Replicación WAN para la implementación de múltiples centros de datos de NCache
Seminario web grabado
Por Ron Hussain y Zack Khan
Este seminario web le mostrará todo lo que necesita saber sobre el NCache Función de puente para la replicación WAN de la memoria caché en los centros de datos.
Esto es lo que cubre este seminario web:
- NCacheFunción de puente para la replicación WAN
- NCache Topología de puente (activo-activo, activo-pasivo, más de 3 centros de datos activo-activo)
- Características avanzadas del puente:
- Puente de alta disponibilidad y conmutación por error
- Resolución dinámica de conflictos
- Replicación asíncrona en paralelo y masiva
- Optimización de colas
- Función de sesiones multisitio en cola
- Opciones de supervisión de depuración/rendimiento del puente
El tema del seminario web de hoy será la replicación de WAN para una implementación de varios centros de datos mediante NCache. En el webinar de hoy, vamos a cubrir NCachefunción de puente. que también incluye NCachetopología de puente de 's, las características avanzadas de puente NCache tiene, poner en cola sesiones de sitios múltiples, así como opciones de supervisión de depuración y rendimiento de puente.
Hoy hemos alineado un tema muy importante. Específicamente, para aplicaciones que se implementan en múltiples centros de datos. Estos pueden deberse a varias razones. Por ejemplo, necesita un sitio DR, necesita una implementación de centro de datos múltiple activo-activo o podría ser una migración de datos de este a oeste lo que necesita.
Entonces, tenemos un Función de replicación de WAN disponible, con la ayuda de nuestra topología de puente y cubriré todos los detalles. Cómo usar el almacenamiento en caché de objetos mientras tiene activada la replicación WAN. Úselo para implementaciones de centro de datos activo-pasivo, activo-activo y activo-activo múltiple. Entonces, tenemos mucho que cubrir. Creo que todos pueden ver mi pantalla y escucharme bien. Si puedo obtener confirmaciones rápidas a través de la pestaña de preguntas y respuestas de GoTo Meeting, sería muy bueno y luego comenzaremos rápidamente con la presentación. Entonces, confirme, si todos pueden ver nuestra pantalla y aquí está bien sin ningún problema.
Introducción a los NCache
Entonces, comenzaré con la información muy básica sobre por qué necesita un sistema de almacenamiento en caché distribuido como NCache? Por lo tanto, por lo general, es el cuello de botella de rendimiento y escalabilidad de la aplicación lo que permite el problema, lo que limita el rendimiento de sus aplicaciones de una manera más rápida y luego más confiable.
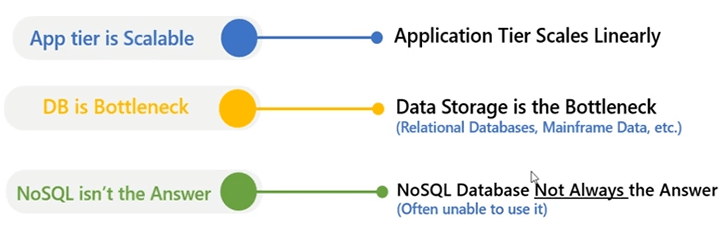
Su nivel de aplicación es muy escalable. Puede tener una aplicación web o una aplicación backend. Siempre puede crear una granja web o una granja de servidores de aplicaciones, donde su aplicación se puede implementar en varios servidores. Su carga se puede distribuir. Múltiples servidores ayudan a atender todas esas solicitudes de aplicaciones en paralelo, en combinación entre sí, pero todas estas aplicaciones necesitan comunicarse con una base de datos de back-end y eso suele ser una fuente de contención. La base de datos se convierte en un cuello de botella de rendimiento y escalabilidad para su aplicación porque no puede escalar los servidores de la base de datos y su recurso muy costoso también. Entonces, siempre puede escalar, pero hay un límite de cuánto puede escalar un servidor de base de datos. NoSQL generalmente no es la respuesta porque necesita rediseñar su aplicación. Debe dejar de usar nuestra base de datos relacional y comenzar a usar una NoSQL fuente de datos para usar eso y también tenemos un producto llamado NosDB el cual es un NoSQL database pero estamos proyectando una forma diferente de manejar esto y eso es a través del sistema de almacenamiento en caché distribuido.
Entonces, en primer lugar, la solución a este problema de escalabilidad es muy simple: comienza a usar un sistema de almacenamiento en caché distribuido en memoria. Es súper rápido porque está en la memoria, en comparación con el disco. Por lo tanto, el rendimiento de su aplicación mejorará de inmediato tan pronto como se conecte NCache.
En segundo lugar, es un equipo de servidores. Es un clúster de caché. No es solo una fuente única como la base de datos. Tiene varios servidores unidos en un clúster de caché. Entonces, es un almacenamiento lógico, ya sabes, que está agrupado por muchos servidores que puede elegir agregar. Eso lo hace muy escalable en comparación con sus bases de datos relacionales. Puede comenzar con 2 servidores y puede agregar más servidores en tiempo de ejecución. Por lo tanto, lo hace cada vez más escalable y, de hecho, linealmente escalable, donde puede agregar más servidores y, como resultado, sigue aumentando su capacidad de manejo de solicitudes de NCache. lo bueno de NCache es que lo usa además de una base de datos de back-end, una base de datos relacional. Hay muchas funciones que complementan el uso de los datos que provienen de una base de datos interna. Entonces, siempre puedes usar NCache junto con su base de datos relacional. No es un reemplazo de sus fuentes de datos relacionales. Algunos números de escalabilidad.
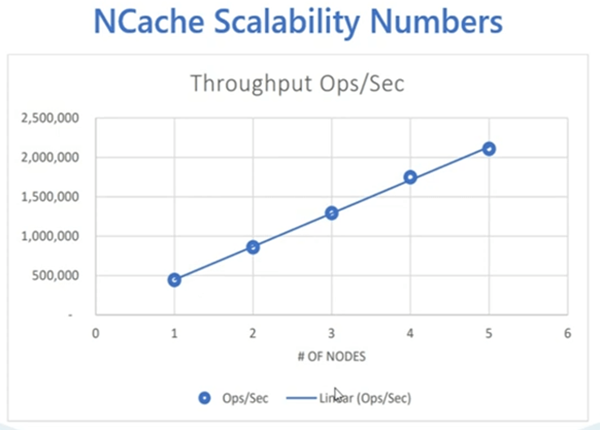
NCache es muy escalable, a medida que agrega más servidores NCache le permite manejar más y más solicitudes de NCache grupo. Recientemente realizamos estas pruebas en nuestro entorno de control de calidad. Usamos nuestro laboratorio de AWS, donde seguimos aumentando la carga y también agregando más servidores y hasta 5 NCache servidores, que es una configuración muy regular para nuestro caché distribuido. Pudimos lograr 2 millones de solicitudes por segundo y esa fue una tendencia ascendente en la que, cada vez que agregamos más servidores, agregamos más capacidad al clúster de caché. Con un tamaño de objeto promedio de 1 Kilobyte, este es el tipo de rendimiento que también puede esperar de NCache y con un mejor hardware, incluso puede estirar estos números y obtener un mejor rendimiento de rendimiento de NCache. Por cierto, estos puntos de referencia, hay un whitepaper y video demostración publicada en nuestro sitio web también. Entonces, también puedes echarle un vistazo a eso.
Algunos detalles de implementación. ¿Cómo sería una implementación típica de NCache se va a parecer.
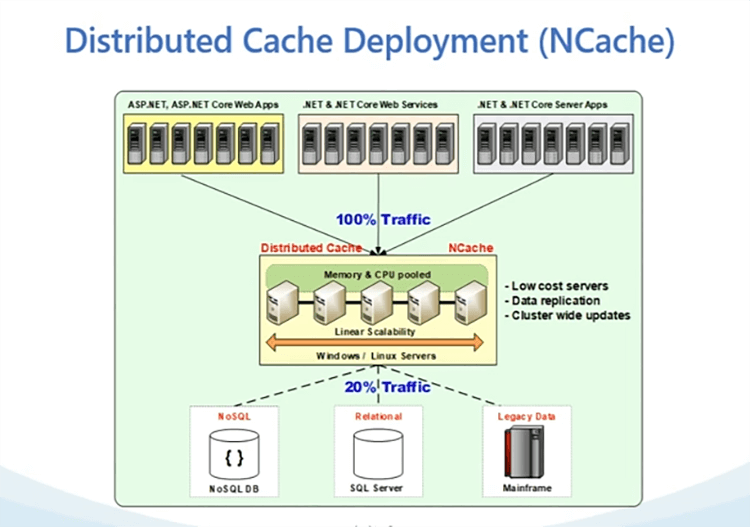
Aquí hay una implementación en un solo sitio de NCache. Como puede ver, tenemos un sitio único y, en su caso, lo que hablamos sobre el aspecto de replicación de WAN, obviamente tendríamos más de una implementación, tendríamos un centro de datos separado, donde también tendríamos NCache y aplicaciones implementadas.
