 풀링하고 매우 선형적으로 확장 가능한 모델을 얻습니다. 그리고, NCache 데이터베이스 확장성 문제를 처리하는 데 사용할 수 있는 바로 그런 종류의 솔루션입니다.
메모리 내 분산 캐시란 무엇입니까?
일반적인 인 메모리 분산 캐싱 시스템은 무엇입니까? NCache? 특징은 무엇입니까?
여러 저렴한 캐시 서버의 클러스터
논리적 용량으로 결합되는 여러 저렴한 캐시 서버의 클러스터가 될 것입니다.
그래서 이것은 그 예입니다. XNUMX~XNUMX개의 캐싱 서버가 있을 수 있습니다. 을 위한 NCache, Windows 2008, 2012 또는 2016 환경을 사용할 수 있습니다. 에 대한 전제 조건 NCache .NET 4입니다. 애플리케이션과 데이터베이스 사이의 중간 계층이며 데이터베이스 계층과 비교할 때 매우 확장 가능하지만 속도 향상 .NET 웹에서 얻을 수 있는 동일한 종류의 확장성을 제공합니다. 양식 또는 WCF 웹 서비스 웹 양식.
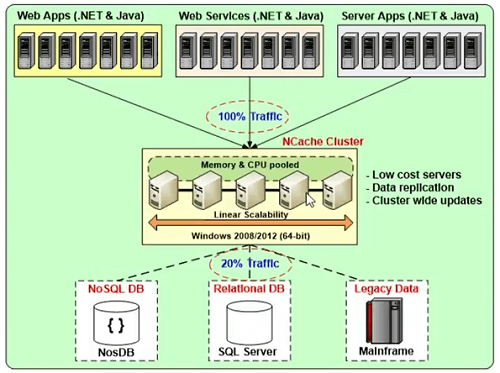
모든 캐시 서버에서 캐시 업데이트를 동기화합니다.
데이터 일관성이 프로토콜에 내장되도록 모든 캐시 서버에서 캐시 업데이트를 동기화합니다. 모든 업데이트는 연결된 모든 클라이언트에 대한 일관된 데이터 보기를 이해하여 자동 방식으로 적용됩니다.
트랜잭션 및 메모리 용량을 선형적으로 확장
트랜잭션과 메모리 용량에 대해 선형적으로 확장해야 합니다. 단순히 서버를 더 추가하면 용량이 늘어나지 않아야 합니다. 두 대의 서버가 있고 세 번째와 네 번째 서버를 추가하면 서비스 양이 두 배로 늘어났으므로 기본적으로 해당 시스템의 용량이 두 배가 됩니다. 그래서, 그게 NCache 뿐만 아니라 제공합니다.
신뢰성을 위해 데이터 복제
그런 다음 복제는 안정성을 위한 또 다른 기능입니다. 다운되는 모든 서버는 무엇보다도 데이터 손실이나 중단 시간이 없어야 합니다. 고가용성 고신뢰성 시스템이어야 하고 그것이 바로 NCache 돌보다.
NCache 전개
따라서 관계형 데이터 소스 및 다음과 같은 분산 캐싱 시스템에 확장성 문제가 있다고 논의했습니다. NCache 이에 대한 솔루션이며 애플리케이션과 데이터베이스 사이의 중앙 계층이 되며 데이터는 두 위치에 존재합니다.
데이터베이스에 데이터가 있고 분산 캐시에 데이터가 있습니다. 그럼 NCache 또한 두 개의 서로 다른 소스에 데이터가 있을 때 발생할 수 있는 몇 가지 동기화 문제를 관리합니다. 이 주제에 대한 별도의 웨비나가 있지만 일부 데이터 액세스 계층 공급자가 있음을 알려드리기 위해 설정할 수 있는 몇 가지 변경 알림 종속성이 있습니다.
따라서 데이터베이스의 모든 변경 사항은 캐시 항목의 무효화 또는 업데이트를 트리거할 수 있으며 마찬가지로 캐시에서 발생하는 모든 변경 사항 또는 업데이트를 데이터베이스에 적용할 수 있습니다. 따라서 이는 데이터 액세스 계층 공급자의 도움으로 달성할 수 있습니다. Read-through 및 Write-through.
그리고 데이터베이스와 캐시 레코드 사이의 100% 동기화를 보장하기 위해 실제로 사용한 일부 데이터베이스 변경 종속성, 레코드 변경 종속성도 있습니다. 그러나 일반적으로 데이터는 서로 다른 두 위치에 존재합니다. 일반적으로 데이터의 하위 집합인 캐시에 데이터가 있고 데이터베이스에 실제 데이터가 있습니다. 데이터 마이그레이션은 기본적으로 데이터 마이그레이션입니다. 이 두 소스를 서로 조합하여 사용하고 있지만 이들은 서로 다른 두 소스입니다.
캐시할 데이터는 무엇입니까?
계속 진행하기 전에 캐시할 수 있는 데이터 유형에 대해 빠르게 이야기하겠습니다. 참조 데이터일 수도 있고 트랜잭션 데이터일 수도 있습니다.

일반적으로 관계형 데이터베이스에 속해 캐시하는 읽기 집약적인 데이터에 가깝습니다. 변하지 않는 것이 아니라 100% 정적이 아닙니다. 데이터를 변경하고 있지만 해당 변경의 빈도는 그리 크지 않습니다. 따라서 참조 데이터로 분류됩니다. 그리고 매우 자주 변경되는 트랜잭션 데이터입니다. 몇 초, 몇 분 또는 경우에 따라 몇 밀리초일 수도 있습니다.
그리고 대부분의 캐시된 데이터는 관계형입니다. 그것은 관계형 데이터베이스에서 가져온 것이고 관계형 데이터베이스에 마스터 복사본의 데이터가 있고 분산 캐시로 가져온 해당 데이터의 하위 집합인 참조 및 트랜잭션이 있다고 이미 논의했습니다. 오른쪽!
도전 과제는 무엇입니까?
그렇다면 도전 과제는 무엇입니까? 그럼 실제로 그 문제에 대해 논의해 봅시다! 시스템에 대한 성능과 확장성 및 안정성을 향상시키기 위해 데이터 원본에서 분산 캐시로의 관계로 데이터를 이동할 때. 여러분이 보고 있는 문제가 무엇인지 실제로 빠르게 논의해 봅시다.

아주 잘 작동합니다. 메모리에 있기 때문에 성능이 향상됩니다. 선형 확장 가능하므로 데이터베이스의 확장성 문제를 처리합니다. 여러 서버가 있고 모든 서버를 다운시킬 수 있기 때문에 단일 실패 지점이 아닙니다. 문제 없이 서버를 불러올 수 있습니다. 유지보수가 훨씬 쉬워집니다. 업그레이드가 훨씬 쉬워집니다. 따라서 비교하면 많은 이점을 얻을 수 있습니다. 그러나 데이터를 마이그레이션하거나 데이터베이스에서 분산 캐시로 데이터를 이동하고 분산 캐싱 시스템 사용을 시작할 때 해결해야 하는 한 가지 문제가 있으며 이를 고려해야 합니다.
