パーティションレプリカおよびパーティションキャッシュトポロジ
クラスターでは、すべてのサーバー ノードに同じデータのコピーがある場合、そのデータの可用性が高くなります。つまり、クラスターは、数回のノード障害が発生しても、データ損失が発生することなく生き残ることができます。ただし、これでは拡張性が得られません。データが膨大に増加し始めると、設計ではレプリケーションの範囲を減らし、データのパーティション分割を開始する必要があります。
パーティショニングとは、読み取りデータと書き込みデータの両方の読み込みが分散されるように、複数のノード間でデータを分散する必要があることを意味します。データが増加するにつれて、より多くのデータを保持するためにクラスターにサーバー ノードを追加できます。クラスター内の各サーバー ノードはパーティションと呼ばれます。
データをパーティション分割することでスケーラビリティを実現できますが、問題はそのデータがどのようにパーティション分割されるのかということです。 簡単な解決策は、ラウンドロビン方式でデータをパーティションに割り当てることかもしれませんが、特定のデータがストアに追加された後、どのようにしてそのデータを見つけるのでしょうか?
ラウンドロビンにより、データの場所を追跡できなくなります。データを均等に分散するだけでなく、データを迅速に検索できるように、データを分散するためのより良い方法が必要です。
Note
パーティショントポロジは以下でもサポートされています。 NCache Professional.
Note
PartitionedトポロジとPartition-Replicaトポロジの唯一の違いは、前者にはレプリカキャッシュがないため、データが失われる傾向があることです。
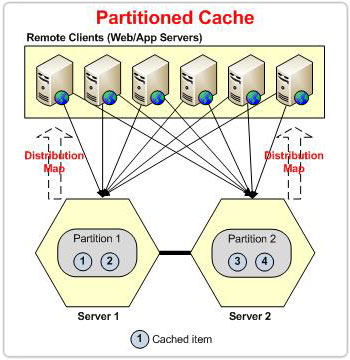
パーティションキャッシュのためのハッシュベースのデータパーティショニング
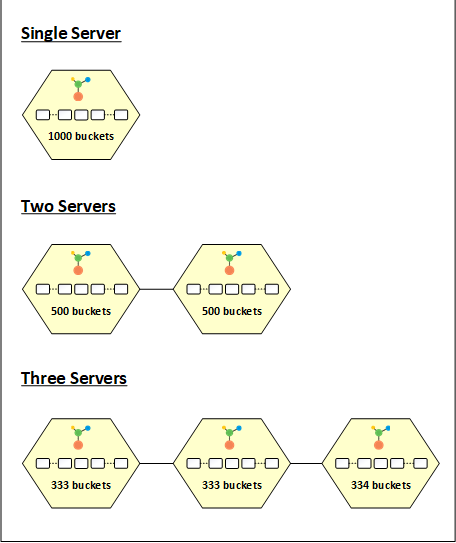
NCache データを複数のチャンクに分割し、これらのチャンクを異なるパーティションに配置します。 これらのチャンクはバケットと呼ばれます。 合計 1000 個のバケットがあり、クラスター内のノード間で均等に分割されます。 ここでの考え方は、アイテムのキーにハッシュ関数を適用し、合計バケット数 (この場合は 1000) でモード設定して、このデータの所有者バケットを取得することです。
分布図
クラスター内のコーディネーター サーバーは、バケットの分布を含むマップを生成する責任があります。 この地図を分布図と呼びます。 コーディネーター サーバーは、この分散マップをクラスター内の残りのパーティションおよび接続されているクライアントと共有します。 この方法では、クラスター内のサーバーの数に関係なく、アイテムに対して常に同じバケット アドレスが与えられます。 どの段階でもバケットがあるパーティションから別のパーティションに移動する可能性がありますが、アイテムのバケットは決して変更できません。 つまり、バケットが移動すると、そのすべてのデータも一緒に移動します。
分布図に従ったデータの分布
単一のパーティションでキャッシュクラスターを開始すると、1000個のバケットすべてがこのノードに割り当てられます。 つまり、すべてのデータがこのパーティションに送られます。 クラスタ内で別のノードを起動すると、バケットはそれぞれ500個のバケットを持つXNUMXつのパーティションに均等に分散されます。 同様に、クラスターにXNUMX番目のノードを追加すると、バケットは再び redis賛辞。 この場合、333つのノードにはそれぞれ333、334、およびXNUMXのバケットがあります。
同様に、パーティションがクラスターから離れると、バケットの分散が変わります。たとえば、パーティションが 333 ノードのクラスターから離れると、そのパーティションが所有する 334 または XNUMX のバケットは redis残りの 2 つのノード間でトリビュートされます。分布に変化があると常に、バケットの分布に従ってノード間のデータのバランスを再調整するための状態転送がトリガーされます。
