Umgang mit relationalen Daten in einem verteilten Cache
Aufgezeichnetes Webinar
Von Ron Hussain und Adam J. Keller
In diesem Video-Webinar erfahren Sie, wie Sie Ihre bestehenden Datenbeziehungen auf Cache-Objekte für verteiltes Caching anwenden.
Sie können erwarten, Folgendes zu hören:
- Das Datenspeichermodell für eine relationale Datenbank und für einen verteilten Cache
- Die Vorteile von objektrelationalem Mapping – wie man Datenbeziehungen auf Objektebene verwaltet
- Abbildung von „Eins-Eins“-, „Eins-Viele“- und „Viele-Viele“-Beziehungen
- Die richtigen NCache Funktionen zum Aufbau von Beziehungen zwischen Objekten, um das Verhalten relationaler Daten nachzuahmen
- Verwendung von schlüsselbasierter Abhängigkeit, Objektabfragesprache, Gruppen, Gruppen-APIs, Sammlungen und Tags
- Weitere wichtige verteilte Caching-Funktionen für relationale Daten
Ich werde über ein verteiltes Caching sprechen. Wenn Sie eine relationale Datenbank haben, wissen Sie, haben Sie einige Herausforderungen, einige Leistungsprobleme, einige Skalierbarkeitsprobleme und dann gehen Sie dazu über, einen verteilten Cache zusammen mit der relationalen Datenbank zu verwenden. Was sind die Herausforderungen, die Sie bekommen und wie Sie diese Herausforderungen bewältigen? Das ist es, was wir für das heutige Webinar auf der Tagesordnung haben.
Es wird ziemlich handfest. Ich möchte Ihnen einige Codebeispiele zeigen. Ich werde über einige reale Beispiele sprechen. Ich habe einige Beispiele aufgereiht, die ich tatsächlich verwenden werde, um dies zu demonstrieren. Und gegen Ende hatte ich dann auch einen praktischen Teil, um einige Grundlagen zu besprechen NCache Konfigurationen.
NCache, das ist das wichtigste verteilte Caching-Produkt. Wir werden das als Beispielprodukt für dieses spezielle Webinar verwenden. Aber insgesamt ist es ein Webinar zu allgemeinen Themen. Wir haben relationale Daten in der Datenbank und dann haben Sie einen verteilten Cache. Wie Sie den verteilten Cache innerhalb der relationalen Daten, die Beziehungen haben, und das sind strukturierte Daten, umstellen und dann mit der Verwendung beginnen. Gehen wir das also durch.
Was ist Skalierbarkeit?
Also, zuerst werde ich über Skalierbarkeit sprechen, das Konzept der Skalierbarkeit. Skalierbarkeit ist eine Fähigkeit innerhalb der Anwendung, mit der Sie die Transaktionslast erhöhen können. Wo Sie mehr und mehr Anforderungen aus der Anwendungsarchitektur heraus verarbeiten können. Und Sie gehen keine Kompromisse bei der Leistung ein. Wenn Sie also einen hohen Durchsatz und eine niedrige Latenz haben, wird diese Fähigkeit als Skalierbarkeit bezeichnet. So können Sie eine große Anzahl von Anfragen bewältigen und die Leistung einzelner Anfragen sinkt nicht. Es ist gleich! Und mit mehr Ressourcen können Sie dies sogar noch steigern, und lineare Skalierbarkeit ist ein damit verbundener Begriff, mit dem Sie tatsächlich skalieren können, wo Sie mehr oder mehr Kapazität für die Verarbeitung von Anforderungslasten in das System eingeführt haben, indem Sie weitere Server hinzufügen. Und in den meisten Fällen sinkt die Leistung nicht.
Wenn Sie also eine geringe Latenz und eine lineare Verbesserung der Anforderungslast haben, haben Sie zuvor beispielsweise 10,000 Anforderungen pro Sekunde verarbeitet, oder sogar für fünf Benutzer haben Sie eine bestimmte Latenz, beispielsweise einige Millisekunden oder Reaktionszeiten von weniger als einer Millisekunde für fünf Benutzer ; Sie sollten die gleiche Art von Antworten haben, die gleiche Art von Latenz für fünftausend Benutzer oder fünfzigtausend Benutzer ausführen. Und diese Fähigkeit, die Benutzerlast und die damit verbundene Anforderungslast weiter zu erhöhen, wird als lineare Skalierbarkeit bezeichnet.
Welche Apps benötigen Skalierbarkeit?
Was sind also die typischen Anwendungen, die Skalierbarkeit benötigen,

Es werden Ihre ASP.NET-Webanwendungen, Java-Webanwendungen oder sogar allgemeine .NET-Webanwendungen sein, die öffentlich zugänglich sind. Es könnte ein E-Commerce-System sein, es könnte ein Flugticketsystem, ein Buchungssystem oder ein Finanzdienstleistungs- oder Gesundheitsdienst sein, der viele Benutzer hat, die seine öffentliche Ausrichtung tatsächlich nutzen. Das können Webdienste WCF oder jeder andere Kommunikationsdienst sein, der mit einigen Datenzugriffsschichten interagiert oder sich mit einigen Front-End-Anwendungen befasst. Es kann jedoch zu einem bestimmten Zeitpunkt Millionen von Anfragen bearbeiten. Es könnte das Internet der Dinge sein, einige Back-End-Geräte, die Daten verarbeiten können, die einige Aufgaben für diese Geräte verarbeiten. Es könnten also viele Anfragen geladen werden. Big-Data-Verarbeitung, das ist heutzutage ein gängiges Schlagwort, wo wir viele kleine, kostengünstige Rechenserver haben und durch die Verteilung von Daten auf mehrere Server tatsächlich riesige Datenmengen verarbeiten.
Und in ähnlicher Weise würde es für diese bestimmten Daten eine enorme Modellanforderungslast geben. Und dann könnten alle anderen allgemeinen Serveranwendungen und Tier-Anwendungen, die Millionen von Anfragen und viele Benutzer verarbeiten, die besten Kandidaten für Skalierbarkeit sein. Das sind die Anwendungen, die Skalierbarkeit innerhalb der Architektur benötigen.
Skalierbarkeitsengpass
Dies ist ein typisches Diagramm. Was ist der Skalierbarkeitsengpass?
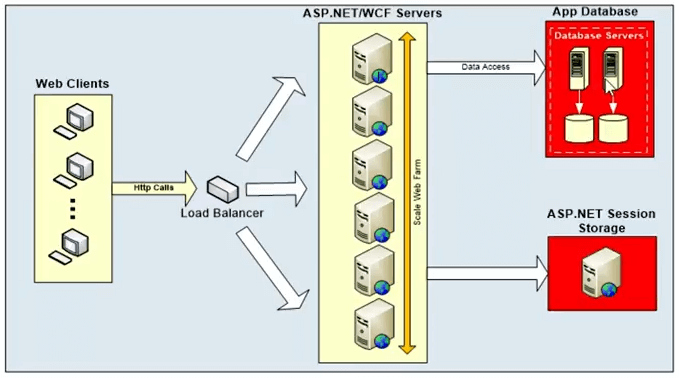
Das sind also die Anwendungen. Diese Frameworks sind konstruktionsbedingt sehr skalierbar. ASP.NET-Webformular oder WCF-Formular gibt es Optionen, mit denen Sie diese Systeme horizontal skalieren können. Aber sie alle kommunizieren mit einer Back-End-Datenbank und normalerweise ist es eine relationale Datenbank. Es könnte auch ein ASP.NET-Sitzungsspeicher oder ein Mainframe oder ein Dateisystem sein, aber das ist nicht das, was wir im heutigen Webinar behandeln. Das heutige Webinar konzentriert sich mehr auf relationale Daten. Relationale Daten sind also eine einzige Quelle. Obwohl Sie hier eine sehr skalierbare Plattform haben. Sie können dieser Stufe immer mehr Server hinzufügen. Sie können horizontal skalieren, indem Sie einen Load Balancer voranstellen, und dieser Load Balancer kann Anforderungen zwischen verschiedenen Servern weiterleiten. Aber all diese Webserver kommunizieren am Ende mit einer Datenbankschicht, die nicht so skalierbar ist.
Das wird also eine Quelle des Streits sein. Es wird zu langsam sein, um zu starten, und dann kann es nicht skaliert werden. Es handelt sich um eine einzige Quelle, es gibt keine Möglichkeit, mehr und mehr Datenbankserver hinzuzufügen, um die Anforderungskapazität zu erhöhen. Daher kann die Kapazität der Anfrage maximal sein, was zu einer hohen Latenz führen kann. Es handelt sich also um ein Kapazitätsproblem bei der Bearbeitung von Anforderungen, und es könnte auch zu einem Latenzproblem führen, sodass das System bei einer großen Anforderungslast abwürgen kann.
