分布式持久缓存
NCache 提供键值分布式持久缓存,以根据需要可靠地检索有价值的数据。它在持久性存储中维护缓存数据的副本,然后在缓存重新启动(计划或计划外)时加载持久数据。它存储和加载缓存服务器可以容纳的尽可能多的数据。持久化保证了数据的高可用性,同时内存中的数据提供了高性能。在本文档中,具有持久性的分布式缓存也称为持久性缓存。
备注
具有持久性的分布式缓存仅支持 分区拓扑 和 本地(OutProc)缓存.
您可以使用以下方法创建具有持久性的分布式缓存: NoSQL 文档存储作为数据备份的持久性存储。 缓存将保留所有写入 API、元信息、 流, 数据结构及 动态索引 到后端存储。
备注
Pub/Sub 消息不会持久化,但 NCache 支持 发布/订阅 API 并使您能够创建一个专用的 Pub/Sub 消息缓存.
请注意,由于任何数据失效或显式删除而从缓存中删除的数据也将从底层持久性存储中删除。 支持添加具有过期和密钥依赖项的项目。 但是,我们不推荐这种方法,因为存储在此类持久缓存中的数据是永久数据。 同时,数据与 对数据库的依赖 并且对外部资源的依赖不会持续存在。
备注
与易失性分布式缓存类似,具有持久性的分布式缓存支持后备源。
持久化缓存:为什么要持久化数据
NCache 将数据存储在 RAM 中以便更快地访问。 由于高速缓存具有易失性,因此在以下情况下数据丢失是不可避免的:
- 分区拓扑中的节点关闭。
- 分区-副本拓扑中多个节点同时关闭。
- 由于维护原因或灾难性故障,集群关闭。
使用持久缓存,您可以实现以下目标:
高数据可用性: 如果由于上述任何原因导致内存故障, NCache 通过从底层持久性存储中加载数据来快速恢复数据。 即使在发生灾难性故障后,缓存也可以正常运行,而不会影响客户端操作。
容错能力: 维护缓存数据的实时副本可最大限度地减少停机时间,并在单个/多个节点离开集群时提供容错能力。
重要
对于持久性,密钥长度不应超过 1023 字节。
持久缓存:它是如何工作的
在这里,我们描述了具有持久性的分布式缓存的工作和行为。 下图显示了基本架构。 您可以在后端使用持久性存储创建具有持久性的分布式缓存。 商店是集中的,所有节点都可以访问。 NCache 以可维护的时间间隔将添加到缓存的数据写入后端存储。 在缓存重启或节点离开/加入时,持久化数据将加载到缓存服务器可以容纳的尽可能多的内存中。
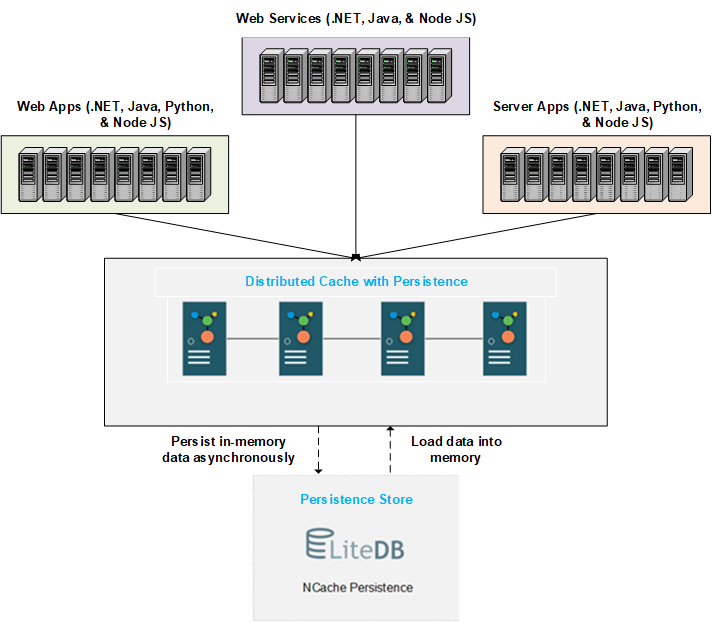
下面我们讨论数据持久化和加载的详细过程。
持久缓存中的数据持久化
一旦创建了具有持久性的分布式缓存,所有的写操作首先在内存中执行,然后持久化到后端存储。 自从 NCache 具有分布式架构,每个服务器节点都保存其数据,而所有服务器节点都可以访问存储。 此外,由于分区的原因,数据分布是基于桶的,因此数据同样会被持久化。
持久缓存中的异步持久性
NCache 通过异步持久化的方式将内存中的数据持久化到持久化存储中。 在这里我们解释它是如何工作的。 每个分区都有一个持久化队列来记录客户端执行的操作。 客户端执行的任何写入操作一旦成功就会排队。 由于持久性是异步工作的,因此客户端在将操作排队后不会等待。 排队的操作会定期在可配置的位置进行检查 persistence-interval 并最终通过持久性线程复制到后端存储。 每个队列都是独立写入的。
备注
默认值为 persistence-interval is 1 秒 并且它可以在 NCache 管理中心.
