处理分布式缓存中的关系数据
录制的网络研讨会
作者:罗恩·侯赛因和亚当·J·凯勒
在此视频网络研讨会中,了解如何将现有数据关系应用于缓存对象以进行分布式缓存。
您可以期待听到:
- 关系数据库和分布式缓存的数据存储模型
- 对象关系映射的好处——如何在对象级别管理数据关系
- 映射“一对一”、“一对多”和“多对多”关系
- 运用 NCache 用于在对象之间建立关系以模仿关系数据行为的功能
- 使用基于键的依赖、对象查询语言、组、组 API、集合和标签
- 关系数据的其他重要分布式缓存功能
我将讨论部署分布式缓存。 当你有一个关系数据库时,你知道,你会遇到一些挑战、一些性能问题、一些可伸缩性问题,然后你会过渡到使用分布式缓存和关系数据库。 您遇到了哪些挑战以及如何应对这些挑战? 所以,这就是我们今天网络研讨会的议程。
这将是非常实用的。 我想向您展示一些代码示例。 我会讲一些真实的例子。 我列出了一些示例,我将实际使用它们来演示这一点。 而且,到最后我也会有一个动手部分来复习一些基本的 NCache 配置。
NCache,这是主要的分布式缓存产品。 我们将使用它作为这个特定网络研讨会的示例产品。 但是,总的来说,这是一个一般性的主题网络研讨会。 我们在数据库中有一个关系数据,然后你有一个分布式缓存。 如何在具有关系的关系数据中转换然后开始使用分布式缓存,这是结构化数据。 所以,让我们来看看这个。
什么是可扩展性?
所以,首先,我会谈谈可伸缩性,可伸缩性的概念。 可扩展性是应用程序中的一种能力,您可以在其中增加事务负载。 您可以在其中处理越来越多的应用程序架构之外的请求。 而且,您不会在性能上妥协,因此,如果您具有高吞吐量和低延迟,那么这种能力称为可扩展性。 因此,您可以处理大量请求负载,并且单个请求的性能不会下降。 一样! 而且,使用更多资源,您甚至可以增加它,线性可扩展性是一个相关术语,它允许您通过添加更多服务器来实际扩展您在系统中引入更多或更多请求负载处理能力的地方。 而且,在大多数情况下,性能不会下降。
因此,如果您具有低延迟并且您的请求负载有线性改进,那么之前您每秒处理 10,000 个请求,甚至对于五个用户,您有一定量的延迟,例如五个用户的几毫秒或亚毫秒响应时间; 你应该有同样的响应,对于五千或五万用户执行同样的延迟。 而且,这种不断增加用户负载及其相关请求负载的能力,称为线性可扩展性。
哪些应用需要可扩展性?
那么,什么是需要可扩展性的典型应用程序,

它将是面向公众的 ASP.NET Web 应用程序、Java Web 应用程序甚至是 .NET 通用 Web 应用程序。 它可以是电子商务系统,可以是机票系统、预订系统,也可以是金融服务或医疗保健服务,有很多用户实际使用其面向公众的服务。 这可能是 Web 服务 WCF 或任何其他与某些数据访问层交互或正在处理某些前端应用程序的通信服务。 但是,它可能在任何给定时间点处理数百万个请求。 它可能是物联网,一些后端设备可以为这些设备处理某些任务的数据。 因此,它可能会加载大量请求。 大数据处理是当今流行的流行语,我们拥有许多小型廉价计算服务器,并且通过在多个服务器上分发数据,您实际上可以处理大量数据负载。
并且,类似地,对于该特定数据将有巨大的模型请求负载。 然后可能是任何其他通用服务器应用程序和层级应用程序,它们可能处理数百万个请求、大量用户,它们是可扩展性的主要候选者。 这些是在架构中需要可扩展性的应用程序。
可扩展性瓶颈
这是一个典型的图表。 什么是可扩展性瓶颈?
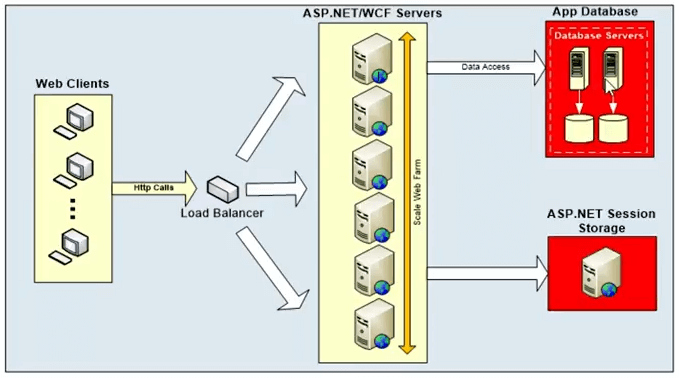
所以,这些是应用程序。 通过设计,这些框架非常可扩展。 ASP.NET Web 表单或 WCF 表单有一些选项可用于横向扩展这些系统。 但是,它们都与后端数据库通信,通常是关系数据库。 它也可以是 ASP.NET 会话存储、大型机或文件系统,但这不是我们在今天的网络研讨会中讨论的内容。 今天的网络研讨会更关注关系数据。 因此,关系数据是单一来源。 尽管您在这里拥有一个非常可扩展的平台。 您可以在此层上添加越来越多的服务器。 您可以通过在前面放置一个负载均衡器来横向扩展,并且该负载均衡器可以在不同服务器之间路由请求。 但是所有这些 Web 服务器最终都与一个不可扩展的数据库层通信。
所以,这将成为争论的根源。 开始时会很慢,然后无法扩展。 它是单一来源,无法添加越来越多的数据库服务器来增加请求的容量。 因此,请求的容量可能会达到最大值,这可能会导致高延迟。 因此,这是请求处理的容量问题,也可能最终导致延迟问题,因此当您有大量请求负载时,它可能会阻塞系统。
解决方案
因此,这是关系数据源的主要问题,解决方案非常简单,您开始使用分布式缓存。
分布式缓存系统,如 NCache 这是超快的,因为相比之下它是在内存中的,然后它是线性可扩展的。 它不仅仅是单个服务器。 这是多服务器环境,我们有一组服务器一起加入容量。 您将内存容量和事务容量汇集在一起,并从中获得一个非常线性可扩展的模型。 和, NCache 正是您可以用来处理数据库可伸缩性问题的那种解决方案。
什么是内存分布式缓存?
