Azure Cosmos DB에서 캐싱을 사용하는 방법
녹화된 웨비나
론 후세인과 샘 아완
Azure Cosmos DB는 전 세계적으로 분산된 다중 모델 클라우드 기반 NoSQL database 서비스. 그것은 매우 인기가있다 NoSQL database 배포의 단순성과 Microsoft의 강력한 SLA로 인해 트랜잭션이 많은 응용 프로그램을 위한 서비스입니다.
다음을 사용하여 CosmosDB를 추가로 확장할 수 있습니다. NCache. NCache 메모리에 있다는 것은 매우 빠르다는 것을 의미합니다. 그리고, NCache 분포되어 있다는 것은 선형적으로 확장될 수 있음을 의미합니다. 또한, NCache 애플리케이션에 훨씬 더 가깝기 때문에 훨씬 빠르게 액세스할 수 있습니다. 다음을 사용하여 Azure Cosmos DB 애플리케이션에 분산 캐싱을 통합하는 방법을 알아보세요. NCache.
이 웨비나에서는 다음을 사용하여 Azure CosmosDB 성능을 개선하는 방법을 알아봅니다. NCache.
이 웨비나는 다음 내용을 다룹니다.
- Azure Cosmos DB 및 일반적인 작업 소개
- 다음을 사용하여 Azure Cosmos DB 애플리케이션에서 CRUD 데이터 캐싱 NCache
- 컬렉션의 캐싱 처리
- Azure Cosmos DB로 캐시 동기화 관리
- 전체에 걸친 실습 예제 및 데모
오늘의 주제는 Microsoft Azure Cosmos DB의 속도를 높이는 것입니다. NCache. NCache 우리의 주요 분산 캐싱 제품입니다. Alachisoft. .NET 내에서 사용할 수 있습니다. .NET Core 또는 Java 응용 프로그램 또는 기타 일반 응용 프로그램을 사용하여 응용 프로그램의 성능, 확장성 및 안정성을 향상시킬 수 있습니다. 오늘은 Azure Cosmos DB와 함께 사용할 수 있는 캐싱 옵션에 대해 설명합니다. 코스모스 DB도 인기를 얻고 있기 때문입니다. 그것은 매우 중요하다 NoSQL database. 그래서 Cosmos DB로 캐싱을 시작하고 NCache 이에 대한 예시 제품으로. 그래서 모든 것이 좋아 보인다고 믿습니다. 빨리 시작하겠습니다. 다른 기능을 발표하는 동안 질문이 있는 경우 언제든지 저를 멈추고 필요한 만큼 질문을 게시하십시오. Sam은 이러한 질문을 주시하고 해당 질문에 답변해 드리겠습니다. 아래로.
Azure Cosmos DB 소개
처음 몇 개의 슬라이드는 Microsoft Azure Cosmos DB 소개에 관한 아주 기본적인 슬라이드입니다. Azure Cosmos DB가 무엇인지 모두가 알고 있다고 확신합니다. 그러나 완전성을 위해 전 세계적으로 분산된 다중 모델 데이터베이스입니다. 따라서 어디서나 사용할 수 있습니다. Microsoft Azure 내에서 호스팅되는 완전 관리형 호스팅 데이터베이스 서비스이며 다중 모델 데이터베이스입니다. 이는 본질적으로 키 값을 사용할 수 있고, 테이블 패밀리를 사용할 수 있고, SQL API를 사용할 수 있고, MongoDB 커넥터가 있고, 그래프용 Gremlin API도 있음을 의미합니다. 따라서 응용 프로그램 내에서 Cosmos DB를 데이터베이스로 사용할 수 있는 다양한 방법을 얻을 수 있습니다.
그래서, 그것은 본질적으로 NoSQL database 그러나 Microsoft는 다중 모델 데이터베이스라고 주장합니다. 그래서, 그것은보다 약간 더 NoSQL database 그런 점에서. 따라서 정의에 따라 다중 모델 데이터베이스이며 완전 관리형 데이터베이스 서비스이기 때문에 매우 유연하고 배포가 쉽습니다. 따라서 애플리케이션 내에서 NuGet 패키지를 사용하고 Microsoft Azure의 Cosmos DB 인스턴스를 가리키기만 하면 됩니다. 온프레미스 애플리케이션인 경우 해당 문제에 대해 Microsoft Azure Cosmos DB에 계속 연결할 수 있으며 Microsoft의 포괄적인 SLA로 백업됩니다. 따라서 완전히 관리되므로 배포 또는 해당 문제에 대한 기타 문제에 대해 걱정할 필요가 없습니다. 매우 유연한 JSON 형식을 지원합니다. 따라서 비정형 문서 데이터를 사용할 수 있습니다. JSON 형식을 사용하여 문서를 만든 다음 Cosmos DB에 푸시하면 바로 검색됩니다. 따라서 매우 유연하고 사용하기 쉬우며 이를 시작하는 데 필요한 코드가 적으며 트랜잭션이 많은 응용 프로그램에서 매우 인기가 있습니다. 당신은 그것을 사용하여 웹 앱을 가질 수 있습니다. 웹 서비스, 마이크로서비스, 백엔드 서버 애플리케이션이 될 수 있습니다. 애플리케이션 내에서 많은 데이터를 처리하고 처리해야 하는 경우 모든 종류의 애플리케이션에서 Microsoft Azure Cosmos DB를 활용할 수 있습니다.
다음은 테이블, SQL, JavaScript, Gremlin, Spark에 대해 다시 설명하는 다이어그램입니다. 따라서 활용할 수 있는 다양한 커넥터와 가장 일반적인 커넥터가 핵심 가치입니다. 그런 다음 열 패밀리, 중첩 문서가 있는 문서, 그래프용 Gremlin도 있습니다. 따라서 그래프를 저장할 수 있습니다.
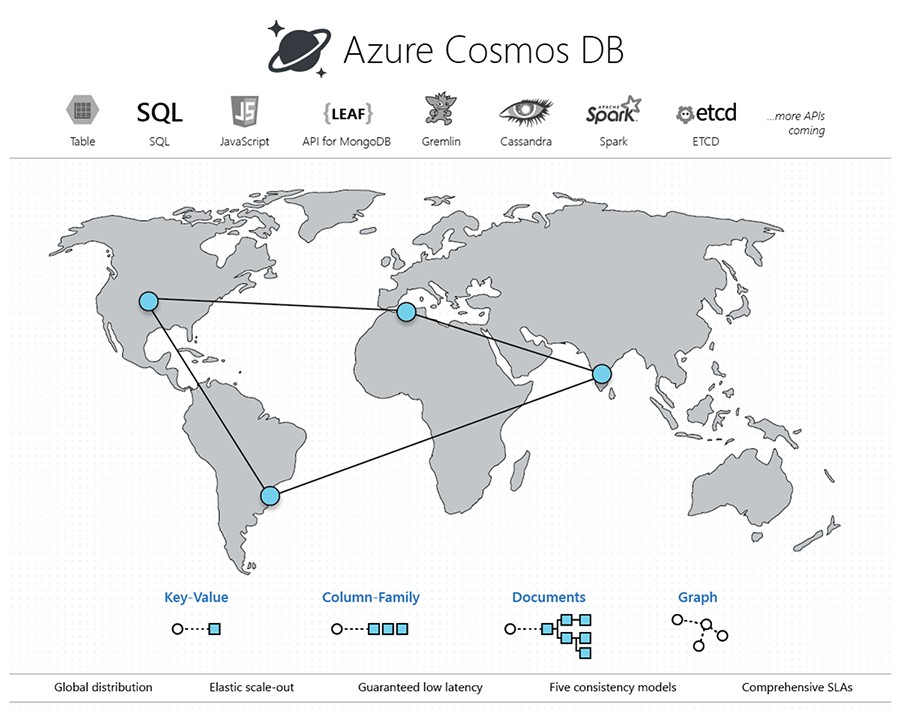
따라서 전 세계적으로 배포되는 것이기도 합니다. Microsfot Azure에서는 여러 데이터 센터를 가질 수 있습니다. 다중 분할을 가질 수도 있습니다. 따라서 Microsoft Azure Cosmos DB와 함께 제공되는 모든 좋은 기능.
Cosmos DB의 일반적인 사용 사례
일반적인 사용 사례 중 일부. IoT 및 Telematics에서 많은 데이터를 수집, 처리 및 저장하는 데 사용할 수 있으며 일반적으로 이 특정 산업에서 트랜잭션이 많은 애플리케이션을 처리하는 경우 Cosmos DB를 사용할 수 있으며 관리에 대해 걱정할 필요가 없습니다. 그 양의 데이터와 그 양의 요청도 관리합니다. 데이터베이스 계층이 중요한 구성 요소인 카탈로그 정보, 이벤트 소싱, 주문 처리, 게임 저장을 위한 지역 마케팅. 따라서 여러 게임 앱을 활용하거나 서로 다른 플레이어가 상호 작용할 수 있습니다. 토너먼트 정보, 고득점 리더보드 및 해당 문제에 대한 소셜 미디어 통합.
웹 및 모바일 애플리케이션은 또 다른 사용 사례가 될 수 있습니다. 소셜 애플리케이션은 타사 서비스와 통합되는 또 다른 예가 될 수 있습니다. 따라서 많은 데이터를 처리하고 처리하고 해당 문제에 대해 많은 데이터를 저장해야 하는 거의 모든 애플리케이션에서 사용할 수 있습니다. 따라서 Cosmos DB가 선호되는 선택이 될 수 있습니다. 이제 도입 측면에서 이것이 좋은 것 같아요. 질문이 있으면 알려주세요.
오늘의 초점은 캐싱에 대한 요구 사항이 무엇이며 그 문제에 대해 캐싱이 필요한 이유는 무엇입니까? 이를 위해 Microsoft Azure Cosmos DB에는 두 가지 문제가 있으며 이는 우리가 수행한 성능 테스트와 수행한 요청 단위 비용 추정을 기반으로 합니다.
Azure Cosmos DB 문제
따라서 Microsoft Azure Cosmos DB에는 주로 두 가지 문제가 있습니다.