따라서 분산 캐시는 인터페이스와 같은 해시 테이블입니다. 오른쪽! 각 항목은 키와 값으로 구분되어 있죠? 따라서 캐시에 있는 각 항목이나 캐시에 있는 각 항목 또는 캐시에 있는 레코드가 키의 도움으로 표현되는 해시 테이블입니다. 따라서 테이블이 아니거나 관계가 있는 관계형 데이터가 아닙니다. 스키마를 정의하고 서로 간에 적절한 관계를 갖는 엔터티가 있습니다. 캐시의 개체를 나타내는 별도의 키 값 항목이 됩니다. 따라서 데이터베이스에는 엔터티 간의 관계가 있으며 데이터를 마이그레이션하거나 관계형 데이터베이스에서 분산 캐시로 데이터를 이동할 때 해당 데이터의 관계 특성이 손실됩니다.
따라서 기본적으로 해당 기능이 없으므로 제거할 수 있습니다. 이것이 주요 과제 중 하나이며 데이터베이스 쿼리가 개체 모음으로 이어지는 몇 가지 다른 관련 과제가 있습니다. 또한 데이터 테이블 또는 데이터 판독기로 연결됩니다. 따라서 분산 캐시에서 데이터 테이블과 데이터 판독기를 처리하는 것은 좋은 생각이 아닙니다. 그래서 우리는 실제로 이러한 모든 도전을 하나씩 겪게 될 것입니다.
주로 관계형 데이터 소스에서 캐시로 데이터를 가져온 후 분산 캐시에서 관계를 관리하는 방법에 대해 자세히 설명합니다.
엿보기 NCache API
다음으로 캐싱 API에 대해 이야기하겠습니다.

기본적으로 키 값 저장소라고 논의했습니다. 우리는 "mykey" 키가 있는 cache.add를 가지고 있으며 허용된 데이터 및 허용된 직렬화된 객체인 객체를 가지고 있습니다. 고객 개체, 제품 개체, 주문 개체가 될 수 있습니다. 그러나 이것은 cache.add, cache.update를 사용하여 키 값 메서드를 호출하는 매우 간단한 hello world 종류의 예입니다. 마찬가지로 cache.get을 호출하여 동일한 항목을 다시 가져온 다음 cache.remove를 호출합니다.
캐시에서 관계 관리
계속! 그렇다면 캐시에서 관계를 관리하는 방법은 무엇입니까? 이제 우리는 캐시가 키 값 쌍인 인터페이스와 같은 해시 테이블이라는 이 문제를 정의했습니다. 값은 .NET 개체이고 키는 형식을 지정하는 문자열 키이며 이들은 서로 독립적인 개체입니다. 그리고 데이터베이스에는 서로 관계가 있는 관계 테이블이 있습니다. 서로 다른 테이블 간의 일대일 일대다 및 다대다 관계일 수 있습니다.
첫 번째 단계: 캐시 종속성 사용
먼저 캐시 종속성 사용을 고려해야 하는 두 가지 사항이 있습니다. 우리는 주로 기능 중 하나인 키 기반 종속성에 중점을 둡니다. 캐시 항목 간의 단방향 종속성을 추적합니다.

따라서 하나의 부모 개체를 가질 수 있고 그 특정 개체에 종속 개체를 가질 수 있습니다. 그리고 그것이 작동하는 방식은 한 항목이 다른 항목에 의존한다는 것입니다. 기본 항목, 기본 개체 또는 상위 개체 변경을 거치면 업데이트되거나 제거됩니다. 종속 항목은 자동으로 캐시에서 제거됩니다.
다음 슬라이드에 나열한 전형적인 예는 특정 고객에 대한 주문 목록입니다. 따라서 고객 A가 있습니다. 주문 목록(예: 100개의 주문)이 있고 해당 고객이 업데이트되거나 캐시에서 제거되면 어떻게 됩니까? 이와 관련된 주문이 필요하지 않으므로 해당 주문 수집과 관련하여 무언가를 수행하고 싶을 수 있습니다. 이것이 바로 이 종속성이 필요한 이유입니다. 이 두 레코드는 관계형 데이터베이스.
그런 다음 이 종속성은 A가 B에 종속되고 B가 C에 종속되는 본질적으로 캐스케이드될 수 있습니다. C의 모든 변경 사항은 B의 무효화를 트리거하고 A도 무효화합니다. 따라서 계단식 종속성이 될 수 있고 다중 항목 종속성일 수도 있습니다. 하나의 항목은 항목 A와 항목 B에 종속될 수 있으며 유사하게 하나의 상위 항목도 여러 하위 항목을 가질 수 있습니다. 그리고 이것은 ASP.NET 캐시에 의해 처음 도입된 기능이었습니다. 강력한 기능 중 하나였습니다. NCache 또한 가지고 있습니다. 우리는 이를 별도의 캐시 종속성 개체와 멋진 개체 중 하나로 제공하며 이것이 이 특정 웨비나에서 주요 초점이 될 것입니다.
두 번째 단계: 개체 관계형 매핑 사용
두 번째 단계는 관계형 데이터를 매핑하기 위해 실제로 도메인 개체를 데이터 모델에 매핑해야 한다는 권장 사항이 하나 더 있습니다.

따라서 도메인 개체는 데이터베이스 테이블을 나타내야 합니다. 일종의 O/R 매핑을 사용해야 하며 일부 O/R 매핑 도구를 사용할 수도 있습니다. 데이터베이스 테이블에 클래스를 매핑하면 코드를 재사용할 수 있어 프로그래밍이 간소화됩니다. Entity framework 및 NHibernate와 같은 ORM 또는 O/R 매핑 도구도 사용할 수 있습니다. 이들은 인기있는 도구가 거의 없습니다.
여기서 아이디어는 애플리케이션에 클래스가 있어야 한다는 것입니다. 응용 프로그램의 개체, 도메인 개체입니다. 따라서 데이터베이스 개체, 데이터 테이블 또는 데이터 판독기가 변환되어 도메인 개체에 매핑됩니다. 따라서 고객 테이블은 애플리케이션의 고객 클래스를 나타내야 합니다. 마찬가지로 정렬된 컬렉션 또는 주문 테이블은 주문 클래스와 애플리케이션을 나타내야 합니다. 그런 다음 분산 캐시에서 처리 및 저장하고 키 종속성의 도움으로 관계를 공식화하는 개체입니다.
관계 처리 예
예를 들어 봅시다!