什么是一般的内存分布式缓存系统 NCache? 有哪些特点?
多个廉价缓存服务器的集群
它将是多个廉价缓存服务器的集群,这些缓存服务器连接在一起形成一个逻辑容量。
所以,这是一个例子。 您可以拥有两到三个缓存服务器。 为了 NCache,您可以使用 Windows 2008、2012 或 2016 环境。 只有先决条件 NCache 是 .NET 4。它是您的应用程序和数据库之间的中间层,与您的数据库层相比,它具有很强的可扩展性,但它可以为您提供与加速 .NET Web 相同的可扩展性表单或 WCF Web 服务 Web 表单。
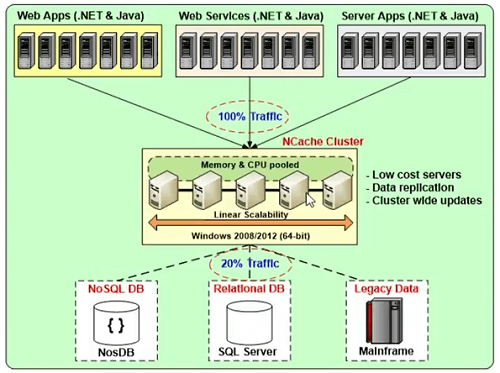
在所有缓存服务器之间同步缓存更新
在所有缓存服务器之间同步缓存更新,以便将数据一致性内置到协议中。 所有更新都以自动方式应用,并了解连接到它的所有客户端的一致数据视图。
线性扩展事务和内存容量
它应该针对事务以及内存容量线性扩展,您只需添加更多服务器,它不应该增加容量来响应它。 如果您有两台服务器并添加第三台和第四台服务器,那么由于您的服务量翻了一番,它应该基本上使该系统的容量翻倍。 所以,就是这样 NCache 优惠。
复制数据以提高可靠性
然后复制是可靠性的另一个特征。 任何服务器宕机,首先,它不应该有任何数据丢失或停机。 它应该是高度可用的高度可靠的系统,这就是 NCache 照顾。
NCache 部署
因此,在讨论了这一点之后,您在关系数据源和分布式缓存系统(如 NCache 是一个解决方案,它成为您的应用程序和数据库之间的中心层,并且您的数据存在于两个地方。
您在数据库中有数据,然后在分布式缓存中有数据。 那么,那么 NCache 当您拥有两个不同来源的数据时,还可以管理您可能遇到的一些同步挑战。 关于这个主题有一个单独的网络研讨会,但是,为了让您知道有一些数据访问层提供程序,您可以设置一些更改通知依赖项。
因此,数据库中的任何更改都可能触发缓存中项目的失效或更新,类似地,缓存中发生的任何更改或更新都可以应用于数据库。 因此,这可以在我们的数据访问层提供者的帮助下实现; 通读和直写。
并且,我们还有一些数据库变更依赖,记录变更依赖,我们实际用来保证数据库和缓存记录100%同步。 但是,通常数据存在于两个不同的地方。 您在缓存中有数据,通常是数据的一个子集,然后您在数据库中有实际数据。 当您迁移数据时,它本质上是数据的迁移。 尽管您将这两种来源结合使用,但这是两种不同的来源。
要缓存什么数据?
在继续之前,我们将快速讨论可以缓存的数据类型,它可以是参考数据,也可以是事务数据。

它更多的是您缓存的读取密集型数据,通常它属于关系数据库。 并不是说它没有改变它不是 100% 静态的。 它正在改变数据,但这种变化的频率并没有那么大。 因此,这将归类为参考数据。 而且,我们曾经交易过的数据变化非常频繁。 频率可能在几秒钟、几分钟或在某些情况下可能在几毫秒内。
而且,大多数缓存数据都是关系型的。 它来自关系数据库,我已经讨论过,您在关系数据库中拥有主副本的数据,然后您拥有该数据的子集,即参考和事务性数据,被带入分布式缓存。 正确的!
挑战是什么?