Entonces, con nuestra implementación de caché distribuida, como se muestra en el diagrama, hablemos de cómo se ve una implementación típica. Entonces, tenemos un equipo de servidores nuevamente. Tenemos de 4 a 5 servidores que se muestran en el diagrama, ahí es donde se aloja su clúster de caché y, como puede ver, se encuentra entre su aplicación y la base de datos. La idea aquí es que use estas fuentes en combinación entre sí, para el almacenamiento en caché de objetos, pero para el almacenamiento en caché de sesiones, el caché se convierte en su principal fuente de datos. Por lo tanto, todas sus sesiones se pueden almacenar en NCache y no tienes que ir a ningún otro lado. Se encuentra disponible un modelo de implementación muy flexible. NCache se puede alojar en las instalaciones. Pueden ser cajas físicas o virtuales. También podría estar en la nube. Puede ser una nube pública o privada. También podría estar en Azure AWS, porque tenemos imágenes de mercado disponibles para ambos proveedores de la nube. Pero, en general, cualquier servidor que tenga Windows o Linux y solo sea un requisito previo para NCache es .NET o .NET Core Estructura. Entonces, estos son requisitos previos. Es solo .NET y .NET Core que NCache necesidades como requisito previo. Si eso está disponible, NCache es muy flexible para implementarse en entornos Windows y Linux y, como dije, también podría ser cualquier entorno, podría ser, puede usar Docker y también puede alojar NCache en el clúster de Kubernetes y eso abre muchas otras plataformas. Puede usarlo en OpenShift. Puede usarlo en el servicio Azure Kubernetes. Ya sabes, el servicio Elastic Kubernetes también. Entonces, todas esas plataformas están equipadas y NCache está equipado para ser desplegado en todas esas plataformas.
Hay dos opciones de implementación. Una es que vaya con el nivel de caché dedicado, como se muestra en el diagrama y el segundo es, y en dedicado, sus aplicaciones se ejecutan en cajas separadas y NCache se ejecuta en un nivel dedicado separado. También tenemos un enfoque de nivel compartido disponible, donde también puede ejecutar NCache junto con sus cajas de solicitud. Por lo tanto, dondequiera que se alojen sus aplicaciones NCache se puede alojar encima de él. Entonces, creo que esto es bastante sencillo. En una implementación de varios centros de datos, tendría más de un centro de datos y tendría la misma implementación para NCache en el otro centro de datos también, que cubriremos en las próximas diapositivas y, por cierto, si hay alguna pregunta, siempre puede publicar esa pregunta en nuestra pestaña de preguntas y respuestas y Zack y yo mantendremos, ya saben, mantendremos un Esté atento a todas las preguntas que se publicarán y estaremos encantados de responderlas por usted. Hablando de preguntas, ya que lo mencionó hace un momento, tengo una que me gustaría mencionar, bueno, fue muy simple que mencionara Kubernetes ahora. Entonces, la pregunta era, vamos a hablar sobre puentes y esto en general, ¿hay algún requisito de sistema operativo para todo esto? ¿Eres capaz de ejecutar esto en Linux? Absolutamente. NCache es muy flexible Como puede ver, incluso en nuestro diagrama de implementación. Puedes ver NCache es compatible con servidores Windows y Linux. Entonces, en los servidores Linux, solo necesita .NET Core liberarse de NCache y tenemos un servidor así como un cliente para estos. Entonces, si quieres correr NCache servidores en .NET en Linux usando .NET Core eso es posible y sus aplicaciones siempre pueden usar nuestro .NET Core lanzamiento e implementación en Windows y Linux, entonces, sí. Impresionante. Te dejaré repasar el resto y luego haré las preguntas.
Implementación de múltiples centros de datos de NCache
Entonces, a continuación hablaremos sobre la implementación de Multi-Datacenter de NCache. Ahora, si su aplicación se implementa en varios centros de datos, o podría ser que tenga un sitio activo y luego tengamos un sitio pasivo para escenarios de recuperación ante desastres. Por ejemplo, el sitio activo deja de funcionar y su aplicación requiere que esté siempre en funcionamiento, si es una aplicación de misión crítica, es importante para su negocio. Tener un tiempo de inactividad a nivel de sitio es algo que afectaría su negocio.
NCache El clúster está diseñado de tal manera que ya está equipado con funciones de alta disponibilidad y confiabilidad de datos. Entonces, en un solo nivel de sitio, si uno o dos servidores se caen, por ejemplo, si pierde un servidor, NCache está equipado para manejar esa interrupción sin ningún problema. Pero hoy estamos hablando de si nosotros, ¿qué sucede si tenemos una interrupción en el nivel del sitio? O bien, debemos desactivar el sitio para realizar tareas de mantenimiento, ya que todo el sitio está inactivo. Entonces, todos los servidores están caídos. NCache incluso está equipado para manejar ese escenario y eso es lo que planeamos cubrir hoy. Entonces, hablemos de por qué necesitamos la replicación WAN.

Por lo general, cuando sus aplicaciones necesitan alta disponibilidad, un sitio único puede convertirse en un único punto de falla. Si su sitio deja de funcionar, perderá todos los datos y podría generar tiempo de inactividad para los usuarios de su aplicación y eso podría afectar su negocio, ya lo hemos establecido. Las aplicaciones multirregionales son lentas si tienen que comunicarse entre sí a través de la WAN. Por ejemplo, tiene un centro de datos implementado, su aplicación implementada en un centro de datos que se encuentra en la región de EE. UU. y luego tiene otra aplicación que se implementa en Europa o en cualquier otra, por ejemplo, en la región asiática. Entonces, en ese caso, si las bases de datos de su aplicación están ubicadas en uno de los centros de datos, el sitio remoto debe cruzar la red. Por lo tanto, la velocidad de su red afectaría la latencia de ese otro sitio. Ya sabe, para manejar ese escenario, generalmente también replica sus fuentes de datos a través de WAN y eso es lo que recomendamos para NCache también, eso NCache debe ser replicado. Pero, teniendo en cuenta que usted tiene una fuente de datos común, el sitio remoto tiene que atravesar la WAN y eso podría tener un impacto potencial en el rendimiento porque los datos no son locales para ese sitio, la distancia entre los centros de datos también afectaría su rendimiento. . Solo hay una cantidad limitada de datos que puede transmitir entre sitios. Entonces, eso puede limitar su capacidad de manejo de solicitudes.
Entonces, estos son dos problemas si tiene aplicaciones multirregionales y si ambas aplicaciones están activas. La replicación de datos a nivel de solicitud también es costosa. Por ejemplo, no replica la base de datos completa y tiene una fuente de datos ubicada en un centro de datos. Ahora, una solicitud que va de nuestra ubicación remota, una ubicación geográfica que es remota, a su base de datos. Una replicación de nivel de solicitud para cada dato, ya sabes, unidad de solicitud que llega a nuestra fuente de datos, eso será extremadamente costoso y consumiría una gran cantidad de ancho de banda y recursos. Por lo tanto, necesita un mecanismo activo, en el que tenga datos disponibles localmente y es por eso que necesita la replicación WAN de la memoria caché. Entonces, sus datos de un centro de datos se replican a través de la red al otro sitio.
Algunos casos de uso. ¿Por qué, ya sabes, dónde exactamente puedes usar la replicación WAN?
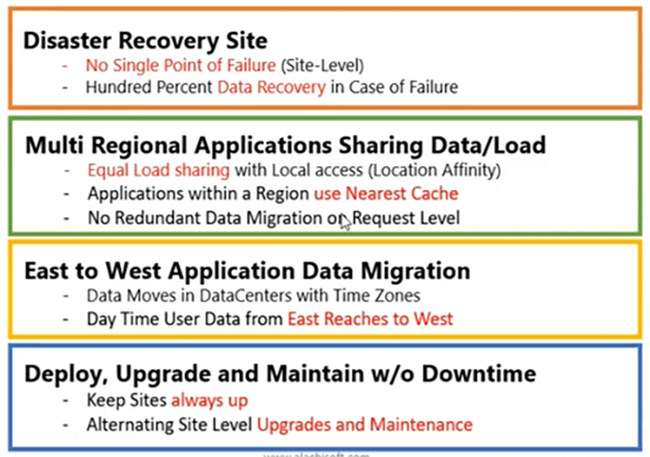
El más común, con el que nos encontramos, es el sitio de recuperación ante desastres. Tiene un sitio activo, que está sirviendo a su principal caso de uso empresarial. Ahí es donde se genera y se maneja su tráfico. ¿Qué pasa si todo el sitio se cae? Necesitas una opción alternativa, ¿verdad? Entonces, ese sitio DR ya debería tener datos disponibles. De lo contrario, no se manejarían los requisitos de datos si tiene que volver al sitio que ya está caído, ¿verdad? Por lo tanto, necesita que los datos estén disponibles en el sitio de DR, para que ya esté en funcionamiento. Solo necesita cambiar su tráfico a ese sitio DR. No debe hacer nada más, simplemente enrutar su tráfico al sitio de recuperación ante desastres y debería funcionar con el mismo valor de rendimiento, las mismas matrices de rendimiento que tenía con el sitio activo. Por lo tanto, es posible recuperar el 100% de los datos en caso de falla, con la ayuda de NCache Replicación WAN.
