NCache 性能基准
2 万次操作/秒
(5节点集群)
执行摘要
NCache 可以帮助您轻松且经济高效地线性扩展和提高性能。 世界500强企业信任 NCache 13 年多来消除与数据存储和数据库相关的性能瓶颈,并将 .NET 应用程序扩展到极限事务处理 (XTP)。
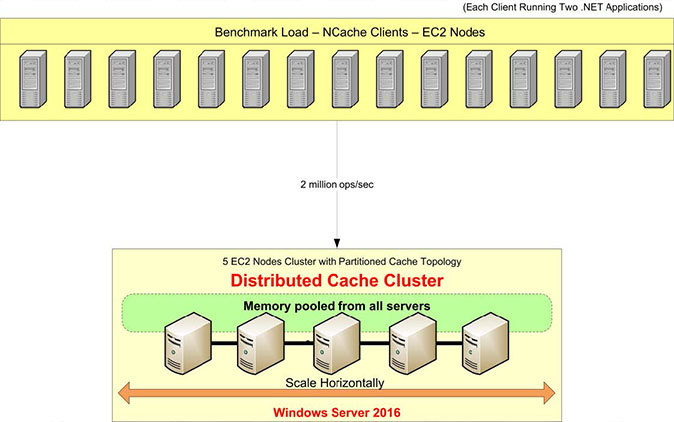
本文档将使用 NCache 5.0 具有现代 API 和一些新功能,以展示您可以为您的 .NET 应用程序实现的线性可扩展性和极端性能。 在这个实验中,我们捆绑了一个调制解调器 NCache 具有启用流水线的分区缓存拓扑的 API。 数据完全分布在所有缓存服务器上,客户端连接到所有服务器以进行读写请求。
在这个基准测试中,我们证明了 NCache 集群可以线性扩展,我们实现了 仅使用 2 个缓存服务器节点每秒处理 5 万次事务. 我们还将证明 NCache 即使在大型集群中也可以提供亚微秒级的延迟。 在本白皮书中,我们将介绍基准设置、执行基准测试的步骤、测试配置、加载配置和结果。 您可以在此查看运行中的基准实验 电影.
基准设置概述
让我们回顾一下我们的基准设置。 我们将使用 AWS m4.10xlarge 服务器进行此测试。 我们有这五个 NCache 我们将在其上配置缓存集群的服务器。 我们将有 15 个客户端服务器,我们将从那里运行应用程序以连接到这个缓存集群。
我们将使用 Windows Server 2016 作为操作系统 – 数据中心版,64 位。 这 NCache 正在使用的版本是 5.0 Enterprise。 在此基准设置中,我们将使用 分区缓存拓扑. 在分区缓存拓扑中,所有数据将完全分布在所有缓存服务器上的分区中。 并且所有客户端将连接到所有服务器以进行读取和写入请求,以同时使用所有服务器。 我们没有为此拓扑打开复制,但还有其他拓扑,例如 分区副本拓扑 它配备了复制支持。
我们将有 流水线 启用这是一个新功能 NCache 5.0。 它的工作方式是在客户端累积运行时发生的所有请求,并在服务器端立即应用这些请求。 累积在微秒内完成,因此非常优化,当您有高事务负载要求时,这是推荐的配置。
