NCache Benchmarks de desempenho
2 milhões de operações/seg
(Conjunto de 5 nós)
Sumário executivo
NCache pode ajudá-lo a dimensionar linearmente e aprimorar o desempenho de maneira fácil e econômica. As empresas da Fortune 500 em todo o mundo confiaram NCache por mais de 13 anos para remover gargalos de desempenho relacionados ao armazenamento de dados e bancos de dados e dimensionar aplicativos .NET para processamento de transações extremas (XTP).
Este documento usará NCache 5.0 com APIs modernas e alguns novos recursos para demonstrar a escalabilidade linear e o desempenho extremo que você pode obter para seus aplicativos .NET. Neste experimento, agrupamos um modem NCache API com uma topologia de cache particionado com pipeline ativado. Os dados são totalmente distribuídos em todos os servidores de cache e os clientes se conectam a todos os servidores para solicitações de leitura e gravação.
Neste benchmark, demonstramos que o NCache cluster pode escalar linearmente e que conseguimos 2 milhões de transações por segundo usando apenas 5 nós de servidor de cache. Também vamos demonstrar que NCache pode fornecer latência abaixo de microssegundos mesmo em um grande cluster. Neste whitepaper, abordaremos as configurações de benchmark, etapas para realizar benchmarks, configurações de teste, configurações de carga e resultados. Você pode ver o experimento de referência em ação neste vídeo.
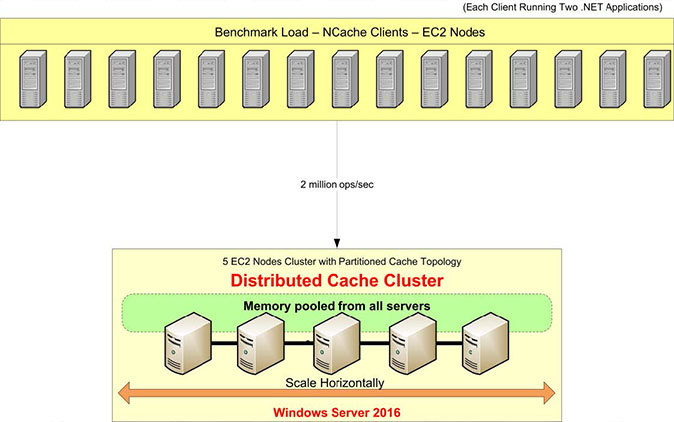
Visão geral da configuração do comparativo de mercado
Vamos revisar nossa configuração de benchmark. Vamos usar servidores AWS m4.10xlarge para este teste. Temos cinco desses NCache servidores nos quais configuraremos nosso cluster de cache. Teremos 15 servidores clientes, de onde executaremos aplicativos para conectar a este cluster de cache.
Vamos usar o Windows Server 2016 como sistema operacional – Data Center Edition, 64 bits. o NCache a versão utilizada é a 5.0 Enterprise. Nesta configuração de benchmark, usaremos um Topologia de cache particionado. Em uma Topologia de Cache Particionado, todos os dados serão totalmente distribuídos em partições em todos os servidores de cache. E todos os clientes estarão conectados a todos os servidores para solicitações de leitura e gravação para utilizar todos os servidores ao mesmo tempo. Não temos a replicação ativada para esta topologia, mas existem outras topologias, como a Topologia de réplica particionada que vem equipado com suporte de replicação.
Nós teremos Pipelining habilitado que é um novo recurso em NCache 5.0. Funciona de tal forma que no lado do cliente acumula todas as requisições que estão acontecendo em tempo de execução e aplica essas requisições de uma só vez no lado do servidor. A acumulação é feita em microssegundos, por isso é muito otimizada e é a configuração recomendada quando você tem altos requisitos de carga transacional.
Aqui está uma visão geral rápida de nossa configuração de benchmark, incluindo hardware, software e configurações de carga.
