XNUMX가지 이유 NCache 보다 낫다 Redis
녹화된 웨비나
이크발 칸
어떻게하는지 배우다 Redis 과 NCache 기능 수준에서 서로 비교합니다. 이 웨비나의 목표는 두 제품을 더 쉽고 빠르게 비교하는 작업을 만드는 것입니다.
웨비나는 다음 내용을 다룹니다.
- 다른 제품 기능 영역.
- 지원이 하는 일 Redis 과 NCache 각 기능 영역에서 제공합니까?
- 의 강점은 무엇입니까 NCache 위에 Redis 그 반대?
NCache .NET용으로 널리 사용되는 오픈 소스(Apache 2.0 라이선스) 인메모리 분산 캐시입니다. NCache 응용 프로그램 데이터 캐싱, ASP.NET 세션 상태 저장 및 이벤트를 통한 게시/구독 스타일 런타임 데이터 공유에 일반적으로 사용됩니다.
Redis 또한 데이터베이스, 캐시 및 메시지 브로커로 사용되는 인기 있는 오픈 소스(BSD 라이선스) 인메모리 데이터 구조 저장소입니다. Redis Linux에서 매우 인기가 있지만 최근 Microsoft가 홍보하여 Azure에서 주목을 받았습니다.
살펴보기
안녕하세요 여러분, 제 이름은 Iqbal Khan이고 기술 전도사입니다. Alachisoft. Alachisoft 샌프란시스코 베이 지역에 기반을 둔 소프트웨어 회사이며 인기 있는 NCache .NET용 오픈 소스 분산 캐시인 제품. Alachisoft 의 제작자이기도 합니다. NosDB.NET용 오픈 소스 SQL 데이터베이스가 없습니다. 오늘은 XNUMX가지 이유에 대해 이야기 해보려고 합니다. NCache 보다 더 Redis .NET 애플리케이션용. Redis, 아시다시피 에 의해 개발되었습니다. Redis 실험실에서 Azure용으로 Microsoft에서 선택했습니다. 뽑게 된 가장 큰 이유는 Redis 다중 플랫폼 지원과 다양한 언어를 제공하는 반면 NCache 순전히 .NET에 중점을 둡니다. 시작하겠습니다.
분산 캐시
비교를 시작하기 전에 먼저 분산 캐싱이 무엇인지, 왜 필요한지, 어떤 문제를 해결하는지 간략하게 소개하겠습니다. 분산 캐싱은 실제로 애플리케이션 확장성을 개선하는 데 사용됩니다. 아시다시피 웹 응용 프로그램이나 웹 서비스 응용 프로그램 또는 서버 응용 프로그램이 있는 경우 응용 프로그램 계층에 서버를 더 추가할 수 있습니다. 일반적으로 애플리케이션 아키텍처를 통해 이를 매우 원활하게 수행할 수 있습니다. 그러나 특히 관계형 데이터베이스나 레거시 메인프레임 데이터를 사용하는 경우 데이터베이스 계층에서 동일한 작업을 수행할 수 없습니다. SQL 없이 그렇게 할 수 있습니다. 그러나 대부분의 경우 기술 및 비즈니스상의 이유로 관계형 데이터베이스를 사용해야 합니다.
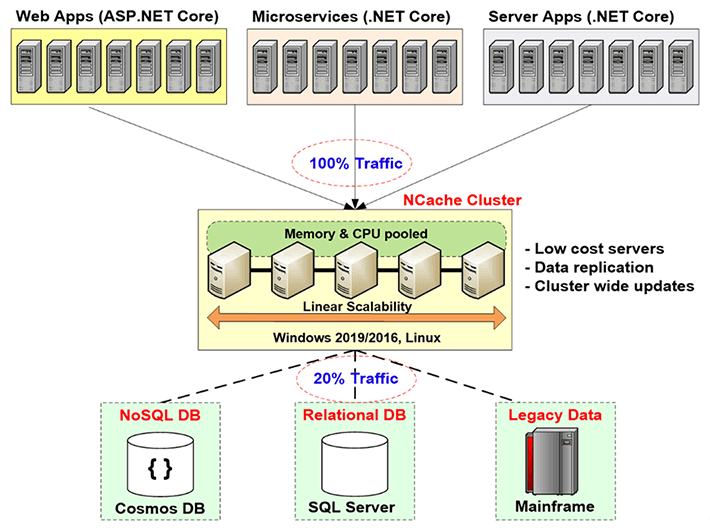
따라서 관계형 데이터베이스 또는 레거시 메인프레임이 제공하는 이러한 확장성 병목 현상을 분산 캐싱을 통해 해결해야 하며 이를 수행하는 방법은 애플리케이션 계층과 데이터베이스 사이에 캐싱 계층을 생성하는 것입니다. 이 캐싱 계층은 두 개 이상의 서버로 구성됩니다. 이들은 일반적으로 저렴한 서버입니다. 의 경우 NCache, 일반적인 구성은 16~32Gig의 RAM과 1~10기가비트 속도의 네트워크 카드 XNUMX~XNUMX개를 포함하는 듀얼 CPU, 쿼드 코어 시스템입니다. 이러한 캐싱 서버는 다음과 같은 경우 TCP 기반 클러스터를 형성합니다. NCache 이러한 모든 서버의 리소스를 하나의 논리적 용량으로 함께 풀링합니다. 이렇게 하면 애플리케이션 계층이 성장함에 따라 트래픽이 증가하거나 트랜잭션 로드가 많아지면 애플리케이션 계층에 더 많은 서버를 추가할 수 있습니다. 캐싱 계층에서 더 많은 서버를 추가할 수도 있습니다. 일반적으로 응용 프로그램 계층과 캐싱 계층 간의 비율을 4:1 또는 5:1로 유지합니다.
따라서 이 때문에 분산 캐시는 결코 병목 현상이 되지 않습니다. 따라서 여기에서 애플리케이션 데이터 캐시를 시작하고 데이터베이스에 대한 트래픽을 줄일 수 있습니다. 목표는 트래픽의 약 80%를 캐시로 이동하고 일반적으로 업데이트인 트래픽의 약 20%를 데이터베이스로 이동하는 것입니다. 그렇게 하면 애플리케이션이 확장성 병목 현상에 직면하지 않습니다.
분산 캐시의 일반적인 사용
좋습니다. 분산 캐싱의 이점을 염두에 두고 여러분이 알고 있는 다양한 사용 사례, 분산 캐시를 사용할 수 있는 다양한 상황에 대해 이야기해 보겠습니다.
