Verteilte persistente Caches
NCache Bietet verteilte persistente Schlüsselwert-Caches, um wertvolle Daten bei Bedarf zuverlässig abzurufen. Es verwaltet eine Kopie der Cache-Daten im Persistenzspeicher und lädt die persistenten Daten später bei einem Cache-Neustart (geplant oder ungeplant). Es speichert und lädt so viele Daten, wie die Cache-Server aufnehmen können. Persistenz gewährleistet eine hohe Datenverfügbarkeit und gleichzeitig sorgen In-Memory-Daten für eine hohe Leistung. In diesem Dokument wird ein verteilter Cache mit Persistenz auch als persistenter Cache bezeichnet.
Note
Nur verteilter Cache mit Persistenzunterstützung Partitionierte Topologien und Lokale (OutProc) Caches.
Sie können einen verteilten Cache mit Persistenz erstellen, indem Sie a verwenden NoSQL Document Store als Persistenzspeicher zur Datensicherung. Der Cache speichert alle Schreib-APIs, Metainformationen usw. Ströme, Datenstrukturen und dynamische Indizes zum Backend-Store.
Note
Pub/Sub-Nachrichten werden nicht dauerhaft gespeichert, aber NCache unterstützt Pub/Sub-API und ermöglicht Ihnen die Erstellung eines dedizierten Pub/Sub-Messaging-Cache.
Bitte beachten Sie, dass die Daten, die aufgrund einer Datenungültigkeitserklärung oder einer expliziten Entfernung aus dem Cache entfernt wurden, auch aus dem zugrunde liegenden Persistenzspeicher entfernt werden. Das Hinzufügen von Elementen mit Ablauf und Schlüsselabhängigkeit wird unterstützt. Wir empfehlen diesen Ansatz jedoch nicht, da die in einem solchen persistenten Cache gespeicherten Daten permanente Daten sind. Inzwischen Daten mit Abhängigkeit von der Datenbank und die Abhängigkeit von externen Quellen soll nicht dauerhaft bestehen bleiben.
Note
Ähnlich wie bei einem flüchtigen verteilten Cache wird eine Sicherungsquelle für einen verteilten Cache mit Persistenz unterstützt.
Persistenter Cache: Warum Daten persistent bleiben?
NCache speichert Daten im RAM für einen schnelleren Zugriff. Da der Cache-Speicher flüchtig ist, ist ein Datenverlust in den folgenden Szenarien unvermeidlich:
- Knoten in der partitionierten Topologie ausgefallen.
- In der Partition-Replica-Topologie sind mehrere Knoten gleichzeitig ausgefallen.
- Der Cluster ist aus Wartungsgründen oder aufgrund eines schwerwiegenden Fehlers ausgefallen.
Mit einem persistenten Cache können Sie Folgendes erreichen:
Hohe Datenverfügbarkeit: Im Falle eines Speicherausfalls aus einem der oben genannten Gründe, NCache stellt die Daten schnell wieder her, indem es sie aus dem zugrunde liegenden Persistenzspeicher lädt. Der Cache ist auch nach einem katastrophalen Ausfall betriebsbereit, ohne den Clientbetrieb zu beeinträchtigen.
Fehlertoleranz: Das Aufrechterhalten einer Echtzeitkopie der Cache-Daten minimiert Ausfallzeiten und bietet Fehlertoleranz, wenn einzelne/mehrere Knoten den Cluster verlassen.
Wichtig
Für Persistenz sollte die Schlüssellänge 1023 Byte nicht überschreiten.
Persistenter Cache: So funktioniert es
Hier beschreiben wir die Funktionsweise und das Verhalten eines verteilten Caches mit Persistenz. Das folgende Diagramm zeigt die grundlegende Architektur. Sie können einen verteilten Cache mit Persistenz mit einem Persistenzspeicher am Back-End erstellen. Der Speicher ist zentralisiert und für alle Knoten zugänglich. NCache schreibt Daten, die dem Cache hinzugefügt wurden, in wartbaren Zeitintervallen in den Backend-Speicher. Beim Cache-Neustart oder Verlassen/Beitreten von Knoten werden die persistenten Daten in den Arbeitsspeicher geladen, so viel wie die Cache-Server aufnehmen können.