那么,挑战是什么? 所以,让我们真正讨论一下这个挑战吧! 当您将数据从数据源移动到关系到分布式缓存中以实现更高的性能、更高的可扩展性和更高的系统可靠性时。 让我们快速讨论一下您看到的挑战。

它工作得很好。 它可以提高您的性能,因为它在内存中。 它是线性可扩展的,因此它可以解决数据库的可扩展性问题。 这不是单点故障,因为有多个服务器,任何服务器都可以关闭。 您可以毫无问题地启动服务器。 维护变得容易很多。 您的升级变得容易得多。 所以,相比之下,你会得到很多好处。 但是,您需要解决一个挑战,当您迁移数据或将数据从数据库移动到分布式缓存并开始使用分布式缓存系统时,您需要考虑到这一点。
所以,分布式缓存是一个类似于接口的哈希表。 正确的! 每个项目都用键和值分隔,对吗? 因此,它是一个哈希表,其中缓存中的每个对象或缓存中的每个项目或缓存中的记录在键的帮助下表示。 所以,它不是一个表,也不是一个关系数据,我们有关系,我们定义了模式,我们有彼此之间有适当关系的实体。 它将是一个单独的键值项,表示缓存中的一个对象。 因此,数据库在实体之间存在关系,当您迁移数据或将数据从关系数据库移动到分布式缓存时,您会丢失该数据的这种关系特征。
因此,默认情况下您没有该功能,因此我们可以将其删除。 这是主要挑战之一,然后还有一些其他相关的挑战,数据库查询会导致对象集合。 它还会生成数据表或数据读取器。 所以,在分布式缓存中处理数据表和数据读取器并不是一个好主意,对吧? 所以我们实际上将一一经历所有这些挑战。
首先,我们将讨论如何管理分布式缓存中的关系,一旦您将数据从关系数据源带入缓存,您将如何处理该细节。
窥视 NCache API
因此,接下来我们将讨论缓存 API。

现在我们已经讨论过它基本上是一个键值存储。 我们有一个 cache.add ,其中我们有一个键“mykey”,然后我们有一个对象,它是任何允许的数据和允许的序列化对象。 它可以是任何客户对象、产品对象、订单对象。 但这是非常简单的 hello world 示例,我们使用 cache.add、cache.update 调用键值方法。 同样,我们调用 cache.get 来获取相同的项目,然后我们调用 cache.remove。
管理缓存中的关系
继续! 那么,如何管理缓存中的关系呢? 现在我们已经定义了缓存是一个类似于接口的哈希表的挑战,它是一个键值对。 值是 .NET 对象,键是您格式化的字符串键,它们是彼此独立的对象。 而且,数据库具有相互关联的关系表。 它可以是不同表之间的一对一一对多和多对多关系。
第一步:使用缓存依赖
您应该首先考虑做两件事,您应该考虑使用缓存依赖项,我们主要关注基于键的依赖项,这是功能之一,我将向您展示一些代码示例,这些示例可以帮助您保持跟踪缓存项之间的单向依赖关系。

因此,您可以拥有一个父对象,然后您可以在该特定对象上拥有一个依赖对象。 而且,它的工作方式是一个项目依赖于另一个项目。 主项、主对象或父对象; 如果它经过更改,它会被更新或删除,从缓存中自动删除依赖项。
我在即将发布的幻灯片中列出的一个典型示例是某个客户的订单列表。 因此,您有一个客户 A。它有订单列表,比如 100 个订单,如果该客户已更新或从缓存中删除怎么办。 您不需要那些相关的订单,因此您可能也想围绕这些订单集合做一些事情,而这正是这种依赖关系的原因,您需要在这两条记录之间建立联系,因为它们在关系型数据库。
然后,这种依赖关系也可以在本质上级联,其中 A 依赖于 B,B 依赖于 C。C 中的任何更改都会触发 B 的失效,进而也会使 A 失效。 因此,它可能是级联依赖项,也可能是多项依赖项。 一个项目可以依赖于项目 A 以及项目 B,类似地,一个父项目也可以有多个子项目。 而且,这是最初由 ASP.NET 缓存引入的功能。 这是强大的功能之一 NCache 也有。 我们将它作为一个单独的缓存依赖对象和一个精美的对象提供,这将成为本次特定网络研讨会的主要焦点。
第二步:使用对象关系映射
第二步,为了映射您的关系数据,我们建议您实际上应该将域对象映射到您的数据模型上的另一个挑战,对吗?

因此,您的域对象应该代表一个数据库表。 您应该使用某种 O/R 映射,也可以使用一些 O/R 映射工具。 它简化了您的编程,一旦您将类映射到数据库表,您就可以重用代码。 您甚至可以使用 ORM 或 O/R 映射工具,例如实体框架和 NHibernate。 这些是少数流行的工具。
这里的想法是你应该在应用程序中有类。 对象,应用程序中的域对象。 因此,您的数据库对象、数据表或数据读取器被转换映射到域对象。 因此,客户表应该代表应用程序中的客户类。 同样,有序集合或订单表应该代表订单类和应用程序。 然后这些是您在分布式缓存中处理和存储的对象,并在 Key Dependency 的帮助下制定关系。
处理关系示例
举个例子吧!
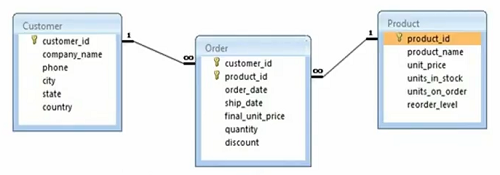
而且,我们有来自 Northwind 的数据库模型。 我们有客户表,我们有订单表,然后我们有产品。 我们有客户的所有列名,我们有客户 ID、公司名称、电话、城市、州、国家、一些属性。 同样,我们有带有产品 ID、名称、价格、库存单位、订购单位、再订购级别的产品。 因此,这些是产品的一些属性或一些列,然后我们还有订单表,其中客户 ID 和产品 ID 作为外键。 这是制定一个复合主键,然后我们有订单日期、发货日期和订单本身的一些属性。 如果您注意到,客户和订单之间存在一对多的关系,然后产品和订单之间存在一对多的关系。 同样,我们在订单和客户以及订单和产品之间分别存在多对一和多对一。 因此,我们将处理这种特殊情况。
最初,客户产品多对多关系被规范化为两个一对多关系。 所以,这是一个规范化的数据模型,我们将使用一个例子,我们在主对象上有一个类映射到这个特定的数据模型。 因此,我们稍后将讨论主要对象,但让我在这里快速向您展示示例。
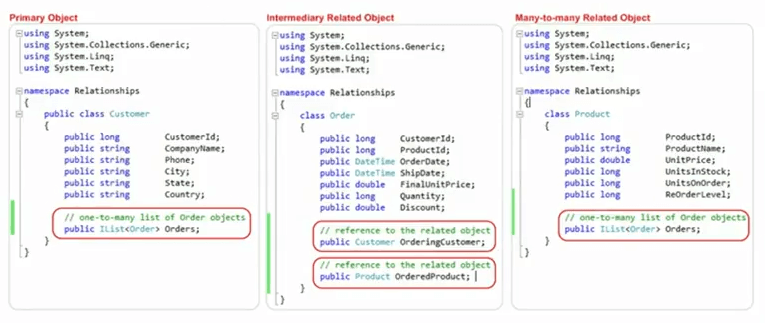