Die Lösung
Das ist also das Hauptproblem bei relationalen Datenquellen, und die Lösung dafür ist sehr einfach, dass Sie anfangen, einen verteilten Cache zu verwenden.
Ein verteiltes Caching-System wie NCache Das ist superschnell, weil es im Vergleich dazu In-Memory ist und dann linear skalierbar ist. Es ist nicht nur ein einzelner Server. Es ist eine Umgebung mit mehreren Servern, in der wir ein Team von Servern haben, die zu Kapazitäten zusammengeschlossen sind. Sie bündeln sowohl die Speicherkapazität als auch die Transaktionskapazität und erhalten ein sehr linear skalierbares Modell. Und, NCache ist genau diese Art von Lösung, die Sie verwenden können, um Probleme mit der Datenbankskalierbarkeit zu lösen.
Was ist verteilter In-Memory-Cache?
Wie sieht ein allgemeines verteiltes In-Memory-Caching-System aus? NCache? Was sind die Merkmale?
Cluster aus mehreren kostengünstigen Cache-Servern
Es wird ein Cluster aus mehreren kostengünstigen Cache-Servern sein, die zu einer logischen Kapazität zusammengefügt werden.
Dies ist also ein Beispiel dafür. Sie könnten zwei bis drei Caching-Server haben. Für NCache, können Sie die Umgebung von Windows 2008, 2012 oder 2016 verwenden. Nur Voraussetzung für NCache ist .NET 4. Und es ist eine mittlere Ebene zwischen Ihrer Anwendung und der Datenbank und im Vergleich zu Ihrer Datenbankebene sehr skalierbar, aber es ist etwas, das Ihnen die gleiche Art von Skalierbarkeit bietet, die Sie von einem schnelleren .NET-Web erhalten würden Form- oder WCF-Webdienst-Webformular.
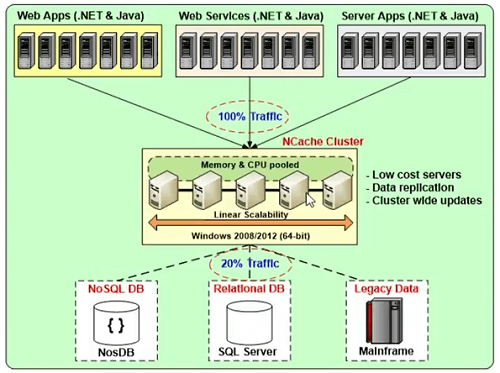
Synchronisiert Cache-Updates auf allen Cache-Servern
Synchronisiert Cache-Updates auf allen Cache-Servern, sodass die Datenkonsistenz in das Protokoll integriert ist. Alle Aktualisierungen werden automatisch mit dem Verständnis einer konsistenten Datenansicht für alle damit verbundenen Clients angewendet.
Skaliert Transaktionen und Speicherkapazität linear
Es sollte sowohl für Transaktionen als auch von der Speicherkapazität linear skaliert werden, Sie fügen einfach mehr Server hinzu und es sollte die Kapazität nicht als Reaktion darauf erhöhen. Wenn Sie zwei Server haben und einen dritten und vierten Server hinzufügen, sollte die Kapazität dieses Systems im Wesentlichen verdoppelt werden, da Sie nun die doppelte Menge an Diensten haben. Also, das ist was NCache bietet auch.
Repliziert Daten für Zuverlässigkeit
Dann ist die Replikation ein weiteres Merkmal für die Zuverlässigkeit. Jeder Server, der ausfällt, sollte zuallererst keinen Datenverlust oder Ausfallzeiten haben. Es sollte ein hochverfügbares, hochzuverlässiges System sein und das ist was NCache kümmert sich um.
NCache Einsatz
Nachdem Sie dies besprochen haben, haben Sie ein Skalierbarkeitsproblem mit relationalen Datenquellen und verteilten Caching-Systemen wie NCache ist eine Lösung dafür und wird zur zentralen Ebene zwischen Ihren Anwendungen und der Datenbank, und Ihre Daten existieren an zwei Stellen.
Sie haben Daten in der Datenbank und dann Daten im verteilten Cache. Also dann NCache bewältigt auch einige Synchronisierungsherausforderungen, die auftreten können, wenn Sie Daten aus zwei verschiedenen Quellen haben. Es gibt ein separates Webinar zu diesem Thema, aber nur um Sie wissen zu lassen, dass es einige Anbieter von Datenzugriffsschichten gibt, gibt es einige Abhängigkeiten für Änderungsbenachrichtigungen, die Sie einrichten können.
Jede Änderung in der Datenbank kann also eine Invalidierung oder Aktualisierung von Elementen im Cache auslösen, und ebenso können alle Änderungen oder Aktualisierungen, die im Cache vorgenommen werden, auf die Datenbank angewendet werden. Dies kann also mit Hilfe unserer Datenzugriffsschichtanbieter erreicht werden; Durchlesen und Durchschreiben.
Und dann haben wir auch einige Datenbankänderungsabhängigkeiten, Datensatzänderungsabhängigkeiten, die wir tatsächlich verwendet haben, um eine 100%ige Synchronisierung zwischen der Datenbank und den Cache-Datensätzen sicherzustellen. Typischerweise existieren Daten jedoch an zwei verschiedenen Orten. Sie haben Daten im Cache, die normalerweise eine Teilmenge der Daten sind, und dann haben Sie tatsächliche Daten in der Datenbank. Wenn Sie Daten migrieren, handelt es sich im Wesentlichen um eine Datenmigration. Obwohl Sie diese beiden Quellen in Kombination miteinander verwenden, handelt es sich jedoch um zwei verschiedene Quellen.
Welche Daten zwischenspeichern?
Bevor wir fortfahren, sprechen wir kurz über Datentypen, die Sie zwischenspeichern können. Dies können Referenzdaten oder Transaktionsdaten sein.

Es handelt sich eher um leseintensive Daten, die Sie zwischenspeichern, normalerweise gehört sie in eine relationale Datenbank. Es ist nicht so, dass es sich nicht ändert, es ist nicht 100% statisch. Es ändert Daten, aber die Häufigkeit dieser Änderung ist nicht so groß. Das würde also als Referenzdaten kategorisiert werden. Und dann haben wir immer Transaktionsdaten, die sich sehr häufig ändern. So oft wie in wenigen Sekunden, wenigen Minuten oder in einigen Fällen in wenigen Millisekunden.
Und dann sind die meisten zwischengespeicherten Daten relational. Es stammt aus einer relationalen Datenbank, und ich habe bereits besprochen, dass Sie Daten der Masterkopie in der relationalen Datenbank haben und dann eine Teilmenge dieser Daten, eine Referenz und eine Transaktion, in den verteilten Cache bringen. Recht!
Was ist die Herausforderung?
Also, was ist die Herausforderung? Also, lasst uns diese Herausforderung tatsächlich besprechen! Wenn Sie Ihre Daten von einer Datenquelle in eine Relation in einen verteilten Cache verschieben, erreichen Sie mehr Leistung, mehr Skalierbarkeit und mehr Zuverlässigkeit des Systems. Lassen Sie uns einfach schnell diskutieren, was die Herausforderungen sind, die Sie sehen.

Es funktioniert sehr gut. Es verbessert Ihre Leistung, weil es im Gedächtnis ist. Es ist linear skalierbar und kümmert sich daher um Skalierbarkeitsprobleme mit der Datenbank. Es ist kein Single Point of Failure, da es mehrere Server gibt und jeder Server heruntergefahren werden kann. Sie können Server ohne Probleme hochfahren. Die Wartung wird viel einfacher. Ihre Upgrades werden viel einfacher. Im Vergleich erhalten Sie also viele Vorteile. Es gibt jedoch eine Herausforderung, die Sie angehen müssen, und Sie müssen dies berücksichtigen, wenn Sie Ihre Daten migrieren oder Ihre Daten von der Datenbank in den verteilten Cache verschieben und mit der Verwendung eines verteilten Caching-Systems beginnen.
Der verteilte Cache ist also eine hashtabellenähnliche Schnittstelle. Recht! Jedes Element wird durch den Schlüssel und einen Wert getrennt, richtig? Es handelt sich also um eine Hash-Tabelle, in der jedes Objekt im Cache oder jedes Element im Cache oder ein Datensatz im Cache mit Hilfe eines Schlüssels dargestellt wird. Es handelt sich also nicht um eine Tabelle oder um relationale Daten, bei denen wir Beziehungen haben, wir haben Schemata definiert, wir haben Entitäten, die untereinander richtige Beziehungen haben. Es wird ein separates Schlüsselwertelement sein, das ein Objekt im Cache darstellt. Die Datenbank hat also Beziehungen zwischen Entitäten, und wenn Sie Ihre Daten migrieren oder wenn Sie Ihre Daten von einer relationalen Datenbank in einen verteilten Cache verschieben, verlieren Sie diese für diese Daten charakteristische Beziehung.