애플리케이션 데이터 캐싱
첫 번째는 애플리케이션 데이터 캐싱으로, 성능과 확장성을 향상시킬 수 있도록 데이터베이스에 있는 데이터를 캐싱하는 위치에서 방금 설명한 것과 동일합니다. 애플리케이션 데이터 캐싱에 대해 염두에 두어야 할 주요 사항은 이제 데이터가 두 위치에 있다는 것입니다. 그것은 마스터 데이터 소스인 데이터베이스에 존재하며 캐싱 계층에도 존재합니다. 그런 일이 발생할 때 명심해야 할 가장 중요한 것은 가장 큰 걱정거리가 , 캐시가 오래되지 않습니까? 데이터베이스에서 데이터가 변경된 경우에도 캐시에 이전 버전의 데이터가 저장됩니까? 그런 상황이 발생하면 당연히 큰 문제가 발생하고 많은 사람들이 데이터 무결성 문제에 대한 두려움 때문에 읽기 전용 데이터만 캐시합니다. 읽기 전용 데이터는 캐싱해야 하는 전체 데이터의 아주 작은 하위 집합이며 데이터의 약 XNUMX~XNUMX%입니다.
실제 이점은 트랜잭션 데이터 캐시를 시작할 수 있다는 것입니다. 이것은 고객, 활동, 기록, 런타임에 생성되고 매우 자주 변경되는 모든 종류의 데이터입니다. 해당 데이터를 계속 캐시해야 하지만 캐시가 항상 캐시되는 방식으로 캐시해야 합니다. 신선하게 유지됩니다. 이것이 첫 번째 사용 사례이고, 우리는 그것에 대해 다시 돌아올 것입니다.
ASP.NET 특정 캐싱
두 번째 사용 사례는 세션 상태, 보기 상태 및 MVC 프레임워크 및 페이지 출력이 없는 경우를 캐시하는 ASP.NET 특정 캐싱에 대한 것입니다. 이 상황에서 캐시는 데이터베이스보다 훨씬 빠르고 확장 가능한 저장소이기 때문에 세션 상태를 캐싱하는 것입니다. 과도 현상. 일시적이라는 것은 본질적으로 일시적임을 의미합니다. 그것은 당신이 그것을 버리고 데이터가 캐시에만 존재하는 짧은 시간 동안만 필요합니다. 캐시는 마스터 저장소입니다. 따라서 이 사용 사례에서 걱정거리는 캐시가 데이터베이스와 동기화되어야 한다는 것이 아니라 캐시 서버가 다운되면 일부 데이터가 손실된다는 것입니다. 알다시피 메모리는 모두 인메모리 스토리지이며 메모리는 휘발성이기 때문입니다. 따라서 우수한 분산 캐시는 지능적인 복제 전략을 제공해야 합니다. 따라서 모든 데이터 조각이 둘 이상의 서버에 존재합니다. 하나의 서버가 다운되더라도 데이터는 손실되지 않지만 복제에는 관련 비용, 성능 비용이 있습니다. 따라서 복제는 초고속이어야 합니다. NCache 그건 그렇고.
런타임 데이터 공유
세 번째 사용 사례는 캐시를 본질적으로 데이터 공유 플랫폼으로 사용하는 런타임 데이터 공유 사용 사례입니다. 따라서 다양한 애플리케이션이 캐시에 연결되어 Pub/Sub 모델에서 데이터를 공유할 수 있습니다. 따라서 한 응용 프로그램이 데이터를 생성하고 캐시에 넣고 이벤트를 실행하면 해당 이벤트에 관심을 등록한 다른 응용 프로그램에 알림이 전송되어 해당 데이터를 사용할 수 있습니다. 따라서 다른 이벤트도 있습니다. 키 기반 이벤트, 캐시 수준 이벤트, 다음을 수행하는 연속 쿼리 기능이 있습니다. NCache 가지다. 따라서 다음과 같은 분산 캐시를 사용할 수 있는 여러 가지 방법이 있습니다. NCache 다른 응용 프로그램 간에 데이터를 공유합니다. 이 경우에도 데이터베이스에 있는 데이터로 데이터를 생성하더라도 공유되는 형태는 캐시에만 존재할 수 있다. 따라서 캐시가 데이터를 복제하는지 확인해야 합니다. 따라서 문제는 ASP.NET 캐싱의 경우와 동일합니다. 따라서 분산 캐시 사용에 공통적인 세 가지 사용 사례가 있습니다. 다음과 같은 기능을 비교할 때 이러한 사용 사례를 염두에 두십시오. NCache 제공하는 Redis 하지 않습니다.
이유 1 - 캐시를 최신 상태로 유지
그래서, 당신이 사용해야하는 첫 번째 이유, NCache 위에 Redis 그게 NCache 캐시를 최신 상태로 유지하는 매우 강력한 기능을 제공합니다. 우리가 이것에 대해 이야기했듯이 캐시를 최신 상태로 유지할 수 없으면 읽기 전용 데이터를 캐시해야 하고 읽기 전용 데이터를 캐시하면 그것이 진정한 이점이 아닙니다. 따라서 거의 모든 데이터를 캐시할 수 있어야 합니다. 10~15초마다 바뀌는 데이터라도.
절대 만료 / 슬라이딩 만료
따라서 캐시를 최신 상태로 유지하는 첫 번째 방법은 만료를 통하는 것입니다. 만료는 둘 다 NCache 과 Redis 제공하다. 따라서 예를 들어 캐시에 10분, 2분 또는 1분 후에 이 데이터를 만료하라고 지시하는 절대 만료가 있습니다. 그 시간이 지나면 캐시가 캐시에서 해당 데이터를 제거하고 추측을 하게 됩니다. 알다시피, 이 데이터를 캐시에 오랫동안 보관하는 것이 안전하다고 생각합니다. 데이터베이스의 변경. 따라서 그 추측을 기반으로 캐시에 데이터를 만료하도록 지시하는 것입니다.
만료는 다음과 같습니다. 제가 보여드릴 것이 있습니다. 의 경우 NCache, 설치할 때 NCache 그건 그렇고, 그것은 당신에게 많은 샘플을 제공합니다. 그래서 샘플 중 하나를 기본 작업이라고 하며 여기에서 열었습니다. 따라서 기본 작업에서 간단히 설명하겠습니다. 일반적인 .NET 응용 프로그램이 사용하는 방법은 다음과 같습니다. NCache 보이는 군.
당신은 링크 NCache 런타임에 NCache.Web 어셈블리를 사용하면 NCache.실행 시간 네임스페이스, NCache.웹.캐싱 네임스페이스로 이동한 다음 애플리케이션 시작 시 캐시에 연결합니다. 모든 캐시에 이름이 지정됩니다.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...캐시를 만드는 방법을 알고 싶다면 다음을 시청하십시오. 비디오 시작하기. 저희 웹사이트에서 확인하실 수 있습니다. 그러나 이 캐시에 연결했기 때문에 캐시 핸들이 있다고 가정해 보겠습니다. 이제 몇 가지 개체로 구성된 데이터를 만든 다음 수행합니다. 캐시.추가. 캐시.추가 에는 문자열인 키와 객체인 실제 값이 있으며 이 경우에는 XNUMX분의 절대 만료를 지정합니다. 그래서, 당신은 지금부터 XNUMX분 후에 이 개체를 만료한다고 말하고 있습니다. NCache 이 개체를 만료합니다. 그래서, 그것이 만료가 작동하는 방식입니다. 물론 제가 말했듯이, Redis 도 제공합니다.
