Manejo de datos relacionales en una caché distribuida
Seminario web grabado
Por Ron Hussain y Adam J. Keller
En este seminario web en video, aprenda cómo aplicar sus relaciones de datos existentes a objetos en caché para el almacenamiento en caché distribuido.
Puede esperar escuchar acerca de:
- El modelo de almacenamiento de datos para una base de datos relacional y para un caché distribuido
- La bondad del mapeo relacional de objetos: cómo administrar las relaciones de datos a nivel de objeto
- Mapeo de relaciones 'uno-uno', 'uno-muchos' y 'muchos-muchos'
- Usar NCache características para construir relaciones entre objetos para imitar comportamientos de datos relacionales
- uso de dependencia basada en claves, lenguaje de consulta de objetos, grupos, API de grupo, colecciones y etiquetas
- Otras funciones importantes de almacenamiento en caché distribuido para datos relacionales
Hablaré sobre tener un almacenamiento en caché distribuido en su lugar. Cuando tiene una base de datos relacional, sabe, tiene algunos desafíos, algunos problemas de rendimiento, algunos problemas de escalabilidad y luego pasa a usar una caché distribuida junto con la base de datos relacional. ¿Cuáles son los desafíos que obtienes y cómo manejar esos desafíos? Entonces, eso es lo que tenemos en la agenda para el seminario web de hoy.
Va a ser bastante práctico. Quiero mostrarles algunos ejemplos de código. Hablaré de algunos ejemplos reales. Tengo algunos ejemplos alineados que usaré para demostrar esto. Y, luego, hacia el final, también tendría una parte práctica para repasar algunos conceptos básicos. NCache configuraciones.
NCache, ese es el principal producto de almacenamiento en caché distribuido. Lo usaremos como un producto de ejemplo para este seminario web en particular. Pero, en general, es un seminario web sobre un tema general. Tenemos datos relacionales en la base de datos y luego tienes un caché distribuido. Cómo hacer la transición y luego comenzar a usar el caché distribuido dentro de, ya sabes, los datos relacionales que tienen relaciones y que son datos estructurados. Entonces, analicemos esto.
¿Qué es la escalabilidad?
Entonces, antes que nada, hablaré sobre la escalabilidad, el concepto de escalabilidad. La escalabilidad es una habilidad dentro de la aplicación donde puede aumentar la carga transaccional. Donde puede manejar más y más solicitudes de carga fuera de la arquitectura de la aplicación. Y no se compromete con el rendimiento. Entonces, si tiene un alto rendimiento y baja latencia, esa capacidad se llama escalabilidad. Por lo tanto, puede manejar una gran cantidad de cargas de solicitudes y el rendimiento de las solicitudes individuales no disminuye. ¡Es lo mismo! Y, con más recursos, incluso puede aumentar eso y la escalabilidad lineal es un término asociado que le permite escalar horizontalmente donde tiene más o más capacidad de manejo de carga de solicitudes introducida en el sistema al agregar más servidores. Y, en la mayoría de los casos, el rendimiento no baja.
Entonces, si tiene una latencia baja y tiene una mejora lineal en la carga de solicitudes, anteriormente manejaba, digamos, 10,000 solicitudes por segundo o incluso para cinco usuarios, tiene cierta cantidad de latencia, digamos unos pocos milisegundos o tiempos de respuesta de submilisegundos para cinco usuarios. ; debe tener el mismo tipo de respuestas, el mismo tipo de ejecución del mismo tipo de latencia para cinco mil usuarios o cincuenta mil usuarios. Y esa capacidad de seguir aumentando la carga de usuarios y sus solicitudes asociadas se llama escalabilidad lineal.
¿Qué aplicaciones necesitan escalabilidad?
Entonces, ¿cuáles son las aplicaciones típicas que necesitan escalabilidad,

Van a ser sus aplicaciones web ASP.NET, aplicaciones web Java o incluso aplicaciones web generales .NET que son de cara al público. Podría ser un sistema de comercio electrónico, podría ser un sistema de emisión de boletos de avión, un sistema de reservas o podría ser un servicio financiero o de atención médica que tiene muchos usuarios que realmente usan su cara al público. Podrían ser servicios web WCF o cualquier otro servicio de comunicación que esté interactuando con algunas capas de acceso a datos o esté tratando con algunas aplicaciones front-end. Pero, puede estar manejando millones de solicitudes en cualquier momento dado. Podría ser Internet de las cosas, algunos dispositivos de back-end que pueden procesar datos que procesan algunas tareas para esos dispositivos. Por lo tanto, podría tener una gran cantidad de solicitudes cargadas. El procesamiento de big data es una palabra de moda común en estos días, donde tenemos muchos servidores informáticos pequeños y económicos y, a través de la distribución de datos en múltiples servidores, en realidad procesa una gran cantidad de cargas de datos.
Y, de manera similar, habría una gran carga de solicitudes de modelos para esos datos en particular. Y luego podría haber otras aplicaciones de servidor generales y aplicaciones de nivel que pueden estar manejando millones de solicitudes, muchos usuarios, esos son los principales candidatos para la escalabilidad. Esas son las aplicaciones que necesitan escalabilidad dentro de la arquitectura.
Cuello de botella de escalabilidad
Este es un diagrama típico. ¿Cuál es el cuello de botella de la escalabilidad?
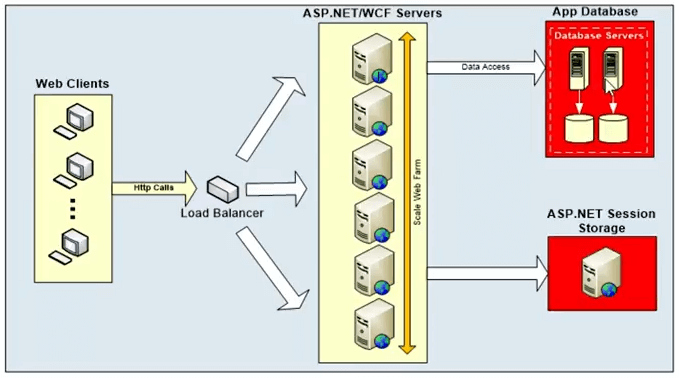
Entonces, estas son las aplicaciones. Por diseño, estos marcos son muy escalables. El formulario web ASP.NET o el formulario WCF hay opciones que puede usar para escalar estos sistemas. Pero todos hablan con una base de datos de back-end y, por lo general, es una base de datos relacional. También podría ser un almacenamiento de sesión ASP.NET, un mainframe o un sistema de archivos, pero eso no es lo que trataremos en el seminario web de hoy. El seminario web de hoy se centra más en los datos relacionales. Por lo tanto, los datos relacionales son una fuente única. Aunque aquí tienes una plataforma muy escalable. Puede agregar más y más servidores en este nivel. Puede escalar horizontalmente colocando un balanceador de carga al frente y ese balanceador de carga puede enrutar solicitudes entre diferentes servidores. Pero todos estos servidores web terminan hablando con un nivel de base de datos que no es tan escalable.
