Para aplicativos de alta transação com arquiteturas complexas, a troca contínua de dados causa uma carga não uniforme e atraso no rendimento. O refinamento de dados é um grande desafio quando se trata de aplicativos de negócios grandes e complexos. Para atender a isso, o processamento de fluxo é usado para definir um fluxo de dados específico criando fluxos de dados. Um aplicativo de fluxo típico consiste em vários produtores gerando novos eventos e um conjunto de consumidores processando esses eventos.
Um desses aplicativos populares é o Pub/Sub, em que os editores inserem mensagens e os assinantes recebem as mensagens que assinam. No entanto, no processamento de stream, o Pub/Sub enfrenta algumas limitações, como quando o assinante recebe a mensagem, o aplicativo não retém mais a mensagem. Então, mais tarde, se outro assinante quiser as mensagens do editor, as mensagens anteriores não existirão. Além disso, para dados de fluxo de entrada, a filtragem de dados ocorre no cliente (assinante) e não no servidor, tornando a arquitetura do aplicativo complexa.
Para superar essas limitações do Pub/Sub, NCache vem com um mecanismo eficiente de processamento de dados no lado do servidor usando consultas contínuas. As consultas contínuas permitem que os aplicativos sejam notificados de todas as alterações que ocorrem nos dados que residem no cache, atendendo a determinados critérios. Este blog ajuda você a entender as vantagens de usar consultas contínuas no processamento de fluxo com a ajuda de uma solução criada para processamento de fluxo em GitHub.
Como usar a consulta contínua para processamento de fluxo
A solução explica um aplicativo de e-commerce, que processa milhares de clientes todos os dias para suas compras online. Se você observar o diagrama abaixo, os clientes de todos os tipos e categorias são adicionados ao aplicativo. Para tornar o processamento de clientes eficiente, os clientes não filtrados são categorizados e filtrados como clientes “Ouro”, “Prata” e “Bronze” com base no número de seus pedidos, usando consultas contínuas.
Consulta contínua permite que os aplicativos recebam notificações quando um dado que atende a determinados critérios muda dentro do cache e os critérios são especificados usando comandos SQL. Por exemplo, se um aplicativo deseja marcar os clientes com o maior número de pedidos como 'Clientes Gold', tudo o que ele precisa fazer é registrar um critério de comando SQL, fornecendo um retorno de chamada. Esse retorno de chamada é acionado em qualquer alteração que ocorra no conjunto de resultados que atenda aos critérios. Uma vez que o retorno de chamada é invocado, o aplicativo pode categorizar esses clientes como “Clientes Gold” usando Tags.
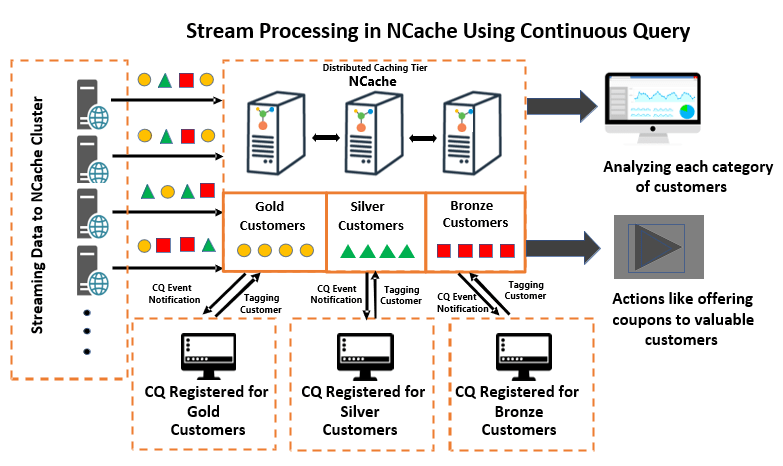
Figura 1: Processamento de fluxo usando consulta contínua
Da mesma forma, o aplicativo pode criar várias categorias registrando vários CQs, cada um com seus próprios critérios e um retorno de chamada. Dessa forma, o aplicativo obtém apenas os dados filtrados nos quais está interessado. Os dados filtrados podem ser analisados de acordo com os requisitos de negócios, como oferecer descontos aos clientes de alto nível com base na categoria do cliente.
Os eventos são acionados se qualquer uma das seguintes ações de modificação de dados ocorrer no cache:
- Adicionar: Adicionando um novo item ao cache que atende aos critérios de consulta
- Update: Atualizando um item existente no conjunto de resultados da consulta.
- Remover: Removendo o item do cache ou atualizando qualquer item em cache existente de forma que cause a remoção do item do conjunto de resultados da consulta.
Vamos percorrer um exemplo de código rápido do uso de processamento de fluxo no cache com consulta contínua. Neste exemplo, uma consulta contínua é executada nos dados em que os pedidos superiores a 10 são adicionados à categoria “Clientes Gold”. Além disso, um evento é acionado em cada item adicionado ao conjunto de resultados da consulta.
|
1 2 3 4 5 6 7 8 9 10 11 |
string query = SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery (queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification (new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
NCache Adicionar ao carrinho Consulta contínua e Pub/Sub
A consulta contínua mantém os dados que o Pub/Sub não
Agora os dados filtrados por meio de consulta contínua (para clientes com pedidos >10) são marcados como “Clientes Gold” e são atualizados no cache. Veja o código abaixo para ver como é feito.
|
1 2 3 4 5 6 7 8 9 10 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.None); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
A consulta contínua mantém os dados preservados no cache mesmo após o processamento. Dessa forma, ele resolve o problema enfrentado pelo Pub/Sub para dados continuamente emergentes que são vários aplicativos que publicam os dados em NCache camada de mensagens. Assim, vários assinantes recebem os dados e não têm armazenamento de dados confiável, pois as mensagens são removidas do barramento de mensagens uma vez recebidas. Os dados são armazenados pelo aplicativo ou pela adição de uma nova fonte de dados, o que é um cenário muito mais complexo. A consulta contínua, por outro lado, garante que não haja perda de dados, poupando assim todo o esforço extra de persistir manualmente seus dados.
