NCache 성능 벤치 마크
2백만 작업/초
(5노드 클러스터)
개요
NCache 쉽고 비용 효율적으로 성능을 선형적으로 확장하고 향상시킬 수 있습니다. 전 세계 Fortune 500대 기업이 신뢰하는 기업 NCache 13년 이상 동안 데이터 스토리지 및 데이터베이스와 관련된 성능 병목 현상을 제거하고 .NET 애플리케이션을 XTP(Extreme Transaction Processing)로 확장했습니다.
이 문서는 NCache 최신 API와 몇 가지 새로운 기능이 포함된 5.0은 .NET 애플리케이션에서 달성할 수 있는 선형 확장성과 최고의 성능을 보여줍니다. 이 실험에서는 모뎀을 번들로 제공했습니다. NCache 파이프라이닝이 활성화된 분할된 캐시 토폴로지가 있는 API. 데이터는 모든 캐싱 서버에 완전히 분산되며 클라이언트는 읽기 및 쓰기 요청을 위해 모든 서버에 연결됩니다.
이 벤치마크에서 우리는 NCache 클러스터는 선형적으로 확장할 수 있으며 우리가 달성한 2개의 캐시 서버 노드만 사용하여 초당 5백만 트랜잭션. 우리는 또한 그것을 증명할 것입니다 NCache 대규모 클러스터에서도 XNUMX마이크로초 미만의 대기 시간을 제공할 수 있습니다. 이 백서에서는 벤치마크 설정, 벤치마크 수행 단계, 구성 테스트, 로드 구성 및 결과에 대해 다룹니다. 여기에서 벤치마크 실험이 실제로 진행되는 것을 볼 수 있습니다. 비디오.
벤치마크 설정 개요
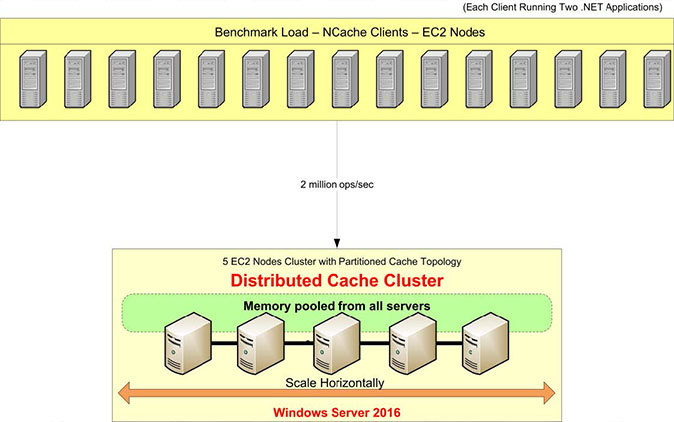
벤치마크 설정을 검토해 보겠습니다. 이 테스트에는 AWS m4.10xlarge 서버를 사용할 예정입니다. 우리는 이 다섯 NCache 캐시 클러스터를 구성할 서버입니다. 이 캐시 클러스터에 연결하기 위해 응용 프로그램을 실행할 15개의 클라이언트 서버가 있습니다.
운영 체제로 Windows Server 2016(Data Center Edition, 64비트)을 사용할 것입니다. 그만큼 NCache 사용중인 버전은 5.0 Enterprise입니다. 이 벤치마크 설정에서는 분할된 캐시 토폴로지. 분할된 캐시 토폴로지에서 모든 데이터는 모든 캐싱 서버의 분할 영역에 완전히 분산됩니다. 그리고 모든 클라이언트는 동시에 모든 서버를 활용하기 위해 읽기 및 쓰기 요청을 위해 모든 서버에 연결됩니다. 이 토폴로지에 대해 복제를 설정하지 않았지만 다음과 같은 다른 토폴로지가 있습니다. 분할된 복제본 토폴로지 복제 지원 기능이 제공됩니다.
우리는 파이프 라이닝 의 새로운 기능인 활성화됨 NCache 5.0. 클라이언트 측에서 런타임에 발생하는 모든 요청을 누적하고 서버 측에서 해당 요청을 한 번에 적용하는 방식으로 작동합니다. 누적은 마이크로초 단위로 이루어지므로 매우 최적화되어 있으며 트랜잭션 로드 요구 사항이 높을 때 권장되는 구성입니다.
다음은 하드웨어, 소프트웨어 및 로드 구성을 포함한 벤치마크 설정에 대한 간략한 개요입니다.
