次のような分散キャッシュを使用する e コマース ビジネスがあるとします。 NCache 応答時間を短縮します。 ホリデー シーズン中、キャッシュ クラスターは、数千の接続されたクライアントにサービスを提供することを期待しています。 しかし、代わりに、カスタマー サポート チームには、ウェブサイトのダウンタイムやユーザー エクスペリエンスの低下に関する苦情が殺到しています。 何が悪かったのか? まあ、それは簡単です。 負荷のピーク時にキャッシュを監視できませんでした。
なぜそれが重要なのですか? 本番中にキャッシュを監視すると、問題が発生する前に警告サインを特定するのに役立ちます。 時間をかけてこれを行うことで、ビジネスで潜在的なネットワークの中断やメモリのオーバーヘッドなどが発生するのを防ぐことができます。
NCache 詳細 ダウンロード NCache エディションの比較
豊富な監視ツールセット NCache
幸いなことに、 NCache には、キャッシュの監視に役立つ多数のツールが付属しています。 これらには、次のすべてが含まれます。
NCache Webマネージャ
Webマネージャ は、キャッシュを構成し、その統計を表示するための Web ベースの管理ツールです。 このツールは、 NCache ノードを追加または削除したり、セキュリティを構成したりして、キャッシュを管理できます。
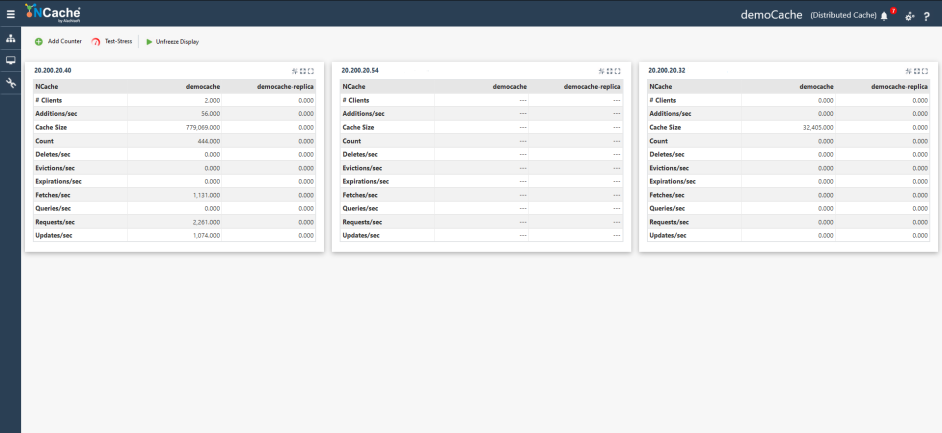
図1: NCache Web マネージャー クラスター統計
NCache Webモニター
Webモニター は Web ベースの監視ツールで、分散キャッシュと remote client実行します。 これには、ノードごとに監視するための単純なドラッグ アンド ドロップ カウンターを提供する既存のダッシュボードが含まれています。 関心のある指標に従って、カスタム ダッシュボードを設計することもできます。
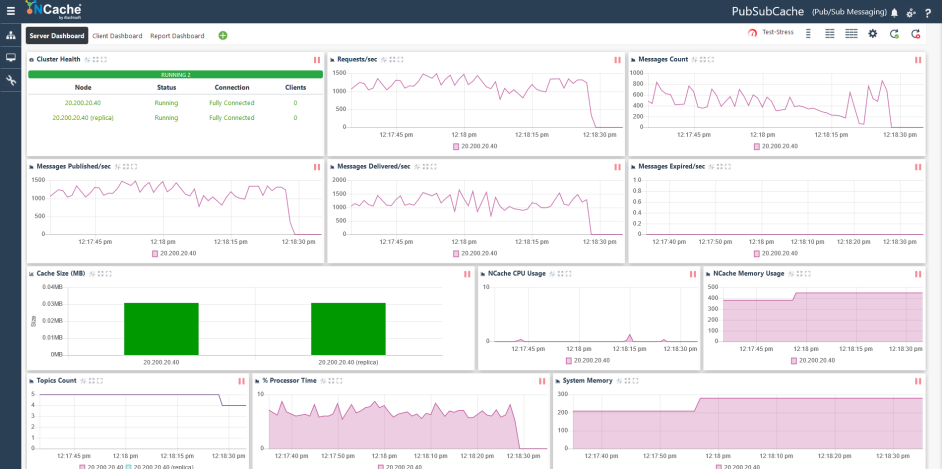
図2: NCache Webモニター
NCache Windows PowerShellの
この PowerShellの は、Windows PowerShell を使用してサーバーとクライアントの統計を監視できる CLI ツールです。 カウンターのリストが .CSV 形式で提供されます。
NCache ログ
ボーマン ログ すべてのキャッシュ アクティビティをログに記録し、深刻になる前に問題を検出したり、特定の環境でのキャッシュの動作を観察したりするために不可欠です。 デフォルトでは、すべてのキャッシュ/ブリッジ アクティビティが各サーバー ノードのファイルに記録されます。 NCache また、読みやすくするためにログを整理するための洗練されたログ ビューアーも提供します。
Windows PerfMon ツール