성능 병목 현상
1위이자 가장 중요한 것은 성능 병목 현상입니다. Microsoft Azure는 Cosmos DB가 밀리초 응답 시간을 제공할 것이라고 주장합니다. 테스트 결과에 따르면 이는 거의 사실입니다. 그러나 밀리초 미만 응답이 필요한 경우 어떻게 하시겠습니까? 때문에 NCache 우리의 로컬 테스트 내에서 로컬 캐시라도 다른 파티셔닝에 대해 이야기하거나 캐시 데이터를 호스팅하는 여러 서버가 있는 것이 아닙니다. 로컬 캐시도 네트워크를 통해 있을 수 있으며 밀리초 미만 응답을 얻을 수 있으며 Cosmos DB를 테스트한 비교 NCache.
따라서 Microsoft Azure Cosmos DB를 NCache. 따라서 몇 초에서 밀리초로, 밀리초에서 밀리초 미만의 응답 시간으로 Cosmos DB의 성능 향상이 필요함을 알 수 있습니다. 기본적으로 좀 더 분석하면 Microsoft Azure Cosmos DB가 호스팅된 서비스가 되어 프로덕션 환경에 배포할 때 애플리케이션 내에서 실제로 발생하기 때문입니다. 따라서 자체 구독에서 항상 VNET에 걸쳐 있습니다. 구독의 일부를 허용할 수 있으며 요청 단위에 따라 요금을 청구하지만 이미 가상 네트워크에서 호스팅되는 경우 Microsoft Azure 및 애플리케이션 내에서 호스팅되고 VNET을 통과하는 경우 네트워크 비용이 있어야 합니다. 그것에 추가되어 대기 시간 부분도 증가합니다.
즉, 애플리케이션이 온프레미스인 경우 애플리케이션도 더 느려질 것입니다. 그래서 처음에는 Cosmos DB와 NCache. NCache 인메모리이기 때문에 이미 더 빠르며 밀리초에 비해 밀리초 미만의 응답을 제공하고 실제로 배포하고 애플리케이션이 클라우드에서 호스팅될 때 그 위에 있습니다. Azure의 Cosmos DB는 VNET을 가로질러 VNET과 VNET 간 통신이 될 것이며, 여러 분할이 있고 두 개의 데이터 센터가 있고 데이터가 앞뒤로 이동하는 경우 작동할 수 있는 상당한 대기 시간이 있습니다. 결국 다른 파티션이나 다른 데이터 센터로 이동하게 되면 상황이 온프레미스에 비해 더 느려질 것입니다. 온프레미스 애플리케이션이 Microsoft Azure Cosmos DB를 사용하는 경우는 그리 일반적인 사용 사례는 아니지만, 이 경우 Cosmos DB에 액세스하려면 WAN을 통과해야 합니다. 따라서 이것은 매우 빠른 옵션이 아닙니다.
따라서 Microsoft Azure Cosmos DB가 성능 면에서 잘 배포되지 않는 것이 가장 큰 문제입니다. 따라서 특히 높은 트랜잭션에서 성능이 저하됩니다. 많은 요청이 들어오고 해당 데이터를 적시에 신속하게 처리해야 할 때. 따라서 성능이 약간 저하될 수 있으며 솔루션은 매우 간단합니다. 이에 대해서는 다음 슬라이드에서 다음과 같은 캐싱 시스템을 사용하기 시작합니다. NCache.
고가의 요청 단위
두 번째 문제는 비용이 많이 드는 요청 단위이며 비용이 많이 드는 문제입니다. 따라서 각 요청 단위에는 비용이 있습니다. 읽기 전용 데이터에 대해서도 Microsoft Azure Cosmos DB에 액세스할 때마다. 해당 데이터가 자주 변경되지 않는 경우 동일한 내용이지만 여전히 찾고 있는 데이터인 Cosmos DB에서 오는 마스터 원본이 있습니다. 해당 데이터를 위해 Microsoft Azure로 계속 이동해야 합니다. Cosmos DB는 요청 단위로 비용을 지불하고 비용을 증가시키는 곳입니다. 따라서 요청 로드가 증가하면 비용이 증가합니다. 따라서 처리할 수 있는 요청 로드만큼 확장성이 뛰어나지만 해당 시나리오에서는 비용 친화적이지 않습니다. 따라서 비용 요소에도 영향을 미칩니다. 따라서 확장에 대한 잠재적인 장애물이 될 수 있습니다. 규모 확장을 계획할 때. 파티션이 여러 개 있고 데이터 로드가 증가하지만 비용 요소도 함께 증가합니다.
따라서 Microsoft Azure Cosmos DB를 다룰 때 이 두 가지 문제를 고려해야 할 수도 있습니다.
해결 방법 : NCache 분산 캐시
이러한 문제에 대한 솔루션은 다음과 같은 분산 캐싱 시스템을 사용하는 매우 간단합니다. NCache. 가장 먼저, NCache 메모리에 있습니다. 그래서, 당신이 저장하는 모든 NCache 비교하여 메모리에 저장됩니다. 따라서 즉시 몇 밀리초의 성능 향상을 제공할 예정이며 동일한 컴퓨터에서 localhost에서 실행되는 Cosmos DB와 NCache 같은 머신에서 실행, NCache 요인이 더 빨랐습니다. 비교했을 때 훨씬 빨랐다. 동일한 데이터 세트에 대한 밀리초 응답과 비교하여 밀리초 미만이었습니다.
둘째, 네트워크 응용 프로그램 내에서도 호스팅할 수 있으며 Cosmos DB에 추가하여 사용할 수 있습니다. 코스모스 DB를 대체하는 것이 아닙니다. 이 특정 웨비나에서는 Cosmos DB를 함께 사용할 수 있는 다양한 접근 방식을 설명합니다. NCache 과 NCache 대부분의 데이터를 캐시하고 비용 및 성능 면에서 Cosmos DB로의 값비싼 여행을 절약하는 데 도움이 되는 제품이 될 것입니다. 두 번째로 NCache 분산 캐시 클러스터입니다. 따라서 그에 따라 확장할 수 있습니다. 고가용성이 내장되어 있고 서버 수가 많고 각 서버에도 다른 서버에 백업이 있기 때문에 매우 안정적입니다. 이를 지원하는 데 도움이 되는 배포 다이어그램이 있습니다.
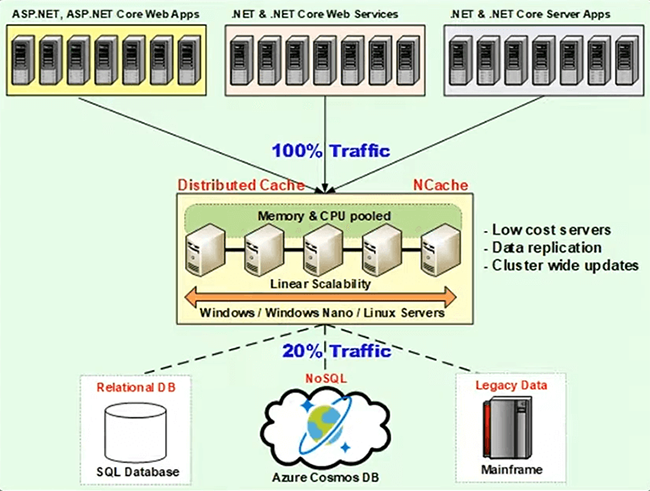
모든 종류의 응용 프로그램 ASP.NET 또는 ASP를 가질 수 있습니다..NET Core 웹 앱 .NET 또는 .NET Core 웹 서비스 및 유사하게 다른 모든 서버 응용 프로그램, 심지어 Java 응용 프로그램도 마찬가지입니다. 이전에는 클라우드에서 Cosmos DB를 사용 중이거나 애플리케이션이 온프레미스이거나 모든 것이 클라우드에 있는 경우 동일한 라인에 캐싱 계층을 도입할 수 있습니다. Microsoft Azure에서는 다음을 사용할 수 있습니다. NCache .NET을 사용하여 Azure에서 또는 .NET Core 설치. 그것은에서 사용할 수 있습니다 Microsoft Azure marketplace 그리고 캐시 클러스터를 형성할 수 있고 NCache 그것은 자신의 VNET 내에 앉을 것입니다. 따라서 네트워크 대기 시간이 완전히 완화될 것입니다. 그래서 그것은 더 이상 문제가 되지 않으며 무엇보다 NCache 메모리에 있습니다.
그래서, NCache 에 비해 이미 매우 빠릅니다. 따라서 성능이 즉시 향상되고 온프레미스 애플리케이션의 경우 NCache 온프레미스와 Cosmos DB는 여전히 Microsoft Azure 클라우드에 상주할 수 있으며 성능 측면에서 모든 것이 변경됩니다. 비용 단위 측면에서 모든 데이터를 저장할 수 있습니다. 보시다시피 100% 트래픽이 다음으로 라우팅될 수 있습니다. NCache 그러면 Microsoft Azure Cosmos DB에 대한 값비싼 여행을 절약할 수 있고 Cosmos DB에 대한 여행을 저장하는 즉시 요청 단위가 줄어들기 때문에 비용 절감에 도움이 됩니다. 이에 비해 요청 단위 공간이 더 적고 Microsoft Azure Cosmos DB 액세스 및 사용과 관련된 비용이 더 적습니다. 20% 이하의 트래픽만 Microsoft Azure Cosmos DB로 이동할 수 있으며 애플리케이션에 도움이 되는 이러한 캐싱 옵션에 대해 설명합니다.
질문이 있으면 알려주세요. 다음과 같은 제품 사용을 고려해야 하는 이유에 대한 몇 가지 기본 세부 정보를 만들었습니다. NCache 귀하의 응용 프로그램을 개선하기 위해. 다음으로 이야기할 일반적인 사용 사례는 NCache 그런 다음 몇 가지 샘플을 가지고 있습니다. 이를 보여드리고자 합니다. 따라서 이 시점에서 질문이 있으면 알려주세요. 이 시점에서 질문이 없다고 가정합니다. 계속하겠습니다.
