Seis razones por las cuales NCache es mejor que Redis
Seminario web grabado
Por Iqbal Kan
Aprende cómo Redis y NCache comparar entre sí a nivel de característica. El objetivo de este seminario web es hacer que su tarea de comparar los dos productos sea más fácil y rápida.
El webinar cubre lo siguiente:
- Diferentes áreas funcionales del producto.
- que apoyo hacen Redis y NCache proporcionar en cada área característica?
- ¿Cuáles son los puntos fuertes de NCache Más de Redis ¿y viceversa?
NCache es un popular caché distribuido en memoria de código abierto (licencia Apache 2.0) para .NET. NCache se usa comúnmente para el almacenamiento en caché de datos de aplicaciones, el almacenamiento de estado de sesión de ASP.NET y el uso compartido de datos de tiempo de ejecución de estilo pub/sub a través de eventos.
Redis es también un popular almacén de estructura de datos en memoria de código abierto (licencia BSD) que se utiliza como base de datos, caché y agente de mensajes. Redis es muy popular en Linux, pero últimamente ha llamado la atención en Azure debido a que Microsoft lo promociona.
General
Hola a todos, mi nombre es Iqbal Khan y soy un evangelista tecnológico en Alachisoft. Alachisoft es una empresa de software con sede en el Área de la Bahía de San Francisco y es la creadora del popular NCache producto, que es un caché distribuido de código abierto para .NET. Alachisoft es también el fabricante de NosDB, que es una base de datos SQL de código abierto para .NET. Hoy voy a hablar de seis razones por las que NCache es mejor que Redis para aplicaciones .NET. Redis, como saben, está desarrollado por Redis labs y fue elegido por Microsoft para Azure. La principal razón para elegir fue que Redis ofrece soporte multiplataforma y muchos idiomas diferentes, mientras que NCache se centra exclusivamente en .NET. Entonces empecemos.
Caché distribuida
Antes de entrar en las comparaciones, primero permítanme darles una breve introducción de qué es el almacenamiento en caché distribuido y por qué lo necesita y qué problema resuelve. El almacenamiento en caché distribuido se usa realmente para ayudar a mejorar la escalabilidad de sus aplicaciones. Como sabe, si tiene una aplicación web o una aplicación de servicios web o cualquier aplicación de servidor, puede agregar más servidores en el nivel de la aplicación. Por lo general, las arquitecturas de aplicaciones permiten que eso se haga sin problemas. Pero no puede hacer lo mismo en el nivel de la base de datos, especialmente si está utilizando una base de datos relacional o datos de mainframe heredados. Puedes hacer eso sin SQL. Pero ya sabes, en la mayoría de los casos tienes que usar bases de datos relacionales por razones técnicas y comerciales.
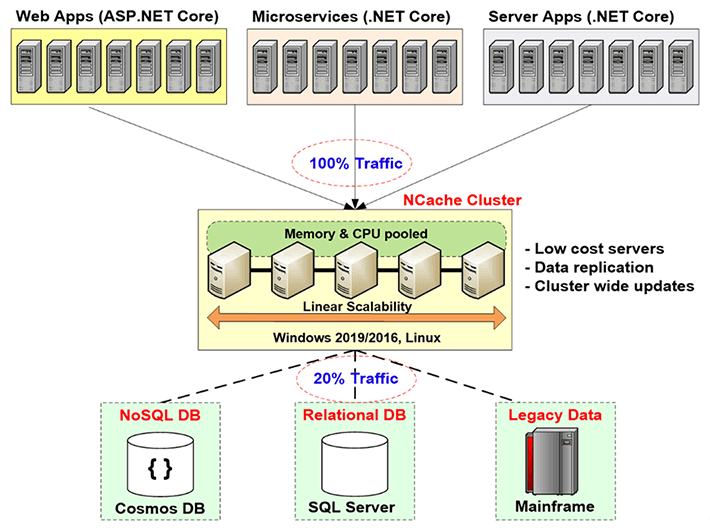
Por lo tanto, debe resolver este cuello de botella de escalabilidad que las bases de datos relacionales o el mainframe heredado le brindan a través del almacenamiento en caché distribuido, y la forma de hacerlo es creando un nivel de almacenamiento en caché entre el nivel de la aplicación y la base de datos. Este nivel de almacenamiento en caché consta de dos o más servidores. Suelen ser servidores de bajo coste. En caso de NCache, la configuración típica es una CPU dual, una máquina de cuatro núcleos, con 16 a 32 Giga de RAM y una o dos tarjetas de red, que tienen una velocidad de 1 a 10 gigabits. Estos servidores de almacenamiento en caché forman un clúster basado en TCP en caso de NCache y agrupar los recursos de todos estos servidores en una sola capacidad lógica. De esa manera, a medida que crezca el nivel de la aplicación, digamos que si tiene más y más tráfico o más y más carga de transacciones, puede agregar más servidores en el nivel de la aplicación. También puede agregar más servidores en el nivel de almacenamiento en caché. Por lo general, mantiene una proporción de 4 a 1 o de 5 a 1 entre el nivel de aplicación y el nivel de almacenamiento en caché.
Entonces, debido a esto, el caché distribuido nunca se convierte en un cuello de botella. Por lo tanto, puede comenzar a almacenar en caché los datos de la aplicación aquí y reducir el tráfico a la base de datos. El objetivo es que aproximadamente el 80 % de su tráfico vaya a la memoria caché y aproximadamente el 20 % del tráfico, que generalmente son sus actualizaciones, vaya a la base de datos. Y si lo hace, entonces su aplicación nunca enfrentará un cuello de botella de escalabilidad.
Usos comunes de la caché distribuida
De acuerdo, teniendo en cuenta el beneficio de un almacenamiento en caché distribuido, hablemos de los diferentes casos de uso que conoce, las diferentes situaciones en las que puede usar un caché distribuido.
