最新のアプリケーションは、大量のデータを処理および生成します。 単一の Web サーバー/データ ソースに障害が発生し、アプリケーションや貴重なデータが失われる可能性は、ソフトウェア開発者の間でよくある悪夢です。 ただし、すべてのサーバー ノードに同一のデータ コピーがあれば、高いデータ可用性を実現できます。つまり、クラスター内のいくつかのノードに障害が発生しても、データが失われることはありません。 しかし、データが大幅に拡大し始めるとどうなるでしょうか? このような場合、レプリケーションをダイヤルバックして、データのパーティション分割を開始する必要があります。
NCache 分散型のインメモリ キャッシング ソリューションであるため、データ集約型アプリケーションに高いスケーラビリティ、パフォーマンス、および可用性が提供されます。 POR (パーティション化されたレプリカ) トポロジを使用して、データを複数のチャンク (バケット) に分割し、それらを異なるパーティションに配置します。 読み取りと書き込みの負荷を均等に分散するために、データは複数のノードに分割されます。 これにより、データを分割することでスケーラビリティを実現する際の最初の問題が解決されますが、データを均等に分割するにはどうすればよいでしょうか。 このブログは、データ パーティショニングがどのように行われるかについて説明することを目的としています。 NCache.
均等なデータ分散のためのハッシュベースのパーティショニング
多くの場合、さまざまなアプリケーションがラウンドロビン戦略を採用して、データを異なるパーティションに割り当てます。 このアプローチは均一な分散を保証しますが、特定のデータ項目を見つけることに関しては課題があります。 アイテムの場所を追跡する方法がないと、データの検索と取得に時間がかかり、効果がなくなる可能性があります。
この問題を解決するには、 NCache 組み込む ハッシュベースのパーティショニング. データは多数のバケットに分割され、その後複数のパーティションに分散されます。 目標は、クラスター内のノード間でバケットを均等に分散して、パフォーマンスを最適化し、高可用性を確保することです。 これを達成するには、 NCache 各データ項目を項目のキーに基づいて特定のバケットにマップするハッシュ技術を採用しています。 ここで、バケットの所有者を特定するために、アイテムのキーにハッシュ関数を適用し、バケットの総数でそれを変更する必要があります。合計で 1000 個のバケットがあります。
分布図とは
コーディネーター サーバーは、バケットの分散を監視し、キーに基づいて各アイテムが特定のバケットに割り当てられるようにするため、分散キャッシュ クラスターに不可欠です。 これを実現するために、コーディネーター サーバーは 分布図 バケット配布を含め、クラスタ内の他のすべてのパーティションと、接続されているすべてのクライアントに配布します。
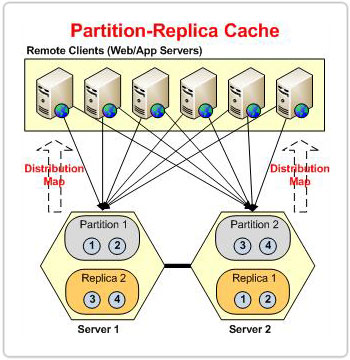
図 1: POR トポロジのディストリビューション マップに基づくパーティション
クラスター内のサーバーの数に関係なく、 NCache このメソッドを使用して、各アイテムに一貫したバケット アドレスが与えられていることを確認します。 これは、 分布図 クラスター内のサーバーの数が変わっても、一定のままです。 その結果、どの段階でバケットがあるパーティションから別のパーティションに移動しても、アイテムのバケット アドレスは変わりません。 これにより、データが損なわれないことが保証され、バケットの移動中にデータが失われることはありません。
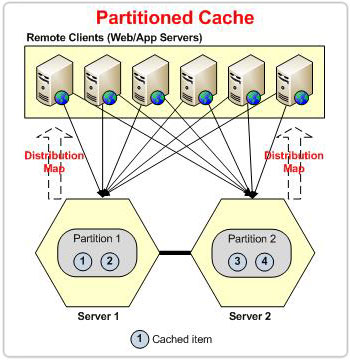
図 2: パーティション トポロジのディストリビューション マップに基づくパーティション
分割トポロジの場合、ノードがクラスターを離れるたびに、クラスターでデータが失われます。 離脱ノードが所有するバケットはすべて失われます。 ただし、POR の場合、レプリカは別のノードに存在します。 redis分布図に基づいて提供され、データの損失を防ぎます。
分布図に基づくデータ分布
によって提供される動的バケット分散戦略のおかげで、データはキャッシュ クラスター内のすべてのノードに均等に分散されます。 NCache. キャッシュ クラスターを開始すると、1000 個のバケットすべてがノードに割り当てられます。これにより、すべてのデータが XNUMX つのパーティションに格納されます。 最高のパフォーマンスと負荷分散を実現するために、クラスターにノードが追加されると、バケットはパーティション全体で均等に分割されます。
たとえば、1000 個のバケットは、500 番目のノードがクラスターに追加されたときに XNUMX つのパーティション間で均等に分割され、分割ごとに XNUMX 個のバケットが与えられます。 同様に、XNUMX 番目のノードがクラスターに入ると、バケットは redisこれにより、各パーティションに 333、333、および 334 のバケットが割り当てられます。
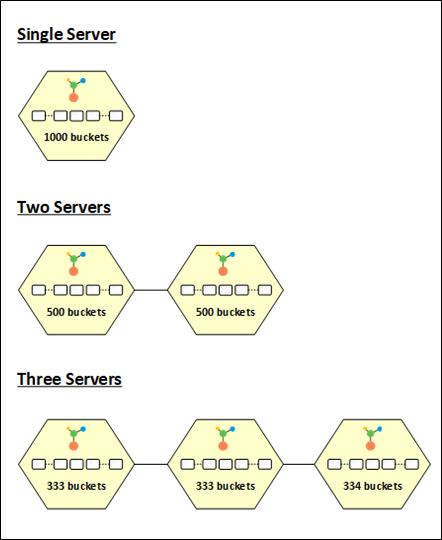
図3: NCache バケット配布
パーティションがクラスターを離れると、バケットの分散が再度変更されます。 たとえば、パーティションが 333 ノード クラスタを終了するときに、データの均等な分散を維持するために、そのパーティションに属する 334 または XNUMX バケットは残りの XNUMX つのノードに分散されます。 NCacheの状態転送メカニズムは、バケットの分散が変化するたびにノード間のデータのバランスを取り直すために作動し、データがバケットの分散に従って最適に分散されるようにします。 同様に、クライアントは、実行中のサーバー ノードとそれらのハッシュ ベースのディストリビューションについて通知するディストリビューション マップも受け取ります。
データ負荷分散
一方、 redisキャッシュ クラスタのノードの周囲にバケットをトリビュートし、 NCache 各パーティションが受信するデータの量が均等になるように、データ中心の戦略を採用しています。 これを実現するために、クラスタ内の各パーティションは、所有するバケットの統計をクラスタ内の他のパーティションと定期的に交換します。 これにより、バランスの取れた 分布図 これは、各パーティションが所有するデータの量を説明します。 NCache データのバランスを自動的にとる 各パーティションが均等にデータを受け取るようにします。 また、手動でデータのバランスを取ることもできます。 あなたはそれについてもっと読むことができます こちら.
まとめ
結論として、POR を使用してデータを分割します。 NCache アプリケーションの速度とスケーラビリティを向上させるための便利な手法です。 データが常に利用可能であることを保証し、データを小さなチャンクに分割して多数のキャッシュ ノードに分散させることで、パフォーマンスのボトルネックの可能性を減らすことができます。