일반적인 용도 NCache
일반적인 사용 사례 중 일부. 우리는 처음에 업계 전반의 사용 사례에 대해 이야기했습니다. 따라서 이러한 모든 응용 프로그램은 다음을 사용할 수 있습니다. NCache 또한. 사실, NCache 더 큰 클라이언트 집합, 다양한 클라이언트가 있으며 NCache. 전자 상거래가 될 수도 있고, 은행이 될 수도 있고, 금융이 될 수도 있고, 자동화가 될 수도 있고, IoT, 통신 부문이 될 수도 있습니다. 따라서 모든 부문은 다음과 같은 잠재력을 가지고 있습니다. NCache 활용할 수 있기 때문에 NCache 일반적으로 데이터를 다루는 모든 응용 프로그램에서. 그들은 성능이 필요하고 확장성이 필요하며 고가용성과 안정성이 필요하며 이러한 문제를 처리하고 있습니다. 그래서 그들은 NCache. 그러나 기술적인 사용 사례에 관한 한 다음을 사용할 수 있습니다. NCache 애플리케이션 데이터 캐싱용.
애플리케이션 데이터 캐싱
따라서 첫 번째 사용 사례는 앱 데이터 캐싱입니다. Microsoft Azure Cosmos DB에는 Cosmos DB가 기본 원본으로 있습니다. 대부분의 문서 또는 전체가 존재하고 일부 또는 전체를 가져올 수 있는 곳입니다. NCache 더 빠른 액세스를 위해. 따라서 수행자를 개선하고 애플리케이션에 대한 요청 단위 효과를 줄이기 위해 다양한 종류의 동기화 접근 방식을 사용할 수 있습니다. 이 웹 세미나에서도 다룰 것입니다. 따라서 관계형 데이터베이스 및 Cosmos DB와 관련하여 가장 일반적인 사용 사례입니다.
Ron, 나는 당신에게 질문이 있는데 그 질문은 어떻게 동일한 Cosmos DB와 NCache, 변경 NCache? 알겠습니다. 방금 얘기했습니다. 그래서, 우리는 이것을 위해 정렬된 세그먼트가 있습니다. Microsoft Azure Cosmos DB 내에 메커니즘이 있습니다. 변경 피드를 사용합니다. 관찰자 패턴이 있습니다. 따라서 추가 및 업데이트를 관리할 수 있으며 변경 피드에서 이러한 추가 및 업데이트를 추적합니다. 따라서 이 웨비나에는 두 가지 접근 방식이 준비되어 있습니다. 여기서 변경 피드 알림을 사용하여 해당 변경 사항을 적용하는 방법에 대해 설명하겠습니다. NCache 또한. 그래서 Cosmos DB 데이터베이스가 변경되는 즉시 자동으로 적용됩니다. NCache 또한. 그래서, 그것이 제가 오늘 데모 중 하나에 줄을 섰던 것입니다.
세션 캐싱 및 SignalR Backplane
다른 사용 사례도 있습니다. ASP.NET과 ASP가 있습니다..NET Core 웹 앱도 사용할 수 있습니다. NCache 세션을 위해, 시그널R, 응답 캐싱의 경우 상태 및 출력 캐시를 확인한 다음 NCache 메시징 플랫폼이기도 합니다. 당신이 사용할 수있는 게시/구독 메시지. SignalR은 Pub/Sub 메시징으로 백업됩니다. 데이터 기반 이벤트, Pub/Sub 이벤트, 연속 쿼리 이벤트도 있습니다. 그래서, NCache 메시지 버스, 메시지 플랫폼 및 데이터 공유 플랫폼으로 사용할 수 있습니다.
데모에 손
알겠습니다. 시작하는 방법을 빠르게 알려 드리겠습니다. NCache. 따라서 캐시를 생성한 다음 다른 접근 방식에 대해 이야기하겠습니다. 캐싱은 어떻게 하고 어떻게 시작할까요? 따라서 몇 가지 기본 예제를 가지고 실제로 이를 기반으로 구축하고 동기화를 사용하는 방법과 컬렉션 및 업데이트를 관리하는 방법을 보여줍니다.
우선 데모 환경부터 시작하겠습니다. NCache 온프레미스와 Microsoft Azure Cloud에서 호스팅할 수 있습니다. 에 대한 기본 배포 옵션 NCache 는 VM이고 우리는 웹 기반 관리 도구를 가지고 있어 Windows 상자와 Linux 상자를 관리할 수 있습니다. 그래서 의 도움으로 .NET Core 당신은 설치할 수 있습니다 NCache 리눅스에서도. 따라서 그것은 전적으로 당신에게 달려 있습니다. Windows 또는 Linux 측의 VM에 캐시를 유지할지 여부. Windows 상자를 사용하고 있습니다. 이제 캐시를 생성해 보겠습니다. 그래서 우선 제가 만들겠습니다.
여기에서 이 마법사를 시작하겠습니다. 내 캐시 이름을 Democache로 지정하겠습니다.
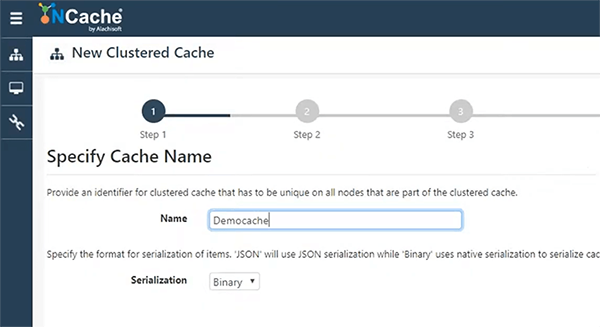
모든 것을 기본값으로 유지하겠습니다. 이러한 설정에 대한 세부 정보는 문서와 다른 웨비나에서 확인할 수 있습니다. NCache 건축물. 따라서 파티션된 복제본 캐시를 유지합니다. 가장 선호하는 것입니다.
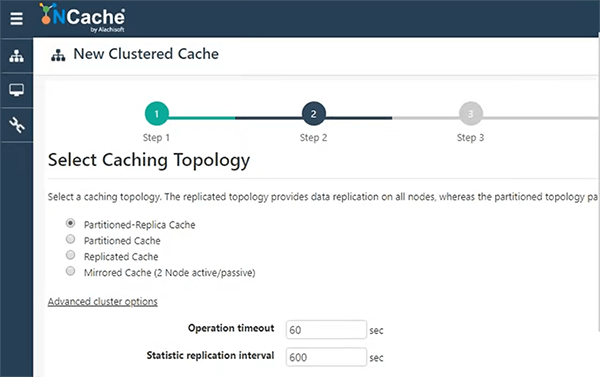
활성 파티션과 이것의 백업 간의 비동기 복제. 두 대의 서버가 있는 경우 서버 XNUMX은 XNUMX에서 백업을 갖고 서버 XNUMX는 XNUMX에서 백업을 갖습니다. 따라서 해당 백업을 유지 관리하는 것은 들어오는 요청에 따라 동기식 또는 비동기식일 수 있습니다. 따라서 다시 매우 빠르고 선호되기 때문에 비동기를 선택하겠습니다. 따라서 캐시를 호스팅할 두 개의 서버를 지정하겠습니다.
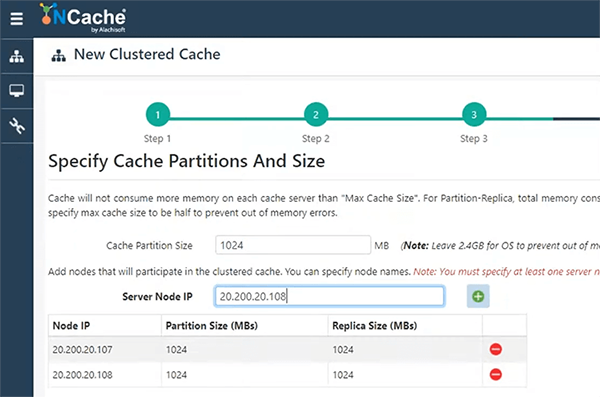
NCache 이미 설치되어 있습니다. 이것들은 Windows 상자입니다. TCP/IP 설정까지 모든 것을 기본값으로 유지하겠습니다. NCache TCP/IP 기반 프로토콜입니다. 따라서 서로 통신하려면 IP 주소와 포트가 필요하며 거기에서 가져옵니다. 그런 다음 화면의 모든 것을 기본값으로 유지하고 완료되면 이 캐시를 시작하겠습니다.
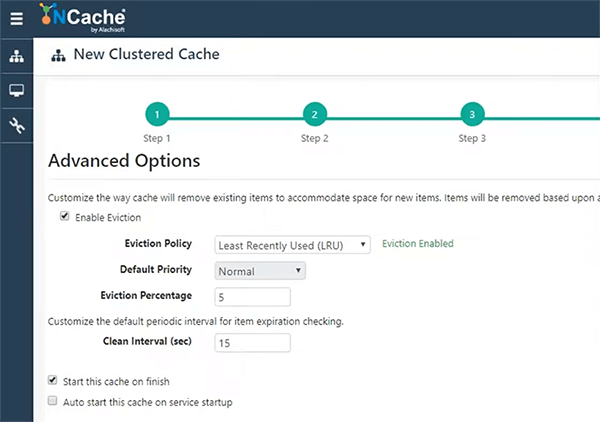
따라서 이것은 구성되고 바로 시작되며 시간이 좀 걸리고 자동으로 캐시가 생성되며 여기에 Azure Cosmos DB 에뮬레이터가 있습니다. 나는 그것의 localhost 배포를 사용하고 있습니다. 여기 고객과 임대라는 두 개의 문서 저장소가 있습니다.
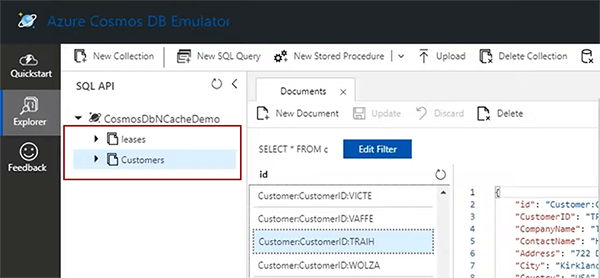
임대는 변경 피드를 통해 다시 동기화됩니다. 나는 동기화에 대해 이야기할 때 또는 나중에 그것에 대해 이야기할 것입니다. 그래서, 고객, 그것은 우리가 다른 고객이있는 기본 고객 저장소 문서 저장소입니다. 고객을 클릭하면 이름, ID, 주소, 도시 및 국가를 가진 고객이 있는 것을 볼 수 있으며 이 고객은 이 데모에서 다룰 것입니다.