通常,批处理后应用 persistence-interval,但是如果持久化批次连续失败,那么之后 persistence-retries 批处理间隔被转移到 persistence-interval-longer. 一旦成功,批次间隔将重置为 persistence-interval.
重要
由于异步复制,客户端操作照常发生,因此缓存的性能不会降低。
如果缓存由于任何问题而无法将数据持久化到持久化队列中,它将继续进行写操作,直到缓存满为止。 如果排队的操作没有持续存在,有关失败存储桶的信息会记录到缓存日志中。
备注
分区-副本拓扑通过副本的队列从队列故障中恢复。 然而,如果节点及其副本同时关闭,数据丢失是不可避免的。
将数据加载到持久缓存中
一旦数据在存储中,缓存会在缓存重启时自动将持久化数据重新加载到 RAM 中。 持久存储必须始终对缓存节点可用。 如果他们不能访问商店,缓存将不会启动。 数据加载以分布式方式进行。 由于数据存储是基于桶的过程,每个节点都可以访问集中存储以根据数据分布图加载其分配的桶。 此外,如果您为查询缓存中的数据配置了索引,则查询索引会在缓存重启时重新生成。
重要
持久性存储应该始终对所有缓存节点可用。
数据加载过程中的操作行为
数据加载和持久化进程同时运行。 同时,如果请求的数据加载,则基于键的提取将从缓存中获取。 如果它不在缓存中,则通过延迟加载直接从商店提供此类操作。 在这种情况下,性能 Get 运行会受到影响。
请注意,非基于关键字或基于标准的搜索操作,例如 GetGroupKeys, GetKeysByTag和 SQL 查询,直到数据从存储中完全加载到内存中时才会被提供。
警告
如果在数据加载过程中发生非键搜索操作,请求的数据没有完全加载,应用程序将抛出异常说明 数据未完全从持久性存储加载.
数据加载场景
在以下场景中从持久性存储加载数据:
在缓存开始时: 在缓存启动时,协调器节点加载所有桶。 一旦其他节点加入集群,桶分布就会更新。 每个节点在本地环境中查找分配给它的桶。 缓存中加载的桶被拉取 状态转移. 如果分配给节点的桶没有完全加载,那么这些桶将由该节点直接从存储中加载。 如果缓存中存在,每个节点都可以访问存储以加载其分配的存储桶。
当具有持久性的分布式缓存第一次启动时,可以通过配置来填充它 缓存启动加载器 因为持久性存储当时没有数据。 一旦存储填充,数据总是在缓存启动时从存储加载,即使您已经配置了缓存加载器。 但是,如果您需要定期添加更多数据,您可以使用 缓存刷新器. 缓存刷新器定期运行,不管缓存和存储是否已经有数据。
在节点加入: 当一个新节点加入集群时,如果它们已经加载,它会通过状态传输从现有集群节点获取分配的桶。 如果分配的桶没有完全加载到缓存中,它们将由新节点从存储中加载。
节点离开时: 数据从存储中加载,以避免在一个/多个节点离开集群时丢失数据。 节点离开时的加载行为因不同的拓扑而异。
分区拓扑: 当一个节点离开时,它的桶分布在现有的集群节点中,并由新的所有者从持久存储中加载。
分区副本拓扑: 分区副本通过从副本的状态传输恢复丢失的存储桶,可以容忍高达一级的节点故障。 但是,当节点及其副本同时关闭时,丢失的数据仍然可以从备份存储中恢复。
重要
缓存应该有能力在节点关闭/离开的情况下容纳数据。
具有持久性的分布式缓存的容量管理
仅当缓存有足够的缓冲来容纳离开的一个或多个节点的数据时,持久缓存才能从节点离开或关闭时的数据丢失中恢复。 如果缓存由于已满或任何其他原因而无法容纳持久性存储上的所有数据,则添加或更新操作将开始失败。 同时,有些桶不会有完整的数据。 这些不完整的存储桶在两种情况下从存储中重新加载:
- 新节点加入集群。
- 通过热应用增加缓存大小。
备注
如果缓存已满但与持久性存储 100% 同步,则只会阻止新添加的内容。 所有其他操作都可能在缓存上发生而不会出现任何问题。
当缓存已满且内存中有部分数据时,缓存可能不会提供非基于键或基于条件的操作(例如 GetGroupKeys, GetKeysByTag和 SQL 查询)。 另一方面,基于键的提取将始终通过缓存或商店提供服务。 具体来说,在缓存未命中的情况下,缓存将尝试为不完整的桶延迟加载所有基于键的获取。
警告
如果基于条件的搜索操作发生在缓存已满且请求的数据不在缓存中时,将抛出异常 无法进行操作,因为缓存中没有所有数据在内存中.
