医学上的脑裂是指大脑内部的通讯故障状态; 一半的大脑不知道另一半的行为。 分布式计算中的裂脑是指集群的活动服务器之间的通信丢失。 发生这种情况时,所有子集群将失去彼此之间的所有同步和心跳连接。
就像在功能正常的大脑中一样,在分布式系统中发生裂脑的可能性是完全相同的。 如果这样的灾难降临到你的分布式系统上,那对你的系统管理员来说将是一个真正的恐怖,并且无法从中恢复。 除非你正在使用 NCache 作为您的分布式缓存。 只有这样,你才有希望。
脑裂 NCache 簇
NCache 使用互连的服务器创建自我修复的动态集群,以实现集群内通信。 但与任何分布式系统一样, NCache 集群也可以面对 裂脑 一个或多个缓存服务器与集群的其余部分断开连接并形成子集群的问题。 就像大脑一样,你的集群被分成两半,每一个都不知道对方的存在。
我们以 5 个节点的集群为例。 集群工作正常,缓存、通信、处理,但不知从何而来的网络故障将完美运行的集群分成两部分。
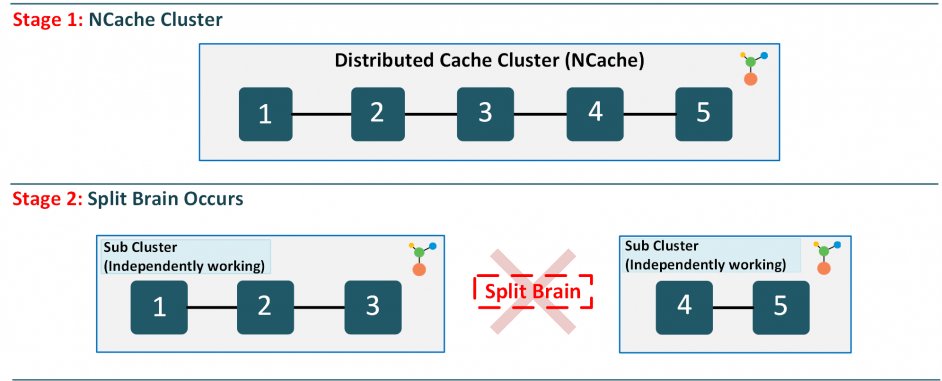
图 1:脑裂发生 NCache 簇
当集群中发生这种情况时,集群的两半开始独立行动,假设另一半已经关闭,因此产生独立的子集群。
这种行为将导致双方都拥有自己的数据副本,这些数据正在由客户端更新而没有任何同步。 当应用程序中存在缓存操作失败和数据完整性问题时,这违背了使用分布式缓存的目的。
如何 NCache 从脑裂中恢复?
从裂脑中恢复的第一步是在集群中检测它。 你很幸运, NCache 具有自动检测脑裂发生的能力。 就是这样。
