对于具有复杂架构的高事务应用程序,不断交换数据会导致负载不均匀和吞吐量延迟。 当涉及到大型和复杂的业务应用程序时,数据提炼是一个巨大的挑战。 为了迎合这一点,流处理用于通过创建数据流来定义特定的数据流。 一个典型的流应用程序由多个生成新事件的生产者和一组处理这些事件的消费者组成。
一种流行的应用程序是 Pub/Sub,发布者输入消息,订阅者接收他们订阅的消息。 但是,在流处理中,Pub/Sub 面临一些限制,例如一旦订阅者收到消息,应用程序就不再保留该消息。 所以稍后,如果另一个订阅者想要来自发布者的消息,则之前的消息不存在。 此外,对于传入的流数据,数据过滤发生在客户端(订阅者)而不是服务器,这使得应用程序架构变得复杂。
为了克服 Pub/Sub 的这些限制, NCache 带有使用连续查询在服务器端处理数据的有效机制。 连续查询允许应用程序收到缓存中数据发生的所有变化的通知,满足特定标准。 本博客借助为流处理创建的解决方案帮助您了解在流处理中使用连续查询的优势 GitHub上.
使用连续查询进行流处理
该解决方案解释了一个电子商务应用程序,该应用程序每天处理数千名客户的在线购买。 如果您查看下图,应用程序中添加了各种类型和类别的客户。 为了高效处理客户,未过滤的客户根据订单数量,通过连续查询,分类过滤为“金”、“银”和“铜”客户。
连续查询 允许应用程序在满足特定条件的数据在缓存内发生更改并且使用 SQL 命令指定条件时接收通知。 例如,如果一个应用程序想要将订单数量较多的客户标记为“黄金客户”,它所要做的就是注册一个 SQL 命令条件,从而提供一个回调。 当结果集中发生满足条件的任何更改时,将触发此回调。 调用回调后,应用程序可以使用标签将这些客户归类为“金牌客户”。
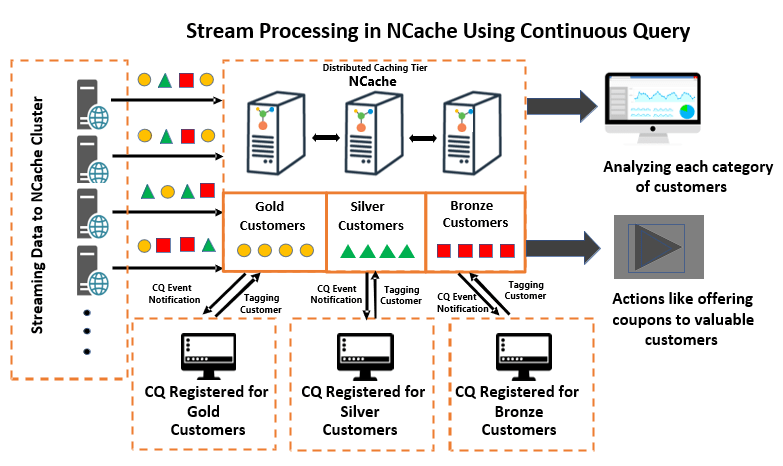
图 1:使用连续查询的流处理
同样,应用程序可以通过注册多个 CQ 创建多个类别,每个 CQ 都有自己的标准和回调。 这样,应用程序只获取它感兴趣的过滤数据。过滤后的数据可以根据业务需求进一步分析,例如根据客户的类别为高端客户提供折扣。
如果在缓存中发生以下任何数据修改操作,则会触发事件:
- 添加: 将满足查询条件的新项目添加到缓存中
- 更新: 更新查询结果集中的现有项目。
- 移除: 从缓存中删除项目或更新任何现有的缓存项目,从而导致从查询结果集中删除项目。
让我们通过一个在缓存中使用流处理和连续查询的快速代码示例。 在此示例中,对将大于 10 的订单添加到“黄金客户”类别的数据执行连续查询。 此外,在添加到查询结果集中的每个项目上都会触发一个事件。
|
1 2 3 4 5 6 7 8 9 10 11 |
string query = SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery (queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification (new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
Continuous Query 保留 Pub/Sub 不保留的数据
现在通过连续查询过滤的数据(对于订单>10的客户)被标记为“金牌客户”并在缓存中更新。 查看下面的代码,看看它是如何完成的。
|
1 2 3 4 5 6 7 8 9 10 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.None); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