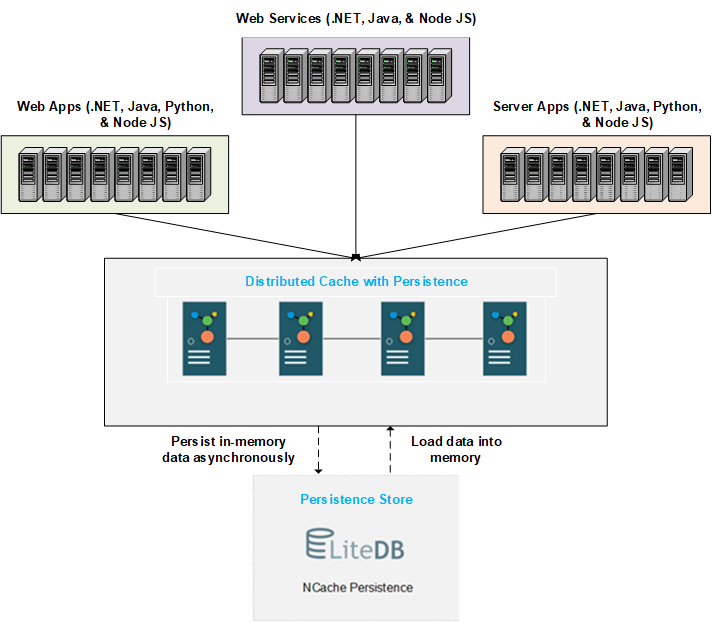
Wir besprechen den detaillierten Prozess der Datenpersistenz und des Ladens unten.
Datenpersistenz in einem persistenten Cache
Nachdem Sie einen verteilten Cache mit Persistenz erstellt haben, werden alle Schreibvorgänge zuerst im Arbeitsspeicher ausgeführt und dann im Back-End-Speicher gespeichert. Seit NCache verfügt über eine verteilte Architektur. Jeder Serverknoten behält seine Daten bei, während alle Serverknoten auf den Speicher zugreifen können. Da die Datenverteilung aufgrund von Partitionen außerdem Bucket-basiert erfolgt, bleiben die Daten ebenfalls erhalten.
Asynchrone Persistenz in einem persistenten Cache
NCache speichert Daten im Speicher durch asynchrone Persistenz im Persistenzspeicher. Hier erklären wir, wie es funktioniert. Jede Partition verfügt über eine Persistenzwarteschlange, um ausgeführte Client-Vorgänge aufzuzeichnen. Alle vom Client ausgeführten Schreibvorgänge werden nach Erfolg in die Warteschlange gestellt. Da die Persistenz asynchron funktioniert, wartet der Client nicht, nachdem er den Vorgang in die Warteschlange gestellt hat. Die in der Warteschlange befindlichen Vorgänge werden regelmäßig zu einem konfigurierbaren Zeitpunkt überprüft persistence-interval und schließlich durch einen Persistenzthread in den Backend-Speicher repliziert. Jede Warteschlange wird unabhängig geschrieben.
Note
Der Standardwert von persistence-interval is 1 Sek. und es ist im konfigurierbar NCache Management Center.
Normalerweise wird die Charge danach aufgetragen persistence-interval, aber wenn der Persistenzbatch nacheinander fehlschlägt, dann danach persistence-retries Batch-Intervall verschoben wird persistence-interval-longer. Sobald es erfolgreich ist, wird das Batch-Intervall auf zurückgesetzt persistence-interval.
Wichtig
Die Leistung des Caches wird nicht beeinträchtigt, da Clientvorgänge aufgrund der asynchronen Replikation wie gewohnt ausgeführt werden.
Wenn der Cache aufgrund eines Problems keine Daten in der Persistenzwarteschlange speichern kann, nimmt er weiterhin Schreibvorgänge entgegen, bis er voll ist. Wenn die Vorgänge in der Warteschlange nicht bestehen bleiben, werden Informationen zu den fehlgeschlagenen Buckets in den Cache-Protokollen protokolliert.
Note
Die Partition-Replica-Topologie wird nach einem Warteschlangenfehler über die Warteschlange des Replikats wiederhergestellt. Allerdings ist ein Datenverlust unvermeidlich, wenn ein Knoten und sein Replikat gleichzeitig ausfallen.
