Las aplicaciones modernas procesan y generan grandes volúmenes de datos. La posibilidad de que falle un solo servidor web/fuente de datos, lo que resulta en la pérdida de aplicaciones y datos invaluables es una pesadilla común entre los desarrolladores de software. Sin embargo, puede lograr una alta disponibilidad de datos si todos los nodos del servidor tienen una copia idéntica de los datos; esto implica que no habrá pérdida de datos si algunos nodos fallan en el clúster. Pero, ¿qué sucede cuando los datos comienzan a expandirse significativamente? En casos como estos, debe volver a marcar la replicación y comenzar a particionar los datos.
NCache Al ser una solución de almacenamiento en caché distribuida y en memoria, proporciona alta escalabilidad, rendimiento y disponibilidad para aplicaciones con uso intensivo de datos. Adelanta el POR (Réplica Particionada) topología para dividir los datos en varios fragmentos (depósitos) y colocarlos en diferentes particiones. Para distribuir uniformemente las cargas de lectura y escritura, los datos se dividen en varios nodos. Esto resuelve el problema inicial de lograr la escalabilidad al dividir los datos, pero ¿cómo se dividen exactamente los datos por igual? Este blog tiene como objetivo educarlo sobre cómo se realiza la partición de datos en NCache.
Particionamiento basado en hash para distribución equitativa de datos
La mayoría de las veces, varias aplicaciones emplean la estrategia round-robin para asignar datos a diferentes particiones. Si bien este enfoque garantiza una distribución uniforme, presenta un desafío cuando se trata de ubicar elementos de datos específicos. La búsqueda y recuperación de datos puede llevar mucho tiempo y ser ineficaz sin forma de rastrear las ubicaciones de los elementos.
Para resolver este problema, NCache incorpora Particionamiento basado en hash. Los datos se dividen en muchos cubos que posteriormente se dispersan entre varias particiones. El objetivo es distribuir los cubos de manera uniforme entre los nodos del clúster para optimizar el rendimiento y garantizar una alta disponibilidad. Lograr esto, NCache emplea una técnica de hashing que asigna cada elemento de datos a un depósito específico en función de la clave del elemento. Ahora, para averiguar el propietario del cubo, debe aplicar la función hash en la clave del elemento y modificarla según el número total de cubos: tenemos 1000 cubos en total.
¿Qué es un Mapa de Distribución?
El servidor coordinador es esencial en un clúster de caché distribuida porque supervisa la distribución de depósitos y garantiza que cada elemento se asigne a un depósito en particular en función de su clave. Para lograr esto, el servidor coordinador crea un mapa de distribucion incluida la distribución del depósito y la distribuye a todas las demás particiones del clúster, así como a todos los clientes conectados.
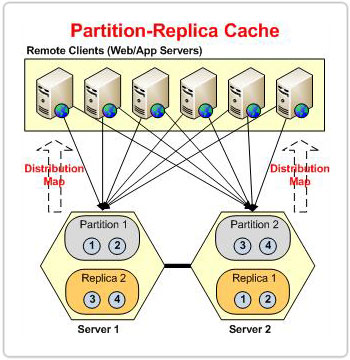
Figura 1: Particiones en base al mapa de distribución en topología POR
No importa cuántos servidores haya en el clúster, NCache se asegura de que a cada elemento se le asigne una dirección de depósito coherente a través de este método. Esto se debe a que el mapa de distribucion permanece constante, incluso si cambia el número de servidores en el clúster. Como resultado, incluso si un depósito se mueve de una partición a otra en cualquier etapa, la dirección del depósito de un elemento sigue siendo la misma. Esto garantiza que los datos permanezcan intactos y que no se pierdan datos durante los movimientos del balde.