NCache Adicionar ao carrinho Baixar NCache Comparação de edições
A consulta contínua permite o desacoplamento de aplicativos por meio de filtragem poderosa
Grandes aplicativos complexos podem ter vários agrupamentos com base em suas arquiteturas, por exemplo, com 10 aplicativos em execução, dois deles podem estar lidando com o conjunto de dados dos clientes Gold, enquanto os outros dois podem estar lidando com o conjunto de dados dos clientes Silver. Nesses casos, você deseja uma lógica de negócios separada para cada conjunto de dados em que os dados são filtrados de acordo com as necessidades de processamento de fluxo de cada aplicativo. Portanto, esses aplicativos grandes e complexos precisam ser desacoplados, pois a dependência de aplicativos entre si causa enormes gargalos de desempenho, bem como maior complexidade dos aplicativos.
A consulta contínua filtra de maneira muito eficiente os dados de seus aplicativos com a ajuda de instruções SQL bastante sofisticadas, portanto, nenhum aplicativo se sobrepõe aos outros aplicativos. Esse desacoplamento se torna de grande utilidade em uma arquitetura de microsserviços em que cada serviço é executado em uma pilha de aplicativos separada. Cada microsserviço obtém e processa seus próprios dados sem causar dependência. Esse nível de filtragem de dados e desacoplamento de aplicativos não pode ser alcançado usando o Pub/Sub.
A Figura 2 mostra vários aplicativos clientes lidando com seus respectivos conjuntos de dados em arquitetura desacoplada usando NCache consultas contínuas.
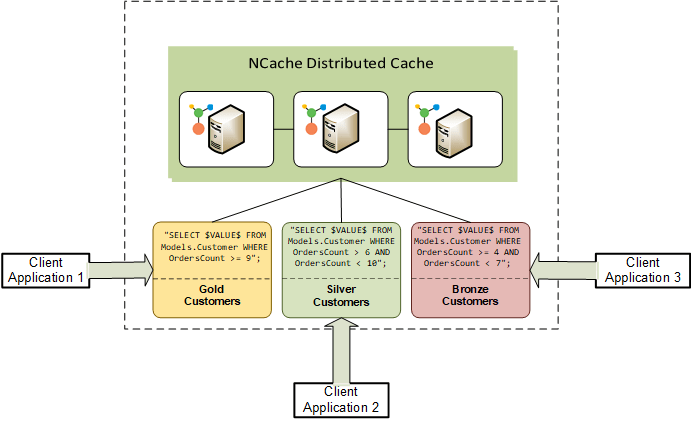
Figura 2: Desacoplamento entre aplicativos
Buscando dados usando tags
Tags in NCache são qualificadores adicionados para os dados que são usados para categorizar os dados com base neles. Para grandes conjuntos de dados, como o cenário mencionado, as tags são realmente úteis para buscar dados relevantes em vez de pesquisar os dados em todo o cache. Se um cliente se enquadra na categoria de “Clientes Gold”, uma tag é adicionada a ele para recuperação rápida. Com base nessas categorias, os clientes podem receber benefícios adicionais, como descontos, cupons etc. NCache fornece vários maneiras flexíveis de buscar dados usando tags, explicado detalhadamente na documentação.
Agora vamos ver o exemplo de código de tags associadas aos “Clientes Gold”. Esses clientes podem receber cupons ou serviços premium.
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
Dados de cache expirando
NCache permite expiração de dados em cache que invalida os dados após um intervalo específico e os remove do cache em um intervalo limpo.
NCache fornece dois tipos de expirações:
No caso de clientes, a validade é adicionada aos itens que não se enquadram em nenhuma das três categorias, ou seja, Ouro, Prata ou Bronze. Todos os outros clientes com pedidos inferiores a 4 são adicionados com um intervalo de tempo de expiração e são removidos do cache para nenhuma análise posterior. No entanto, a expiração de qualquer cliente pertencente a qualquer uma das categorias é definida como Nenhum para manter os dados no cache, a menos que sejam removidos manualmente. É assim que você pode adicionar 15 segundos de expiração a um cliente com menos de 4 pedidos.
|
1 2 3 4 5 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, new TimeSpan(0, 0, 15)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
Por que usar NCache?
NCache is 100% .NET/.NET Core, solução de cache distribuído na memória e líder no mercado há muito tempo. Ele é extremamente rápido e linearmente escalável e remove com eficiência os gargalos de desempenho do seu aplicativo ao armazenar os dados em cache. Ele economiza o custo da rede, reduzindo as dispendiosas viagens de rede. NCache fornece um rico conjunto de recursos, como Consulta Contínua, que torna a análise de dados muito rápida e eficiente, juntamente com outros recursos para facilitar o fluxo suave de seu aplicativo.
NCache Adicionar ao carrinho Baixar NCache Comparação de edições