Las aplicaciones multirregionales pueden compartir datos y cargar. Ahora, con los sitios Activo-Activo, si tiene una región en EE. UU. y otra en otra parte del mundo, por ejemplo, Europa o Asia. Si desea eso, ya sabe, la solicitud de, ya sabe, un centro de datos debe manejarse en función de la afinidad de ubicación, puede lograrlo. Ahora, el usuario de Asia podría conectarse a un sitio dentro de esa región, más cercano a esa región y también puede usar el caché allí y ese caché está sincronizado con el otro caché que está en la región de EE. UU. Entonces, cualquier usuario que rebota. Por ejemplo, necesita administrar el desbordamiento o necesita distribuir la capacidad. Algunos de los usuarios necesitan, ahora necesitan rebotar a la región de EE. UU. porque la región de Asia está completamente obstruida, por lo que siempre puede hacerlo. Por lo tanto, a nivel de sitio, puede equilibrar la carga de su solicitud, en función de la capacidad que maneja ese sitio en ese momento y en ese momento. Dado que los datos de caché ya están replicados en los centros de datos y hablaremos sobre cómo lograrlo, de modo que sus aplicaciones multirregionales puedan compartir de manera eficiente los datos de sus aplicaciones y también compartir la carga de solicitudes y también pueden compartir la carga equitativamente. . No se realiza ninguna migración de datos redundantes. Solo se basa en la solicitud que rebota de un centro de datos a otro y siempre puede obtener esos datos del caché que ya está conectado allí.
La migración de datos de aplicaciones de este a oeste es otro caso de uso. Por ejemplo, los mercados asiáticos comienzan antes que, ya sabes, los mercados occidentales, ¿verdad? Por lo tanto, su tendencia de datos, por lo general, sigue de este a oeste. Por lo tanto, su sitio del este puede tener nuestro caché configurado y con la zona horaria, los datos se mueven entre el centro de datos y la región occidental y llegan al oeste. Por lo tanto, si tiene datos replicados en los centros de datos, los datos de caché, la región occidental podría aprovechar todos los datos que están disponibles en la región oriental. Por lo tanto, puede tener disponible la migración de datos de este a oeste y el caso de uso de mantenimiento es el tercero.
Cuarto, donde podemos implementar actualizaciones y mantener sin ningún tiempo de inactividad. Eso se está convirtiendo en un caso de uso muy apremiante, con NCache también. Que, si planea actualizar, puede tener actualizaciones entre versiones anteriores y nuevas, utilizando nuestra topología de puente. Donde los datos más antiguos, los datos de la versión se pueden transmitir a la versión más nueva con la función de actualizaciones en vivo. Podría ser entre sitios, por ejemplo, puede usar un sitio y replicar datos activamente en el sitio pasivo y puede actualizar, implementar un nuevo código, mantener el rendimiento, el mantenimiento en el sitio activo y tiene todos los datos disponibles y su el tráfico se puede enrutar al sitio pasivo para el caso. Por lo tanto, ambos sitios siempre pueden estar en funcionamiento sin tiempo de inactividad ni pérdida de datos de la aplicación.
NCache Puente para replicación WAN
Entonces, hablemos de cómo manejar eso. El nombre de la función es NCache puente. Es parte del mismo producto. No necesita ninguna instalación separada para ello. NCache Enterprise está equipado con NCache topología de puente y hablemos de ello.
Entonces, nuestro caché, NCache La función de puente le permite replicar la memoria caché en los centros de datos.

Se basa en el modelo de replicación asíncrona. No incurre en ninguna degradación del rendimiento en el lado de la aplicación. Sus aplicaciones de caché están conectadas en forma activa al caché en un centro de datos. Por ejemplo, tiene clientes aquí y luego puede crear un puente que también es una cola activa-pasiva y que transmitiría datos a los otros sitios de forma asíncrona.
Por lo tanto, se basa en la replicación asíncrona, por lo que no hay degradación del rendimiento en la replicación de datos. Es muy confiable. Es tolerante a fallas. Detecta automáticamente los fallos de conexión. Se vuelve a conectar automáticamente. Hay opciones de reintento automático disponibles, por lo que también se realiza una copia de seguridad del puente en la cola activa-pasiva.
Entonces, hay un servidor Active Bridge y también hay un servidor Passive Bridge. Si el servidor Active Bridge deja de funcionar, el Pasivo se recuperará e iniciará todas las operaciones de replicación sin demoras. Es muy fácil de configurar, no necesita ningún cambio de código, no necesita instalaciones adicionales. Forma parte del mismo producto, el Enterprise y da su propio soporte de monitorización y gestión, que está integrado en el mismo NCache Enterprise producto y es compatible con múltiples topologías que voy a cubrir a continuación.
Entonces, tenemos tres topologías principales.

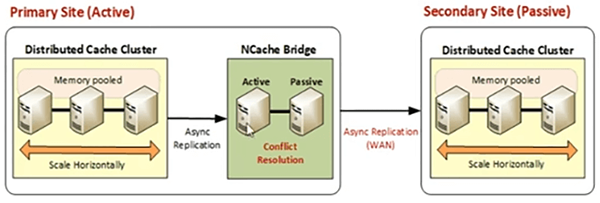
Disponemos de Activo-Pasivo. Donde tenemos un sitio activo y luego tenemos un sitio pasivo. El sitio pasivo también acepta solicitudes de clientes, pero el flujo de datos es de activo a pasivo. Entonces, si tiene requisitos de sitio DR, puede usar un sitio para estar activo, conectado al puente y luego puede tener otro sitio pasivo. El sitio activo transmite datos al sitio pasivo. Entonces, es una transmisión unidireccional. El término pasivo esencialmente significa que el sitio pasivo no está transmitiendo datos de vuelta al activo. Todavía se está ejecutando y tiene aplicaciones cliente que lo aprovechan. Entonces, no es algo que se detenga de ninguna manera. La migración de este a oeste se puede lograr con pasivo activo. Su caso de uso de mantenimiento y actualización se puede manejar con la ayuda de activo-pasivo.
La topología activo-activo es cuando tiene una aplicación implementada en dos ubicaciones geográficas diferentes y desea que los datos del sitio 1 estén disponibles en el sitio 2 y que los datos del sitio 2 estén disponibles en el sitio 1. Si su aplicación necesita requisitos de intercambio de datos entre sitios geográficos, puede apuntar a activos-activos donde tenga usuarios activos en ambos centros de datos. Los clientes están conectados a ambos centros de datos y hay una replicación bidireccional entre dos sitios diferentes y luego tenemos una topología 3, 2+ o 3+ activo-activo, donde tenemos un servidor de oferta principal, pero está transmitiendo datos a todos sitios y esos sitios también están transmitiendo datos a todos los demás sitios. Por lo tanto, se debe aplicar una actualización en todos los centros de datos y viceversa.
Entonces, aquí está nuestro activo-pasivo.
En esto tenemos puente, que es una cola, que también es activo-pasivo. Tenemos un clúster de caché en el sitio 1, que es solo, ya sabes, el manejo de las solicitudes de los clientes. Tenemos 3 servidores aquí. Está conectado al puente. Bridge también reside en uno de los sitios. O, en algunos casos, puede tener un puente activo en el sitio 1 y un servidor de puente pasivo en el sitio 2. Eso también es posible, pero generalmente recomendamos que mueva el puente a uno de los sitios en su arquitectura de implementación. El segundo sitio es un sitio pasivo y nuevamente por pasivo todavía se está ejecutando. Es solo que el sitio pasivo no replica los datos en el activo. Es una transmisión de datos unidireccional y eso es todo lo que significa cuando decimos que este es un sitio pasivo. Esencialmente, puede ejecutar aplicaciones cliente aquí y es completamente funcional incluso en este estado. Entonces, es una replicación de datos, activo pasivo, entonces, si este servidor se cae, el pasivo se activa y es automático. No se necesitan cambios de código. Le mostraré cómo configurar el puente, una vez que avancemos a nuestra parte práctica. Entonces, es bastante simple.
Llegó una pregunta y tiene que ver con este activo-pasivo, es, principalmente si tiene un sitio activo y otro pasivo, ¿cómo activa el sitio pasivo? ¿Es un proceso manual? ¿Está detenido el sitio? ¿Cómo haces eso? Bien, entonces, si entendí bien esta pregunta, ¿el sitio pasivo en términos de cómo lo activamos? Ya está activado. Se está ejecutando y si deshabilitamos este sitio o queremos mover el tráfico aquí, es la carga de tráfico de su aplicación lo que debe mover a este sitio. Entonces, tiene servidores de aplicaciones aquí, tiene servidores de aplicaciones aquí, cualquier información que tenga se transmitirá aquí y los usuarios de este sitio pueden tener los datos disponibles desde el caché mismo. Ahora, siempre puede enrutar su tráfico al sitio pasivo y puede obtener todos los datos disponibles. Por lo tanto, no se necesitan pasos para activarlo. Sin embargo, si desea que este sitio también comience a transmitir datos al sitio activo, puede activarlo utilizando nuestras herramientas GUI. Entonces, en términos de replicación, si desea que esto replique los datos nuevamente al activo, siempre puede activarlo y este es un proceso de tiempo de ejecución. Entonces, solo con una línea, con un clic en la herramienta GUI puede lograrlo o puede usar nuestra herramienta PowerShell para que eso suceda. Pero si su pregunta es sobre cómo activar el nodo pasivo. Si hay un paso manual para que las aplicaciones cliente se conecten y puedan usar los datos, ya se está ejecutando. Sus aplicaciones comienzan a usarlo si comienza a enrutar el tráfico a este clúster de caché. Entonces, dentro de su balanceador de carga. Apaga este sitio y enruta todo su tráfico al sitio disponible, que ya está en funcionamiento y puede obtener/aprovechar todos los datos que se están replicando.
