六个原因 NCache 优于 Redis
录制的网络研讨会
伊克巴尔汗
了解如何 Redis 和 NCache 在特征级别相互比较。 本次网络研讨会的目标是让您更轻松、更快速地比较这两种产品。
网络研讨会涵盖以下内容:
- 不同的产品功能区。
- 做什么支持 Redis 和 NCache 在每个功能区提供?
- 有哪些强项 NCache 超过 Redis 反之亦然?
NCache 是一种流行的开源(Apache 2.0 许可)内存分布式缓存,适用于 .NET。 NCache 通常用于应用程序数据缓存、ASP.NET 会话状态存储以及通过事件进行发布/订阅样式的运行时数据共享。
Redis 也是一种流行的开源(BSD 许可)内存数据结构存储,用作数据库、缓存和消息代理。 Redis 在 Linux 上非常流行,但最近由于微软的推广而在 Azure 上引起了关注。
概述
大家好,我的名字是 Iqbal Khan,我是 Alachisoft. Alachisoft 是一家位于旧金山湾区的软件公司,是流行的 NCache 产品,它是 .NET 的开源分布式缓存。 Alachisoft 也是制造商 NosDB,这是一个用于 .NET 的开源无 SQL 数据库。 今天我就来说说六大理由 NCache 优于 Redis 对于 .NET 应用程序。 Redis,如您所知,由 Redis 实验室,它被微软选为 Azure。 选择的主要原因是 Redis 提供多平台支持和许多不同的语言,而 NCache 纯粹专注于.NET。 那么,让我们开始吧。
分布式缓存
在进行对比之前,我先给大家简单介绍一下什么是分布式缓存,为什么需要它,它解决了什么问题。 分布式缓存实际上用于帮助提高应用程序的可伸缩性。 如您所知,如果您有 Web 应用程序或 Web 服务应用程序或任何服务器应用程序,则可以在应用程序层添加更多服务器。 通常,应用程序架构允许非常无缝地完成此操作。 但是,您不能在数据库层做同样的事情,尤其是当您使用关系数据库或遗留大型机数据时。 您可以在没有 SQL 的情况下做到这一点。 但是您知道,在大多数情况下,出于技术和业务原因,您必须使用关系数据库。
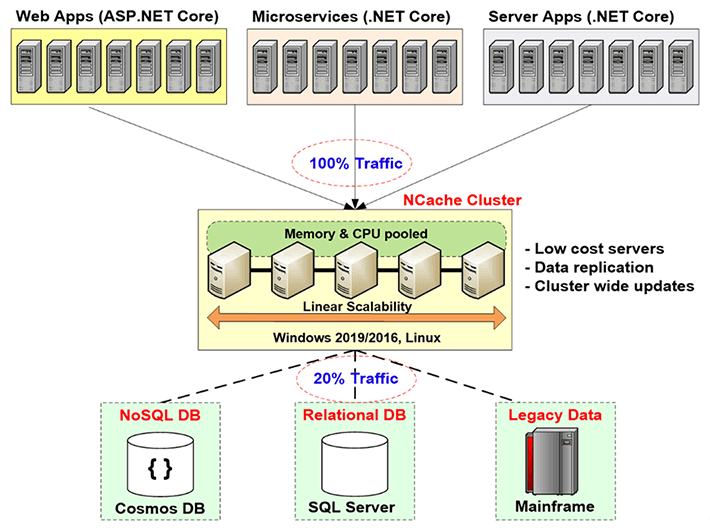
因此,您必须解决关系数据库或传统大型机通过分布式缓存为您提供的可扩展性瓶颈,而您这样做的方式是在应用程序层和数据库之间创建一个缓存层。 此缓存层由两个或多个服务器组成。 这些通常是低成本服务器。 的情况下 NCache,典型的配置是双CPU,四核机器,有16到32G的RAM和1到10块网卡,速度为XNUMX到XNUMXG。 这些缓存服务器形成一个基于 TCP 的集群,以防万一 NCache 并将所有这些服务器的资源集中到一个逻辑容量中。 这样,随着应用层的增长,假设您有越来越多的流量或越来越多的事务负载,您可以在应用层添加更多服务器。 您还可以在缓存层添加更多服务器。 通常,您在应用程序层和缓存层之间保持 4 比 1 或 5 比 1 的比例。
因此,分布式缓存永远不会成为瓶颈。 因此,您可以在此处开始缓存应用程序数据并减少到数据库的流量。 目标是让大约 80% 的流量进入缓存,大约 20% 的流量(通常是您的更新)进入数据库。 如果你这样做了,那么你的应用程序就永远不会面临可扩展性瓶颈。
分布式缓存的常见用途
好的,记住分布式缓存的好处,让我们谈谈您知道的不同用例,可以使用分布式缓存的不同情况。
应用程序数据缓存
第一个是应用程序数据缓存,这与我刚刚解释的缓存驻留在数据库中的数据的位置相同,这样您就可以提高性能和可伸缩性。 对于应用程序数据缓存,要记住的主要事情是您的数据现在存在于两个位置。 它存在于作为主数据源的数据库中,它也存在于缓存层中,当发生这种情况时,您需要记住的最重要的事情是,您知道,最大的担忧是,您知道,缓存会变得陈旧吗? 即使数据库中的数据已更改,缓存是否也会包含旧版本的数据。 如果出现这种情况,那你的问题当然就大了,很多人因为担心数据完整性问题,只缓存只读数据。 好吧,只读数据是您应该缓存的全部数据的一个非常小的子集,它大约占数据的 XNUMX% 到 XNUMX%。
真正的好处在于,如果您可以开始缓存事务数据。 这是您的客户,您的活动,您的历史,您知道,在运行时创建的各种数据并且它会非常频繁地更改,您仍然需要缓存这些数据,但您需要以缓存的方式缓存它保持新鲜。 所以,这是第一个用例,我们会回到那个。
ASP.NET 特定缓存