{
"id": "Customer:CustomerID:TRAIH",
"CustomerID": "TRAIH",
"CompanyName": "Trail's Head Gourmet Provisioners",
"ContactName": "Helvetius Nagy",
"Address": "722 DaVinci Blvd.",
"City": "Kirkland",
"Country": "USA",
"_rid": "Xpd7ANtwbZjSAAAAAAAAAA==",
"_self":"dbs/Xpd7AA==/colls/Xpd7ANtwbZI=/docs/Xpd7ANtwbZjSAAAAAAAAAA==/",
"_etag":"\"00000000-0000-0000-1649-a9a8daaa01d5"
"_attachements": "attachements/"
"_ts":1559153371
}여기로 돌아와서 캐시가 완전히 시작되었습니다. 이를 확인하고 세부 정보를 볼 수 있으며 내 상자를 클라이언트로 추가할 수 있습니다. 그것은 선택적인 단계입니다. NuGet 패키지를 사용하는 경우 이 단계를 건너뛸 수 있지만 사용 편의성을 위해 생략하겠습니다. 따라서 GUI 관리자에서 모든 것을 추가하기만 하면 클라이언트 시스템에 구성이 채워집니다. 우리는 좋은 것 같아요. 한 가지 더 할게요. 통계 창을 열고 함께 설치되는 모니터링 도구도 엽니다. NCache. 그래서 이것들은 나에게 성능 카운터를 제공하고 이 창들은 NCache 모니터링 도구, 모니터링 측면의 약간 참조 NCache 그런 다음 PowerShell 창을 열고 다음과 함께 설치되는 스트레스 테스트 도구 응용 프로그램을 실행합니다. NCache 그리고 바로 다음에 Cosmos DB용으로 준비한 샘플 애플리케이션에 대해 이야기하겠습니다. 그것은 내 캐시 클러스터에 대한 일부 더미 로드를 시뮬레이트할 도구이며 적중하자마자 일부 활동을 볼 수 있어야 합니다. 하나의 클라이언트가 연결되어 있습니다.
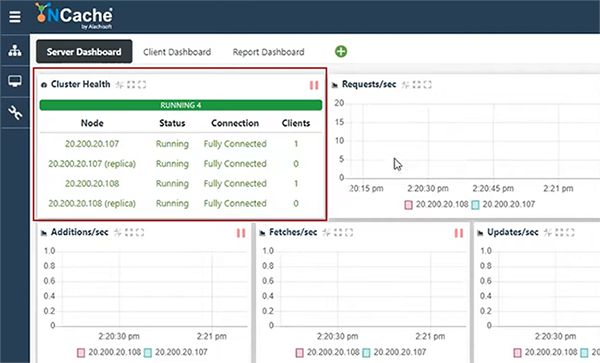
그리고 몇 가지 활동을 보여주는 초당 요청이 표시되어야 합니다. 사실 바로 여기 이 상자에 로그온할 수 있습니다. 다른 컴퓨터에서 이것을 보여주므로 더 빨리 볼 수 있습니다. 알겠습니다. 여기에서 활동을 볼 수 있습니다. GUI 도구를 새로 고칠 수 없다고 생각합니다. 몇 가지 권한 문제가 있다고 생각합니다. 그러나 그럼에도 불구하고 개수가 업데이트되는 것을 볼 수 있고 초당 요청을 볼 수 있으며 이것이 이 특정 데모에 필요한 전부입니다.
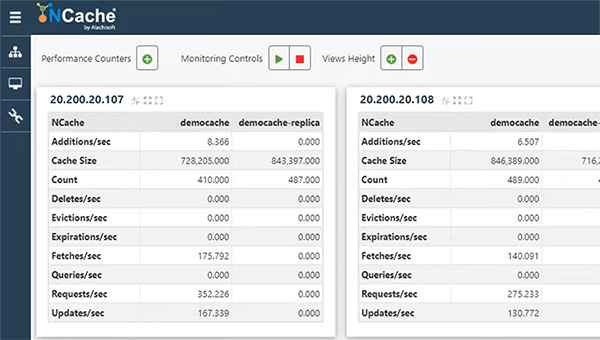
Azure Cosmos DB를 사용한 앱 데이터 캐싱
따라서 샘플 응용 프로그램을 사용하는 것이 좋습니다. 앱 데이터 캐싱 사용 사례에 대해 빠르게 이야기하고 샘플 애플리케이션의 작동 방식도 설명하고 샘플 애플리케이션을 단계별로 디버그하고 명령을 보여드리겠습니다. 캐싱을 시작하기 위해 통합했습니다. 아주 간단하고 기본적인 프로그램입니다. 그것은 처음에 hello world이고 거기에서 진행됩니다.
따라서 앱 데이터 캐싱이 있습니다. 가장 먼저 해야 할 일은 참조 데이터를 처리하는 것입니다. 자주 바뀌지 않는 데이터는 트랜잭션 데이터도 될 수 있습니다. 변경되는 데이터를 위해 별도의 세그먼트가 정렬되어 있지만 참조 데이터의 경우 주로 읽기를 처리하게 됩니다. 따라서 먼저 Cosmos DB에 연결한 다음 연결해야 합니다. NCache. 가져오기 작업을 수행한 다음 업데이트 작업도 수행해야 합니다. 가져오기 작업 내에서 단일 문서 또는 문서 컬렉션을 캐시한 다음 업데이트 내에서 문서를 추가, 업데이트 및 삭제할 수 있습니다. 이것은 코드 조각이며 바로 여기에서 강조 표시될 것입니다.
//Add NCache Nuget and Include Namespaces
using Alachisoft.NCache.Client;
using Alachisoft.NCache.Runtime.Caching;
//Add Cosmos DB Nuget and Include Namespaces
using Microsoft.Azure.Documents;
using Microsoft.Azure.Documents.Client;
...
{
//NCache Connection call
static ICache _NCacheClient = CacheManager.GetCache("DemoCache");
//Cosmos DB Connection call
static DocumentClient _CosmosDbClient = new DocumentClient(
serviceEndpoint: new Uri("https://localhost:8081"),
authKeyOrResourceToken:@"C2y6yDjf5/R+ob0N8A7Cgv30VRDJIWEHLM+4QDU5DE2nQ9nDuVTqobD4b8mGGyPMbIZnqyMsEcaGQy67XIw/Jw==");
}...그래서 내 CRUD 내에서 NCache Cosmos DB 샘플 애플리케이션, 다른 케이스, 다른 테스트 케이스가 있습니다. 따라서 우선 DemoCache라는 캐시 이름을 제공하겠습니다. 대소문자를 구분하지 않으며 일부 Cosmos DB 연결 설정이 있습니다. 내가 선택한 예의 관점에서 가장 관련성이 높은 SQL 클라이언트를 예로 사용하고 있습니다. 그러나 Cosmos DB의 모든 클라이언트를 생각해 낼 수 있으며 여전히 사용할 수 있습니다. NCache 때문에 NCache API는 매우 간단합니다. JSON 객체가 될 수 있는 응답을 얻을 수 있으며 다음을 사용하여 캐시할 수 있습니다. NCache API 및 내부 NCache 캐시와 상호 작용하는 다양한 방법도 있습니다. 따라서 이들 중에서 선택할 수 있지만 캐싱에 대한 아이디어는 정확히 동일하게 유지됩니다.
괜찮은. 그래서 내 Cosmos DB 내에서 바로 여기로 오면 이 내에서 URL, 기본 키, 연결 문자열을 볼 수 있습니다. 따라서 여기에서 지정해야 하는 설정이 있으며 연결을 열 수 있습니다. 따라서 이것이 캐시 핸들 "_cache", ICache 인터페이스를 얻는 방법입니다. 이것을 보여주면 관리 API도 일부 제공됩니다. 알겠습니다. CacheManager 클래스도 캐시 컬렉션을 제공합니다. ICache, CacheHealth 및 해당 문제에 대한 다른 StartCache 및 StopCache 메서드가 있습니다. 여기에 연결되면 가장 먼저 해야 할 일은 캐시 항목을 가져와서 Cosmos DB에서 일부 문서를 가져온 다음 캐시하는 것입니다. 하지만 우리가 사용하기 때문에 NCache 중간에, 그래서 우리 애플리케이션은 항상 캐시에서 먼저 확인해야 하는 방식으로 설계되어야 하고 그렇게 해야 Cosmos DB에 대한 값비싼 여행도 절약할 수 있습니다. 이것이 바로 우리 사례에서 진행되는 일입니다. 여기.
우리가 실제로 하고 있는 것은 고객 ID를 얻는 것입니다. 그것은 고객 ID, 고객 ID를 기반으로 한 가져오기일 수 있으며 먼저 "_cache.Get"을 호출하고 키를 제공합니다. 키는 사용자가 정의하는 것입니다. NCache. NCache 키 값 쌍에 모든 것을 저장합니다. 따라서 키는 고객일 수 있고 고객 ID는 런타임 매개변수에 있을 수 있으며 캐시에서 데이터를 찾으면 Cosmo DB로 이동할 필요가 없습니다. 이 지점에서 돌아올 수 있습니다. 그렇지 않으면 항상 Cosmos DB API를 실행합니다. 예를 들어 이 경우 Cosmos DB "_client.ReadDocumentAysnc"를 사용하여 응답을 받고 CollectionID 및 키와 같은 모든 세부 정보를 제공하고 이를 기반으로 Cosmos DB에서 레코드를 가져온 다음 캐시합니다. 이것은 다음에 캐시에 데이터가 이미 있는지 확인하기 위한 것입니다.