데이터베이스와 캐시 동기화
그러나 만료 문제는 정확하지 않거나 정확하지 않을 수 있는 추측을 하고 있다는 것입니다. 따라서 데이터가 지정한 XNUMX분 전에 XNUMX분 전에 변경되면 어떻게 될까요? 따라서 캐시를 데이터베이스와 동기화라는 다른 기능이 필요합니다. 이 기능은 NCache 가지고 있고 Redis 이 없습니다.
그래서, NCache 여러 가지 방법으로 그렇게합니다. 첫 번째 숫자는 SQL 종속성. SQL 종속성은 ADO.NET을 통한 SQL 서버의 기능입니다. 여기서 기본적으로 SQL 문을 지정하고 SQL 서버에 알리고 이 데이터 세트를 모니터링하고 이 데이터 세트가 변경되면 행이 추가된다는 의미입니다. , 이 데이터 세트 기준과 일치하는 업데이트 또는 삭제된 항목이 있으면 알려주세요. 따라서 데이터베이스에서 데이터베이스 알림을 보내면 적절한 조치를 취할 수 있습니다. 그래서, 방법 NCache 이것은 무엇입니까, NCache SQL 종속성을 사용하고 Oracle과 동일한 작업을 수행하는 Oracle 종속성도 있습니다. 둘 다 데이터베이스 이벤트와 함께 작동합니다. 그래서, NCache SQL 종속성을 사용합니다. 여기서 그 코드를 보여드리겠습니다. 따라서 SQL 종속성 코드로 이동하겠습니다. 다시 말하지만, 동일한 방식으로 일부 어셈블리와 연결합니다. 캐시 핸들을 얻었고 이제 항목을 추가하고 있으므로 여기로 이동하고 정의로 이동합니다. 이제 이 데이터를 추가하고 있으므로 추가의 일부로 SQL 종속성을 지정합니다. 따라서 캐시 종속성은 NCache 데이터베이스에 대한 연결 문자열을 사용하는 클래스입니다. SQL 문이 필요합니다. 이 경우 제품 ID가 이 ID인 SQL 문을 원한다고 가정해 보겠습니다. 따라서 제품 개체를 캐싱하므로 제품 테이블의 해당 행과 일치시킵니다. 그래서, 당신은 말하고 있습니다, 당신은 말하고 있습니다 NCache SQL 서버와 대화하고 SQL 종속성을 사용하여 SQL 서버가 이 명령문을 모니터링할 수 있도록 하고 이 데이터가 변경되면 SQL 서버가 알립니다. NCache.
이제 캐시 서버가 데이터베이스의 클라이언트가 되었습니다. 따라서 캐시 서버는 이 데이터 세트가 변경되고 해당 데이터 세트가 변경되면 SQL 서버가 캐시 서버와 NCache 그런 다음 서버는 캐시에서 해당 항목을 제거하고 제거하는 이유는 한 번 제거하면 다음에 필요할 때 캐시에서 찾을 수 없고 데이터베이스에서 강제로 가져와야 하기 때문입니다. 그래서, 당신은 일종의 새로 고침 방법입니다. 잠시 후에 이야기할 항목을 자동으로 다시 로드하는 또 다른 방법이 있습니다.
따라서 SQL 종속성은 NCache 캐시를 데이터베이스 및 Oracle 종속성과 실제로 동기화하려면 SQL 서버 대신 Oracle에서 작동한다는 점을 제외하고는 정확히 동일한 방식으로 작동합니다. SQL 종속성은 정말 강력하지만 수다스럽기도 합니다. 예를 들어, 10,000개 항목 또는 100,000개 항목이 있는 경우 100,000개의 SQL 종속성을 생성하여 모든 SQL 종속성에 대해 SQL 서버 데이터베이스가 데이터 구조를 생성하고 서버가 그 데이터를 모니터링하는 것은 추가 오버헤드입니다.
따라서 동기화할 데이터가 많다면 DB 종속성에만 의존하는 것이 더 나을 수 있습니다. DB 종속성은 SQL 문 및 데이터베이스 이벤트를 사용하는 대신, NCache 실제로 데이터베이스를 가져옵니다. 당신이 만드는 특별한 테이블이 있습니다. NCache DB 동기화 후 트리거를 수정하여 이 캐시된 항목에 해당하는 행의 플래그를 업데이트한 다음 NCache 기본적으로 15초 정도마다 이 테이블을 자주 가져온 다음 변경된 행을 찾으면 캐시에서 해당 캐시 항목을 무효화할 수 있습니다. 따라서 이들 모두와 물론 DB 종속성은 모든 데이터베이스에서 작동할 수 있습니다. SQL 서버, Oracle뿐만 아니라 DB2, MySQL 또는 기타 데이터베이스가 있는 경우에도 마찬가지입니다.
따라서 이러한 기능을 조합하면 캐시가 항상 데이터베이스와 동기화되고 거의 모든 데이터를 캐시할 수 있다는 확신을 가질 수 있습니다. CLR 저장 프로시저인 세 번째 방법이 있으므로 실제로 CLR 저장 프로시저를 구현할 수 있습니다. 거기에서 당신은 만들 수 있습니다 NCache 전화. 따라서 데이터베이스 트리거에서 저장 프로시저를 호출합니다. 고객 테이블이 있고 실제로 업데이트 트리거 또는 삭제 트리거 또는 추가 트리거가 있다고 가정해 보겠습니다. CLR 절차의 경우 새 데이터를 추가할 수도 있습니다. CLR 프로시저가 트리거에 의해 호출되고 CLR 프로시저가 NCache 호출하면 데이터베이스가 데이터를 추가하거나 캐시에 데이터를 다시 업데이트하도록 하는 것과 같습니다.
따라서 이 세 가지 다른 방법으로 NCache 데이터베이스와 동기화해야 하며 이것이 사용하는 정말 강력한 이유입니다. NCache 위에 Redis 때문에 Redis 충분하지 않은 만료만 사용하도록 합니다. 그것은 정말로 당신을 취약하게 만들거나 읽기 전용 데이터를 캐시하도록 강요합니다.
비관계형 데이터베이스와 캐시 동기화
캐시를 비관계형 데이터베이스와 동기화할 수도 있습니다. 따라서 레거시 데이터베이스인 메인프레임이 있는 경우 캐시 서버에서 실행되는 코드인 사용자 지정 종속성을 가질 수 있습니다. NCache 코드를 호출하여 데이터 원본을 모니터링하고 웹 메서드를 호출하거나 다른 작업을 수행하여 사용자 지정 데이터 원본을 모니터링하고 캐시된 항목을 해당 사용자 지정 데이터 원본의 데이터 변경 사항과 동기화할 수 있습니다. 따라서 데이터베이스의 동기화는 매우 강력한 이유입니다. NCache 위에 Redis 이제 거의 모든 데이터를 캐시하기 때문입니다. 반면, 다음의 경우 Redis 읽기 전용이거나 매우 자신 있게 추측할 수 있는 데이터를 캐시해야 합니다. 만료.
