NCache ist eine Lösung zur Leistungsoptimierung, die Skalierbarkeit und hohe Verfügbarkeit bietet. Es bietet verschiedene Caching-Topologien, um lineare Skalierbarkeit sowie Datenkonsistenz und -zuverlässigkeit zu gewährleisten. Diese Topologien sind darauf ausgelegt, unterschiedliche Caching-Anforderungen von Anwendungen zu erfüllen, die in einer kleinen Caching-Umgebung mit zwei Servern betrieben werden, bis hin zu riesigen Cache-Clustern mit Hunderten Cache-Servern.
Im Folgenden sind die Merkmale der Caching-Topologien aufgeführt, die NCache bietet:
Replizierter Cache
Die Topologie gewährleistet Datenzuverlässigkeit durch Datenreplikation auf mehreren Cache-Servern. Der Replizierter Cache ist extrem schnell und skalierbar für Leseoperationen. Für Schreibvorgänge ist es jedoch nicht sehr skalierbar, da sie mit allen Servern im Cluster synchron sind. Die Topologie ist für kleinere Caching-Umgebungen vorgesehen, in denen die Anzahl der Lesevorgänge höher ist als die der Schreibvorgänge. Im Folgenden finden Sie eine kurze Übersicht über die Funktionsweise der Replicated Cache-Topologie.
Wie funktioniert die replizierte Cache-Topologie?
Die Replicated Cache-Topologie bietet eine hohe Datenverfügbarkeit und unterstützt das dynamische Hinzufügen und Löschen von Servern, ohne den vorhandenen Cache zu stoppen.
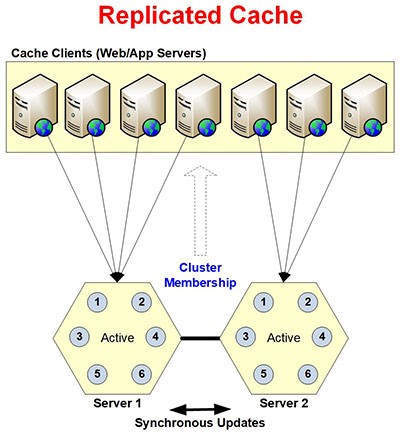
Abbildung 1: Architektur der replizierten Caching-Topologie
Anders als bei den Topologien „Partition“ und „Partitionsreplikat“ stellt jede Client-Anwendung eine Verbindung zu nur einem Serverknoten her, basierend auf einem Lastausgleichsalgorithmus, der von den Cache-Servern bestimmt wird. Wenn der verbundene Server ausfällt, stellt die Clientanwendung eine Verbindung zum nächsten Server in der Liste her.
Gespiegelte Cache-Topologie
Das Gespiegelter Cache ist ein 2-Knoten-Aktiv/Passiv-Cache-Cluster, der für kleinere Caching-Umgebungen entwickelt wurde. Die Topologie bietet Datenzuverlässigkeit und -verfügbarkeit durch asynchrone Replikation/Spiegelung vom aktiven Knoten zum passiven Knoten.
Wie funktioniert die gespiegelte Cache-Topologie?
In der Topologie mit gespiegeltem Cache verbinden sich die Client-Knoten für alle Lese- und Schreibvorgänge nur mit dem aktiven Server-Knoten im Cluster. Wenn der aktive Serverknoten ausfällt, verbinden sich die Clientanwendungen automatisch mit dem zuvor passiven Knoten. Diese Failover-Unterstützung stellt sicher, dass der gespiegelte Cache immer betriebsbereit ist. Die Topologie bietet asynchrone Spiegelung für Schreibvorgänge, die zur Verbesserung der Anwendungsleistung beitragen, da mehrere Schreibvorgänge als BULK-Vorgang auf dem passiven Serverknoten ausgeführt werden.