以下是我们的基准设置的快速概览,包括硬件、软件和负载配置。
硬件配置:
| 客户端和服务器详细信息 (虚拟机) |
AWS m4.10xlarge:40 核、160 GB 内存、网络 - 10 Gbps 以太网 |
| 服务器节点数 | 5 |
| 客户端节点数 | 15 |
软件配置:
| 运行系统 | Windows服务器2016的 数据中心版 – x64 |
| NCache 版本 | 5.0 |
| 集群拓扑 | 分区缓存配置 |
负载配置:
| 缓存大小 | 4 GB |
| 资料大小 | 大小为 100 的字节数组 |
| 总项目 | 1,000,000 |
| 流水线 | 启用 |
| 获取/更新比率 | 80:20 |
| 线 | 1280 |
| 应用程序实例 | 每台客户机 2 个实例,总共 30 个实例 |
数据人口
在我们的基准测试环境设置之后,我们将从缓存集群中 1 万个项目的数据填充开始。 我们将运行客户端应用程序(Cache Item Loader),它将连接并在缓存中添加 1 万个项目。 一个客户端将连接所有缓存服务器,并将在缓存集群中添加 1 万个项目,之后我们可以开始读取和写入请求。
您可以使用此 Nuget 包 – NCache 软件开发套件(SDK) 在客户端机器上安装 SDK 并配置客户端-服务器之间的管道并部署负载生成应用程序 (GitHub) 以在缓存集群上填充 1 万个缓存项。
构建事务负载
我们现在将运行应用程序以在这个缓存集群上构建一些事务负载,其中 80% 读取和 20% 写入操作。 您可以使用 Perfmon 计数器监控所有活动。 最初,我们将 10 个客户端实例连接到每个 NCache 服务器具有获取活动以及每秒更新的活动。
第一阶段 1 万次操作/秒事务负载
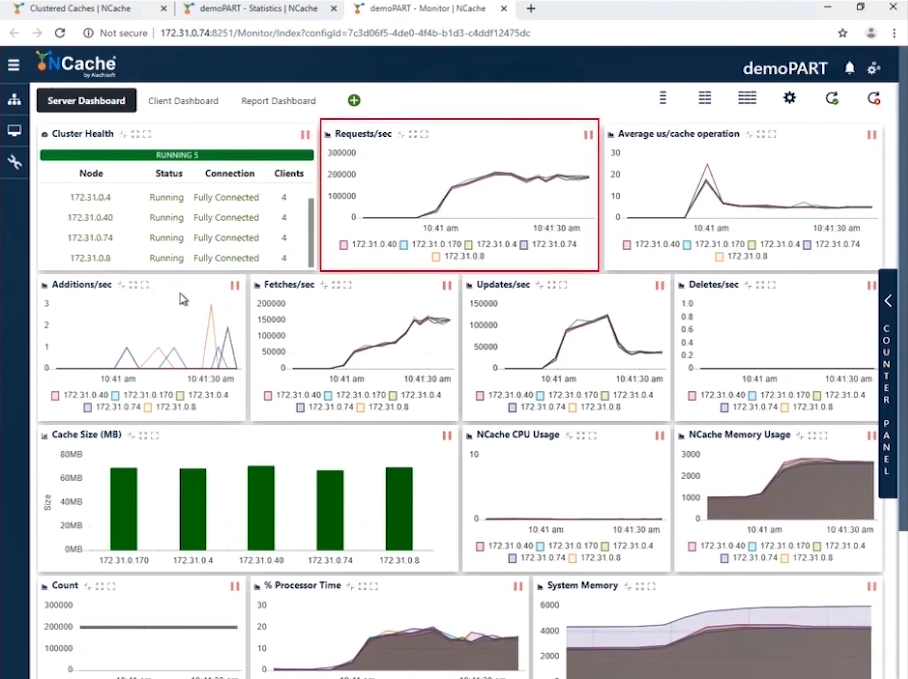
您可以在屏幕截图中看到,有 10 个客户端实例连接到一个 5 节点集群,我们每秒的请求数在 180,000 到 190,000 之间。 因为我们有 5 NCache 并行工作的服务器,累积这些请求使我们通过这个缓存集群达到每秒 1 万个请求。