Almacenamiento en caché de datos de aplicaciones
El número uno es el almacenamiento en caché de datos de la aplicación, que es lo mismo que acabo de explicar donde almacena en caché los datos que residen en su base de datos, para que pueda mejorar el rendimiento y la escalabilidad. Lo principal a tener en cuenta para el almacenamiento en caché de datos de una aplicación es que sus datos ahora existen en dos lugares. Existe en su base de datos, que es la fuente de datos maestra y también existe en el nivel de almacenamiento en caché y cuando eso sucede, lo más importante que debe tener en cuenta es que, ya sabe, la mayor preocupación que surge es, ya sabe , ¿el caché se volverá obsoleto? ¿El caché tendrá una versión anterior de los datos, aunque los datos hayan cambiado en la base de datos? Si esa situación ocurre, entonces, por supuesto, tiene un gran problema, y muchas personas, debido a este temor a los problemas de integridad de los datos, solo almacenan en caché datos de solo lectura. Bueno, los datos de solo lectura son un subconjunto muy pequeño de los datos totales que debe almacenar en caché y son aproximadamente del diez al quince por ciento de los datos.
El beneficio real radica en que puede comenzar a almacenar en caché los datos transaccionales. Estos son sus clientes, sus actividades, su historial, ya sabe, todo tipo de datos que se crean en el tiempo de ejecución y cambian con mucha frecuencia, aún necesita almacenar en caché esos datos, pero debe almacenarlos en caché de manera que el caché siempre se mantiene fresco. Entonces, ese es el primer caso de uso, y volveremos a eso.
Almacenamiento en caché específico de ASP.NET
El segundo caso de uso es para el almacenamiento en caché específico de ASP.NET, donde almacena en caché el estado de la sesión, el estado de la vista y si no tiene el marco MVC y una salida de página. En esta situación, está almacenando en caché el estado de la sesión porque un caché es un almacenamiento mucho más rápido y escalable que su base de datos, que es donde de otro modo estaría almacenando en caché estas sesiones o las otras opciones que ofrece Microsoft y, en este caso, los datos son transitorio. Transitorio significa que es de naturaleza temporal. Solo es necesario durante un breve período de tiempo, después del cual simplemente lo tira y los datos solo existen en el caché. El caché es el almacén principal. Entonces, en este caso de uso, la preocupación no es que el caché deba sincronizarse con la base de datos, sino que si algún servidor de caché deja de funcionar, perderá algunos de los datos. Porque todo es almacenamiento en memoria y la memoria, como saben, es volátil. Por lo tanto, una buena caché distribuida debe proporcionar estrategias de replicación inteligentes. Por lo tanto, tiene todos los datos que existen en más de un servidor. Si un servidor deja de funcionar, no pierde ningún dato, pero la replicación tiene un costo asociado, un costo de rendimiento. Entonces, la replicación debe ser súper rápida, que es lo que NCache lo hace, por cierto.
Intercambio de datos en tiempo de ejecución
El tercer caso de uso es el caso de uso de uso compartido de datos en tiempo de ejecución, en el que utiliza la memoria caché como una plataforma de intercambio de datos esencialmente. Por lo tanto, muchas aplicaciones diferentes están conectadas al caché y pueden compartir datos en un modelo Pub/Sub. Entonces, una aplicación produce los datos, los coloca en el caché, activa un evento y se notificará a otras aplicaciones que hayan registrado interés en ese evento, para que puedan ir y consumir esos datos. Entonces, también hay otros eventos. Hay eventos basados en claves, los eventos de nivel de caché, hay una función de consulta continua que NCache posee. Por lo tanto, hay varias formas en que puede usar un caché distribuido como NCache para compartir datos entre diferentes aplicaciones. En este caso también, aunque los datos se crean a partir de los datos de la base de datos, la forma en que se comparten solo puede existir en la memoria caché. Por lo tanto, debe asegurarse de que el caché replique los datos. Entonces, la preocupación es la misma que para el almacenamiento en caché de ASP.NET. Entonces, esos son los tres casos de uso que son comunes para un caché distribuido de uso. Tenga en cuenta estos casos de uso mientras comparo las características que NCache proporciona que Redis no.
Razón 1: mantener la memoria caché fresca
Entonces, la primera razón por la que deberías usar NCache Más de Redis es eso, NCache le proporciona funciones muy potentes para mantener el caché actualizado. Como hablamos sobre esto, si no puede mantener el caché actualizado, se ve obligado a almacenar en caché datos de solo lectura y si almacena datos de solo lectura, entonces, ese no es el beneficio real. Por lo tanto, debe poder almacenar en caché prácticamente todos sus datos. Incluso los datos que cambian cada 10-15 segundos.
Vencimientos Absolutos / Vencimientos Móviles
Entonces, la primera forma de mantener el caché actualizado es a través de los vencimientos. La caducidad es algo que ambos NCache y Redis proveer. Entonces, por ejemplo, hay una caducidad absoluta en la que le dices a la caché que caduque estos datos después de 10 minutos, 2 minutos o 1 minuto. Después de ese tiempo, el caché elimina esos datos del caché y usted está adivinando, está diciendo, ya sabe, creo que es seguro mantener estos datos en el caché durante tanto tiempo porque no creo que vaya a cambio en la base de datos. Entonces, según esa suposición, le está diciendo al caché que caduque los datos.
Así es como se ve la Expiración. Solo voy a mostrarte algo. En caso de NCache, cuando instalas NCache por cierto, ya sabes, te da un montón de muestras. Entonces, una de las muestras se llama operaciones básicas y la tengo abierta aquí. Entonces, en las operaciones básicas, permítame darle también rápidamente, esto es lo que usa una aplicación .NET típica NCache parece.
te vinculas con NCache en tiempo de ejecución NCache.Web ensamblado luego usa el NCache.Tiempo de ejecución espacio de nombres, NCache.Web.caching espacio de nombres y luego, al comienzo de su aplicación, se conecta con el caché. Todos los cachés tienen nombre.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Si quieres saber cómo crear un caché, mira nuestro video de inicio. Está disponible en nuestro sitio web. Pero, supongamos que se ha conectado a este caché, por lo que tiene un identificador de caché. Ahora creas tus datos, que son un montón de objetos y luego haces caché.Agregar. caché.Agregar tiene una clave que es una cadena y el valor real que es su objeto y luego, en este caso, está especificando un vencimiento absoluto de un minuto. Por lo tanto, está diciendo que caduque este objeto dentro de un minuto y al decir que está diciendo NCache para caducar este objeto. Entonces, así es como funciona la caducidad que, por supuesto, como dije, Redis también te proporciona.