NCache 在组成集群的所有缓存服务器上维护集群成员资格。 因此,每当服务器之间的连接中断时,整个集群都会收到通知。 两半(子集群)都假设它们是幸存的集群,并开始独立处理存储的数据。 除了单独行动以免影响性能之外,子集群还不断尝试与“丢失的集群”重新连接,以使初始集群重新组合在一起。 同时,两个子集群都将事件记录到 Windows 事件日志中,指示集群的状态。 子集群还可以通过电子邮件通知通知缓存管理员与某些服务器的连接已丢失。
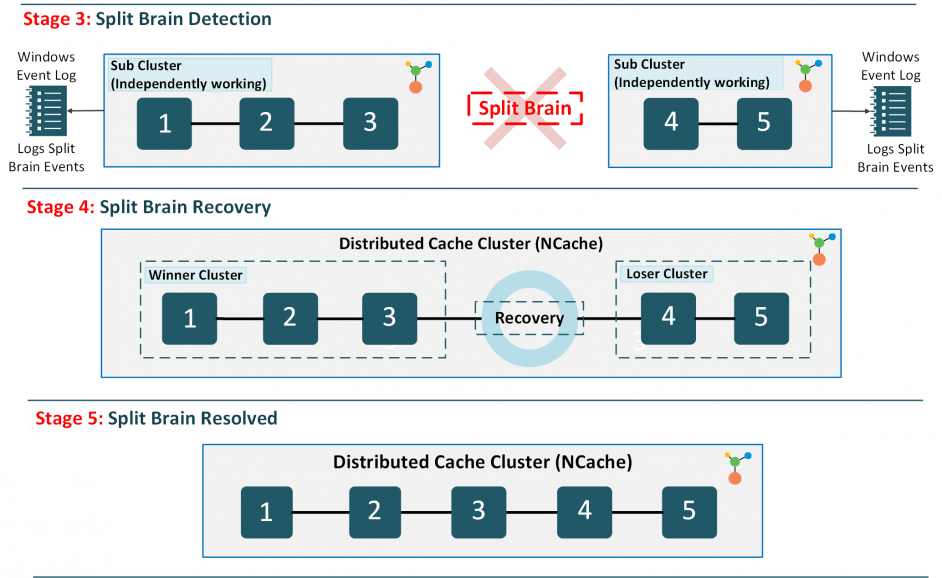
图 2:裂脑自动恢复 NCache 簇
到目前为止,双方都没有真正意识到他们遇到了脑裂。 直到网络连接恢复,他们才终于明白集群分裂的原因。
当连接恢复并且服务器开始相互通信时,就需要决定谁将成为“赢家”集群。 获胜者集群基本上是满足以下排序标准的集群:
- 包含最大节点数的子集群。 这样做是为了确保最小的数据丢失。
- 如果两个子集群的大小相同,则其协调节点的 IP 地址较低的子集群将被视为获胜集群。
一旦决定,获胜者集群有责任重新启动“失败者”集群并 redis新节点之间的贡数据。 通过这一切 redistribution,失败者集群将丢失其数据,但从好的方面来说,胜利者集群会保留其数据。
启用裂脑自动恢复
默认情况下,Split-Brain Auto Recovery 功能 NCache 被禁用。 如果您的数据不能完全丢失,您应该启用此功能。 下面提供了您可以启用的方法 裂脑自动恢复 为您的集群。