请注意,域对象映射到我们的数据库模型。 对于同一个示例,我们有一个客户类,它的客户 ID 将用作主键,然后我们有一个订单集合,代表与订单类的太多关系。 同样,我们有一个产品,其产品属性与这些产品 ID、名称、单价相同,对吗? 然后我们在这里也有订单集合,它代表一对多关系,在订单方面,我们有从这里带来的客户 ID 产品 ID 从这里带来,然后我们有订购客户,客户多对 -一种关系,然后我们将产品订购为多对一关系,作为域对象的一部分。
因此,这是我将在接下来的幻灯片中详细介绍的技术之一。 让我也向您展示 Visual Studio 中的这些对象,因此这是课程之一。
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.Runtime;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Alachisoft.NCache.Runtime.Dependencies;
using System.Collections;
namespace Relationships
{
public class Customer
{
public long CustomerId;
public string CompanyName;
public string Phone;
public string City;
public string State;
public string Country;
// one-to-many list of Order objects
public IList<Order> Orders;
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// Let's cache each product as seperate item. Later
// we'll search them through OQL
foreach (Product product in products)
{
string productKey = "Product:ProductId:" + product.ProductId;
cache.Add(productKey, product, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
cache.GetGroupData("DummyGroup", "DummySubGroup");
cache.GetByTag(new Alachisoft.NCache.Runtime.Caching.Tag("DummyTag"));
}
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string query = "SELECT Relationships.Product WHERE this.UnitPrice >= ?";
Hashtable values = new Hashtable();
values.Add("UnitPrice", unitPrice);
ICacheReader products = cache.ExecuteReader(query, values, true);
IList<Product> prodList = new List<Product>();
// For simplicity, assume that list is not very large
while (products.Read())
{
prodList.Add((Product)products.GetValue(1));// 1 because on 0 you'll get the Cache Key
}
return prodList;
}
}
}我会推荐的一件事是你用可序列化的标签来装饰这些类,对吧? 所以,你需要缓存它们,对吧? 因此,这些域对象应该被序列化,因为它们将在您的客户端应用程序和分布式缓存之间来回传输。
所以,我们有客户类,我们有产品类,就在这里。 订单列表,我们有订单类,它也具有演示幻灯片上显示的所有属性。
什么是主要对象?
接下来,我们将讨论主要对象。 现在我们已经展示了一些映射在这个域数据模型上的主要对象。 我们将向您展示一些技巧来处理一对一的一对多和多对多的关系。
因此,首先,我将讨论一个我将在即将发布的幻灯片中使用的术语。

主要对象,它是一个域对象。 它映射到您的数据库。 这是您的应用程序的起点,例如,您有一个客户对象,然后如果您需要订单,您需要客户开始,对吗? 因此,它是您的应用程序获取的第一个对象,并且与此相关的所有其他对象都将与此相关,对吧?
另一个示例可能是,如果您正在正确处理订单,那么您可能想在该处理单元中获取订单,然后您想知道订购它以发送该特定订单的客户,对吗? 因此,在这种情况下,订单成为您的主要对象,然后它具有多对一关系,或者它与实际订购该特定订单或该订单中所有产品的客户之一有关系。 所以,这将是一种或另一种方式,但我们将给出我们将使用一个将缓存的主对象,然后我们将使其他对象依赖于它。 这就是将要遵循的方法。
分布式缓存中的关系
所以,让我们真正开始吧。 所以,首先,我们将讨论分布式缓存中的一对一和多对一关系,这是最常见的场景,对吧? 因此,一种选择是使用主对象缓存相关对象。 现在您已经看到了我们的域对象,我们有一个订单列表作为客户的一部分。 因此,如果我们填充这些订单并且客户将这些订单作为它的一部分,如果您将客户作为单个对象存储在缓存中,其中包含所有订单,对吗? 所以,这将完成工作。
使用主对象缓存相关对象
所以,这里有一个代码示例。
// cache order along with its OrderingCustomer and OrderedProduct
// but not the "Orders" collection in both of them
public void CacheOrder(Cache cache, Order order)
{
// We don't want to cache "Orders" from Customers and Product
order.OrderingCustomer.Orders = null;
order.OrderedProduct.Orders = null;