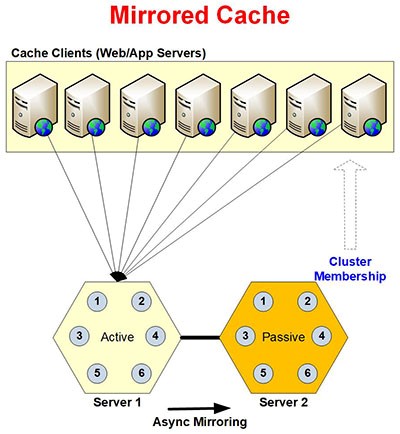
Abbildung 2: Architektur der gespiegelten Caching-Topologie
Partitionierter Cache
Es ist eine der schnellsten und am besten skalierbaren Caching-Topologien, die von angeboten werden NCache. Die Topologie ist sowohl für Lese- als auch für Schreibvorgänge gleichermaßen effizient. Durch das Hinzufügen von Servern zum Cluster wird eine lineare Skalierbarkeit erreicht. Nachfolgend finden Sie einen kurzen Überblick über die Funktionsweise der Partitioned Cache Topology.
Wie funktioniert die partitionierte Cache-Topologie?
In der Topologie mit partitioniertem Cache wird der Cache zur Laufzeit in Teile unterteilt, wobei für jeden Cache-Server eine einzelne Partition vorhanden ist. Diese Partitionen bilden zusammen einen geclusterten Cache mit 1000 Buckets, die gleichmäßig auf alle Partitionen verteilt sind. Der Cluster erstellt eine Verteilungskarte, die die Zuordnung von Buckets in verschiedenen Partitionen enthält. Diese Zuordnung stellt eine sinnvolle Kommunikation zwischen Client- und Serverknoten sicher.
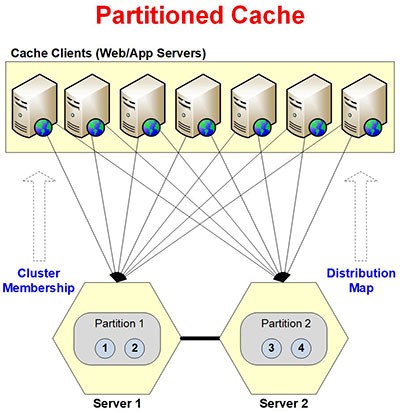
Abbildung 3: Architektur der partitionierten Caching-Topologie
Die Topologie bietet auch eine hohe Datenverfügbarkeit, indem alle Clientanwendungen mit Cache-Servern verbunden werden. Damit die Anwendung die erforderlichen Daten auch dann abrufen kann, wenn der verbundene Server ausfällt, indem sie die anderen Server anfordert.
Topologie des Partitionsreplikat-Cache
Dies ist die beliebteste Caching-Topologie in NCache. Da es Benutzern das Beste aus beiden Welten bietet, mit linearer Skalierbarkeit und hoher Datenzuverlässigkeit. Diese Topologie ist fast so skalierbar wie die partitionierte Topologie und bietet vielversprechende Leistung und hohe Datenverfügbarkeit mit synchronisierten und asynchronen Replikationsmodi. Im Folgenden finden Sie einen kurzen Überblick über die Funktionsweise dieser Topologie.
Wie funktioniert die Partition Replica Cache-Topologie?
Neben der Erstellung dynamischer Partitionen erstellt die Topologie auch dynamische Repliken dieser Partitionen auf verschiedenen Serverknoten – die als Backup dienen, wenn eine Verbindung fehlschlägt oder ein Knoten ausfällt. In solchen Fällen, NCache erhält Daten vom Replikatknoten und rediswürdigt es. Diese Replikate schränken jedoch die Clusterskalierbarkeit ein, da jeder hinzugefügte Serverknoten in aktive und Replikatpartitionen unterteilt wird.
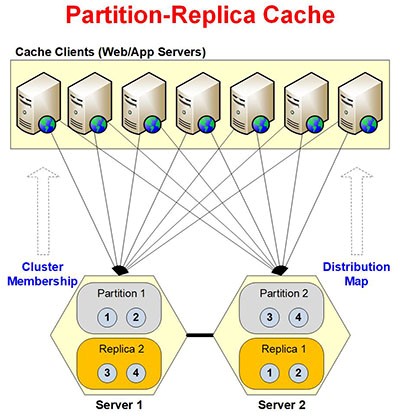
Abbildung 4: Architektur der Partition-Replica-Caching-Topologie
Die Topologie bietet zwei Replikationsmodi; synchronisiert und asynchron. Bei der asynchronen Replikation werden alle Replikate im Hintergrund erstellt, was zu null Leistungsverzögerungen führt. Dies beinhaltet jedoch ein geringes Risiko eines Datenverlusts, wenn das Replikat ausgefallen ist, da die Daten dort nicht ankommen. Um einen solchen Verlust zu vermeiden, bietet die Topologie auch eine synchronisierte Replikation, bei der während der Laufzeit Replikate erstellt werden und jeder Vorgang, der auf einem Replikat fehlgeschlagen ist, auch auf der Partition als fehlgeschlagen betrachtet wird. Die Topologie bietet vollständige Serverkonnektivität, um eine hohe Datenverfügbarkeit sicherzustellen.