Sincronizar caché con base de datos
Pero, el problema con la caducidad es que estás haciendo una conjetura que puede no ser correcta, puede no ser precisa. Entonces, ¿qué pasa si los datos cambian antes de ese minuto antes de los cinco minutos que había especificado? Entonces, ahí es donde necesita esta otra función llamada sincronizar el caché con la base de datos. Esta es la característica que NCache tiene y Redis no tiene.
¿Entonces NCache lo hace de varias maneras. el numero primero es Dependencia SQL. La dependencia de SQL es una característica del servidor SQL a través de ADO.NET, donde básicamente especifica una declaración SQL y le dice al servidor SQL y dice, ya sabe, controle este conjunto de datos y si este conjunto de datos cambia, significa que se agrega cualquier fila. , actualizado o eliminado que coincida con los criterios de este conjunto de datos, notifíqueme. Entonces, la base de datos le envía una notificación de la base de datos y luego puede tomar la acción apropiada. Entonces, el camino NCache esto es, NCache utilizará la dependencia de SQL y también hay una dependencia de Oracle que hace lo mismo con Oracle. Ambos trabajan con eventos de bases de datos. Asi que, NCache utilizará la dependencia de SQL. Déjame mostrarte ese código aquí. Entonces, solo voy a ir al código de dependencia de SQL. Nuevamente, de la misma manera se vincula con algunos de los ensamblajes. Obtiene el identificador de caché y ahora que está agregando cosas, solo voy a ir a esto, ir a definición. Entonces, ahora que está agregando estos datos, como parte de la adición, especifique una dependencia de SQL. Por lo tanto, la dependencia de caché es un NCache clase que toma una cadena de conexión a su base de datos. Se necesita una declaración SQL. Entonces, digamos, en este caso está diciendo, quiero que la declaración SQL sea donde la identificación del producto es esta identificación. Entonces, dado que está almacenando en caché un objeto de producto, lo está emparejando con la fila correspondiente en la tabla de productos. Entonces, estás diciendo, estás diciendo NCache para hablar con el servidor SQL y usar la dependencia de SQL para que el servidor SQL pueda monitorear esta declaración, y si estos datos cambian, el servidor SQL notifica NCache.
Entonces, ahora el servidor de caché se ha convertido en un cliente de su base de datos. Entonces, el servidor de caché le ha pedido a su servidor SQL que me notifique si este conjunto de datos cambia y cuando ese conjunto de datos cambia, el servidor SQL notifica al servidor de caché y al NCache El servidor luego elimina ese elemento del caché y la razón por la que lo elimina es porque una vez que se elimina la próxima vez que lo necesite, no lo encontrará en el caché y se verá obligado a obtenerlo de la base de datos. Entonces, así es como lo actualizas. Hay otra forma de recargar automáticamente el elemento del que hablaré en un momento.
Entonces, la dependencia de SQL permite NCache para sincronizar realmente el caché con la base de datos y con la dependencia de Oracle, funciona exactamente de la misma manera, excepto que funciona con Oracle en lugar de con el servidor SQL. La dependencia de SQL es realmente poderosa pero también es habladora. Entonces, digamos, si tiene 10,000 elementos o 100,000 elementos, va a crear 100,000 dependencias de SQL, lo que genera una sobrecarga de rendimiento en la base de datos del servidor SQL porque para cada dependencia de SQL, la base de datos del servidor SQL crea una estructura de datos y el servidor para monitorear esos datos y eso es una sobrecarga adicional.
Entonces, si tiene una gran cantidad de datos para sincronizar, tal vez sea mejor depender solo de la base de datos. Las dependencias de la base de datos son nuestra propia característica donde, en lugar de usar una declaración SQL y eventos de la base de datos, NCache en realidad extrae la base de datos. Hay una tabla especial que creas que se llama NCache Sincroniza la base de datos y luego modificas tus disparadores, de modo que vas y actualizas una bandera en una fila, correspondiente a este elemento almacenado en caché y luego NCache extrae esta tabla de vez en cuando, digamos, cada 15 segundos de forma predeterminada y luego puede, ya sabes, si encuentra alguna fila que se haya cambiado, invalida los elementos correspondientes almacenados en la memoria caché. Entonces, ambos y, por supuesto, la dependencia de la base de datos pueden funcionar en cualquier base de datos. No es solo el servidor SQL, Oracle, sino también si tiene DB2 o MySQL u otras bases de datos.
Por lo tanto, con la combinación de estas funciones, puede sentirse realmente seguro de que su caché siempre estará sincronizada con la base de datos y que puede almacenar en caché prácticamente cualquier dato. Hay una tercera forma que es un procedimiento almacenado CLR, por lo que en realidad puede implementar un procedimiento almacenado CLR. Desde allí puedes hacer un NCache llamar. Entonces, llama al procedimiento almacenado desde el disparador de la base de datos. Digamos que tiene una tabla de clientes y tiene un disparador de actualización o un disparador de eliminación o incluso un disparador de agregar en realidad. En el caso de un procedimiento CLR, también puede agregar nuevos datos. Entonces, el disparador llama al procedimiento CLR y el procedimiento CLR hace NCache llamadas y de esa manera prácticamente tienes la base de datos agregando los datos o actualizando los datos nuevamente en el caché.
Entonces, esas tres formas diferentes permiten NCache estar sincronizado con la base de datos y esta es una razón realmente poderosa para usar NCache Más de Redis porque Redis te obliga a usar solo vencimientos, lo cual no es suficiente. Realmente lo hace vulnerable o lo obliga a almacenar en caché datos de solo lectura.