データのランダムな配布
このパーティショニング方法により、かなりのランダム性が得られ、データがバケットとパーティション間で均等にパーティショニングされるようになります。 ただし、このパーティション分割方法では、どのデータをどのパーティションに割り当てるかを制御できなくなります。 ほとんどの場合、データがどこに行くかは気にしないでしょう。 ただし、場合によっては、関連データを同じ場所に配置したい場合もあります。 これには、キー全体ではなくキーの一部にハッシュ関数が適用されるロケーション アフィニティを使用できます。
データのバランスの取れた配布
バケットがあるときはいつでも redisノード間で賛辞、 NCache バケットが redis各パーティションが受け取るデータのサイズがほぼ同じになるようにトリビュートされます。各パーティションは、構成可能な間隔で、所有するバケットの統計をクラスター内の他のパーティションと共有します。これは、必要に応じて、各パーティションが取得するデータの観点から公平なバランスのとれた分散マップを生成するのに役立ちます。バランスは項目数ではなくデータのサイズに基づいて行われます。このバランスは通常、バケットの作成時に確保されます。 redisノードの離脱または参加の結果としての分布。
自動および手動のデータ ロード バランシング
ただし、クラスター内のXNUMXつ以上のパーティションが歪んでいて、残りのパーティションよりも多くの負荷を受け取っていることがわずかに見られる可能性があります。 この場合、特定のノードのデータのバランスを手動で調整して、そのノードのデータが各パーティションが受信するデータの平均サイズと等しくなるようにするオプションがあります。 次に、バックグラウンドで自動的にジョブを実行する「自動データ負荷分散」と呼ばれる機能もあります。 この機能はデフォルトで無効になっています。注意せずに使用すると、バケットが頻繁に発生する可能性があるためです。 redisトリビューション、したがって、パーティション間の不要な状態転送。
パーティションあたりのデータのサイズ
各パーティションが保持できるデータのサイズは、構成されたキャッシュ サイズと同じです。 たとえば、構成されたキャッシュ サイズが 2 GB で、クラスター サイズが 6 つのパーティションからなる場合、このクラスターのキャッシュ サイズの合計は XNUMX GB になります。
したがって、このトポロジでは、サーバー間で読み取りと書き込みの負荷を分散するだけでなく、クラスターに新しいサーバーを追加するたびに容量を増やします。
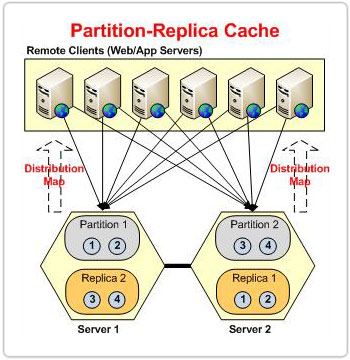
パーティション-レプリカ
これで、Partition-Replicaトポロジがトランザクションの負荷とストレージ容量をどのようにスケーリングするかについて説明しました。 高可用性をどのように処理するかについて話しましょう。 クラスタ内の各ノードには、レプリカと呼ばれるパッシブパーティションとして機能する別のパーティションのバックアップがあります。 ノードに障害が発生した場合、キャッシュクラスターは、失われたパーティションが所有するデータが引き続きレプリカで使用可能であることを認識しています。 そのため、失われたパーティションが所有するデータは引き続きこのレプリカを介してクラスターによって提供されるため、クライアントアプリケーションは引き続きスムーズに実行されます。
クライアントアプリケーションは、アクティブなパーティションとのみ直接通信します。 次に、各パーティションは、そのデータをそれぞれのレプリカに複製する責任があります。
このトポロジでのレプリケーションの程度は、 複製されたトポロジー、バックアップが 1 つあると、ノード障害が発生した場合でもデータが安全であることが少なくとも保証されます。ノード障害が同時に発生しない限り、このトポロジ内のデータは安全であり、ほとんどのシナリオをカバーします。