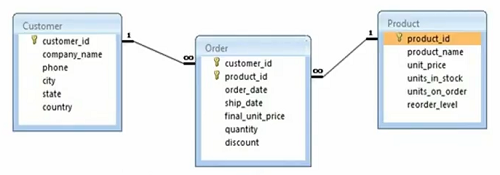
그리고 Northwind의 데이터베이스 모델이 있습니다. 고객 테이블, 주문 테이블, 제품이 있습니다. 고객 ID, 회사 이름, 전화번호, 도시, 주, 국가, 일부 속성이 있는 고객의 모든 열 이름이 있습니다. 마찬가지로 제품 ID, 이름, 가격, 재고 단위, 주문 단위, 재주문 수준이 있는 제품이 있습니다. 그래서 그것들은 제품의 일부 속성 또는 일부 열이며 외래 키로 고객 ID 및 제품 ID가 있는 주문 테이블도 있습니다. 그것은 복합 기본 키를 공식화하고 주문 날짜, 배송 날짜 및 주문 자체의 일부 속성을 갖습니다. 고객과 주문 사이에는 일대다 관계가 있고 제품과 주문 사이에는 일대다 관계가 있습니다. 마찬가지로 주문과 고객, 주문과 제품 사이에 각각 다대일과 다대일이 있습니다. 따라서 이 특정 시나리오를 다룰 것입니다.
처음에는 두 개의 일대다 관계로 정규화된 고객 제품 다대다 관계였습니다. 따라서 이것은 정규화된 데이터 모델이며 이 특정 데이터 모델에 매핑된 기본 개체에 클래스가 있는 예를 사용할 것입니다. 그래서 우리는 기본 개체에 대해 조금 이야기할 것이지만 여기에서 예를 간단히 보여드리겠습니다.
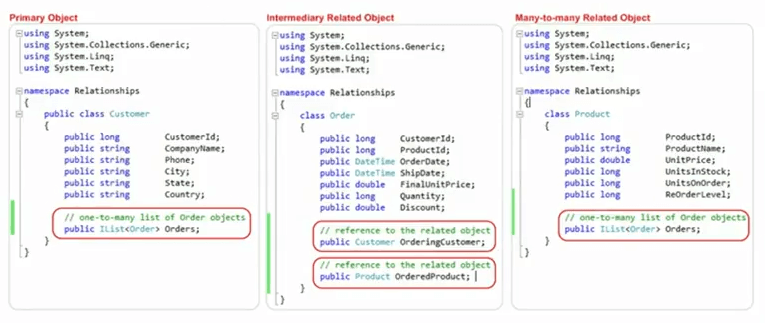
데이터베이스 모델에 매핑된 도메인 객체에 주목하십시오. 동일한 예에서 기본 키로 사용될 고객 ID가 있는 고객 클래스가 있고 주문 클래스와 너무 많은 관계를 나타내는 주문 컬렉션이 있습니다. 마찬가지로 제품 ID, 이름, 단가와 같은 제품 속성을 가진 제품이 있습니다. 맞습니까? 그런 다음 일대다 관계를 나타내는 주문 모음도 있습니다. 주문 측에는 여기에서 가져온 고객 ID가 있고 여기에서 가져온 제품 ID가 있습니다. 그런 다음 주문 고객, 다대다 고객이 있습니다. 하나의 관계 다음에는 도메인 개체의 일부로 캡처된 다대일 관계로 제품을 주문합니다.
그래서 이것은 다음 슬라이드에서 매우 자세하게 다룰 기술 중 하나입니다. Visual Studio 내에서도 이러한 개체를 보여 드리겠습니다. 이것이 클래스 중 하나입니다.
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.Runtime;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Alachisoft.NCache.Runtime.Dependencies;
using System.Collections;
namespace Relationships
{
public class Customer
{
public long CustomerId;
public string CompanyName;
public string Phone;
public string City;
public string State;
public string Country;
// one-to-many list of Order objects
public IList<Order> Orders;
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// Let's cache each product as seperate item. Later
// we'll search them through OQL
foreach (Product product in products)
{
string productKey = "Product:ProductId:" + product.ProductId;
cache.Add(productKey, product, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
cache.GetGroupData("DummyGroup", "DummySubGroup");
cache.GetByTag(new Alachisoft.NCache.Runtime.Caching.Tag("DummyTag"));
}
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string query = "SELECT Relationships.Product WHERE this.UnitPrice >= ?";
Hashtable values = new Hashtable();
values.Add("UnitPrice", unitPrice);
ICacheReader products = cache.ExecuteReader(query, values, true);
IList<Product> prodList = new List<Product>();
// For simplicity, assume that list is not very large
while (products.Read())
{
prodList.Add((Product)products.GetValue(1));// 1 because on 0 you'll get the Cache Key
}
return prodList;
}
}
}한 가지 추천하고 싶은 것은 이러한 클래스를 직렬화 가능한 태그로 장식하는 것입니다. 그래서, 당신은 그것들을 캐시해야 합니다, 그렇죠? 따라서 이러한 도메인 개체는 클라이언트 응용 프로그램과 분산 캐시 간에 앞뒤로 이동할 것이기 때문에 직렬화되어야 합니다.
그래서 우리는 바로 여기에 고객 등급과 제품 등급이 있습니다. 주문 목록과 프레젠테이션 슬라이드에 표시된 모든 속성이 있는 주문 클래스도 있습니다.
기본 개체는 무엇입니까?
다음으로 기본 객체에 대해 이야기하겠습니다. 이제 이 도메인 데이터 모델에 매핑되는 몇 가지 기본 개체를 보여 주었습니다. 일대일 일대다 및 다대다 관계를 살펴보는 몇 가지 기술을 보여드리겠습니다.
먼저 다음 슬라이드에서 사용할 용어에 대해 이야기하겠습니다.

기본 개체는 도메인 개체입니다. 데이터베이스에 매핑됩니다. 애플리케이션의 시작점입니다. 예를 들어 고객 개체가 있고 주문이 필요한 경우 고객이 시작해야 합니다. 따라서 이것은 애플리케이션이 가져오는 첫 번째 개체이고 이것과 관련된 다른 모든 개체는 이것과 관련하여 가져올 것입니다. 맞습니까?
또 다른 예로는 주문을 올바르게 처리하고 있어 해당 처리 장치에서 주문을 가져오고 특정 주문을 발송하기 위해 주문한 고객에 대해 알고 싶을 수 있습니다. 따라서 이 경우 주문이 주요 대상이 되고 다대일 관계를 갖거나 특정 주문을 실제로 주문한 고객 중 한 명 또는 해당 주문 내의 모든 제품과 관계를 갖습니다. 그래서 어떤 식으로든 될 것이지만 우리는 캐시할 기본 개체를 사용하고 다른 개체가 그것에 종속되도록 만들 것입니다. 그것이 뒤따를 접근법입니다.