Configuração de hardware:
| Detalhes do cliente e do servidor (Máquina virtual) |
AWS m4.10xlarge: 40 núcleos, 160 GB de memória, rede - 10 Gbps Ethernet |
| Nº de nós do servidor | 5 |
| Nº de nós clientes | 15 |
Configuração de software:
| Sistema Operacional | Servidor 2016 do Windows Edição do Data Center – x64 |
| NCache Versão | 5.0 |
| Topologia de cluster | Configuração de cache particionado |
Carregar configuração:
| Tamanho da memória cache | 4 GB |
| Tamanho dos Dados | Matriz de bytes de tamanho 100 |
| Total de Itens | 1,000,000 |
| Pipelining | ativado |
| Taxa de obtenção/atualização | 80:20 |
| Tópicos | 1280 |
| Instâncias de aplicativos | 2 instâncias por máquina cliente, total de 30 instâncias |
População de dados
Após a configuração do nosso ambiente de referência, começaremos com uma população de dados de 1 milhão de itens no cluster de cache. Vamos rodar o aplicativo Client (Cache Item Loader) que vai conectar e adicionar 1 milhão de itens no cache. Um cliente se conectará a todos os servidores de cache e adicionará 1 milhão de itens no cluster de cache, após o qual poderemos começar com as solicitações de leitura e gravação.
Você pode usar esta pacote Nuget - NCache SDK para instalar o SDK na máquina cliente e configurar o pipeline entre o cliente-servidor e implantar o Load Generation Application (GitHub) para preencher 1 milhão de itens de cache no cluster de cache.
Carregar Transação de Compilação
Agora executaremos o aplicativo para construir alguma carga transacional neste cluster de cache com 80% de leitura e 20% de operações de gravação. Você pode monitorar todas as atividades usando contadores Perfmon. Inicialmente, conectaremos 10 instâncias de clientes a cada NCache servidor com atividade em buscas, bem como em atualizações por segundo.
Estágio 1 Carga de transação de 1 milhão de operações/seg
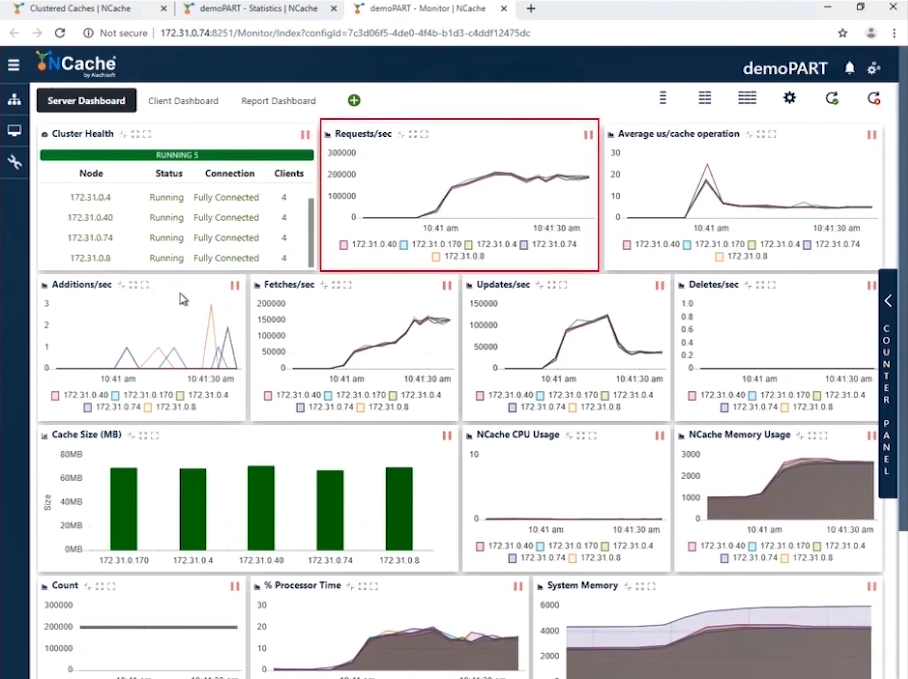
Você pode ver na captura de tela que, com 10 instâncias de cliente conectadas a um cluster de 5 nós, temos solicitações por segundo numeradas entre 180,000 e 190,000. E como temos 5 NCache servidores que estão trabalhando em paralelo, acumular essas solicitações nos leva a 1 milhão de solicitações por segundo por esse cluster de cache.