하드웨어 구성 :
| 클라이언트 및 서버 세부 정보 (가상 기기) |
AWS m4.10xlarge: 40코어, 160GB 메모리, 네트워크 - 10Gbps 이더넷 |
| 서버 노드 수 | 5 |
| 클라이언트 노드 수 | 15 |
소프트웨어 구성 :
| 운영체제 | 윈도우 서버 2016 데이터 센터 에디션 - x64 |
| NCache 버전 | 5.0 |
| 클러스터 토폴로지 | 분할된 캐시 구성 |
로드 구성 :
| 캐시 크기 | 4 GB |
| 데이터 크기 | 크기가 100인 바이트 배열 |
| 총 항목 | 1,000,000 |
| 파이프 라이닝 | 사용 |
| 가져오기/업데이트 비율 | 80:20 |
| 스레드 | 1280 |
| 애플리케이션 인스턴스 | 클라이언트 머신당 2개의 인스턴스, 총 30개의 인스턴스 |
데이터 채우기
벤치마크 환경 설정 후 캐시 클러스터에서 1만 항목의 데이터 채우기로 시작합니다. 캐시에 백만 개의 항목을 연결하고 추가할 클라이언트 응용 프로그램(캐시 항목 로더)을 실행합니다. 하나의 클라이언트가 모든 캐싱 서버에 연결하고 캐시 클러스터에 백만 개의 항목을 추가한 후 읽기 및 쓰기 요청을 시작할 수 있습니다.
이것을 사용할 수 있습니다. 너겟 패키지 – NCache SDK 클라이언트 시스템에 SDK를 설치하고 클라이언트-서버 간 파이프라인을 구성하고 부하 생성 애플리케이션(GitHub)을 배포하여 캐시 클러스터에 1만 개의 캐시 항목을 채웁니다.
트랜잭션 부하 구축
이제 애플리케이션을 실행하여 80% 읽기 및 20% 쓰기 작업으로 이 캐시 클러스터에 일부 트랜잭션 부하를 구축합니다. Perfmon 카운터를 사용하여 모든 활동을 모니터링할 수 있습니다. 처음에는 각각에 10개의 클라이언트 인스턴스를 연결합니다. NCache 페치 활동과 초당 업데이트 활동이 있는 서버.
무대 1 1만 Ops/초 트랜잭션 로드
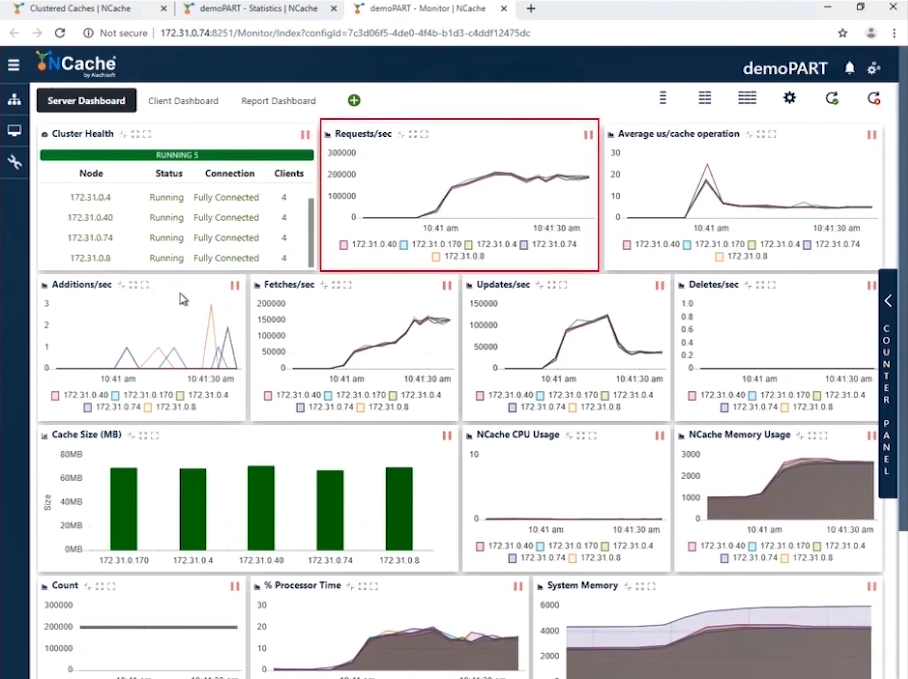
스크린샷에서 10노드 클러스터에 연결된 5개의 클라이언트 인스턴스에서 초당 요청 수가 180,000에서 190,000 사이인 것을 볼 수 있습니다. 그리고 우리는 5를 가지고 있기 때문에 NCache 병렬로 작동하는 서버에서 이러한 요청을 누적하면 이 캐시 클러스터에 의해 초당 1만 요청이 발생합니다.
