Como os dados foram cunhados como “a nova moeda”, o Apache Lucene ganhou força como um popular mecanismo de pesquisa de texto completo, amplamente usado em aplicativos para incorporar pesquisa de texto flexível em quantidades significativas de dados textuais. Lucene usa indexação invertida, reduzindo drasticamente o tempo para encontrar documentos relacionados a um determinado termo.
NCache Adicionar ao carrinho Lucene distribuído NCache Docs
No entanto, é uma solução autônoma que não escala à medida que seus dados crescem – você precisa reconstruir índices Lucene inteiros para pesquisar dados, o que é uma tarefa cara e lenta, tornando-se um gargalo de desempenho. Embora já existam algumas soluções baseadas em Java e REST para atender à pesquisa de texto completo escalável, ainda falta uma solução de pesquisa de texto completo escalável que possa caber naturalmente na pilha .NET.
Usando o Lucene distribuído com NCache para .NET
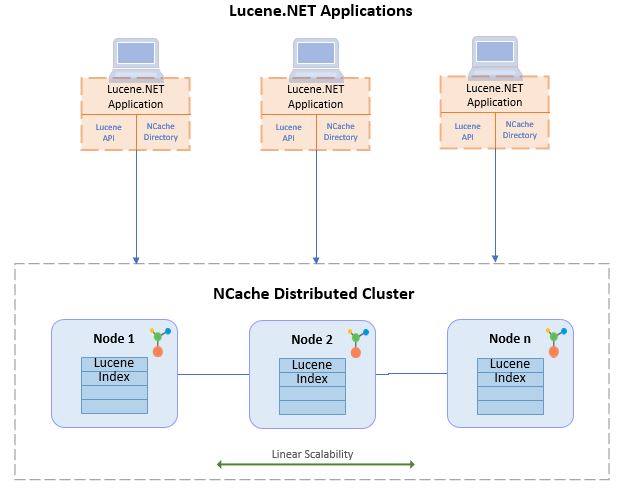
NCache, um poderoso e popular armazenamento de dados .NET In-Memory, implementou a API Lucene.NET nativa em sua arquitetura distribuída. NCache.
NCache também utiliza este Lucene.NET para criar índices em um ambiente dinamicamente escalável para permitir pesquisas de texto completo distribuídas. Os resultados dessas pesquisas são mesclados antes de serem enviados de volta ao seu aplicativo.
NCache Adicionar ao carrinho Trabalho de Lucene Distribuído Componentes e visão geral do Lucene
Isso aprimora o Lucene autônomo em uma solução de pesquisa de texto completo rápida e linearmente escalável.
NCache Adicionar ao carrinho Lucene distribuído para pesquisa corporativa Lucene distribuído
Usando o Lucene em aplicativos .NET
Vamos considerar um site de comércio eletrônico que contém informações de milhares de produtos, pedidos e detalhes de clientes. Portanto, indexar todos os atributos, especialmente campos não textuais (que não são usados durante a pesquisa), não é uma abordagem sábia, pois esgota a memória cache.
Por exemplo, nosso documento para um produto é assim:
|
1 2 3 4 5 6 7 8 9 |
{ “ID”: “ABC34”, “Name”: “Tupperware”, “Description”: “Microwaveable, dishwasher-friendly, reusable Tupperware in three sizes”, “RetailPrice”: 15.00, “Discount”: 3.00 } |
Agora, sabemos que nossos clientes realizam pesquisas de texto completo na descrição do produto, que é um campo do documento. Então, e se indexarmos apenas os campos que podem ser pesquisados e tiver uma chave que se refira ao seu documento correspondente no armazenamento de persistência, por exemplo, banco de dados ou sistema de arquivos? Dessa forma, quando você consultar um tipo específico de produto, digamos “Tupperware adequado para lava-louças”, todos os produtos com uma descrição que corresponda a esses termos aparecerão com seu ProductID como uma chave de documento e todo o documento poderá ser obtido de o índice persistente.
Para usar o Lucene distribuído em seus aplicativos existentes, tudo o que você precisa é especificar NCacheDiretório ao abrir um diretório. Isso requer o NCache nome do cache e o nome do índice. O trecho de código a seguir abre um diretório em um cache LuceneCache em NCache e um índice chamado ProductIndex.
|
1 2 3 4 5 6 7 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string index = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, index); |
O Lucene fornece uma linguagem de consulta extensa, que interpreta uma determinada string em uma consulta do Lucene. Isso pode ser feito em um termo, vários termos, curingas ou até mesmo palavras difusas. Para saber mais sobre as consultas do Lucene, leia Documentos de consulta do Lucene.