Sincronizar caché con base de datos no relacional
También puede sincronizar el caché con una base de datos no relacional. Entonces, si tiene una base de datos heredada, mainframe, puede tener una dependencia personalizada que es su código que se ejecuta en el servidor de caché y de vez en cuando NCache llama a su código para ir y monitorear su fuente de datos y tal vez pueda hacer llamadas a métodos web o hacer otras cosas para ir y monitorear la fuente de datos personalizada y de esa manera puede sincronizar el elemento almacenado en caché con los cambios de datos en esa fuente de datos personalizada. Por lo tanto, la sincronización de la base de datos es una razón muy poderosa por la que debe usar NCache Más de Redis porque ahora almacenas en caché prácticamente todos los datos. Considerando que, en caso de Redis se verá obligado a almacenar en caché datos que son de solo lectura o en los que puede hacer conjeturas con mucha confianza sobre el vencimientos.
Razón 2: búsqueda de SQL
Razón número dos, está bien. Ahora que, digamos, ha comenzado a usar la sincronización con la función de base de datos y ahora puede almacenar en caché prácticamente una gran cantidad de datos. Entonces, cuantos más datos almacene en caché, más comenzará a parecerse a una base de datos y luego, si solo tiene la opción de obtener datos en función de las claves, que es lo que Redis entonces eso es muy limitante. Entonces, necesitas poder hacer otras cosas. Por lo tanto, debe poder encontrar datos de manera inteligente. NCache le brinda varias formas en las que puede agrupar datos y encontrar datos en función de atributos de objetos o en función de grupos y subgrupos o puede asignar etiquetas, etiquetas de nombre. Entonces, todas esas son formas diferentes en las que puede recuperar colecciones de datos. Por ejemplo, si fuera a emitir una consulta SQL, déjeme mostrarle que, digamos, hago una consulta SQL aquí. Entonces, quiero ir y encontrar, digamos, todos los clientes donde customer.city es Nueva York. Entonces, emitiré un estado SQL, diré seleccionar clientes, ya sabes, mi espacio de nombres completo, cliente donde esta. Ciudad es un signo de interrogación y en el valor que voy a especificar Nueva York como valor y cuando emita esa consulta, obtendré una colección de esos objetos de cliente que coincidan con este criterio.
Entonces, esto ahora se parece mucho a una base de datos. Entonces, lo que esto significa es que realmente puede comenzar a almacenar datos en caché. Puede almacenar en caché conjuntos de datos completos, especialmente tablas de búsqueda u otros datos de referencia en los que su aplicación se usó para emitir consultas SQL contra aquellos en la base de datos y el mismo tipo de consultas SQL que puede emitir contra NCache. La única limitación es que puede hacer uniones en caso de NCache pero muchos de estos no son necesarios para hacer las juntas. búsqueda SQL hace que el caché sea muy amigable para buscar y encontrar realmente los datos que está buscando.
Agrupación y subagrupación déjame mostrarte este ejemplo de agrupación. Entonces, por ejemplo, aquí puede agregar un montón de objetos y puede agregarlos todos. Entonces, los está agregando como un grupo. Entonces, esta es la clave, el valor, aquí está el nombre del grupo, aquí está el nombre del subgrupo y luego puedes decir dame todo lo que pertenece al Grupo de Electrónica. Esto le devuelve una colección y puede iterar sobre la colección para obtener sus cosas.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}También puede obtener las claves según el grupo. También puedes hacer otras cosas basadas en el grupo. Entonces, los grupos y las etiquetas funcionan de manera similar. Etiquetas de nombres también son lo mismo que las etiquetas, excepto que es un concepto de valor clave. Entonces, digamos, si está almacenando en caché texto de forma libre y realmente desea obtener algunos de los metadatos del texto indexado, entonces puede usar el concepto de valor clave con las etiquetas de nombre y de esa manera una vez que las etiquetas de grupos y las etiquetas de nombre que tiene entonces puede incluirlos en consultas SQL.
También puede emitir Consultas LINQ. Si se siente más cómodo con LINQ, puede emitir consultas LINQ. Entonces, en el caso de LINQ, por ejemplo, digamos, aquí está su NCache. Entonces, harías un NCache consulta con un objeto de producto. te da un IQueryable interfaz y luego puede emitir una consulta LINQ como lo haría con cualquier colección de objetos y en realidad está buscando en el caché.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}Entonces, cuando ejecuta esta consulta, cuando ejecuta esta consulta, en realidad va al nivel de almacenamiento en caché y busca sus objetos. Entonces, ya sabe, la interfaz disponible para usted es muy simple, de una manera muy amigable, pero detrás de escena, en realidad está almacenando en caché o buscando en todo el clúster de caché. Entonces, la razón número dos es que puede buscar en el caché, puede agrupar datos a través de grupos y subgrupos, etiquetas y etiquetas con nombre y hace posible encontrar datos de una manera amigable, que es algo en lo que ninguna de estas características existe. Redis.
Indexación de datos es otro aspecto de esto, que cuando se va a buscar en función de estos atributos, entonces es imperativo, es muy importante que el caché indexe, cree índices en esos atributos. De lo contrario, es un proceso extremadamente lento para encontrar esas cosas. Asi que, NCache le permite crear la indexación de datos. Por ejemplo, cada grupo y subgrupo, etiquetas, etiquetas de nombre se indexan automáticamente, pero también puede crear índices en sus objetos. Entonces, podría, por ejemplo, crear un índice en su objeto de cliente en el atributo de la ciudad. Entonces, el atributo de la ciudad porque sabes que vas a buscar en el atributo de la ciudad. Dices, quiero indexar ese atributo y de esa manera NCache lo indexará.
Razón 3: código del lado del servidor
La razón número tres es que con NCache en realidad puedes escribir código del lado del servidor. Entonces, ¿qué es ese código del lado del servidor y por qué es tan importante? Veamos eso. Es de lectura directa, escritura inmediata, escritura posterior y cargador de caché. Asi que, leer de parte a parte es esencialmente su código que implementa y se ejecuta en el servidor de caché. Entonces, déjame mostrarte cómo se ve una lectura completa. Entonces, por ejemplo, si implementa un IReadThruProvider de la interfaz del.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}Esta interfaz tiene tres métodos. Hay un método init que se llama cuando se inicia el caché y su propósito es conectar su controlador de lectura a su fuente de datos y hay un método llamado dispose que se llama cuando se detiene el caché y de esa manera puede desconectarse de su fuente de datos y hay un método de carga desde la fuente, que le pasa la clave y espera una salida de un elemento de caché, un objeto de elemento de caché de proveedor. Entonces, ahora puede usar la clave para determinar qué objeto necesita obtener de su base de datos. Entonces, la clave, como dije, podría ser cliente, ID de cliente 1000. Entonces, le dice que el tipo de objeto es cliente, la clave es ID de cliente y el valor es 1000. Entonces, si usa formatos como esos, entonces puede, en base a eso, puede seguir adelante y obtener su código de acceso a datos.