Entonces, activo-activo, nuevamente se basa en el mismo principio. Donde tenemos puentes corriendo en uno de los sitios.
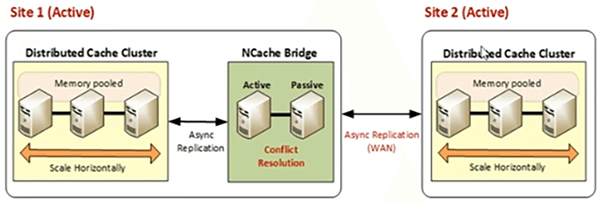
Tenemos el caché 1, el caché 2. Ambos sitios están activos e incluso la topología pasiva se puede convertir en activa, haciendo clic derecho y haciéndola activa y, en este caso, los datos del caché del sitio 1 se transmiten al sitio 2, de forma asíncrona desde el caché al puente. y del puente al caché y luego, de manera similar, el sitio 2 también está transfiriendo datos al sitio 1.
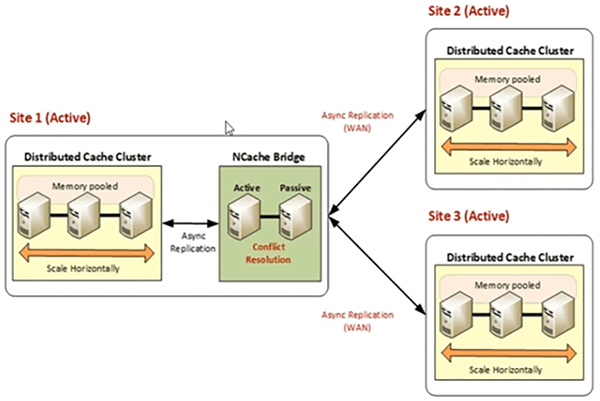
3+ centros de datos activos-activos, donde tenemos tres o más activo-activo, donde tenemos uno de los sitios como servidor puente. También podemos tener un sitio alternativo para el puente. También podemos tener un sitio puente de respaldo. Pero, en general, tendríamos uno de los sitios que alojaría, que sería el puente de alojamiento y luego ese sitio está transmitiendo datos a otros sitios y, de manera similar, el sitio 2 está transfiriendo datos al sitio 1 a través del puente y al sitio 3. Y para activos -activo, tenemos una resolución de conflictos que se basa en el tiempo, por lo que gana la última actualización. Todas las estructuras de datos que utilizamos están libres de conflictos. Estos son tipos de datos libres de conflictos. No hay condiciones de carrera ni ningún problema de consistencia de datos conocido porque la última actualización se aplicará en el clúster de caché en todos los ámbitos. Asi que, NCache gestiona si entran dos actualizaciones para la misma clave, NCache evaluaría eso y también le permitiría construir su propia resolución de conflictos, si eso es un requisito. Por lo tanto, se administra como parte de NCache topologías.
Entonces, aquí hay un vistazo rápido a nuestras configuraciones de puente.

Tenemos NCache configuración de puente NCache Bridge es el nombre y luego tenemos LondonCache entorno 1, por lo que también puede tener varios cachés con el mismo nombre. NewYorkCache y estos están conectados.
Demostración práctica NCache
Entonces, déjame mostrarte todo esto en acción, ¿cómo configurar un puente? Cómo comenzar con él y luego le mostraremos las aplicaciones de almacenamiento en caché de objetos y de sesión. Antes de entrar en eso, Ron, tuve una pregunta justo en la diapositiva anterior con el código y la pregunta es ¿cuáles son los cambios de código que están involucrados para configurar el puente? ¿Necesitan escribir algún código para que los datos se repliquen a través del puente? De nada. No necesitamos ningún código. Es solo una configuración. Entonces, tiene el caché 1 en el centro de datos 1 y el caché 2 en el centro de datos 2. Simplemente configure el puente y cualquier dato que sus aplicaciones ya agreguen en NCache, se replicará a través del puente automáticamente. Entonces, es responsabilidad del puente hacerse cargo de toda la replicación. No necesita escribir ningún código explícitamente para que los datos se repliquen en los centros de datos y cuando decimos los tipos de datos, la resolución de conflictos, eso es algo que también se implementa de forma predeterminada, que se basa en el tiempo, pero si desea implementar su propio resolución de conflictos, si los requisitos de su negocio son que evalúe objetos, en caso de que ingresen múltiples actualizaciones, en ese caso puede implementar esa interfaz. Pero en lo que respecta a la replicación de datos, es responsabilidad del puente. No tienes que escribir ningún código para eso.
Crear cachés
Entonces, permítanme comenzar rápidamente, voy a crear un caché.
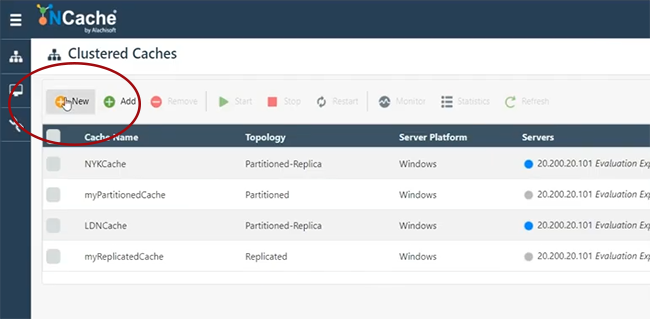
Digamos, voy a nombrar site1cache o dejarme usar esto aquí mismo SiteOneCache. Esto es solo para darle una idea de cómo comenzar rápidamente y poder crear el puente. Mantendré todo predeterminado, porque NCache la arquitectura cubre todos estos detalles.
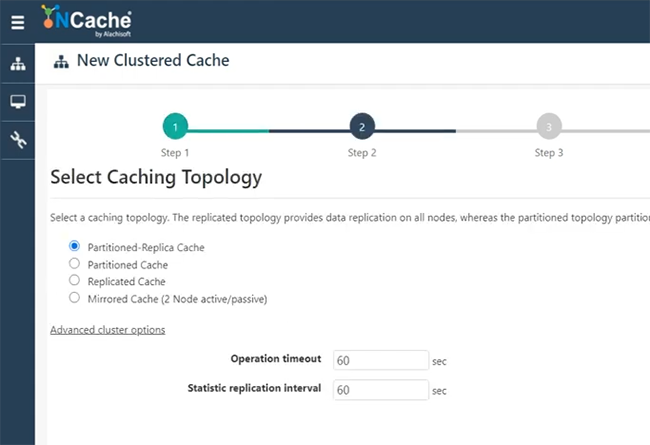
Por lo tanto, voy a ir rápidamente a través de ellos. Partición de caché de réplica, cualquier clúster. Replicación asíncrona de topología. Voy a elegir 101 y veamos si puedo elegir 102, si está disponible. Estos son mis dos servidores, para alojar el puente. Mantendré todo esto por defecto. Inicie esto y el inicio automático también. Finalizar. Entonces, mi caché uno está en 101 y 102, que se va a crear. Veamos cómo va y luego continuaré y crearé otro caché que estaría en un conjunto separado de servidores y luego hospedaré el puente y les mostraré cómo funcionaría todo esto. Derecha. Entonces, tenemos SiteOneCache completamente configurado. Como puede ver, también comenzó.
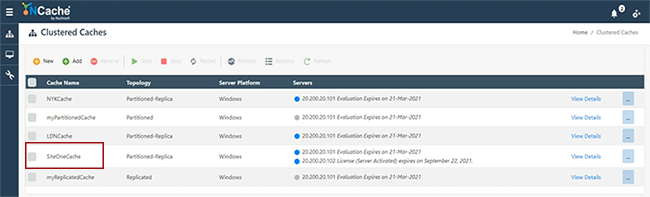
Ahora, voy a seguir adelante y crear, de hecho, voy a crear otro caché, que es SiteTwoCache. Creo que puedo usar eso. Estuve jugando con eso antes. Mantenga todo simple y esta vez voy a dar un conjunto separado de servidores, para que representemos esto como un sitio completamente separado. Mantenga todo predeterminado y, por cierto, nuestro puente le permite tener una administración remota de todos los sitios, desde las herramientas de administración y monetarias que le permiten administrar realmente todos los sitios junto con el puente, desde una ubicación central. Entonces, si tiene acceso a la red. Si hay un enlace WAN disponible entre su SiteOne y SiteTwo, básicamente puede administrarlo todo. Entonces, tenemos SiteTwoCache justo aquí. SiteOneCache aquí mismo. 101 102 que representa SiteOneCache. 107 y 108 que representan SiteTwoCache. Ahora, y estos se inician también.