第二个用例是针对 ASP.NET 特定的缓存,您可以在其中缓存会话状态、视图状态以及如果您没有 MVC 框架和页面输出。 在这种情况下,您正在缓存会话状态,因为缓存是比数据库更快且更具可扩展性的存储,否则您将缓存这些会话或 Microsoft 提供的其他选项,在这种情况下,数据是短暂的。 瞬态意味着它本质上是暂时的。 它只需要一小段时间,之后你就扔掉它,数据只存在于缓存中。 缓存是主存储。 因此,在这个用例中,担心的不是缓存需要与数据库同步,而是担心如果任何缓存服务器出现故障,您会丢失一些数据。 因为,正如你所知,它都是内存存储和内存,是易失的。 所以,一个好的分布式缓存必须提供智能的复制策略。 因此,您拥有的每条数据都存在于多个服务器中。 如果任何一台服务器出现故障,您不会丢失任何数据,但复制具有相关成本,即性能成本。 所以,复制必须超快,这就是 NCache 顺便说一句,确实如此。
运行时数据共享
第三个用例是运行时数据共享用例,您将缓存用作本质上的数据共享平台。 因此,许多不同的应用程序都连接到缓存,它们可以在 Pub/Sub 模型中共享数据。 因此,一个应用程序生成数据,将其放入缓存中,触发一个事件,其他已注册对该事件感兴趣的应用程序将收到通知,因此,他们可以去使用该数据。 因此,还有其他事件。 有基于键的事件、缓存级事件,还有一个连续查询功能 NCache 拥有。 因此,您可以通过多种方式使用分布式缓存,例如 NCache 在不同的应用程序之间共享数据。 同样在这种情况下,即使数据是从数据库中的数据创建的,但共享它的形式可能只存在于缓存中。 因此,您必须确保缓存复制数据。 因此,问题与 ASP.NET 缓存相同。 因此,这些是使用分布式缓存常见的三个用例。 请记住这些用例,因为我比较的功能 NCache 提供了哪些 Redis 才不是。
原因 1 – 保持缓存新鲜
所以,第一个原因,为什么你应该使用 NCache 超过 Redis 就是它, NCache 为您提供非常强大的功能来保持缓存新鲜。 正如我们所讨论的,如果您不能保持缓存新鲜,您将被迫缓存只读数据,如果您缓存只读数据,那么您知道,这并不是真正的好处。 因此,您需要能够缓存几乎所有数据。 即使是每 10-15 秒更改一次的数据。
绝对到期/滑动到期
因此,保持缓存新鲜的第一种方法是通过过期。 过期是两者兼而有之的东西 NCache 和 Redis 提供。 因此,例如,有一个绝对过期,您告诉缓存请在 10 分钟或 2 分钟或 1 分钟后过期此数据。 在那之后,缓存会从缓存中删除该数据并且您正在猜测,您是说,您知道,我认为将这些数据保存在缓存中这么长时间是安全的,因为我认为它不会数据库中的变化。 因此,基于该猜测,您是在告诉缓存使数据过期。
这是过期的样子。 我只是要给你看点东西。 的情况下 NCache, 安装时 NCache 顺便说一句,你知道,它给了你一堆样本。 因此,其中一个示例称为基本操作,我在这里打开了它。 所以,在基本操作中,让我快速也给你,这是一个典型的 .NET 应用程序使用 NCache 好像。
你链接到 NCache 在运行时 NCache.Web 程序集然后你使用 NCache。运行 命名空间, NCache.Web.缓存 命名空间,然后在您的应用程序开始时,您连接到缓存。 所有缓存都被命名。
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...如果您想如何创建缓存,请观看我们的 入门视频. 这可以在我们的网站上找到。 但是,假设您已连接到此缓存,因此,您有一个缓存句柄。 现在你创建你的数据,这是一些对象,然后你做 缓存。添加. 缓存。添加 有一个键,它是一个字符串,实际值是你的对象,然后在这种情况下,你指定一分钟的绝对到期。 所以,你说的是从现在起一分钟后使这个对象过期,并说你在告诉 NCache 使该对象过期。 所以,这就是到期的运作方式,当然,正如我所说, Redis 还为您提供。
将缓存与数据库同步
但是,到期的问题是你在做一个可能不正确、可能不准确的猜测。 那么,如果数据在您指定的五分钟之前的那一分钟之前发生变化怎么办。 因此,这就是您需要另一个称为将缓存与数据库同步的功能的地方。 这是该功能 NCache 有和 Redis 不具有。
