Bei Anwendungen mit hohem Transaktionsvolumen und komplexen Architekturen führt der kontinuierliche Datenaustausch zu einer ungleichmäßigen Belastung und einer Verzögerung des Durchsatzes. Die Datenveredelung ist eine große Herausforderung, wenn es um große und komplexe Geschäftsanwendungen geht. Um diesem Umstand Rechnung zu tragen, wird die Stream-Verarbeitung verwendet, um einen bestimmten Datenfluss durch die Erstellung von Datenströmen zu definieren. Eine typische Stream-Anwendung besteht aus mehreren Produzenten, die neue Ereignisse generieren, und einer Reihe von Verbrauchern, die diese Ereignisse verarbeiten.
Eine dieser beliebten Anwendungen ist Pub/Sub, bei der Herausgeber Nachrichten eingeben und Abonnenten die Nachrichten erhalten, die sie abonniert haben. Allerdings unterliegt Pub/Sub bei der Stream-Verarbeitung einigen Einschränkungen: Sobald der Abonnent die Nachricht erhält, speichert die Anwendung die Nachricht nicht mehr. Wenn also später ein anderer Abonnent die Nachrichten vom Herausgeber möchte, sind die vorherigen Nachrichten nicht vorhanden. Darüber hinaus erfolgt die Datenfilterung für eingehende Stream-Daten auf der Client-Seite (Abonnent) und nicht auf dem Server, was die Anwendungsarchitektur komplex macht.
Um diese Einschränkungen von Pub/Sub zu überwinden, NCache verfügt über einen effizienten Mechanismus zur Verarbeitung von Daten auf der Serverseite mithilfe kontinuierlicher Abfragen. Kontinuierliche Abfragen ermöglichen es Anwendungen, über alle Änderungen an den im Cache befindlichen Daten benachrichtigt zu werden, die bestimmte Kriterien erfüllen. Dieser Blog hilft Ihnen, die Vorteile der Verwendung kontinuierlicher Abfragen bei der Stream-Verarbeitung mithilfe einer Lösung zu verstehen, die für die Stream-Verarbeitung erstellt wurde GitHub.
Verwenden kontinuierlicher Abfragen für die Stream-Verarbeitung
Die Lösung erklärt eine E-Commerce-Anwendung, die täglich Tausende von Kunden für ihre Online-Einkäufe verarbeitet. Wenn Sie sich das Diagramm unten ansehen, werden der Anwendung Kunden aller Art und Kategorien hinzugefügt. Um die Bearbeitung der Kunden effizient zu gestalten, werden die ungefilterten Kunden anhand der Anzahl ihrer Bestellungen anhand kontinuierlicher Abfragen in „Gold“, „Silber“ und „Bronze“-Kunden kategorisiert und gefiltert.
Kontinuierliche Abfrage ermöglicht Anwendungen den Empfang von Benachrichtigungen, wenn sich Daten, die bestimmte Kriterien erfüllen, im Cache ändern und die Kriterien mithilfe von SQL-Befehlen angegeben werden. Wenn eine Anwendung beispielsweise Kunden mit der höheren Anzahl an Bestellungen als „Goldkunden“ kennzeichnen möchte, muss sie lediglich ein SQL-Befehlskriterium registrieren und so einen Rückruf bereitstellen. Dieser Rückruf wird bei jeder Änderung ausgelöst, die in der Ergebnismenge auftritt und die Kriterien erfüllt. Sobald der Rückruf aufgerufen wird, kann die Anwendung diese Kunden mithilfe von Tags als „Goldkunden“ kategorisieren.
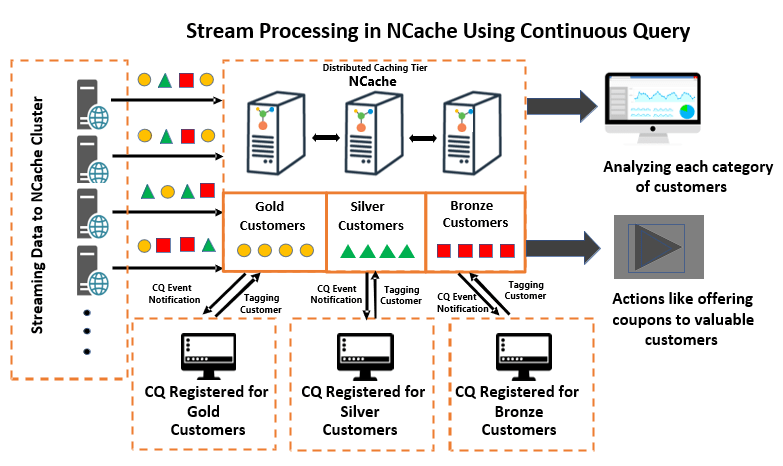
Abbildung 1: Stream-Verarbeitung mit kontinuierlicher Abfrage
Ebenso kann die Anwendung mehrere Kategorien erstellen, indem sie mehrere CQs registriert, jede mit ihren eigenen Kriterien und einem Rückruf. Auf diese Weise erhält die Anwendung nur die gefilterten Daten, an denen sie interessiert ist. Die gefilterten Daten können dann entsprechend den Geschäftsanforderungen weiter analysiert werden, beispielsweise durch die Gewährung von Rabatten für High-End-Kunden basierend auf der Kundenkategorie.
