Poiché i dati sono stati coniati come "la nuova valuta", Apache Lucene ha guadagnato terreno come popolare motore di ricerca full-text, ampiamente utilizzato nelle applicazioni per incorporare la ricerca di testo flessibile su quantità significative di dati testuali. Lucene utilizza indicizzazione invertita, riducendo drasticamente i tempi di ricerca dei documenti relativi a un determinato termine.
NCache Dettagli Lucene distribuita NCache Docs
Tuttavia, è una soluzione autonoma che non si ridimensiona man mano che i dati crescono: è necessario ricostruire interi indici Lucene per cercare i dati, un'attività costosa e lenta, che diventa un collo di bottiglia delle prestazioni. Sebbene ora esistano alcune soluzioni basate su Java e REST per soddisfare la ricerca full-text scalabile, manca ancora una soluzione di ricerca full-text scalabile che possa naturalmente adattarsi allo stack .NET.
Utilizzo di Lucene distribuita con NCache per .NET
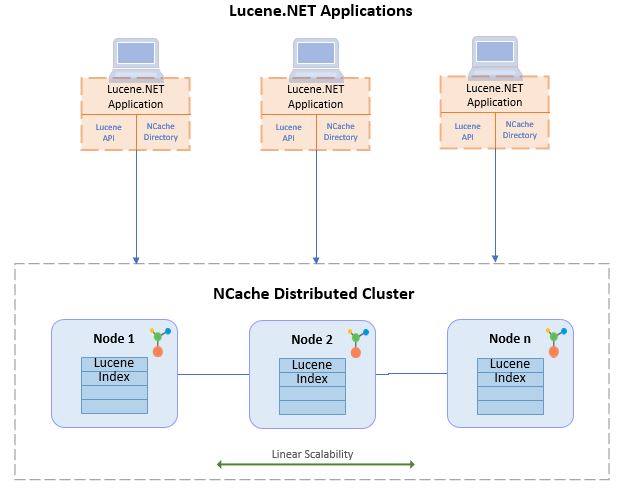
NCache, un potente e popolare archivio dati in memoria .NET, ha implementato l'API Lucene.NET nativa sulla sua architettura distribuita. NCache.
NCache utilizza anche questo Lucene.NET per creare indici in un ambiente dinamicamente scalabile per consentire ricerche full-text distribuite. I risultati di queste ricerche si uniscono prima di essere rispediti alla tua applicazione.
NCache Dettagli Funzionamento di Lucene Distribuita Componenti e panoramica di Lucene
Questo migliora Lucene standalone in una soluzione di ricerca full-text veloce e linearmente scalabile.
NCache Dettagli Lucene distribuito per la ricerca aziendale Lucene distribuita
Utilizzo di Lucene nelle app .NET
Consideriamo un sito di e-commerce che contiene informazioni per migliaia di prodotti, ordini e dettagli dei clienti. Pertanto, l'indicizzazione di tutti gli attributi, in particolare i campi non testuali (che non vengono utilizzati durante la ricerca), non è un approccio saggio, in quanto esaurisce la memoria cache.
Ad esempio, il nostro documento per un prodotto è simile al seguente:
|
1 2 3 4 5 6 7 8 9 |
{ “ID”: “ABC34”, “Name”: “Tupperware”, “Description”: “Microwaveable, dishwasher-friendly, reusable Tupperware in three sizes”, “RetailPrice”: 15.00, “Discount”: 3.00 } |
Ora sappiamo che i nostri clienti eseguono ricerche full-text sulla descrizione del prodotto, che è un campo del documento. Quindi, cosa succede se indicizziamo solo quei campi che possono essere cercati e abbiamo una chiave che fa riferimento al documento corrispondente nell'archivio di persistenza, ad esempio database o file system? In questo modo, una volta che si esegue una query per un tipo specifico di prodotto, diciamo "Tupperware lavabile in lavastoviglie", tutti i prodotti con una descrizione che corrisponde a questi termini appariranno con il loro ID prodotto come chiave del documento e l'intero documento può quindi essere recuperato da l'indice persistente.
Per utilizzare Lucene distribuito nelle applicazioni esistenti, è sufficiente specificare NCacheDirectory quando si apre una directory. Ciò richiede il NCache nome della cache e il nome dell'indice. Il seguente frammento di codice apre una directory su una cache LuceneCache in NCache e un indice denominato ProductIndex.
|
1 2 3 4 5 6 7 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string index = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, index); |
Lucene fornisce un linguaggio di query completo, che interpreta una determinata stringa in una query Lucene. Questo può essere fatto su un termine, più termini, caratteri jolly o anche parole sfocate. Per saperne di più sulle query Lucene, leggi Lucene Query Documenti.