所以, NCache 以多种方式做到这一点。 数字第一是 SQL 依赖. SQL 依赖是 SQL Server 通过 ADO.NET 的一个特性,在这里你基本上指定一个 SQL 语句,然后你告诉 SQL Server 说,你知道,请监视这个数据集,如果这个数据集发生变化,那就意味着添加了任何行,更新或删除符合此数据集标准的,请通知我。 因此,数据库会向您发送数据库通知,然后您可以采取适当的措施。 那么,方式 NCache 这是吗, NCache 将使用 SQL 依赖项,还有一个 Oracle 依赖项与 Oracle 做同样的事情。 它们都处理数据库事件。 所以, NCache 将使用 SQL 依赖项。 让我在这里向您展示该代码。 所以,我只是去 SQL 依赖代码。 同样,与某些程序集链接的方式相同。 你得到了缓存句柄,现在你要添加东西了,我要去这个,去定义。 因此,现在您正在添加此数据,作为添加的一部分,您需要指定 SQL 依赖项。 所以,缓存依赖是一个 NCache 将连接字符串连接到数据库的类。 它需要一条 SQL 语句。 所以,比方说,在这种情况下,你说,我希望 SQL 语句中的产品 ID 就是这个 ID。 因此,由于您正在缓存产品对象,因此您将其与产品表中的相应行匹配。 所以,你在说,你在说 NCache 与 SQL Server 对话并使用 SQL 依赖,以便 SQL Server 可以监视此语句,如果此数据更改 SQL Server 会通知 NCache.
因此,现在缓存服务器已成为您数据库的客户端。 因此,缓存服务器已要求您的 SQL 服务器在此数据集更改时通知我,当该数据集更改时,SQL 服务器会通知缓存服务器和 NCache 服务器然后从缓存中删除该项目,它删除它的原因是因为一旦它被删除,下次您需要它时,您将无法在缓存中找到它,您将被迫从数据库中获取它。 所以,这就是你刷新它的方式。 还有另一种方法可以自动重新加载项目,我稍后会谈到。
所以,SQL 依赖允许 NCache 要真正将缓存与数据库和 Oracle 依赖项同步,它的工作方式完全相同,只是它与 Oracle 而不是 SQL 服务器一起工作。 SQL 依赖确实很强大,但也很健谈。 因此,假设您有 10,000 个或 100,000 个项目,您将创建一个 100,000 个 SQL 依赖项,这会给 SQL 服务器数据库带来性能开销,因为对于每个 SQL 依赖项,SQL 服务器数据库都会创建一个数据结构和服务器监控该数据,这是额外的开销。
所以,如果你有很多数据要同步,也许最好只依赖数据库。 数据库依赖是我们自己的特性,而不是使用 SQL 语句和数据库事件, NCache 实际上拉数据库。 您创建了一个特殊的表,它被称为 NCache 数据库同步,然后你修改你的触发器,所以,你去更新一个标志,对应于这个缓存的项目,然后 NCache 每隔 15 秒左右拉一次这个表,默认情况下每 2 秒左右,然后你可以,你知道,如果它发现任何已更改的行,它会使缓存中相应的缓存项无效。 因此,这两个当然还有 DB 依赖项都可以在任何数据库上工作。 不仅是 SQL 服务器、Oracle,而且如果您有 DBXNUMX 或 MySQL 或其他数据库。
因此,通过这些功能的组合,您可以真正确信您的缓存将始终与数据库同步,并且您可以缓存几乎任何数据。 第三种方式是 CLR 存储过程,因此您可以实际实现 CLR 存储过程。 从那里你可以做一个 NCache 称呼。 这样,您就可以从数据库触发器中调用存储过程。 假设您有一个客户表,并且实际上有一个更新触发器或删除触发器甚至一个添加触发器。 在 CLR 过程的情况下,您还可以添加新数据。 因此,触发器调用了 CLR 过程,并且 CLR 过程使 NCache 调用,这样你就可以让数据库添加数据或将数据更新回缓存。
所以,这三种不同的方式允许 NCache 与数据库同步,这是使用的一个非常有力的理由 NCache 超过 Redis 因为 Redis 强制您仅使用不够的过期时间。 它确实使您容易受到攻击,或者它迫使您缓存只读数据。
将缓存与非关系数据库同步
您还可以将缓存与非关系数据库同步。 所以,如果你有一个遗留数据库、大型机,你可以有一个自定义依赖项,即你的代码在缓存服务器上运行,并且每隔一段时间 NCache 调用您的代码来监控您的数据源,您可以进行 Web 方法调用或执行其他操作来监控自定义数据源,这样您就可以将缓存项与该自定义数据源中的数据更改同步。 所以,数据库的同步是一个很强大的理由,为什么要使用 NCache 超过 Redis 因为现在您几乎缓存了所有数据。 鉴于,如果 Redis 您将被迫缓存只读数据或您可以非常自信地猜测 期满.