이유 2 – SQL 검색
두 번째 이유, 알겠습니다. 이제 데이터베이스 기능과의 동기화를 사용하기 시작했으며 이제 실제로 많은 데이터를 캐시할 수 있다고 가정해 보겠습니다. 따라서 더 많은 데이터를 캐시할수록 캐시가 데이터베이스처럼 보이기 시작하고 키를 기반으로 데이터를 가져올 수 있는 옵션만 있는 경우 Redis 매우 제한적입니다. 따라서 다른 일을 할 수 있어야 합니다. 따라서 데이터를 지능적으로 찾을 수 있어야 합니다. NCache 개체 속성 또는 그룹 및 하위 그룹을 기반으로 데이터를 그룹화하고 데이터를 찾거나 태그, 이름 태그를 할당할 수 있는 여러 방법을 제공합니다. 따라서 이 모든 것은 데이터 컬렉션을 다시 가져올 수 있는 다양한 방법입니다. 예를 들어, SQL 쿼리를 실행해야 한다면 여기에서 SQL 쿼리를 실행한다고 가정해 보겠습니다. 그래서 customer.city가 New York인 모든 고객을 찾고 싶습니다. 그래서 저는 SQL 상태를 발행하겠습니다. 고객을 선택하겠습니다. 제 전체 네임스페이스가 여기 있는 고객입니다. 여기서 도시는 물음표이고 값에 New York을 값으로 지정할 때 해당 쿼리를 실행하면 이 기준과 일치하는 고객 개체 컬렉션을 다시 가져옵니다.
그래서 이것은 이제 데이터베이스처럼 보입니다. 따라서 이것이 의미하는 바는 실제로 데이터 캐시를 시작할 수 있다는 것입니다. 전체 데이터 세트, 특히 조회 테이블 또는 애플리케이션이 데이터베이스에 있는 쿼리 및 실행할 수 있는 동일한 유형의 SQL 쿼리에 대해 SQL 쿼리를 실행하는 데 사용된 기타 참조 데이터를 캐시할 수 있습니다. NCache. 유일한 제한 사항은 다음과 같은 경우 조인을 수행할 수 있다는 것입니다. NCache 그러나 이들 중 많은 부분이 실제로 관절을 수행할 필요가 없습니다. SQL 검색 캐시를 매우 친숙하게 만들어 원하는 데이터를 실제로 검색하고 찾을 수 있습니다.
그룹화 및 하위 그룹화 그룹화의 예를 보여드리겠습니다. 예를 들어 여기에 여러 개체를 추가하고 모두 추가할 수 있습니다. 따라서 그룹으로 추가하고 있습니다. 이것은 키, 값입니다. 여기에 그룹 이름이 있고 여기에 하위 그룹 이름이 있습니다. 그러면 나중에 전자 그룹에 속한 모든 것을 알려줄 수 있습니다. 이것은 컬렉션을 다시 제공하고 컬렉션을 반복하여 물건을 얻을 수 있습니다.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}그룹을 기반으로 키를 가져올 수도 있습니다. 그룹을 기반으로 다른 작업을 수행할 수도 있습니다. 따라서 그룹과 태그는 유사한 방식으로 작동합니다. 이름표 키 값 개념을 제외하고 태그와 동일합니다. 예를 들어, 자유 형식 텍스트를 캐싱하고 텍스트의 메타데이터 중 일부를 인덱싱하려는 경우 이름 태그와 함께 키 값 개념을 사용할 수 있습니다. 그런 다음 SQL 쿼리에 포함할 수 있습니다.
당신은 또한 발행할 수 있습니다 LINQ 쿼리. LINQ에 더 익숙해지면 LINQ 쿼리를 실행할 수 있습니다. 예를 들어 LINQ의 경우 NCache. 그래서, 당신은 할 것입니다 NCache 제품 개체로 쿼리합니다. 그것은 당신에게 제공합니다 쿼리 가능 인터페이스를 사용하면 개체 컬렉션에 대해 수행하는 것처럼 LINQ 쿼리를 실행할 수 있으며 실제로 캐시를 검색합니다.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}따라서 이 쿼리를 실행할 때 이 쿼리를 실행할 때 실제로는 캐싱 계층으로 이동하여 개체를 검색합니다. 따라서 사용 가능한 인터페이스는 매우 친숙한 방식으로 매우 간단하지만 실제로는 전체 캐시 클러스터를 캐싱하거나 검색하고 있습니다. 따라서 두 번째 이유는 캐시를 검색할 수 있고 그룹 및 하위 그룹, 태그 및 명명된 태그를 통해 데이터를 그룹화할 수 있고 친숙한 방식으로 데이터를 찾을 수 있기 때문입니다. Redis.
데이터 인덱싱 이것의 또 다른 측면은 이러한 속성을 기반으로 검색할 때 필수적이며 캐시 인덱스가 해당 속성에 대한 인덱스를 생성하는 것이 정말 중요하다는 것입니다. 그렇지 않으면 그러한 것들을 찾는 과정이 매우 느립니다. 그래서, NCache 데이터 인덱싱을 생성할 수 있습니다. 예를 들어, 모든 그룹 및 하위 그룹, 태그, 이름 태그는 자동으로 색인이 생성되지만 객체에 색인을 생성할 수도 있습니다. 따라서 예를 들어 도시 속성의 고객 개체에 대한 인덱스를 만들 수 있습니다. 따라서 city 속성에서 검색할 것임을 알고 있기 때문에 city 속성입니다. 당신은 그 속성을 색인화하고 싶다고 말합니다. NCache 인덱싱합니다.
이유 3 - 서버 측 코드
세 번째 이유는 NCache 실제로 서버 측 코드를 작성할 수 있습니다. 그래서, 그 서버 측 코드는 무엇이며 그것이 왜 그렇게 중요합니까? 살펴보겠습니다. 그것은 read-through, write-through, write-behind 및 캐시 로더입니다. 그래서, 통독 본질적으로 구현하는 코드이며 캐시 서버에서 실행됩니다. 그래서, 실제로 내가 당신에게 read-through가 어떻게 생겼는지 보여드리겠습니다. 예를 들어 IReadThruProvider 인터페이스.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}이 인터페이스에는 세 가지 방법이 있습니다. 캐시가 시작될 때 호출되는 init 메소드가 있고 그 목적은 read-through 핸들러를 데이터 소스에 연결하는 것이며 캐시가 중지될 때 호출되는 dispose 메소드가 있습니다. 이렇게 하면 데이터 소스에서 연결을 끊을 수 있습니다. 키를 전달하고 캐시 항목, 공급자 캐시 항목 개체의 출력을 예상하는 소스 메서드에서 로드가 있습니다. 따라서 이제 키를 사용하여 데이터베이스에서 가져와야 하는 개체를 결정할 수 있습니다. 따라서 내가 말한 키는 고객, 고객 ID 1000이 될 수 있습니다. 따라서 개체 유형이 고객이고 키는 고객 ID이고 값이 1000이라고 알려줍니다. 따라서 이러한 형식을 사용하면 다음을 수행할 수 있습니다. 이를 기반으로 데이터 액세스 코드를 작성할 수 있습니다.