Por lo tanto, este controlador de lectura completa en realidad se ejecuta en los servidores de caché. Entonces, en realidad implementa este código en todos los servidores de caché. En caso de NCache es bastante fluido. Puedes hacerlo a través de un NCache herramienta de administrador. Entonces, implementa ese controlador de lectura directa en los servidores de caché y el caché llama a ese controlador de lectura directa. Digamos que su aplicación hace el caché.Obtener y ese elemento no está en el caché. NCache llama a su controlador de lectura. Su controlador de lectura va a su base de datos, obtiene ese elemento, se lo devuelve a NCache. NCache lo pone en el caché y luego lo devuelve a la aplicación. Entonces, la aplicación se siente como si los datos estuvieran siempre en el caché. Entonces, incluso si no está en el caché, el caché tiene la capacidad de ir y obtener los datos de su base de datos. Ese es el primer beneficio de la lectura.
El segundo beneficio de la lectura completa es que cuando ocurren los vencimientos. Digamos que tenías una caducidad absoluta. Dijiste que caducara este elemento dentro de 5 minutos o dentro de 2 horas, en ese momento, en lugar de eliminar ese elemento del caché, puedes decir NCache para volver a cargar ese elemento automáticamente llamando al controlador de lectura. Y recargar significa que ese elemento nunca se elimina del caché. Solo se actualiza y esto es realmente importante porque muchas de las tablas de búsqueda de referencia tienen muchas transacciones solo leyendo esos datos y si esos datos se eliminan incluso por un breve período de tiempo, muchas transacciones contra la base de datos se creará para obtener esos datos, simultáneamente. Entonces, si pudiera actualizarlo en el caché, entonces es mucho mejor. Entonces, ese es un caso de uso.
El segundo caso de uso es con la sincronización de bases de datos. Entonces, cuando ocurre la sincronización de la base de datos y se elimina ese elemento, en lugar de eliminarlo, ¿por qué no volver a cargarlo desde la base de datos y eso es lo que sucede? NCache voluntad. Puedes configurar NCache, de modo que cuando se activa la sincronización de la base de datos, el NCache en lugar de eliminar ese elemento del caché, llamará a su controlador de lectura para ir y recargar una nueva copia. Nuevamente, de la misma manera que el vencimiento, ese artículo nunca se elimina. Nunca se elimina del caché. Por lo tanto, la lectura es una característica realmente poderosa.
Otro beneficio de la lectura directa es que simplifica sus aplicaciones, porque está moviendo más y más si tiene código persistente en el nivel de almacenamiento en caché y si tiene varias aplicaciones que acceden a los mismos datos, todo lo que tienen que hacer es hacer un caché.Obtener. La caché.Obtener es una llamada muy simple y luego hacer un tipo de codificación ADO.NET adecuado.
Por lo tanto, la lectura simplifica el código de su aplicación. También se asegura de que el caché siempre tenga los datos. Recarga automáticamente en vencimientos y sincronizaciones de bases de datos.
La siguiente característica es la escritura simultánea. La escritura simultánea funciona igual que la lectura simultánea, excepto que es para actualizar. Déjame mostrarte cómo se ve la escritura directa. Entonces, esto fue una lectura completa. Déjame ir a escribir. Por lo tanto, implementa un controlador de escritura simultánea. De nuevo, tienes un método init. Tiene un método de eliminación, al igual que la lectura completa, pero ahora tiene un método de escritura en la fuente de datos y tiene un método de escritura masiva en la fuente de datos. Entonces, esto es algo que es diferente de la lectura completa.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Entonces, en el caso de la escritura simultánea, obtienes el objeto y la operación también, y esta operación podría ser Agregar, podría ser una Actualización o podría ser una Eliminación, ¿verdad? Porque podrías hacer un caché.Agregar, caché.Insertar, caché.Eliminar, y todo eso dará como resultado que se realice una llamada de escritura simultánea. Esto ahora puede ir y actualizar los datos en la base de datos.
Del mismo modo, si realiza una operación masiva, una actualización masiva, también se puede realizar una actualización masiva de la base de datos. Por lo tanto, la escritura simultánea también tiene los mismos beneficios que la lectura simultánea de que puede simplificar la aplicación porque mueve cada vez más código de persistencia al nivel de almacenamiento en caché.
Pero también hay una función de escritura posterior que es una variación de la escritura simultánea. Básicamente, con la escritura en segundo plano, actualiza el caché y el caché luego actualiza su fuente de datos de forma asíncrona. Básicamente, lo actualiza más tarde. Por lo tanto, su aplicación no tiene que esperar.
Write-behind realmente acelera su aplicación. Porque, ya sabes, las actualizaciones de la base de datos no son tan rápidas como las actualizaciones del caché. Entonces, ya sabes, puedes usar una escritura inmediata con una función de escritura diferida y la memoria caché se actualiza de inmediato. Su aplicación retrocede y hace lo suyo y luego se llama a la escritura simultánea y actualiza la base de datos y, por supuesto, si la actualización de la base de datos falla, se notifica a la aplicación.
Por lo tanto, cada vez que se crea una cola, existe el riesgo de que, si ese servidor deja de funcionar, esa cola se pierda. Bueno, en caso de NCache la cola de escritura diferida también se replica en más de un servidor y, de esa manera, si algún servidor de caché deja de funcionar, la cola de escritura diferida no se pierde. Así es como NCache asegura una alta disponibilidad. Por lo tanto, la escritura simultánea y la escritura diferida son funciones muy potentes. Simplifican el código de la aplicación y también, en caso de escritura posterior, aceleran la aplicación porque no es necesario esperar a que se actualice la base de datos.