原因 2 – SQL 搜索
原因二,好吧。 现在,假设您已经开始使用与数据库功能同步的功能,现在您实际上可以缓存大量数据。 因此,您缓存的数据越多,缓存就越开始看起来像一个数据库,然后如果您只能选择基于键获取数据,这就是 Redis 那么这是非常有限的。 所以,你需要能够做其他事情。 因此,您需要能够智能地查找数据。 NCache 为您提供了多种方法,您可以通过这些方法根据对象属性或基于组和子组对数据进行分组和查找数据,或者您可以分配标签、名称标签。 因此,所有这些都是您可以获取数据集合的不同方式。 例如,如果您要发出 SQL 查询,让我向您展示,假设我在这里执行 SQL 查询。 所以,我想去寻找,比如说,customer.city 是纽约的所有客户。 所以,我会发出一个 SQL 状态,我会说选择客户,你知道,我的完整命名空间,客户 this.City 是问号,在值中我将指定 New York 作为值,当我发出该查询,我将获得与此条件匹配的那些客户对象的集合。
所以,这现在看起来很像一个数据库。 因此,这意味着您实际上可以开始缓存数据。 您可以将其缓存整个数据集,尤其是查找表或其他参考数据,您的应用程序用于针对数据库中的数据发出 SQL 查询,以及您可以发出的相同类型的 SQL 查询 NCache. 唯一的限制是它可以在以下情况下进行连接 NCache 但是很多这些你不需要真正做关节。 SQL 搜索 使缓存非常友好,可以真正搜索和找到您正在寻找的数据。
分组和子分组 让我给你看这个分组的例子。 因此,例如,您可以在此处添加一堆对象,然后将它们全部添加。 因此,您将它们添加为一个组。 所以,这是键,值,这是组名,这是子组名,然后你可以稍后说给我属于电子组的所有东西。 这会给你一个集合,你可以遍历集合来获取你的东西。
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}您还可以根据组获取密钥。 您也可以根据组做其他事情。 因此,组和标签以类似的方式工作。 名称标签 也与标签相同,只是它是一个键值概念。 所以,假设你正在缓存自由格式的文本,并且你真的想获取文本的一些元数据索引,那么你可以使用键值概念和名称标签,这样一旦你有任何分组标签和名称标签那么您可以将它们包含在 SQL 查询中。
你也可以发出 LINQ 查询. 如果您更熟悉 LINQ,则可以发出 LINQ 查询。 因此,例如,对于 LINQ,假设这是您的 NCache. 所以,你会做一个 NCache 使用产品对象进行查询。 它给你一个 可查询 接口,然后您可以像针对任何对象集合一样发出 LINQ 查询,并且您实际上是在搜索缓存。
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}因此,当您运行此查询时,当您执行此查询时,它实际上会进入缓存层并搜索您的对象。 因此,您知道,您可以使用的界面非常简单,以一种非常友好的方式,但在幕后它实际上是在缓存或搜索整个缓存集群。 所以,第二个原因是您可以搜索缓存,您可以通过组和子组、标签和命名标签对数据进行分组,这使得以友好的方式查找数据成为可能,而这些功能都不存在 Redis.
数据索引 另一个方面是,当您要根据这些属性进行搜索时,这是非常重要的,缓存索引非常重要,它会在这些属性上创建索引。 否则,找到这些东西的过程非常缓慢。 所以, NCache 允许您创建数据索引。 例如,每个组和子组、标签、名称标签都会自动索引,但您也可以在对象上创建索引。 因此,例如,您可以在城市属性的客户对象上创建索引。 所以,城市属性,因为你知道你要搜索城市属性。 你说,我想用那种方式索引那个属性 NCache 将索引它。
原因 3 – 服务器端代码
原因三是 NCache 您实际上可以编写服务器端代码。 那么,服务器端代码是什么,为什么如此重要。 让我们看看。 它是通读、直写、后写和缓存加载器。 所以, 通读 本质上是您实现的代码,它在缓存服务器上运行。 所以,实际上让我向您展示通读的样子。 因此,例如,如果您实现一个 IReadThruProvider 界面。
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}这个接口有三个方法。 有一个 init 方法,它在缓存启动时被调用,其目的是将您的通读处理程序连接到您的数据源,还有一个称为 dispose 的方法,它在缓存停止时被调用,这样您就可以断开与数据源的连接并且有一个来自源方法的加载,它传递给你密钥,它需要一个缓存项的输出,一个提供者缓存项对象。 因此,现在您可以使用该键来确定您需要从数据库中获取哪个对象。 所以,我说的键可能是客户,客户 ID 1000。所以,它告诉你对象类型是客户,键是客户 ID,值是 1000。所以,如果你使用这样的格式,那么你可以,基于此,您可以继续提出您的数据访问代码。