Entonces, eso va a ser una fuente de controversia. Va a ser lento para comenzar y luego no puede escalar. Es una fuente única, no hay opción de agregar más y más servidores de bases de datos para aumentar la capacidad de solicitud. Por lo tanto, la capacidad de solicitud puede llegar al máximo y eso puede conducir a una alta latencia. Por lo tanto, es un problema de capacidad para el manejo de una solicitud y también podría terminar en un problema de latencia, por lo que puede ahogar el sistema cuando tiene una gran carga de solicitudes.
La Solución
Entonces, ese es el problema principal con las fuentes de datos relacionales y la solución es muy simple: comienza a usar un caché distribuido.
Un sistema de almacenamiento en caché distribuido como NCache que es súper rápido porque está en memoria en comparación y luego es linealmente escalable. No es solo un servidor único. Es un entorno de servidor múltiple donde tenemos un equipo de servidores unidos en capacidad. Agrupa la capacidad de la memoria, así como la capacidad transaccional, y obtiene un modelo escalable muy lineal. Y, NCache es exactamente ese tipo de solución que puede usar para manejar los problemas de escalabilidad de la base de datos.
¿Qué es la caché distribuida en memoria?
¿Cómo es un sistema general de almacenamiento en caché distribuido en memoria? NCache? Cuales son las caracteristicas?
Clúster de múltiples servidores de caché económicos
Será un grupo de múltiples servidores de caché económicos que se unirán en una capacidad lógica.
Entonces, este es un ejemplo de ello. Podría tener de dos a tres servidores de almacenamiento en caché. Para NCache, puede usar el entorno Windows 2008, 2012 o 2016. Único requisito previo para NCache es .NET 4. Y es un nivel medio entre su aplicación y la base de datos y es muy escalable en comparación con el nivel de su base de datos, pero es algo que le daría el mismo tipo de escalabilidad que obtendría de una web .NET acelerada. formulario o formulario web de servicios web de WCF.
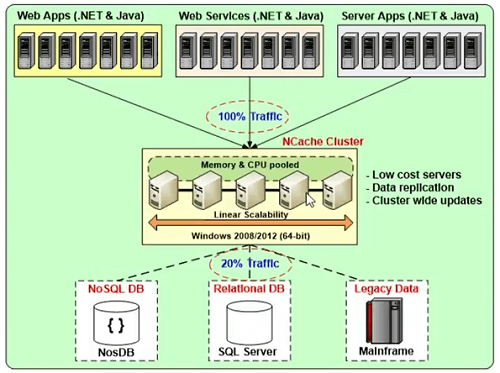
Sincroniza las actualizaciones de caché en todos los servidores de caché
Sincroniza las actualizaciones de caché en todos los servidores de caché para que la coherencia de los datos esté integrada en el protocolo. Todas las actualizaciones se aplican de manera automática con una comprensión de la vista de datos consistente para todos los clientes que están conectados a ella.
Escala linealmente las transacciones y la capacidad de la memoria
Debería escalar linealmente para las transacciones, así como para la capacidad de la memoria, simplemente agregue más servidores y no debería aumentar la capacidad en respuesta a eso. Si tiene dos servidores y agrega un tercer y cuarto servidor, esencialmente debería duplicar la capacidad de ese sistema ahora que tiene el doble de servicio. Entonces, eso es lo que NCache ofertas también.
Replica los datos para mayor confiabilidad.
Luego, la replicación es otra característica de la confiabilidad. Cualquier servidor que se caiga, en primer lugar, no debería tener ninguna pérdida de datos o tiempo de inactividad. Debe ser un sistema altamente confiable y altamente disponible y eso es lo que NCache cuidar algo.
NCache Despliegue
Entonces, habiendo discutido esto, tiene un problema de escalabilidad con las fuentes de datos relacionales y los sistemas de almacenamiento en caché distribuidos como NCache es una solución para eso y se convierte en un nivel central entre sus aplicaciones y la base de datos y sus datos existen en dos lugares.
Tiene datos en la base de datos y luego tiene datos en el caché distribuido. Por lo que entonces NCache también gestiona algunos desafíos de sincronización que puede tener cuando tiene datos en dos fuentes diferentes. Hay un seminario web separado sobre este tema, pero, solo para informarle que hay algunos proveedores de capa de acceso a datos, hay algunas dependencias de notificación de cambios que puede configurar.
Por lo tanto, cualquier cambio en la base de datos puede desencadenar una invalidación o actualización de elementos en el caché y, de manera similar, cualquier cambio o actualización que ocurra en el caché se puede aplicar en la base de datos. Entonces, esto se puede lograr con la ayuda de nuestros proveedores de capa de acceso a datos; Lectura directa y Escritura directa.
Y, luego, también tenemos algunas dependencias de cambio de base de datos, dependencias de cambio de registro que en realidad usamos para garantizar el 100% de sincronización entre la base de datos y los registros de caché. Pero, por lo general, los datos existen en dos lugares diferentes. Tiene datos en el caché, que generalmente es un subconjunto de los datos y luego tiene datos reales en la base de datos. Cuando migra datos, es esencialmente una migración de datos. Aunque está utilizando estas dos fuentes en combinación entre sí, son dos fuentes diferentes.
¿Qué datos almacenar en caché?
Antes de continuar, hablaremos rápidamente sobre los tipos de datos que puede almacenar en caché; podrían ser datos de referencia, podrían ser datos transaccionales.

Es más una lectura intensiva de datos que almacena en caché, por lo general pertenece a una base de datos relacional. No es que no cambie, no es 100% estático. Están cambiando los datos, pero la frecuencia de ese cambio no es tan grande. Entonces, eso se clasificaría como datos de referencia. Y, luego, siempre tenemos datos transaccionales que cambian con mucha frecuencia. Con tanta frecuencia como en unos segundos, unos minutos o en algunos casos que podría ser en unos pocos milisegundos.
Y, luego, la mayoría de los datos almacenados en caché son relacionales. Se trae de una base de datos relacional y ya he discutido que tiene datos de copia maestra en la base de datos relacional y luego tiene un subconjunto de esos datos, una referencia y transaccional, llevados a la memoria caché distribuida. ¡Derecha!
¿Cuál es el desafío?
Entonces, ¿cuál es el desafío? Entonces, ¡discutamos ese desafío! Cuando mueve sus datos de una fuente de datos a una relación en un caché distribuido para lograr más rendimiento, más escalabilidad y más confiabilidad para el sistema. Analicemos rápidamente cuáles son los desafíos que ven.

Funciona muy bien. Mejora tu rendimiento porque está en la memoria. es linealmente escalable, por lo que se ocupa de los problemas de escalabilidad con la base de datos. No es un único punto de falla porque hay múltiples servidores y cualquier servidor puede caerse. Puede activar los servidores sin ningún problema. El mantenimiento se vuelve mucho más fácil. Sus actualizaciones se vuelven mucho más fáciles. Entonces, en comparación, obtienes muchos beneficios. Pero hay un desafío que debe abordar y debe tenerlo en cuenta cuando migre sus datos o mueva sus datos de la base de datos al caché distribuido y comience a usar el sistema de almacenamiento en caché distribuido.