La tercera característica es el cargador de caché. Hay una gran cantidad de datos que preferiría precargar en el caché, para que sus aplicaciones no tengan que ir a la base de datos. Si no tiene una función de cargador de caché, ahora debe escribir ese código. Bueno, no solo tienes que escribir ese código, también tienes que ejecutarlo en alguna parte como un proceso. Es la ejecución como un proceso que realmente se vuelve más complicado. Entonces, en el caso de un cargador de caché, simplemente registre su caché. Implementa una interfaz de cargador de caché, registra su código con NCache, NCache llama a su código cada vez que se inicia el caché, y de esa manera puede asegurarse de que el caché siempre esté precargado con esa cantidad de datos.
Por lo tanto, estas tres funciones: lectura directa, escritura directa, escritura diferida y cargador en caché, son funciones muy poderosas que solo NCache tiene. Redis no tiene tales características. Entonces, en caso de Redis pierdes toda esta capacidad que NCache dispone lo contrario.
Motivo 4: caché del cliente (caché cercano)
La razón número cuatro es Caché de cliente. El caché del cliente es una característica muy poderosa. Es realmente, es un caché local que se encuentra en la caja del servidor de aplicaciones, pero no es un caché aislado. Es local para su aplicación. Puede ser en proceso. Por lo tanto, este caché de cliente podría ser objetos guardados en su montón y en caso de NCache si elige la opción In-Proc que NCache mantiene la forma de datos y objetos. No en forma serializada, en la memoria caché del cliente. En el caché agrupado lo mantiene en forma serializada. Pero, en el caché del cliente lo mantiene en forma de objeto. ¿Por qué? Entonces, cada vez que lo busca, no tiene que deserializarlo en un objeto. Por lo tanto, acelera las búsquedas o las obtiene mucho más.
Un caché de cliente es una característica muy poderosa. Es un caché encima de un caché. Entonces, una de las cosas que pierde cuando pasa de un caché In-Proc independiente a un caché distribuido es que en un caché distribuido el caché mantiene los datos en un proceso separado, incluso en un servidor separado y hay un interproceso comunicación en curso, hay una serialización y deserialización en curso y eso ralentiza su rendimiento. Por lo tanto, en comparación con un In-Proc, el caché de forma de objeto, un caché distribuido es al menos diez veces más lento. Entonces, con un caché de cliente obtienes lo mejor de ambos mundos. Porque, si no tiene el caché del cliente, si solo tiene un caché aislado independiente, entonces hay muchos otros problemas sobre el tamaño del caché, ¿qué pasa si ese proceso falla? Luego pierde el caché y cómo mantiene el caché sincronizado con los cambios en varios servidores. Todos estos problemas son abordados por NCache en su caché de cliente.
Por lo tanto, obtiene el beneficio de ese caché In-Proc independiente pero está conectado al clúster de almacenamiento en caché. Por lo tanto, lo que sea que se mantenga en la memoria caché de este cliente, también se encuentra en la memoria caché agrupada y si alguno de los clientes lo actualiza aquí, el nivel de almacenamiento en caché notifica a la memoria caché del cliente. Para que pueda ir y actualizarse, inmediatamente. Entonces, así es como se asegura o tiene la seguridad de que la caché de su cliente siempre estará sincronizada con el nivel de almacenamiento en caché que luego se sincroniza con la base de datos.
Entonces, en caso de NCache un caché de cliente es algo que simplemente se conecta sin ninguna programación adicional. Realiza las llamadas a la API como si estuviera hablando con el nivel de almacenamiento en caché y el caché del cliente simplemente se conecta a un cambio de configuración y un caché del cliente le brinda un rendimiento 10 veces más rápido. Esta es una característica que Redis no tiene. Entonces, a pesar de todas las afirmaciones de rendimiento de que Redis tiene, ya sabes, son un producto rápido, pero también lo es NCache. Asi que, NCache está cabeza a cabeza en el rendimiento con Redis sin la caché del cliente. Pero cuando activas la memoria caché del cliente, NCache es 10 veces más rápido. Entonces, ese es el beneficio real de usar un caché de cliente. Entonces, esta es la razón número cuatro para usar NCache Más de Redis.
Motivo 5: compatibilidad con varios centros de datos
La razón número cinco es que NCache proporciona soporte para múltiples centros de datos. Ya sabe, en estos días, si tiene una aplicación de alto tráfico, es muy probable que ya la esté ejecutando en varios centros de datos, ya sea para DR de recuperación ante desastres o para dos centros de datos activo-activo para balanceo de carga o una combinación de DR y balanceo de carga. , ya sabes, o tal vez su equilibrio de carga geográfica. Entonces, ya sabes, puedes tener un centro de datos en Londres y Nueva York o Tokio o algo así para atender el tráfico regional. Siempre que tenga varios centros de datos, las bases de datos proporcionan replicación porque sin eso no podría tener varios centros de datos. Porque sus datos son los mismos en varios centros de datos. Si los datos no eran los mismos, entonces, ya sabes, son separados, no hay problema, pero en muchos casos los datos son los mismos y no solo eso, sino que también desea poder descargar parte del tráfico de uno. centro de datos al otro de manera transparente. Entonces, si tiene la base de datos que se replica en los centros de datos, ¿por qué no el caché? Redis no proporciona tales características, NCache proporciona funciones muy potentes.
