직렬화는 개체를 바이트 스트림으로 변환하므로 지속성을 위해 프로세스 밖으로 이동하거나 다른 프로세스로 보낼 수 있습니다. 역직렬화는 바이트 스트림을 다시 개체로 변환하는 역 과정입니다.
그리고 독립 실행형 캐시와 달리 분산 캐시는 객체를 직렬화해야 캐시 클러스터의 다른 컴퓨터로 보낼 수 있습니다. 그러나 다음에서 제공하는 직렬화 메커니즘은 .NET framework 두 가지 주요 문제가 있습니다.
1. 매우 느림: .NET 직렬화는 리플렉션을 사용하여 런타임에 유형 정보를 검사합니다. 리플렉션은 미리 컴파일된 코드에 비해 매우 느린 프로세스입니다.
2. 매우 부피가 큰: .NET 직렬화는 전체 클래스 이름, 문화권, 어셈블리 세부 정보 및 멤버 변수의 다른 인스턴스에 대한 참조를 저장하며 이 모든 것이 직렬화된 바이트 스트림을 원래 개체 크기의 몇 배로 만듭니다.
애플리케이션 성능과 확장성을 개선하기 위해 분산 캐시가 사용되기 때문에 이를 방해하는 모든 것이 매우 중요해집니다. 그리고 일반 .NET 직렬화는 분산 캐시에서 주요 성능 오버헤드입니다. 메모리 내 저장을 위해 분산 캐시로 전송되기 전에 수천 개의 개체가 매초 직렬화되어야 하기 때문입니다. 그리고 여기에서 모든 속도 저하가 분산 캐시의 속도 저하가 됩니다.
다른 문제는 부피가 큰 직렬화된 바이트 스트림이 2-3배의 추가 공간을 소비하고 분산 캐시의 전체 저장 용량을 줄인다는 것입니다. 인 메모리 스토리지는 디스크 스토리지만큼 클 수 없으므로 분산 캐시에 대해 훨씬 더 민감한 문제입니다.
.NET 직렬화 문제를 극복하기 위해 NCache 구현했습니다 컴팩트 직렬화 프레임워크. 이 프레임워크에서는 NCache 정규화된 어셈블리/클래스 이름 대신 XNUMX바이트 유형 ID를 저장합니다. 필드 값만 직렬화하고 해당 유형 세부 정보를 제외하여 직렬화된 바이트 스트림을 더 줄입니다. 마지막으로, NCache Compact Serialization Framework는 인스턴스 개체의 필드 및 속성에 직접 액세스하여 발생하는 오버헤드로 인해 .NET 리플렉션을 사용하지 않습니다.
두 가지 사용 방법이 있습니다. NCache 애플리케이션의 압축 직렬화.
- 하자 NCache 런타임 시 압축 직렬화 코드 생성
- ICompactSerializable 인터페이스 직접 구현
이 블로그에서는 첫 번째 접근 방식만 고수하겠습니다. 두 번째 접근 방식은 별도의 블로그에서 설명하겠습니다.
하자 NCache 런타임 시 압축 직렬화 코드 생성
캐싱하는 객체 유형을 식별하고 등록합니다. NCache 그림과 같이 Compact Serialization 유형으로. 그것이 당신이 해야 할 전부이며, NCache 나머지는 알아서 처리합니다.
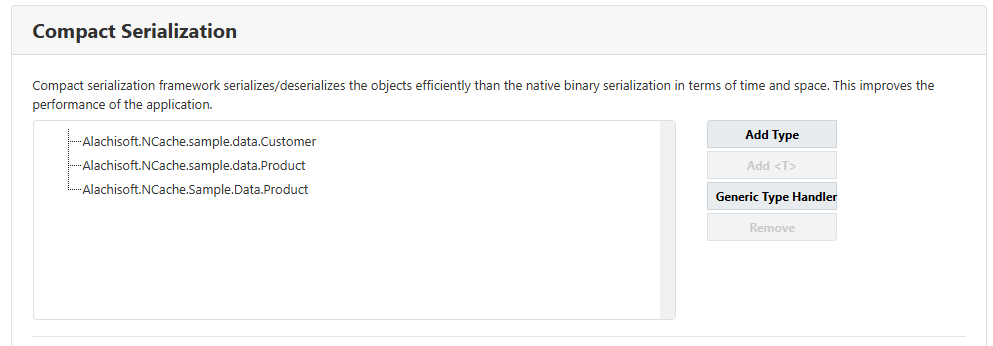
그림 1: Compact 직렬화를 위한 레지스터 유형 NCache
NCache 등록된 유형을 다음으로 보냅니다. NCache 초기화 시 클라이언트. 받은 유형에 따라 NCache 클라이언트는 런타임 코드를 생성하여 각 유형을 직렬화 및 역직렬화합니다. 런타임 코드는 다음에 의해 한 번만 생성됩니다. NCache 클라이언트는 초기화 시점에 반복해서 사용됩니다. Reflection 기반 직렬화보다 훨씬 빠르게 실행됩니다.
따라서 NCache 컴팩트 직렬화는 분산 캐시 메모리를 효율적으로 활용하고 애플리케이션 성능을 높일 수 있습니다.
따라서 완전히 작동하는 60일 평가판을 다운로드하십시오. NCache Enterprise 그리고 직접 사용해 보세요.






안녕,
위의 2가지 옵션을 조합하신 것으로 알고 있습니다. IDE를 통한 컴팩트 직렬화와 인터페이스 구현을 언제 사용합니까?
-자베드