메모리와 CPU 사용량이 효율적이며 평균 마이크로초/캐시 작업은 작업당 10마이크로초 미만입니다. 캐시 클러스터에서 초당 1만 작업을 달성한 XNUMX단계가 완료되었습니다.
| 1단계 – 요약 데이터 시트 | |
| 클러스터의 총 캐시 서버 | 5 |
| 연결된 총 클라이언트 인스턴스 | 10 |
| 초당 요청/노드 | 180,0000 ~ 190,000 |
| 총 요청 - 캐시 클러스터 | 950,000 ~ 1,000,000 |
| % 프로세서 시간(최대) | 20% |
| 시스템 메모리 | 4.2 GB |
| 대기 시간(마이크로초/캐시 작업) | 10마이크로초/작업 |
무대 2 1.5만 Ops/초 트랜잭션 로드
이제 1만 TPS를 달성했으므로 더 많은 애플리케이션 인스턴스의 형태로 부하를 높여 트랜잭션 부하를 증가시킬 때입니다. 그리고 이러한 애플리케이션이 실행되는 즉시 초당 요청 카운터가 증가하는 것을 볼 수 있습니다. 클라이언트 수를 20개로 늘릴 예정입니다. 이 구성을 사용하면 아래 스크린샷에서 이제 인스턴스당 초당 300,000개의 요청을 표시하고 있음을 확인할 수 있습니다. 이 캐시 클러스터에서 초당 1.5만 요청을 성공적으로 달성했습니다.
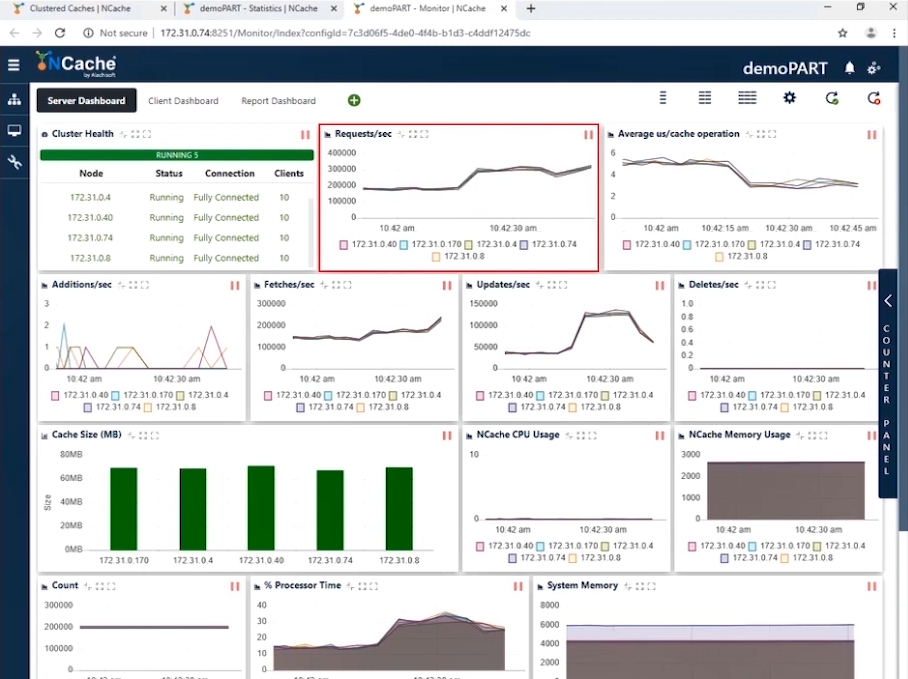
각 서버의 초당 요청 수가 300,000임을 알 수 있습니다. 가져오기는 초당 200,000을 조금 넘고 업데이트는 50,000 - 100,000 사이이며 캐시 작업당 평균 마이크로초가 4마이크로초 미만임을 알 수 있습니다. 파이프라이닝의 영향과 함께 대기 시간이 매우 짧기 때문에 놀라운 일입니다. 클라이언트 쪽에서 트랜잭션 부하가 높을 때 파이프라이닝은 대기 시간을 줄이고 처리량을 늘리는 데 실제로 도움이 됩니다. 이것이 우리가 이 기능을 켜는 것을 권장하는 이유입니다. 또한 캐시 작업당 평균 마이크로초는 이제 캐시 작업당 약 3-4마이크로초입니다.