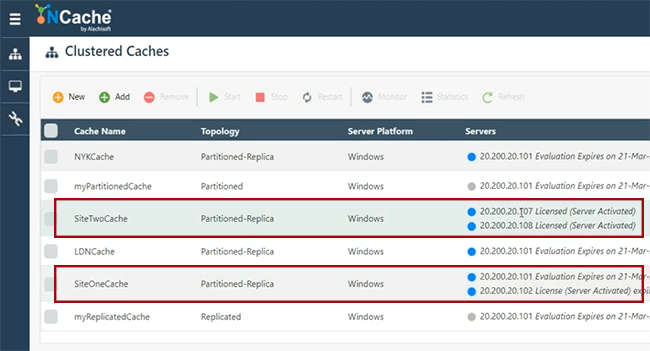
Si hago clic en estadísticas, puede ver que todavía no se han agregado objetos aquí. Los datos no se agregan en SiteOneCache o SiteTwoCache, así que estamos bien. Simplemente ejecutaría esto. Creo que tengo un problema de permisos para revisar este contador. Creo que puedo, está bien. Entonces, puede ver que todavía no hay artículos disponibles. Ahora voy a vincular estos dos cachés con la ayuda de un puente, que configuraré a continuación.
crear un puente
Entonces, aquí vamos a crear un puente.
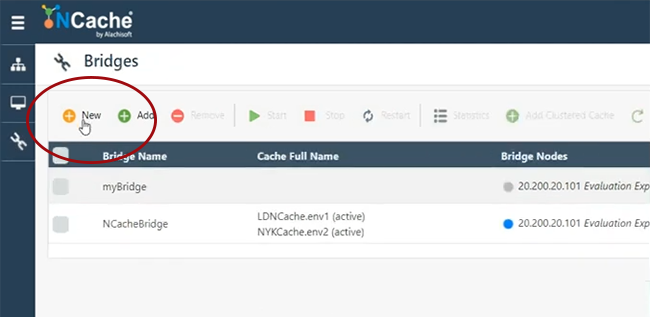
Entonces, solo diré NCachepuente de demostración.
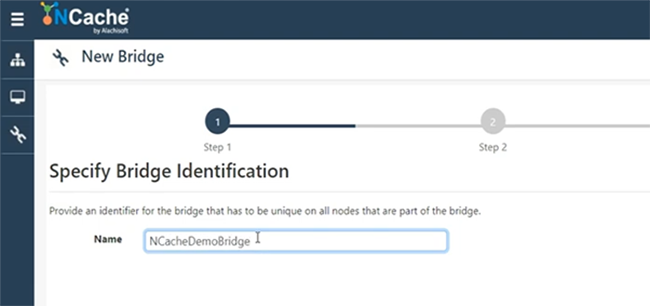
Puede crear cualquier nombre y el puente puede estar en cualquier servidor. Por ejemplo, en 107. Déjame dar mi caja, ahí tienes. Entonces, permítanme crear un puente en 101 y 102. Tengo problemas de permisos. Entonces, déjame ver si puedo agregar 107, de lo contrario, solo usaré un servidor para el puente. Esto requiere que se abran ciertos puertos. Entonces, creo que mi máquina tiene todos esos puertos abiertos. Entonces, déjame usar 101 por ahora. Un servidor es lo suficientemente bueno. El servidor de respaldo no está allí, pero siempre podemos agregarlo y mantendré todo predeterminado y elegiré Finalizar. Iniciar automáticamente el puente, cuando se inicia, esa también es una posibilidad y luego, si hago clic en Ver detalles en el puente, por ejemplo, si hago clic aquí, eso abriría todas las configuraciones del puente que tenemos. Aquí puede especificar, puede agregar más nodos al puente, si es necesario, y también puede agregar más cachés, que actuarían como activos o pasivos. Entonces, si hago clic en Agregar, por alguna razón no me permite agregar. Por favor, tenga paciencia conmigo. Puedo introducir una pregunta mientras esperamos. Claro, adelante, por favor. Claro, sí, acaba de aparecer uno. Es bastante sencillo, tiene que ver con ¿cómo se asegura la transmisión segura de datos? Tenemos funciones de encriptación disponibles. Por lo tanto, si tiene activado el cifrado de nivel de caché o la seguridad, el puente obedecerá eso. Por lo tanto, cualquier transmisión que se transmita entre CacheOne y CacheTwo se cifrará, si tiene el cifrado y la seguridad desactivados, activados. Por lo tanto, también tenemos proveedores de encriptación compatibles con AES, DES y FIPS. También tenemos TLS 1.2 compatible. Por lo tanto, tenemos seguridad de nivel de transporte, así como características de encriptación de seguridad de nivel de carga útil. Por lo tanto, puede aprovechar esas características.
Agregar cachés al puente
Muy bien, voy a seleccionar uno de los cachés, SiteOneCache aquí mismo, a la derecha. Entonces, puedo elegir que sea Activo o Pasivo. Voy a ir con Activo y elegir Terminar.
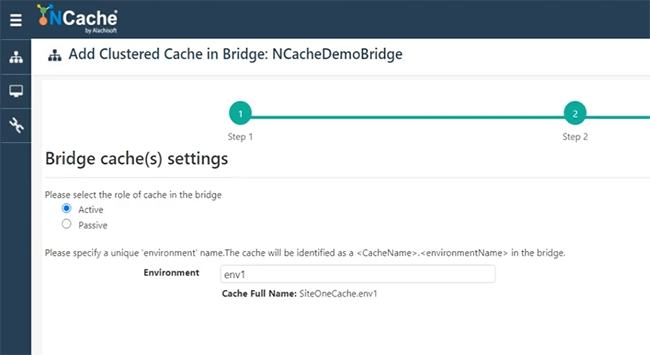
Entonces, SiteOneCache se agrega debajo del puente. Ahora voy a agregar el segundo caché, que es del cuadro 107. Espero poder abrir el administrador de control de servicios. Soy. Selecciónelo, SiteTwoCache. Hagámoslo de nuevo Activo. Si elige Pasivo, será caché del sitio uno al sitio dos, pero si elige activo, será entre el sitio uno y el sitio dos y entre el sitio dos y el sitio uno para la replicación de datos. Elijamos el acabado.
Supervisar las estadísticas del puente
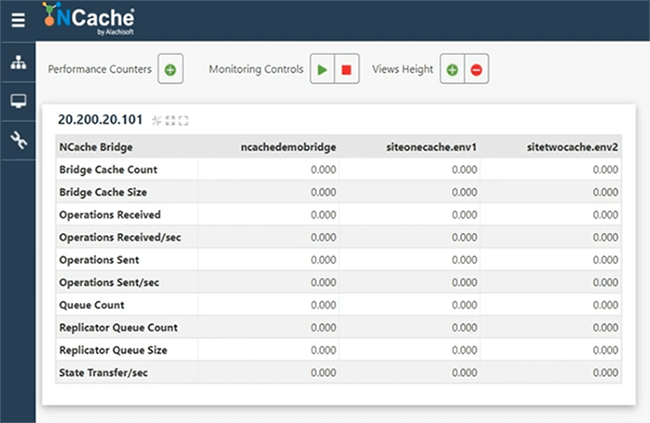
Entonces, también puede revisar los contadores de puente. Por ejemplo, si vengo aquí y abro las estadísticas del puente desde aquí, siempre puedo ver los contadores del puente también. Permítanme comenzar esto primero. Por alguna razón, el sistema no responde muy bien, por lo tanto, tenga paciencia conmigo y déjeme abrir la ventana de estadísticas. Entonces, aquí está nuestro puente. No se está replicando nada todavía porque no tenemos ninguna carga.
Entonces, solo voy a simular algo de carga ejecutando una herramienta de prueba de estrés, siteonecache.
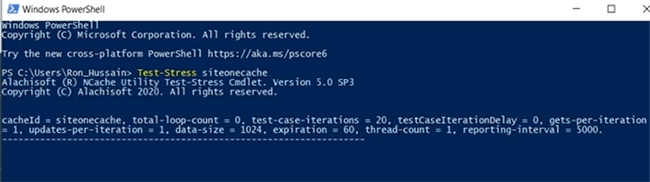
Como tenemos contadores disponibles, tendríamos un cliente conectado y comenzaríamos a simular. Aunque hemos ejecutado esto solo para SiteOneCache, tan pronto como se conecta. Entonces, por favor tengan paciencia conmigo. Entonces, déjame abrir el monitor para revisar si realmente está conectado al caché o no. Creo que es. Entonces, el puente tiene algo de actividad, lo que sugiere que el puente ahora está aceptando solicitudes. El medio ambiente está un poco lento hoy. Me disculpo por eso, pero vamos a revisar cómo va. Bien, entonces, ya que el puente muestra actividad. El tamaño de la memoria caché del puente está creciendo, las operaciones recibidas y luego recibidas por segundo muestran actividad. Entonces, eso esencialmente significa que está replicando datos entre sitios. Ahí tienes Entonces, tenemos SiteOneCache aquí mismo.