따라서 처음으로 디버깅하지 않고 샘플을 실행하겠습니다. 모든 테스트 케이스를 보여주고 우리는 이 테스트 케이스를 하나씩 살펴보고 이것이 어떻게 수행되는지 보여줄 것입니다. 질문이 있으면 알려주세요.
그래서 고객을 추가하겠습니다. Ross123을 제공하고 Enter 키를 누른 다음 고객을 검토한다고 가정해 보겠습니다. 다시 Ross123을 제공하면 연락처 이름이 있는 더미 고객 Ross123이 생성되고 날짜와 시간이 추가된 것을 볼 수 있습니다. .
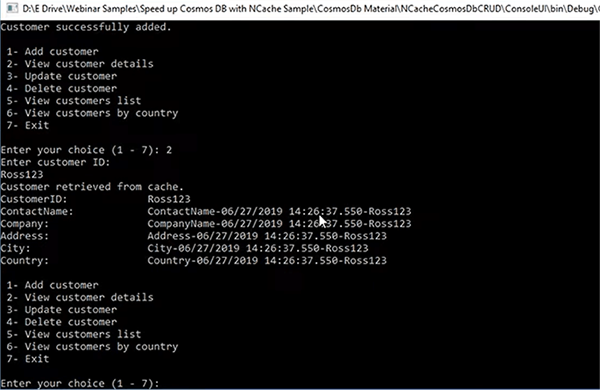
이미 Cosmo DB에 있는 다른 고객도 찾을 수 있습니다. 그래서, 그것을 얻었고 우리가 이것을 할 때 캐시에서 두 개의 항목을 볼 수 있어야 합니다. Ross와 ALFKI가 이미 캐시에 추가되었습니다.
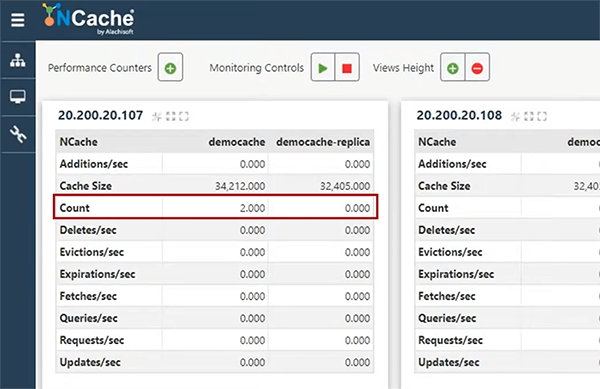
그래서 나는 이 일을 계속할 수 있다. 이 고객을 업데이트할 수 있습니다. 예를 들어 Ross123. 매개변수를 사용하지 않습니다. 단순히 날짜/시간 값을 업데이트하는 것입니다. 따라서 이것을 다시 치면 14:27:13과 비교하여 14:26:37을 볼 수 있습니다. 그래서 Cosmos DB는 물론 캐시에서도 업데이트했는데 여기에서 바로 보여드리면 업데이트된 고객을 Explorer 창에서 빠르게 보여드릴 수 있고 업데이트된 값이 있습니다. 따라서 이 두 소스를 나란히 다루고 있습니다. 이 고객도 삭제할 수 있습니다. 실제로 고객을 볼 수 있습니다. 이러한 중단점을 제거하겠습니다. 좋아요, 그것은 저에게 모든 고객을 얻을 것입니다. 만약 제가 5를 치면, 그리고 제가 6을 치면, 그것은 국가를 기반으로 한 고객을 얻게 될 것입니다.
따라서 가장 먼저 강조하고 싶은 것은 Cosmos DB를 사용하여 캐시에서 고객을 확보하고 NCache, 단일 문서 캐싱. 그럼 빠르게 리뷰해보도록 하겠습니다.
Customer GetCustomer (Customer customer)
{
string key = $"Customer:CustomerID:{customer.customerID}";
//Check data in NCache first
Customer customer = _NCacheClient.Get<Customer>(key);
if (customer != null)
{
return customer;
}
//If data is not in NCache then get from Cosmos DB and Cache it
else
{
ResourceResponse<Document> response =
_CosmosDbClient.ReadDocumentAsync(UriFactory.CreateDocumentUri (DatabaseId,CollectionId,key)).Result;
customer = (Customer)(dynamic)response.Resource;
_NCacheClient.Insert(key, customer);
return customer;이미 매우 간단하기 때문에 이 시점에서 추가를 표시하지 않을 것입니다. 그래서 저는 플레이를 하려고 합니다. 이 중단점에 도달하고 이 작업을 수행하기 전에 변경합니다. 내용을 정리하고 진행하겠습니다. 그래서 새롭게 시작합니다. 괜찮아. 따라서 콘텐츠는 두 서버 모두에서 XNUMX입니다. 그것이 예상되는 것입니다. 자, 이것을 치자. 중단점에 있습니다. 맞습니다. 따라서 내가 고객 ALFAKI를 가져올 것으로 예상하고 이를 기반으로 처음으로 계속 입력하면 고객 키를 구성한다는 것을 빠르게 알 수 있습니다. 이것이 우리가 다루고 있는 키이며 캐시에서 이를 가져오려고 시도할 것이고 분명히 새로운 시작이기 때문에 null을 찾을 것입니다.
null이면 Cosmos DB에서 가져온 다음 캐시에도 추가하고 한 항목이 추가된 것을 볼 수 있습니다. 다음으로 값을 검색하여 화면에 표시합니다. 이것을 한 번 더 실행합니다. 이번에는 캐시에서 동일한 고객을 기대하고 있습니다. 이제 캐시가 저장되고 계속 진행할 때마다 모든 종류의 TTL, Cosmo DB에 있는 모든 종류의 속성을 지정할 수 있기 때문입니다. 그리고 캐시에서도 고객을 얻습니다. 정확히 같은 고객인데 이번에는 코스모스 DB로 가지 않고 화면에서도 보여주기만 하면 된다.
따라서 이것은 간단한 hello world 프로그램으로, 캐시에서 동일한 값을 가져옵니다. 이제 캐시가 캐시되고 그것이 여러분이 원하는 방식이고 훨씬 더 빠르기 때문입니다. Cosmos DB와 Cosmos DB 간에 나란히 비교 테스트를 실행할 수 있습니다. NCache 너는 볼 수있다. NCache 훨씬 더 빠르고 Cosmos DB로의 여행을 저장할 수도 있으며 이는 비용 요소에도 영향을 미칩니다. 그것은 단지 그것을 줄일 것입니다. 이것이 첫 번째 사용 사례입니다.
두 번째 사용 사례는 컬렉션을 관리하는 방법이며 여기에는 두 가지 옵션이 있습니다. 전체 컬렉션을 하나의 항목으로 사용하거나 각 컬렉션 항목을 개별적으로 캐시할 수도 있습니다. 따라서 먼저 XNUMX단계를 거쳐 여기에 코드를 표시하면 목록을 단일 항목으로 저장할 수 있습니다. 그래서 저는 여기서 중단점에 도달했습니다. 이것은 아무 것도 기대하지 않고 캐시에서 가져온 다음 즉시 재생 버튼을 누르는 것을 보여줍니다.
론, 질문이 있습니다. 사용 가능한 SQL 유형 검색 옵션이나 다른 종류의 특수 기능이 있습니까? 네, 아주 좋은 질문입니다. 제가 보여드리는 기본 API입니다. NCache 태그를 사용하는 메커니즘도 있습니다. SQL 검색을 사용할 수도 있습니다. 링크, 전체 텍스트 검색도 사용할 수 있습니다. 하여튼 아주 비교가 됩니다. 여러분이 SQL에 익숙하다면 SQL API를 사용할 수 있습니다. NCache. 라고 불린다 개체 쿼리 언어. 여러분이 LINQ에 익숙하고 그것이 선호하는 경우 LINQ를 기반으로 항목을 가져올 수 있으며 전체 텍스트 검색은 또 다른 기능입니다. 단순함을 위해 키 값 쌍을 보여주고 있습니다. 그러나 내가 말했듯이 이것들은 당신이 그것의 일부로 활용할 수도 있는 모든 옵션입니다.
따라서 처음에 다시 null 값을 얻은 다음 재생을 누르면 이 고객이 캐시의 단일 항목으로 로드되어야 합니다. 하나의 항목만 로드됩니다. 이것을 한 번 더 실행하면 아무 것도 중지하지 않고 이번에는 캐시에서 이 고객 컬렉션을 가져옵니다. 따라서 98개의 목록 요소가 있지만 이것은 단일 항목 저장소인 고객의 고객 목록입니다. 따라서 이것은 하나의 옵션입니다. 결과 집합 캐싱에 관심이 있는 경우 전체 컬렉션을 하나의 항목으로 캐시할 수 있으며 이것이 컬렉션이고 항상 필요하며 다른 목록 구성원이나 결과 집합이 필요하지 않다는 것을 알고 있습니다. 당신은 하나의 항목이 아프지 않도록 저장에 관심이 있습니다. 그러나 대부분 소규모 컬렉션과 결과 집합 캐싱에 권장됩니다.
두 번째이자 가장 선호되는 접근 방식은 각 컬렉션 항목도 별도로 캐시하는 것입니다. 따라서 쿼리를 실행하고 Cosmos DB에 대해 API를 실행하고 많은 문서를 가져오고 해당 문서를 반복하고 개별적으로 저장한 다음 태그를 사용하여 논리적으로 그룹화합니다. 예를 들어, 우리는 바로 여기에서 이것을 하고 있습니다.
void GetCustomersByCity (string country)
{
//Retrieve all customers from NCache first
List<Customer> customers = new List<Customer>();
var tagByCountry = new Tag($"Customer:Country:{country}");
IDictionary<string, Customer> items = _NCacheClient.SearchService.GetByTags<Customer>(new[]{tagByCountry},
TagSearchOptions.ByAnyTag);
//If data is not in NCache then get from Cosmos DB and Cache it
if (items != null && items.Count > 0)
{
IDocumentQuery<Customer> query = _CosmosDbClient.CreateDocumentQuery<Customer>(
UriFactory.CreateDocumentCollectionUri(DatabaseId, CollectionId), new FeedOptions { MaxItemCount = -1,
EnableCrossPartitionQuery=true }).Where(c => c.Country == country
).AsDocumentQuery();예를 들어 코드를 보여주면 이것이 바로 여기 테스트 케이스입니다. 국가 이름을 입력하고 목록을 구성하고 런타임 매개변수 country를 사용하여 국가별로 태그를 구성한 다음 "_cache.SearchService"를 호출하고 검색 서비스의 일부로 OQL이 있는지 여부에 따라 일부 검사를 입력합니다. 우리도 가지고있다 연속 쿼리, LINQ도 있고 사용할 수 있는 다른 검색 메커니즘도 있습니다. 하지만 get by 태그를 사용하고 있습니다.