Standardmäßig haben Sie diese Fähigkeit nicht, sodass wir dies entfernen können. Das ist eine der größten Herausforderungen, und dann gibt es noch einige andere damit verbundene Herausforderungen, bei denen Datenbankabfragen zu einer Sammlung von Objekten führen. Es führt auch zu einer Datentabelle oder einem Datenleser. Der Umgang mit Datentabellen und Datenlesern in einem verteilten Cache ist also keine gute Idee, oder? also werden wir alle diese Herausforderungen nacheinander durchgehen.
In erster Linie werden wir besprechen, wie Beziehungen im verteilten Cache verwaltet werden, nachdem Sie Daten aus einer relationalen Datenquelle in den Cache gebracht haben, wie Sie mit diesem Detail umgehen.
Guck in die NCache API
Als nächstes werden wir über die Caching-API sprechen.

Nun, da wir besprochen haben, dass es sich im Grunde um einen Schlüsselwertspeicher handelt. Wir haben eine cache.add, wo wir einen Schlüssel „mykey“ haben, und dann haben wir ein Objekt, das alle erlaubten Daten und erlaubten serialisierten Objekte sind. es könnte ein beliebiges Kundenobjekt, Produktobjekt, Auftragsobjekt sein. Aber dies ist ein sehr einfaches Hallo-Welt-Beispiel, bei dem wir Schlüsselwertmethoden mit cache.add, cache.update aufrufen. In ähnlicher Weise rufen wir cache.get auf, um dasselbe Element zurückzubekommen, und dann rufen wir cache.remove auf.
Beziehungen im Cache verwalten
Weiter gehts! Wie verwaltet man also Beziehungen im Cache? Nun, da wir diese Herausforderung definiert haben, dass der Cache eine Hash-Tabelle wie eine Schnittstelle ist, ist es ein Schlüssel-Wert-Paar. Wert ist ein .NET-Objekt und Schlüssel ist ein Zeichenfolgenschlüssel, den Sie formatieren, und dies sind voneinander unabhängige Objekte. Und die Datenbank hat Beziehungstabellen, die Beziehungen zueinander haben. Es könnte eine Eins-zu-Eins-Eins-zu-Viele- und eine Viele-zu-Viele-Beziehung zwischen verschiedenen Tabellen sein.
Erster Schritt: Cache-Abhängigkeit verwenden
Es gibt zwei Dinge, die Sie in Betracht ziehen sollten. Zunächst einmal sollten Sie die Cache-Abhängigkeit verwenden, und wir konzentrieren uns hauptsächlich auf die schlüsselbasierte Abhängigkeit, die eine der Funktionen ist, und ich werde Ihnen einige Codebeispiele dazu zeigen, die Ihnen helfen, a Verfolgung der einseitigen Abhängigkeit zwischen den Cache-Elementen.

Sie könnten also ein übergeordnetes Objekt haben und dann könnten Sie ein abhängiges Objekt von diesem bestimmten Objekt haben. Und es funktioniert so, dass ein Element von einem anderen abhängt. Das Hauptelement, das primäre Objekt oder das übergeordnete Objekt; Wenn es eine Änderung durchläuft, wird es aktualisiert oder entfernt. Das abhängige Element wird automatisch aus dem Cache entfernt.
Ein typisches Beispiel, das ich in den nächsten Folien aufgereiht habe, ist eine Liste mit Bestellungen für einen bestimmten Kunden. Sie haben also einen Kunden A. Er hat eine Liste mit Bestellungen, sagen wir 100 Bestellungen, was ist, wenn dieser Kunde aktualisiert oder aus dem Cache entfernt wird. Sie brauchen diese zugehörigen Bestellungen nicht, also möchten Sie vielleicht auch etwas um diese Bestellsammlung herum tun, und genau dafür ist diese Abhängigkeit da, dass Sie eine Verknüpfung zwischen diesen beiden Datensätzen haben müssen, da diese in in verwandt sind relationale Datenbank.
Dann kann diese Abhängigkeit auch in der Natur kaskadiert werden, wobei A von B abhängt und B von C abhängt. Jede Änderung von C würde eine Ungültigkeitserklärung von B auslösen, und das wiederum würde auch A ungültig machen. Es könnte sich also um eine kaskadierte Abhängigkeit und dann auch um eine Multi-Item-Abhängigkeit handeln. Ein Element kann sowohl von Element A als auch von Element B abhängig sein, und ebenso kann ein übergeordnetes Element mehrere untergeordnete Elemente haben. Und dies war eine Funktion, die ursprünglich vom ASP.NET-Cache eingeführt wurde. Es war eines der mächtigen Features, die NCache hat auch. Wir stellen es als separates Cache-Abhängigkeitsobjekt und eines der ausgefallenen Objekte bereit, und dies wird der Hauptfokus in diesem speziellen Webinar sein.
Zweiter Schritt: Verwenden Sie Object Relational Mapping
Im zweiten Schritt, um Ihre relationalen Daten abzubilden, gibt es eine weitere Herausforderung, die wir empfehlen, dass Sie Ihre Domänenobjekte tatsächlich auf Ihr Datenmodell abbilden sollten, richtig?

Ihre Domänenobjekte sollten also eine Datenbanktabelle darstellen. Sie sollten eine Art O/R-Mapping verwenden, Sie können auch einige O/R-Mapping-Tools verwenden. Es vereinfacht Ihre Programmierung. Sie können den Code wiederverwenden, sobald Sie Klassen auf Ihre Datenbanktabellen abgebildet haben. Sie können sogar die ORM- oder O/R-Mapping-Tools wie Entity Framework und NHibernate verwenden. Dies sind einige beliebte Tools.
Die Idee dabei ist, dass Sie Klassen in der Anwendung haben sollten. Die Objekte, die Domänenobjekte in der Anwendung. Ihre Datenbankobjekte, Datentabellen oder Datenleser werden also transformiert und auf die Domänenobjekte abgebildet. Eine Kundentabelle sollte also eine Kundenklasse in der Anwendung darstellen. In ähnlicher Weise sollte die geordnete Sammlung oder Auftragstabelle die Auftragsklasse und die Anwendung darstellen. Und das sind dann die Objekte, die Sie handhaben und in verteilten Caches speichern und Beziehungen mit Hilfe von Key Dependency formulieren.
Beispiel für den Umgang mit Beziehungen
Nehmen wir ein Beispiel!
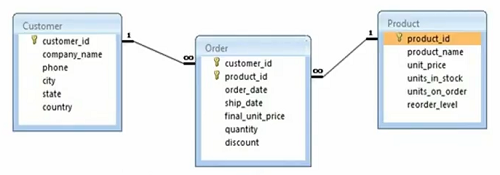
Und wir haben unser Datenbankmodell von Northwind. Wir haben eine Kundentabelle, wir haben eine Bestelltabelle und dann haben wir ein Produkt. Wir haben alle Spaltennamen des Kunden, wir haben Kunden-ID, Firmenname, Telefon, Stadt, Bundesland, Land, einige Attribute. Ebenso haben wir Produkte mit Produkt-ID, Name, Preis, Einheiten auf Lager, Einheiten auf Bestellung, Nachbestellmenge. Das sind also einige Attribute oder einige Spalten aus dem Produkt, und dann haben wir auch eine Bestelltabelle, die Kunden-ID und Produkt-ID als Fremdschlüssel enthält. Das ist die Formulierung eines zusammengesetzten Primärschlüssels, und dann haben wir das Bestelldatum, das Versanddatum und einige Attribute der Bestellungen selbst. Und wenn Sie das bemerken, gibt es eine Eins-zu-Viele-Beziehung zwischen Kunde und Bestellung und dann gibt es eine Eins-zu-Viele-Beziehung zwischen Produkt und Bestellung. In ähnlicher Weise haben wir viele-zu-eins und viele-zu-eins zwischen Bestellung und Kunde bzw. Bestellung und Produkt. Also werden wir dieses spezielle Szenario angehen.
Anfänglich war es eine Kundenprodukt-Viele-zu-Viele-Beziehung, die in zwei Eins-zu-Viele-Beziehungen normalisiert wurde. Dies ist also ein normalisiertes Datenmodell, und wir verwenden ein Beispiel dafür, bei dem wir eine Klasse im Hauptobjekt auf dieses bestimmte Datenmodell abgebildet haben. Also, wir werden gleich über das primäre Objekt sprechen, aber lassen Sie mich Ihnen kurz das Beispiel hier zeigen.