Entonces, el caché distribuido es una tabla hash como interfaz. ¡Derecha! Cada elemento está separado con la clave y un valor, ¿verdad? Por lo tanto, es una tabla hash donde los elementos de cada objeto en el caché o cada elemento en el caché o un registro en el caché se representa con la ayuda de una clave. Entonces, no es una tabla o no es un dato relacional donde tenemos relaciones, tenemos esquemas definidos, tenemos entidades que tienen relaciones apropiadas entre sí. Va a ser un elemento de valor clave separado que representa un objeto en el caché. Entonces, la base de datos tiene relaciones entre entidades y cuando migra sus datos o cuando mueve sus datos de una base de datos relacional a un caché distribuido, pierde esa relación característica de esos datos.
Entonces, de forma predeterminada, no tiene esa capacidad, por lo que podemos eliminar esto. Ese es uno de los principales desafíos y luego hay otros desafíos asociados. Las consultas de la base de datos dan como resultado una colección de objetos. También da como resultado una tabla de datos o un lector de datos. Entonces, tratar con tablas de datos y lectores de datos en un caché distribuido no es una buena idea, ¿verdad? así que en realidad pasaremos por todos estos desafíos uno por uno.
Principalmente, discutiremos cómo administrar las relaciones en la memoria caché distribuida una vez que haya traído datos de una fuente de datos relacionales a la memoria caché, cómo abordar ese detalle.
Mirar en el NCache API
Entonces, a continuación, hablaremos sobre la API de almacenamiento en caché.

Ahora que hemos discutido que es básicamente un almacén de valor clave. Tenemos un cache.add donde tenemos una clave "mykey" y luego tenemos un objeto que es cualquier dato permitido y objeto serializado permitido. podría ser cualquier objeto de cliente, objeto de producto, objeto de pedido. Pero este es un ejemplo muy simple de hola mundo en el que llamamos a los métodos de valor clave usando cache.add, cache.update. De manera similar, llamamos a cache.get para recuperar el mismo elemento y luego llamamos a cache.remove.
Administrar relaciones en la caché
¡Hacia adelante! Entonces, ¿cómo administrar las relaciones en el caché? Ahora que hemos definido este desafío de que el caché es una tabla hash como interfaz, es un par de valores clave. El valor es un objeto .NET y la clave es una clave de cadena que formateas y estos son objetos independientes entre sí. Y, la base de datos tiene tablas de relaciones que tienen relaciones entre sí. Podría ser una relación de uno a uno de uno a muchos y de muchos a muchos entre diferentes tablas.
Primer paso: usar la dependencia de caché
Hay dos cosas que debe considerar hacer primero que nada, debe considerar usar la dependencia de caché y nos enfocamos principalmente en la dependencia basada en claves que es una de las características y le mostraré algunos ejemplos de código que lo ayudan a mantener un seguimiento de la dependencia unidireccional entre los elementos de caché.

Entonces, podría tener un objeto principal y luego podría tener un objeto dependiente en ese Objeto en particular. Y, la forma en que funciona es que un elemento depende de otro. El elemento principal, el objeto primario o el objeto principal; si pasa por un cambio, se actualiza o elimina, el elemento dependiente automáticamente se elimina del caché.
Un ejemplo típico que he alineado en las próximas diapositivas es la lista de pedidos de un determinado cliente. Entonces, tiene un cliente A. Tiene una lista de pedidos, digamos 100 pedidos, ¿qué pasa si ese cliente se actualiza o se elimina del caché? No necesita esos pedidos asociados con eso, por lo que es posible que también desee hacer algo con respecto a la recopilación de esos pedidos y eso es exactamente para lo que es esta dependencia, necesita tener un enlace entre estos 2 registros ya que estos están relacionados en el en el base de datos relacional.
Entonces, esta dependencia también puede tener una naturaleza en cascada donde A depende de B y B depende de C. Cualquier cambio en C desencadenaría una invalidación de B y eso, a su vez, también invalidaría A. Por lo tanto, podría ser una dependencia en cascada y luego también podría ser una dependencia de varios elementos. Un elemento puede depender tanto del elemento A como del elemento B y, de manera similar, un elemento principal también puede tener varios elementos secundarios. Y esta fue una característica introducida inicialmente por la memoria caché de ASP.NET. Era una de las características poderosas que NCache también tiene. Lo proporcionamos como un objeto de dependencia de caché separado y uno de los objetos elegantes y este será el enfoque principal en este seminario web en particular.
Segundo paso: usar el mapeo relacional de objetos
Segundo paso, para mapear sus datos relacionales, hay otro desafío que le recomendamos que mapee sus objetos de dominio en su modelo de datos, ¿verdad?

Por lo tanto, sus objetos de dominio deben representar una tabla de base de datos. Debería usar algún tipo de mapeo O/R, también puede usar algunas herramientas de mapeo O/R. Simplifica su programación, puede reutilizar el código una vez que haya asignado las clases a las tablas de su base de datos. Puede usar incluso las herramientas de mapeo ORM u O/R como Entity Framework y NHibernate también. Estas son algunas herramientas populares.
La idea aquí es que deberías tener clases en la aplicación. Los objetos, los objetos de dominio en la aplicación. Por lo tanto, los objetos de su base de datos, las tablas de datos o los lectores de datos se transforman y se asignan a los objetos del dominio. Por lo tanto, una tabla de clientes debe representar una clase de cliente en la aplicación. De manera similar, la colección ordenada o la tabla de pedidos deben representar la clase de pedido y la aplicación. Y luego esos son los objetos que maneja y almacena en caché distribuida y formula relaciones con la ayuda de Key Dependency.
Ejemplo de manejo de relaciones
¡Tomemos un ejemplo!
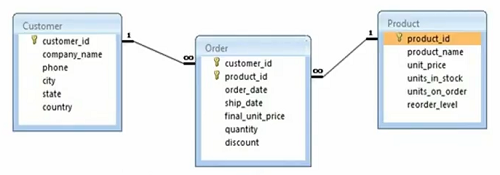
Y tenemos nuestro modelo de base de datos de Northwind. Tenemos tabla de clientes, tenemos tabla de pedidos y luego tenemos Producto. Tenemos todos los nombres de las columnas del cliente, tenemos la identificación del cliente, el nombre de la empresa, el teléfono, la ciudad, el estado, el país y algunos atributos. De igual forma tenemos producto con Product ID, nombre, precio, unidades en stock, unidades en pedido, nivel de reorden. Entonces, esos son algunos atributos o algunas columnas del producto y luego también tenemos la tabla de pedidos que tiene ID de cliente e ID de producto como claves externas. Eso es formular una clave principal compuesta y luego tenemos la fecha de pedido, la fecha de envío y algunos atributos de los pedidos en sí. Y si nota eso, hay una relación de uno a muchos entre el cliente y el pedido y luego hay una relación de uno a muchos entre el producto y el pedido. De manera similar, tenemos muchos a uno y muchos a uno entre pedido y cliente y pedido y producto, respectivamente. Entonces, abordaremos este escenario en particular.
Inicialmente, fue la relación de muchos a muchos del producto del cliente la que se normalizó en dos relaciones de uno a muchos. Entonces, este es un modelo de datos normalizado y usaremos un ejemplo de esto donde tenemos una clase en el objeto principal asignado a este modelo de datos en particular. Entonces, hablaremos sobre el objeto principal en un momento, pero permítanme mostrarles rápidamente el ejemplo aquí.