すべてのクラスターノードにはアクティブインスタンスとレプリカがあり、アクティブインスタンスとレプリカインスタンスの両方がすべてのクラスターノードの同じキャッシュプロセスに存在します。
すべてのキャッシュ ノードにレプリカ インスタンスが存在するため、アクティブなキャッシュ インスタンスと同じメモリ サイズが必要です。 これは、すべてのパーティション レプリカ キャッシュ ノードが、構成されたキャッシュ サイズに対して XNUMX 倍のメモリを必要とすることを意味します。
クライアントに追加されたすべてのデータはアクティブノードに保存され、そこからクラスター内の他のノードにある専用レプリカに複製されます。 このレプリカノードの配置により、アクティブノードがダウンしたときにデータが失われることはありません。
レプリカ選択戦略
NCache ノードがキャッシュクラスターに参加している順序に基づいて、レプリカノードを自動的に選択します。 最初のノードのレプリカは、最初のノードの後にクラスターに参加したサーバーノードに存在します。 そして、最後のノードのレプリカは、キャッシュクラスターの最初のサーバーノード(コーディネーターサーバー)に配置されます。
このレプリカ選択プロセス全体は自動的に行われます。 サーバーノードがキャッシュクラスターを離れるとき、または新しいノードがキャッシュクラスターに参加するときはいつでも、更新されたメンバーシップマップに従ってレプリカも再割り当てされます。
単一ノードのメモリ消費
各サーバーノード(アクティブおよびレプリカ)は、構成されたキャッシュサイズの記録を保持し、保存されたデータが指定されたメモリ制限を超えないようにします。 このメモリ制限チェックの動作が異なるXNUMXつの特別なシナリオがあります。 それらについて以下に説明します。
- 1 つのノードのみが実行状態にあり、そこにデータが追加されています。アクティブ キャッシュ インスタンスは、そのレプリカが役に立たないため、指定されたキャッシュ サイズの 2 倍を使用してデータを保持できます。
- マルチノードクラスターでは、他のすべてのノードがクラスターを離れ、XNUMXつのノードのみが稼働している場合、そのレプリカキャッシュインスタンスからのデータがアクティブキャッシュインスタンスに転送されます。 次に、レプリカからの空きメモリは、レプリカから受信したデータに対応するためにアクティブキャッシュによって消費されます。
レプリケーション戦略
Partition-Replicaトポロジには、アクティブなサーバーノードからレプリカノードにデータをレプリケートするためのXNUMXつのレプリケーション戦略があります。
非同期レプリケーション: このモードでは、バックグラウンド キューを使用して、クライアントの操作をブロックすることなくデータを複製します。すべての書き込み操作はキューに入れられ、専用のバックグラウンド スレッドがこのキューからデータを分割して取得し、レプリカ インスタンスに複製します。このレプリケーション戦略は、頻繁に書き込みを行う傾向があるが、次のキャッシュ操作までレプリケーションの完了を待ちたくないアプリケーションに適しています。ただし、ノードが突然離脱すると、データが失われる可能性があります。この場合、複製されなかったキューに入れられた操作は失われます。
同期レプリケーション: 同期レプリケーションモードでは、クライアントからのすべての書き込み操作がレプリカにレプリケートされてから、クライアントアプリケーションに制御が返されます。 このレプリケーションモードにより、アクティブキャッシュインスタンスとレプリカキャッシュインスタンスの両方がユーザーデータの同じコピーを持つことが保証されます。 レプリカインスタンスでレプリケーションが失敗した場合、そのアイテムはアクティブなレプリカキャッシュインスタンスから削除されます。