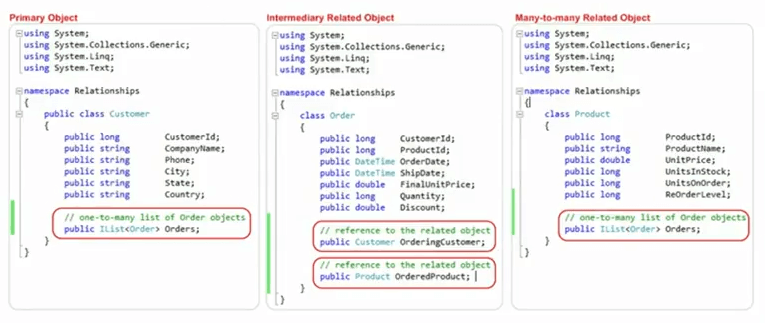
Beachten Sie, dass die Domänenobjekte unserem Datenbankmodell zugeordnet sind. Für dasselbe Beispiel haben wir eine Kundenklasse mit einer Kunden-ID, die als Primärschlüssel verwendet wird, und dann haben wir eine Sammlung von Bestellungen, die zu viele Beziehungen zur Bestellklasse darstellen. In ähnlicher Weise haben wir ein Produkt, das dieselben Produktattribute wie diese Produkt-ID, Name, Stückpreis hat, richtig? Und dann haben wir auch hier die Auftragserfassung, die eine Eins-zu-Viele-Beziehung darstellt, und auf der Auftragsseite haben wir die Kunden-ID, die von hier gebracht wird, die Produkt-ID, die von hier gebracht wird, und dann haben wir den bestellenden Kunden, den Kunden, der eine Viele-zu-Viele-Beziehung hat eine Beziehung und dann haben wir das Bestellen von Produkten so viele zu einer Beziehung, die als Teil des Domänenobjekts erfasst wird.
Dies ist also eine der Techniken, die ich in den kommenden Folien ausführlich behandeln werde. Lassen Sie mich Ihnen diese Objekte auch in Visual Studio zeigen, also ist dies eines der Klasse.
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.Runtime;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Alachisoft.NCache.Runtime.Dependencies;
using System.Collections;
namespace Relationships
{
public class Customer
{
public long CustomerId;
public string CompanyName;
public string Phone;
public string City;
public string State;
public string Country;
// one-to-many list of Order objects
public IList<Order> Orders;
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// Let's cache each product as seperate item. Later
// we'll search them through OQL
foreach (Product product in products)
{
string productKey = "Product:ProductId:" + product.ProductId;
cache.Add(productKey, product, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
cache.GetGroupData("DummyGroup", "DummySubGroup");
cache.GetByTag(new Alachisoft.NCache.Runtime.Caching.Tag("DummyTag"));
}
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string query = "SELECT Relationships.Product WHERE this.UnitPrice >= ?";
Hashtable values = new Hashtable();
values.Add("UnitPrice", unitPrice);
ICacheReader products = cache.ExecuteReader(query, values, true);
IList<Product> prodList = new List<Product>();
// For simplicity, assume that list is not very large
while (products.Read())
{
prodList.Add((Product)products.GetValue(1));// 1 because on 0 you'll get the Cache Key
}
return prodList;
}
}
}Eine Sache, die ich empfehlen würde, ist, dass Sie diese Klassen mit einem serialisierbaren Tag dekorieren, richtig? Sie müssen sie also zwischenspeichern, oder? Diese Domänenobjekte sollten also serialisiert werden, da sie zwischen Ihrer Clientanwendung und dem verteilten Cache hin und her reisen.
Wir haben also Kundenklasse, wir haben Produktklasse, genau hier. Eine Liste von Bestellungen und wir haben eine Bestellklasse, die alle Attribute hat, die auch auf der Präsentationsfolie gezeigt werden.
Was ist Primärobjekt?
Als nächstes werden wir über das primäre Objekt sprechen. Nun, da wir einige Hauptobjekte gezeigt haben, die auf diesem Domänendatenmodell abgebildet sind. Wir zeigen Ihnen einige Techniken, um Eins-zu-Eins-Eins-zu-Viele- und Viele-zu-Viele-Beziehungen durchzugehen.
Zunächst werde ich also über einen Begriff sprechen, den ich in den kommenden Folien verwenden werde.

Primäres Objekt, es ist ein Domänenobjekt. Es wird auf Ihre Datenbank abgebildet. Es ist ein Ausgangspunkt Ihrer Anwendung, zum Beispiel haben Sie ein Kundenobjekt und wenn Sie dann Bestellungen benötigen, brauchen Sie den Kunden, um zu beginnen, richtig? Es ist also das erste Objekt, das Ihre Anwendung abruft, und alle anderen Objekte, die damit in Beziehung stehen, werden damit in Beziehung gesetzt, richtig?
Ein weiteres Beispiel könnte sein, wenn Sie die Bestellungen richtig verarbeiten, also möchten Sie vielleicht Bestellungen in dieser Verarbeitungseinheit abrufen und dann möchten Sie wissen, welcher Kunde es bestellt hat, um diese bestimmte Bestellung zu versenden, richtig? In diesem Fall wird die Bestellung also zu Ihrem Hauptobjekt und hat dann eine Viele-zu-Eins-Beziehung oder eine Beziehung zu einem der Kunden, die diese bestimmte Bestellung oder alle Produkte in dieser Bestellung tatsächlich bestellt haben. Es wird also so oder so sein, aber wir geben an, dass wir ein primäres Objekt verwenden werden, das zwischengespeichert wird, und dann werden wir andere Objekte davon abhängig machen. Das ist der Ansatz, der folgen wird.
Beziehungen im verteilten Cache
Fangen wir also tatsächlich damit an. Also sprechen wir zunächst über Eins-zu-eins- und Viele-zu-eins-Beziehungen innerhalb des verteilten Caches, das ist das häufigste Szenario, richtig? Eine Möglichkeit besteht also darin, verwandte Objekte mit dem primären Objekt zwischenzuspeichern. Nachdem Sie nun unsere Domänenobjekte gesehen haben, haben wir eine Liste mit Bestellungen als Teil der Kunden. Also, wenn wir diese Bestellungen füllen und der Kunde diese Bestellungen als Teil davon hat, wenn Sie den Kunden als einzelnes Objekt im Cache speichern, das alle Bestellungen als Teil davon enthält, richtig? Damit wäre die Arbeit erledigt.
Verknüpftes Objekt mit primärem Objekt zwischenspeichern
Also, hier ist ein Codebeispiel dafür.
// cache order along with its OrderingCustomer and OrderedProduct
// but not the "Orders" collection in both of them
public void CacheOrder(Cache cache, Order order)
{
// We don't want to cache "Orders" from Customers and Product
order.OrderingCustomer.Orders = null;
order.OrderedProduct.Orders = null;
string orderKey = "Order:CustoimerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Wir haben eine Cache-Bestellung, wir setzen den bestellenden Kunden innerhalb der Bestellung auf „null“. Gut! Damit wir keine Bestellungen haben, die auch einen Kundenbezug haben. Es ist überflüssig. Dies ist keine sehr gute Programmierpraxis, aber dies dient nur der Durchsetzung. Wir wollen keine Cache-Bestellungen von Kunden- und Produkt-ID. Wir möchten also nur einen Kunden im Cache hinzufügen und dann möchten wir nur Bestellungen als Teil davon haben.
Schauen wir uns das also an, oder? Wir setzen dies also auf null und speichern es dann einfach, oder wenn wir es nicht auf null setzen, kann dies tatsächlich einen Verweis darauf haben. Ebenso, wenn wir einen Kunden haben, richtig? Wenn wir also die Bestellung nicht auf null setzen, obwohl dies ein separates Objekt ist, aber wenn wir diesen Kunden einfach speichern, lassen Sie mich Sie einfach dazu bringen, da es eine Liste von Bestellungen enthält, wenn wir diesen Kunden einfach als speichern einzelnes Objekt im Cache, es hat unsere Auftragssammlung als Teil dieses Objekts. Obwohl ich es für ein anderes Beispiel auf null setze, aber nur um Ihnen diesen speziellen Fall zu zeigen, können Sie ein großes Objekt sortieren und es hätte alle zugehörigen Objekte als Teil dieses Objekts.
Sie müssen also von Ihrem Domänenobjekt ausgehen, Sie sollten Ihre Beziehung als Teil des Domänenobjekts erfassen lassen, und Sie sollten dies unabhängig davon tun. Und danach sollten Sie zwischenspeichern, Sie sollten tatsächlich eine gefüllte Liste mit Bestellungen haben, eine Liste verwandter Objekte als Teil davon. Dies ist also der einfachste Ansatz, den Sie bekommen können.
Es gibt einige Vorteile davon, dass Sie ein Objekt haben, das alles repräsentiert. Aber es gibt auch einige Nachteile. Es wäre ein größeres Objekt in der Größe. In manchen Fällen brauchen Sie nur Kunden, aber Sie würden als Teil davon Aufträge erhalten. Sie werden es mit einer größeren Nutzlast zu tun haben. Und Sie haben keine granularen Bestellungen als separate Elemente im Cache, sodass Sie sich ständig mit der Sammlung von Bestellungen befassen müssten, obwohl Sie nur an einer interessiert sind, oder? Das ist also ein Ansatz. Das ist der Ausgangspunkt.