| 2단계 – 요약 데이터 시트 | |
| 클러스터의 총 캐시 서버 | 5 |
| 연결된 총 클라이언트 인스턴스 | 20 |
| 평균 초당 요청/노드 | 300,000 |
| 총 요청 - 캐시 클러스터 | 1,500,000 |
| % 프로세서 시간(최대) | 30% |
| 시스템 메모리 | 6 GB |
| 대기 시간(마이크로초/캐시 작업) | 3~4마이크로초/작동 |
무대 3 2만 Ops/초 트랜잭션 로드
더 많은 응용 프로그램 인스턴스를 실행하여 로드를 더 늘리면 초당 요청 수가 추가로 증가합니다. 이제 30개의 클라이언트 인스턴스를 모두에 연결하려고 합니다. NCache 서버.
아래 스크린샷에 따라 이제 초당 400,000개의 요청을 성공적으로 처리했음을 알 수 있습니다. NCache 섬기는 사람; 우리는 5 NCache 이로 인해 초당 최대 XNUMX만 건의 트랜잭션이 발생합니다. NCache 캐시 클러스터. 그리고 캐시 작업당 평균 마이크로초는 3마이크로초 미만입니다. 또한 시스템 메모리와 프로세서 시간은 양쪽 모두에서 40 - 50%의 활용률로 한도 아래에 있습니다.
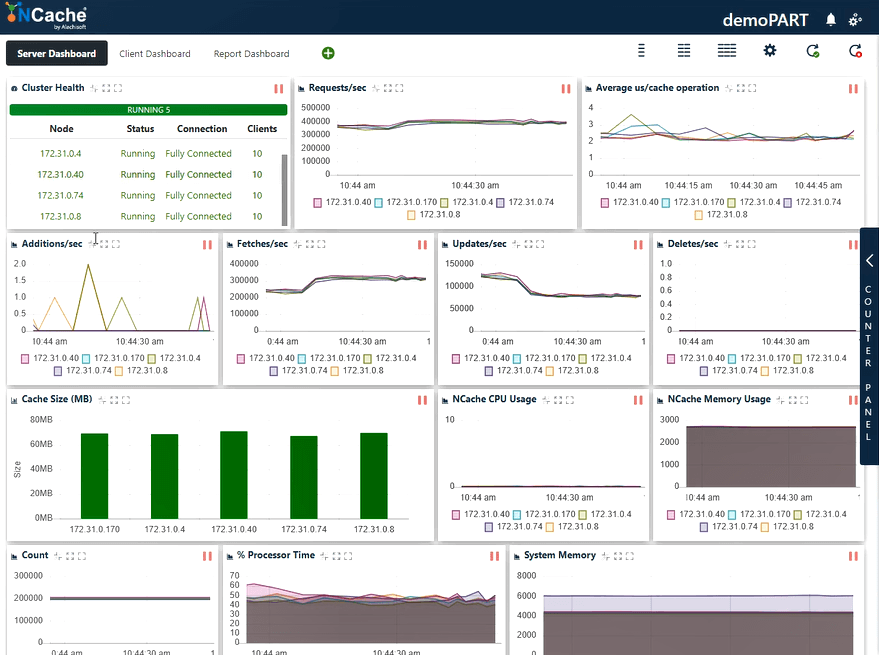
이제 이전 결과보다 개선된 2 ~ 3us/작업 대기 시간이 있습니다. 가져오기, 업데이트, CPU 및 메모리 리소스의 효율적인 활용이 혼합된 것을 다시 한 번 볼 수 있습니다. 우리는 여기서 결론을 내릴 수 있습니다. NCache 선형 확장 가능합니다. 이제 확장성 수치를 검토해 보겠습니다.