Client-Cache-Topologie
Im Client-Cache Topologie befindet sich der Cache sehr nahe an Ihrer Anwendung und ermöglicht es Ihnen, die Daten aus dem verteilten Cache schnell zwischenzuspeichern. Der Client-Cache kann auch als „Cache on Top of Cache“ betrachtet werden. Es ist für leseintensive Anwendungen geeignet, aber wenn Ihre Anwendung eine gleiche Anzahl von Lese- und Schreibvorgängen ausführen muss, wird es langsamer arbeiten, da Schreibvorgänge die Aktualisierung der Daten an zwei Stellen erfordern.
Obwohl der Client-Cache lokal ist, ist er nicht eigenständig, da er immer mit dem Cluster-Cache synchronisiert wird. Diese Synchronisierung stellt sicher, dass die Daten im Client-Cache immer aktualisiert werden. Im Folgenden finden Sie eine Übersicht über die Hauptmerkmale der Client-Cache-Topologie.
Wie funktioniert die Client-Cache-Topologie?
Der Client-Cache existiert entweder im InProc-Modus (innerhalb Ihres Prozesses) oder im OutProc-Modus (lokal auf dem Web-/App-Server). In beiden Fällen verbessert es die Leistung Ihrer Anwendung. Im InProc-Modus können Sie Objekte auf Ihrem „Anwendungs-Heap“ zwischenspeichern, wodurch Sie „InProc-Geschwindigkeit“ als anderen verteilten Cache erhalten. Das Beste am Client-Cache ist, dass er keine Codeänderung in Ihrer Anwendung erfordert. Stattdessen schließen Sie es einfach durch eine Konfigurationsänderung an.
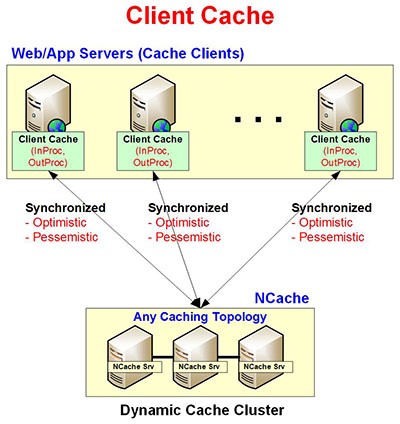
Abbildung 5: Architektur des Client-Cache
Die Topologie bietet optimistische und pessimistische Datensynchronisation. Die Standardsynchronisierung im Client-Cache ist optimistisch, wobei NCache Der Client geht davon aus, dass alle Daten, die der Client-Cache enthält, die neueste Kopie sind. Bei der pessimistischen Synchronisierung überprüft der Cache-Client zuerst den Clustered Cache, ob er eine neuere Version eines zwischengespeicherten Elements enthält. Wenn dies der Fall ist, ruft der Client sie ab, legt sie in den Client-Cache und gibt sie an die Client-Anwendung zurück.
Zusammenfassung
NCache bietet eine Vielzahl von Caching-Topologien an, um die unterschiedlichen Caching-Anforderungen seiner Kunden zu erfüllen. Alle von ihnen sind verteilt, hochgradig skalierbar und zuverlässig. Abhängig von der Größe Ihrer Daten, der Art der auszuführenden Operationen und der Anzahl der durchzuführenden Transaktionen können Sie eine der genannten Topologien auswählen. Um mehr darüber zu erfahren NCache Topologien Zögern Sie nicht, die kostenlose 60-Tage-Testversion herunterzuladen NCache.