Zugehörige Objekte separat zwischenspeichern
Zweitens speichern Sie das gewichtete Objekt als separates Element im Cache.
public void CacheOrder(Cache cache, Order order)
{
Customer cust = order.OrderingCustomer;
// Set orders to null so it doesn't get cached with Customer
cust.Orders = null;
string custKey = "Customer:CUstomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures order is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
cache.Add(orderKey, order, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Ein Beispiel dafür ist die Order-Klasse, in der wir Cache-Order haben, richtig? Das ist also das Beispiel, wo wir einen Kunden haben. Zunächst einmal, oder? Und dann speichern wir den Kunden als ein einzelnes Objekt. Sie können sehen, dass wir die Bestellung erhalten haben, und dann haben wir aus der Bestellung den Kunden extrahiert, und dann haben wir die Auftragssammlung innerhalb dieses Kundenobjekts auf null gesetzt, richtig? Das sollten Sie also innerhalb des Konstruktors tun, aber das wird hier nur getan, um zu erzwingen, dass dieses Kundenobjekt diese Bestellung nicht als Teil davon hat. Und dann speichern Sie diesen Kunden als einzelnes Objekt. Was wir hier tun, ist, dass wir einen Kundenschlüssel erstellen, der Kunde, Kunden-ID, der Laufzeitparameter ist, und dann speichern wir unseren Kunden als einzelnes Objekt im Cache.
Als nächstes erstellen wir eine Cache-Abhängigkeit. Wir haben also über zwei Schritte gesprochen, die wir ausführen wollten. Ein Schritt war, dass Sie Ihr Datenmodell auf Ihr Domänenobjekt abbilden, sodass Ihre Domänenobjekte eine relationale Tabelle in der Datenbank darstellen sollten, und wenn Sie dann planen, diese zwischenzuspeichern, haben Sie ein primäres Objekt in diesem Fall ist es der Kunde, und dann haben wir Aufträge, die sich auf den Kunden in der Eins-zu-Viele-Beziehung beziehen. Mit Hilfe eines Cache-Abhängigkeitsobjekts erstellen Sie eine Abhängigkeit zwischen Kunde und Auftragserfassung. Sie erstellen eine Cache-Abhängigkeit. Dieselbe Cache-Abhängigkeit benötigt zwei Parameter; Das erste ist eine Datei, richtig? Es kann also vom Dateinamen abhängen und es kann auch vom Schlüssel abhängen, richtig? Also setzen wir den ersten Parameter auf null. Wir wollen also nicht, dass es von irgendwelchen Dateien abhängt.
Es gibt eine weitere Funktion, die innerhalb NCache wo Sie Elemente von einem bestimmten Dateisystem abhängig machen können einige Dateien in Ihrem Dateisystem. Und wenn Sie dann die schlüsselbasierte Abhängigkeit verwenden, benötigt sie den Schlüssel des übergeordneten Elements, von dem das untergeordnete Element abhängig gemacht werden soll. Und dann konstruieren wir den Bestellschlüssel der Sammlung der Bestellung. Wir haben hier die gesamte Auftragssammlung, die an diese Methode übergeben wird, und dann rufen wir einfach Cache.Add order auf.
Nun stehen Kunde und Auftrag in Beziehung zueinander. Wir haben eine Liste mit Bestellungen von diesem Kunden, die als separates Objekt im Cache dargestellt werden, sodass Sie immer dann, wenn Sie alle Bestellungen dieses bestimmten Kunden benötigen, nur diesen Schlüssel verwenden müssen. Alles, was Sie tun müssen, ist anzurufen, lassen Sie mich einfach dieses Beispiel hier verwenden. Es tut mir Leid! Sie können Cache.Get aufrufen und dann einfach den Bestellschlüssel weitergeben, und das würde Ihnen diese bestimmte Bestellung holen, die wir innerhalb dieser Methode erstellt haben, richtig?
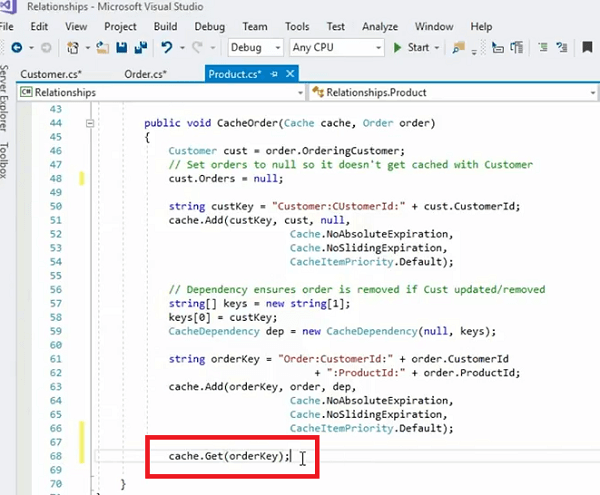
Das brauchen Sie also, um die gesamte Sammlung aller Bestellungen dieses bestimmten Kunden auf einmal abzurufen. Aber was ist, wenn der Kunde eine Veränderung durchmacht? Wenn der Kunde aktualisiert wird, muss die Auftragssammlung nicht im Cache bleiben. Es kann entweder entfernt oder in einigen Fällen auch aktualisiert werden, oder?
Das ist also unser Ansatz Nummer zwei, der in Bezug auf die Speicherung, in Bezug auf die Benutzerfreundlichkeit anspruchsvoller ist und auch zwei Datensätze in unserer Beziehung einer Eins-zu-Viele-Beziehung oder einer Viele-zu-Eins-Beziehung abbildet. Es könnte auch umgekehrt sein, was wir gleich behandeln werden, wo Sie Listen von Bestellungen haben können und jede Bestellung diesen einzelnen Bestellungen zugeordnet werden kann, können diesen mehreren ID-Bestellungen zugeordnet werden, wenn die Bestellung einem Kunden zugeordnet werden kann ist das primäre Objekt für diesen speziellen Anwendungscode. Dies definiert nun eine Beziehung zwischen Kunde und Aufträgen.
Ein paar weitere Details zur Cache-Abhängigkeitsfunktion.
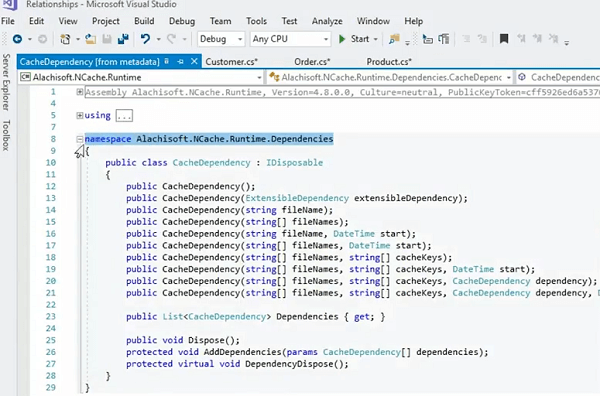
Wenn ich hierher gehe, wird es zunächst einmal ausgesetzt, aber mit Hilfe von Alachisoft.NCache.Runtime.Dependencies und dies ist eine der Überladungen, die Sie verwenden, und dann verwenden Sie einfach diese spezielle Methode hier. Und das Verhalten davon ist so, dass es Ihnen ermöglicht, die unidirektionale Abhängigkeit zwischen Objekten einfach zu verfolgen, und es könnte auch kaskadiert werden, wie zuvor in der Präsentation besprochen.
Eins-zu-viele-Beziehung
Als Nächstes sprechen wir über XNUMX:n-Beziehungen. Da wir über Eins-zu-Eins oder Viele-zu-Eins gesprochen haben, wo wir eine Bestellung hatten und dann einen Kunden hatten, ist dies in den meisten Fällen ähnlich wie Eins-zu-Viele, aber da es der Ausgangspunkt war, war die Bestellung und dann fügten wir ein der Kunde, speicherte den Kunden und dann speichern wir die Auftragssammlung und dann haben wir eine Viele-zu-Eins-Beziehung zwischen der Auftragssammlung und diesem Kunden definiert.

Nun, eine Eins-zu-Viele-Beziehung, das wird dem, was wir besprochen haben, sehr ähnlich sein. Unsere erste Option ist, dass Sie Ihre Objektsammlung als Teil des primären Objekts zwischenspeichern, also ist Kunde Ihr primäres Objekt, Bestellung sollte ein Teil davon sein.
Der zweite Punkt ist, dass Ihre verwandten Objekte separat zwischengespeichert werden, aber einzelne Elemente im Cache, richtig?