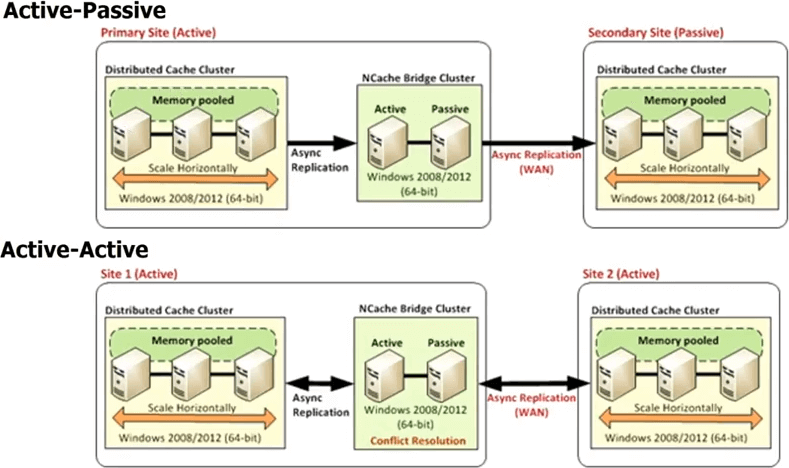
Entonces, en caso de NCache todos los centros de datos van a tener su propio clúster de caché, pero hay un topología de puente entre. Ese puente esencialmente conecta los clústeres de caché en cada centro de datos, para que pueda replicar de forma asíncrona. Entonces, puede tener un puente activo-pasivo, donde este es un centro de datos activo, este es pasivo. También puede tener un puente activo-activo y también estamos lanzando más de dos configuraciones de centro de datos activo-activo o activo-pasivo, donde puede tener, digamos, tres o cuatro centros de datos y el caché se replicará en todos ellos. ya sea de forma activa-activa o de forma activa-pasiva. En un activo-activo, debido a que las actualizaciones se realizan de forma asíncrona o la replicación se ha realizado de forma asíncrona, existe la posibilidad de un conflicto de que el mismo elemento se actualizó en ambos centros de datos.
¿Entonces NCache proporciona dos mecanismos diferentes para manejar esa resolución de conflicto. Uno se llama la última actualización gana. Donde el elemento que se actualizó por última vez, se aplica a ambos lugares. Entonces, digamos que actualiza un elemento aquí, otro usuario actualiza el elemento aquí. Ambos ahora para comenzar a propagarse al otro caché. Entonces, cuando llegan al puente, el puente se da cuenta de que se han actualizado en ambos lugares. Entonces, luego verifica la marca de tiempo y, cualquiera que sea la marca de tiempo que fue la última, aplica esa actualización a la otra ubicación y descarta la actualización que realizó la otra ubicación. Entonces, así es como ocurre la última actualización activa-activa que gana la resolución de conflictos. Si eso no es suficiente para usted, puede implementar un controlador de resolución de conflictos. Ese es tu código. Por lo tanto, el puente en realidad, en caso de conflicto, llamará a su código, pasará ambas copias de los objetos, para que pueda realizar un análisis basado en el contenido y luego, en función de ese análisis, puede determinar qué objeto es más apropiado para actualizar, para aplicarse a ambos centros de datos. La misma regla se aplica si tiene incluso más de dos centros de datos.
Por lo tanto, una compatibilidad con varios centros de datos es una característica muy poderosa NCache te da fuera de la caja. una vez que compras NCache, está todo ahí, Redis no lo hace y si planea tener varios centros de datos o incluso si solo quiere tener la flexibilidad, incluso si no tiene varios centros de datos hoy pero quiere tener la flexibilidad de poder ir a varios centros de datos, ¿podría comprar una base de datos hoy que no admita la replicación? Probablemente no lo haría, incluso si solo tiene un centro de datos. Entonces, ¿por qué optar por la caché que no es compatible con la replicación WAN? Entonces, esta es una característica muy poderosa de NCache.
Entonces, hasta ahora hemos hablado principalmente de las características que debe tener un buen caché distribuido. NCache, ya sabes, brilla. Gana sin dudarlo Redis. Redis es un caché simple muy básico.
Motivo 6: plataforma y tecnología (para aplicaciones .NET)
.NET y Windows frente a Linux
La razón número seis es probablemente una de las más importantes para usted, que es la plataforma y la tecnología. Si tiene una aplicación .NET, ya sabe, preferiría tener la pila .NET completa. Estoy seguro de que le gustaría, no le gustaría mezclar .NET con Java o Windows con Linux, en la mayoría de los casos. En algunos casos, puede que sí, pero en la mayoría de los casos, las personas que están desarrollando aplicaciones .NET prefieren usar la plataforma Windows y prefieren que toda su pila sea .NET, si es posible. Bien, Redis no es un producto .NET. Es un producto basado en Linux que fue desarrollado en C/C++.

Déjame mostrarte un poco. Aquí esta la Redis labs website que es la empresa que fabrica Redis. Si vas a la página de descarga verás que ni siquiera te dan una opción de Windows. Entonces, a pesar de que Microsoft los eligió para Azure, no tienen ninguna intención de admitir Windows. Entonces, en cuanto Redis Labs está preocupado, Redis es solo para Linux. Microsoft Open Technology Group ha portado Redis a Windows. Entonces, hay una versión de Windows de Redis disponible. Es de código abierto y no es compatible, pero, ya sabes, tiene errores e es inestable y la prueba está en el pudín, pero Microsoft no lo usa en Azure. Entonces el Redis que usa en Azure es en realidad un sistema basado en Linux Redis y no la base de Windows. Entonces, si desea incorporar Redis en su pila de aplicaciones, va a mezclar aceite con agua, ya sabe. Considerando que, en caso de NCache todo es nativo .NET. Tienes Windows. Tienes 100 % .NET. NCache fue desarrollado en C Sharp (C#). Está certificado para Windows Server 2012 R2 y cada vez que sale una nueva versión del sistema operativo está certificado para eso. Ya sabes, muy pronto vamos a lanzar el ASP.NET Core apoyo. Entonces, tenemos un cliente .NET oficialmente. También tenemos un Cliente Java oficialmente. Entonces, creo que si usas NCache y otra vez NCache también es de código abierto. Entonces, si no tiene el dinero, vaya con la versión de código abierto de NCache. Pero, si su proyecto es importante, vaya con la versión Enterprise que le brinda más funciones y admite ambos. Pero, le recomiendo encarecidamente que utilice NCache si tiene una aplicación .NET para la combinación de .NET y Windows.
Soporte local
El segundo beneficio que NCache te da es, si no estás en la nube, digamos, no has decidido moverte a la nube, estás alojando tu propia aplicación, entonces, es esencialmente local. Entonces, está bien en su propio centro de datos Redis que está disponible por Microsoft está en Azure solamente. Entonces, cualquier cosa que sea local, entonces, hay un Redis que está disponible en las instalaciones por Redis Labs, pero eso es solo Linux y el único local en Windows es el código abierto, el que viene sin soporte y el que tiene errores e inestable y el que tiene tantos errores que Microsoft mismo no lo usa en Azure.