运用 NCache 网络管理员
您可以使用 NCache 网络管理器。 遵循提供的帮助 启用裂脑自动恢复 启用此功能。
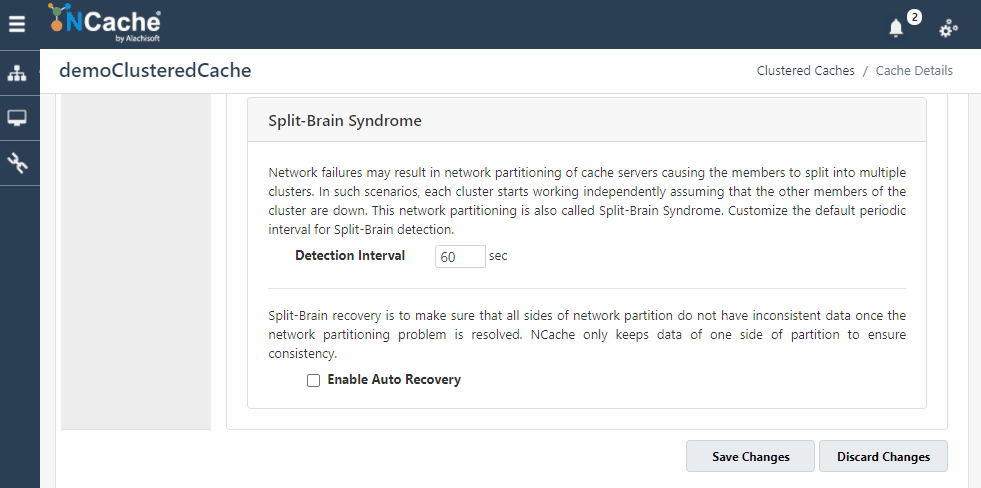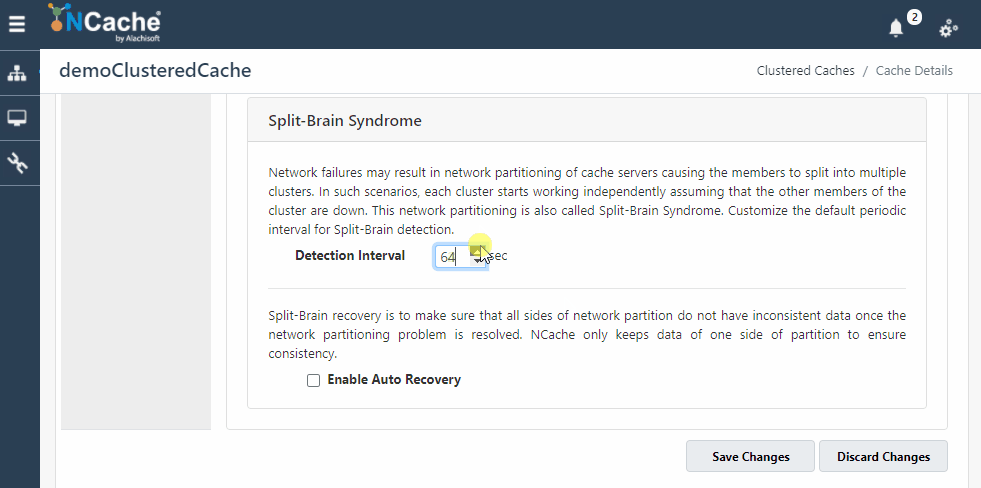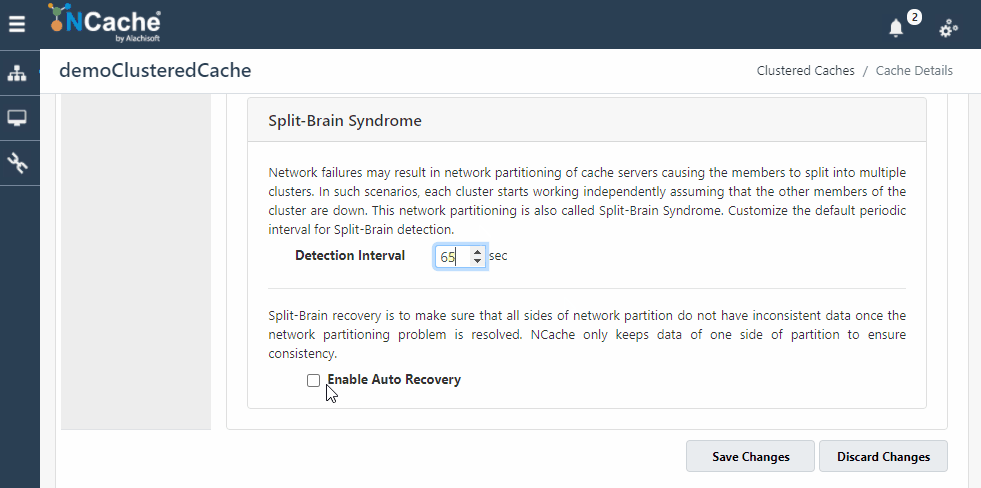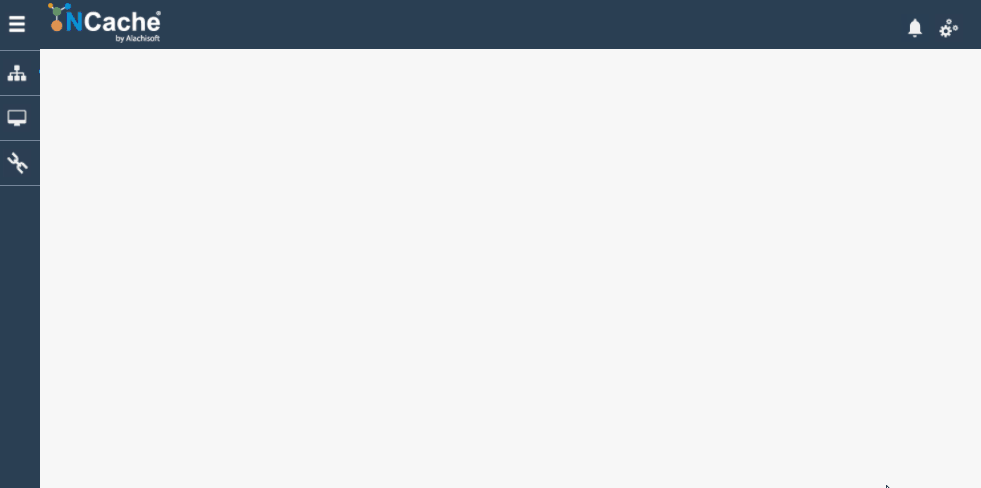
图 3:启用裂脑自动恢复 NCache 运用 NCache 网络管理员
使用缓存配置文件
可以通过启用裂脑恢复 NCache 配置文件。 手动编辑 缓存配置 按照此处提到的步骤创建文件: 手动编辑 NCache 裂脑恢复的配置.
|
1 2 3 |
<cache-settings...> <split-brain-recovery enable="True" detection-interval="60"/> </cache-settings> |
简而言之…
有时在处理数据的过程中,您的缓存集群会遇到将集群划分为子集群的网络故障。 这种划分,无论多么合乎逻辑,仍然对您的缓存数据构成威胁。 这整个场景类似于医学术语裂脑综合症。 为了纠正这种综合症对您的集群造成的可能损害, NCache 以裂脑自动恢复功能的形式提供补救措施。 如果你有 NCache 那么一旦集群被分成两半,您就无需担心管理集群。 NCache 总能节省一天的时间。