따라서 이미 개별적으로 캐시되어 있고 모든 개별 항목은 목록이 아니지만 태그를 사용하여 컬렉션에 넣을 수 있습니다. 따라서 해당 태그를 사용하여 전체 컬렉션을 다시 가져올 수 있습니다. 처음으로 캐시를 확인하고 반환하는 것을 찾으면 Cosmo DB로 이동하여 쿼리를 실행한 다음 각 고객에 대한 개별 고객 항목을 반복합니다. 캐시 항목을 구성하고 개별 항목에 태그를 첨부하고 이를 기반으로 캐시 항목에 저장합니다. NCache 또한 cache.InsertBulk를 사용하고 여기에 바로 가져오면 사례 번호 XNUMX이 바로 여기에 있습니다. 컬렉션을 호출하고 캐시 항목 목록과 cache.InsertBulk를 생성합니다.
자, 한 번 더 실행해 보겠습니다. XNUMX번 선택 항목을 제공하면 이 경우 캐시 수도 표시하겠습니다. 이번에는 국가 이름(예: UK)을 예상하고 처음 기준으로 목록을 구성합니다. 목록은 첫 번째 반복 이후에 비어 있으므로 Cosmos DB를 실행한 다음 캐시 항목을 구성하고 모든 항목을 반복합니다. 얼마나 많은지 봅시다. 나는 XNUMX에서 XNUMX이라고 생각하고 캐시에도 삽입되어 XNUMX과 XNUMX을 볼 수 있습니다. 그래서 대략 XNUMX개 항목에 대해 XNUMX개 항목이 개별적으로 추가되지만 국가별 태그라는 그룹이 있다고 생각합니다. 그리고 이것을 한 번 더 실행하면 이 코어 블록에 한 번 더 들어갔다는 의미입니다. 방금 말한 태그를 사용하여 모든 항목을 가져올 수 있어야 합니다. 괜찮은. 그리고 이번에는 개별적으로 저장되지만 태그로 분류되고 태그로 장식된 이 개별 항목을 모두 얻을 것으로 기대하고 있습니다. 그래서, 그 태그는 저에게 그 XNUMX개 항목을 모두 컬렉션으로 다시 가져와야 합니다. 따라서 그 일부로 고객 목록을 반환합니다. 따라서 고객의 IDictionary이며 고객을 반복할 수 있으며 재생을 누르면 캐시에서도 똑같은 응답을 계속해서 받습니다. NCache 이는 XNUMX개의 요청 단위에 대해서도 성능, 공간 측면에서 엄청난 개선이 될 것입니다. 이 샘플 애플리케이션의 경우 수백만 개의 요청이 들어오고 나가는 수백만 개의 문서가 있다고 생각하십시오. 따라서 컬렉션을 관리하고 단일 항목으로 컬렉션, 전체 또는 각 컬렉션 항목을 캐시에 별도로 저장하는 방법입니다.
Azure Cosmos DB를 사용한 업데이트 작업 캐싱
다음으로 Azure Cosmos DB를 사용한 업데이트 작업이 있습니다. 이것은 매우 간단합니다. 일부 문서를 추가해야 할 때마다 같은 줄에서 cache.add를 호출할 수 있습니다. 시간을 절약하기 위해 이것을 보여 드리겠습니다. 따라서 Cosmo DB에 "CreateDocumentAsync"라는 문서를 구성한 다음 cache.Insert를 호출합니다. 따라서 데이터베이스에 추가하고 캐시에도 추가하고 업데이트를 위해 항상 캐시에서 업데이트할 수 있고 Cosmos DB에서 업데이트한 다음 캐시에서도 업데이트할 수 있으며 삭제도 매우 간단합니다. "DeleteDocumentAsync"를 사용하여 Cosmos DB에서 제거한 다음 "cache.remove"도 호출합니다. 따라서 이 작업이 완료되어야 하며 이러한 예제가 정렬되어야 합니다. 따라서 다른 질문이 있는 경우 동기화인 다음 부분으로 넘어가겠습니다. 이 부분에도 시간이 걸립니다. 따라서 질문이 있으면 알려주세요. 그렇지 않으면 동기화에 대해 다루겠습니다. NCache Azure Cosmos DB를 사용합니다. Ron 우리는 질문을 잘하고 있습니다. 제품 소개를 잘 하셨다고 생각합니다. 질문이 오면 반드시 던질 것입니다.
Sync NCache Azure Cosmos DB 사용
확인. 동기화는 큰 측면입니다. 캐시와 데이터베이스의 서로 다른 두 위치에 데이터가 있고 그것이 우리가 주장한 것이기도 하면 Cosmos DB와 함께 캐시를 사용해야 합니다. 캐시에 변경 사항이 있을 때마다 해당 변경 사항을 데이터베이스에도 적용합니다. 업데이트가 있습니다. 해당 업데이트를 적용하세요. 삭제, 해당 삭제를 적용합니다. 그러나 Cosmos DB에서 데이터가 직접 변경되고 Cosmos DB가 다른 애플리케이션에 의해 업데이트되고 다른 커넥터와 데이터가 다른 소스에 의해 수집되고 애플리케이션이 해당 데이터를 읽기만 하는 가장 자연스러운 시나리오가 되는 경우 어떻게 됩니까? 응용 프로그램에서 업데이트되는 데이터는 Cosmos DB에서도 업데이트되지만 다른 응용 프로그램의 경우 Cosmos DB에서 직접 데이터가 변경됩니다.
그래서, 내가 무언가를 캐시했다면 어떻게 될까요? 이것을 가정하고 Cosmos DB에서 변경을 하고 그 변경은 바로 여기 Cosmos DB에서 이루어집니다. 그러나 데이터가 서로 다른 두 위치에 존재하고 이 두 소스가 동기화되지 않기 때문에 해당 변경 사항은 캐시에 반영되지 않습니다. 따라서 Azure Cosmos DB와 NCache 여기에서 사용한 개념은 Microsoft Azure 변경 피드 처리를 기반으로 합니다. 따라서 변경 피드 메커니즘이 있으며 이를 기반으로 시도할 수 있는 두 가지 옵션이 있습니다.
하나는 Cosmos DB 트리거가 있는 Azure 기능입니다. 따라서 암시적 변경 피드 처리입니다. 따라서 it0은 많은 백 작업을 수행하고 시작하기 위해 추가 및 업데이트를 관리하고 삭제에 대한 해결 방법을 제시할 수 있습니다. Microsoft는 이를 일시 삭제라고 주장합니다. 따라서 소프트 삭제 접근 방식을 사용할 수 있습니다. 이는 본질적으로 업데이트이지만 TTL(Time to Live) 첨부와 함께 일부 키워드가 첨부된 애플리케이션 내에서 일부 키워드를 사용할 수 있으며 이 항목이 더 이상 존재하지 않는다는 알림을 받을 수 있습니다. 코스모스 DB에 있을 것입니다.
두 번째 옵션은 변경 피드 프로세서를 명시적으로 구현하는 것입니다. Azure 함수에서 Cosmos DB 트리거를 사용하는 대신 이 인터페이스를 직접 구현합니다. 두 가지 예를 모두 나열했습니다. 먼저 Azure 기능에 중점을 두겠습니다.
Azure 함수 DB 트리거
따라서 Azure 기능 DB 트리거를 사용하면 이것은 매우 간단한 다이어그램입니다.
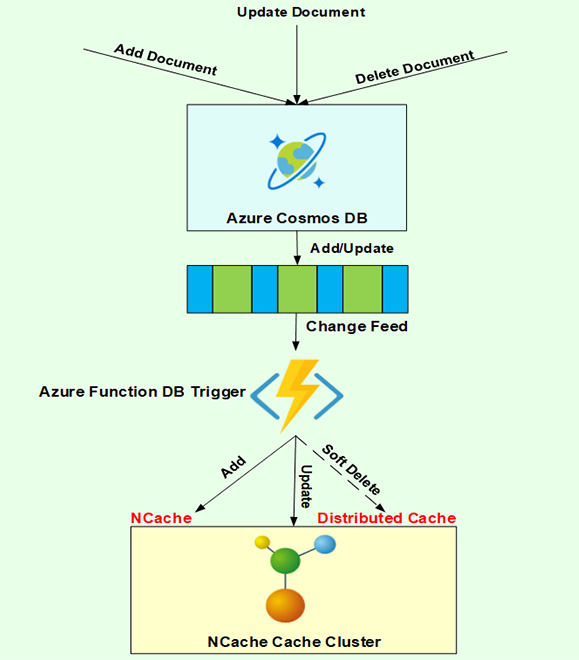
이번에도 Cosmos DB가 바로 여기에 있습니다. NCache 바로 여기에 있습니다. 귀하의 애플리케이션은 NCache 그리고 코스모스 DB나 여기 어딘가. 추가, 업데이트 또는 삭제되는 문서가 있으면 어떻게 합니까? 따라서 Microsoft Azure는 변경 피드를 구현하고 그 위에 프로세서를 기반으로 할 수 있습니다. 따라서 이 변경 피드는 추가 및 업데이트 이벤트를 관리합니다. Microsoft Azure Cosmos DB는 아직 삭제를 지원하지 않으며 DB 트리거로 Azure 기능을 구현할 수 있습니다. 다음과 같은 모든 소스에서 이러한 변경 사항을 추가하고 업데이트할 수 있습니다. NCache 구현하고 있습니다. NCache 추가, 업데이트 및 삭제 명령. 일시 삭제, 바로 다루겠습니다.