Ereignisse werden ausgelöst, wenn eine der folgenden Datenänderungsaktionen im Cache stattfindet:
- Hinzufügen: Hinzufügen eines neuen Elements zum Cache, das die Abfragekriterien erfüllt
- Update: Aktualisieren eines vorhandenen Elements im Abfrageergebnissatz.
- Entfernen: Entfernen eines Elements aus dem Cache oder Aktualisieren eines vorhandenen zwischengespeicherten Elements, sodass das Element aus dem Abfrageergebnissatz entfernt wird.
Lassen Sie uns ein kurzes Codebeispiel für die Verwendung der Stream-Verarbeitung im Cache mit kontinuierlicher Abfrage durchgehen. In diesem Beispiel wird eine kontinuierliche Abfrage der Daten ausgeführt, bei der Bestellungen mit mehr als 10 zur Kategorie „Goldkunden“ hinzugefügt werden. Darüber hinaus wird für jedes zum Abfrageergebnissatz hinzugefügte Element ein Ereignis ausgelöst.
|
1 2 3 4 5 6 7 8 9 10 11 |
string query = SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery (queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification (new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
NCache Details Kontinuierliche Abfrage und Pub/Sub
Continuous Query behält die Daten bei, die Pub/Sub nicht behält
Jetzt werden die durch kontinuierliche Abfrage gefilterten Daten (für Kunden mit Bestellungen >10) als „Gold-Kunden“ markiert und im Cache aktualisiert. Schauen Sie sich den Code unten an, um zu sehen, wie es gemacht wird.
|
1 2 3 4 5 6 7 8 9 10 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.None); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
Bei einer kontinuierlichen Abfrage bleiben die Daten auch nach der Verarbeitung im Cache erhalten. Auf diese Weise wird das Problem gelöst, mit dem Pub/Sub bei ständig neu entstehenden Daten konfrontiert ist, bei denen mehrere Anwendungen die Daten veröffentlichen NCache Nachrichtenschicht. Daher empfangen mehrere Teilnehmer die Daten und verfügen über keinen zuverlässigen Datenspeicher, da die Nachrichten nach dem Empfang vom Nachrichtenbus entfernt werden. Die Daten werden entweder von der Anwendung oder durch Hinzufügen einer neuen Datenquelle gespeichert, was ein weitaus komplexeres Szenario darstellt. Die kontinuierliche Abfrage hingegen stellt sicher, dass es zu keinem Datenverlust kommt, und erspart Ihnen so den zusätzlichen Aufwand für die manuelle Speicherung Ihrer Daten.
NCache Details Herunterladen NCache Editionsvergleich
Kontinuierliche Abfrage ermöglicht Anwendungsentkopplung durch leistungsstarke Filterung
Große komplexe Anwendungen können je nach Architektur unterschiedliche Gruppierungen haben. Wenn beispielsweise zehn Anwendungen ausgeführt werden, könnten zwei von ihnen den Datensatz der Gold-Kunden verarbeiten, während die anderen beiden den Datensatz der Silver-Kunden verarbeiten könnten. In solchen Fällen möchten Sie für jeden Datensatz eine separate Geschäftslogik, in der die Daten entsprechend den Anforderungen der einzelnen Anwendungen an die Stream-Verarbeitung gefiltert werden. Daher müssen solch große, komplexe Anwendungen entkoppelt werden, da die Abhängigkeit der Anwendungen voneinander zu enormen Leistungsengpässen und einer erhöhten Anwendungskomplexität führt.