| 3단계 – 요약 데이터 시트 | |
| 클러스터의 총 캐시 서버 | 5 |
| 연결된 총 클라이언트 인스턴스 | 30 |
| 평균 초당 요청/노드 | 400,000 |
| 총 요청 - 캐시 클러스터 | 2,000,000 |
| % 프로세서 시간(최대) | 60% |
| 시스템 메모리 | 6 GB |
| 대기 시간(마이크로초/캐시 작업) | 2~3마이크로초/작동 |
벤치 마크 결과
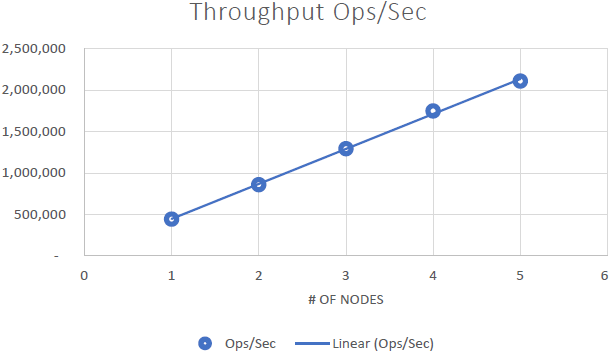
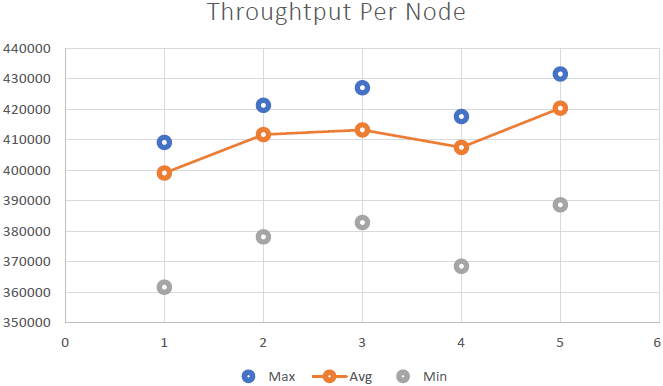
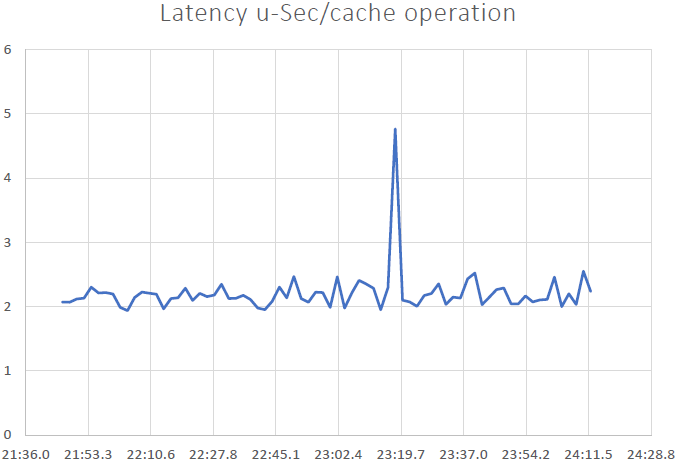
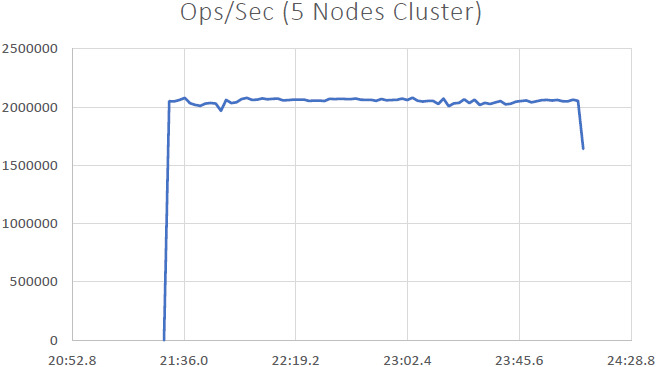
우리는 그것을 증명할 수 있었습니다 NCache 선형 확장 가능하며 벤치마크를 실행한 후 다음과 같은 결과를 얻을 수 있었습니다.
결론
- 선형 확장성: 5개로 NCache 우리는 초당 2백만 요청을 달성할 수 있었습니다. 더 많은 서버를 추가한다는 것은 더 많은 요청 처리 기능을 의미합니다. NCache.
- 낮은 대기 시간 및 높은 처리량: NCache 클러스터 크기가 큰 경우에도 2.5마이크로초 미만(3 ~ XNUMX마이크로초)의 대기 시간을 제공합니다. NCache 대규모에서도 낮은 대기 시간과 높은 처리량 요구 사항을 충족하도록 지원합니다. 지연 시간이 매우 짧습니다. 이는 파이프라이닝에서 파생된 영향입니다. 클라이언트 측에서 트랜잭션 부하가 높을 때 파이프라이닝은 대기 시간을 줄이고 처리량을 늘리는 데 실제로 도움이 됩니다.