Laden von Daten in einen persistenten Cache
Sobald sich die Daten im Speicher befinden, lädt der Cache die persistenten Daten beim Cache-Neustart automatisch neu in den Arbeitsspeicher. Der persistente Speicher muss für Cache-Knoten jederzeit verfügbar sein. Wenn sie nicht auf den Store zugreifen können, wird der Cache nicht gestartet. Das Laden von Daten erfolgt auf verteilte Weise. Da die Datenspeicherung ein Bucket-basiertes Verfahren ist, kann jeder Knoten auf den zentralisierten Speicher zugreifen, um seine zugewiesenen Buckets basierend auf der Datenverteilungskarte zu laden. Wenn Sie außerdem Indizes zum Abfragen von Daten im Cache konfiguriert haben, werden die Abfrageindizes beim Cache-Neustart neu generiert.
Wichtig
Der Persistenzspeicher sollte allen Cache-Knoten jederzeit zur Verfügung stehen.
Betriebsverhalten beim Laden von Daten
Datenlade- und Persistenzprozesse laufen gleichzeitig. In der Zwischenzeit werden die schlüsselbasierten Abrufe aus dem Cache bedient, wenn die angeforderten Daten geladen werden. Wenn es sich nicht im Cache befindet, werden solche Operationen direkt aus dem Speicher durch verzögertes Laden bedient. In diesem Fall ist die Leistung der Get Der Betrieb wird beeinträchtigt.
Bitte beachten Sie, dass die nicht schlüsselbasierten oder kriterienbasierten Suchoperationen, wie z GetGroupKeys, GetKeysByTagund SQL-Abfragen werden erst bedient, wenn die Daten vollständig aus dem Speicher in den Arbeitsspeicher geladen wurden.
Warnung
Wenn während des Ladens von Daten ein nicht schlüsselbasierter Suchvorgang auftritt und die angeforderten Daten nicht vollständig geladen werden, gibt die Anwendung eine Ausnahme aus Daten nicht vollständig aus dem Persistenzspeicher geladen.
Szenarien zum Laden von Daten
Daten werden in den folgenden Szenarien aus dem Persistenzspeicher geladen:
Beim Cache-Start: Beim Cache-Start lädt der Koordinatorknoten alle Buckets. Sobald andere Knoten dem Cluster beitreten, wird die Bucket-Verteilung aktualisiert. Jeder Knoten sucht nach seinen zugewiesenen Buckets in der lokalen Umgebung. Die in den Cache geladenen Buckets werden durchgezogen staatliche Übertragung. Wenn die einem Knoten zugewiesenen Buckets nicht vollständig geladen werden, werden diese Buckets von diesem Knoten direkt aus dem Speicher geladen. Jeder Knoten kann auf den Speicher zugreifen, um seine zugewiesenen Buckets zu laden, sofern sie im Cache vorhanden sind.
Wenn ein verteilter Cache mit Persistenz zum ersten Mal gestartet wird, kann er durch Konfiguration gefüllt werden Cache-Startuploader da der Persistenzspeicher zu diesem Zeitpunkt keine Daten enthält. Sobald der Speicher gefüllt ist, werden die Daten beim Cache-Start immer aus dem Speicher geladen, auch wenn Sie den Cache Loader konfiguriert haben. Wenn Sie jedoch regelmäßig weitere Daten hinzufügen müssen, können Sie verwenden Cache-Refresher. Die Cache-Aktualisierung wird in regelmäßigen Abständen ausgeführt, unabhängig davon, ob der Cache und der Speicher bereits über die Daten verfügen.
Beim Knotenbeitritt: Wenn ein neuer Knoten dem Cluster beitritt, erhält er die zugewiesenen Buckets von den vorhandenen Cluster-Knoten durch Zustandsübertragung, wenn sie bereits geladen sind. Wenn die zugewiesenen Buckets nicht vollständig in den Cache geladen werden, werden sie vom neuen Knoten aus dem Speicher geladen.
Beim Verlassen des Knotens: Daten werden aus dem Speicher geladen, um Datenverluste zu vermeiden, wenn ein Knoten oder Knoten den Cluster verlassen. Das Ladeverhalten beim Verlassen des Knotens variiert je nach Topologie.
Partitionierte Topologie: Wenn ein Knoten verlässt, werden seine Buckets auf die vorhandenen Clusterknoten verteilt und von den neuen Eigentümern aus dem Persistenzspeicher geladen.
Partitions-Replikat-Topologie: Partition-Replica toleriert Knotenausfälle bis zu einer Ebene, indem verlorene Buckets durch Statusübertragung vom Replikat wiederhergestellt werden. Wenn jedoch ein Knoten und sein Replikat gleichzeitig ausfallen, können die verlorenen Daten immer noch aus dem Sicherungsspeicher wiederhergestellt werden.