string orderKey = "Order:CustoimerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}我们有一个缓存订单,我们将订单中的订购客户设置为“null”。 好的! 所以,我们没有订单也有客户参考。 这是多余的。 这不是一个很好的编程实践,但这只是为了强制执行。 我们不希望缓存来自客户和产品 ID 的订单。 因此,我们只想在缓存中添加一个客户,然后我们希望将订单作为其中的一部分。
那么,让我们来看看这个,对吧? 因此,我们将它设置为 null 然后我们简单地存储它,或者如果我们不将它设置为 null 这实际上可以有一个返回的引用。 同样,如果我们有客户,对吗? 因此,如果我们不将订单设置为 null,尽管这是一个单独的对象,但如果我们只是简单地存储这个客户,让我带你到这里,因为它有一个订单列表,如果我们简单地将这个客户存储为缓存中的单个对象,它具有我们的订单集合作为该对象的一部分。 尽管我将它设置为 null 用于另一个示例,但只是为了向您展示这种特殊情况,您可以对一个大对象进行排序,它会将所有相关对象作为该对象的一部分。
因此,您需要从域对象开始,您应该将您的关系作为域对象的一部分捕获,并且无论如何都应该这样做。 而且,在那之后你应该缓存,你实际上应该有一个填充的订单列表,相关对象的列表作为其中的一部分。 因此,这是您可以获得的最简单的方法。
它的一些好处是你有一个代表一切的对象。 但是,也有一些缺点。 这将是一个更大的物体。 在某些情况下,您只需要客户,但最终会收到订单。 您将处理更大的有效载荷。 而且,您在缓存中没有作为单独项目的细粒度订单,因此尽管您只对一个感兴趣,但您必须一直处理订单集合,对吗? 所以,这是一种方法。 这就是起点。
分别缓存相关对象
其次,您将加权对象作为单独的项目缓存在缓存中。
public void CacheOrder(Cache cache, Order order)
{
Customer cust = order.OrderingCustomer;
// Set orders to null so it doesn't get cached with Customer
cust.Orders = null;
string custKey = "Customer:CUstomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures order is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}一个例子是我们有缓存订单的订单类,对吧? 所以,这是我们有客户的例子。 首先,对吧? 然后我们将客户存储为单个对象,您可以看到我们得到了订单,然后我们从订单中提取了客户,然后我们将该客户对象中的订单集合设置为空,对吗? 因此,这是您应该在构造函数中执行的操作,但在这里执行此操作只是为了强制此客户对象没有此订单作为其中的一部分。 然后,您将此客户存储为单个对象。 我们在这里所做的是创建一个客户键,它是客户、客户 ID、运行时参数,然后我们将客户作为单个对象存储在缓存中。
接下来我们要做的是创建一个缓存依赖项。 所以,我们谈到了我们想要做的两个步骤,一个是将数据模型映射到域对象上,因此域对象应该表示数据库中的关系表,然后一旦您计划缓存它们,您就有了主对象在这种情况下,它是客户,然后我们有与客户以一对多关系相关的订单。 您在缓存依赖对象的帮助下创建客户和订单集合之间的依赖关系。 您创建一个缓存依赖项。 同样的缓存依赖有两个参数; 第一个是文件,对吧? 所以,它可以依赖于文件名,也可以依赖于密钥,对吧? 因此,我们将第一个参数设置为 null。 所以,我们不希望它依赖于任何文件。
里面还有一个特点 NCache 您可以在其中使项目依赖于某个文件系统文件系统上的某些文件。 然后,如果您使用基于键的依赖项,它需要父项的键,子项将依赖于该键。 然后,我们构造订单集合的订单键。 我们在这里有整个订单集合,它被传递给这个方法,然后我们简单地调用 Cache.Add order。
现在客户和订单是相互关联的。 我们有一个来自该客户的订单列表,这些订单在缓存中表示为一个单独的对象,因此当您需要该特定客户的所有订单时,您只需要使用此键即可。 你需要做的就是打电话,让我在这里实际使用这个例子。 对不起! 您可以调用 Cache.Get ,然后您只需传递订单键,这将获取我们在此方法中构造的特定订单,对吗?
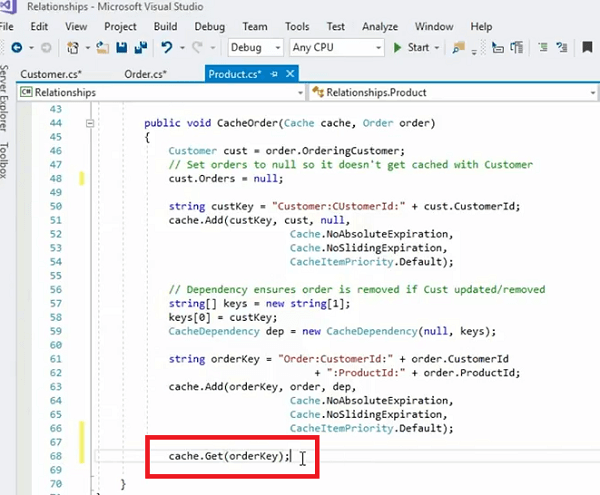
因此,这就是您一次获取该特定客户的所有订单的所有集合所需要的。 但是,如果客户发生变化怎么办? 如果客户得到更新,订单集合不需要保留在缓存中。 它可以被删除,或者在某些情况下也可以更新,对吧?
因此,这是我们的方法二,它在存储方面、可用性方面更加复杂,它还映射了我们的一对多关系或多对一关系中的两条记录。 也可以是其他方式,我们将在稍后介绍,您可以拥有订单列表,每个订单可以映射到这些单独的订单可以映射到多个 ID 订单可以映射到一个客户,如果订单是该特定应用程序代码的主要对象。 现在这定义了客户和订单之间的关系。
关于缓存依赖特性的更多细节。
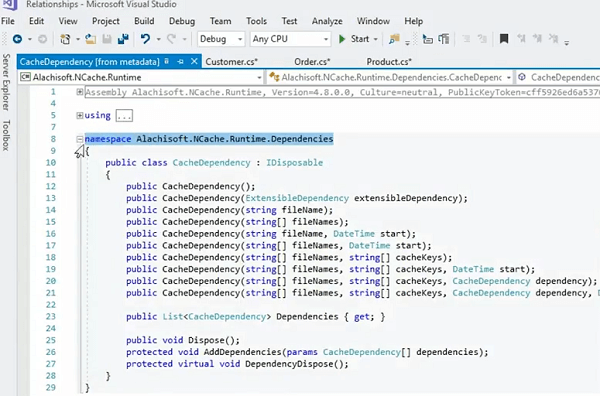
如果我去这里,它首先是暴露的,但在 Alachisoft.NCache.Runtime.Dependencies 这是您使用的重载之一,然后您只需在此处使用此特定方法。 而且,它的行为是这样一种方式,它允许您简单地跟踪对象之间的单向依赖关系,并且它也可以像演示文稿前面所讨论的那样级联。
一对多关系
接下来,我们将讨论一对多关系。 因为我们谈到了一对一或多对一,我们有订单,然后我们有一个客户,所以这在大多数情况下类似于一对多,但因为它的起点是订单,然后我们插入客户,存储客户,然后我们存储订单集合,然后我们定义订单集合和该客户之间的多对一关系。

现在,一对多的关系,这将与我们讨论过的非常相似。 我们的第一个选择是将对象集合缓存为主要对象的一部分,因此客户是您的主要对象,订单应该是其中的一部分。
第二项是您的相关对象是单独缓存的,但缓存中的个别项目,对吗?