我们有高效的内存和 CPU 使用率,平均微秒/缓存操作每次操作略低于 10 微秒。 我们的第一阶段已经完成,我们从缓存集群中实现了每秒 1 万次操作。
| 第 1 阶段 – 汇总数据表 | |
| 集群中的缓存服务器总数 | 5 |
| 连接的客户端实例总数 | 10 |
| 每秒请求数/节点 | 180,0000〜190,000 |
| 总请求 - 缓存集群 | 950,000〜1,000,000 |
| % 处理器时间(最大值) | 20% |
| 系统内存 | 4.2 GB |
| 延迟(微秒/缓存操作) | 10微秒/操作 |
第一阶段 1.5 万次操作/秒事务负载
现在我们已经达到了 1 万 TPS,是时候以更多应用程序实例的形式增加负载以增加事务负载了。 一旦这些应用程序运行,您就会看到每秒请求数计数器的增加。 我们将把客户端数量增加到 20 个。使用此配置,您可以在下面的屏幕截图中看到,我们现在显示每个实例每秒 300,000 个请求。 我们已经从这个缓存集群成功地实现了每秒 1.5 万个请求。
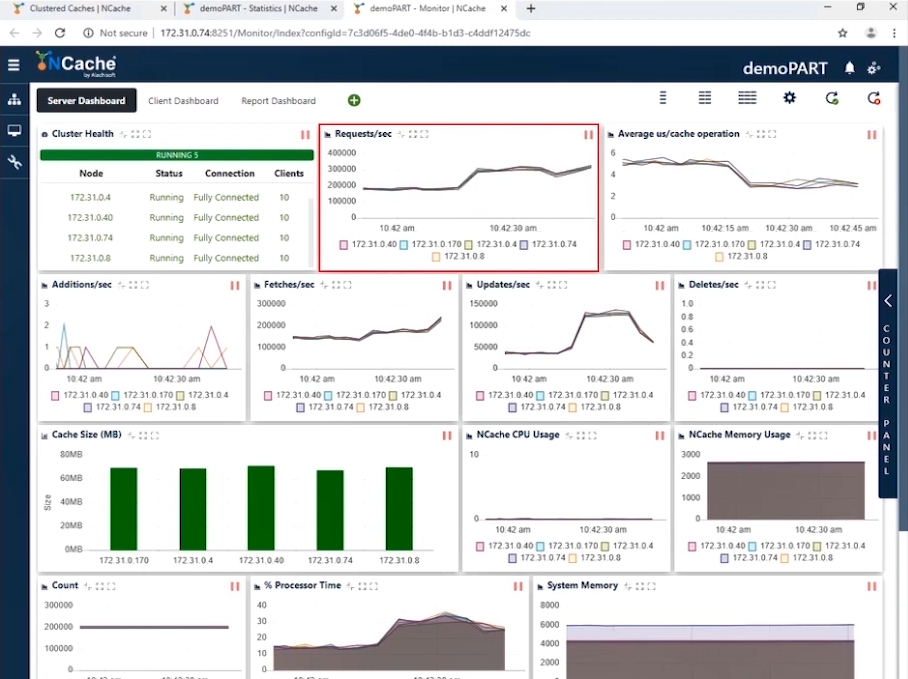
您可以看到每台服务器每秒的请求数为 300,000。 每秒获取略多于 200,000 次,更新在 50,000 到 100,000 次之间,您可以看到每个缓存操作的平均微秒小于 4 微秒; 这太神奇了,因为我们有非常低的延迟以及流水线的影响。 当您有来自客户端的高事务负载时,流水线确实有助于减少延迟并提高吞吐量。 这就是为什么我们建议打开它。 此外,我们现在每个缓存操作的平均微秒时间约为 3-4 微秒。
| 第 2 阶段 – 汇总数据表 | |
| 集群中的缓存服务器总数 | 5 |
| 连接的客户端实例总数 | 20 |
| 平均每秒请求数/节点 | 300,000 |
| 总请求 - 缓存集群 | 1,500,000 |
| % 处理器时间(最大值) | 30% |
| 系统内存 | 6 GB |
| 延迟(微秒/缓存操作) | 3~4微秒/操作 |
第一阶段 2 万次操作/秒事务负载
让我们通过运行更多的应用程序实例来进一步增加负载,这也将显示每秒请求的进一步增加。 我们现在要将 30 个客户端的实例连接到所有 NCache 服务器。