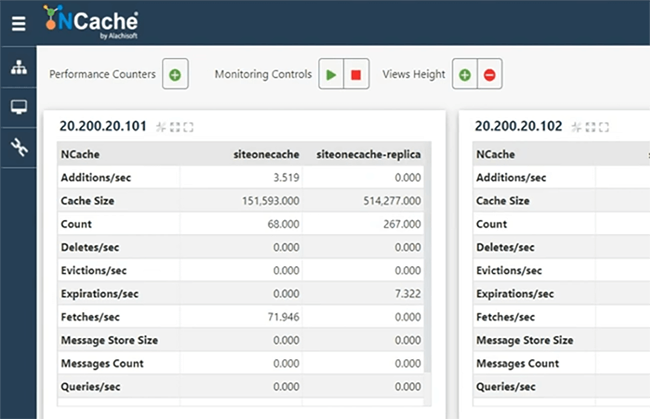
Si vamos a abrir, déjame iniciar sesión en nuestro entorno de demostración, para que podamos ver la vista correcta de los contadores desde allí. Creo que eso también debería ayudarnos a revisar cualquier problema relacionado con los permisos porque está tomando mucho tiempo cargar esto y tampoco puedo ver la actividad del contador. Está bien. Entonces, permítanme iniciar este administrador web aquí. Ahí tienes Entonces, aunque antes no mostraba contadores en la pantalla local, cuando inicié sesión en SiteTwoCache desde ese servidor, el administrador web puede ver todos los contadores. Entonces, tenemos un conteo que se está replicando activamente. Nunca ejecuté ninguna herramienta de estrés dentro de dos cachés, pero está obteniendo datos activamente aquí. Ahora, si detengo eso o incluso si lo mantengo en ejecución, ahora también puedo ejecutar una herramienta de estrés para SiteTwoCache y eso también replicaría los datos en mi SiteOneCache. Entonces, eso completa nuestras pruebas. Creo que también debería ceñirme a tener control remoto en este entorno, para que podamos ver la actividad por separado en ambos entornos. Entonces, solo usaré siteonecache desde aquí, puente desde aquí y sitetwocache desde allá.
Voy a cubrir algunos casos de uso relacionados con la aplicación a continuación. Entonces, por favor, hágamelo saber si hay alguna pregunta. Es solo una pregunta bastante básica, pero se trataba principalmente de qué entornos admitimos. Nuevamente, sé que mencionaste un par antes, pero pensé que podrías enumerarlos todos. Como dije, el único requisito previo para NCache es .NET o .NET Core. Usted puede utilizar NCache en entornos Windows y Linux, dondequiera que estén disponibles. Podría ser local, podría ser un entorno en la nube, podría ser Azure, AWS, Google Cloud o cualquier otro. También podría ser un entorno alojado. Está disponible en Docker, a través de Docker Container y puede usar Docker Images para alojar su caché y sus aplicaciones. Kubernetes también es compatible. OpenShift, Kubernetes Service, mencionó Azure Kubernetes Service, Elastic Kubernetes Service. Entonces, donde sea que pueda usar Docker, puede usar NCache allí y todo se reduce a un simple hecho de que si tienes .NET Core o .NET instalado, ese es el único requisito previo para NCache y NCache esencialmente puede ejecutarse en todas esas plataformas, en todos esos servidores.
Ejecutar aplicación de muestra
Entonces, permítanme correr, aunque estoy usando este puente aquí, tengo otro puente que está disponible. Entonces, déjame ejecutar otra aplicación, que está justo aquí. Es una aplicación web con equilibrio de carga. Lo hemos diseñado de tal manera que podemos enrutar una solicitud en un centro de datos y si ese centro de datos está inactivo, la solicitud posterior iría al otro centro de datos. Entonces, eso esencialmente le daría una idea de cómo administrar la recuperación ante desastres, si tiene NCache puente activado y puede tener todos sus datos disponibles.
Entonces, antes que nada, ejecutaría esto desde aquí, donde tenemos, permítanme abrir esto desde esta ventana, aquí mismo. Entonces, permítanme comenzar con la muestra de almacenamiento en caché de objetos. Bien, déjame ejecutar este LondonCache muestra y luego déjame abrir la otra muestra que está disponible. Entonces, voy a comenzar con Visual Studio. Corriendo las muestras. Entonces, tan pronto como se ejecuten estos ejemplos, le mostraré que puede usar esencialmente el almacenamiento en caché de objetos y enrutar la solicitud entre los centros de datos según sea necesario.
Entonces, eso le daría una representación visual de los datos que se agregan desde un centro de datos y se recuperan de otro y viceversa a través de nuestro puente. Muy bien, entonces, esto es usar un LondonCache que he configurado aquí mismo. Si te muestro muy rápido. Entonces, tenemos un LondonCache y tenemos NewYorkCache. Entonces, dos cachés que representan dos centros de datos y luego tenemos un puente que es NCache puente. tiene londonCache como CacheOne activo y NYCache como segundo. Entonces, voy a detener el puente por ahora. Muestre estos dos cachés por separado y luego simularé algunos datos y le mostraré cómo funciona esto en el caché. Entonces, déjalo correr y tan pronto como se cargue y esté usando NYKCache, entonces, déjame girar esto también. Ahora que sabe cómo configurar el puente, es muy simple en términos de conectar estos dos cachés ejecutando la herramienta de administración en cualquier caja y poder configurar ese puente. Entonces, por favor tengan paciencia conmigo. Daría vueltas a algunos casos. Es terriblemente lento hoy, me disculpo por eso. Entonces, su evento construido se ha completado, por lo que lo simulará en breve. Correcto, entonces, este es nuestro Main.aspx y dentro de esto solo estoy cargando algunos objetos en el caché. Eso es todo lo que estoy haciendo. Por ejemplo, dentro de la derecha, entonces, si les muestro Main.aspx, en realidad está cargando algunos de los objetos en el caché. Entonces, la idea aquí es que llegaríamos al sitio de la región de Londres y luego llegaríamos a la región de Nueva York y luego les mostraré cómo sincronizar los datos agregados de la región de Londres a Nueva York y viceversa y una representación visual haría que todo fuera mucho más claro en comparación. Entonces, tenemos ambos lados en funcionamiento. Permítanme abrir uno aquí y el otro aquí. Ahora, si agrego digamos 10 elementos, lo que permite. Se agregan 10 artículos. Si recupero del mismo caché, muestra que estos datos se agregaron desde la región del Reino Unido y los clientes del Reino Unido se muestran aquí.
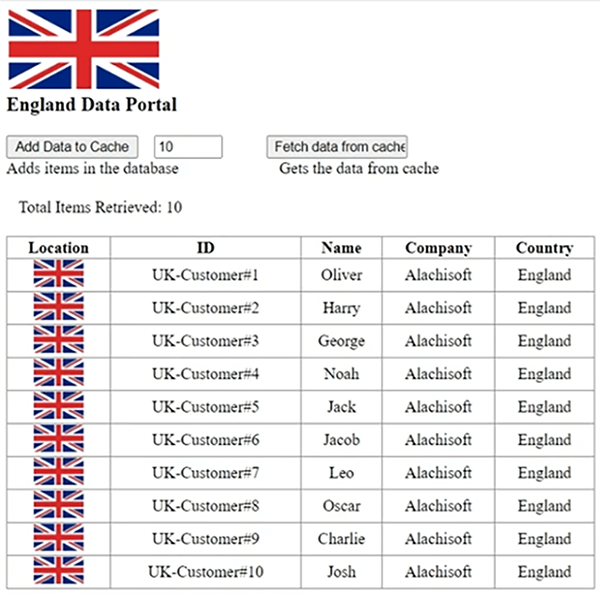
De manera similar, si agrego datos del portal de Londres, EE. UU., agrega 10 elementos y luego ve todos esos 10 elementos, pero ¿qué pasa si el usuario rebota y necesita que los datos de ambas regiones estén disponibles simultáneamente? Entonces, eso no es posible todavía. Permítanme agregar 5 elementos más aquí, para que esto sea diferente en términos de números. Entonces, tenemos alrededor de 15 artículos aquí y 10 artículos aquí. Entonces, con solo un clic de distancia, si enciendo este puente, a la derecha, y abro las estadísticas, lo primero que hace ese puente, ya sabes, es en realidad replicar todos los datos que ya están en los cachés.
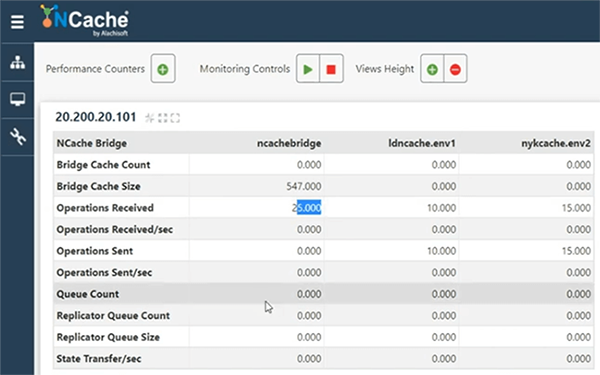
Entonces, los cachés ya están conectados, tan pronto como comenzamos el puente. Tenemos puente replicado, replicando 25 elementos. Entonces, eso es exactamente lo que agregamos. Entonces, si abro los mostradores de, déjame abrir el LondonCache, así como NewYorkCache y estadísticas abiertas. Por alguna razón, esto está tomando tiempo, pero eventualmente se abrirá. Ahora, tenemos estadísticas aquí mismo.