一对多——分别缓存相关的对象集合public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}所以,这是一个单独的集合,我们有订单,我们在这里有一个客户对象是一对多的,客户有订单,我们从中得到了订单集合,然后我们将客户订单设置为空,所以客户是一个 e对象,一个主要对象,订单集合是一个单独的对象,然后您存储客户,存储数据缓存依赖项并存储订单。 所以,这将是一个一对多的整个集合。
一对多——分别缓存相关集合中的每个对象第二种方法是这个集合也可以分解。
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
// Let's cache each order as seperate item but assign it
// a group so we can fetch all orders for a given customer
foreach (Order order in orders)
{
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
CacheItem cacheItem = new CacheItem(order);
cacheItem.Group = "Customer:CustomerId:" + cust.CustomerId;
cacheItem.Dependency = dep;
cache.Add(orderKey, cacheItem);
}
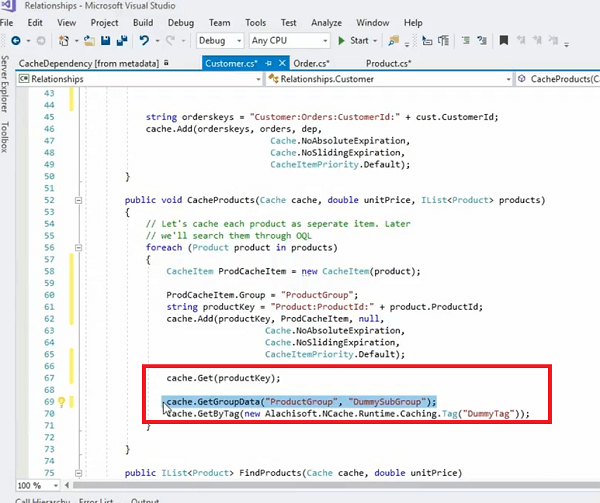
}订单集合可以是单独的,该集合中的每个项目都可以是缓存中的单独项目。 因此,在这种情况下,我们将只使用相同的方法。 我们将获取客户,获取订单,存储客户,使用关键依赖创建该客户的依赖,然后我们将遍历所有订单。
让我在这里通过缓存客户方法,因为它在这里更直观。 因此,我们从中获取订单集合,我们将客户订单设置为空,因此客户仅与客户有关,使用缓存将客户存储在缓存中。添加键,围绕客户的特定键构建缓存依赖关系,然后然后我们简单地迭代。 这里有一个循环。 我们实际上应该遍历它,这实际上更好的是我们遍历它,然后我们只需将它作为单独的项目一次存储在缓存中,因此订单在每个订单中都有自己的键是缓存中的单独项目。 而且,我们已经完成的另一件事是我们实际上已经将这些我们称为缓存项添加组和客户 ID 分组。 所以,我们实际上也在缓存中管理一个集合。
让我看看我是否有.. 你去吧,例如,我们就在这里。 我们实际上可以缓存这些产品,顺便说一句,这是另一个例子,我们循环了所有产品集合,然后我们将它们单独存储,然后我们实际上将所有东西放在一个组中,对吗?
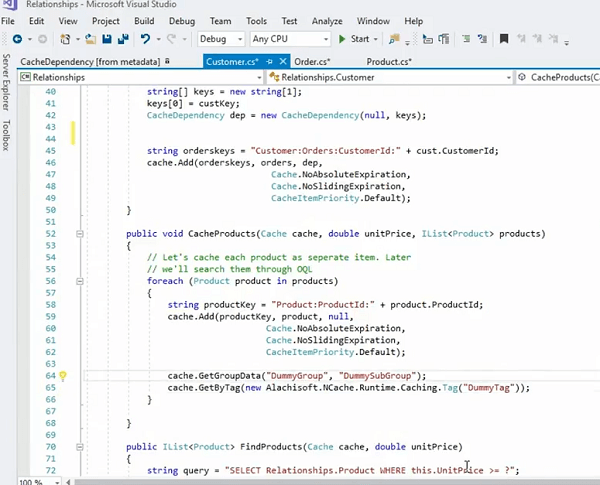
因此,这个作为项目存储的产品也可以像这样存储在我们有 ProdCacheItem 的地方。 我的键盘正在弹奏,所以请多多包涵! 让我们暂时使用它,然后我将简单地做。 我实际上可以添加一个组。 所以,这实际上允许我为此设置一个组。 现在让我们说虚拟组。 如果我存储这个缓存项目,它实际上可以有一个产品作为这个项目,对吧? 因此,我什至可以将它安排在一个组中,而不是存储实际的原始对象。 我可以简单地使用产品缓存项。 给你! 正确的? 所以,现在它实际上是或者不是使用虚拟组,让我们说产品组是对的,当我需要获取它时,我可以简单地使用产品组,它会一次获取这个集合的所有项目。 尽管这些是单独存储的,但这些都是单独的 Cache.Get 调用产品集合中的各个产品是单独排序的,但我可以将它们排列在集合中的一个组中,然后我可以获取它们。 但这样做的好处是它仍在使用依赖项,对吧? 因此,它使用了一个客户对这些单个项目的依赖关系。
所以,让我们举个例子,我们有一个客户有一百个订单。 因此,我们总共将在缓存中为客户提供一项项目,我们将在缓存中将一百个订单分别存储为一百个项目,并且该一位客户和一百个订单之间存在单向依赖关系。 如果您从缓存中删除该一位客户,一百个订单将立即失效。 而且,如果您需要,现在您可以获取单个订单。 因此,您可以单独与这些项目进行交互。 一次一件。 你需要一个可以处理的订单,当你需要这些订单的整个集合时,你可以简单地调用 Cache.GetGroupData,并提供产品组,然后子组可以是任何东西。 它甚至可以为空,然后您也可以使用该标签。
例如; 另一种管理方式是使用产品项目并为其创建标签,对吗? 然后,你..有一个..是的! 它在那里,你可以提供一个标签,可以像产品标签一样,对吧? 然后你可以把它作为其中的一部分。
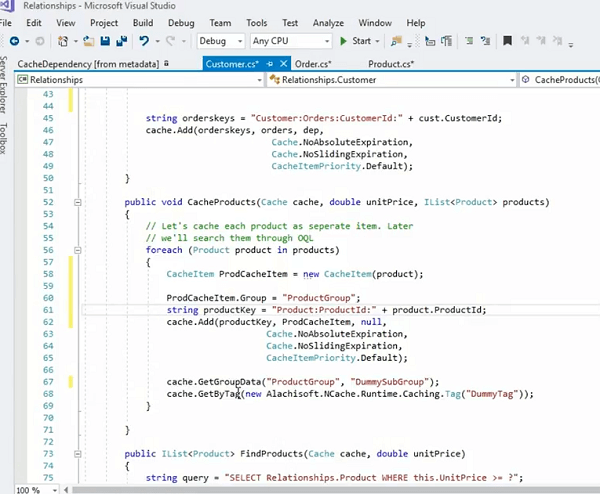