Temos uso eficiente de memória e CPU e a operação média de microssegundos/cache é um pouco menos de 10 microssegundos por operação. Nosso estágio um está concluído, onde alcançamos 1 milhão de operações por segundo em nosso cluster de cache.
| Etapa 1 - Folha de Dados Resumida | |
| Total de servidores de cache no cluster | 5 |
| Total de instâncias de cliente conectadas | 10 |
| Solicitações por segundo/nó | 180,0000 ~ 190,000 |
| Total de Solicitações - Cluster de Cache | 950,000 ~ 1,000,000 |
| % de tempo do processador (máx.) | 20% |
| Memória do Sistema | 4.2 GB |
| Latência (Microssegundo/Operação de Cache) | 10 microssegundos/operação |
Estágio 2 Carga de transação de 1.5 milhão de operações/seg
Agora que alcançamos 1 milhão de TPS, é hora de aumentar a carga na forma de mais instâncias de aplicativos para aumentar a carga transacional. E assim que esses aplicativos fossem executados, você veria um aumento no contador de solicitações por segundo. Vamos aumentar o número de clientes para 20. Com essa configuração, você pode ver na captura de tela abaixo que agora estamos mostrando 300,000 solicitações por segundo por instância. Alcançamos com sucesso 1.5 milhão de solicitações por segundo desse cluster de cache.
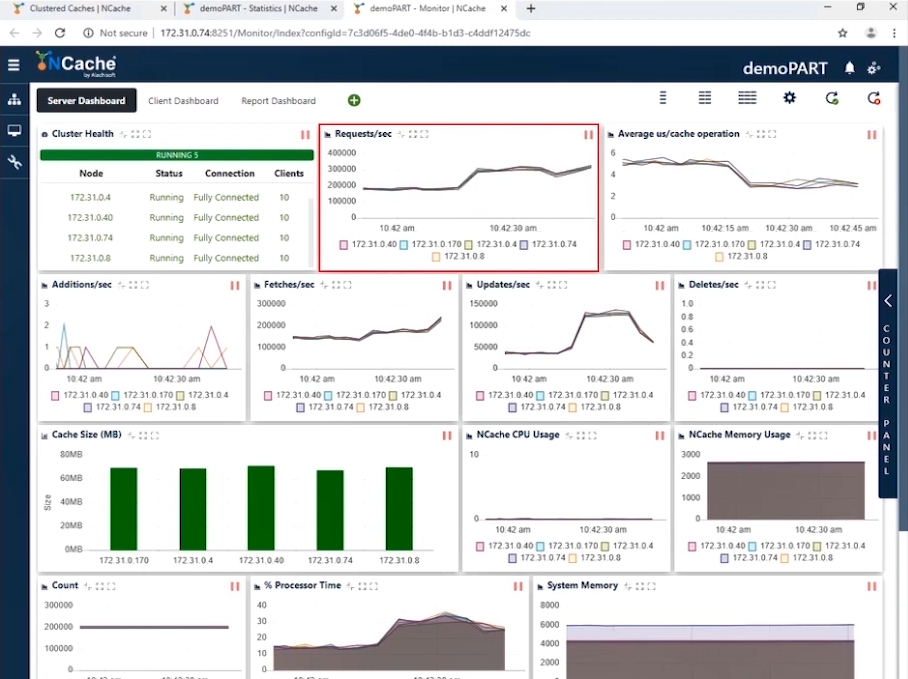
Você pode ver que a contagem de solicitações por segundo por cada servidor é de 300,000. As buscas são um pouco mais de 200,000 por segundo e as atualizações estão entre 50,000 e 100,000 e você pode ver que a média de microssegundos por operação de cache é inferior a 4 microssegundos; isso é incrível porque temos latência muito baixa junto com o impacto do pipeline. Quando você tem uma alta carga transacional do lado do cliente, o pipelining realmente ajuda e reduz a latência e aumenta a taxa de transferência. É por isso que recomendamos que isso seja ativado. Além disso, temos a média de microssegundos por operação de cache agora em torno de 3-4 microssegundos por operação de cache.