Wichtig
Der Cache sollte die Kapazität haben, die Daten im Falle eines Knotenausfalls/-verlassens aufzunehmen.
Kapazitätsverwaltung für einen verteilten Cache mit Persistenz
Ein persistenter Cache kann sich nur dann von einem Datenverlust beim Verlassen oder Ausfall eines Knotens erholen, wenn der Cache über genügend Puffer verfügt, um die Daten des/der verlassenen Knoten aufzunehmen. Wenn der Cache nicht alle Daten im Persistenzspeicher aufnehmen kann, weil er voll ist oder aus einem anderen Grund, schlagen die Hinzufügungs- oder Aktualisierungsvorgänge fehl. In der Zwischenzeit verfügen einige Buckets nicht über vollständige Daten. Diese unvollständigen Buckets werden in zwei Fällen aus dem Speicher neu geladen:
- Ein neuer Knoten tritt dem Cluster bei.
- Die Cache-Größe erhöht sich durch Hot Apply.
Note
Wenn ein Cache voll ist, aber zu 100 % mit dem Persistenzspeicher synchronisiert ist, werden nur neue Hinzufügungen blockiert. Alle anderen Operationen können problemlos auf dem Cache ausgeführt werden.
Wenn der Cache mit Teildaten im Arbeitsspeicher voll ist, kann der Cache möglicherweise keine nicht schlüsselbasierten oder kriterienbasierten Operationen (wie z GetGroupKeys, GetKeysByTag, und SQL-Abfragen). Andererseits werden die schlüsselbasierten Abrufe immer entweder über den Cache oder über den Speicher bereitgestellt. Insbesondere versucht der Cache, alle schlüsselbasierten Gets für die unvollständigen Buckets im Falle von Cache-Fehlschlägen zu laden.
Warnung
Wenn ein kriterienbasierter Suchvorgang bei vollem Cache stattfindet und sich die angeforderten Daten nicht im Cache befinden, wird eine Ausnahme ausgelöst Der Vorgang kann nicht ausgeführt werden, da der Cache nicht alle Daten im Speicher hat.
Kapazitätsplanung für Cache voll
Um die Probleme zu vermeiden, die bei vollem Cache auftreten, müssen Sie die Kapazität Ihres persistenten Caches planen, bevor Sie ihn verwenden. Wenn Sie die Kapazitätsplanung für einen verteilten Cache mit Persistenz durchführen, empfehlen wir Ihnen, die Größe des Caches pro Knoten so zu planen, dass beim Ausfall eines Knotens die verbleibenden Knoten alle Daten des verlorenen Knotens aufnehmen können.
Cache-Größenerweiterung bei vollem Cache
Wichtig
NCache versucht, eine hohe Datenverfügbarkeit beim Verlassen eines einzelnen Knotens in einem auf Partitionsreplikaten basierenden verteilten Cache mit Persistenz durch Größenerweiterung sicherzustellen. Eine hohe Datenverfügbarkeit wird jedoch weder versprochen noch garantiert.
Wenn im Fall von Partition-Replica ein Knoten einen Cluster verlässt, nehmen die verbleibenden Knoten im Cluster die Daten auf, die dem verlassenden Knoten gehören. Es besteht jedoch die Möglichkeit, dass die Daten vom ausgehenden Knoten aufgrund von Größenproblemen keinen Platz haben. NCache unterstützt die automatische Cache-Größenerweiterung, wenn ein Knoten den auf Partitionsreplikaten basierenden verteilten Cache mit Persistenz verlässt. Der Erweiterungsmodus wird nur für den Ausfall eines einzelnen Knotens unterstützt. Der Zweck besteht darin, Teildaten im Cache zu vermeiden und die kriterienbasierten Vorgänge für den gesamten Cache bereitzustellen.
Der Expansionsprozess erfolgt intern. Der Erweiterungsmodus wird ausgelöst, wenn ein einzelner Knoten den Cluster verlässt, während laufende Knoten entweder gleich oder größer als die konfigurierten Knoten sind. Die erweiterte Größe wird basierend auf den konfigurierten Knoten oder den ausgeführten Knoten im Cluster (je nachdem, welcher Wert höher ist) berechnet. Wenn sich der Cache im erweiterten Modus befindet, vergrößert jeder Knoten im Cluster automatisch seine Größe, um die Daten aufzunehmen, die durch die Zustandsübertragung beim Verlassen des Knotens empfangen werden.