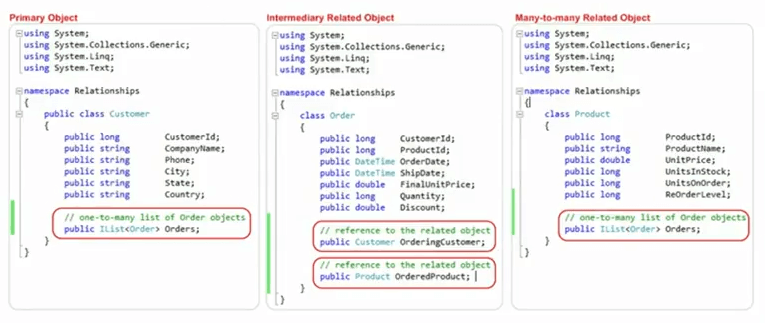
Observe que los objetos de dominio se asignaron a nuestro modelo de base de datos. Para este mismo ejemplo, tenemos una clase de cliente que tiene una ID de cliente que se utilizará como clave principal y luego tenemos una colección de pedidos que representa demasiadas relaciones con la clase de pedido. Del mismo modo, tenemos un producto que tiene atributos de producto iguales a estos ID de producto, nombre, precio unitario, ¿verdad? Y luego tenemos la colección de pedidos aquí también, lo que representa una relación de uno a muchos y en el lado del pedido tenemos la identificación del cliente traída de aquí, la identificación del producto traída de aquí y luego tenemos el cliente que realiza el pedido, el cliente de muchos a una relación y luego tenemos un producto de pedido de tantos a una relación capturada como parte del objeto de dominio.
Entonces, esta es una de las técnicas que voy a cubrir con gran detalle en las próximas diapositivas. Déjame mostrarte estos objetos dentro de Visual Studio también, así que este es uno de la clase.
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.Runtime;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Alachisoft.NCache.Runtime.Dependencies;
using System.Collections;
namespace Relationships
{
public class Customer
{
public long CustomerId;
public string CompanyName;
public string Phone;
public string City;
public string State;
public string Country;
// one-to-many list of Order objects
public IList<Order> Orders;
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// Let's cache each product as seperate item. Later
// we'll search them through OQL
foreach (Product product in products)
{
string productKey = "Product:ProductId:" + product.ProductId;
cache.Add(productKey, product, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
cache.GetGroupData("DummyGroup", "DummySubGroup");
cache.GetByTag(new Alachisoft.NCache.Runtime.Caching.Tag("DummyTag"));
}
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string query = "SELECT Relationships.Product WHERE this.UnitPrice >= ?";
Hashtable values = new Hashtable();
values.Add("UnitPrice", unitPrice);
ICacheReader products = cache.ExecuteReader(query, values, true);
IList<Product> prodList = new List<Product>();
// For simplicity, assume that list is not very large
while (products.Read())
{
prodList.Add((Product)products.GetValue(1));// 1 because on 0 you'll get the Cache Key
}
return prodList;
}
}
}Una cosa que recomendaría es que decores estas clases con una etiqueta serializable, ¿verdad? Entonces, necesitas almacenarlos en caché, ¿verdad? Por lo tanto, estos objetos de dominio deben serializarse porque estos son los que van a viajar de ida y vuelta entre su aplicación cliente y el caché distribuido.
Entonces, tenemos clase de cliente, tenemos clase de producto, aquí mismo. Una lista de pedidos y tenemos una clase de pedido que también tiene todos los atributos que se muestran en la diapositiva de presentación.
¿Qué es el Objeto Primario?
A continuación, hablaremos sobre el objeto principal. Ahora que hemos mostrado algunos objetos principales que se asignan en este modelo de datos de dominio. Le mostraremos algunas técnicas para repasar las relaciones uno a uno, uno a muchos y muchos a muchos.
Entonces, antes que nada, hablaré sobre un término que usaré en las próximas diapositivas.

Objeto principal, es un objeto de dominio. Está asignado a su base de datos. Es un punto de partida de su aplicación, por ejemplo, tiene un objeto de cliente y luego, si necesita pedidos, necesita que el cliente comience, ¿verdad? Por lo tanto, es el primer objeto que obtiene su aplicación y todos los demás objetos relacionados con este se relacionarán con este, ¿verdad?
Otro ejemplo podría ser si está procesando los pedidos correctamente, por lo que es posible que desee buscar pedidos en esa unidad de procesamiento y luego le gustaría saber sobre el cliente que lo ordenó para enviar ese pedido en particular, ¿verdad? Entonces, en ese caso, el pedido se convierte en su objeto principal y luego tiene una relación de muchos a uno o tiene una relación con uno de los clientes que realmente ordenó ese pedido en particular o todos los productos dentro de ese pedido. Por lo tanto, va a ser de una forma u otra, pero estaremos usando un objeto principal que almacenará en caché y luego haremos que otros objetos dependan de eso. Ese es el enfoque que seguirá.
Relaciones en caché distribuida
Entonces, comencemos con esto. Entonces, antes que nada, hablaremos sobre las relaciones de uno a uno y de muchos a uno dentro del caché distribuido que es el escenario más común, ¿verdad? Por lo tanto, una opción es almacenar en caché los objetos relacionados con el objeto principal. Ahora que ha visto nuestros objetos de dominio, tenemos una lista de pedidos como parte de los clientes. Entonces, si completamos estos pedidos y el cliente tiene esos pedidos como parte de él, si almacena al cliente como un solo objeto en el caché que tiene todos los pedidos como parte, ¿verdad? Entonces, eso haría el trabajo.
Objeto relacionado con caché con objeto principal
Entonces, aquí hay un ejemplo de código para ello.
// cache order along with its OrderingCustomer and OrderedProduct
// but not the "Orders" collection in both of them
public void CacheOrder(Cache cache, Order order)
{
// We don't want to cache "Orders" from Customers and Product
order.OrderingCustomer.Orders = null;
order.OrderedProduct.Orders = null;
string orderKey = "Order:CustoimerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Tenemos un pedido de caché, configuramos el cliente que realiza el pedido dentro del pedido como "nulo". ¡Bien! Entonces, no tenemos pedidos que también tengan una referencia al cliente. es redundante Esta no es una muy buena práctica de programación, pero es solo para hacer cumplir. No queremos almacenar pedidos del ID del cliente y del producto. Entonces, solo queremos que se agregue un cliente en el caché y luego nos gustaría tener pedidos como parte de eso.
Entonces, echemos un vistazo a esto, ¿verdad? Entonces, establecemos esto en nulo y luego simplemente lo almacenamos o, si no lo establecemos en nulo, esto puede tener una referencia a eso. Del mismo modo, si tenemos un cliente, ¿no? por lo tanto, si no configuramos el pedido como nulo aunque este es un objeto separado, pero si simplemente almacenamos este cliente, permítame llevarlo a esto, ya que tiene una lista de pedidos, si simplemente almacenamos este cliente como un único objeto en el caché, tiene nuestra colección de pedidos como parte de ese objeto. Aunque lo estoy configurando como nulo para otro ejemplo, solo para mostrarle este caso particular, puede ordenar un objeto grande y tendría todos los objetos relacionados como parte de ese objeto.
Por lo tanto, debe comenzar desde su objeto de dominio, debe tener su relación capturada como parte del objeto de dominio y debe hacerlo independientemente. Y, después de eso, debe almacenar en caché, debe tener una lista completa de pedidos, una lista de objetos relacionados como parte de eso. Entonces, este es el enfoque más simple que puede obtener.