Die kontinuierliche Abfrage filtert die Daten Ihrer Anwendungen sehr effizient mit Hilfe ziemlich ausgefeilter SQL-Anweisungen, sodass es zu keinen Überschneidungen zwischen Anwendungen und anderen Anwendungen kommt. Diese Entkopplung ist in einer Microservices-Architektur von großem Nutzen, in der jeder Dienst auf einem separaten Anwendungsstapel ausgeführt wird. Jeder Microservice ruft und verarbeitet seine eigenen Daten, ohne dass eine Abhängigkeit entsteht. Dieses Maß an Datenfilterung und Anwendungsentkopplung kann mit Pub/Sub nicht erreicht werden.
Abbildung 2 zeigt verschiedene Clientanwendungen, die ihre jeweiligen Datensätze in einer entkoppelten Architektur verarbeiten NCache Kontinuierliche Abfragen.
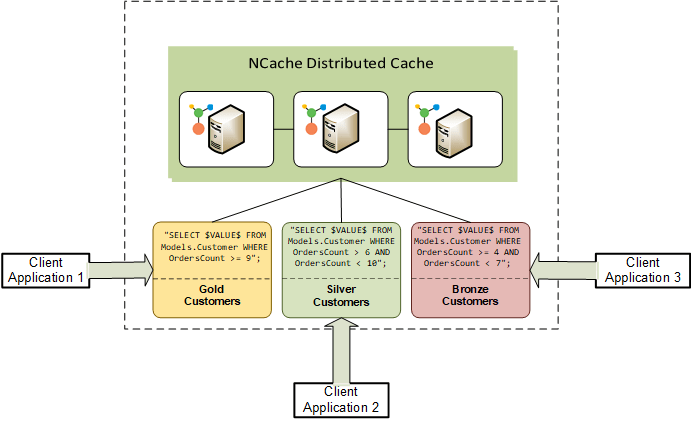
Abbildung 2: Entkopplung zwischen Anwendungen
Abrufen von Daten mithilfe von Tags
Schlüsselwörter in NCache werden Qualifizierer für die Daten hinzugefügt, die verwendet werden, um die Daten basierend auf ihnen zu kategorisieren. Bei großen Datenmengen wie dem genannten Szenario sind Tags sehr hilfreich, um relevante Daten abzurufen, anstatt den gesamten Cache nach den Daten zu durchsuchen. Wenn ein Kunde in die Kategorie „Gold-Kunden“ fällt, wird ihm zum schnellen Auffinden ein Tag hinzugefügt. Basierend auf diesen Kategorien können den Kunden Zusatzleistungen wie Rabatte, Gutscheine etc. angeboten werden. NCache bietet verschiedene Flexible Möglichkeiten zum Abrufen von Daten mithilfe von Tags, ausführlich in der Dokumentation erklärt.
Schauen wir uns nun das Codebeispiel der Tags an, die mit „Gold-Kunden“ verknüpft sind. Diesen Kunden können Gutscheine oder Premium-Dienste angeboten werden.
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
Ablaufende Cache-Daten
NCache erlaubt Ablauf der Cache-Daten Dadurch werden die Daten nach einem bestimmten Intervall ungültig gemacht und dann in einem sauberen Intervall aus dem Cache entfernt.
NCache bietet zwei Arten von Abläufen:
Bei Kunden wird das Ablaufdatum für die Artikel hinzugefügt, die nicht unter eine der drei Kategorien Gold, Silber oder Bronze fallen. Alle anderen Kunden mit weniger als 4 Bestellungen werden mit einem Ablaufzeitintervall hinzugefügt und für keine weitere Analyse aus dem Cache entfernt. Allerdings wird der Ablauf jedes Kunden, der zu einer der Kategorien gehört, auf „Keine“ gesetzt, um die Daten im Cache beizubehalten, sofern sie nicht manuell entfernt werden. So können Sie einem Kunden mit weniger als 15 Bestellungen eine Ablauffrist von 4 Sekunden hinzufügen.
|
1 2 3 4 5 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, new TimeSpan(0, 0, 15)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
Warum verwenden? NCache?
NCache is 100% .NET/.NET Zentrale, verteilte In-Memory-Caching-Lösung und seit langem führend auf dem Markt. Es ist extrem schnell und linear skalierbar und beseitigt effizient Leistungsengpässe für Ihre Anwendung, indem es die Daten zwischenspeichert. Sie sparen Netzwerkkosten, indem Sie teure Netzwerkfahrten reduzieren. NCache bietet Ihnen zahlreiche Funktionen wie Continuous Query, die die Datenanalyse sehr schnell und effizient machen, sowie andere Funktionen, die einen reibungslosen Ablauf Ihrer Anwendung ermöglichen.