| Etapa 2 - Folha de Dados Resumida | |
| Total de servidores de cache no cluster | 5 |
| Total de instâncias de cliente conectadas | 20 |
| Média Solicitações por segundo/nó | 300,000 |
| Total de Solicitações - Cluster de Cache | 1,500,000 |
| % de tempo do processador (máx.) | 30% |
| Memória do Sistema | 6 GB |
| Latência (Microssegundo/Operação de Cache) | 3 ~ 4 microssegundos/operação |
Estágio 3 Carga de transação de 2 milhão de operações/seg
Vamos aumentar ainda mais a carga executando mais algumas instâncias de aplicativos que também mostrarão um aumento adicional nas solicitações por segundo. Agora vamos conectar 30 instâncias de clientes a todos NCache Servidores.
De acordo com a captura de tela abaixo, agora você pode ver que atendemos com sucesso 400,000 solicitações por segundo que estamos recebendo por cada NCache servidor; nós temos 5 NCache servidores de modo que faz o número de até dois milhões de transações por segundo por este NCache cluster de cache. E temos a média de microssegundos por operação de cache com menos de 3 microssegundos. Também temos a memória do sistema e o tempo do processador bem abaixo dos limites, com 40 a 50% de utilização em ambas as frentes.
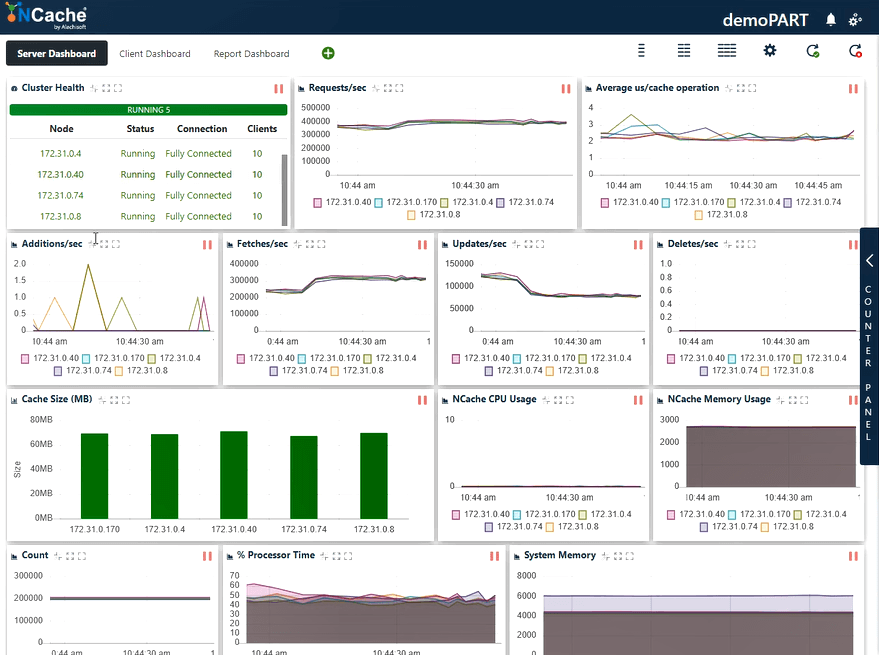
Agora temos latência de 2 ~ 3 us/operação, uma melhora em relação ao resultado anterior. Você pode ver novamente uma combinação de buscas, atualizações e uma utilização eficiente dos recursos de CPU e memória. Podemos concluir aqui que NCache é linearmente escalável. Agora vamos revisar nossos números de escalabilidade.