即使在处理之后,连续查询也会将数据保留在缓存中。 这样,它解决了 Pub/Sub 面临的不断涌现的数据的问题,即多个应用程序将数据发布到 NCache 消息层。 因此,多个订阅者接收数据并且没有可靠的数据存储,因为一旦接收到消息就会从消息总线中移除。 数据要么由应用程序存储,要么通过添加新数据源来存储,这是一个更复杂的场景。 另一方面,连续查询确保没有数据丢失,从而为您节省了手动持久化数据的所有额外工作。
连续查询通过强大的过滤实现应用解耦
大型复杂应用程序可以根据其架构进行各种分组,例如,在运行 10 个应用程序时,其中两个可能处理金牌客户的数据集,而另外两个可能处理银牌客户的数据集。 在这种情况下,您可能希望每个数据集都有一个单独的业务逻辑,其中数据根据每个应用程序对流处理的需求进行过滤。 因此,如此庞大的复杂应用程序需要解耦,因为应用程序之间的依赖会导致巨大的性能瓶颈以及增加的应用程序复杂性。
在相当复杂的 SQL 语句的帮助下,连续查询非常有效地过滤应用程序的数据,因此没有应用程序与其他应用程序重叠。 这种解耦在微服务架构中非常有用,其中每个服务都在单独的应用程序堆栈上运行。 每个微服务都可以获取和处理自己的数据,而不会造成任何依赖。 使用 Pub/Sub 无法实现这种级别的数据过滤和应用程序解耦。
图 2 显示了在解耦架构中处理各自数据集的各种客户端应用程序,使用 NCache 连续查询。
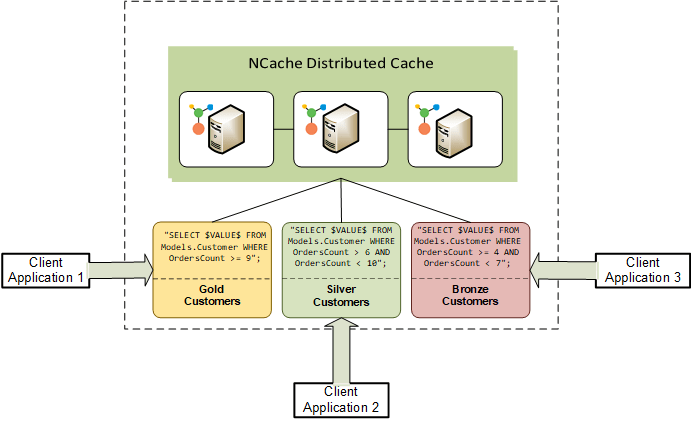
图 2:应用程序之间的解耦
使用标签获取数据
标签 in NCache 为数据添加限定符,用于根据它们对数据进行分类。 对于像上面提到的场景这样的大型数据集,标签对于获取相关数据非常有帮助,而不是在整个缓存中搜索数据。 如果客户属于“黄金客户”类别,则会添加一个标签以便快速检索。 基于这些类别,可以为客户提供额外的好处,例如折扣、优惠券等。 NCache 提供各种 使用标签获取数据的灵活方式,在文档中彻底解释。
现在让我们看一下与“金牌客户”相关的标签的代码示例。 可以向这些客户提供优惠券或高级服务。
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
即将过期的缓存数据
NCache 允许 缓存数据过期 在特定时间间隔后使数据无效,然后以干净的时间间隔将其从缓存中删除。
NCache 提供两种到期类型:
在客户的情况下,到期被添加到不属于任何三个类别的项目,即黄金、白银或青铜。 订单少于 4 的所有其他客户都添加了到期时间间隔,并从缓存中删除,不再进行进一步分析。 但是,属于任一类别的任何客户的过期设置为 None 以将数据保留在缓存中,除非手动删除。 这就是您可以为少于 15 个订单的客户添加 4 秒到期的方法。
|
1 2 3 4 5 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, new TimeSpan(0, 0, 15)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
为什么要使用 NCache?
NCache is 100% .NET/.NET 核心、内存中分布式缓存解决方案,长期处于市场领先地位。 它速度极快且具有线性可扩展性,并且通过缓存数据有效地消除了应用程序的性能瓶颈。 它通过减少昂贵的网络旅行为您节省网络成本。 NCache 为您提供丰富的功能集,例如连续查询,使数据分析非常快速和高效以及其他功能,以促进您的应用程序的顺畅流动。