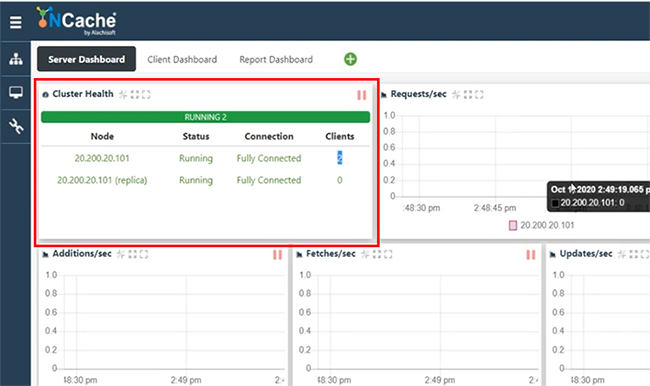
Tenemos clientes conectados y tenemos el valor de conteo que se muestra aquí. Entonces, muestra alrededor de 25 elementos y eso es lo que también está viendo en NewYorkCache. Ahora, volviendo a mi aplicación, mantendría la misma aplicación ejecutándose, pero esta vez solo buscaría datos desde aquí y espero ver todos los elementos en el caché. Entonces, los 25 elementos, Londres, así como los elementos de EE. UU. recuperados aquí porque unen los datos replicados de CacheOne a CacheTwo y CacheTwo a CacheOne. Entonces, 15 elementos aquí ahora se agregan con 10 elementos más a 25 elementos juntos y si obtengo datos del caché, USCache, también veo todos los elementos en la región de EE. UU. Entonces, nuevamente es una transmisión bidireccional. Podrían ser más de dos. Puede ser activo-pasivo. Donde se puede hacer transmisión unidireccional o activo-activo como se muestra en la aplicación de muestra.
Ahora, cualquier artículo nuevo que se agregue, digamos, 20 artículos más agregados, digamos y los busques desde aquí, obtienes 45 artículos y si busco esos artículos desde aquí, verás 45 artículos aquí. Entonces, es instantáneo. Cualquier elemento aquí agregado aquí, digamos, agregue datos en el, eso aumentaría el conteo de 45 a 68, pero si obtengo datos de aquí, obtengo los mismos elementos disponibles desde aquí. Entonces, vea qué tan rápido es replicar datos entre diferentes sitios. Entonces, estos dos cachés son, y estos cachés también se ejecutan en múltiples servidores mientras hablamos. Entonces, eso completa nuestra demostración de almacenamiento en caché de objetos.
Replicación de sesiones ASP.NET entre centros de datos
Permítame mostrarle también cómo manejar esto si está utilizando sesiones ASP.NET. En sitios múltiples, ya sabes, también puedes tener sesiones ASP.NET. Entonces, por ejemplo, si esto es a través de un balanceador de carga, solo agregaría algunos elementos, esa es una aplicación separada. Tenemos dos servidores web, el servidor web del sitio uno y el servidor web del sitio dos, que alojan la misma aplicación en todos los centros de datos. Entonces, agregaré algunos elementos. Entonces, tan pronto como se agregue, déjame detener el puente una vez más. Si veo el carrito. Entonces, tenemos un elemento agregado. Digamos agregar algunos elementos más. Entonces, tenemos algunos artículos disponibles. Ahora, si voy a IIS, ya sabes, el sitio de Londres. Permítanme comenzar esto también, ¿verdad? Traiga de vuelta aquí, tiene, realmente espero que llegue al sitio de Londres como una prioridad. No tenemos ningún elemento allí, entonces, veamos dónde termina y luego conectaremos el puente y le mostraremos que cualquier dato que agregue desde el Sitio Uno estará disponible en el Sitio Dos y viceversa. La primera solicitud suele ser lenta. Acabo de iniciar la aplicación, ahí lo tienes. Entonces, si llegamos aquí, obtenemos 0 artículos devueltos. Por lo tanto, estos dos sitios no están sincronizados, aunque su sesión de usuario rebota de un sitio a otro, cada vez que iniciamos o detenemos el sitio.
Ahora, simplemente encendería el puente, en las mismas líneas, como lo hicimos anteriormente. Derecha. Por lo tanto, se ejecutaría y se va a iniciar. De nuevo, voy a ver las estadísticas. Entonces, hay 69 elementos, ya sabes, estos son de la prueba anterior. Pero ahora, si vuelvo a mi sitio aquí mismo. Derecha. Empecemos de nuevo. Hemos añadido algunos artículos. Sigamos haciendo eso. Ahora, coincidentemente, si esto o si se cae debido a un corte de energía o lo dejas caer, si dejo fuera de servicio el sitio de Londres, el único sitio es, ya sabes, el sitio de Nueva York todavía está en funcionamiento, entonces, si yo simplemente haga clic en ver carrito, los mismos elementos de datos están disponibles en el portal de EE. UU. y tiene datos agregados desde el sitio del Reino Unido. Por lo tanto, puede ver los datos que se rebotan de un sitio a otro y su usuario aún recupera los datos. Ahora, incluso si el sitio vuelve, ya sabes, vuelve a estar en línea, nuevamente podría recuperar todos los datos de la sesión del caché.
Sesiones ASP.NET multisitio
Del mismo modo, tenemos sesiones ASP.NET multisitio. Esa es una característica separada. Por lo tanto, recomendamos puente para sus escenarios de almacenamiento en caché de objetos, donde tenemos una gran cantidad de transmisión de datos detrás de escena entre dos cachés y lo hemos visto tanto para el almacenamiento en caché de objetos como para el almacenamiento en caché de sesiones.

Pero para el almacenamiento en caché de sesiones, también tenemos un caso de uso de almacenamiento en caché de sesiones ASP.NET de sitios múltiples. Entonces, si no uso el puente. Todavía puedo vincular estos dos sitios y eso es a través de una función separada que está disponible y para eso simplemente detendré el puente. Tan pronto como se detenga, voy a volver aquí. Permítanme borrar el contenido, para que comencemos de nuevo y esa es en realidad una mejor manera de sincronizar su caché para el almacenamiento en caché de la sesión. Razones para eso, la sesión es un dato muy transaccional. Por lo tanto, no desea que se repliquen los datos de su sesión, aunque su usuario no está rebotando de un sitio a otro, ¿verdad? Entonces, si su usuario está principalmente en un sitio y porque es un usuario humano que tiene sesiones ASP.NET. Entonces, en ese caso, se trata de datos transaccionales de naturaleza transitoria, no serían necesarios en el otro sitio. Solo se basa en el usuario que está allí y si termina cambiando su usuario de un sitio a otro, eso podría administrarse con la replicación de datos a pedido. No necesita replicar todos los datos de la sesión. Por ejemplo, el desbordamiento ocurre cuando un sitio está siendo más, alcanzando más capacidad que otro y desea que los usuarios desbordados vayan al otro sitio y ya tenían un objeto de sesión creado aquí. Por lo tanto, no necesita todas las sesiones allí. Solo necesita sesiones de ese usuario en particular. Entonces, para atender ese escenario, no recomendamos que encienda el puente.
Entonces, para eso tenemos otra característica llamada NCache Sesión multisitio. Por lo tanto, el Proveedor de estado de sesiones ASP.NET de varias regiones le permite lograr todo eso, sin usar el puente.
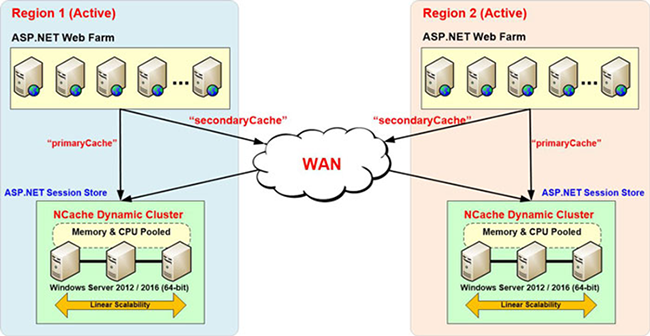
Entonces, tiene el caché del sitio uno, que tiene sesiones y tenemos el caché del sitio dos y el sitio uno tiene la dirección del caché principal y luego la dirección del caché de respaldo en toda la región y, de manera similar, el caché del sitio dos tiene un concepto principal y de respaldo. Entonces, si un usuario rebota de un sitio a otro, sus clientes de caché, que son sus servidores de aplicaciones, irán al otro sitio a pedido y obtendrán los datos de la sesión disponibles desde allí y todo lo que necesita es información para el caché de otro sitio. , por ejemplo, tenemos caché principal y caché secundario, Londres, Nueva York y puede tener múltiples cachés de respaldo. Entonces, en caso de que el usuario de Londres rebote al sitio de Nueva York, volvería a LondonCache y buscaría los datos y los mantendría allí para demostrar que volvería a empezar con una aplicación de caché. Por ejemplo, agrego algunos datos aquí, nuevamente esto está usando LondonCache. Agregue artículos aquí. Recuerde que he borrado el contenido del caché, por lo que no tenemos ningún elemento aquí y, de manera similar, déjeme abrir el LondonCache Estadísticas. Entonces, no tenemos ningún artículo aquí, hasta que llegue la primera solicitud. Digamos, agregue. Entonces, tenemos dos elementos, con el mismo nombre, por supuesto. Entonces, se crea una sesión aquí. Todavía no se ha replicado en el sitio de Nueva York, pero tenemos habilitada la función de sesión en varios sitios. No necesitamos puente para esto, porque queremos que se realice la replicación de sesión bajo demanda. Hemos realizado estas configuraciones, donde tenemos caché principal y caché secundario y luego tenemos conectado el proveedor de estado de sesión.