これらのツールは、同様に貴重なリソースです。 の Windowsパフォーマンスモニター いろいろアクセスできる NCache Perfmon カウンター。 そのため、PerfMon 互換ツールを使用してキャッシュ パフォーマンスを監視することもできます。 このカウンター情報は、プロセスの制限を判断し、必要に応じて環境とアプリケーションを微調整するのに役立ちます。
NCache イベントログ NCache
これらのログは、重大度に従ってイベントをログに記録します。 Windowsイベントログ (すべてのセキュリティ、アプリケーション、およびシステム アプリケーションの詳細な記録を提供します)。 これらのログにより、キャッシュ クラスター内のエラーを迅速に診断できます。
サードパーティツール
グラファナ & プロメテウス キャッシュ クラスターを監視するもう XNUMX つの優れた方法です。 Prometheus は、収集された NCache メトリクスであり、Grafana はそれをデータ ソースとして使用して、データを人間が判読できるグラフとして表示します。
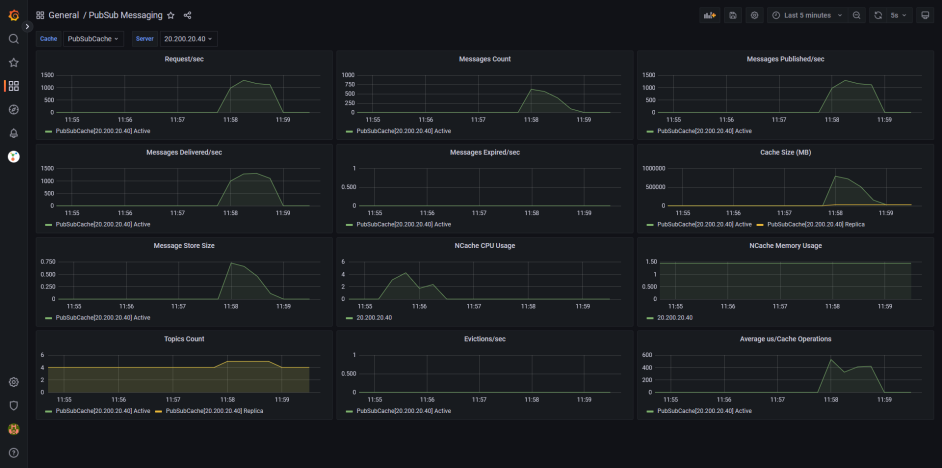
図 3: の Grafana ダッシュボード NCache Pub / Subメッセージング
NCache 詳細 トラブルシューティング NCache 監視 キャッシュを監視する
本番前のベースライン パフォーマンス テスト
本番環境でキャッシュの監視を開始する前に、本番前のベースライン テストをお勧めします (特にライブ環境の構成では)。 このようなテストの主な目的は、キャッシュの許容可能なパフォーマンスしきい値です。 このテストは、本番環境が終了している場合、ステージング中にも実行できます。
このベースライン パフォーマンス テストでは、このしきい値に対するキャッシュ パフォーマンスを監視でき、最適なパフォーマンスがわかっている場合は特定の問題を診断するのに役立ちます。 たとえば、メモリ使用率がベースライン マークより一貫して高い場合は、さらにサーバーを追加することを選択できます。
1. アプリケーションのパフォーマンスのベースライン
次の点を考慮して、環境をテストするだけで済みます。
アプリケーション層のテスト - これは、 NCache そして、あなたのアプリケーションのパフォーマンスのみです。 たとえば、Web アプリの場合、ページ リクエストの応答時間をテストする必要があります。
データベース層のテスト (また NCache 独立) には、クエリに対するデータベースの応答時間、ネットワーク オーバーヘッド、および大規模なデータベース セットのパフォーマンスのチェックが含まれます。
2. NCache パフォーマンスのベースライン