動作動作
立ち退き, 有効期限, 依存関係, writeThru / writeBehind、などはアクティブノードによって制御されます。 アクティブノードは、前述の機能のいずれかに基づいてアイテムを削除するたびに、そのアイテムをレプリカに複製して、以前に保存されたデータをノードから削除します。 同様に、 writeThru / writeBehind 操作はアクティブキャッシュからのみ実行されます。
パーティション レプリカ トポロジでは、クライアントは各サーバー ノードに直接接続されますが、アクティブなパーティション/インスタンスにのみ接続されます。ただし、クライアントがクラスター呼び出しを通じて一時的にレプリカ インスタンスと対話する状況がいくつかあります。それらについては以下で説明します。
- 状態の転送中、ノードがクラスターから離脱すると、離脱ノード向けのクライアント操作はそのレプリカから提供されます。
- クラスターがメンテナンス モードにある場合、メンテナンス中のノードを対象としたすべての操作は、メンテナンス期間中にそのレプリカから提供されます。
状態転送
状態転送は、キャッシュノード間でデータを自動転送/コピーするプロセスです。 状態転送は、新しいノードがクラスターに参加したとき、または現在のノードがクラスターを離れたときにトリガーされます。 ノードの脱退/参加により、クラスターのメンバーシップも変更されます。
ノードが更新されたものを受け取ったとき 分布図、ローカル環境内に (割り当てられた) バケットが存在することを確認します。ノードのローカル環境に存在しない割り当てられたバケットは、他のノードから 1 つずつプルされます。そのため、キャッシュ クラスター内のサーバー ノードの数に応じて、状態転送中に複数のバケットが転送されます。
状態転送は、次のXNUMXつの主要なシナリオでトリガーされます。
ノード参加時
新しいノードがキャッシュクラスターに参加すると、コーディネーターサーバーは新しい配布マップを生成して、現在のノードから新しく参加したノードにバケットを配布します。 そして、配布マップを受け取った後、新しく参加したノードは現在のノードからバケットをプルします。 この状態転送中に、新しく参加したノードは一度にXNUMXつのバケットをプルします。 XNUMXつのバケットを受け取った後、分散マップに従って、割り当てられたすべてのバケットを他のノードからフェッチするまで、次のバケットをプルします。
ノード脱退時
同様に、状態転送は、キャッシュノードがキャッシュクラスターを離れるときにトリガーされます。 コーディネーターサーバー redisクラスターのアクティブノード間でバケットを分配します。 この場合、アクティブノードは離脱ノードのレプリカからデータをプルします。
Note
すでに状態転送が進行中のときに、複数のノードが同時にまたは次々にクラスターを離れると、データが失われる可能性があります。
自動データ負荷分散について
パーティション-レプリカトポロジには、次の機能があります。 自動データ負荷分散 クラスターノード間のデータの分布を継続的に監視します。また、データの分散が予想される分散範囲 (60% ~ 40%) 内にない場合は、自動データ ロード バランシングが自動的にトリガーされます。この場合、コーディネーター サーバーは新しい配布マップを再生成し、 redisすべてのクラスターノードが同じサイズのデータを持つようにバケットを提供します。
Note
データ負荷分散も実行できます 手動で NCache 管理センター。
状態転送の理由が何であれ、このプロセス全体は自動的かつシームレスです。また、状態転送中、特にサーバー ノードがキャッシュ クラスターから離脱するとき、離脱するノードを対象としたすべてのクライアント操作は、クラスター操作を通じてそのレプリカから提供されます。