因此,这实际上可以在同一行上工作,您也可以通过标记方法调用 get,这将同时处理所有项目。 它会立即为您带来所有物品。 因此,这将使您可以更好地控制缓存中的数据排列,然后仍然保持一对多关系完好无损。
因此,这需要处理一个非常特殊的场景,其中我们有一对多关系并且我们添加了一个对象,然后我们将这些项目放在集合存储单独存储在缓存中的该集合中的多个项目然后你仍然有一个依赖,然后你仍然有一个与这些相关项目的行为的集合类型。 所以,这些项目是相互关联的,它们形成一个集合,然后它们在一对多的公式中与另一个对象建立了关系。 所以,这个代码片段,非常简单直观的 API 可以处理所有这些场景。 您在关键依赖关系的帮助下捕获了一对多关系。 您已经在缓存中单独排列了这些项目,但您仍然将它们放在组或标签的逻辑集合中,然后当您需要单独的这些项目时,您调用缓存开始获取,对吗?
因此,获取此项目的一种方法是调用 Cache.Get,对吗? 并在这里使用作为产品密钥的密钥,对吗? 因此,这会为您获取使用此特定密钥存储的特定产品,对吗? 而且,另一个选项是您需要该集合中的所有项目,以便您可以使用 Cache.GetGroupData。 因此,它可以为您提供收集行为,同时还可以为您提供对这些相关项目的个人管理。
因此,这应该同时处理集合中的集合和项目以及一对多。
多对多关系
接下来,我们有多对多的关系。

多对多关系通常不存在于域对象中。 它也总是会被规范化为数据库中的两个一对多关系。 事实上,我们在客户和产品之间建立了多对多的关系。 我们在中间对象的帮助下将多对多关系规范化为两个一对多关系。 因此,我们在客户订单和订单到产品之间分别存在一对多和多对一。 所以,这就是你处理多对多的方式。 因此,它最终会使用一对一的多对一或一对多的关系。
所以,这应该照顾你的多对多关系。
处理分布式缓存中的集合
接下来是你有一个集合,我们已经在我们的产品示例的帮助下触及了这一点,但我仍然会通过它作为一个项目缓存到我们的集合中。

例如,您存储产品。 让我们通过它,对吧?
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// cache the entire collection as one item
string productskey = "Product:UnitPrice:" + unitPrice;
cache.Add(productskey, products, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string productskey = "Product:UnitPrice:" + unitPrice;
IList<Product> products = (IList<Product>)cache.Get(productskey);
return products;
}所以,你有缓存产品,所以你创建了一个产品密钥,然后你有被带到这里的产品列表,然后你缓存它们并有一个对象。 而且,就像我之前解释的那样,它会起作用,它只会让你完成工作,而且它主要在你一次需要该列表中的所有项目时起作用。 您对该列表中的单个项目不感兴趣。 您对整个商店的整个列表作为一个项目完全感兴趣,但它会使对象更重,它不会为您提供编码、搜索的支持,这是我们的下一个主题。 因为它是一个通用列表,所以我列出了,里面有一个产品,但是 NCache 这只是一个列表,我列出。 正确的! 因此,您无法在该列表中精确定位对象,然后是属性,然后您无法根据这些属性进行搜索。
因此,一种更复杂的处理方式是分别缓存每个集合项。 我们在前面的示例中介绍了这一点,但让我们再看一遍。 例如; 让我们再次浏览缓存产品,您只需将它们存储为单独的项目。 让我为你找到这个例子! 好的! 它在那里。
所以,首先,我们实际上会单独存储产品,对吧? 我们将围绕单个产品构建一个密钥。 这样做的好处是,产品集合的所有单个项目都作为单个项目存储在缓存中,因此您可以使用重载的键,即 Cache.Get 的方法来获取它们。 您也可以将它们作为一个集合来获取。 这是我们详细讨论过的事情。 另一种选择是您也可以运行查询,并且这些类似 SQL 的搜索查询可以直接应用于对象的属性。 而且,只有当您单独存储它们时,您才能执行此操作,集合中的所有项目都存储为单独的项目。 您将它们映射到域对象(在这种情况下为产品),并且产品集合中的产品作为单独的项目单独存储在缓存中。
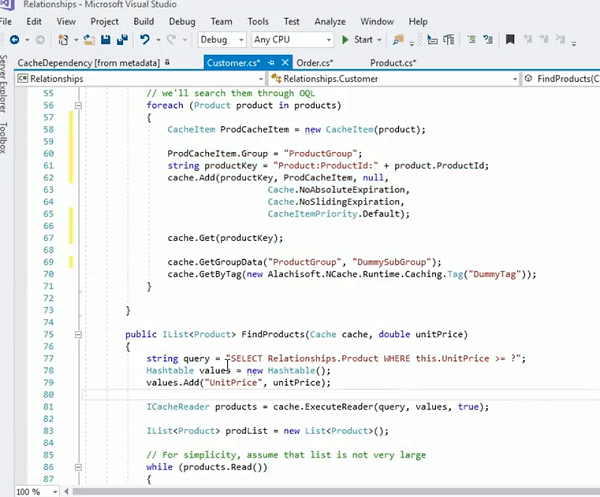