だから、どこに NCache これに収まる? 為に NCache、リクエスト/秒、平均時間/操作、オブジェクト サイズ、およびメモリ/CPU を考慮する必要があります。 さらに、イベント ログを監視して、正常な動作状態のクラスターのイベントを理解し、運用環境に移行するときに比較するための参照として保持できます。 比較のために、これらのベースラインの詳細を監視チームと共有することもできます。
それを覚えておいてください NCache パフォーマンスがアプリケーションのパフォーマンスに影響を与える可能性があり、異常が発生することは避けられません。 たとえば、負荷が増加すると、クラスター内のすべてのサーバー ノードの CPU 消費量が増加します。 この時点では何も失敗していないため、これは完全に正常です。 クラスターに別のサーバーを追加するだけで、すべてのサーバーで負荷を共有できます。
NCache 詳細 パフォーマンスベンチマーク シミュレート NCache 使用法
モニター NCache 本番環境でのパフォーマンス
監視 NCache 本番環境でのクラスターの健全性
分散キャッシュ クラスター内の多数のクライアントを処理する場合、言うまでもなく、ピーク時の負荷の下でクライアントが正常に調整されていることを確認する必要があります。 の NCache サーバーおよびクライアント アプリケーションの状態は、次の方法で監視できます。 NCache キャッシュ カウンターを通じて正常なアクティビティを表示するツール。
通常、データセンターには優れたネットワークがありますが、お客様の環境で、ソケットが破損したり、ネットワークが中断されたりする可能性があることに気付きました。 この種のシナリオでは、接続全体が切断されなくても通信が中断されるため、遅延が発生します。 したがって、ネットワークが部分的に接続されてスプリットブレインが発生し、クライアント接続が中断されないように監視する必要があります。
NCache これを解決するために自動回復メカニズムを開始しますが、これはコストのかかる作業です。 したがって、クラスターの状態を監視する必要があります。
使い方 NCache Web モニターを使用すると、キャッシュの状態に関するさまざまなメトリックを監視できます。
1- クラスターの健全性
あなたが見ることができます クラスタ内の各サーバー ノードのステータス、他のノードとの接続、および接続されているクライアントの数が一目でわかります。
2- Windows イベント ログ
簡単にチェックできます イベント ログのエラー、各イベントに対する詳細なメッセージも表示されます。 そのため、部分的に接続されたクラスターの場合、それが原因であるかどうかを簡単に診断できます。 スプリットブレイン またはその他の理由で、イベント ログ ウィンドウに記録されます。
3- API ログ
また選ぶことができます API 呼び出しのログ サーバー ノードからクライアントへ – ただし、これはメモリ カウンターです。
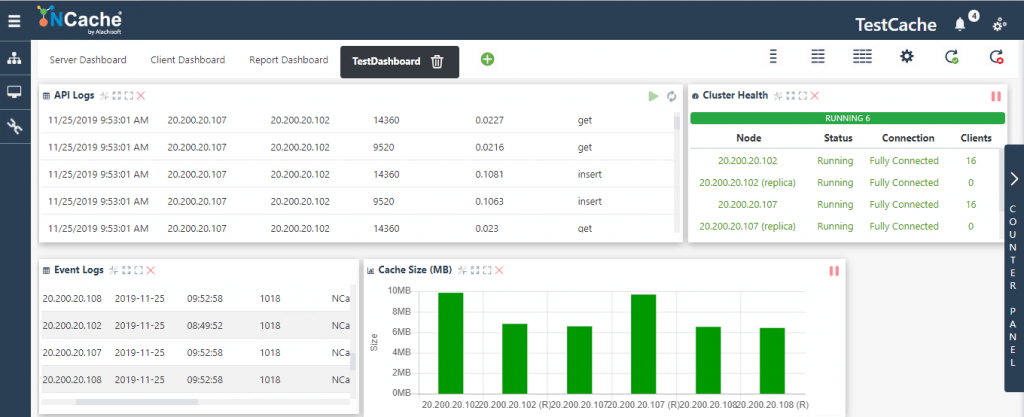