분산 캐시의 관계
그래서, 실제로 이것으로 시작합시다. 그래서 먼저 가장 일반적인 시나리오인 분산 캐시 내의 일대일 및 다대일 관계에 대해 이야기하겠습니다. 따라서 한 가지 옵션은 관련 개체를 기본 개체로 캐시하는 것입니다. 이제 도메인 개체를 보았으므로 고객의 일부로 주문 목록이 있습니다. 따라서 우리가 이러한 주문을 채우고 고객이 해당 주문을 It의 일부로 가지고 있다면 고객을 모든 주문이 포함된 캐시에 단일 객체로 저장한다면 맞습니까? 그래서, 그것은 일을 끝낼 것입니다.
기본 개체가 있는 캐시 관련 개체
여기에 이에 대한 코드 예제가 있습니다.
// cache order along with its OrderingCustomer and OrderedProduct
// but not the "Orders" collection in both of them
public void CacheOrder(Cache cache, Order order)
{
// We don't want to cache "Orders" from Customers and Product
order.OrderingCustomer.Orders = null;
order.OrderedProduct.Orders = null;
string orderKey = "Order:CustoimerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}캐시 주문이 있고 주문 내의 주문 고객을 "null"로 설정했습니다. 괜찮은! 따라서 고객에 대한 참조가 있는 주문이 없습니다. 중복입니다. 이것은 그다지 좋은 프로그래밍 방식은 아니지만 시행하기 위한 것입니다. 우리는 고객 및 제품 ID의 캐시 주문을 원하지 않습니다. 따라서 우리는 캐시에 한 명의 고객을 추가하고 그 일부로 주문을 받기를 원합니다.
자, 그럼 한번 볼까요? 따라서 이것을 null로 설정한 다음 단순히 저장하거나 null로 설정하지 않으면 실제로 참조를 다시 가질 수 있습니다. 마찬가지로 고객이 있다면 맞습니까? 따라서 이것은 별도의 개체이지만 주문을 null로 설정하지 않고 단순히 이 고객을 저장하는 경우 주문 목록이 있으므로 여기로 이동하겠습니다. 캐시의 단일 개체, 해당 개체의 일부로 주문 컬렉션이 있습니다. 다른 예에서는 null로 설정했지만 이 특별한 경우를 보여주기 위해 하나의 큰 개체를 정렬할 수 있으며 모든 관련 개체가 해당 개체의 일부로 포함됩니다.
따라서 도메인 개체에서 시작해야 하며 관계를 도메인 개체의 일부로 캡처해야 하며 관계없이 그렇게 해야 합니다. 그런 다음 캐시해야 합니다. 실제로 채워진 주문 목록, 관련 개체 목록이 그 일부로 있어야 합니다. 따라서 이것이 얻을 수 있는 가장 간단한 접근 방식입니다.
모든 것을 나타내는 하나의 개체가 있다는 이점이 있습니다. 그러나 몇 가지 단점도 있습니다. 크기면에서 더 큰 물체가 될 것입니다. 어떤 경우에는 고객이 필요하지만 그 일부로 주문을 받게 될 수도 있습니다. 더 큰 페이로드를 처리하게 됩니다. 그리고, 세분화된 주문을 캐시에 별도의 항목으로 가지고 있지 않기 때문에 하나에만 관심이 있지만 항상 주문 수집을 처리해야 하겠죠? 이것이 하나의 접근 방식입니다. 그것이 출발점입니다.
관련 객체를 별도로 캐시
둘째, 가중 개체를 캐시에 별도의 항목으로 캐시합니다.
public void CacheOrder(Cache cache, Order order)
{
Customer cust = order.OrderingCustomer;
// Set orders to null so it doesn't get cached with Customer
cust.Orders = null;
string custKey = "Customer:CUstomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures order is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}이에 대한 예는 캐시 주문이 있는 주문 클래스입니다. 맞습니까? 이것이 고객이 있는 예입니다. 우선, 그렇지? 그런 다음 고객을 단일 개체로 저장하고 있습니다. 주문을 받은 다음 주문에서 고객을 추출한 다음 해당 고객 개체 내의 주문 컬렉션을 null로 설정한다는 것을 알 수 있습니다. 맞습니까? 따라서 이것은 생성자 내에서 수행해야 하는 작업이지만 여기서 수행되는 작업은 이 고객 개체가 해당 주문의 일부로 이 주문을 갖지 않도록 강제하기 위한 것입니다. 그런 다음 이 고객을 단일 개체로 저장합니다. 여기서 우리가 하는 일은 고객, 고객 ID, 런타임 매개변수인 고객 키를 생성한 다음 고객을 캐시에 단일 개체로 저장하는 것입니다.
다음으로 할 일은 캐시 종속성을 만드는 것입니다. 그래서 우리는 두 가지 단계에 대해 이야기했습니다. 한 단계는 데이터 모델을 도메인 개체에 매핑하여 도메인 개체가 데이터베이스의 관계형 테이블을 나타내고 일단 캐싱을 계획하면 기본 개체를 갖게 되는 것입니다. 이 경우 고객이고 일대다 관계에서 고객과 관련된 주문이 있습니다. 캐시 종속성 개체를 사용하여 고객과 주문 컬렉션 간의 종속성을 만듭니다. 캐시 종속성을 만듭니다. 이 동일한 캐시 종속성은 두 개의 매개변수를 사용합니다. 첫 번째는 파일입니다. 맞죠? 따라서 파일 이름에 종속될 수도 있고 키에 종속될 수도 있습니다. 맞습니까? 따라서 첫 번째 매개변수를 null로 설정합니다. 따라서 어떤 파일에도 의존하지 않기를 바랍니다.
안에 또 다른 기능이 있습니다. NCache 특정 파일 시스템에 종속된 항목을 파일 시스템의 일부 파일로 만들 수 있습니다. 그런 다음 키 기반 종속성을 사용하는 경우 하위 항목이 종속될 상위 항목의 키가 필요합니다. 그런 다음 주문 컬렉션의 주문 키를 구성합니다. 우리는 바로 여기에 이 메서드로 전달되는 전체 주문 컬렉션을 가지고 있으며, 그런 다음 단순히 Cache.Add 주문을 호출합니다.
이제 고객과 주문은 서로 연결되어 있습니다. 캐시에 별도의 개체로 표시되는 이 고객의 주문 목록이 있으므로 이 특정 고객의 모든 주문이 필요할 때마다 이 키를 사용하기만 하면 됩니다. 당신이 해야 할 일은 전화하는 것뿐입니다. 제가 바로 여기 이 예제를 실제로 사용하겠습니다. 죄송합니다! Cache.Get을 호출한 다음 단순히 주문 키를 전달하면 이 메서드 내에서 구성한 특정 주문을 가져올 수 있습니다. 맞습니까?