따라서 이 read-through 처리기는 실제로 캐시 서버에서 실행됩니다. 따라서 실제로 모든 캐시 서버에 이 코드를 배포합니다. 의 경우 NCache 그것은 꽤 원활합니다. 당신은 그것을 통해 할 수 있습니다 NCache 관리자 도구. 따라서 해당 read-through 핸들러를 캐시 서버에 배포하면 해당 read-through 핸들러가 캐시에 의해 호출됩니다. 귀하의 애플리케이션이 캐시.가져오기 해당 항목은 캐시에 없습니다. NCache read-through 핸들러를 호출합니다. read-through 핸들러는 데이터베이스로 이동하여 해당 항목을 가져와서 다시 NCache. NCache 캐시에 넣은 다음 응용 프로그램에 다시 제공합니다. 따라서 애플리케이션은 데이터가 항상 캐시에 있는 것처럼 느껴집니다. 따라서 캐시에 없더라도 캐시는 이제 데이터베이스에서 데이터를 가져올 수 있습니다. 이것이 바로 read-through의 첫 번째 이점입니다.
read-through의 두 번째 이점은 만료가 발생할 때입니다. 당신이 절대 만기를 가졌다고 가정해 봅시다. 지금부터 5분 또는 지금부터 2시간 후에 이 항목을 만료한다고 말했습니다. 그때 캐시에서 해당 항목을 제거하는 대신 알 수 있습니다. NCache read-through 핸들러를 호출하여 해당 항목을 자동으로 다시 로드합니다. 그리고 다시 로드는 항목이 캐시에서 제거되지 않음을 의미합니다. 업데이트만 했을 뿐인데 참조 룩업 테이블이 많기 때문에 해당 데이터만 읽는 트랜잭션이 많고, 해당 데이터가 짧은 시간이라도 제거되면 데이터베이스에 대한 트랜잭션이 많기 때문에 정말 중요합니다. 동시에 해당 데이터를 가져오기 위해 생성됩니다. 따라서 캐시에서 업데이트할 수 있다면 훨씬 좋습니다. 그래서, 그것은 하나의 사용 사례입니다.
두 번째 사용 사례는 데이터베이스 동기화입니다. 따라서 데이터베이스 동기화가 발생하고 해당 항목이 제거될 때 제거하는 대신 데이터베이스에서 다시 로드하면 됩니다. NCache 할 것이다. 구성할 수 있습니다. NCache, 따라서 데이터베이스 동기화가 시작되면 NCache 캐시에서 해당 항목을 제거하는 대신 read-through 핸들러를 호출하여 새 복사본을 다시 로드합니다. 다시 말하지만 만료와 같은 방식으로 해당 항목은 절대 제거되지 않습니다. 캐시에서 제거되지 않습니다. 따라서 read-through는 정말 강력한 기능입니다.
read-through의 또 다른 이점은 캐싱 계층에서 코드를 지속성으로 이동하고 동일한 데이터에 액세스하는 여러 응용 프로그램이 있는 경우 점점 더 많이 이동하기 때문에 응용 프로그램을 단순화한다는 것입니다. 캐시.가져오기. 에이 캐시.가져오기 적절한 ADO.NET 유형의 코딩을 수행하는 매우 간단한 호출입니다.
따라서 read-through는 애플리케이션 코드를 단순화합니다. 또한 캐시에 항상 데이터가 있는지 확인합니다. 만료 및 데이터베이스 동기화 시 자동 다시 로드를 수행합니다.
다음 기능은 연속 쓰기입니다. 연속 기입은 갱신을 위한 것을 제외하고는 연속 기입과 동일하게 작동합니다. 글쓰기가 어떻게 생겼는지 보여드리겠습니다. 그래서, 이것은 읽혀졌습니다. 그냥 넘어가도록 하겠습니다. 따라서 연속 기입 처리기를 구현합니다. 다시, 당신은 init 메소드를 가지고 있습니다. read-through와 같은 dispose 메소드가 있지만 이제 데이터 소스에 쓰기 메소드가 있고 데이터 소스 메소드에 대량 쓰기가 있습니다. 그래서 이것은 읽는 것과는 다른 것입니다.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}따라서 write-through의 경우 개체와 작업도 가져오고 이 작업은 추가, 업데이트 또는 삭제가 될 수 있습니다. 당신이 할 수 있었기 때문에 캐시.추가, 캐시.삽입, 캐시.삭제, 그리고 그 모든 것은 write-through 호출이 만들어지는 결과를 낳을 것입니다. 이제 데이터베이스의 데이터를 업데이트할 수 있습니다.
마찬가지로 대량 작업, 대량 업데이트를 수행하면 데이터베이스에 대한 대량 업데이트도 수행할 수 있습니다. 따라서 연속 기입은 계속해서 더 많은 지속성 코드를 캐싱 계층으로 이동하기 때문에 응용 프로그램을 단순화할 수 있다는 점에서 연속 읽기와 동일한 이점을 갖습니다.
그러나 write-through의 변형인 write-behind 기능도 있습니다. write-behind를 사용하면 기본적으로 캐시를 업데이트한 다음 캐시가 데이터 소스를 비동기식으로 업데이트합니다. 기본적으로 나중에 업데이트합니다. 따라서 응용 프로그램을 기다릴 필요가 없습니다.
나중에 쓰기를 사용하면 애플리케이션 속도가 정말 빨라집니다. 데이터베이스 업데이트가 캐시 업데이트만큼 빠르지 않기 때문입니다. 따라서 write-behind 기능과 함께 write-through를 사용할 수 있으며 캐시는 즉시 업데이트됩니다. 응용 프로그램이 돌아가서 작업을 수행한 다음 write-through가 write-behind 방식으로 호출되고 데이터베이스를 업데이트하며, 물론 데이터베이스 업데이트가 실패하면 응용 프로그램에 알림이 전송됩니다.
따라서 대기열이 생성될 때마다 해당 서버가 다운되면 해당 대기열이 손실될 위험이 있습니다. 글쎄, 경우에 NCache write-behind 대기열은 둘 이상의 서버에 복제되며 캐시 서버가 다운되더라도 write-behind 대기열은 손실되지 않습니다. 그래서, 그렇게 NCache 고가용성을 보장합니다. 따라서 write-through 및 write-behind는 매우 강력한 기능입니다. 그들은 애플리케이션 코드를 단순화하고 또한 write-behind의 경우 데이터베이스가 업데이트될 때까지 기다릴 필요가 없기 때문에 애플리케이션 속도를 높입니다.
세 번째 기능은 캐시 로더입니다. 응용 프로그램이 데이터베이스로 이동할 필요가 없도록 캐시에 미리 로드하려는 데이터가 많이 있습니다. 캐시 로더 기능이 없다면 이제 해당 코드를 작성해야 합니다. 글쎄요, 그 코드를 작성해야 할 뿐만 아니라 어딘가에서 프로세스로 실행해야 합니다. 그것은 실제로 더 복잡해지는 프로세스로 실행되고 있습니다. 따라서 캐시 로더의 경우 캐시를 등록하기만 하면 됩니다. 캐시 로더 인터페이스를 구현하고 코드를 등록합니다. NCache, NCache 캐시가 시작될 때마다 코드를 호출하여 캐시에 항상 많은 데이터가 미리 로드되도록 할 수 있습니다.