이것이 전체 구현입니다. 이 데모 후에는 Cosmos DB에 문서를 추가할 때마다 자동으로 반영되는 NCache. Cosmos DB에 자동으로 반영되는 업데이트가 있는 경우 NCache 마찬가지로 삭제가 있는 경우 삭제에 대한 관리도 있습니다. 따라서 이 두 소스를 서로 100% 동기화하면 데이터 불일치 문제가 없고 데이터가 최신 상태가 필요한 일관된 형식이어야 하는 애플리케이션에 큰 문제가 될 수 있습니다. 중요한 데이터이자 매우 민감한 데이터이기도 합니다. 그래서 그것이 우리가 제시하는 솔루션입니다.
따라서 먼저 DB 트리거가 있는 Azure 기능을 보여드리겠습니다.
[FunctionName("AzureFunction1")]
public static void Run([CosmosDBTrigger(
databaseName: "CosmosDbNCacheDemo",collectionName: "Customers",
ConnectionStringSetting = "CosmosDbConnection",
LeaseCollectionPrefix ="NCache-CosmosDbTrigger-",
LeaseCollectionName = "leases")]IReadOnlyList<Document> documents,
ILogger log)
{
using (var cache = CacheManager.GetCache("myCache"))
{
Customer customer = null;
foreach (var document in documents)
{
customer = new Customer{Address =
document.GetPropertyValue<string>("Address"),
City = document.GetPropertyValue<string>("City"),
CompanyName =document.GetPropertyValue<string>("CompanyName"),
ContactName =document.GetPropertyValue<string>("ContactName"),
Country = document.GetPropertyValue<string>("Country"),
CustomerID = document.GetPropertyValue<string>("CustomerID")
};따라서 캐시 이름이 다시 필요하며 이것이 구현입니다. Cosmos DB 트리거가 있습니다. 그냥 여기로 데려다 드리겠습니다. 따라서 임대 정보와 임대가 있는 것을 볼 수 있습니다. 임대라는 이름의 문서 저장소가 있습니다. 이름은 무엇이든 지정할 수 있으며 포인터를 가질 수 있습니다. 예를 들어 158이 마지막 포인터입니다. 따라서 많은 매개 변수가 있습니다. 따라서 체인 푸드 프로세서는 다른 것이지만 마지막 포인터로 158이 있습니다. 따라서 마지막으로 작동한 시간부터 메모리의 모든 업데이트를 추적합니다. 따라서 해당 변경 사항을 모니터링한 마지막 시간부터 추가 및 업데이트된 모든 문서 모음이 있습니다. 따라서 Cosmo DB가 지속적으로 정보를 푸시하고 해당 정보가 메모리에 유지되고 Cosmos DB에도 참조가 있는 변경 피드 관찰자 패턴을 기반으로 합니다.
이에 대한 샘플 구현은 다음과 같습니다. Azure 기능을 다시 가져오면. 따라서 이 Cosmos DB 트리거가 필요합니다. 물론 데이터베이스 이름이 필요합니다. 변경 피드를 통해 모니터링하려는 컬렉션입니다. 연결 문자열과 임대 컬렉션 접두사는 임대 문서 내에 넣은 다음 임대 컬렉션이라는 이름의 임대 컬렉션입니다. 그리고 여기에도 내 캐시 이름이 필요합니다. 예를 들어, 그 이름은 Democache를 사용하고 있으며 이 컬렉션의 모든 고객이 해당 고객 개체를 구성한 다음 cache.InsertAsync를 호출하도록 하는 것입니다. 이것이 비동기 호출의 작업입니다. 그래서, 당신은 그것을 사용할 수 있으며 삭제에 대해 조금 이야기하겠습니다. 그러나 먼저 삽입 부분을 검토합시다.
따라서 이 앱을 실행하면 변경 사항을 기다릴 것입니다. 해당 변경 피드 메커니즘을 사용하고 해당 임대 내에서 마지막 시간부터 추가 및 업데이트된 모든 문서를 기다리고 해당 추가 및 업데이트를 기반으로 NCache API 호출도 가능합니다. 자, 이만 실행하겠습니다. 디버깅하는 데 시간이 좀 걸립니다. 나는 재건될 것이고 그 후에 이것들을 적용할 수 있을 것이다. 나는 이것을 위해 어떤 로거도 구현하지 않았습니다. 따라서 샘플 구현에 따라 일부 로거 오류가 발생할 수 있습니다. 그러나 그와 함께 일부 로깅 세부 정보를 구현할 수도 있습니다. 제 목적을 위해 사용한 완전한 코드입니다. 따라서 데모가 끝날 때에도 공유할 수 있습니다. 이것이 제 Azure 기능입니다. 일부 매개변수가 누락되어 null 값이 표시되지만 전반적으로 동기화 작업이 완료됩니다. NCache Cosmos DB에 변경 사항이 발생하는 경우.
그 동안 제가 변경할 문서를 준비하겠습니다. Ross123은 우리가 처음에 만든 것이기 때문에 사용합시다. 일부 값을 추가한다고 가정해 보겠습니다. 지금 실행 중인지 확인하겠습니다. 예, 실행 중이며 대기 모드입니다. 따라서 호스트가 초기화되고 응용 프로그램이 시작되었습니다. 내가 놀고 있었기 때문에 마지막으로 실행하는 기능도 일부 변경되었습니다. 그래서, 그것을 완료하자. 가세요. 내가 업데이트 한 Ross123을 돌보고 있습니다. 그래서 그 임대 문서가 업데이트되었습니다.
따라서 캐시의 내용을 한 번 더 지우고 다시 시작하겠습니다. 따라서 캐시에 항목이 없으며 이는 실행 중인 상태입니다. 그래서 여기에 그대로 두고 이번에는 Cosmos DB를 열어서 국가 끝에 문자를 추가해 보겠습니다. UK를 여러 번 가정한 다음 Ross123, 일부 임의의 문자열도 도시에 추가한다고 가정해 보겠습니다. 여기에서 업데이트를 누르면 Cosmos DB도 트리거되고 Ross123 UK UK로 이동하는 것을 볼 수 있습니다. Ross123 44. 그래서, 그것은 그 임대 수집품을 사용하게 될 것이고, 그리고 그것은 실제로 그 기능을 실행하고 그것이 한 일은 바로 여기에 해당 고객을 추가했다는 것입니다. . 따라서 Ross123을 보면 디버그가 있기 때문에 재생을 눌러야 합니다. 그것은 내가 구현하지 않은 로거입니다. 여기에는 임의의 문자가 추가된 Ross123 444 및 Ross123이 있어야 합니다. 그래서 Cosmos DB용 Azure 기능을 구현하는 것은 간단합니다.
Ron, Azure 기능에 대한 질문이 있는데 Azure 기능으로 반드시 사용해야 하는 기능이며 이와 관련된 비용은 얼마입니까? Azure 기능은 필수 사항이 아닙니다. 다음에 설명할 다른 접근 방식도 사용할 수 있습니다. 변경 필드 옵저버의 옵저버를 직접 구현할 수 있습니다. 인터페이스입니다. 모든 방법을 구현하고 Azure 기능에서 Azure Cosmos DB 트리거를 사용하지 마십시오. 그래서, 그것은 또 다른 옵션입니다. 따라서 필수 사항은 아닙니다. 유일한 옵션은 아닙니다. Azure 기능은 Microsoft Azure에서 호스팅됩니다. 따라서 그에 따른 비용도 발생합니다. 그러나 그 문제에 대해서는 최소한입니다. 사용법은 간단하지만 유일한 옵션은 아닙니다.
삭제의 경우 여기에 추가 및 업데이트가 포함됩니다. 새 문서를 추가하면 자동으로 여기로 가져와야 합니다. 추가 및 업데이트를 사용하고 있기 때문에 계속 실행해야 합니다. 임대 컬렉션은 같은 줄에서 업데이트되지만 삭제는 Microsoft에서 일시 삭제를 사용하도록 권장하고 업데이트를 대안으로 사용해야 한다고 권장하는 경우입니다. 키워드, 임의의 키워드를 사용하십시오. 예를 들어 이것은 문서 내에서 삭제되고 Microsoft Azure Cosmos DB에서 삭제하는 대신 이 속성을 사용합니다. 임의의 삭제, 폐기 및 TTL을 사용한 다음 업데이트합니다. 그리고 이를 바탕으로 한 번 더 실행하고 코드도 보여주면 됩니다. 이 작업이 수행되는 작업은 속성이 삭제된 문서가 있는 것으로 확인되면 캐시를 호출하거나 문서에서 제거하고 해당 TTL을 기반으로 데이터베이스에서 제거되지만 캐시에서는 제거됩니다. 곧.
그래서, 저는 이것을 실행할 것입니다. 제 생각에는 이미 실행되고 있다고 생각합니다. 예, 그렇습니다. 오류 코드가 있지만 그것이 로거입니다. 여기에서 변경하고 이 문서를 업데이트하면 캐시에도 적용됩니다. 함수 고객 Ross123도 캐시에서 삭제되었습니다. 내가 바로 여기에 오면 캐시에 없는 것을 볼 수 있습니다. 이제 다음은 TTL이 있다는 것입니다. 따라서 10초 후에 Ross123을 여기에서 제거해야 합니다. 따라서 Microsoft Azure는 삭제 관리를 권장합니다. 현재로서는 변경 피드 관찰자를 위한 유일한 옵션은 추가 및 업데이트입니다. 따라서 삭제는 일시 삭제해야 하며 Microsoft 권장 사항을 기반으로 권장하는 해결 방법이기도 합니다.