所以,这个通读处理程序实际上是在缓存服务器上运行的。 因此,您实际上在所有缓存服务器上部署了此代码。 的情况下 NCache 它非常无缝。 您可以通过 NCache 管理工具. 因此,您将该通读处理程序部署到缓存服务器,并且该通读处理程序被缓存调用。 假设,您的应用程序执行 缓存.获取 并且该项目不在缓存中。 NCache 调用您的通读处理程序。 您的通读处理程序进入您的数据库,获取该项目,将其返回给 NCache. NCache 将其放入缓存中,然后将其返回给应用程序。 因此,应用程序感觉数据始终在缓存中。 因此,即使它不在缓存中,缓存现在也有能力从您的数据库中获取数据。 这是通读的第一个好处。
通读的第二个好处是到期时。 比方说,你有一个绝对到期。 你说从现在起 5 分钟或从现在起 2 小时后过期这个项目,那时你可以告诉而不是从缓存中删除那个项目 NCache 通过调用通读处理程序自动重新加载该项目。 重新加载意味着该项目永远不会从缓存中删除。 它只是更新了,这真的很重要,因为很多参考查找表,你有很多事务只是读取这些数据,如果这些数据即使在很短的时间内被删除,也会有很多针对数据库的事务将同时创建以获取该数据。 所以,如果你可以在缓存中更新它,那就更好了。 所以,这是一个用例。
第二个用例是数据库同步。 因此,当数据库同步发生并且该项目被删除时,而不是删除它,为什么不从数据库中重新加载它,这就是 NCache 将要。 你可以配置 NCache,所以,当数据库同步开始时, NCache 它不会从缓存中删除该项目,而是会调用您的通读处理程序去重新加载它的新副本。 同样,与过期一样,该项目永远不会被删除。 它永远不会从缓存中删除。 所以,通读是一个非常强大的功能。
通读的另一个好处是它简化了您的应用程序,因为如果您在缓存层中持久化代码并且如果您有多个应用程序正在访问相同的数据,那么您所要做的就是做一个 缓存.获取。 一个 缓存.获取 是一个非常简单的调用,然后进行适当的 ADO.NET 类型的编码。
因此,通读简化了您的应用程序代码。 它还确保缓存始终具有数据。 它会在到期和数据库同步时自动重新加载。
下一个功能是直写。 通写的工作方式与通读类似,但它用于更新。 让我向您展示直写的样子。 所以,这是通读的。 让我去写一遍。 因此,您实现了一个直写处理程序。 同样,您有一个 init 方法。 您有一个 dispose 方法,就像 read-through 一样,但现在您有一个写入数据源的方法,并且您有一个批量写入数据源的方法。 因此,这与通读不同。
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}所以,在直写的情况下,你知道,你也得到了对象和操作,这个操作可能是一个添加,它可能是一个更新,或者它可能是一个删除,对吧。 因为你可以做一个 缓存.添加、缓存.插入、缓存.删除,所有这些都将导致进行直写调用。 现在可以去更新数据库中的数据了。
同样,如果你做批量操作,批量更新,那么也可以对数据库进行批量更新。 因此,直写也与直读具有相同的好处,即它可以简化应用程序,因为它将越来越多的持久性代码移动到缓存层。
但是,还有一个 write-behind 功能,它是 write-through 的一种变体。 基本上,使用后写,您更新缓存,然后缓存异步更新您的数据源。 基本上,它稍后会更新它。 因此,您的应用程序不必等待。
后写确实加快了您的应用程序。 因为,您知道,数据库更新不如缓存更新快。 因此,您知道,您可以使用带有 write-behind 功能的 write-through,并且缓存会立即更新。 您的应用程序返回并执行其操作,然后以 write-behind 方式调用 write-through 并更新数据库,当然如果数据库更新失败,则通知应用程序。
因此,无论何时创建队列,如果该服务器出现故障,该队列就有丢失的风险。 那么,万一 NCache 后写队列也被复制到多个服务器,这样如果任何缓存服务器出现故障,您的后写队列就不会丢失。 所以,就是这样 NCache 确保高可用性。 因此,write-through 和 write-behind 是非常强大的功能。 它们简化了应用程序代码,并且在后写的情况下,它们加速了应用程序,因为您不必等待数据库更新。
