Lucene ist eine .NET-Volltext-Suchmaschinenbibliothek, die leistungsstarke APIs zum Erstellen von Volltextindizes und zum Implementieren fortschrittlicher und präziser Suchtechnologien in Ihre Programme enthält. Lucene bietet viel mehr als Sie von anderen Textsuchmaschinen erwarten würden, da die Auswahlmöglichkeiten für den Benutzer vielfältig sind. Es verfügt über einen leistungsstarken Suchalgorithmus und unterstützt eine Vielzahl von Suchabfragen.
Obwohl Lucene allein so leistungsfähig ist, ist es nicht ohne Einschränkungen. Lucene wird prozessintern in der Clientanwendung ausgeführt, und Lucene-Anwendungen schreiben normalerweise Daten in eine Datei und speichern sie auf der Festplatte, was zu einer enormen Speicherzuweisung führt. Es handelt sich jedoch um eine eigenständige Lösung, die nicht skaliert, wenn Ihre Daten wachsen. Sie müssen ganze Lucene-Indizes neu erstellen, um Daten zu durchsuchen, was eine teure und langsame Aufgabe ist, die zu einem Leistungsengpass führen kann. Das bedeutet, dass Lucene nicht skalierbar ist und einen Single Point of Failure hat.
NCache Details Herunterladen NCache NCache Docs
Wie Distributed Lucene Ihnen hilft
NCache bietet eine verteilte Implementierung von Lucene, die Lucene-Anwendungen skalierbar macht. NCache Die Verteilung in der Natur mit Lucene bietet eine lineare Schreibskalierbarkeit, da die von den Anwendungen indizierten Dokumente automatisch auf Cache-Knoten verteilt werden, wo sie separat indiziert werden.
In ähnlicher Weise bietet Distributed Lucene auch eine lineare Leseskalierbarkeit, da Abfragen auf jeder Partition weitergegeben und Ergebnisse zusammengeführt werden. Eine höhere Anzahl von Partitionen bietet eine höhere Lese- und Schreibskalierbarkeit. Lucene-Indizes werden auf dem physischen Laufwerk beibehalten. Je mehr Knoten vorhanden sind, desto höher sind die Skalierbarkeit, Leistung und Speicherkapazität, um eine große Anzahl von Lucene-Dokumenten und indizierten Daten aufzunehmen.
NCache Details Herunterladen NCache Verteilte Lucene-Dokumente
Funktionsweise von Distributed Lucene
Verteiltes Lucene enthält mehrere Serverknoten, jeder Server von NCache verfügt über ein dediziertes Lucene-Modul. Das Verhalten und die Funktionsweise von Lucene und Distributed Lucene sind ähnlich, abgesehen von einigen Änderungen.
Das folgende Diagramm zeigt, wie das verteilte Lucene-Modell funktioniert.
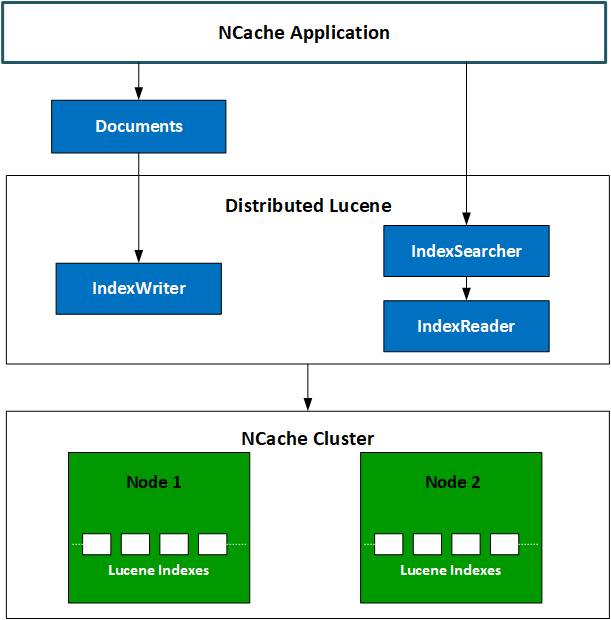
NCache Verteilte Lucene-Architektur
Die Clientanwendung möchte möglicherweise Dokumente indizieren oder vorhandene indizierte Dokumente mithilfe der Lucene-API abfragen. Diese Interaktionen mit der API wirken wie Remote Procedure Calls (RPCs) zwischen dem Client und dem Server. API-Aufrufe werden direkt an die Lucene-Module weitergeleitet, die mit jedem Serverknoten verbunden sind. Lucene-Module führen diese Aufrufe aus, und je nach Art der Aufrufe findet eine der folgenden Aktionen statt:
- Falls es sich um einen Abfrageaufruf handelte, geben die Distributed Lucene-Module Ergebnisse an die Clientseite zurück, wo alle diese Ergebnisse zusammengeführt und verarbeitet werden.
