现代应用程序处理并生成大量数据。 单个 Web 服务器/数据源发生故障并导致应用程序和无价数据丢失的可能性是软件开发人员的常见噩梦。 但是,如果所有服务器节点都具有相同的数据副本,则可以实现高数据可用性——这意味着即使集群中的少数节点发生故障,也不会丢失任何数据。 但是,当数据开始显着扩展时会发生什么? 在这种情况下,您必须回拨复制并开始对数据进行分区。
NCache 作为分布式内存缓存解决方案,为数据密集型应用程序提供高可扩展性、性能和可用性。 它提出了 POR (分区副本) 拓扑将数据分成多个块(桶),并将它们放在不同的分区中。 为了均匀分布读取和写入负载,数据在多个节点之间进行分区。 这解决了最初通过划分数据来实现可扩展性的问题,但是数据究竟是如何平均划分的呢? 该博客旨在向您介绍数据分区是如何发生的 NCache.
用于平等数据分布的基于散列的分区
通常情况下,各种应用程序采用循环策略将数据分配给不同的分区。 虽然这种方法可以保证均匀分布,但在定位特定数据项时会带来挑战。 由于无法跟踪项目位置,数据的搜索和检索可能会变得非常耗时且效率低下。
要解决此问题, NCache 合并 基于散列的分区. 数据被分成许多桶,这些桶随后分散在几个分区中。 目标是在集群中的节点之间均匀分布桶,以优化性能并确保高可用性。 为了达成这个, NCache 采用哈希技术,根据项的键将每个数据项映射到特定的桶。 现在,要找出存储桶的所有者,您需要对项目的键应用哈希函数,并根据存储桶的总数对其进行修改——我们总共有 1000 个存储桶。
什么是分布图?
协调器服务器在分布式缓存集群中是必不可少的,因为它监督桶的分布并确保每个项目都根据其键分配给特定的桶。 为此,协调服务器创建了一个 分布图 包括桶分布并将其分布到集群中的所有其他分区,以及所有连接的客户端。
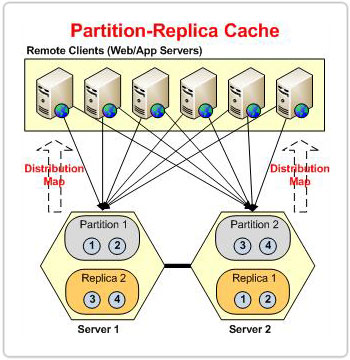
图 1:POR 拓扑中基于分布图的分区
无论集群中有多少台服务器, NCache 确保通过此方法为每个项目提供一致的桶地址。 这是因为 分布图 保持不变,即使集群中的服务器数量发生变化。 因此,即使桶在任何阶段从一个分区移动到另一个分区,项目的桶地址也保持不变。 这保证了数据保持完整,并且在存储桶移动期间没有数据丢失。
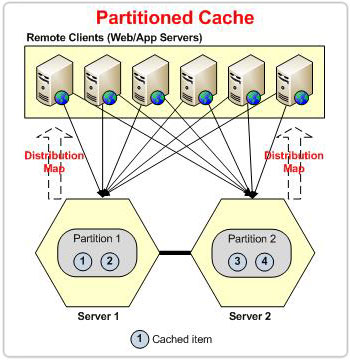
图2:分区拓扑中基于分布图的分区
在分区拓扑的情况下,每当节点离开集群时,集群都会经历数据丢失。 离开节点拥有的桶将全部丢失。 然而,在 POR 的情况下,副本存在于另一个节点上,该节点将 redis根据分布图分配 - 防止数据丢失。
基于分布图的数据分布
得益于由 NCache. 当您启动缓存集群时,所有 1000 个桶都分配给该节点,这导致所有数据都存储在一个分区中。 为了提供最佳性能和负载平衡,当更多节点添加到集群时,桶将在整个分区中平均分配。
例如,当第二个节点添加到集群时,这 1000 个桶在两个分区之间平均分配,每个分区有 500 个桶。 同样,当第三个节点进入集群时,桶是 redis分配,相应地给每个分区 333、333 和 334 个桶。
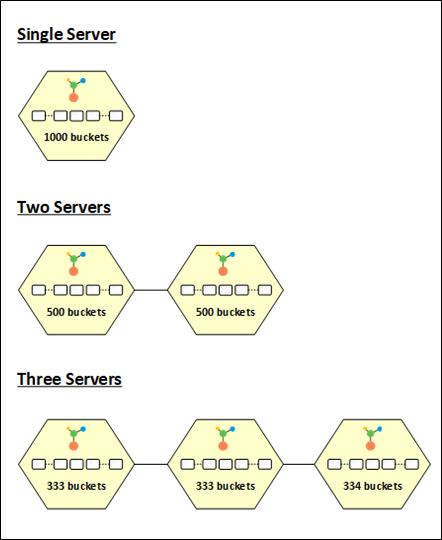
图3: NCache 桶分布
如果分区离开集群,桶分布将再次修改。 为了保持数据的均匀分布,例如,当一个分区退出三节点集群时,属于该分区的 333 或 334 个桶分散在其余两个节点上。 NCache每当桶分布发生变化时, 的状态转移机制就会启动以重新平衡节点之间的数据,确保数据根据桶分布进行最佳分布。 类似地,客户端还接收分布图,该分布图通知正在运行的服务器节点及其基于散列的分布。
数据负载均衡
而 redis在缓存集群的节点周围分配桶, NCache 采用以数据为中心的策略来确保每个分区接收的数据量是平衡的。 为了实现这一点,集群中的每个分区定期与集群中的其他分区交换它拥有的桶的统计信息。 这样可以创建一个平衡的 分布图 这说明了每个分区拥有的数据量。 NCache 自动平衡数据 以确保每个分区接收到相等份额的数据。 它还允许手动平衡数据。 您可以阅读更多相关信息 此处.
结论
总之,利用 POR 将数据拆分为 NCache 是提高应用程序速度和可扩展性的有用技术。 您可以保证数据始终可用,并通过将数据分成更小的块并将它们分布在多个缓存节点上来减少性能瓶颈的可能性。