One to Many – Sammlung verwandter Objekte separat zwischenspeichernpublic void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
string orderskeys = "Customer:Orders:CustomerId:" + cust.CustomerId;
cache.Add(orderskeys, orders, dep,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}Das ist also eine getrennte Sammlung, wir haben Bestellungen, wir haben hier ein Kundenobjekt, eins zu vielen, und der Kunde hat Bestellungen, wir haben die Bestellungen daraus gesammelt, und dann setzen wir die Kundenbestellungen auf null, sodass der Kunde ein e ist Objekt, ein primäres Objekt, die Auftragserfassung ist ein separates Objekt, und dann speichern Sie den Kunden, speichern die Datencache-Abhängigkeit und speichern die Aufträge. Es wird also eine One-to-Many-Sammlung für die gesamte Sammlung sein.
One to Many – Jedes Objekt in der verwandten Sammlung separat zwischenspeichernDer zweite Ansatz ist, dass diese Sammlung auch aufgeschlüsselt werden kann.
public void CacheCustomer(Cache cache, Customer cust)
{
// Let's preserve "orders"
IList<Order> orders = cust.Orders;
// Let's now empty "orders" so it doesn't get cached with customer
cust.Orders = null;
string custKey = "Customer:CustomerId:" + cust.CustomerId;
cache.Add(custKey, cust, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
// Dependency ensures orders is removed if Cust updated/removed
string[] keys = new string[1];
keys[0] = custKey;
CacheDependency dep = new CacheDependency(null, keys);
// Let's cache each order as seperate item but assign it
// a group so we can fetch all orders for a given customer
foreach (Order order in orders)
{
string orderKey = "Order:CustomerId:" + order.CustomerId
+ ":ProductId:" + order.ProductId;
CacheItem cacheItem = new CacheItem(order);
cacheItem.Group = "Customer:CustomerId:" + cust.CustomerId;
cacheItem.Dependency = dep;
cache.Add(orderKey, cacheItem);
}
}Die Auftragssammlung kann separat sein, jeder Artikel innerhalb dieser Sammlung könnte ein separater Artikel im Cache sein. In diesem Fall würden wir also einfach den gleichen Ansatz verwenden. Wir erhalten die Kunden, erhalten die Bestellungen, speichern den Kunden, erstellen mithilfe der Schlüsselabhängigkeit eine Abhängigkeit dieses Kunden und durchlaufen dann alle Bestellungen.
Lassen Sie mich hier einfach die Cache-Kundenmethode durchgehen, weil sie hier intuitiver ist. Wir holen also die Auftragssammlung heraus, wir setzen die Kundenaufträge auf null, sodass es bei Kunden nur um Kunden geht, speichern den Kunden im Cache mit Cache.Füge Schlüssel hinzu, konstruierte eine Cache-Abhängigkeit um diesen einen bestimmten Schlüssel des Kunden und dann iterieren wir einfach durch. Hier ist eine Schleife. Wir sollten es tatsächlich iterieren, und das ist tatsächlich besser, wir iterieren es und speichern es dann einfach sofort als einzelne Elemente im Cache, sodass die Bestellung ihren eigenen Schlüssel hat, da jede Bestellung ein separates Element im Cache ist. Und eine andere Sache, die wir getan haben, ist, dass wir diese, die wir Cache-Elemente nennen, tatsächlich gruppiert haben, und die Kunden-ID ist auch eine Gruppe. Wir verwalten also tatsächlich auch eine Sammlung im Cache.
Lassen Sie mich sehen, ob ich ... da haben Sie, zum Beispiel, wir haben das hier. Wir könnten diese Produkte tatsächlich zwischenspeichern, das ist übrigens ein weiteres Beispiel, wo wir die gesamte Produktsammlung durchlaufen und dann einzeln gespeichert und dann tatsächlich alles in einer Gruppe zusammengefasst haben, richtig?
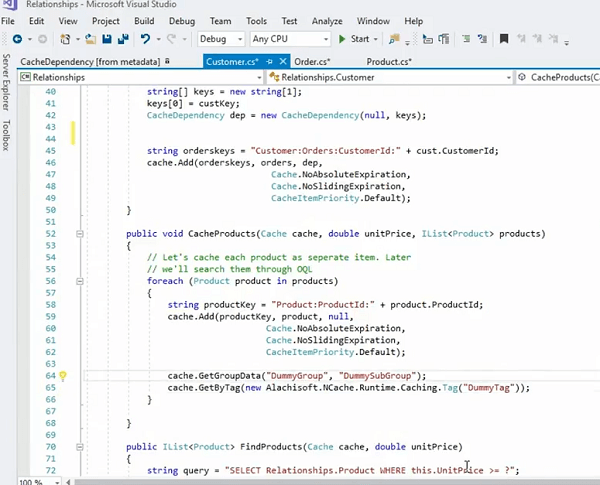
Dieses Produkt, das als Artikel gespeichert wird, kann also auch so gespeichert werden, wo wir ein ProdCacheItem haben. Meine Tastatur spielt, also bitte haben Sie Geduld mit mir! Lassen Sie uns das jetzt einfach verwenden und dann werde ich es einfach tun. Ich kann tatsächlich eine Gruppe hinzufügen. Also, dies hier würde mir tatsächlich erlauben, eine Gruppe dafür einzurichten. Sagen wir jetzt Dummy-Gruppe. Wenn ich diesen Cache-Artikel speichere und er tatsächlich ein Produkt als Artikel dafür haben könnte, richtig? Anstatt das eigentliche Rohobjekt zu speichern, kann ich es sogar in einer Gruppe anordnen. Ich kann einfach das Produkt-Cache-Element verwenden. Los geht's! Recht? Also, jetzt ist es tatsächlich oder anstatt die Dummy-Gruppe zu verwenden, sagen wir, Produktgruppe richtig, und wenn ich diese abrufen muss, kann ich einfach Produktgruppe verwenden, und es würde mir alle Artikel dieser Sammlung auf einmal abrufen. Obwohl diese einzeln gespeichert werden, handelt es sich um individuelle Caches. Einzelne Produkte innerhalb der Produktsammlung werden einzeln sortiert, aber ich kann sie in einer Gruppe in einer Sammlung anordnen und dann abrufen. Aber das Schöne daran ist, dass es immer noch eine Abhängigkeit verwendet, oder? Es wird also eine Abhängigkeit eines Kunden von diesen einzelnen Artikeln verwendet.
Nehmen wir also ein Beispiel: Wir haben einen Kunden mit hundert Bestellungen. Insgesamt hätten wir also einen Artikel für den Kunden im Cache, wir hätten hundert Bestellungen separat als hundert Artikel im Cache gespeichert, und es besteht eine einseitige Abhängigkeit zwischen diesem einen Kunden und hundert Bestellungen. Wenn Sie diesen einen Kunden aus dem Cache entfernen, werden hundert Bestellungen auf einmal ungültig. Und jetzt haben Sie den Vorteil, dass Sie bei Bedarf einzelne Bestellungen abrufen können. Sie können also mit diesen Elementen einzeln interagieren. Ein Artikel nach dem anderen. Sie benötigen eine bestimmte Bestellung, die Sie verarbeiten können, und wenn Sie die gesamte Sammlung dieser Bestellungen auf einmal benötigen, können Sie einfach Cache.GetGroupData aufrufen und die Produktgruppe und dann die Untergruppe angeben, die alles sein kann. Es könnte sogar null sein und dann können Sie auch das Tag verwenden.
Zum Beispiel; Die andere Möglichkeit, dies zu verwalten, besteht darin, dass Sie das Produktelement verwenden und ein Tag dafür erstellen, richtig? Und dann hast du... da ist ein... ja! Da ist es und Sie können ein Tag bereitstellen, das so etwas wie ein Produkt-Tag sein kann, richtig? und dann können Sie dies als Teil davon assoziieren.
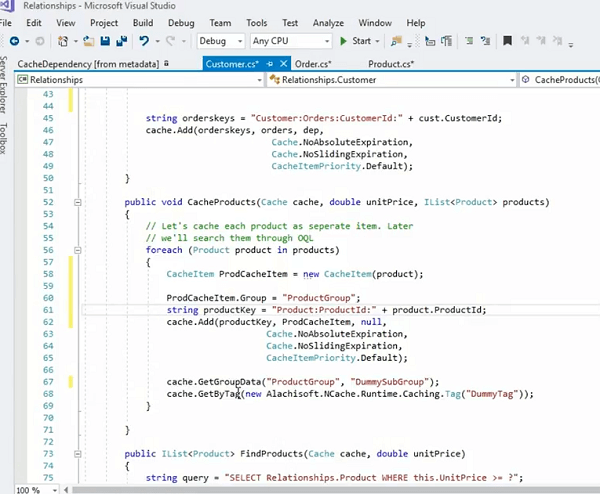
Dies würde also tatsächlich auf die gleiche Weise funktionieren, und Sie können auch get by tag-Methoden aufrufen, und das würde sich um alle Elemente auf einmal kümmern. Es würde Ihnen alle Gegenstände auf einmal bringen. Dies würde Ihnen also mehr Kontrolle über Ihre Anordnung der Daten im Cache geben und dann immer noch eine Eins-zu-Viele-Beziehung intakt halten.