- Falls es sich um einen Aufruf zur Indizierung eines Dokuments handelte, speichern die Distributed Lucene-Module dieses Dokument auf einem Laufwerk.
NCache Details Verteilte Lucene-Dokumente Verteilter Lucene-Cache
Datenverteilung
Eine Verteilungskarte wird gegen die generiert NCache Cluster für verteiltes Lucene. Diese Karte enthält Informationen zur Verteilung des Buckets auf die Cache-Knoten. Diese Buckets (in der Karte sind 100 Buckets vorhanden) werden mithilfe einer bestimmten Strategie im Cluster verteilt. Das Hinzufügen oder Entfernen eines Knotens aus dem Cluster ändert die Verteilungskarte und löst eine Zustandsübertragung für die laufenden Serverknoten aus, die Buckets mit indizierten Daten auf dem jeweiligen Knoten übertragen.
100 Buckets zu haben bedeutet, dass ein Lucene-Index in 100 Unterindizes aufgeteilt wird NCache Cluster. Ein einzelner Bucket enthält einen Unterindex, der mit einem Lucene-Index in Lucene.Net identisch ist. Ein Serverknoten kann mehrere Indizes enthalten, und jeder Index innerhalb dieses Serverknotens enthält Buckets, die ihm gemäß der Verteilungsstrategie des Clusters zugewiesen werden. Die Daten innerhalb der Indizes werden gleichmäßig über diese Buckets verteilt.
So starten Sie mit verteiltem Lucene
Verteiltes Lucene funktioniert genauso wie Lucene. Ein großer Vorteil bei der Verwendung von verteiltem Lucene besteht darin, dass Sie dieselbe API erhalten wie Lucene. Als Lucene-Benutzer erhalten Sie die Skalierbarkeit, die Sie sich wünschen, mit einem Add-on einer einzeiligen Codeänderung. Sie müssen nur verwenden NCache Directory und Ihre Anwendung ist startklar. Es gibt nur sehr wenige Verhaltens- und API-Änderungen in verteiltem Lucene, die in der aufgeführt sind Dokumentation.
Sehen wir uns diese Schritte aus technischer Sicht genauer an, und der erste Schritt besteht darin, das Lucene.NET-Nuget-Paket aus Ihrer Bibliothek durch das verteilte Lucene-Nuget-Paket zu ersetzen Lucene.Net.NCache.
Verbinden mit NCache Verzeichnis
NCache Verzeichnis ist, wie der Name schon sagt, eine Basisklasse zum Speichern der Indizes, um die Indizes skalierbar zu machen. Der erste Schritt ist also Verbinden Sie sich mit dem NCache Verzeichnis.
Unten ist der Code, der Sie mit einem Cache namens verbindet luceneCache und öffnet das bereitgestellte Verzeichnis auf allen Servern.
|
1 2 3 4 5 6 7 8 9 |
// Specify the cache name that is used for Lucene string cache = "LuceneCache"; // Specify the index name to create the indexes string indexName = "ProductIndex"; // Create a directory and open it on the cache and the index path NCacheDirectory ncacheDirectory = NCacheDirectory.Open(cache, indexName); |
NCache Details Verteilte Lucene Geo-Spatial-API Verteiltes Lucene initialisieren
Indexdaten in verteiltem Lucene
Sobald das Verzeichnis initialisiert ist, IndexWriter erstellt Dokumente auf dem Index mit dem gleichen Mechanismus wie in Lucene.NET verwenden AddDocument Methode. Wenn das Dokument geschrieben ist, IndexWriter.Commit wird aufgerufen, um das Dokument beizubehalten und durchsuchbar zu machen.