Hay algunos beneficios de tener un objeto que representa todo. Pero, también hay algunos inconvenientes. Sería un objeto más grande en tamaño. En algunos casos, solo necesita un cliente, pero terminaría recibiendo pedidos como parte de eso. Estarás lidiando con una carga útil más grande. Y, no tiene pedidos granulares como elementos separados en el caché, por lo que tendría que lidiar con la recopilación de pedidos todo el tiempo, aunque solo esté interesado en uno, ¿verdad? Entonces, ese es un enfoque. Ese es el punto de partida.
Caché de objetos relacionados por separado
En segundo lugar, almacena en caché el objeto ponderado como un elemento separado en el caché.
public void CacheOrder(Cache cache, Order order)
{
Customer cust = order.OrderingCustomer;
// Set orders to null so it doesn't get cached with Customer
cust.Orders = null;
string custKey = "Customer:CUstomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures order is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Un ejemplo de eso es la clase de orden donde tenemos orden de caché, ¿verdad? Entonces, este es el ejemplo donde tenemos un cliente. En primer lugar, ¿verdad? Y luego estamos almacenando el cliente como un solo objeto, puede ver que obtuvimos el pedido y luego del pedido extrajimos el cliente y luego configuramos la colección de pedidos dentro de ese objeto del cliente en nulo, ¿verdad? Entonces, esto es algo que debe hacer dentro del constructor, pero eso se está haciendo aquí solo para hacer cumplir que este objeto de cliente no tiene este pedido como parte de eso. Y luego almacena este cliente como un solo objeto. Lo que estamos haciendo aquí es que estamos creando una clave de cliente que es el cliente, la identificación del cliente, el parámetro de tiempo de ejecución y luego estamos almacenando nuestro cliente como un solo objeto en el caché.
Lo siguiente que haremos es crear una dependencia de caché. Por lo tanto, hablamos de dos pasos que queríamos hacer: un paso fue asignar su modelo de datos a su objeto de dominio, por lo que sus objetos de dominio deberían representar una tabla relacional en la base de datos y luego, una vez que planee almacenarlos en caché, tiene un objeto principal en este caso es cliente y luego tenemos pedidos que están relacionados con el cliente en la relación de uno a muchos. Crea una dependencia entre el cliente y la colección de pedidos con la ayuda de un objeto de dependencia de caché. Crea una dependencia de caché. Esta misma dependencia de caché toma dos parámetros; el primero es el archivo, ¿verdad? Entonces, puede depender del nombre del archivo y también puede depender de la clave, ¿verdad? Entonces, establecemos el primer parámetro en nulo. Por lo tanto, no queremos que dependa de ningún archivo.
Hay otra característica que dentro NCache donde puede hacer que los elementos dependan de un determinado sistema de archivos, algunos archivos en su sistema de archivos. Y, luego, si usa la dependencia basada en clave, necesita la clave del elemento principal del que dependerá el elemento secundario. Y luego construimos la clave de orden de la colección de la orden. Tenemos toda la colección de pedidos aquí que se pasa a este método y luego simplemente llamamos Cache.Add order.
Ahora el cliente y el pedido están relacionados entre sí. Tenemos una lista de pedidos de este cliente que se representan como un objeto separado en el caché, por lo que siempre que necesite todos los pedidos de este cliente en particular, solo necesita usar esta clave. Todo lo que necesita hacer es llamar, déjeme usar este ejemplo aquí mismo. ¡Lo siento! Puede llamar a Cache.Get y luego simplemente pasar la clave de pedido y esto le traerá este pedido particular que construimos dentro de este método, ¿verdad?
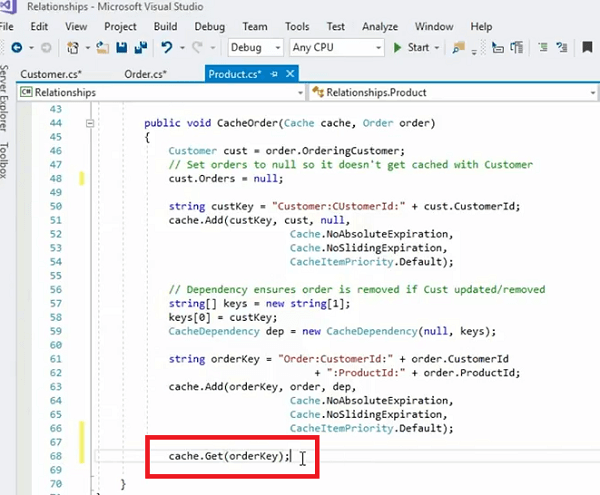
Entonces, eso es lo que necesita para obtener toda la colección de todos los pedidos de este cliente en particular a la vez. Pero, ¿y si el cliente pasa por un cambio? Si el cliente se actualiza, la colección de pedidos no necesita permanecer en el caché. Se puede eliminar o, en algunos casos, también se puede actualizar, ¿verdad?
Entonces, ese es nuestro enfoque número dos, que es más sofisticado en términos de almacenamiento, en términos de usabilidad y también mapea dos registros en nuestra relación de uno a muchos o de muchos a uno. También podría ser al revés, lo que cubriremos en un momento donde puede tener listas de pedidos y cada pedido puede asignarse a esos pedidos individuales puede asignarse a esos pedidos de identificación múltiple pueden asignarse a un cliente si el pedido es el objeto principal para ese código de aplicaciones en particular. Ahora bien, esto define una relación entre el cliente y los pedidos.
Algunos detalles más sobre la función de dependencia de caché.
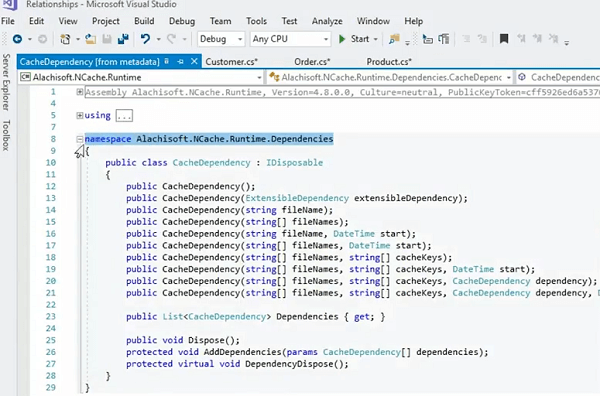
Si voy aquí, es en primer lugar, expuesto pero con la ayuda de Alachisoft.NCache.Runtime.Dependencies y esta es una de las sobrecargas que usa y luego simplemente usa este método en particular, aquí mismo. Y, el comportamiento de esto es tal que le permite rastrear simplemente la dependencia unidireccional entre los objetos y también podría conectarse en cascada como se discutió anteriormente en la presentación.
Relación de uno a muchos
A continuación, hablaremos de las relaciones de uno a muchos. Ya que hablamos de uno a uno o muchos a uno donde teníamos un pedido y luego teníamos un cliente, esto es similar a uno a muchos en la mayoría de los casos, pero como el punto de partida era el pedido y luego insertamos el cliente, almacenó al cliente y luego almacenamos la colección de pedidos y luego definimos una relación Muchos a uno entre la colección de pedidos y ese cliente.