따라서 이 세 가지 기능은 read-through, write-through, write-behind 및 캐시된 로더입니다. 이 세 가지 기능은 NCache 있다. Redis 그런 기능이 없습니다. 따라서 다음의 경우 Redis 이 모든 기능을 잃게 됩니다. NCache 달리 제공합니다.
이유 4 - 클라이언트 캐시(캐시 근처)
네 번째 이유는 클라이언트 캐시. 클라이언트 캐시는 매우 강력한 기능입니다. 이것은 실제로 응용 프로그램 서버 상자에 있는 로컬 캐시이지만 격리된 캐시는 아닙니다. 애플리케이션에 로컬입니다. In-Proc일 수 있습니다. 따라서 이 클라이언트 캐시는 객체가 힙에 있는 것처럼 보관될 수 있습니다. NCache In-Proc 옵션을 선택하면 NCache 데이터와 객체 형태를 유지합니다. 직렬화된 형식이 아니라 클라이언트 캐시에 있습니다. 클러스터된 캐시에서는 직렬화된 형식으로 유지합니다. 그러나 클라이언트 캐시에서는 개체 형식으로 유지합니다. 왜요? 따라서 가져올 때마다 개체로 역직렬화할 필요가 없습니다. 따라서 가져오기 속도가 빨라지거나 더 많이 가져옵니다.
클라이언트 캐시는 매우 강력한 기능입니다. 캐시 위에 캐시입니다. 따라서 독립 실행형 In-Proc 캐시에서 분산 캐시로 이동할 때 잃게 되는 것 중 하나는 분산 캐시에서 캐시가 별도의 서버에서도 별도의 프로세스에 데이터를 유지하고 내부 프로세스가 있다는 것입니다. 통신이 진행 중이면 직렬화 및 역직렬화가 진행되어 성능이 저하됩니다. 따라서 In-Proc에 비해 개체 형태 캐시는 분산 캐시가 XNUMX배 이상 느립니다. 따라서 클라이언트 캐시를 사용하면 두 가지 장점을 모두 누릴 수 있습니다. 클라이언트 캐시가 없고 독립 실행형 격리 캐시가 있는 경우 캐시 크기에 대한 다른 많은 문제가 있기 때문에 해당 프로세스가 중단되면 어떻게 될까요? 그런 다음 캐시를 잃게 되며 캐시를 여러 서버의 변경 사항과 동기화된 상태로 유지하는 방법은 무엇입니까? 이러한 모든 문제는 NCache 클라이언트 캐시에 있습니다.
따라서 독립 실행형 In-Proc 캐시의 이점을 얻을 수 있지만 캐싱 클러스터에 연결됩니다. 따라서 이 클라이언트 캐시에 보관된 모든 것은 클러스터된 캐시에도 있으며 클라이언트 중 하나가 여기에서 업데이트하면 캐싱 계층에서 클라이언트 캐시에 알립니다. 즉시 이동하여 자체 업데이트할 수 있습니다. 따라서 클라이언트 캐시가 항상 데이터베이스와 동기화되는 캐싱 계층과 동기화되도록 하거나 안심할 수 있는 방법입니다.
따라서 다음의 경우에는 NCache 클라이언트 캐시는 추가 프로그래밍 없이 플러그 인되는 것입니다. 캐싱 계층과 대화하는 것처럼 API를 호출하면 클라이언트 캐시가 구성 변경에 연결되고 클라이언트 캐시가 10배 더 빠른 성능을 제공합니다. 하는 기능입니다 Redis 이 없습니다. 따라서 모든 성능 주장에도 불구하고 Redis 그들은 빠른 제품을 가지고 있지만 NCache. 그래서, NCache 와 성능면에서 일대일입니다. Redis 클라이언트 캐시 없이. 그러나 클라이언트 캐시를 켜면 NCache 10배 빠릅니다. 이것이 클라이언트 캐시 사용의 진정한 이점입니다. 이것이 XNUMX번을 사용하는 이유입니다. NCache 위에 Redis.
이유 5 - 다중 데이터 센터 지원
다섯 번째 이유는 NCache 다중 데이터 센터 지원을 제공합니다. 요즘 트래픽이 많은 애플리케이션이 있는 경우 재해 복구 DR 또는 로드 밸런싱 또는 DR과 로드 밸런싱의 조합을 위해 XNUMX개의 활성-활성 데이터 센터를 위해 여러 데이터 센터에서 이미 실행 중일 가능성이 매우 높습니다. , 알다시피, 또는 아마도 지리적 로드 밸런싱입니다. 따라서 런던과 뉴욕에 데이터 센터가 있거나 지역 트래픽을 처리하기 위해 도쿄 또는 이와 유사한 것을 알고 있을 수 있습니다. 여러 데이터 센터가 있을 때마다 데이터베이스는 복제를 제공합니다. 그렇지 않으면 여러 데이터 센터를 가질 수 없기 때문입니다. 여러 데이터 센터에서 데이터가 동일하기 때문입니다. 데이터가 동일하지 않은 경우 알다시피 별도이며 문제가 없지만 많은 경우 데이터가 동일하고 그뿐만 아니라 하나의 트래픽 중 일부를 오프로드 할 수 있기를 원합니다. 원활한 방식으로 데이터 센터를 다른 사람에게 전달합니다. 따라서 데이터 센터 간에 데이터베이스를 복제하는 경우 캐시를 사용하지 않는 이유는 무엇입니까? Redis 그러한 기능을 제공하지 않으며, NCache 매우 강력한 기능을 제공합니다.
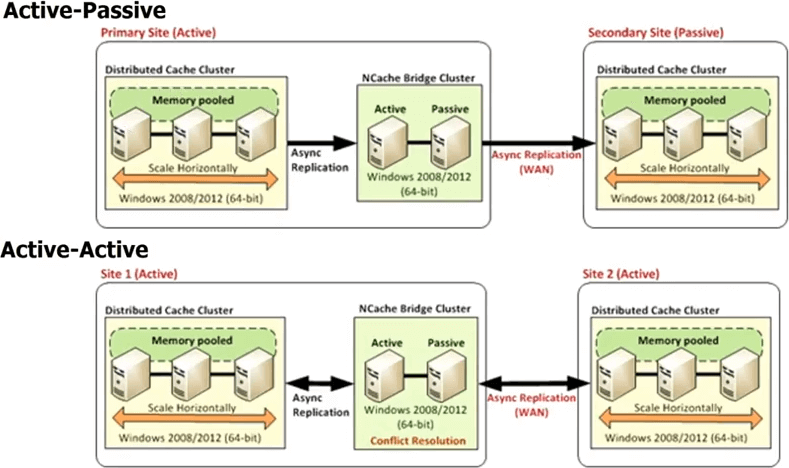
따라서 다음의 경우에는 NCache 모든 데이터 센터에는 자체 캐시 클러스터가 있지만 브리지 토폴로지 사이. 해당 브리지는 기본적으로 각 데이터 센터의 캐시 클러스터를 연결하므로 비동기식으로 복제할 수 있습니다. 따라서 능동-수동 브리지를 가질 수 있습니다. 여기가 능동 데이터 센터이고 이것은 수동입니다. 또한 활성-활성 브리지를 가질 수 있으며 XNUMX개 이상의 데이터 센터 활성-활성 또는 활성-수동 구성을 출시할 예정입니다. 여기에서 XNUMX개 또는 XNUMX개의 데이터 센터를 가질 수 있고 캐시가 모두에 복제됩니다. 능동-능동 방식 또는 능동-수동 방식으로. 활성-활성에서는 업데이트가 비동기식으로 수행되거나 복제가 비동기식으로 수행되기 때문에 두 데이터 센터에서 동일한 항목이 업데이트된 충돌 가능성이 있습니다.