现在您可以索引产品的单价,产品 ID,然后您可以运行这样的查询。 选择产品,即产品的命名空间,其中设置单价等于运行时参数。 然后,您可以调用 Cache.ExecuteReader,这将获取您可以迭代的所有产品,并继续在您的应用程序中获取。 同样,你也可以在哪里说出This.Tag。 如果您在其上关联了一个标签,您也可以对其运行查询。 这是标签的另一个好处以及检索优势、性能优势,它还从搜索的角度为您提供了灵活性。 而且,标签还通过标签为您提供 Cache.Get。 它为您提供所有 API,通过所有标签获取任何标签,因此您实际上也可以使用这些标签 API 获取对象。 但是,我想强调的功能是您可以单独安排它们。 这就是起点。 您可以使用标签或组创建逻辑集合。 因此,检索更容易。 您需要调用 Cache.Get 的单个项目。 根据密钥获取项目。 您需要使用组或标签出现的集合,并且在它之上您可以运行查询并可以关联,您实际上可以根据条件获取我们的项目。
在这种情况下,它可能是单价。 单价可以大于10,小于XNUMX。 因此,支持逻辑运算符,您也可以进行一些聚合,计数,求和,在操作中通过类似运算符的分组有一些排序顺序,因此就支持而言,它非常令人兴奋,它类似于 SQL,它是SQL 查询,但它的使用非常灵活,并且在您需要的项目方面,它让您很容易使用。 您不再需要使用密钥。 因此,只有当您简单地将每个集合项单独存储在缓存中时,才会发生这种情况。 我希望这会有所帮助。
入门 NCache
这完成了我们今天的主题。 最后,我将向您展示开始使用的五个简单步骤 NCache 只是过去 NCache 配置,然后能够在实际应用程序中运行这些 API。
好的! 所以,我要快速开始。 我打开了管理工具。 顺便说一句,我们最近发布了,实际上我们刚刚发布了 4.9。 所以,这是我们的最新版本,所以您可能想开始使用它。 因此,您需要做的就是创建一个缓存,按其名称,选择下一步,选择一个缓存拓扑,分区副本缓存是最合适的,异步复制选项,在这里您指定将托管此缓存的服务器。 我已经安装了演示一和二 NCache.
因此,第一步是下载并安装 NCache. 第二步是创建一个命名缓存。 所以,我将通过它,保持一切默认,因为这不是今天讨论的主要范围。 我将介绍每台服务器上缓存的默认值和大小。 只需设置基本设置并选择完成。
第三步是添加一个客户端节点。 我只会用我的机器。 看看我是否可以访问这个,是的! 好的! 所以,这就是我的机器就在这里。 我已经添加了,所以第三步完成了。 服务端和客户端的所有配置都已完成。 作为第 4 步的一部分,我现在需要启动和测试这个缓存集群,然后我会检查它,然后在实际应用程序中使用它。 所以,这就是开始的简单 NCache.
我将向您展示一些快速计数器以向您展示实际情况,然后我们也将快速结束演示。 我将右键单击并选择将打开性能计数器的统计信息,我还可以打开监控工具 NCache 显示器,自带 NCache.
所以,它是由性能计数器驱动的。 它为您提供服务器端性能计数器和客户端执行计数器。 而且,在客户端应用程序端,我可以运行这个压力测试工具应用程序,它再次安装 NCache. 它之所以命名,是因为已经完成了配置,因此它会自动连接到缓存并开始模拟我的缓存集群上的负载。 给你! 因此,我们有请求负载来自这里以及其他服务器。
同样,我们在此服务器以及连接报表查看器服务器和客户端的客户端上显示活动。 然后您还可以拥有自己的自定义仪表板,您可以在其中插入任何这些计数器。 例如,API 日志就是一个很好的例子。 它实时记录所有正在缓存中执行的请求,对吗?
所以,这是使用左侧主计数器的一个简单示例。 就像我说的,这只是为了让您了解缓存的样子。 现在我可以在实际应用程序中实际使用它。 我可以在这里使用我的机器,我可以简单地使用附带的基本操作示例 NCache. 您需要做的就是在示例 .NET 基本操作中有不同的针文件夹,只要使用 NCache 您可以使用的客户端库 NCache SDK NuGet 包。 这是获取所有客户端资源的最简单方法。
另一种选择是您实际使用 Alachisoft.NCache.运行时和 Alachisoft.NCache.Web 图书馆自己。 你包括那些。 这些是这些是开始的库 NCache 在 Microsoft 缓存文件夹中。 一旦你安装 NCache 这将是其中的一部分,然后我将快速向您展示您需要做什么。 给你! 因此,您首先需要添加对这两个库的引用; runtime 和 web,包括我刚刚强调的这些命名空间。 Web.caching,然后从那时起,这个示例对于基本初始化连接到它的缓存、创建一个读取它的对象、删除它、更新它所有类型的创建、读取、更新、删除操作来说已经足够好了。
所以,这就是你初始化缓存的方式。 这是主要的电话,对吧? 它需要缓存名称返回一个缓存句柄,然后简单地调用缓存或添加将所有内容存储在一个键值对 Cache.Get 项中,然后更新项缓存或插入,然后您 Cache.delete。 而且,我们已经向您展示了一些使用基于键的依赖关系的详细示例,这些示例使用标签、使用 SQL 之类的搜索的组。 因此,这实际上应该为您提供一些有关设置环境的详细信息,然后能够在实际应用程序中使用它。
我们的介绍到此结束。