第三个特性是缓存加载器。 您希望将大量数据预加载到缓存中,这样您的应用程序就不必进入数据库。 如果您没有缓存加载器功能,现在您必须编写该代码。 好吧,不仅您必须编写该代码,还必须将其作为进程运行在某个地方。 真正变得更加复杂的是作为一个过程的运行。 因此,在缓存加载器的情况下,您只需注册您的缓存。 你实现一个缓存加载器接口,你注册你的代码 NCache, NCache 每当缓存启动时调用您的代码,这样您就可以确保缓存始终预加载那么多数据。
那么,read-through、write-through、write-behind 和 cached loader 这三个特性,这些都是非常强大的特性,只有 NCache 有。 Redis 没有任何此类功能。 所以,万一 Redis 你失去了所有这些能力 NCache 另有规定。
原因 4 – 客户端缓存(靠近缓存)
原因四是 客户端缓存. 客户端缓存是一个非常强大的功能。 确实,它是位于您的应用程序服务器盒中的本地缓存,但它不是孤立的缓存。 它在您的应用程序中是本地的。 它可以是 In-Proc。 因此,此客户端缓存可能是保存在您的堆上的对象,以防万一 NCache 如果您选择 In-Proc 选项 NCache 保持数据和对象的形式。 不是在客户端缓存中的序列化形式。 在集群缓存中,它以序列化的形式保存它。 但是,在客户端缓存中,它以对象形式保存。 为什么? 因此,每次获取它时,您都不必将其反序列化为对象。 因此,它加快了获取速度或获得更多。
客户端缓存是一个非常强大的功能。 它是缓存之上的缓存。 因此,当您从独立的进程内缓存移动到分布式缓存时,您丢失的一件事是,在分布式缓存中,缓存将数据保存在单独的进程中,即使在单独的服务器上也是如此,并且存在进程间通信正在进行,序列化和反序列化正在进行,这会降低你的性能。 因此,与 In-Proc 相比,分布式缓存的对象形式缓存至少慢十倍。 因此,使用客户端缓存,您可以获得两全其美的效果。 因为,如果您没有客户端缓存,如果您只有一个独立的隔离缓存,那么还有很多其他关于缓存大小的问题,如果该进程出现故障怎么办? 然后您会丢失缓存,以及如何使缓存与跨多个服务器的更改保持同步。 所有这些问题都由 NCache 在其客户端缓存中。
因此,您可以从独立的 In-Proc 缓存中受益,但您已连接到缓存集群。 因此,保存在此客户端缓存中的任何内容也都在集群缓存中,如果有任何客户端在此处更新它,缓存层会通知客户端缓存。 这样它就可以立即进行自我更新。 因此,这就是您确保或放心的方式,即您的客户端缓存将始终与缓存层同步,然后再与数据库同步。
所以,如果出现 NCache 客户端缓存是无需任何额外编程即可插入的东西。 您可以像在与缓存层对话一样进行 API 调用,并且客户端缓存只是插入到配置更改中,客户端缓存可以让您的性能提高 10 倍。 这是一个功能, Redis 不具有。 因此,尽管所有性能声称 Redis 有,你知道,它们是一个快速的产品,但也是 NCache。 所以, NCache 在性能上与 Redis 没有客户端缓存。 但是当你打开客户端缓存时, NCache 快10倍。 所以,这就是使用客户端缓存的真正好处。 所以,这是使用的第四个原因 NCache 超过 Redis.
原因 5 - 多数据中心支持
原因五是 NCache 提供多数据中心支持。 您知道,现在如果您有一个高流量应用程序,那么您很有可能已经在多个数据中心运行该应用程序以进行灾难恢复 DR 或两个主动-主动数据中心以进行负载平衡或 DR 和负载平衡的组合,你知道的,或者可能是它的地理负载平衡。 所以,你知道,你可能在伦敦和纽约有一个数据中心,或者你知道东京或类似的地方来满足区域流量。 您知道,只要您有多个数据中心,数据库就会提供复制,因为没有它您将无法拥有多个数据中心。 因为,您的数据在多个数据中心是相同的。 如果数据不一样,那么,你知道,它是一个单独的,没有问题,但在很多情况下,数据是相同的,不仅如此,你还希望能够从一个卸载一些流量数据中心以无缝方式连接到另一个数据中心。 那么,如果您有跨数据中心复制的数据库,为什么不使用缓存呢? Redis 不提供任何此类功能, NCache 提供了非常强大的功能。
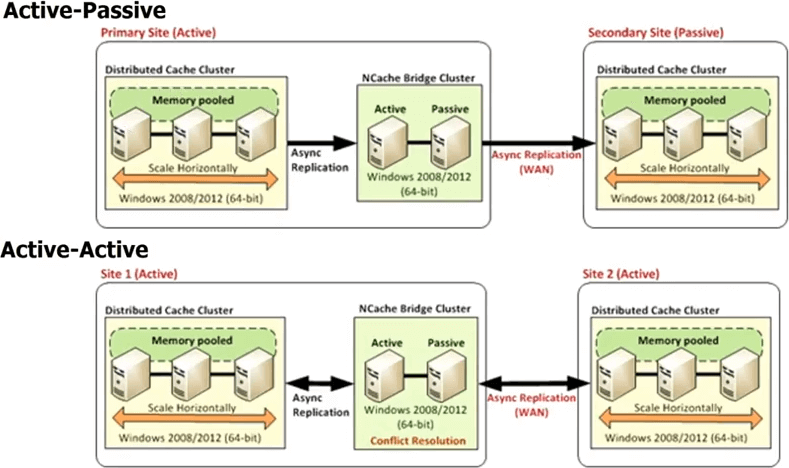