レプリカは、他のアクティブ ノードと同様に、アクティブ ノードからの状態転送も実行します。レプリカは、状態の転送時に、割り当てられたバケットをアクティブ ノードからプルしてデータのコピーをフェッチします。ただし、この状態の転送はバケットの再割り当て時にのみ行われます。それ以外の場合、データはレプリケーション メカニズムを通じてレプリカに複製されます。
状態転送を監視するさまざまな方法
NCache キャッシュクラスター内の状態転送を監視する複数の方法を提供します。 それらについて以下に説明します。
- キャッシュ ログ: 状態転送がトリガーされて停止されるたびに、クラスターのキャッシュ ログに記録されます。キャッシュログは以下に存在します。 %NCHOME%/ bin / log フォルダにコピーします。
- カスタムカウンター: NCache また、WindowsおよびLinuxで表示可能なカスタムカウンターも公開しています。
- Perfmonベースのカウンター: Windowsでは、 NCache また、WindowsPerfmonツールを介して状態転送カウンターを公開します。
- Windowsイベントログ: 状態転送関連の情報/イベントは、Windowsイベントログにも公開されます。
- 電子メールアラート: 状態転送固有の電子メール アラートは、その開始時と停止時に設定できます。
クライアントの接続性
パーティショニングで説明したように、データはクラスター内のすべてのサーバーに分散されます。 他のトポロジとは異なり、パーティショントポロジのクライアントは、すべてのパーティションに接続する必要があります。各パーティションには、合計データのサブセットが含まれています。
クライアントは、接続呼び出しで配布マップを受信します。これにより、実行中のサーバーノードとそのサーバーノードについてクライアントが教育されます。 ハッシュベースのディストリビューション。クライアントはすべてのサーバー ノードに接続して、キャッシュから完全なデータを取得します。クライアントは 更新された地図 接続を維持するために、クラスターメンバーシップが変更されるたびに。 クライアントはまた、メンバーの脱退/参加に関する通知を受信し、受信した内容に応じて接続をリセットします 地図.
クライアントは、キーを含むサーバーノードで直接読み取り/書き込み操作をインテリジェントに実行します。 ハッシュベースの分布図 受け取ります。 キーが不明なすべての操作の場合、 SQL検索, GetByTagsなど、クライアントはすべてのサーバー ノードにリクエストをブロードキャストし、それぞれの応答を結合します。
いずれにせよ、クライアントがクラスターのサーバーノードへの接続に失敗した場合でも、そのサーバーノードからの情報の書き込みと取得に失敗したわけではありません。 この目的のために、接続されている他のサーバーノードを使用します。サーバーノードは、接続されている他のサーバーノードに代わって、到達不能なサーバーノードに操作の実行を要求します。 たとえば、クライアントがnode1との接続に失敗し、node1に存在するキーを取得したい場合、クライアントは要求をnode2に送信し、node1はnodeXNUMXに再ルーティングして、応答を返します。
メンテナンスモード
ハードウェア/ソフトウェアにパッチを適用またはアップグレードする必要がある場合 NCache サーバーでは、アプリケーションのダウンタイムが発生しない場合があります。 ただし、キャッシュノードを停止するとトリガーされます 状態転送 キャッシュクラスター全体で、ネットワーク、CPU、メモリなどのリソースが過剰に使用される結果になります。 これ 状態転送 このプロセスは、キャッシュ データとクラスターのサイズによってはコストがかかる場合があります。アップグレードの一般的なワークフローには、一度にキャッシュ ノードを再起動することが含まれます。これには、ノード離脱時とノード参加時の 2 つの状態転送が必要です。