Distributed Lucene ermöglicht es Ihnen, mehrere Writer im selben Verzeichnis für die parallele Indizierung zu öffnen. Das folgende Codebeispiel zeigt, wie Sie Ihre Dokumente mit Distributed Lucene indizieren können.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// Create an instance of the writer IndexWriter indexWriter = new IndexWriter(ncacheDirectory, new IndexWriterConfig(LuceneVersion.LUCENE_48, new WhitespaceAnalyzer(LuceneVersion.LUCENE_48))); // Indexing // Add the products information that is to be indexed Product[] products = FetchProductsFromDB(); foreach (var prod in products) { // Create a document and add fields to it Document doc = new Document(); doc.Add(new TextField("ProductID", prod.ProductID, Field.Store.YES)); doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO)); doc.Add(new TextField("Category", prod.Category, Field.Store.YES)); doc.Add(new TextField("Description", prod.Description, Field.Store.YES)); // Writer is created previously indexWriter.AddDocument(doc); } // Calling commit on the writer saves all the write operations indexWriter.Commit(); // Dispose the objects after indexing indexWriter?.Dispose(); ncacheDirectory?.Dispose(); |
NCache Details Verteilte Lucene-Facetten Verteilte Lucene-Indizierung
Suchen in verteiltem Lucene
Suchen kann nach Indizierung der Daten durchgeführt werden. Das IndexSearcher verwendet das IndexReader zum Abrufen der Ergebnisse. Das IndexSearcher ist für die Suche der Daten gemäß den gegebenen Abfragen verantwortlich. Lucene bietet eine breite Palette von Abfragen, und Distributed Lucene unterstützt alle Lucene-Abfragen.
Das folgende Codebeispiel zeigt, wie Sie Ihre indizierten Dokumente mit Distributed Lucene durchsuchen können.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Open a new reader instance IndexReader reader = DirectoryReader.Open(ncacheDirectory); // A searcher is open to perform searching IndexSearcher indexSearcher = new IndexSearcher(reader); // Specify analyzer type Analyzer analyzer = new WhitespaceAnalyzer(version); // Create a query parser and parse the query with the parser //Specify the searchTerm and the fieldName QueryParser parser = new QueryParser(LuceneVersion.LUCENE_48, "Category", analyzer); Query query = parser.Parse("Beverages"); // Returns the top 10000 hits from the result set ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs; indexSearcher?.Dispose(); reader?.Dispose(); |
NCache Details Verteilte Lucene-Zähler Verteilte Lucene-Suche
Verwenden Sie native Lucene-Indizes mit verteiltem Lucene
Wenn Sie bereits eine .NET-Anwendung haben, die Lucene verwendet, besteht die Möglichkeit, dass Sie einen großen Lucene-Index erstellt haben. NCache bietet die Import-LuceneIndex Cmdlet, mit dem Benutzer einen vorhandenen Lucene-Index importieren können NCache Verteiltes Lucene, ohne dass Indizes neu erstellt werden müssen.
Dieser Beispielbefehl lädt den nativen Lucene-Index aus C:\Index zu einem verteilten Lucene-Geschäft DemoCache.
|
1 |
Import-LuceneIndex -CacheName demoCache -Path C:\Index -Server 20.200.21.11 |
NCache Details Verteilte Lucene-Dokumente Importieren Sie Lucene-Indizes
Zusammenfassung
Lucene ist eine hocheffiziente Suchmaschine für die Volltextsuche in Ihren Daten, aber es mangelt ihr an Skalierbarkeit. NCache kann mit Lucene verwendet werden, um es mit sehr geringem Aufwand skalierbar zu machen. Skalierbares, verteiltes Lucene macht Ihre Anwendung nicht nur schneller, sondern hilft Ihnen auch, mit dem großen Rückschlag eines Single Point of Failure fertig zu werden. NCache kann mit einer Codeänderung in einer einzigen Zeile einfach in Ihre .NET-Anwendung integriert werden, betrachten Sie es also als die bestmögliche Option für Ihre skalierbare Lucene-Anwendung.