Ahora, la relación de uno a muchos, será muy similar a lo que hemos discutido. Nuestra primera opción es que almacene en caché su colección de objetos como parte del objeto principal, por lo que el cliente es su objeto principal, el pedido debe ser parte de eso.
El segundo elemento es que sus objetos relacionados se almacenan en caché por separado, pero los elementos individuales en el caché, ¿verdad?
Uno a muchos: colección de objetos relacionados con caché por separadopublic void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Entonces, esta es una colección que está separada, tenemos pedidos, tenemos un objeto de cliente aquí uno a muchos y el cliente tiene pedidos, obtuvimos la colección de pedidos y luego estableceremos los pedidos del cliente en nulo para que el cliente sea un e objeto, un objeto principal, la recopilación de pedidos es un objeto separado y luego almacena el cliente, almacena la dependencia de caché de datos y almacena los pedidos. Por lo tanto, va a ser uno a muchos toda la colección.
Uno a muchos: guarde en caché cada objeto en la colección relacionada por separadoEl segundo enfoque es que esta colección también se puede dividir.
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
// Let's cache each order as seperate item but assign it
// a group so we can fetch all orders for a given customer
foreach (Order order in orders)
{
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
CacheItem cacheItem = new CacheItem(order);
cacheItem.Group = "Customer:CustomerId:" + cust.CustomerId;
cacheItem.Dependency = dep;
cache.Add(orderKey, cacheItem);
}
}La colección de pedidos puede estar separada, cada elemento dentro de esa colección podría ser un elemento separado en el caché. Entonces, en este caso usaríamos el mismo enfoque. Obtendremos los clientes, obtendremos los pedidos, almacenaremos al cliente, crearemos una dependencia de ese cliente usando la dependencia clave y luego iteraremos a través de todos los pedidos.
Permítanme revisar el método de cliente de caché aquí porque es más intuitivo aquí. Entonces, sacamos la colección de pedidos, establecemos los pedidos de los clientes en nulos para que los clientes solo se traten del cliente, almacenamos al cliente en el caché usando caché. Agregar clave, construimos una dependencia de caché alrededor de esa clave particular del cliente y entonces simplemente iteramos. Hay un bucle por aquí. De hecho, deberíamos iterar a través de él y esto es realmente mejor, iteramos a través de él y luego simplemente lo almacenamos de una vez como elementos individuales en el caché para que el pedido tenga su propia clave en cada pedido y sea un elemento separado en el caché. Y, otra cosa que hemos hecho es que en realidad los hemos agrupado a los que llamamos grupo de adición de elementos de caché y la identificación del cliente también es un grupo. Entonces, en realidad también estamos administrando una colección dentro del caché.
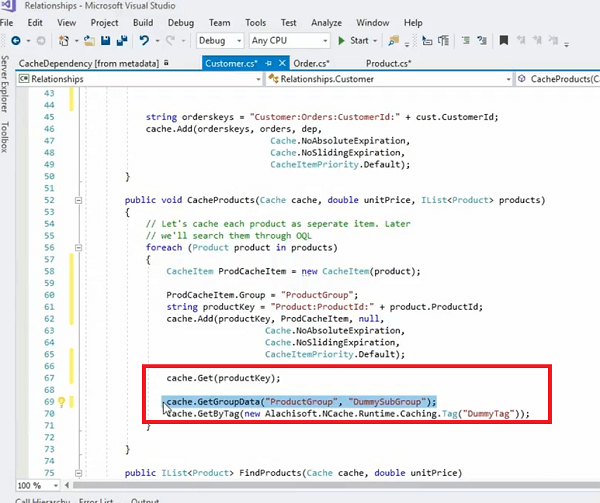
Déjame ver si tengo... ahí lo tienes, por ejemplo, tenemos esto aquí. De hecho, podríamos almacenar en caché estos productos, ese es otro ejemplo por cierto, donde hemos recorrido toda la colección de productos y luego los hemos almacenado individualmente y luego hemos puesto todo en un grupo, ¿verdad?
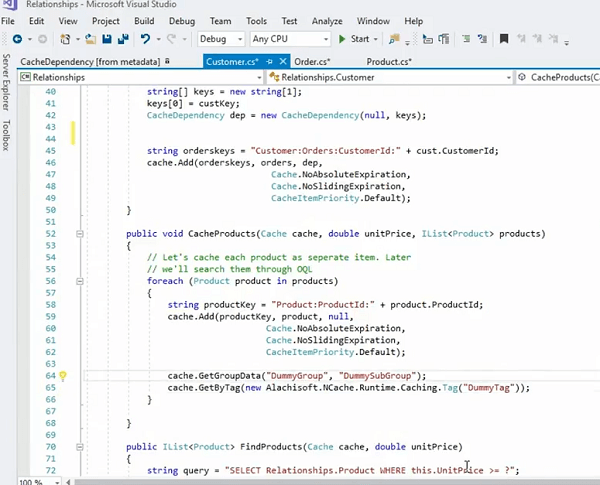
Por lo tanto, este producto que se almacena como elemento también se puede almacenar de esta manera, donde tenemos un ProdCacheItem. ¡Mi teclado está sonando, así que tengan paciencia conmigo! Usemos esto por ahora y luego lo haré de manera simple. De hecho, puedo agregar un grupo. Entonces, esto es lo que realmente me permitiría establecer un grupo para esto. Digamos ahora un grupo ficticio. Si almaceno este elemento de caché y en realidad podría tener un producto como elemento para esto, ¿verdad? Entonces, en lugar de almacenar el objeto sin procesar real, incluso puedo organizarlo en un grupo. Simplemente puedo usar el elemento de caché del producto. ¡Ahí tienes! ¿Derecha? Entonces, ahora en realidad está siendo o en lugar de usar el grupo ficticio, digamos el grupo de productos correcto y cuando necesito buscar esto, simplemente puedo usar el grupo de productos y me traería todos los elementos de esta colección a la vez. Aunque estos se almacenan individualmente, estos son cachés individuales. Obtener llamadas de productos individuales dentro de la colección de productos se clasifican individualmente, pero puedo organizarlos en un grupo en una colección y luego puedo recuperarlos. Pero lo bueno de esto es que todavía está usando una dependencia, ¿verdad? Entonces, está usando una dependencia de un cliente en esos artículos individuales.
Entonces, tomemos un ejemplo, tenemos un cliente que tiene cien pedidos. Entonces, en total tendríamos un artículo para el cliente en el caché, tendríamos cien pedidos almacenados por separado como cien artículos en el caché y hay una dependencia unidireccional entre ese cliente y cien pedidos. Si elimina a ese cliente del caché, cien pedidos se invalidarían a la vez. Y ahora tiene la ventaja de obtener pedidos individuales, si es necesario. Por lo tanto, puede interactuar con esos elementos individualmente. Un artículo a la vez. Necesita un pedido determinado, puede procesarlo y cuando necesita la colección completa de esos pedidos a la vez, simplemente puede llamar a Cache.GetGroupData y proporcionar el grupo de productos y luego el subgrupo podría ser cualquier cosa. Podría ser nulo incluso y luego también puede usar la etiqueta.