所以,如果出现 NCache 每个数据中心都有自己的缓存集群,但有一个 网桥拓扑 介于两者之间。 该网桥本质上是连接每个数据中心中的缓存集群,以便您可以异步复制。 所以,你可以有一个主动-被动桥,这是一个主动数据中心,这是一个被动的。 您还可以拥有一个主动-主动桥接器,我们还发布了两个以上的数据中心主动-主动或主动-被动配置,例如,您可以拥有三个或四个数据中心,并且缓存将被复制到所有数据中心以主动-主动方式或主动-被动方式。 在主动-主动中,因为更新是异步完成的,或者复制是异步完成的,所以在两个数据中心都更新了同一个项目可能会发生冲突。
所以, NCache 提供了两种不同的机制来处理该冲突解决方案。 一个被称为最后更新获胜。 无论哪个项目最后更新,都适用于这两个地方。 因此,假设您在此处更新了一个项目,另一个用户在此处更新了该项目。 它们现在都开始传播到另一个缓存。 因此,当他们来到桥上时,桥意识到它们在两个地方都已更新。 因此,然后它会检查时间戳以及哪个时间戳是最后一次将该更新应用到另一个位置,并丢弃由另一个位置进行的更新。 所以,这就是主动-主动最后一次更新赢得冲突解决的方式。 如果这对您来说还不够,那么您可以实现一个冲突解决处理程序。 那是你的代码。 因此,桥实际上会在发生冲突时调用您的代码,传递对象的两个副本,以便您可以进行基于内容的分析,然后根据该分析,您可以确定哪个对象更适合更新,以应用于两个数据中心。 如果您有两个以上的数据中心,同样的规则也适用。
所以,一 多数据中心支持 是一个非常强大的功能 NCache 开箱即用。 一旦你购买 NCache,都在那里, Redis 没有,如果您计划拥有多个数据中心,或者即使您只想拥有灵活性,即使您今天没有多个数据中心,但您希望能够灵活地访问多个数据中心,您愿意吗?今天买一个不支持复制的数据库? 即使您只有一个数据中心,您也可能不会。 那么,为什么要使用不支持跨 WAN 复制的缓存呢。 所以,这是一个非常强大的功能 NCache.
所以,到目前为止,我们主要讨论了一个好的分布式缓存必须具备的特性。 NCache,你知道,闪耀。 它赢得了胜利 Redis. Redis 是一个非常基本的简单缓存。
原因 6 – 平台和技术(适用于 .NET 应用程序)
.NET & Windows 与 Linux
原因六可能是您最重要的原因之一,即平台和技术。 如果您有一个 .NET 应用程序,您会知道,您希望拥有完整的 .NET 堆栈。 我敢肯定,在大多数情况下,您不会希望将 .NET 与 Java 或 Windows 与 Linux 混合使用。 您知道,在某些情况下,您可能会,但在大多数情况下,开发 .NET 应用程序的人更喜欢使用 Windows 平台,并且如果可能的话,更愿意让他们的整个堆栈都是 .NET。 好, Redis 不是 .NET 产品。 它是一个基于 Linux 的产品,使用 C/C++ 开发。

让我给你看一点。 这是 Redis 实验室网站,这是一家制作公司 Redis. 如果您转到下载页面,您会发现他们甚至没有为您提供 Windows 选项。 因此,尽管微软已经为 Azure 选择了它们,但它们绝对无意支持 Windows。 所以,就 Redis 实验室担心, Redis 仅适用于 Linux。 微软开放技术组已移植 Redis 到 Windows。 所以,有一个Windows版本的 Redis 可用的。 它是开源的,不受支持,但你知道,它有缺陷且不稳定,而且证据在布丁中,但微软本身并没有在 Azure 中使用它。 所以 Redis 您在 Azure 中使用的实际上是基于 Linux 的 Redis 而不是 Windows 基础。 所以,如果你想合并 Redis 在你的应用程序堆栈中,你要混合油和水,你知道的。 鉴于,如果 NCache 一切都是原生的.NET。 你有窗户。 您拥有 100% 的 .NET。 NCache 是用 C Sharp (C#) 开发的。 它通过了 Windows Server 2012 R2 的认证,并且每次新版本的操作系统出现时,它都经过了认证。 你知道,我们很快就会推出 ASP.NET Core 支持。 因此,我们正式拥有了一个 .NET 客户端。 我们也有正式的 Java 客户端。 所以,我认为,如果你使用 NCache 然后再次 NCache 也是开源的。 因此,如果您没有钱,请使用开源版本的 NCache. 但是,如果您的项目很重要,那么请使用 Enterprise 版本,它可以为您提供更多功能并同时支持两者。 但是,我强烈建议您使用 NCache 如果您有适用于 .NET 和 Windows 组合的 .NET 应用程序。
本地支持