Il seguente frammento di codice crea un IndexReader nella directory, che viene utilizzato da IndexSearcher. I dati vengono analizzati e tokenizzati sulla base di StandardAnalyzer. I primi 50 riscontri del risultato vengono restituiti all'applicazione. Si noti che l'analizzatore deve essere lo stesso utilizzato durante la creazione dell'indice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// The 'applyAllDeletes' is true so all enqueued deletes are applied on writer IndexReader reader = DirectoryReader.Open(indexWriter, true); // A searcher is opened to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify the searchTerm, fieldName and analyzer string searchTerm = "Beverages"; string fieldName = "Category"; // Note that the analyzer should be same as the one used during index creation Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); // Create a query parser to parse the query QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, fieldName, analyzer); Query query = parser.Parse(searchTerm); // Returns the top 50 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 50).ScoreDocs; reader.Dispose(); |
Carica dati per creare un indice distribuito
Con Lucene puoi creare indici e caricarvi i dati secondo necessità. Gli indici richiedono un analizzatore, che analizzi e tokenizzi i dati in base alle tue esigenze: potrebbero essere spazi bianchi, non lettere, segni di punteggiatura e così via. Dopo aver creato uno scrittore per il tuo indice Lucene, puoi creare documenti e aggiungervi campi. Questo documento viene quindi indicizzato NCache come indice distribuito dopo aver chiamato Commit(). Per maggiori dettagli sugli analizzatori Lucene, dai un'occhiata a Documenti dell'analizzatore Lucene.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string indexPath = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, indexPath); // The same analyzer is used as for the reader Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); // Create indexWriter on NCache directory IndexWriter indexWriter = new IndexWriter(directory, config); Product[] products = FetchProductsToIndex(); foreach (var product in products) { Document doc = new Document { new StoredField("id", product.ID), new TextField("name", product.Name, Field.Store.YES), new TextField("description", product.Description, Field.Store.YES), new StringField("category", product.Category, Field.Store.No), new StoredField("retail_price", product.RetailPrice), }; indexWriter.AddDocument(doc); } indexWriter.Commit(); </code><br /><br /><a href="/ncache/">NCache Details</a> <a href="/resources/docs/ncache/prog-guide/lucene-ncache.html#working-of-distributed-lucene">Working of Distributed Lucene</a> <a href="/blogs/geospatial-indexes-for-distributed-lucene-with-ncache/">GeoSpatial Indexes for Distributed Lucene</a> |
Perché NCache per Lucene Distribuita?
utilizzando NCache per Lucene distribuito ti offre i seguenti vantaggi:
- Estremamente veloce e linearmente scalabile: NCache è un archivio dati distribuito in memoria, quindi building distribuito Lucene inoltre fornisce le stesse prestazioni ottimali per le tue ricerche full-text. Inoltre, a causa di NCachedell'architettura distribuita, l'indice Lucene è partizionato su tutti i server del cluster. Ciò lo rende scalabile poiché puoi aggiungere più server in movimento man mano che il carico di dati aumenta e gli indici Lucene vengono automaticamente redistributato senza alcun intervento da parte del cliente.
- Replica dei dati per affidabilità e disponibilità elevata: Con NCacheNella topologia Partition-of-Replica di , l'indice Lucene non è solo partizionato su tutti i server, ma ogni partizione viene anche replicata su un altro server del cluster. Quindi, se un server si arresta, la replica della partizione serve tutte le query per t/resources/docs/ncache/admin-guide/distributed-lucene-counters.htmlhat index, garantendo affidabilità. Allo stesso modo, se un nodo del server si interrompe, NCache si autoguarisce dinamicamente riadattando i dati all'interno dei nodi rimanenti, senza tempi di inattività o impatto sull'indice Lucene, garantendo un'elevata disponibilità.
Conclusione
In sintesi, la ricerca full-text è ormai diventata fondamentale in quasi tutti i business, grazie al potente motore di ricerca Lucene. Ma man mano che i dati crescono, la ricostruzione degli indici può causare più danni che guadagni e questo dove una soluzione .NET distribuita in memoria come NCache interviene. Tutto ciò che richiede è una modifica del codice di una riga nella tua applicazione Lucene esistente e voilà, hai il meglio di entrambi i mondi come meccanismo di ricerca full-text distribuito in memoria.