그래서, NCache 충돌 해결을 처리하기 위한 두 가지 다른 메커니즘을 제공합니다. 하나는 마지막 업데이트 승리라고 합니다. 마지막으로 업데이트된 항목이 두 위치에 모두 적용됩니다. 따라서 여기에서 항목을 업데이트하고 다른 사용자가 여기에서 항목을 업데이트한다고 가정해 보겠습니다. 이제 둘 다 다른 캐시로 전파되기 시작합니다. 그래서 그들이 다리에 올 때 다리는 그들이 두 곳 모두에서 업데이트되었음을 깨닫습니다. 따라서 타임스탬프를 확인하고 마지막 타임스탬프가 해당 업데이트를 다른 위치에 적용하고 다른 위치에서 수행한 업데이트를 삭제합니다. 따라서 활성-활성 마지막 업데이트가 충돌 해결에서 승리하는 방법입니다. 그것으로 충분하지 않다면 충돌 해결 핸들러를 구현할 수 있습니다. 그것은 당신의 코드입니다. 따라서 브리지는 실제로 충돌이 발생한 경우 코드를 호출하고 개체의 두 복사본을 모두 전달하여 콘텐츠 기반 분석을 수행한 다음 해당 분석을 기반으로 업데이트하기에 더 적합한 개체를 결정할 수 있습니다. 두 데이터 센터에 모두 적용됩니다. 데이터 센터가 XNUMX개 이상인 경우에도 동일한 규칙이 적용됩니다.
그래서, 다중 데이터 센터 지원 매우 강력한 기능입니다 NCache 당신을 상자 밖으로 제공합니다. 일단 구매하면 NCache, 모든 것이 있습니다. Redis 현재 여러 데이터 센터가 없지만 여러 데이터 센터로 이동할 수 있는 유연성을 원하는 경우에도 여러 데이터 센터를 보유할 계획이거나 유연성만 원할 경우 복제를 지원하지 않는 데이터베이스를 지금 구입하시겠습니까? 데이터 센터가 하나만 있더라도 그렇지 않을 것입니다. 그렇다면 WAN 복제를 지원하지 않는 캐시를 사용하는 이유는 무엇입니까? 따라서 이것은 매우 강력한 기능입니다. NCache.
그래서 지금까지 좋은 분산 캐시가 갖추어야 할 주요 기능에 대해 이야기했습니다. NCache, 빛난다. 그것은 손을 아래로 이긴다 Redis. Redis 매우 기본적인 간단한 캐시입니다.
이유 6 – 플랫폼 및 기술(.NET 앱용)
.NET 및 Windows 대 Linux
여섯 번째 이유는 아마도 가장 중요한 이유 중 하나인 플랫폼과 기술일 것입니다. .NET 애플리케이션이 있다면 완전한 .NET 스택을 선호할 것입니다. 대부분의 경우 .NET과 Java 또는 Windows와 Linux를 혼합하고 싶지는 않을 것입니다. 어떤 경우에는 알겠지만 대부분의 경우 .NET 애플리케이션을 개발하는 사람들은 Windows 플랫폼을 사용하고 가능하면 전체 스택을 .NET으로 사용하는 것을 선호합니다. 잘, Redis .NET 제품이 아닙니다. C/C++로 개발된 Linux 기반 제품입니다.

조금 보여드리겠습니다. 여기 Redis 만드는 회사인 labs 웹사이트 Redis. 다운로드 페이지로 이동하면 Windows 옵션도 제공하지 않는다는 것을 알 수 있습니다. 따라서 Microsoft가 Azure용으로 선택했음에도 불구하고 Windows를 지원할 생각은 전혀 없습니다. 그래서, Redis 연구실은 걱정하고 있습니다. Redis 리눅스 전용입니다. Microsoft 개방형 기술 그룹이 이식되었습니다. Redis 윈도우에. 따라서 Windows 버전의 Redis 사용 가능. 오픈 소스이며 지원되지 않지만 버그가 있고 불안정하며 증거는 푸딩에 있지만 Microsoft 자체는 Azure에서 사용하지 않습니다. 그래서 Redis Azure에서 사용하는 것은 실제로 Linux 기반입니다. Redis Windows 기반이 아닙니다. 따라서 통합하려는 경우 Redis 응용 프로그램 스택에 기름과 물을 섞을 것입니다. 반면, 다음의 경우 NCache 모든 것이 기본 .NET입니다. Windows가 있습니다. 당신은 100% .NET을 가지고 있습니다. NCache C Sharp(C#)로 개발되었습니다. Windows Server 2012 R2에 대해 인증되었으며 새 버전의 운영 체제가 나올 때마다 이에 대해 인증됩니다. 곧 ASP를 출시할 예정입니다..NET Core 지원하다. 따라서 공식적으로 .NET 클라이언트가 있습니다. 공식적으로 Java 클라이언트도 있습니다. 그래서, 나는 당신이 사용하는 경우 NCache 그리고 다시 NCache 도 오픈 소스입니다. 따라서 돈이 없으면 오픈 소스 버전으로 이동하십시오. NCache. 그러나 프로젝트가 중요한 경우 더 많은 기능을 제공하고 두 가지를 모두 지원하는 Enterprise 버전을 사용하십시오. 그러나 나는 당신이 사용하는 것이 좋습니다 NCache .NET 및 Windows 조합에 대한 .NET 응용 프로그램이 있는 경우.
온프레미스 지원
두 번째 혜택은 NCache 클라우드에 있지 않은 경우 클라우드로 이동하기로 결정하지 않고 자체 애플리케이션을 호스팅하므로 기본적으로 온프레미스입니다. 따라서 자체 데이터 센터에 있습니다. Redis Microsoft에서 사용할 수 있는 것은 Azure에만 있습니다. 따라서 온프레미스에 있는 모든 것이 Redis 온프레미스에서 사용할 수 있는 Redis 연구실은 Linux일 뿐이며 Windows의 유일한 온-프레미스는 오픈 소스입니다. 지원되지 않고 버그가 있고 불안정하며 Microsoft 자체가 Azure에서 사용하지 않는 버그가 있는 오픈 소스입니다.