| Etapa 3 - Folha de Dados Resumida | |
| Total de servidores de cache no cluster | 5 |
| Total de instâncias de cliente conectadas | 30 |
| Média Solicitações por segundo/nó | 400,000 |
| Total de Solicitações - Cluster de Cache | 2,000,000 |
| % de tempo do processador (máx.) | 60% |
| Memória do Sistema | 6 GB |
| Latência (Microssegundo/Operação de Cache) | 2 ~ 3 microssegundos/operação |
Resultados de referência
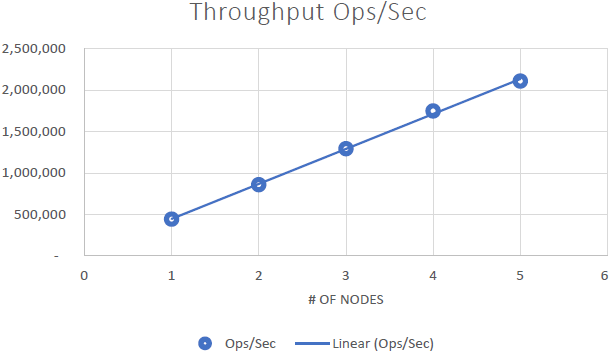
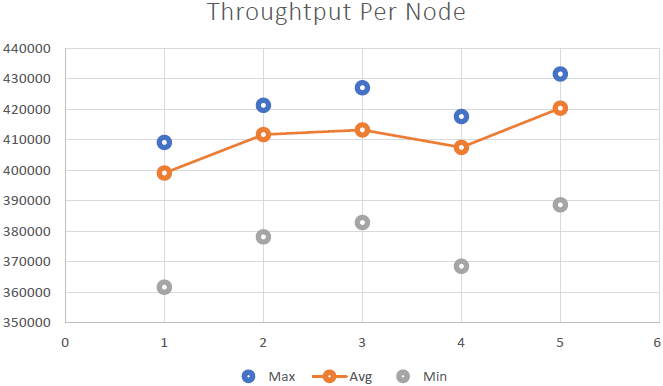
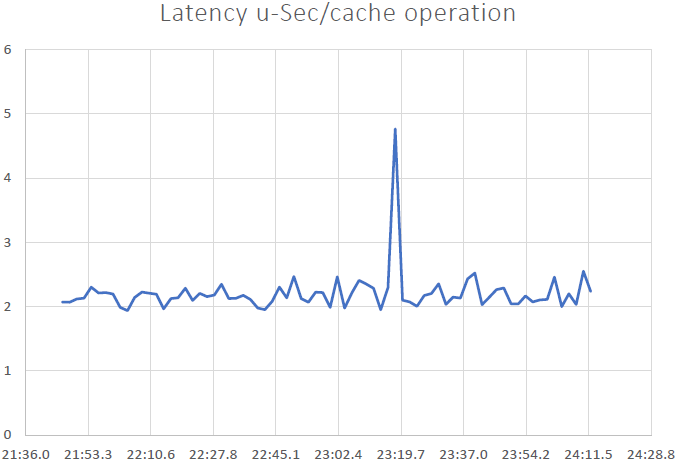
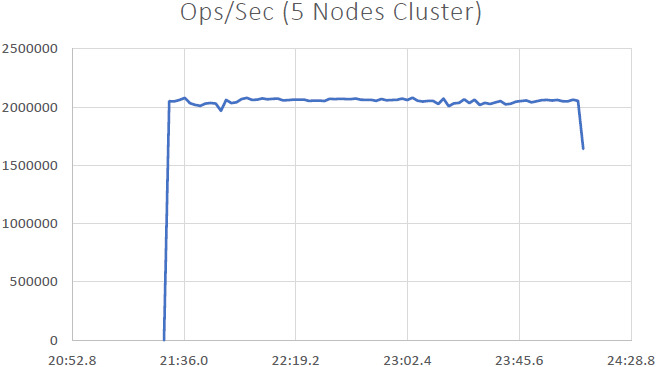
Pudemos demonstrar que NCache é linearmente escalável e conseguimos alcançar os seguintes resultados após executar os benchmarks:
Conclusões
- Escalabilidade linear: Com 5 NCache servidores, conseguimos atingir 2 milhões de solicitações por segundo. Adicionar mais e mais servidores significa mais recursos de manipulação de solicitações de NCache.
- Baixa latência e alta taxa de transferência: NCache oferece latência de submicrossegundos (2.5 ~ 3 microssegundos), mesmo com um tamanho de cluster grande. NCache ajuda a atender aos requisitos de baixa latência e alta taxa de transferência, mesmo em escala. Temos uma latência muito baixa, um impacto derivado do pipeline. Quando você tem altas cargas transacionais do lado do cliente, o pipelining realmente ajuda e reduz a latência e aumenta a taxa de transferência.