図 4: クラスターの健全性監視 NCache
4. システムリソース
クラスターが正常かどうかを確認するには、CPU 使用率、メモリ スパイク、およびネットワーク使用率も監視する必要があります。この監視により、アプリケーションが不足に直面することはありません。 たとえば、CPU 使用率が常に上昇している場合は、CPU リソースを増やすことを選択できます。
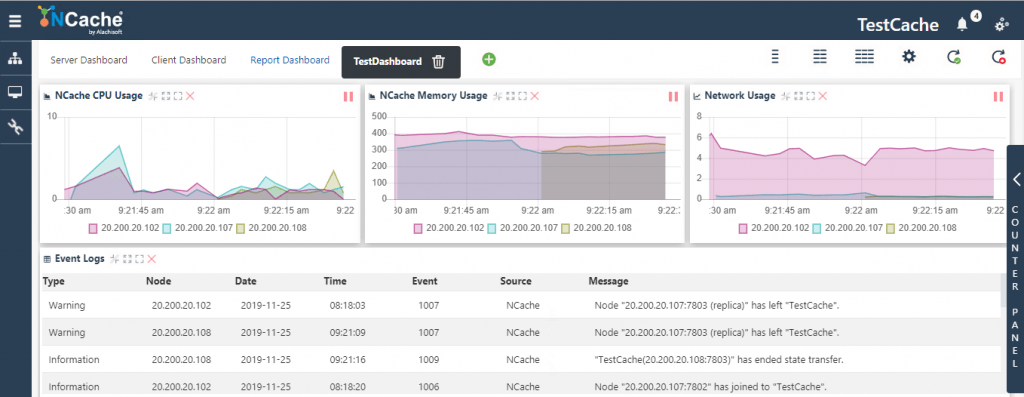
図 5: システムの健全性監視 NCache
5. NCache アラート
NCache また、提供しています メカニズム ノードの開始/停止や状態転送の開始などの特定のイベントでアラートを送信します。 このような通知は指定された電子メールに送信されるため、予期しないアクティビティの通知をどこでも受け取ることができます。 詳細については、 NCache ドキュメント。 これらとは別に、値が事前構成されたしきい値を超えると、CPU 使用率、キュー サイズ、メモリ、ネットワーク帯域幅、および XNUMX 秒あたりの要求数に関するキャッシュ ヘルス アラートも alerts.xml に記録されます。
監視 NCache 本番環境での負荷/容量
このような監視では、キャッシュ クラスターの一般的なピーク負荷と、各サーバーで実行されるトランザクションを特定する必要があります。 流入が増加した場合、たとえば、年間セール中に、環境が不安定になったり、行動が不安定になる可能性があります。 このためには、各サーバーで XNUMX 秒あたりに行われているフェッチまたはリクエストの数を監視して、発生している可能性があるパフォーマンス関連の問題の根本原因分析を迅速に実行する必要があります。
負荷に対するスループットによって、容量を増やす必要があるかどうかが決まります。 負荷監視のベースライン テストを既に実行しており、統計でトランザクション数の一貫したスパイクが示されている場合は、スケールアップを選択できます。 これを行うには、CPU リソースを増やすか、キャッシュ サーバーを追加してスケールアウトします。 使用できるカウンターについては既に説明しました。
まとめ
NCache .NET と Java を 100% ネイティブにサポートする機能豊富な分散データ ストアです。 したがって、キャッシュ クラスターがトランザクションの多い運用環境で実行されている場合は、ノード、クラスター、およびクライアント接続を監視する必要があります。 これに加えて、メモリやネットワーク帯域幅などのキャッシュ リソースに注意する必要があります。 NCache には、クラスタ環境の監視を可能な限り便利にするための複数のツールとアラートが含まれています。
これにより、メトリクスの予期しないスパイクを説明できるだけでなく、パフォーマンス低下の原因を簡単に診断するのにも役立ちます。





