我们都遇到过这样的情况,我们必须等待很长时间才能从数据库获得响应,以换取在应用程序服务器上生成的查询。 对于业务关键型应用程序,延迟和响应延迟是无法容忍的。 这就是需要优化缓存解决方案的地方。
虽然缓存通常与键值存储相关联, NCache 通过允许您查询有关对象的非关键属性的数据,它更进一步。 这意味着您可以根据范围广泛的属性访问数据,而不仅仅是键。 这种方法为数据检索提供了更大的灵活性和效率,使分析和管理数据变得更加容易。
随着时间的推移,缓存中的数据会增长,因此您需要在缓存中具备此类功能,您可以在其中生成查询以提高搜索和检索性能。 NCache 使您能够在搜索时以高效的方式查询数据。
创新中心 NCache 优化搜索和检索性能?
NCache 通过索引、投影、块大小和客户端缓存优化其搜索和检索性能。 通过在内存中缓存查询结果,请求响应能力得到显着提高。 由于直接从缓存中提供许多查询,因此节省了额外的数据库访问。 NCache 使用多种方法来提高搜索和检索性能,如下所述。
1.有策略地创建索引
为了基于查询进行高效的数据搜索, NCache 需要创建搜索索引。 与传统数据库不同,传统数据库在没有索引的情况下会很慢并执行全存储搜索来查找数据, NCache 优先考虑性能,强制创建索引。 通过创建索引, NCache 可以确定最适合您搜索需求的数据类型和存储格式,确保搜索快速高效
然而, NCache 使用 索引 因为它是一种面向性能的方法,但是必须非常小心地为搜索索引属性,因为它需要空间来保留索引,并且索引不必要的属性会导致内存和性能开销。
NCache 提供了两种定义索引的方法。
• 预定义索引 (静态索引)
• 运行时索引 (动态指标)
2.巧妙地使用投影
在查询时, 预测 可以显着提高应用程序的性能。 根据您的查询, NCache 使您能够从缓存存储中检索类或特定投影的所有索引特征。
运用 NCache,您可以指定您选择的列以根据您的查询进行投影,以更有效地执行搜索。 除了特定的列投影,您还可以检索多个投影。 下面提到的是一个项目的例子 $GROUP$ 和 $Value$ 在单个查询中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
string query = "SELECT $Value$, $Group$ FROM FQN.Product WHERE Productid > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader. Read()) { Product value = reader.GetValue(1); string group Name = reader.GetValue(2); // Perform operations } } else { // Null query result set retrieved } |
默认情况下,如果您不指定投影,那么完整的对象连同索引的特征会根据请求从服务器传输到客户端——它会比选择性数据慢。 下面提到的是一个示例,它通过缓存从缓存中检索与类产品相关的所有字段 * 运营商。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
string query = "SELECT * FROM FQN.Product WHERE ProductID > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { string result = reader.GetValue("ProductID"); // Perform operations } } else { // Null query result set retrieved } |
重要的是要注意,通过使用预测, NCache 减少了检索对象的所有索引特征的额外工作,并且只检索所需的列。 NCache 通过促进更好的查询语法,帮助用户以这种方式提高性能。
3. 块大小/以块的形式获取数据
NCache 给出了另一个用于查询优化的特性,称为块大小。 执行搜索查询后,应用程序以块的形式接收数据/密钥包,其中每个块代表特定大小的数据/密钥包。 有多种查询数据的方法,无论您是只想查询键还是选择项,或者是对象的一组完整属性(称为数据集)。
结果集越大,为响应生成的查询而获取的速度越慢。 因此,使用数据而不是一次获取整个结果集的客户端从服务器一个接一个地使用块中的数据。 NCache 默认情况下,将数据以较小的块从服务器传送到客户端,合并数据块,然后将数据提供给应用程序。
块大小的默认值为 512 KB,但用户可以配置 块大小 根据他们的要求,同时执行阅读器根据指定的查询对缓存进行搜索。 由于数据以块的形式在网络上传输,这提高了数据搜索和检索的性能。
4.使用客户端缓存
NCache 具有称为客户端缓存(L1 缓存)的通用功能。 L1 是主缓存的一个子集,它更靠近应用程序,可以是 进程内 和, 输出程序. 由于它是主缓存(L2 缓存)的子集,因此查询不会使用 L1 缓存执行。 只有基于键的操作,比如 add, get或 getbulk 操作通过首先在 L1 缓存中搜索键来执行,然后从 L2 缓存中获取丢失的键,合并和服务。
二级缓存包含完整的数据,因此标签执行的查询和操作始终在其上运行。 用户可以仅从 L2 缓存中获取密钥,而不是执行查询以从 L2 缓存中检索所有数据。 然后使用 bulk get 从 L2 缓存中检索这些键。 如果缺少任何数据,它将从 L1 缓存中提供。 频繁执行的读/写操作存储在客户端缓存中,从而加快对相同数据的后续请求的检索时间。
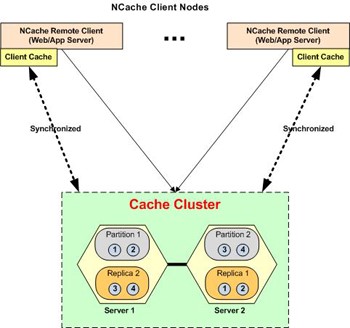
描述客户端缓存工作的图表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// Executing query to fetch keys only ICacheReader reader = _cache.SearchService.ExecuteReader(queryCommand, false); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { //Populate Keys List keys.Add(reader.GetValue(0)); } } //Get Data using Bulk API. IDictionary<string, Product> productsList = _cache.GetBulk(keys); //If the number of keys is very large, you can break the list into multiple chunks and then do GetBulk for each chunk separately. |
NCache 提供示例应用程序,用于从 Client Cache 上有效地获取数据 GitHub上.
结论
在这篇博客中,我们介绍了多种方式 NCache 用于增强其查询搜索和数据检索性能。 NCache 不仅可以提高应用程序性能,还可以确保高可用性和可扩展性以满足用户负载。 所以,无需再等待 下载 NCache 现在开始您的 60 天免费试用!