根据下面的屏幕截图,您现在可以看到我们每秒成功地触及了 400,000 个请求,每个请求都得到了 NCache 服务器; 我们有 5 NCache 服务器,从而使每秒的交易数量达到 XNUMX 万次 NCache 缓存集群。 我们每个缓存操作的平均微秒数少于 3 微秒。 我们的系统内存和处理器时间也远低于限制,两个方面的利用率均为 40 - 50%。
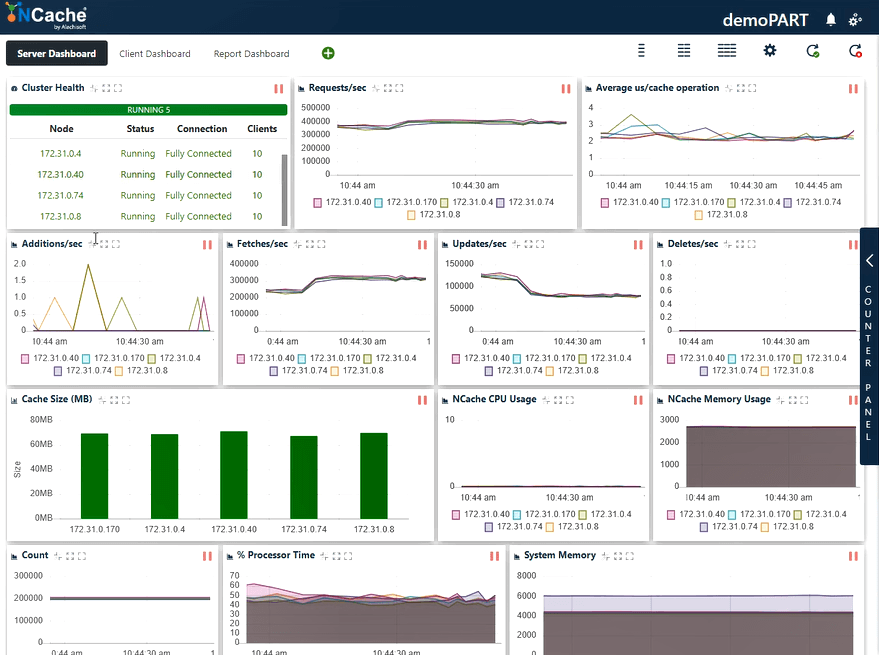
我们现在有 2 ~ 3 us/操作延迟,比之前的结果有所改进。 您可以再次看到获取、更新以及 CPU 和内存资源的有效利用的混合。 我们可以在这里得出结论 NCache 是线性可扩展的。 现在让我们回顾一下我们的可扩展性数字。
| 第 3 阶段 – 汇总数据表 | |
| 集群中的缓存服务器总数 | 5 |
| 连接的客户端实例总数 | 30 |
| 平均每秒请求数/节点 | 400,000 |
| 总请求 - 缓存集群 | 2,000,000 |
| % 处理器时间(最大值) | 60% |
| 系统内存 | 6 GB |
| 延迟(微秒/缓存操作) | 2~3微秒/操作 |
基准测试结果
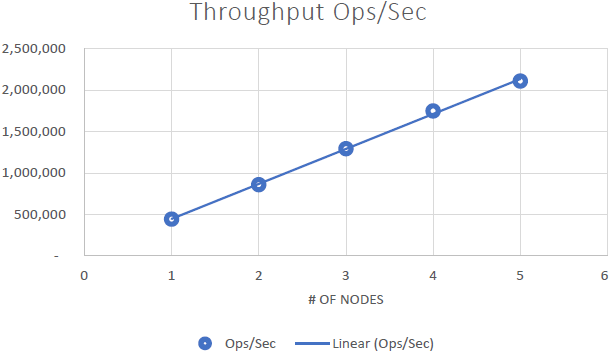
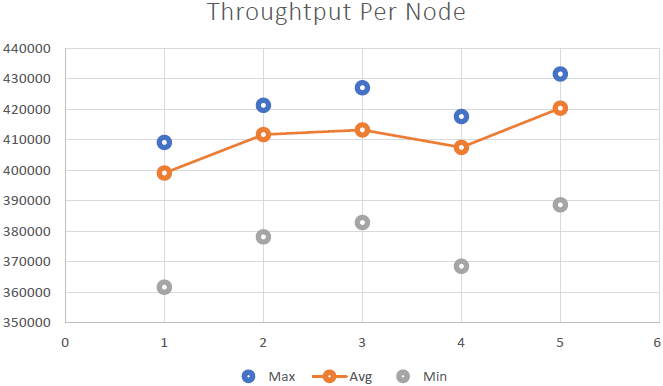
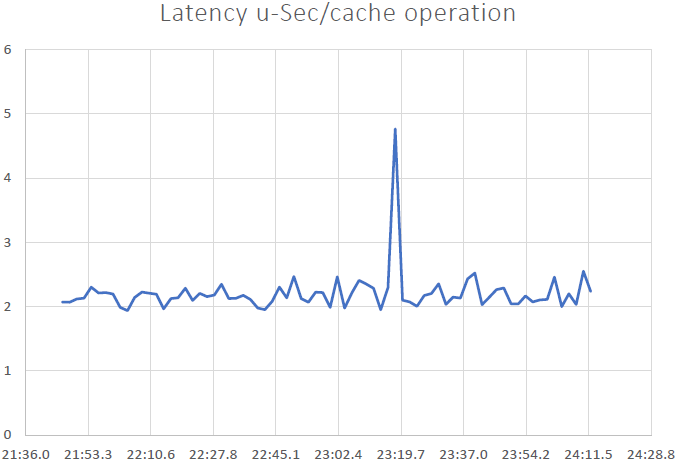
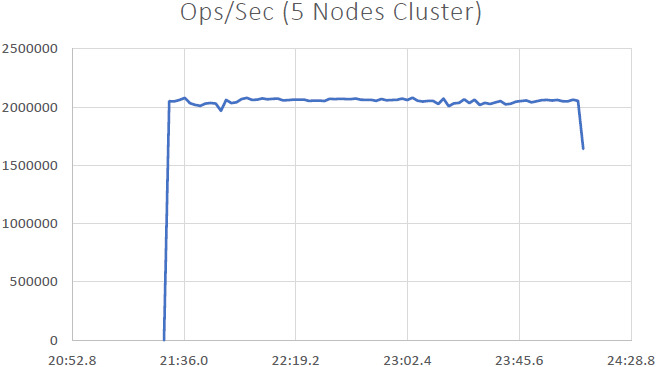
我们能够证明 NCache 是线性可扩展的,我们在运行基准测试后能够获得以下结果:
结论
- 线性可扩展性: 与 5 NCache 我们能够达到每秒 2 万个请求的服务器。 添加越来越多的服务器意味着更多的请求处理能力 NCache.
- 低延迟和高吞吐量: NCache 即使集群规模很大,也能提供亚微秒(2.5 ~ 3 微秒)的延迟。 NCache 即使在规模上也有助于满足低延迟和高吞吐量要求。 我们的延迟非常低,这是流水线带来的影响。 当您有来自客户端的高事务负载时,流水线确实有助于减少延迟并提高吞吐量。