Por ejemplo; la otra forma de administrar esto es que usa el elemento del producto y crea una etiqueta para él, ¿verdad? Y, entonces tú... hay un... ¡sí! ahí está y puede proporcionar una etiqueta que puede ser algo así como la etiqueta del producto, ¿verdad? y luego puedes asociar esto como parte de aquello.
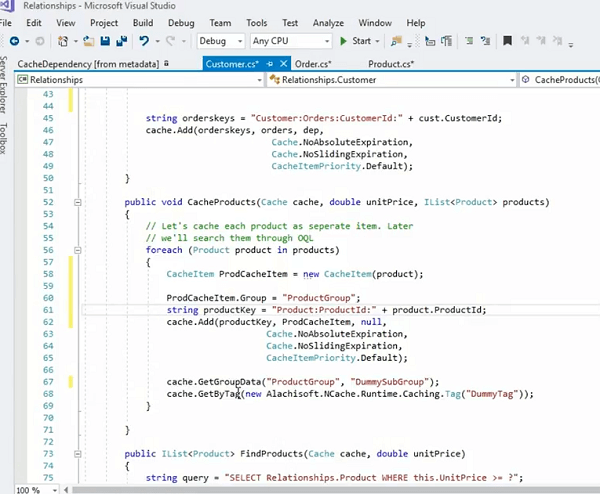
Entonces, esto realmente funcionaría en las mismas líneas y también puede llamar a métodos get by tag y eso se encargaría de todos los elementos a la vez. Te traería todos los artículos a la vez. Por lo tanto, esto le daría un mayor control sobre la disposición de los datos en el caché y luego mantendría intacta una relación de uno a muchos.
Entonces, esto se ocupa de un escenario muy particular en el que tenemos una relación de uno a muchos y tenemos un objeto agregado y luego tenemos esos elementos en el lado de muchos que la colección almacenó individualmente elementos de esa colección almacenados individualmente en el caché y luego todavía tiene una dependencia y luego todavía tiene un tipo de comportamiento de colección para eso con esos elementos relacionados. Entonces, esos elementos están relacionados entre sí, forman una colección y luego tienen nuestra relación con otro objeto en una formulación de uno a muchos. Entonces, este fragmento de código, una API intuitiva muy simple, se encarga de todos estos escenarios. Tiene una relación de uno a muchos capturada con la ayuda de la dependencia clave. Sin embargo, ha organizado esos elementos individualmente en el caché, pero aún los ha colocado en una colección lógica de grupos o etiquetas y luego, cuando necesita esos elementos individualmente, llama a cache start get, ¿verdad?
Entonces, una forma de obtener este elemento es llamando a Cache.Get, ¿verdad? y use la clave que es la clave del producto aquí, ¿verdad? Entonces, esto le traería este producto en particular que se está almacenando con esta clave en particular, ¿verdad? Y la otra opción es que necesita todos los elementos dentro de esa colección a la vez para poder usar Cache.GetGroupData. Por lo tanto, puede brindarle un comportamiento de recopilación y, al mismo tiempo, también puede brindarle una administración individual de esos elementos relacionados.
Entonces, eso debería ocuparse de las colecciones y los elementos dentro de la colección y de uno a muchos a la vez.
Relaciones de varios a varios
A continuación, tenemos una relación de muchos a muchos.

Las relaciones de muchos a muchos normalmente no existen en los objetos de dominio. Siempre se normalizará en dos relaciones de uno a muchos en la base de datos también. De hecho, teníamos una relación de muchos a muchos entre el cliente y los productos. Relaciones de muchos a muchos que normalizamos con la ayuda de un objeto intermediario en dos relaciones de uno a muchos. Entonces, tenemos uno a muchos aquí y muchos a uno aquí entre el pedido del cliente y el pedido del producto, respectivamente. Entonces, así es como lidiarías con muchos a muchos. Por lo tanto, terminaría usando relaciones uno a uno, muchos a uno o uno a muchos.
Entonces, esto debería encargarse de sus relaciones de muchos a muchos.
Manejo de colecciones en caché distribuida
Lo siguiente es que tenía una colección, ya hemos tocado esto con la ayuda de nuestro ejemplo de producto, pero aún lo revisaré para que lo guarde en caché en nuestra colección como un elemento.

Por ejemplo, almacena el producto. Vamos a repasarlo, ¿verdad?
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// cache the entire collection as one item
string productskey = "Product:UnitPrice:" + unitPrice;
cache.Add(productskey, products, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string productskey = "Product:UnitPrice:" + unitPrice;
IList<Product> products = (IList<Product>)cache.Get(productskey);
return products;
}Por lo tanto, tiene productos de caché, por lo que crea una clave de producto y luego tiene una lista de productos que se traen aquí y luego los almacena en caché y tiene un solo objeto. Y, como expliqué anteriormente, va a funcionar, simplemente hará el trabajo y funcionará principalmente cuando necesite todos los elementos de esa lista a la vez. No está interesado en elementos individuales de esa lista. Está interesado en toda la lista completa de la tienda como un elemento, pero hará que el objeto sea más pesado, no le brindará soporte para la codificación, la búsqueda y ese es nuestro próximo tema. Porque es una lista genérica, enumero, tiene un producto ahí pero para NCache esto es solo una lista, enumero. ¡Derecha! Por lo tanto, no puede identificar el objeto dentro de esa lista y luego los atributos y luego no tiene la capacidad de buscar en función de esos atributos.
Entonces, una forma más sofisticada de manejar esto es almacenar en caché cada elemento de la colección por separado. Eso lo cubrimos como parte de nuestro ejemplo anterior, pero repasémoslo una vez más. Por ejemplo; repasemos los productos de caché una vez más y esto simplemente los almacena como elementos individuales. ¡Déjame encontrar este ejemplo para ti! ¡DE ACUERDO! Ahí está.
Entonces, en primer lugar, almacenaremos los productos individualmente, ¿verdad? Tendremos una clave construida alrededor de eso para productos individuales. Lo bueno de esto es que todos los elementos individuales de la colección de productos se almacenan como elementos individuales en el caché para que pueda recuperarlos usando la clave que es la sobrecarga para eso, el método para ese Cache.Get. También puede obtenerlos como una colección. Eso es algo que discutimos en gran detalle. Otra opción es que también ejecute consultas y estas consultas de búsqueda similares a SQL se pueden aplicar directamente en los atributos de los objetos. Y solo puede hacer esto si los ha almacenado individualmente. Todos los elementos dentro de la colección se almacenan como elementos individuales. Los asigna a un objeto de dominio, producto en este caso, y los productos dentro de una colección de productos se almacenan individualmente como elementos separados en el caché.