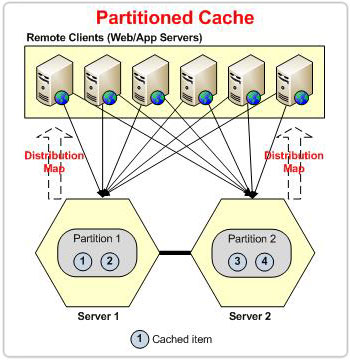
Figura 2: Partición basada en el mapa de distribución en topología de partición
En el caso de la topología con particiones, cada vez que un nodo abandona el clúster, el clúster experimenta una pérdida de datos. Todos los cubos propiedad del nodo saliente se perderán. Sin embargo, en el caso de POR, la réplica está presente en otro nodo que será redistributados sobre la base del mapa de distribución, evitando la pérdida de datos.
Distribución de datos basada en un mapa de distribución
Los datos se distribuyen por igual entre todos los nodos del clúster de caché gracias a la estrategia de distribución dinámica de cubos que ofrece NCache. Los 1000 cubos se asignan al nodo cuando inicia un clúster de caché, lo que da como resultado que todos los datos se almacenen en una sola partición. Para proporcionar el mejor rendimiento y equilibrio de carga, los cubos se dividen por igual entre las particiones cuando se agregan más nodos al clúster.
Los 1000 cubos, por ejemplo, se dividen en partes iguales entre las dos particiones cuando se agrega un segundo nodo al clúster, dando a cada división 500 cubos. De manera similar, cuando un tercer nodo ingresa al clúster, los depósitos se redistributado, dando a cada partición 333, 333 y 334 baldes, según corresponda.
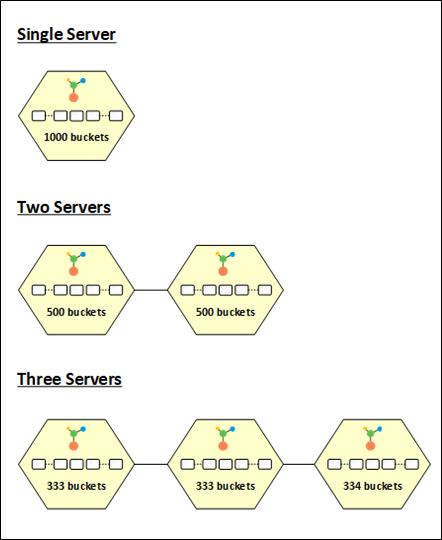
Figura 3: NCache Distribución de baldes
La distribución de cubos se modifica una vez más si una partición abandona el clúster. Para mantener una distribución uniforme de los datos, por ejemplo, cuando una partición sale de un clúster de tres nodos, los cubos 333 o 334 que pertenecen a esa partición se dispersan entre los dos nodos restantes. NCacheEl mecanismo de transferencia de estado se activa para reequilibrar los datos entre los nodos cada vez que cambia la distribución del depósito, lo que garantiza que los datos se distribuyan de manera óptima de acuerdo con la distribución del depósito. De manera similar, el cliente también recibe el mapa de distribución que informa sobre los nodos del servidor en ejecución y sus distribuciones basadas en hash.
Equilibrio de carga de datos
Aunque la redistributar cubos alrededor de los nodos del clúster de caché, NCache adopta una estrategia centrada en los datos para asegurarse de que la cantidad de datos que recibe cada partición esté equilibrada. Para lograr esto, cada partición del clúster intercambia periódicamente las estadísticas de los cubos que posee con las otras particiones del clúster. Esto permite la creación de un equilibrio mapa de distribucion que representa la cantidad de datos que posee cada partición. NCache equilibra automáticamente los datos para garantizar que cada partición reciba una parte igual de datos. También permite equilibrar los datos manualmente. Puedes leer más al respecto esta página.
Conclusión
En conclusión, utilizar POR para dividir datos en NCache es una técnica útil para mejorar la velocidad y la escalabilidad de las aplicaciones. Puede garantizar que los datos estén siempre disponibles y reducir la posibilidad de cuellos de botella en el rendimiento dividiendo los datos en fragmentos más pequeños y distribuyéndolos en numerosos nodos de caché.