Dies kümmert sich also um ein ganz bestimmtes Szenario, in dem wir eine Eins-zu-Viele-Beziehung haben und ein Objekt hinzugefügt haben und dann diese Elemente auf der vielen Seite haben, die diese Sammlung einzeln speichert. Elemente aus dieser Sammlung werden einzeln im Cache gespeichert und dann Sie haben immer noch eine Abhängigkeit und dann haben Sie immer noch ein Sammlungsverhalten dafür mit diesen verwandten Elementen. Diese Gegenstände sind also miteinander verbunden, sie bilden eine Sammlung und dann haben sie unsere Beziehung zu einem anderen Objekt in einer Eins-zu-Viele-Formulierung. Dieses Code-Snippet, eine sehr einfache, intuitive API, kümmert sich also um all diese Szenarien. Sie haben eine Eins-zu-Viele-Beziehung, die mit Hilfe der Schlüsselabhängigkeit erfasst wird. Sie haben diese Elemente zwar einzeln im Cache angeordnet, aber Sie haben sie immer noch in einer logischen Sammlung von Gruppen oder Tags abgelegt, und wenn Sie diese Elemente dann einzeln benötigen, rufen Sie cache start get auf, richtig?
Eine Möglichkeit, dieses Element zu erhalten, besteht also darin, Cache.Get aufzurufen, richtig? und verwenden Sie den Schlüssel, der hier der Produktschlüssel ist, richtig? Das würde Ihnen also dieses bestimmte Produkt bringen, das mit diesem bestimmten Schlüssel gespeichert wird, richtig? Und die andere Option ist, dass Sie alle Elemente in dieser Sammlung auf einmal benötigen, damit Sie Cache.GetGroupData verwenden können. So kann es Ihnen ein Sammelverhalten geben und Ihnen gleichzeitig auch die Verwaltung dieser verwandten Elemente ermöglichen.
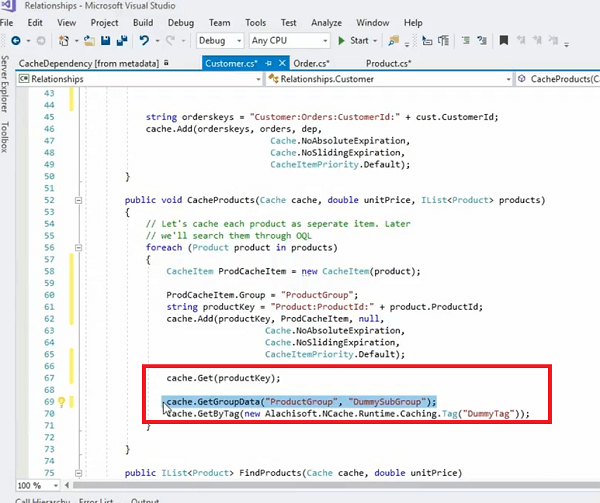
Das sollte sich also um Sammlungen und Elemente innerhalb der Sammlung kümmern, und zwar Eins-zu-Viele auf einmal.
Many-to-Many-Beziehungen
Als nächstes haben wir eine Viele-zu-Viele-Beziehung.

Viele-zu-viele-Beziehungen existieren normalerweise nicht in den Domänenobjekten. Es wird auch in der Datenbank immer in zwei Eins-zu-viele-Beziehungen normalisiert. Tatsächlich hatten wir eine Viele-zu-Viele-Beziehung zwischen Kunden und Produkten. Viele-zu-viele-Beziehungen, die wir mit Hilfe eines Zwischenobjekts in zwei Eins-zu-viele-Beziehungen normalisiert haben. Wir haben hier also One-to-Many und hier Many-to-One zwischen Kundenbestellung und Bestellung zum Produkt. So würden Sie also mit Many-to-Many umgehen. Es würde also entweder Eins-zu-Eins-Viele-zu-Eins- oder Eins-zu-Viele-Beziehungen verwenden.
Dies sollte sich also um Ihre Viele-zu-viele-Beziehungen kümmern.
Umgang mit Sammlungen im verteilten Cache
Als nächstes haben Sie eine Sammlung, wir haben dies bereits anhand unseres Produktbeispiels angesprochen, aber ich werde trotzdem darauf eingehen, dass Sie unsere Sammlung als ein Element zwischenspeichern.

Beispielsweise lagern Sie das Produkt. Lass es uns durchgehen, oder?
public void CacheProducts(Cache cache, double unitPrice, IList<Product> products)
{
// cache the entire collection as one item
string productskey = "Product:UnitPrice:" + unitPrice;
cache.Add(productskey, products, null,
Cache.NoAbsoluteExpiration,
Cache.NoSlidingExpiration,
CacheItemPriority.Default);
}
public IList<Product> FindProducts(Cache cache, double unitPrice)
{
string productskey = "Product:UnitPrice:" + unitPrice;
IList<Product> products = (IList<Product>)cache.Get(productskey);
return products;
}Sie haben also Cache-Produkte, also erstellen Sie einen Produktschlüssel und dann haben Sie eine Liste von Produkten, die hierher gebracht werden, und dann cachen Sie sie und haben ein einzelnes Objekt. Und, wie ich bereits erklärt habe, es wird funktionieren, es würde Ihnen nur die Arbeit erledigen, und es würde meistens funktionieren, wenn Sie alle Elemente aus dieser Liste auf einmal benötigen. Sie sind nicht an einzelnen Artikeln aus dieser Liste interessiert. Sie interessieren sich also für den gesamten Laden, die gesamte Liste als ein Element, aber es würde das Objekt schwerer machen, es würde Ihnen keine Unterstützung beim Codieren, Suchen geben, und das ist unser nächstes Thema. Da es sich um eine generische Liste handelt, liste ich auf, es enthält jedoch ein Produkt für NCache Dies ist nur eine Liste, ich liste auf. Recht! Sie sind also nicht in der Lage, das Objekt innerhalb dieser Liste und dann Attribute zu lokalisieren, und dann haben Sie nicht die Möglichkeit, basierend auf diesen Attributen zu suchen.
Eine ausgefeiltere Art, dies zu handhaben, besteht also darin, jedes Sammlungselement separat zwischenzuspeichern. Das haben wir als Teil unseres früheren Beispiels behandelt, aber gehen wir es noch einmal durch. Zum Beispiel; Gehen wir Cache-Produkte noch einmal durch und speichern Sie sie einfach als einzelne Artikel. Lassen Sie mich dieses Beispiel für Sie finden! IN ORDNUNG! Da ist es.
Also werden wir die Produkte zunächst einmal einzeln lagern, richtig? Wir werden einen Schlüssel für einzelne Produkte darum herum konstruieren lassen. Das Schöne daran ist, dass alle einzelnen Elemente der Produktsammlung als einzelne Elemente im Cache gespeichert werden, sodass Sie sie mit dem Schlüssel abrufen können, der die Überladung dafür darstellt, der Methode für diesen Cache.Get. Sie können sie auch als Sammlung abrufen. Das ist etwas, was wir ausführlich besprochen haben. Eine andere Möglichkeit besteht darin, dass Sie auch Abfragen ausführen und diese SQL-ähnlichen Suchabfragen direkt auf die Attribute der Objekte anwenden können. Und das ist nur möglich, wenn Sie sie einzeln gespeichert haben. Alle Artikel innerhalb der Sammlung werden als einzelne Artikel gespeichert. Sie ordnen sie einem Domänenobjekt zu, in diesem Fall Produkt, und die Produkte innerhalb einer Produktsammlung werden einzeln als separate Elemente im Cache gespeichert.