Considerando que, en caso de NCache puede continuar usando el código abierto que es gratuito, que por supuesto no es compatible, si no tiene el dinero. Pero, todo es .NET nativo o si tiene un proyecto que es importante para su negocio, entonces por el Edición Profesional que tiene más funciones y viene con soporte y es una licencia perpetua. Es bastante asequible, ya sabes, poseerlo y también te brindamos soporte las 24 horas del día, los 7 días de la semana en caso de que sea importante para ti.
Por lo tanto, es totalmente compatible en un entorno local. La mayoría de nuestros clientes que son clientes de alto nivel todavía usan NCache en una situación local. NCache lleva más de 10 años en el mercado. Entonces, es un producto realmente estable.
Soporte en la nube
En cuanto al soporte de la nube, Redis te da un modelo de servicio en la nube, que es Microsoft ha implementado un Redis Servicio. Bien, Redis service significa que no tiene acceso a los servidores de caché. Ya sabes, es una caja negra para ti. No hay código del lado del servidor. Por lo tanto, toda la lectura, la escritura simultánea, la escritura diferida, el cargador de caché, la dependencia personalizada y un montón de otras cosas, no se pueden hacer con Redis. Ya sabes, solo tienes la API de cliente básica y, como dije, ya sabes, en Azure, Microsoft te da la Redis como servicio.
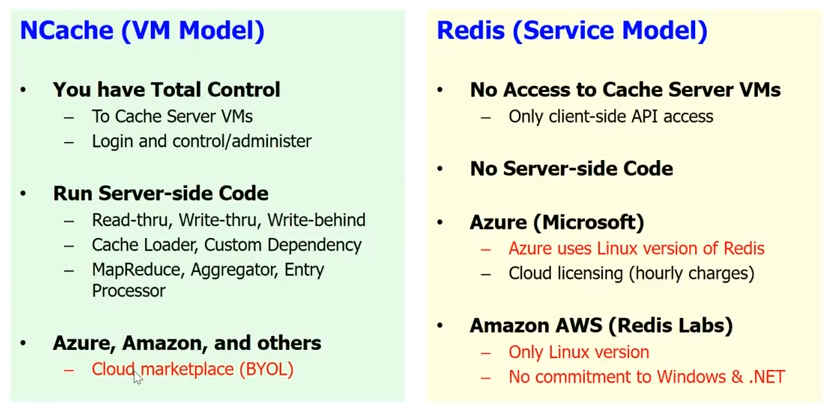
NCache, elegimos intencionalmente un modelo de máquina virtual. Porque queremos que el caché esté cerca de su aplicación y queremos que tenga un control total sobre el caché. Esto es algo muy importante porque tenemos muchos años de experiencia y sabemos que nuestros clientes son muy sensibles. Incluso un pequeño, digamos, si usa el Redis como un servicio y tienes que hacer un salto adicional para llegar al caché cada vez, eso acaba con el propósito de tener un caché. Considerando que, en caso de NCache puede tenerlo como parte de la máquina virtual. Puede tener el caché del cliente. Está realmente integrado en la implementación de su aplicación. Entonces, puedes hacer todo el código del lado del servidor.
NCache también se ejecuta en Azure. se ejecuta en Amazon AWS y también otros líderes plataformas en la nube en el modelo BYOL. Entonces, básicamente obtienes tu VM. En realidad, tienes la NCache en el mercado obtienes un NCache VM y nos compra la licencia y comienza a usar NCache.
Entonces, enfoques muy diferentes. Pero este es el enfoque que se pretende si su aplicación es realmente importante y desea controlar la aplicación, cada aspecto de ella y no tener que depender de otra persona que administre una parte de su infraestructura de nivel de aplicación. Una cosa es administrar las máquinas virtuales y el hardware subyacente, pero a medida que comienza a ascender más y más, pierde ese control y, por supuesto, en el caso del almacenamiento en caché, en el caso de NCache, no es solo ese control, sino también muchas características que perdería si optara por el modelo de servicio.
Entonces, la razón número 6 es la tecnología de plataforma. Para la aplicación .NET, NCache es una opción mucho más adecuada que Redis. no estoy diciendo Redis es una mala opción pero creo que para aplicaciones .NET NCache es una opción mucho más superior que Redis.
NCache Historia
Permítanme darles una breve historia de NCache. NCache ha existido desde mediados de 2005. Entonces, esos son los 11 años, ya sabes, NCache ha estado en el mercado. Es la caché .NET más antigua del mercado. Enero de 2015, nos convertimos en código abierto. Entonces, ahora tenemos la licencia Apache 2.0. Nuestro Edición Profesional está construido sobre nuestro código abierto. Entonces, el código abierto es una versión estable y confiable. Tiene muchas características. Por supuesto, Enterprise tiene más funciones, pero el código abierto es un producto muy útil. Lo básico es que, si no tienes el dinero, opta por el código abierto. Si su aplicación comercial es importante y tiene el presupuesto, opte por Enterprise Edition. Viene con soporte y también le brinda más funciones.
Tenemos cientos de clientes, prácticamente en todas las industrias posibles que necesitan almacenamiento en caché. Entonces, tenemos clientes de la industria financiera, tenemos Walmart, otra industria minorista. Tenemos líneas aéreas, tenemos la industria de seguros, automóviles/automóviles, en todas las industrias.
Entonces, ese es el final de mi charla. Continúe y descargue la Edición Enterprise de NCache. Déjame llevarte a nuestro sitio web. Así que, esencialmente, ve a la Página de descarga y le recomiendo encarecidamente que descargue la edición Enterprise. Incluso si terminas utilizando la edición de código abierto, descarga la edición Enterprise. Es una prueba de 30 días totalmente funcional, que podemos ampliar y jugar fácilmente.
Si desea continuar y descargar el código abierto, continúe y descargue el código abierto. También puedes ir a GitHub y puedes ver NCache en el GitHub. Póngase en contacto con nosotros si desea que hagamos como un demo personalizada. Tal vez hable sobre la arquitectura de su aplicación, responda sus preguntas. Muchas gracias por ver esta charla.