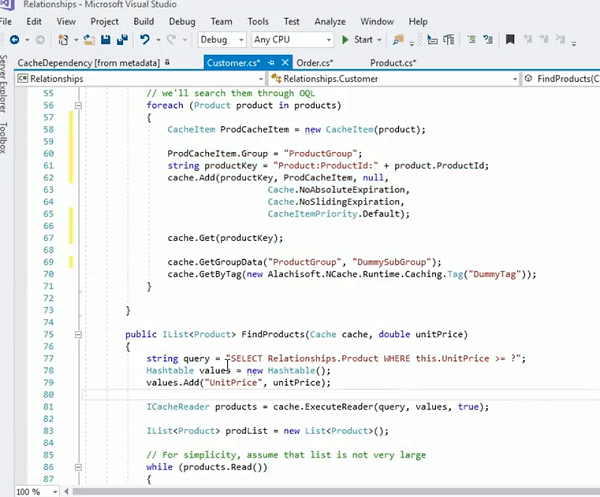
Ahora puede indexar el precio unitario del producto, el ID del producto y luego puede ejecutar una consulta como esta. Seleccione el producto, ese es el espacio de nombres del producto, donde esto establece el precio unitario igual a un parámetro de tiempo de ejecución. Y luego puede llamar a Cache.ExecuteReader y eso le traerá todos los productos que puede iterar y seguir buscando en su aplicación también. Del mismo modo, también puede decir dónde está This.Tag. Si ha asociado una etiqueta encima, también puede ejecutar consultas sobre eso. Ese es otro beneficio de las etiquetas junto con los beneficios de recuperación, los beneficios de rendimiento, también le brinda flexibilidad desde el punto de vista de la búsqueda. Y las etiquetas también te dan Cache.Get por una etiqueta. Le brinda todas las API, obtiene todas las etiquetas, obtiene cualquier etiqueta, por lo que también puede obtener objetos usando estas API de etiquetas. Pero, la característica que quería resaltar es que los organizas individualmente. Ese es el punto de partida. Las colecciones lógicas se crean mediante etiquetas o grupos. Por lo tanto, la recuperación es más fácil. Necesita elementos individuales a los que llama Cache.Get. Obtenga los artículos según la clave. Necesita colecciones, use el grupo o la etiqueta que aparece y, además, puede ejecutar consultas y puede asociar, en realidad puede buscar nuestros artículos según un criterio.
En este caso podría ser el precio unitario. Puede ser precio unitario mayor a 10 y menor a cien. Por lo tanto, los operadores lógicos son compatibles, también podría tener alguna agregación, contar, sumar, hay algún orden de clasificación por un grupo por operador similar en operación, por lo que es bastante emocionante en lo que respecta al soporte, es similar a SQL, es un subconjunto de Consultas SQL, pero su uso es muy flexible y le brinda mucha facilidad de uso en términos de los elementos que necesita. Ya no necesitas trabajar con llaves. Entonces, eso solo sucedería si simplemente usa que cada elemento de la colección se almacena por separado en el caché. Espero que eso ayude.
Empezar con NCache
Eso completa nuestro tema de hoy. Hacia el final, solo le mostraré cinco pasos simples para comenzar con NCache simplemente pasar NCache configuraciones y luego ser capaz de ejecutar estas API en una aplicación de la vida real.
¡Okey! Entonces, voy a comenzar rápidamente con esto. Tengo la herramienta de gestión abierta. Por cierto, lanzamos recientemente, en realidad acabamos de lanzar 4.9. Entonces, esa es nuestra versión más reciente, por lo que es posible que desee comenzar con eso. Entonces, todo lo que necesita hacer es crear un caché, por su nombre, elegir siguiente, elegir una topología de almacenamiento en caché, el caché de réplica de partición es el más adecuado, la opción asíncrona para la replicación y aquí especifica los servidores que alojarán este caché. Tengo demo uno y dos ya instalados con NCache.
Entonces, el primer paso es descargar e instalar NCache. El segundo paso es crear un caché con nombre. Entonces, lo revisaré, mantendré todo predeterminado porque ese no es el ámbito principal de discusión hoy. Voy a repasar los valores predeterminados y el tamaño del caché que se encuentra en cada servidor. Simplemente configure los ajustes básicos y elija finalizar.
El tercer paso es agregar un nodo de cliente. Solo usaré mi máquina. A ver si tengo acceso a esto, ¡sí! ¡Bien! Entonces, esa es mi máquina aquí. He agregado eso para que el paso tres esté completo. Todas las configuraciones en el servidor y en el cliente están completas. Ahora necesito iniciar y probar este clúster de caché como parte de mi paso 4 y luego revisaré esto y luego lo usaré en la aplicación real. Entonces, así de simple es comenzar con NCache.
Le mostraré algunos contadores rápidos para mostrarle las cosas en acción y luego también concluiremos rápidamente la presentación. Haré clic derecho y elegiré estadísticas que abrirán contadores de rendimiento y también puedo abrir herramientas de monitoreo que son NCache monitor, viene instalado con NCache.
Por lo tanto, es impulsado por el contador de rendimiento. Le proporciona contadores de rendimiento del lado del servidor y también contadores de rendimiento del lado del cliente. Y, en el lado de la aplicación del cliente, puedo ejecutar esta aplicación de herramienta de prueba de estrés que nuevamente viene instalada con NCache. Toma el nombre ya que hay configuraciones realizadas, por lo que se conectaría automáticamente al caché y comenzaría a simular la carga en mi clúster de caché. ¡Ahí tienes! Por lo tanto, tenemos una carga de solicitudes que llega aquí y también al otro servidor.
Del mismo modo, tenemos actividad que se muestra en este servidor, así como clientes conectados al servidor y al cliente del visor de informes. Y luego también puede tener sus propios paneles personalizados donde puede conectar cualquiera de estos contadores. Por ejemplo, los registros de API son un buen ejemplo. Registra todas las solicitudes que se están realizando en el caché en este momento en tiempo real, ¿verdad?
Entonces, ese es un ejemplo rápido del uso de estos contadores de la izquierda principal. Como dije, esto es solo para darle una idea de cómo se ve el almacenamiento en caché. Ahora puedo usar esto en una aplicación de la vida real. Puedo usar mi máquina aquí mismo y simplemente puedo usar la muestra de operación básica que viene instalada con NCache. Todo lo que necesita hacer es que haya diferentes carpetas de agujas dentro de las operaciones básicas de muestra .NET, en cuanto a usar NCache bibliotecas del lado del cliente que puede usar NCache Paquete SDK NuGet. Esa es la forma más fácil de obtener todos los recursos del lado del cliente.
La otra opción es que realmente uses Alachisoft.NCache.Tiempo de ejecución y Alachisoft.NCache.Bibliotecas web Usted mismo. Usted incluye esos. Estas son algo, estas son las bibliotecas con las que comienzan NCache en las carpetas de caché de Microsoft. Una vez que instale NCache sería parte de eso y luego te mostraré rápidamente lo que debes hacer. ¡Ahí tienes! Entonces, lo primero que necesita es agregar referencias a estas dos bibliotecas; runtime y web, incluya estos espacios de nombres que acabo de resaltar. Web.caching y luego, a partir de ese momento, esta muestra es lo suficientemente buena para inicializar de forma básica el caché conectándose a él, creando un objeto que lo lea, eliminándolo y actualizándolo, todo tipo de operaciones de creación, lectura, actualización y eliminación.
Entonces, así es como inicializas el caché. Esta es la llamada principal, ¿verdad? Necesita que el nombre de caché devuelva un identificador de caché y luego simplemente llame a caché o agregue almacenar todo en un par de valores clave Cache.Get elementos y luego actualice los elementos en caché o inserte y luego Cache.delete. Y ya le mostramos algunos ejemplos detallados del uso de dependencias basadas en claves usando etiquetas usando grupos usando SQL como búsqueda. Entonces, esto debería brindarle algunos detalles sobre la configuración del entorno y luego poder usarlo en una aplicación real.
Esto concluye nuestra presentación.