Entonces, solo se basa en la configuración del proveedor del estado de la sesión, NCache es capaz de manejar el caso de uso de la sesión Multi-Site sin usar el puente y es bajo demanda, por lo que es mucho más eficiente en lo que respecta a los datos de la sesión. Entonces, lo que haría ahora es devolver la solicitud de sesión a otro sitio yendo a IIS y detendría el sitio de Londres por completo. Mantendría el caché en funcionamiento, por supuesto, y si ahora busco esto. En primer lugar, obtendría los datos del sitio de EE. UU. Los mismos artículos estarían disponibles desde allí y tan pronto como se complete, agregaría algunos artículos más y traería el LondonCache copia de seguridad en línea. Entonces, es una replicación bajo demanda, lo que estoy tratando de demostrar. Entonces, veamos cómo va. Digamos, déjame agregar algunos elementos. Entonces, permítanme volver a poner este sitio en línea. Ya que es pegajoso al sitio de Londres. Entonces, ahora que he traído al usuario de EE. UU. al sitio de Londres, veamos cómo va. Por lo tanto, los mismos elementos también están disponibles en el sitio de Londres y los elementos de datos se agregaron desde la región de EE. UU. Si agrego algún elemento más aquí, también podría agregar esos elementos aquí. Permítanme simular esta falla una vez más deteniendo este sitio y veamos si también rebota al otro lado. Creo que anteriormente hubo algunos problemas relacionados con la configuración, pero ahora que este sitio está detenido. Déjame ver el carrito. Espero, ahí tienes. Entonces, la misma sesión ahora está disponible desde el sitio de EE. UU. y recuerde que no tengo ningún puente configurado aquí para esta función, es solo la sesión de sitios múltiples. El puente está parado. Todavía está replicando datos, pero es bajo demanda. Entonces, eso realmente lo completa.
Para el almacenamiento en caché de objetos y menos datos transaccionales, datos de referencia y datos estáticos, le recomendamos que active el puente y aproveche la replicación activa entre centros de datos, pero la sesión es un caso de uso transaccional que tiene una combinación de solicitudes de lectura y escritura. Por lo tanto, es muy pesado mientras actualiza datos de un centro de datos a otro, los datos ya han cambiado en el centro de datos principal y el usuario de la sesión no rebota de un centro de datos a otro. Sería solo en un sitio en un momento dado. Por lo tanto, no necesita replicación de datos activa. Puede tener replicación bajo demanda. Cuando rebota de la región uno a la región dos, debería poder obtener los datos de la sesión desde allí y si rebota a la región uno, debería poder volver a poner a disposición los datos de la sesión y para eso le recomendamos que use nuestra función de sesión multisitio sin puente.
Hay algunas características avanzadas que discutiría rápidamente.
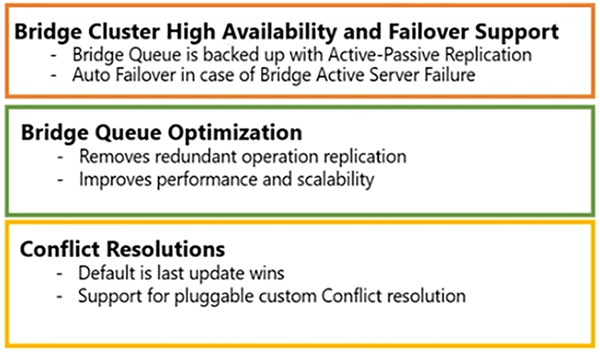
El puente tiene una alta disponibilidad. El soporte de conmutación por error está integrado, cualquier servidor puente que se caiga no incurrirá en ningún tiempo de inactividad. La cola del puente está muy optimizada. Es rápido. Además, puede habilitar algunas funciones de optimización de colas, lo que lo haría aún más óptimo.

La resolución de conflictos está integrada en él. La última actualización gana, pero si desea implementar su propia resolución de conflictos, puede usar un controlador y registrarse con NCache. Por lo tanto, se puede llamar a esta interfaz, en caso de que haya un conflicto de dos claves, donde ocurren dos actualizaciones al mismo tiempo. Asi que, NCache le daría el control y puede verificar la versión de ese elemento y tomar la decisión de cuál gana.
Manejo de desastres en tiempo de ejecución. Inicialmente, Zack preguntó cómo hacer que el sitio Pasivo se active, solo necesita enrutar el tráfico al Pasivo.

Si el sitio activo alguna vez se cae y no hay tiempo de inactividad, se produce una resincronización automática si el activo vuelve a funcionar. En Activo-Activo, el tráfico se enruta a ambos sitios. Cualquier sitio que se caiga no tendrá un impacto, solo necesita enrutar el tráfico de regreso al activo y si el activo, el otro activo vuelve a estar en línea, la resincronización se realiza automáticamente. No hay retrasos, no se necesita intervención manual. En dos o tres o más casos Activo-Activo, si el sitio activo no puente se cae, solo necesita usar el tráfico a cualquier otro sitio y no habrá tiempo de inactividad ni pérdida de datos. En caso de que el sitio activo del puente se caiga, por ejemplo, si tenemos un sitio de puente aquí.
Si esto falla, también tenemos la opción de un sitio puente de respaldo. Por lo tanto, puede habilitar ese sitio de puente y, para ello, puede especificar el puente de respaldo para recoger la replicación. Por lo tanto, la replicación se detendría si todo el sitio del puente se cae, pero también tenemos la opción de un sitio del puente de respaldo.
Entonces, quiero cubrir estos aspectos muy rápido. Creo que debería ser suficiente por ahora. ¿Alguna pregunta hasta ahora? Zack puedes recogerlo desde aquí. Claro, lo sé, estamos corriendo en el último minuto o dos, así que solo agregaré una pregunta que surgió sobre lo que acaba de revisar. Tenía que ver con la resolución de conflictos y creo que la pregunta es ¿cuáles son los ejemplos de resolución de conflictos en los que necesitaríamos implementarlos? Bueno. Por lo general, la mayor parte de la resolución de conflictos se manejaría de forma predeterminada, donde no necesita implementar nada. La resolución de conflictos basada en el tiempo es todo lo que necesita. Con la expectativa de que está ejecutando sitios Activo-Activo y necesita datos de un centro de datos a otro, necesita actualizaciones de un centro de datos a otro. Entonces, la última actualización gana. Pero, en caso de que los datos sean más específicos y desee tener el valor de los datos, eso determinaría qué objeto debe mantenerse en el puente. Por ejemplo, hay cierta versión o cierta información o cierto número de secuencia dentro de la definición del objeto, por ejemplo, hay un atributo de versión de un objeto. Por lo tanto, si hay un conflicto, no desea que se pierda ese objeto. Entonces, verifica ese objeto a través del código, verifica la versión, cuál se necesita mantener, por lo tanto, según la última versión o la última versión en comparación con el tiempo, podría basarse en la versión. Incluso podría basarse en el valor del objeto. Por ejemplo, hay un registro de base de datos y tiene un objeto que representa esa base de datos y que tiene una hora modificada. Entonces, esa no es la actualización en el caché, es una actualización en la base de datos, pero ese tiempo de actualización es parte de ese objeto y si ese objeto se agregó primero y luego otro objeto se sobrescribe, no desea esa última actualización. la base de datos que se perderá, ¿verdad? Entonces, si hay algo dentro del objeto y necesita tomar una decisión basada en los valores de los atributos, debe implementar la resolución de conflictos usted mismo para eso. Pero como dije, la mayor parte de la resolución de conflictos se manejará de forma predeterminada a través de nuestra opción predeterminada de base de tiempo. Por lo tanto, cualquiera que sea la última actualización, se aplicará como la última actualización en el elemento y esto solo sucede, recuerde que esta lógica de resolución de conflictos solo entraría en juego si hay dos actualizaciones agregadas simultáneamente en la cola en el puente. Correcto, entonces Bridge recibe dos actualizaciones al mismo tiempo. Entonces, ¿cuál elegir? El sitio uno agregó o actualizó un elemento y el sitio dos también agregó o actualizó el mismo elemento. Entonces, el puente ahora tiene que decidir cuál mantener en el caché o en la cola y eso es lo que se replica en el sitio uno y el sitio dos también. Porque uno tiene que ganarse al otro. Por lo tanto, la resolución de conflictos basada en el tiempo se implementa de manera predeterminada y eso lo ayudaría a resolver la mayoría de sus casos.
Te lo dejo a ti, ¿hay algo más que estemos revisando? Creo que estamos bien. En cuanto al contenido se refiere. Bueno. La demostración está completa. Muy bien, estamos corriendo justo en el último minuto aquí, así que gracias a todos los que han venido. Si tiene alguna pregunta relacionada con este seminario web específico, no dude en enviarnos un correo electrónico a support@alachisoft.com Definitivamente, diríjase a nuestro sitio web y descargue una prueba gratuita de 2 meses NCache Enterprise y utilícelo en su entorno. Si desea ayuda para incorporarlo, puede comunicarse con support@alachisoft.com y si tienes mas dudas sobre si quieres comprar NCache o para obtener información sobre licencias, no dude en comunicarse con sales@alachisoft.com.