メンテナンスモード は、キャッシュ サーバーのメンテナンス中のこれらのコストのかかる状態転送を回避するために導入されました。キャッシュ サーバーがメンテナンスのために指定された時間停止されると、メンテナンス中のノードのレプリカが一時的にアクティブになり、クライアント リクエストの処理を開始します。指定された時間内にメンテナンスが終了した後、メンテナンス中のノードが再参加すると、 状態転送 このノードがキャッシュクラスターと同期するために開始されます。
クラスターが終了します。 メンテナンスモード 3 つの異なる状態で。指定された時間内にメンテナンス ノードがキャッシュ クラスターに参加すると、 状態転送 クラスターの状態を同期するために開始され、クラスターは終了します。 メンテナンスモード。指定された時間内にメンテナンス ノードがキャッシュ クラスターに再参加できない場合、クラスターはノードがダウンしていると見なし、キャッシュ クラスターを終了します。 メンテナンスモード、新しいを生成します 地図、そして、 状態転送。 成功と失敗とは別に、別の異常があります。 メンテナンスモードつまり、ノードが離脱するときです。 クラスターが メンテナンスモード メンテナンス ノード以外のノードが離れると、クラスターはクラスターから抜け出します。 メンテナンスモード、およびデータの損失につながる可能性があります。
スプリットブレインリカバリ
用語 スプリットブレイン XNUMXつのキャッシュクラスターが複数のサブクラスターに分割される状態を指します。 クラスタ内のキャッシュサーバーはTCPを介して通信します。 したがって、ネットワークの不具合や問題が発生すると、クラスター内に存在するサーバー間の通信が失われる可能性があります。 サーバー間の通信損失が一定時間を超えた場合、サーバー間の接続性に応じてメンバーシップマップが変更されます。 これにより、複数のサブクラスターが形成されます。 これらのサブクラスターはスプリットと呼ばれます。 私たちはそれを呼びます スプリットブレイン スプリットブレイン症候群で脳の半分が互いに通信できないのと同様に、サブクラスターは互いに通信できないためです。
すべてのサブクラスターは正常であり、それらに含まれるデータを処理します。 さらに、クライアントはこれらのサブクラスターに接続して、さらに読み取り/書き込み操作を行うことができます。 クライアントは、クラスターサーバーからメンバーシップマップを受信して、接続を更新します。 ここで、クライアントは、最初に受信したマップに応じて、任意のサブクラスターに接続できます。
スプリットブレイン サーバー間の通信が再開された場合にのみ検出され、すべてのサーバーが稼働しているが、単一のクラスターの一部ではないことが検出されます。 サーバー間の通信損失に応じて、XNUMXつ以上の分割が可能です。 一度 スプリットブレイン が検出されると、リカバリプロセスが開始されます。 すべてのサブクラスターがマージされるまで、すべての分割がXNUMXつずつ回復します。
スプリットブレイン 回復プロセスは検出直後に開始されます。 2 つの正常なスプリットを取得し、コーディネーター サーバーを識別し、クラスター サイズに基づいて勝者スプリットと敗者スプリットを決定し、敗者スプリットのロックを取得してそのクラスター上のクライアント アクティビティを制限し、クラスター メンバーシップを変更します。この後、すべてのクライアントが勝者クラスター スプリットにリダイレクトされ、敗者スプリットのすべてのノードが 1 つずつ再起動されて勝者クラスターに参加します。すべての敗者の分割は、同じ方法で勝者のクラスタの分割とマージされ、クラスタは再び正常になります。
データの損失は スプリットブレイン クラスターが複数のサブクラスターに分割されると、クラスター内の複数のノードが同時に離れるため、データが失われます。 サブクラスターは、次の状態でクライアント要求を楽しませることができます スプリットブレイン、クライアントが接続されているスプリットが敗者スプリットであり、メインクラスターに参加するために再起動された場合、これらの操作が失われる可能性があります。