缓存满容量规划
为避免缓存已满时出现的问题,您需要在开始使用之前规划持久缓存的容量。 在做持久化分布式缓存的容量规划时,我们建议您规划每个节点的缓存大小,这样如果一个节点宕机,其余节点可以容纳丢失节点的所有数据。
缓存满时缓存大小扩展
重要
NCache 试图确保单节点上的高数据可用性,并通过大小扩展保留在基于分区副本的分布式缓存中并保持持久性。 但是,我们不承诺或保证高数据可用性。
在分区副本的情况下,如果一个节点离开集群,集群中的其余节点将容纳离开节点拥有的数据。 然而,由于大小问题,离开节点的数据可能没有空间。 NCache 支持当节点离开基于Partition-Replica的持久化分布式缓存时自动扩展缓存大小。 仅单节点宕机时支持扩容模式。 目的是避免缓存中的部分数据并在完整缓存上提供基于条件的操作。
扩展过程发生在内部。 当运行的节点等于或大于配置的节点时,当单个节点离开集群时触发扩展模式。 扩展大小是根据集群中配置的节点或正在运行的节点(以较高者为准)计算的。 当缓存处于扩展模式时,集群中的每个节点都会自动增加其大小,以容纳在节点离开时通过状态传输接收到的数据。
重要
仅当剩余节点数(节点关闭后)为 {已配置节点/运行节点}-1 的最大值. 扩展大小是根据集群中配置的节点或正在运行的节点(以较高者为准)计算的。
在扩展模式下,提供基于键和基于条件的操作。 但是,如果缓存大小一旦超过配置的缓存大小,它仍然会阻止添加操作。
当新节点加入集群或通过热应用增加缓存大小时,缓存会退出扩展模式。 然后更新分布图,触发状态转移。 一旦状态传输完成,每个节点就会退出扩展模式,并且缓存大小会减少到配置的缓存大小。
备注
当缓存以扩展模式进入和存在时,缓存日志和事件日志中都会记录一个条目。
无法访问行为
在缓存启动时从持久性存储加载数据 - 因此该存储必须始终可用于缓存节点。 在这里,我们讨论持久化存储不可访问时的行为;
- 在创建缓存时: 在创建缓存时验证与商店的连接。 如果它不可访问,您将无法创建缓存并将收到错误通知。 同样,如果存储对任何集群节点不可用,缓存也不会启动。
警告
在创建缓存时所有服务器节点都可以访问持久性存储之前,缓存不会启动。
数据加载时: 由于网络故障,数据加载期间可能无法访问商店。 在这种情况下,缓存将重新尝试加载处于加载状态的剩余数据桶。 同时,基于非键的搜索操作将失败。 你可以 配置数据加载重试 在服务配置文件中。
在运行缓存时: 由于短时间或无限时间内的网络故障,正在运行的缓存可能无法访问存储。 在这种连接丢失时,缓存将继续接受写入操作并将其排队。 同时, NCache 将继续尝试以批次间隔持久化排队的操作,直到重新建立与持久性存储的连接。
如果无限次失去连接,写入操作会一直发生,直到缓存内存已满。 一旦缓存满了,后续的写操作就会失败。 然而,如前所述,将提供基于键的获取操作。
持久缓存创建和监控
备注
具有持久性的分布式缓存仅支持 JSON 序列化缓存。
您可以通过指定新存储或现有存储来创建具有持久性的分布式缓存(使用 NCache)或者通过 NCache 管理中心 或通过 PowerShell 工具.
NCache 提供不同的 性能计数器 用于监视具有持久性的分布式缓存的统计信息。 此外,您可以 使用持久性监控分布式缓存 通过 NCache 监视器、PowerShell 和 PerfMon 工具。