반면, 다음의 경우 NCache 돈이 없다면 물론 지원되지 않는 무료 오픈 소스를 계속 사용할 수도 있습니다. 그러나 모두 기본 .NET이거나 비즈니스에 중요한 프로젝트가 있는 경우 Enterprise Edition 더 많은 기능과 지원이 제공되는 영구 라이선스입니다. 소유하는 것이 매우 저렴하며 중요한 경우에 대비하여 연중무휴 지원을 제공합니다.
따라서 온프레미스에서 완벽하게 지원됩니다. 하이엔드 고객인 대부분의 고객은 여전히 사용하고 있습니다. NCache 온프레미스 상황에서. NCache 10년 이상 시장에 나와 있습니다. 그래서 정말 안정적인 제품입니다.
클라우드 지원
클라우드 지원만큼, Redis Microsoft가 구현한 클라우드의 서비스 모델을 제공합니다. Redis 서비스. 잘, Redis 서비스는 캐시 서버에 대한 액세스 권한이 없음을 의미합니다. 당신을 위한 블랙박스입니다. 서버 측 코드가 없습니다. 따라서 모든 read-through, write-through, write-behind, 캐시 로더, 사용자 지정 종속성 및 기타 여러 가지 작업을 수행할 수 없습니다. Redis. 기본 클라이언트 API만 있고 제가 말했듯이 Azure에서 Microsoft는 Redis 서비스로.
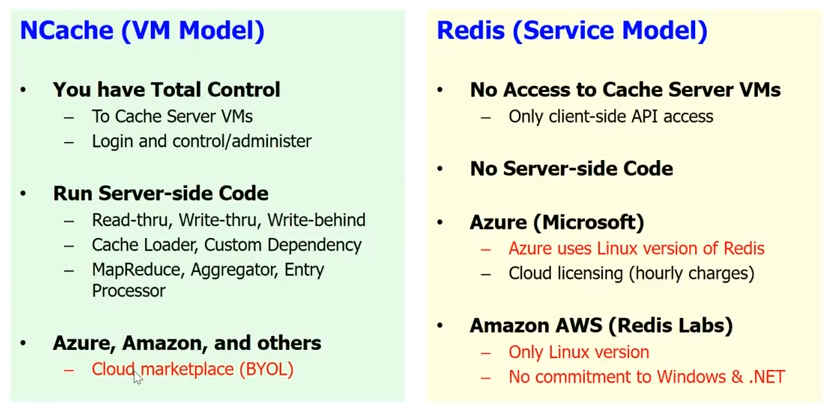
NCache, 우리는 의도적으로 VM 모델을 선택했습니다. 왜냐하면 우리는 캐시가 당신의 애플리케이션에 가깝기를 원하고 당신이 캐시에 대한 완전한 통제권을 갖기를 원하기 때문입니다. 이것은 우리가 다년간의 경험을 갖고 있고 고객이 매우 민감하다는 것을 알고 있기 때문에 매우 중요한 것입니다. 작은 것이라도 사용한다면 Redis 서비스로 제공되며 매번 캐시에 도달하기 위해 하나의 추가 홉을 만들어야 합니다. 반면, 다음의 경우 NCache VM의 일부로 가질 수 있습니다. 클라이언트 캐시를 가질 수 있습니다. 애플리케이션 배포에 실제로 포함되어 있습니다. 따라서 모든 서버 측 코드를 수행할 수 있습니다.
NCache 또한 실행 하늘빛. 그것은에서 실행됩니다 아마존 AWS 또한 다른 선도 클라우드 플랫폼 BYOL 모델에서 따라서 기본적으로 VM을 얻습니다. 사실, 당신은 NCache 시장에서. 당신은 얻을 NCache VM과 당신은 우리에게서 라이선스를 구매하고 사용하기 시작합니다 NCache.
따라서 접근 방식이 매우 다릅니다. 그러나 이것은 응용 프로그램이 정말 중요하고 응용 프로그램의 모든 측면을 제어하고 응용 프로그램 수준 인프라의 청크를 관리하는 다른 사람에게 의존할 필요가 없는 경우에 의도된 접근 방식입니다. VM과 그 아래에 있는 하드웨어를 관리하는 것은 한 가지이지만 점점 더 위로 올라가기 시작하면 해당 제어를 잃게 되며 물론 캐싱의 경우, NCache, 제어뿐만 아니라 서비스 모델을 사용하면 잃게 되는 많은 기능도 있습니다.
그래서 여섯 번째 이유는 플랫폼 기술입니다. .NET 응용 프로그램의 경우 NCache 보다 훨씬 더 적합한 옵션입니다. Redis. 나는 말하지 않는다 Redis 나쁜 옵션이지만 .NET 응용 프로그램에 대해 생각합니다. NCache 보다 훨씬 더 우수한 옵션입니다. Redis.
NCache 연혁
간략한 역사를 알려드리자면 NCache. NCache 2005년 중반부터 사용되었습니다. 이제 11년이 되었습니다. NCache 시장에 있었다. 이것은 시장에서 가장 오래된 .NET 캐시입니다. 2015년 2.0월, 우리는 오픈 소스가 되었습니다. 따라서 우리는 이제 Apache XNUMX 라이센스입니다. 우리의 Enterprise Edition 오픈 소스를 기반으로 구축되었습니다. 따라서 오픈 소스는 안정적이고 신뢰할 수 있는 버전입니다. 그것은 많은 기능을 가지고 있습니다. 물론 엔터프라이즈에는 더 많은 기능이 있지만 오픈 소스는 매우 유용한 제품입니다. 기본적인 것은 돈이 없으면 오픈 소스를 사용하는 것입니다. 비즈니스 응용 프로그램이 중요하고 예산이 있는 경우 Enterprise Edition으로 이동하십시오. 지원과 함께 제공되며 더 많은 기능을 제공합니다.
우리는이 수백명의 고객, 캐싱이 필요한 거의 모든 산업에서 가능합니다. 그래서 우리에게는 금융 산업 고객이 있고 월마트와 다른 소매 산업이 있습니다. 항공, 보험 산업, 자동차/자동차 등 모든 산업 분야에 걸쳐 있습니다.
이상으로 제 이야기를 마치겠습니다. Enterprise Edition을 다운로드하십시오. NCache. 실제로 저희 웹사이트로 안내해 드리겠습니다. 따라서 기본적으로 다운로드 페이지로 Enterprise Edition을 다운로드하는 것이 좋습니다. 오픈소스 버전을 사용하게 되더라도 Enterprise Edition을 다운로드하세요. 완전히 작동하는 30일 평가판이므로 쉽게 연장하고 플레이할 수 있습니다.
계속해서 오픈 소스를 다운로드하려면 오픈 소스를 다운로드하십시오. GitHub로 이동하여 볼 수도 있습니다. NCache GitHub에서. 우리가 좋아하는 것을 원한다면 저희에게 연락하십시오 개인화 된 데모. 애플리케이션 아키텍처에 대해 이야기하고 질문에 답할 수 있습니다. 이 강연을 시청해주셔서 대단히 감사합니다.