第二个好处是 NCache 给你的是,如果你不在云端,假设你还没有决定迁移到云端,你正在托管自己的应用程序,所以,它本质上是本地的。 所以,它在你自己的数据中心里 Redis Microsoft 提供的仅在 Azure 中可用。 所以,任何在本地的东西,所以,有一个 Redis 可在本地通过 Redis 实验室,但那只是 Linux,Windows 上唯一的本地是开源的,一个不提供支持,一个有缺陷且不稳定,另一个有缺陷,以至于微软本身没有在 Azure 中使用它。

鉴于,如果 NCache 如果你没有钱,你可以继续使用免费的开源,当然这是不受支持的。 但是,这都是原生 .NET,或者如果您有一个对您的业务很重要的项目,那么由 企业版 它具有更多功能并提供支持,并且是永久许可证。 您知道,拥有它非常实惠,我们还为您提供 24 小时 7 小时的支持,以防这对您很重要。
因此,它在本地完全受支持。 我们大部分的高端客户仍在使用 NCache 在本地情况下。 NCache 已经进入市场10多年。 所以,它是真正稳定的产品。
云端支援
就云支持而言, Redis 为您提供云中的服务模型,这是微软实施的 Redis 服务。 好, Redis service 意味着您无权访问缓存服务器。 你知道,这对你来说是一个黑匣子。 没有服务器端代码。 所以,所有的 read-through、write-through、write-behind、缓存加载器、自定义依赖和一堆其他的东西,你不能用 Redis. 你知道,你只有基本的客户端 API,正如我所说,你知道,在 Azure 上,微软为你提供 Redis 作为服务。
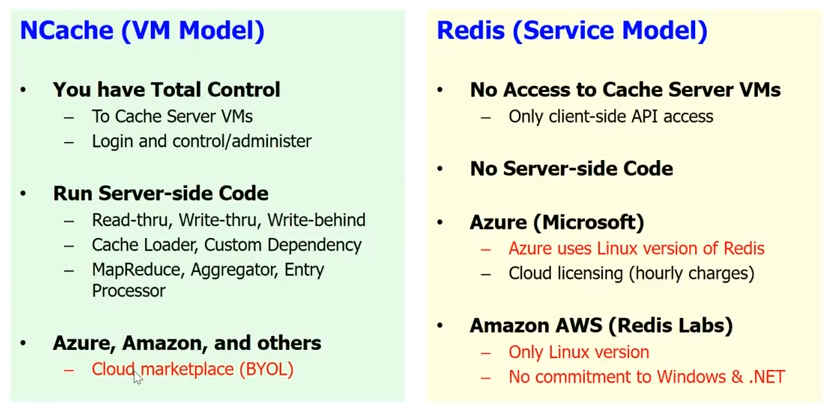
NCache,我们特意选择了一个 VM 模型。 因为,我们希望缓存靠近您的应用程序,并且我们希望您可以完全控制缓存。 这一点非常重要,因为我们有多年的经验,而且我们知道我们的客户非常敏感。 即使是很小的,比如说,如果你使用 Redis 作为一项服务,您每次都必须多跳一次才能到达缓存,这只会扼杀拥有缓存的全部目的。 鉴于,如果 NCache 您可以将其作为 VM 的一部分。 您可以拥有客户端缓存。 它确实嵌入在您的应用程序部署中。 所以,你可以做所有的服务器端代码。
NCache 也运行 Azure。 它在 亚马逊AWS 以及其他领先的 云平台 在 BYOL 模型中。 所以,你基本上得到了你的虚拟机。 其实你有 NCache 在市场上。 你得到一个 NCache VM,您从我们这里购买许可证并开始使用 NCache.
所以,非常不同的方法。 但是,如果您的应用程序非常重要并且您想要控制应用程序的各个方面并且不必依赖其他人来管理您的应用程序级基础架构的一部分,那么这就是您想要的方法。 管理虚拟机和下面的硬件是一回事,但是当你开始越来越向上时,你就会失去控制,当然在缓存的情况下,如果 NCache,如果您使用服务模型,您将失去的不仅是那种控制,还有很多功能。
所以,第 6 个原因是平台技术。 对于 .NET 应用程序, NCache 是一个比 Redis. 我不是说 Redis 是一个糟糕的选择,但我认为对于 .NET 应用程序 NCache 是比 Redis.
NCache 创办缘起
让我简单地给你一个简短的历史 NCache. NCache 自 2005 年年中以来一直存在。所以,那是 11 年,你知道, NCache 已上市。 它是市场上最古老的 .NET 缓存。 2015 年 2.0 月,我们开源了。 所以,我们现在是 Apache XNUMX 许可证。 我们的 企业版 建立在我们的开源之上。 所以,开源是一个稳定、可靠的版本。 它有很多功能。 当然,Enterprise 有更多的功能,但开源是非常有用的产品。 基本的事情是,如果你没有钱去开源。 如果您的业务应用程序很重要并且您有预算,请选择企业版。 它提供支持,还为您提供更多功能。
我们有 数百名客户,几乎在每个可能需要缓存的行业中。 所以,我们有金融行业的客户,我们有沃尔玛,其他零售行业。 我们有航空公司,我们有保险业,汽车/汽车,所有行业。
所以,这就是我的谈话的结束。 请继续下载企业版 NCache. 让我带你到我们的网站。 所以,基本上,去 下载页面 我强烈建议您下载企业版。即使您最终要使用开源版本,也请下载企业版。这是一个完全有效的 30 天试用版,我们可以轻松地延长和使用它。
如果您想继续下载开源,请继续下载开源。 也可以去 GitHub 看看 NCache 在 GitHub. 如果您希望我们这样做,请联系我们 个性化演示. 也许谈谈你的应用架构,回答你的问题。 非常感谢您观看本次演讲。