피드 프로세서 변경
다음 세그먼트는 변경 피드 프로세서를 통해 Cosmos DB와 캐시를 동기화하는 것입니다. 그래서 Azure 기능이 유일한 옵션이 아니라는 질문이 있었습니다. 변경 피드 프로세서를 직접 사용할 수도 있으며 이것이 구현하는 IChangeFeedObserver 인터페이스입니다. 이에 대한 코드를 보여드리겠습니다.
namespace Microsoft.Azure.Documents.ChangeFeedProcessor.FeedProcessing
{
public interface IChangeFeedObserver
{
Task CloseAsync(IChangeFeedObserverContext context,
ChangeFeedObserverCloseReason reason);
Task OpenAsync(IChangeFeedObserverContext context);
Task ProcessChangesAsync(IChangeFeedObserverContext context,
IReadOnlyList<Document> docs);
}
}비교하여 훨씬 더 많은 제어를 제공합니다. 예를 들어 여기가 제 공장입니다. 그래서 IChangeFeedObserverFactory를 구현했습니다. 여기서부터 보여드리겠습니다. 좋습니다. 여러 가지 방법이 있습니다. 이 IChangeFeedObserver를 구현했습니다. 연결을 닫는 방법이 있습니다. 컬렉션을 여는 메서드가 있고 캐시를 초기화하고 닫을 때 실제로 cached.Dispose를 호출하여 리소스를 폐기한 다음 기본 메서드는 ProcessChangesAsync입니다. 따라서 IChangeFeedObserver Context, 목록, 취소 토큰 및 몇 가지 기본 사항이 있습니다. 그래서, 제가 여기서 정말로 하고 있는 것은 이 문서 컬렉션, 문서 목록 내에서 그것을 파악하는 것입니다. 그것이 나와 공유될 것입니다. 그래서 ChangeFeedObserverFactory가 모든 관련 리소스를 가져오는 방식으로 구현했으며 이를 기반으로 내가 제공한 모든 임대 정보와 문서 정보를 기반으로 삭제, 추가 및 업데이트를 빠르게 처리할 수 있습니다. 그래서 이번에는 업데이트를 보여드리고 이를 통해 유스케이스도 추가하고 업데이트 후 삭제를 하고 데모를 마치도록 하겠습니다.
따라서 이것은 IChangeFeedObserver의 명시적 구현입니다. Cosmos DB 트리거의 도움으로 Microsoft Azure 기능에서 사용하는 것입니다. 따라서 Cosmos DB 트리거는 이를 자동으로 구현하므로 더 쉽지만 Azure 기능이 있어야 합니다. 그러나 응용 프로그램에서 처리해야 하는 경우 이를 직접 구현할 수 있습니다. 그래서 캐시가 시작되었습니다. 실제로 다른 캐시를 사용하고 있었는지 확인해 보겠습니다. 검색해 보겠습니다. 그런데 여기에 모든 세부 정보, Cosmo DB 데모, 임대 문서 및 내가 모니터링하려는 고객 문서를 제공하고 모든 매개변수를 여기에서 설정하고 있습니다. democache, save 및 그것을 실행하고 이번에는 문서를 추가하고 업데이트하고 삭제하고 그에 따라 캐시에 적용될 것임을 보여줍니다.
내가 실행하자 CRUD 작업 뿐만 아니라 우리가 가지고 있습니다. Azure 기능을 종료하고 종료합니다. 이것은 이미 추가되었습니다. 자, 여기 내 캐시가 있습니다. 참조를 유지하기 때문에 이미 하나의 문서가 있습니다. 나는 그것을 없애고 싶다. 우리가 새롭게 시작할 수 있도록 이번에는 Cosmo DB에 뭔가를 추가할 것이고 당신은 캐시에서 즉시 그것을 얻을 수 있어야 하고 여기에서 볼 수 있다. 나는 그냥 복사할 것이다. 이것. 새 문서입니다. 여기에 붙여넣자. Ross123 대신에 Ron1122라고 말하고 여기에도 같은 필드를 지정하겠습니다. 이 문서는 이미 삭제되었으므로 일부 값을 업데이트하는 것이므로 문제가 되지 않습니다. 그리고 우리가 좋은 것 같아요. 알겠습니다. 저장합니다. 그래서, 이 문서는 바로 여기 Ron1122이고, 변경 피드 옵저버를 보여주면 자동으로 처리됩니다. 이제 캐시에서 이것을 보기만 하면 됩니다. 우선, 그것은 캐시에 있었습니다. 따라서 캐시에 있으면 어쨌든 캐시에서 로드됩니다. 그래서, 나는 Ron1122라고 말할 것이고 당신은 볼 수 있습니다, 제 생각에 제가 ID를 엉망으로 만든 것 같습니다. Ron1122입니다. 가세요. 따라서 동일한 항목이 있습니다.
이제 업데이트된 사용 사례도 볼 수 있도록 업데이트하겠습니다. 다시, 나는 도시 내의 몇몇 캐릭터를 업데이트할 것입니다. NYK NYK라고 가정해 보겠습니다. 이번에는 UK 대신 USA USA USA라고 하겠습니다. 따라서 업데이트가 적용되고 임대로 이동하고 이를 기반으로 자동으로 적용되어야 합니다. 이 문제를 얼마나 즉각적으로 처리하는지 보십시오. 따라서 이것을 한 번만 더 실행하고 고객 ID Ron1122를 제공하면 NYK NYK USA 및 USA와 함께 업데이트된 값을 바로 여기에서 볼 수 있습니다.
삭제를 위해서는 소프트 삭제인 삭제됨을 다시 사용해야 하며 이를 위해 임의 속성을 추가하기만 하면 됩니다. 그건 그렇고 어떤 속성이 될 것이며 약간의 TTL도 제공합니다. 예를 들어, 업데이트해야 하는 TTL 10으로 삭제되었지만 내 코드에는 삭제된 키워드에 대한 처리가 있고 TTL(time-to-live)은 내가 찾는 즉시 Cosmo DB 및 삭제된 키워드에서 삭제를 처리하기 때문에 제거합니다. 하나, 내 응용 프로그램이 Cosmo DB에서 이 문서를 제거하는 방식으로 설계되었다는 것을 알고 있습니다. 따라서 캐시에서 제거해야 합니다. 따라서 Cosmos DB에 대한 일시 삭제이며 바로 여기에서 알아차리면 알 수 있습니다. 다음 키가 삭제되어 더 이상 캐시에 존재하지 않습니다. 주어진 ID로 항목을 입력해야 하는 경우 존재하지 않습니다. 따라서 다음을 사용하면 오래된 데이터를 제공하지 않습니다. NCache 이 두 가지 접근 방식으로.
자, 빨리 요약하겠습니다. 샘 XNUMX분만 더 할게요. 그래서 우리는 처음에 데이터 캐싱, 가져오기 작업에 대해 이야기했습니다. 간단한 API로 시작할 수 있습니다. 문서 가져오기에 관한 한 cache.Get을 호출하십시오. 먼저 캐시에서 확인하고 찾지 말고 Cosmos DB에서 가져와 캐시에 추가합니다. 따라서 사이클이 완료됩니다. 컬렉션, 캐시 전체 컬렉션은 하나의 항목이거나 각 컬렉션 항목을 개별적으로 캐시하고 이 두 가지 접근 방식의 장점에 대해 이야기한 다음 가장 중요한 측면은 이 동일한 API를 통한 추가, 업데이트입니다. 동기화 중 NCache 코스모스DB로 가능합니다. 꽤 직관적입니다. DB 트리거가 있는 Azure 기능 또는 명시적으로 구현된 IChangeFeedObserver 인터페이스의 두 가지 옵션이 있습니다. 따라서 두 가지 접근 방식이 모두 논의되었으며 이 중에서 선택할 수 있습니다.
끝을 향해, NCache 고가용성, 선형 확장성, 매우 안정적인 .NET 분산 캐시입니다. 우리는 많은 캐싱 토폴로지를 가지고 있습니다. 클라이언트 캐시, WAN 복제 브리지. 따라서 Microsoft Azure Cosmos DB 온프레미스, 클라우드 내 및 온프레미스에 사용할 수 있습니다. 따라서 그 일부로 다양한 옵션을 사용할 수 있습니다. 질문이 있으면 알려주세요. 기술 세부 사항에 관한 한 그렇지 않으면 Sam에게 전달하겠습니다.
Ron, 우리가 다루었던 질문이 있습니다. 그러나 질문은 더 추천하시겠습니까? 더 추천할 수 있는 옵션은 무엇입니까? IChangeFeed 또는 Azure 기능? 당신은 그것에 대해 이야기했지만 그것에 대해 조금이라도 밝히고 싶다면. 물론, 그건 그렇고 논쟁입니다. 사용 편의성을 원한다면 Azure 기능이 더 편하고 구성 요소를 사용하고 제어하려는 개발자라면 IChangeFeedObserver 인터페이스가 연결을 열 때 완전히 제어할 수 있기 때문입니다. , 연결을 닫고 적용합니다. 따라서 더 많은 제어를 원하면 IChangeFeedObserver를 사용하고 사용자 정의 구현을 사용하십시오. 사용 편의성을 원하시면 DB 트리거와 함께 Azure 기능을 사용하십시오.
네, 또 다른 질문이 있습니다. NCache 건축과 일? 예, 있습니다. 녹화된 웨비나에는 사용 가능한 웨비나 시리즈가 있으며 웨비나 중 하나는 실제로 NCache 건축물. 그래서, 당신은 그것을 볼 수 있습니다. 그리고 이 모든 것은 우리 웹사이트에서 사용할 수 있습니다. Ron? 예, 사실, 이 녹음은 앞으로 며칠 안에 게시될 예정입니다. 좋아, 완벽해. 그래서 우리에게 주어진 시간은 단 XNUMX분입니다. 그럼, 여러분 모두 함께 해주셔서 정말 감사합니다. 도움이 되었기를 바랍니다. 우리는 가능한 한 많은 질문에 답하려고 노력합니다. 추가 질문이 있는 경우 다음 연락처로 문의하세요. support@alachisoft.com. 당신이 우리를 원한다면 개인화 된 데모 예약, 우리는 또한 당신을 위해 그렇게 하는 것을 기쁘게 생각합니다. 영업 관련 질문이 있는 경우 언제든지 영업 팀에 문의할 수 있습니다. sales@alachisoft.com. 그런 의미에서 함께 해주신 모든 분들께 다시 한 번 감사의 말씀을 드립니다. 질문이 있는 경우 저희에게 연락하고 시간을 내주셔서 감사합니다. 감사합니다. 좋은 하루 보내세요.