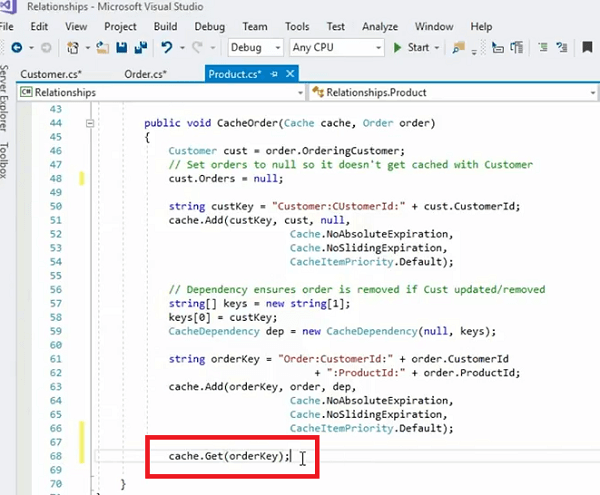
따라서 이 특정 고객의 모든 주문 모음을 한 번에 가져오기 위해 필요한 것입니다. 하지만 고객이 변화를 겪는다면? 고객이 업데이트되면 주문 컬렉션이 캐시에 남아 있을 필요가 없습니다. 제거하거나 경우에 따라 업데이트할 수도 있습니다. 맞습니까?
이것이 스토리지와 사용성 측면에서 더 정교한 두 번째 접근 방식이며 일대다 관계 또는 다대일 관계의 관계에서 두 레코드를 매핑합니다. 주문 목록을 가질 수 있고 각 주문을 개별 주문에 매핑할 수 있고 여러 ID 주문에 매핑할 수 있는 경우 주문이 고객에게 매핑될 수 있는 다른 방법도 있을 수 있습니다. 특정 애플리케이션 코드의 기본 개체입니다. 이제 이것은 고객과 주문 간의 관계를 정의합니다.
캐시 종속성 기능에 대한 몇 가지 추가 세부 정보입니다.
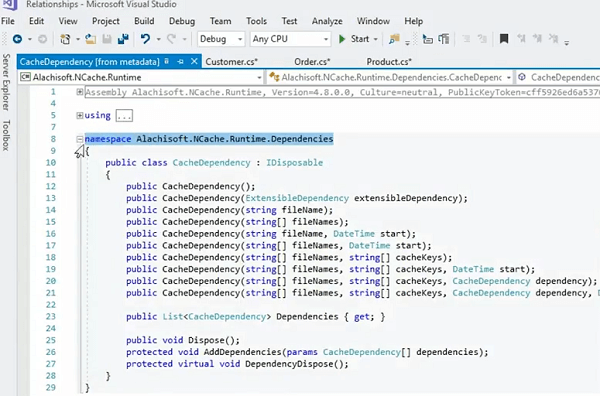
내가 여기에 가면 우선 노출되지만 Alachisoft.NCache.Runtime.Dependencies 그리고 이것은 여러분이 사용하는 오버로드 중 하나이며 바로 여기에서 이 특정 메서드를 사용하기만 하면 됩니다. 그리고 이것의 동작은 개체 간의 단방향 종속성을 단순히 추적할 수 있도록 하는 방식이며 프레젠테이션의 앞부분에서 논의한 대로 캐스케이드될 수도 있습니다.
일대다 관계
다음으로 일대다 관계에 대해 이야기하겠습니다. 일대일이나 다대일 얘기를 하다가 주문을 받고 고객이 생겨서 대부분의 경우 일대다와 비슷하지만 시작점이 주문이었기 때문에 삽입을 했습니다. 고객, 고객을 저장한 다음 주문 모음을 저장한 다음 주문 모음과 해당 고객 간의 다대일 관계를 정의했습니다.

자, 일대다 관계는 우리가 논의한 것과 매우 유사할 것입니다. 첫 번째 옵션은 기본 개체의 일부로 개체 컬렉션을 캐시하는 것입니다. 따라서 고객은 기본 개체이고 주문은 그 일부여야 합니다.
두 번째 항목은 관련 개체가 별도로 캐시되지만 개별 항목은 캐시에 있다는 것입니다. 맞습니까?
일대다 – 관련 개체 수집을 별도로 캐시public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}따라서 이것은 별도의 컬렉션입니다. 여기에 일대다 고객 개체가 있는 주문이 있고 고객이 주문을 가지고 있습니다. 주문 컬렉션을 가져온 다음 고객 주문을 null로 설정하므로 고객은 전자입니다. 개체, 기본 개체, 주문 수집은 별도의 개체이며 고객을 저장하고 데이터 캐시 종속성을 저장하고 주문을 저장합니다. 따라서 전체 컬렉션이 일대다일 것입니다.
일대다 – 관련 컬렉션의 각 개체를 개별적으로 캐시두 번째 접근 방식은 이 컬렉션을 분해할 수도 있다는 것입니다.
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
// Let's cache each order as seperate item but assign it
// a group so we can fetch all orders for a given customer
foreach (Order order in orders)
{
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
CacheItem cacheItem = new CacheItem(order);
cacheItem.Group = "Customer:CustomerId:" + cust.CustomerId;
cacheItem.Dependency = dep;
cache.Add(orderKey, cacheItem);
}
}주문 모음은 해당 모음 내의 각 항목이 캐시의 별도 항목일 수 있습니다. 따라서 이 경우에는 동일한 접근 방식을 사용합니다. 우리는 고객을 얻고, 주문을 받고, 고객을 저장하고, 키 종속성을 사용하여 해당 고객의 종속성을 생성한 다음 모든 주문을 반복합니다.
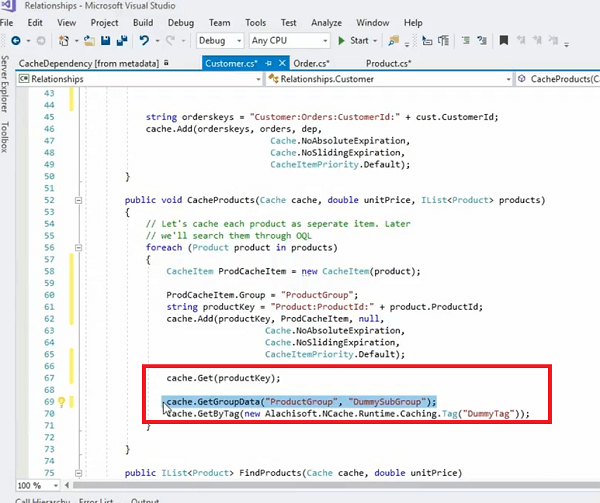
여기에서 캐시 고객 방법이 더 직관적이므로 여기에서 바로 살펴보겠습니다. 따라서 우리는 주문 수집을 가져오고 고객 주문을 null로 설정하여 고객은 고객에 관한 것일 뿐이고 캐시를 사용하여 고객을 캐시에 저장합니다. 키 추가, 고객의 특정 키 주위에 캐시 종속성을 구성하고 그런 다음 단순히 반복합니다. 여기 루프가 있습니다. 우리는 실제로 그것을 통해 반복해야 하고 이것은 실제로 우리가 그것을 통해 반복하는 것이 더 낫습니다. 그런 다음 캐시의 개별 항목으로 한 번에 저장하므로 주문은 각 주문에서 자체 키를 가지며 캐시의 별도 항목입니다. 그리고 우리가 한 또 다른 일은 캐시 항목 추가 그룹이라고 부르는 이들을 실제로 그룹화한 것입니다. 고객 ID도 그룹입니다. 따라서 우리는 실제로 캐시 내부의 컬렉션도 관리하고 있습니다.