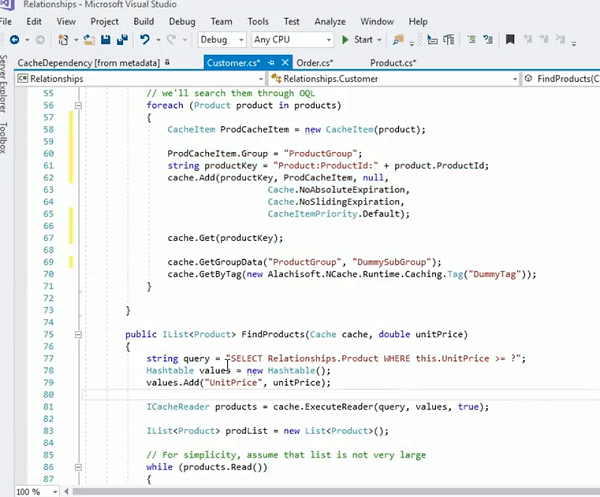
Jetzt können Sie den Einzelpreis des Produkts und die Produkt-ID indizieren und dann eine Abfrage wie diese ausführen. Produkt auswählen, das ist der Namensraum des Produkts, wobei der Einheitspreis einem Laufzeitparameter entspricht. Und dann können Sie Cache.ExecuteReader aufrufen, und das würde Ihnen alle Produkte abrufen, die Sie durchlaufen und auch in Ihrer Anwendung abrufen können. Ebenso können Sie auch sagen, wo This.Tag. Wenn Sie darüber ein Tag verknüpft haben, können Sie auch Abfragen darauf ausführen. Das ist ein weiterer Vorteil von Tags neben Abrufvorteilen und Leistungsvorteilen, es gibt Ihnen auch Flexibilität in Bezug auf die Suche. Und Tags geben Ihnen auch Cache.Get von einem Tag. Es gibt Ihnen alle APIs, holen Sie sich alle Tags, holen Sie sich alle Tags, sodass Sie Objekte auch mit diesen Tag-APIs abrufen können. Aber das Feature, das ich hervorheben wollte, ist, dass Sie sie individuell anordnen. Das ist der Ausgangspunkt. Sie erstellen logische Sammlungen mithilfe von Tags oder Gruppen. So ist das Abrufen einfacher. Sie benötigen einzelne Elemente, die Sie Cache.Get nennen. Holen Sie sich die Artikel basierend auf dem Schlüssel. Sie benötigen Sammlungen, verwenden Sie die Gruppe oder das Tag, das angezeigt wird, und darüber hinaus können Sie Abfragen ausführen und zuordnen, Sie können unsere Artikel tatsächlich anhand eines Kriteriums abrufen.
In diesem Fall könnte es sich um den Stückpreis handeln. Es könnte ein Stückpreis von mehr als 10 und weniger als XNUMX sein. Logische Operatoren werden also unterstützt, Sie könnten auch eine gewisse Aggregation haben, zählen, summieren, es gibt eine gewisse Sortierreihenfolge nach einer Gruppe nach ähnlichen Operatoren, also ist es ziemlich aufregend, umfangreich, was die Unterstützung betrifft, es ist ähnlich wie SQL, es ist eine Teilmenge davon SQL-Abfragen, aber es ist sehr flexibel in der Verwendung und erleichtert Ihnen die Verwendung in Bezug auf die Elemente, die Sie benötigen. Sie müssen nicht mehr mit Schlüsseln arbeiten. Das würde also nur passieren, wenn Sie einfach jedes Sammlungselement separat im Cache speichern. Ich hoffe das hilft.
Anfangen mit NCache
Damit ist unser heutiges Thema abgeschlossen. Gegen Ende zeige ich Ihnen nur fünf einfache Schritte für den Einstieg NCache einfach vorbei gehen NCache Konfigurationen und können diese APIs dann in einer realen Anwendung ausführen.
Okay! Also werde ich schnell damit anfangen. Ich habe das Verwaltungstool geöffnet. Übrigens, wir haben kürzlich veröffentlicht, eigentlich haben wir gerade 4.9 veröffentlicht. Das ist also unsere neueste Version, vielleicht möchten Sie damit anfangen. Alles, was Sie tun müssen, ist, einen Cache zu erstellen, nach Namen zu wählen, als nächstes zu wählen, eine Caching-Topologie auszuwählen, den Replikat-Cache zu partitionieren, der am besten geeignet ist, eine asynchrone Option für die Replikation, und hier geben Sie die Server an, die diesen Cache hosten werden. Demo eins und zwei habe ich bereits mit installiert NCache.
Schritt eins ist also das Herunterladen und Installieren NCache. Schritt zwei besteht darin, einen benannten Cache zu erstellen. Also, ich werde es durchgehen, alles auf Standard belassen, weil das heute nicht der Hauptbereich der Diskussion ist. Ich werde nur die Standardwerte und die Größe des Caches durchgehen, der sich auf jedem Server befindet. Richten Sie einfach die Grundeinstellungen ein und wählen Sie „Fertig stellen“.
Schritt drei besteht darin, dass Sie einen Client-Knoten hinzufügen. Ich werde nur meine Maschine benutzen. Sehen Sie, ob ich Zugriff darauf habe, ja! Gut! Das ist also meine Maschine hier. Ich habe das hinzugefügt, damit Schritt drei abgeschlossen ist. Alle Konfigurationen auf dem Server und im Client sind abgeschlossen. Ich muss diesen Cache-Cluster jetzt als Teil meines Schritts 4 starten und testen, dann werde ich dies überprüfen und dann in der tatsächlichen Anwendung verwenden. So einfach ist der Einstieg also NCache.
Ich zeige Ihnen einige schnelle Zähler, um Ihnen die Dinge in Aktion zu zeigen, und dann schließen wir die Präsentation auch schnell ab. Ich klicke mit der rechten Maustaste und wähle Statistiken aus, die Leistungsindikatoren öffnen würden, und ich kann auch Überwachungstools öffnen, was ist NCache Monitor, wird mit installiert NCache.
Es ist also leistungszählergesteuert. Es gibt Ihnen serverseitige Leistungsindikatoren und auch clientseitige Leistungsindikatoren. Und auf der Client-Anwendungsseite kann ich diese Stresstest-Tool-Anwendung ausführen, die wiederum mit installiert wird NCache. Es nimmt den Namen an, da Konfigurationen vorgenommen wurden, sodass es automatisch eine Verbindung zum Cache herstellt und mit der Simulation der Last auf meinem Cache-Cluster beginnt. Los geht's! Wir haben also eine Anforderungslast, die sowohl hier als auch auf dem anderen Server ankommt.
In ähnlicher Weise werden Aktivitäten auf diesem Server sowie auf Clients angezeigt, die mit Report Viewer-Server und -Client verbunden sind. Und dann können Sie auch Ihre eigenen benutzerdefinierten Dashboards haben, in die Sie jeden dieser Zähler einfügen können. API-Protokolle sind beispielsweise ein gutes Beispiel. Es protokolliert alle Anfragen, die gerade auf dem Cache ausgeführt werden, in Echtzeit, richtig?
Das ist also ein kurzes Beispiel für die Verwendung dieser Zähler aus dem linken Hauptbereich. Wie gesagt, dies soll Ihnen nur ein Gefühl dafür geben, wie das Caching aussieht. Jetzt kann ich dies tatsächlich in einer realen Anwendung verwenden. Ich kann meine Maschine direkt hier verwenden und ich kann einfach das grundlegende Betriebsbeispiel verwenden, das mit installiert wird NCache. Alles, was Sie tun müssen, ist, dass es verschiedene Nadelordner in den Beispielen für grundlegende .NET-Operationen gibt, soweit Sie sie verwenden können NCache clientseitige Bibliotheken, die Sie verwenden können NCache SDK-NuGet-Paket. Das ist am einfachsten, um alle clientseitigen Ressourcen zu erhalten.
Die andere Option ist, dass Sie tatsächlich verwenden Alachisoft.NCache.Laufzeit und Alachisoft.NCache.Web-Bibliotheken selbst. Diese gehören zu Ihnen. Dies sind etwas, das sind die Bibliotheken, mit denen Sie beginnen NCache in Microsoft Cache-Ordnern. Sobald Sie installieren NCache es wäre ein Teil davon und danach werde ich Ihnen schnell zeigen, was Sie tun müssen. Los geht's! Als erstes müssen Sie also Verweise auf diese beiden Bibliotheken hinzufügen. Runtime und Web, enthalten diese Namespaces, die ich gerade hervorgehoben habe. Web.caching und von diesem Punkt an ist dieses Beispiel ziemlich gut genug, um den Cache, der eine Verbindung herstellt, grundlegend zu initialisieren, ein Objekt zu erstellen, das es liest, es zu löschen, es zu aktualisieren und alle Arten von Erstellungs-, Lese-, Aktualisierungs- und Löschvorgängen zu aktualisieren.
So initialisieren Sie also den Cache. Das ist der Hauptanruf, richtig? Es muss der Cache-Name einen Cache-Handle zurückgeben und dann einfach Cache aufrufen oder hinzufügen, alles in einem Schlüssel-Wert-Paar Cache.Get-Elemente speichern und dann Elemente aktualisieren, cachen oder einfügen und dann Cache.delete. Und wir haben Ihnen bereits einige detaillierte Beispiele für die Verwendung von schlüsselbasierter Abhängigkeit unter Verwendung von Tags unter Verwendung von Gruppen unter Verwendung von SQL-ähnlicher Suche gezeigt. Dies sollte Ihnen also tatsächlich einige Details zum Einrichten der Umgebung geben und Sie dann in der Lage sein, sie in einer tatsächlichen Anwendung zu verwenden.
Damit schließen wir unsere Präsentation ab.