Wichtig
Die Erweiterung erfolgt nur, wenn die Anzahl der verbleibenden Knoten (nach dem Knotenausfall) beträgt max. {konfigurierte Knoten/laufende Knoten}-1. Die erweiterte Größe wird basierend auf den konfigurierten Knoten oder laufenden Knoten im Cluster berechnet (je nachdem, welcher Wert höher ist).
Im erweiterten Modus werden sowohl schlüssel- als auch kriterienbasierte Operationen bedient. Es blockiert jedoch weiterhin Operationen zum Hinzufügen, wenn die Cache-Größe einmal die konfigurierte Cache-Größe überschritten hat.
Der Cache verlässt den erweiterten Modus, wenn entweder ein neuer Knoten dem Cluster beitritt oder die Cachegröße durch Hot Apply zunimmt. Dann wird die Verteilungskarte aktualisiert und die Zustandsübertragung ausgelöst. Sobald die Zustandsübertragung abgeschlossen ist, verlässt jeder Knoten den erweiterten Modus, und die Cache-Größe wird auf die konfigurierte Cache-Größe reduziert.
Note
Ein Eintrag wird sowohl in Cache-Protokollen als auch in Ereignisprotokollen protokolliert, wenn der Cache in den erweiterten Modus eintritt und dort existiert.
Verhalten bei Unzugänglichkeit
Daten werden beim Cache-Start aus dem Persistenzspeicher geladen – daher muss der Speicher konsistent für Cache-Knoten verfügbar sein. Hier besprechen wir das Verhalten, wenn auf den Persistenzspeicher nicht zugegriffen werden kann;
- Zum Zeitpunkt der Cache-Erstellung: Die Verbindung zum Store wird zum Zeitpunkt der Cache-Erstellung überprüft. Wenn darauf nicht zugegriffen werden kann, können Sie den Cache nicht erstellen und erhalten eine Fehlermeldung. Ebenso wird ein Cache nicht gestartet, wenn der Speicher für keinen Clusterknoten verfügbar ist.
Warnung
Der Cache wird erst gestartet, wenn der Persistenzspeicher zum Zeitpunkt der Cache-Erstellung für alle Serverknoten zugänglich ist.
Zum Zeitpunkt des Datenladens: Der Speicher kann während des Ladens von Daten aufgrund eines Netzwerkfehlers unzugänglich werden. In diesem Fall versucht der Cache erneut, die verbleibenden Daten-Buckets im Ladezustand zu laden. In der Zwischenzeit werden die nicht auf Schlüsseln basierenden Suchoperationen fehlschlagen. Du kannst Konfigurieren Sie Datenladewiederholungen in der Dienstkonfigurationsdatei.
Zum Zeitpunkt der Ausführung des Caches: Der Speicher kann für einen laufenden Cache aufgrund eines Netzwerkfehlers entweder für kurze Zeit oder für unbegrenzte Zeit unzugänglich werden. Bei einem solchen Verbindungsverlust akzeptiert der Cache weiterhin Schreibvorgänge und stellt sie in die Warteschlange. In der Zwischenzeit, NCache versucht weiterhin, die Vorgänge in der Warteschlange in Stapelintervallen beizubehalten, bis die Verbindung zum Persistenzspeicher wiederhergestellt ist.
Wenn Sie die Verbindung unendlich verlieren, finden die Schreibvorgänge statt, bis der Cache-Speicher voll ist. Sobald der Cache voll ist, schlagen nachfolgende Schreibvorgänge fehl. Schlüsselbasierte Abrufoperationen werden jedoch wie zuvor besprochen bedient.
Persistente Cache-Erstellung und -Überwachung
Note
Für einen verteilten Cache mit Persistenz wird nur der serialisierte JSON-Cache unterstützt.
Sie können einen verteilten Cache mit Persistenz erstellen, indem Sie einen neuen oder einen vorhandenen Speicher angeben (erstellt mit NCache) entweder durch die NCache Management Center Oder durch PowerShell-Tool.
NCache bietet anders Leistungsindikatoren zum Überwachen der Statistiken eines verteilten Caches mit Persistenz. Darüber hinaus können Sie Überwachen Sie einen verteilten Cache mit Persistenz durch das NCache Monitor-, PowerShell- und PerfMon-Tool.
Siehe auch
Erstellen Sie einen verteilten Cache mit Persistenz
Erste Schritte mit verteiltem Cache mit Persistenz