내가 가지고 있는지 봅시다.. 실제로, 예를 들어, 바로 여기에 있습니다. 우리는 실제로 이러한 제품을 캐시할 수 있습니다. 그건 또 다른 예입니다. 모든 제품 컬렉션을 순환한 다음 개별적으로 저장한 다음 실제로 모든 것을 그룹에 넣었습니다. 맞습니까?
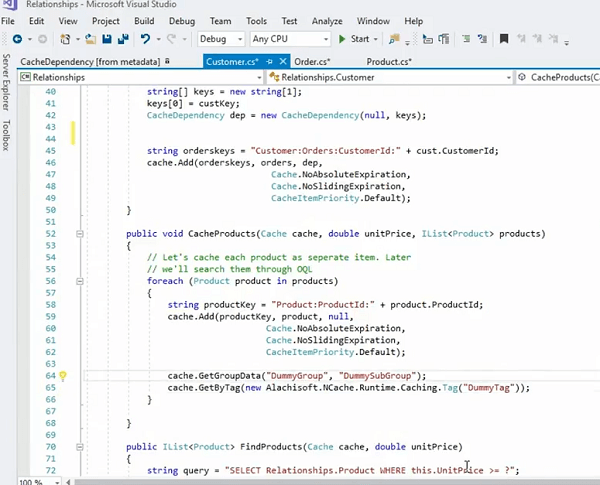
따라서 항목으로 저장되는 이 제품은 ProdCacheItem이 있는 곳에 이와 같이 저장할 수도 있습니다. 내 키보드가 재생 중이니 조금만 참아주세요! 지금은 이것을 사용하고 간단하게 할 것입니다. 실제로 그룹을 추가할 수 있습니다. 그래서 이것은 실제로 제가 이것을 위한 그룹을 설정할 수 있도록 합니다. 이제 더미 그룹을 가정해 보겠습니다. 이 캐시 항목을 저장하면 실제로 이에 대한 항목으로 제품이 있을 수 있습니다. 맞습니까? 따라서 실제 원시 개체를 저장하는 대신 그룹으로 배열할 수도 있습니다. 상품 캐시 아이템을 간단히 사용할 수 있습니다. 자! 오른쪽? 이제 실제로 더미 그룹을 사용하거나 사용하는 대신 제품 그룹을 올바르게 지정하고 이를 가져와야 할 때 단순히 제품 그룹을 사용할 수 있으며 이 컬렉션의 모든 항목을 한 번에 가져올 수 있습니다. 이것들은 개별적으로 저장되고 있지만 개별 Cache.Get 호출 제품 컬렉션 내의 개별 제품은 개별적으로 정렬되지만 컬렉션의 그룹으로 정렬한 다음 가져올 수 있습니다. 하지만 이것에 대한 좋은 점은 여전히 종속성을 사용하고 있다는 것입니다. 그렇죠? 따라서 개별 항목에 대한 한 고객의 종속성을 사용하고 있습니다.
예를 들어, 주문이 XNUMX개 있는 고객이 한 명 있습니다. 따라서 캐시에 고객에 대한 총 하나의 항목이 있고 캐시에 XNUMX개의 항목으로 별도로 저장된 XNUMX개의 주문이 있으며 해당 XNUMX명의 고객과 XNUMX개의 주문 사이에는 단방향 종속성이 있습니다. 한 명의 고객을 캐시에서 제거하면 XNUMX개의 주문이 한 번에 무효화됩니다. 이제 필요한 경우 개별 주문을 가져올 수 있는 이점이 있습니다. 따라서 해당 항목과 개별적으로 상호 작용할 수 있습니다. 한 번에 하나의 항목. 처리할 수 있는 특정 주문이 필요하고 해당 주문의 전체 컬렉션이 한 번에 필요할 때 간단히 Cache.GetGroupData를 호출하고 제품 그룹을 제공한 다음 하위 그룹이 무엇이든 될 수 있습니다. null 일 수도 있고 태그를 사용할 수도 있습니다.
예를 들어; 이를 관리하는 다른 방법은 제품 항목을 사용하고 이에 대한 태그를 만드는 것입니다. 맞습니까? 그리고, 당신은.. 거기에.. 예! 제품 태그와 같은 것으로 갈 수 있는 태그를 제공할 수 있습니다. 맞습니까? 그런 다음 이것을 그것의 일부로 연결할 수 있습니다.
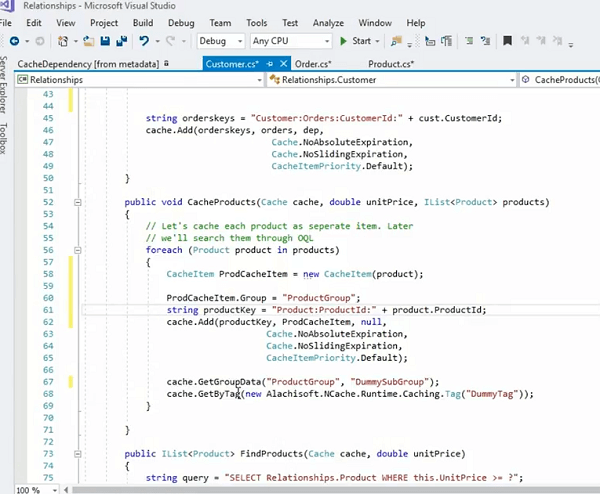
따라서 이것은 실제로 같은 줄에서 작동하고 get by tag 메서드를 호출할 수도 있으며 모든 항목을 한 번에 처리합니다. 그것은 당신에게 한 번에 모든 항목을 가져올 것입니다. 따라서 이렇게 하면 캐시의 데이터 배열을 더 잘 제어할 수 있고 여전히 일대다 관계를 그대로 유지할 수 있습니다.
따라서 이것은 일대다 관계가 있고 하나의 객체가 추가된 다음 컬렉션이 개별적으로 캐시에 저장된 해당 컬렉션의 항목을 개별적으로 저장한 다측에 해당 항목이 있는 매우 특정한 시나리오를 처리합니다. 여전히 종속성이 있고 관련 항목에 대한 컬렉션 유형의 동작이 있습니다. 따라서 이러한 항목은 서로 관련되어 컬렉션을 형성한 다음 일대다 공식에서 다른 개체와 관계를 갖습니다. 따라서 이 코드 스니펫, 매우 간단하고 직관적인 API가 이러한 모든 시나리오를 처리합니다. 키 종속성의 도움으로 캡처된 일대다 관계가 있습니다. 이러한 항목을 캐시에 개별적으로 정렬했지만 여전히 그룹 또는 태그의 논리적 컬렉션에 넣은 다음 해당 항목이 개별적으로 필요할 때 캐시 시작 가져오기를 호출합니다. 맞습니까?