O trecho de código a seguir cria um IndexReader no diretório, que é usado pelo IndexSearcher. Os dados são analisados e tokenizados com base no StandardAnalyzer. As primeiras 50 ocorrências do resultado são retornadas ao aplicativo. Observe que o analisador deve ser o mesmo usado durante a criação do índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// The 'applyAllDeletes' is true so all enqueued deletes are applied on writer IndexReader reader = DirectoryReader.Open(indexWriter, true); // A searcher is opened to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify the searchTerm, fieldName and analyzer string searchTerm = "Beverages"; string fieldName = "Category"; // Note that the analyzer should be same as the one used during index creation Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); // Create a query parser to parse the query QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, fieldName, analyzer); Query query = parser.Parse(searchTerm); // Returns the top 50 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 50).ScoreDocs; reader.Dispose(); |
Carregar dados para criar índice distribuído
Com o Lucene, você pode criar índices e carregar dados neles conforme necessário. Os índices exigem um analisador, que analisa e tokeniza os dados de acordo com sua necessidade – podem ser espaços em branco, não letras, pontuação e assim por diante. Depois de criar um gravador para seu índice Lucene, você pode criar documentos e adicionar campos a ele. Este documento é então indexado em NCache como um índice distribuído quando você chama Commit(). Para obter mais detalhes sobre os analisadores Lucene, consulte Documentos do Lucene Analyzer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// Specify the cache name and index path for Lucene string cache = "LuceneCache"; string indexPath = "ProductIndex"; // Create directory and open it on the cache Directory directory = NCacheDirectory.Open(cache, indexPath); // The same analyzer is used as for the reader Analyzer analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48); IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer); // Create indexWriter on NCache directory IndexWriter indexWriter = new IndexWriter(directory, config); Product[] products = FetchProductsToIndex(); foreach (var product in products) { Document doc = new Document { new StoredField("id", product.ID), new TextField("name", product.Name, Field.Store.YES), new TextField("description", product.Description, Field.Store.YES), new StringField("category", product.Category, Field.Store.No), new StoredField("retail_price", product.RetailPrice), }; indexWriter.AddDocument(doc); } indexWriter.Commit(); </code><br /><br /><a href="/ncache/">NCache Details</a> <a href="/resources/docs/ncache/prog-guide/lucene-ncache.html#working-of-distributed-lucene">Working of Distributed Lucene</a> <a href="/blogs/geospatial-indexes-for-distributed-lucene-with-ncache/">GeoSpatial Indexes for Distributed Lucene</a> |
Sua marca NCache para Lucene distribuído?
utilização NCache para Lucene distribuído oferece os seguintes benefícios:
- Extremamente rápido e linearmente escalável: NCache é um armazenamento de dados distribuído na memória, portanto, construir Lucene distribuído além disso, oferece o mesmo desempenho ideal para suas pesquisas de texto completo. Além disso, por causa NCache's arquitetura distribuída, o índice Lucene é particionado em todos os servidores do cluster. Isso o torna escalável, pois você pode adicionar mais servidores em movimento à medida que sua carga de dados aumenta, e os índices do Lucene são automaticamente redistributados sem qualquer intervenção do cliente.
- Replicação de dados para confiabilidade e alta disponibilidade: Com o NCacheNa topologia Partition-of-Replica, o índice Lucene não é apenas particionado em todos os servidores, mas cada partição também é replicada para outro servidor do cluster. Portanto, se algum servidor cair, a réplica da partição atende a todas as consultas de t/resources/docs/ncache/admin-guide/distributed-lucene-counters.htmlque índice, garantindo confiabilidade. Da mesma forma, se um nó de servidor cair, NCache autocura dinamicamente reajustando os dados dentro dos nós restantes, sem qualquer tempo de inatividade ou impacto no seu índice Lucene, garantindo alta disponibilidade.
Conclusão
Para resumir, a pesquisa de texto completo agora se tornou fundamental em quase todos os negócios, devido ao poderoso mecanismo de pesquisa Lucene. Mas, à medida que os dados crescem, a reconstrução de índices pode causar mais danos do que ganhos, e isso ocorre quando uma solução .NET distribuída na memória, como NCache Tudo o que requer é uma alteração de código de uma linha em seu aplicativo Lucene existente e, voila, você tem o melhor dos dois mundos como um mecanismo de pesquisa de texto completo distribuído na memória.
NCache Adicionar ao carrinho Baixar NCache Comparação de edições