따라서 이 항목을 가져오는 한 가지 방법은 Cache.Get을 호출하는 것입니다. 맞습니까? 여기에서 제품 키인 키를 사용하십시오. 맞습니까? 따라서 이것은 이 특정 키로 저장되는 이 특정 제품을 가져올 것입니다. 맞습니까? 다른 옵션은 Cache.GetGroupData를 사용할 수 있도록 한 번에 해당 컬렉션 내의 모든 항목이 필요하다는 것입니다. 따라서 수집 동작을 제공하는 동시에 관련 항목을 개별적으로 관리할 수도 있습니다.
따라서 컬렉션 및 컬렉션 내의 항목과 일대다를 한 번에 처리해야 합니다.
다대다 관계
다음으로 다대다 관계가 있습니다.

다대다 관계는 일반적으로 도메인 개체에 존재하지 않습니다. 데이터베이스에서도 항상 두 개의 일대다 관계로 정규화됩니다. 사실 우리는 고객과 제품 사이에 다대다 관계가 있었습니다. 중간 개체의 도움으로 두 개의 일대다 관계로 정규화된 다대다 관계. 그래서 우리는 고객 주문과 제품 주문 사이에 각각 일대다와 다대일을 가지고 있습니다. 이것이 다대다를 다루는 방법입니다. 따라서 일대일 다대일 또는 일대다 관계를 사용하게 됩니다.
따라서 이것은 다대다 관계를 처리해야 합니다.
분산 캐시에서 컬렉션 처리
다음은 컬렉션이 있다는 것입니다. 우리는 이미 제품 예제의 도움으로 이를 만졌지만 하나의 항목으로 컬렉션에 캐시하는 것을 계속 살펴보겠습니다.

예를 들어 제품을 보관합니다. 통과하자, 그렇지?
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// cache the entire collection as one item
string productskey = "Product:UnitPrice:" + unitPrice;
cache.Add(productskey, products, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string productskey = "Product:UnitPrice:" + unitPrice;
IList<Product> products = (IList<Product>)cache.Get(productskey);
return products;
}따라서 캐시 제품이 있으므로 제품 키를 만든 다음 여기로 가져오는 제품 목록을 가지고 캐시하고 단일 개체를 가집니다. 그리고 앞에서 설명한 것처럼 작동할 것입니다. 작업을 완료하면 대부분 해당 목록의 모든 항목이 한 번에 필요할 때 작동합니다. 해당 목록의 개별 항목에는 관심이 없습니다. 당신은 하나의 항목으로 전체 매장 전체 목록에 전적으로 관심이 있지만 개체가 무거워지고 코딩, 검색 지원을 제공하지 않을 것입니다. 이것이 우리의 다음 주제입니다. 일반 목록이기 때문에 목록에 제품이 있지만 NCache 이것은 단지 목록일 뿐입니다. 오른쪽! 따라서 해당 목록 내에서 개체를 정확히 지정한 다음 속성을 지정할 수 없으며 해당 속성을 기반으로 검색할 수 없습니다.
따라서 이를 처리하는 보다 정교한 방법은 각 컬렉션 항목을 개별적으로 캐시하는 것입니다. 이전 예제의 일부로 다루었지만 한 번 더 살펴보겠습니다. 예를 들어; 캐시 제품을 한 번 더 살펴보고 이를 개별 항목으로 저장하기만 하면 됩니다. 이 예를 찾아보겠습니다! 좋아요! 거기는.
그래서 우선, 우리는 실제로 제품을 개별적으로 보관할 것입니다. 개별 제품에 대한 키를 중심으로 구성된 키가 있습니다. 이것에 대한 좋은 점은 제품 컬렉션의 모든 개별 항목이 캐시에 개별 항목으로 저장되어 해당 Cache.Get에 대한 메서드인 오버로드인 키를 사용하여 항목을 가져올 수 있다는 것입니다. 컬렉션으로도 가져올 수 있습니다. 그것은 우리가 매우 자세하게 논의한 것입니다. 또 다른 옵션은 쿼리도 실행하고 검색 쿼리와 같은 이러한 SQL을 개체의 특성에 직접 적용할 수 있다는 것입니다. 그리고 개별적으로 저장한 경우에만 이 작업을 수행할 수 있습니다. 컬렉션 내의 모든 항목은 개별 항목으로 저장됩니다. 도메인 개체, 이 경우 제품에 매핑하고 제품 컬렉션 내의 제품은 개별 항목으로 캐시에 개별적으로 저장됩니다.
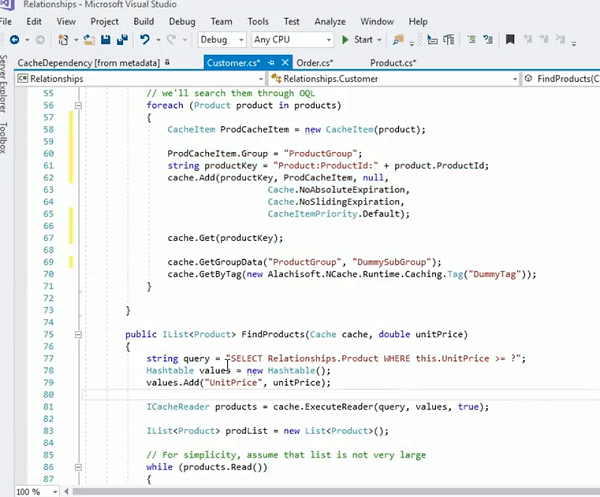
이제 제품의 단가, 제품 ID를 인덱싱한 다음 이와 같은 쿼리를 실행할 수 있습니다. 제품의 네임스페이스인 제품을 선택합니다. 여기서 단가는 런타임 매개변수와 동일하게 설정됩니다. 그런 다음 Cache.ExecuteReader를 호출하면 애플리케이션에서 반복하고 계속 가져올 수 있는 모든 제품을 가져올 수 있습니다. 마찬가지로 where This.Tag도 말할 수 있습니다. 그 위에 태그를 연결한 경우 해당 태그에서 쿼리를 실행할 수도 있습니다. 이는 검색 이점, 성능 이점과 함께 태그의 또 다른 이점이며 검색 관점에서 유연성을 제공합니다. 또한 태그는 Cache.Get을 태그로 제공합니다. 모든 API를 제공하고 모든 태그를 통해 모든 태그를 얻으므로 이러한 태그 API를 사용하여 실제로 개체를 가져올 수도 있습니다. 하지만 제가 강조하고 싶었던 특징은 그것들을 개별적으로 배열한다는 것입니다. 그것이 출발점입니다. 태그 또는 그룹을 사용하여 논리적 컬렉션을 생성합니다. 따라서 검색이 더 쉽습니다. Cache.Get이라고 부르는 개별 항목이 필요합니다. 키를 기반으로 항목을 가져옵니다. 그룹 또는 태그를 사용하는 컬렉션이 필요하며 그 위에 쿼리를 실행하고 연결할 수 있으며 실제로 기준에 따라 항목을 가져올 수 있습니다.
이 경우 단가가 될 수 있습니다. 단가는 10보다 크고 XNUMX보다 작을 수 있습니다. 따라서 논리 연산자가 지원됩니다. 일부 집계, 개수, 합계도 가질 수 있습니다. 그룹별 정렬 순서가 유사 연산자로 작동하므로 지원에 관한 한 매우 흥미롭고 광범위합니다. SQL과 유사합니다. SQL 쿼리이지만 사용이 매우 유연하며 필요한 항목 측면에서 많은 사용 편의성을 제공합니다. 더 이상 키로 작업할 필요가 없습니다. 따라서 캐시에 별도로 저장된 각 컬렉션 항목을 단순히 사용하는 경우에만 발생합니다. 도움이 되길 바랍니다.
시작하기 NCache
이것으로 오늘의 주제를 마칩니다. 마지막으로 시작하기 위한 XNUMX가지 간단한 단계를 보여 드리겠습니다. NCache 그냥 넘어가려고 NCache 실제 애플리케이션에서 이러한 API를 실행할 수 있습니다.
좋아요! 그래서, 나는 이것을 빨리 시작할 것입니다. 관리 도구를 열었습니다. 그건 그렇고, 우리는 최근에 4.9를 출시했습니다. 이것이 우리의 최신 버전이므로 시작하는 것이 좋습니다. 따라서 캐시 이름을 기준으로 캐시를 만들고 다음을 선택하고 캐싱 토폴로지를 선택하고 파티션 복제본 캐시가 가장 적합하며 복제를 위한 비동기 옵션을 선택하고 여기에서 이 캐시를 호스트할 서버를 지정하기만 하면 됩니다. 데모 XNUMX과 XNUMX가 이미 설치되어 있습니다. NCache.
따라서 XNUMX단계는 다운로드 및 설치입니다. NCache. 두 번째 단계는 명명된 캐시를 만드는 것입니다. 오늘 토론의 주요 범위가 아니기 때문에 모든 것을 기본값으로 유지하면서 살펴보겠습니다. 각 서버에 있는 캐시의 기본값과 크기에 대해 살펴보겠습니다. 기본 설정을 지정하고 완료를 선택하기만 하면 됩니다.
4단계는 클라이언트 노드를 추가하는 것입니다. 그냥 내 기계를 사용하겠습니다. 내가 이것에 접근할 수 있는지 알아봐, 그래! 괜찮은! 그래서, 그것은 바로 여기 내 기계입니다. XNUMX단계가 완료되도록 추가했습니다. 서버와 클라이언트의 모든 구성이 완료되었습니다. 이제 XNUMX단계의 일부로 이 캐시 클러스터를 시작하고 테스트해야 합니다. 그런 다음 이를 검토한 다음 실제 애플리케이션에서 사용할 것입니다. 따라서 시작하는 방법은 간단합니다. NCache.
몇 가지 빠른 카운터를 보여 드리고 프레젠테이션도 빠르게 마치도록 하겠습니다. 마우스 오른쪽 버튼을 클릭하고 성능 카운터를 여는 통계를 선택하고 다음과 같은 모니터링 도구를 열 수도 있습니다. NCache 모니터, 함께 설치됨 NCache.
따라서 성능 카운터 기반입니다. 서버 측 성능 카운터를 제공하고 클라이언트 측도 카운터를 수행합니다. 그리고 클라이언트 애플리케이션 측에서 다음과 함께 다시 설치되는 이 스트레스 테스트 도구 애플리케이션을 실행할 수 있습니다. NCache. 구성이 완료되었으므로 이름을 사용하여 자동으로 캐시에 연결하고 내 캐시 클러스터에서 로드 시뮬레이션을 시작합니다. 자! 따라서 여기와 다른 서버에 대한 요청 로드가 있습니다.
마찬가지로 보고서 뷰어 서버와 클라이언트에 연결된 클라이언트뿐만 아니라 이 서버에도 활동이 표시됩니다. 그런 다음 이러한 카운터를 연결할 수 있는 사용자 지정 대시보드를 가질 수도 있습니다. 예를 들어 API 로그가 좋은 예입니다. 지금 캐시에서 수행 중인 모든 요청을 실시간으로 기록하죠?
이것이 왼쪽 메인에서 이러한 카운터를 사용하는 간단한 예입니다. 내가 말했듯이 이것은 캐싱이 어떻게 생겼는지에 대한 느낌을 주기 위한 것입니다. 이제 실제 응용 프로그램에서 실제로 사용할 수 있습니다. 여기에서 내 컴퓨터를 사용할 수 있으며 함께 설치되는 기본 작동 샘플을 간단히 사용할 수 있습니다. NCache. 사용하는 한 샘플 .NET 기본 작업 내에 다른 바늘 폴더가 있기만 하면 됩니다. NCache 사용할 수 있는 클라이언트 측 라이브러리 NCache SDK NuGet 패키지. 모든 클라이언트 측 리소스를 얻는 것이 가장 쉽습니다.
다른 옵션은 실제로 사용하는 것입니다. Alachisoft.NCache.런타임 및 Alachisoft.NCache.웹 라이브러리 직접. 당신은 그것들을 포함합니다. 이들은 처음에 제공되는 라이브러리입니다. NCache Microsoft 캐시 폴더에서. 일단 설치하면 NCache 그것은 그것의 일부가 될 것이고 그 후에 나는 당신이해야 할 일을 빨리 보여줄 것입니다. 자! 따라서 가장 먼저 필요한 것은 이 두 라이브러리에 대한 참조를 추가하는 것입니다. 런타임 및 웹에는 방금 강조한 이러한 네임스페이스가 포함됩니다. Web.caching 그리고 그 시점부터 이 샘플은 캐시에 연결하는 기본 초기화, 캐시를 읽는 객체 생성, 삭제, 모든 종류의 생성, 읽기, 업데이트, 삭제 작업을 업데이트하는 데 충분합니다.
이것이 캐시를 초기화하는 방법입니다. 이게 메인 콜 맞죠? 캐시 이름이 캐시 핸들을 반환한 다음 단순히 캐시를 호출하거나 키 값 쌍 Cache.Get 항목에 모든 항목을 추가하고 항목 캐시를 업데이트하거나 삽입한 다음 Cache.delete해야 합니다. 그리고 이미 검색과 같은 SQL을 사용하는 그룹을 사용하여 태그를 사용하여 키 기반 종속성을 사용하는 몇 가지 자세한 예를 보여 주었습니다. 따라서 이것은 실제로 환경 설정에 대한 세부 정보를 제공한 다음 실제 애플리케이션에서 사용할 수 있어야 합니다.
이것으로 프레젠테이션을 마칩니다.