WAN-Replikation für die Bereitstellung in mehreren Rechenzentren von NCache
Aufgezeichnetes Webinar
Von Ron Hussain und Zack Khan
In diesem Webinar erfahren Sie alles, was Sie über das wissen müssen NCache Bridge-Funktion für die WAN-Replikation des Caches über Rechenzentren hinweg.
Folgendes wird in diesem Webinar behandelt:
- NCache's Bridge-Funktion für die WAN-Replikation
- NCache Brückentopologie (Aktiv-Aktiv, Aktiv-Passiv, 3+ Aktiv-Aktiv-Rechenzentren)
- Erweiterte Bridge-Funktionen:
- Überbrücken Sie Hochverfügbarkeit und Failover
- Dynamischer Konfliktlöser
- Parallele und asynchrone Massenreplikation
- Warteschlangenoptimierung
- Warteschlangenfunktion für Multi-Site-Sitzungen
- Bridge-Leistungs-/Debugging-Überwachungsoptionen
Das heutige Webinar-Thema lautet WAN-Replikation für eine Bereitstellung mit mehreren Rechenzentren NCache. Im heutigen Webinar gehen wir darauf ein NCacheBridge-Funktion von . Was auch dazugehört NCache's Bridge-Topologie, die erweiterten Bridge-Funktionen NCache hat, Multi-Site-Sitzungen in die Warteschlange stellen, sowie Bridge-Performance- und Debugging-Überwachungsoptionen.
Heute haben wir uns ein sehr wichtiges Thema vorgenommen. Insbesondere für Anwendungen, die in mehreren Rechenzentren bereitgestellt werden. Diese können verschiedene Gründe haben. Sie benötigen beispielsweise einen DR-Standort, Sie benötigen eine Aktiv-Aktiv-Bereitstellung mehrerer Rechenzentren oder es könnte eine Ost-West-Migration von Daten erforderlich sein.
Wir haben also eine WAN-Replikationsfunktion verfügbar, mit Hilfe unserer Bridge-Topologie und ich werde alle Details behandeln. So verwenden Sie das Objekt-Caching, während die WAN-Replikation aktiviert ist. Verwenden Sie es für Aktiv-Passiv-, Aktiv-Aktiv- und mehrere Aktiv-Aktiv-Rechenzentrumsbereitstellungen. Wir haben also viel abzudecken. Ich glaube, jeder kann meinen Bildschirm sehen und mich gut hören. Wenn ich schnelle Bestätigungen über die Registerkarte "Fragen und Antworten" von GoTo Meeting erhalten kann, wäre das wirklich gut, und dann können wir schnell mit der Präsentation beginnen. Bitte bestätigen Sie also, ob jeder unseren Bildschirm sehen kann und hier ohne Probleme funktioniert.
Einführung in die NCache
Ich beginne also mit den sehr grundlegenden Informationen darüber, warum Sie ein verteiltes Caching-System wie benötigen NCache? In der Regel ist es also der Engpass bei der Anwendungsleistung und Skalierbarkeit, der das Problem verursacht, das Ihre Anwendungen daran hindert, schneller und dann zuverlässiger zu arbeiten.
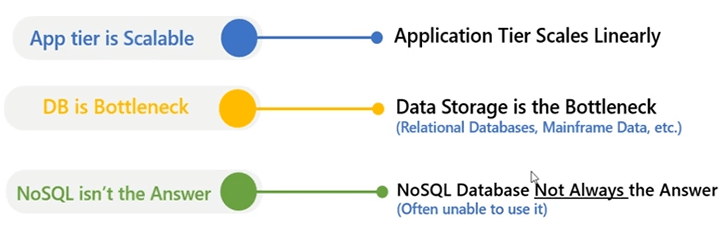
Ihre Anwendungsebene ist sehr skalierbar. Sie können eine Webanwendung oder eine Backend-Anwendung haben. Sie können jederzeit eine Webfarm oder Anwendungsserverfarm erstellen, in der Ihre Anwendung auf mehreren Servern bereitgestellt werden kann. Ihre Last kann verteilt werden. Mehrere Server helfen dabei, all diese Anwendungsanforderungen parallel und in Kombination miteinander zu bedienen, aber alle diese Anwendungen müssen mit einer Backend-Datenbank kommunizieren, und das ist normalerweise eine Quelle von Konflikten. Die Datenbank wird zu einem Leistungs- und Skalierbarkeitsengpass für Ihre Anwendung, da Sie Datenbankserver und ihre sehr teuren Ressourcen nicht skalieren können. Sie können also jederzeit hochskalieren, aber es gibt eine Grenze dafür, wie weit Sie einen Datenbankserver hochskalieren können? NoSQL ist normalerweise nicht die Antwort darauf, da Sie Ihre Anwendung neu strukturieren müssen. Sie müssen die Verwendung unserer relationalen Datenbank einstellen und mit der Verwendung von a beginnen NoSQL Datenquelle, um diese zu verwenden, und wir haben auch ein Produkt namens NosDB das ein NoSQL database aber wir projizieren einen anderen Weg, dies zu handhaben, und zwar durch ein verteiltes Caching-System.
Zunächst einmal ist die Lösung dieses Skalierbarkeitsproblems sehr einfach, indem Sie beginnen, ein verteiltes In-Memory-Caching-System zu verwenden. Es ist superschnell, weil es sich im Vergleich zur Festplatte im Speicher befindet. Die Leistung Ihrer Anwendung wird also sofort verbessert, sobald Sie ein Plug-in durchführen NCache.
Zweitens ist es ein Team von Servern. Es ist ein Cache-Cluster. Es ist nicht nur eine einzelne Quelle wie eine Datenbank. Sie haben mehrere Server, die einem Cache-Cluster beigetreten sind. Es ist also ein logischer Speicher, der von vielen Servern gepoolt wird, die Sie hinzufügen können. Dadurch ist es im Vergleich zu Ihren relationalen Datenbanken sehr skalierbar. Sie können mit 2 Servern beginnen und zur Laufzeit weitere Server hinzufügen. Es wird also immer skalierbarer und tatsächlich linear skalierbar, wobei Sie mehr Server hinzufügen können und dadurch Ihre Kapazität zur Bearbeitung von Anfragen weiter erhöhen NCache. Schöne Sache dabei NCache besteht darin, dass Sie neben einer Backend-Datenbank auch eine relationale Datenbank verwenden. Es gibt viele Funktionen, die Ihre Verwendung von Daten ergänzen, die aus einer Backend-Datenbank stammen. Kannst du also immer verwenden NCache in Verbindung mit Ihrer relationalen Datenbank. Es ist kein Ersatz für Ihre relationalen Datenquellen. Einige Skalierbarkeitszahlen.
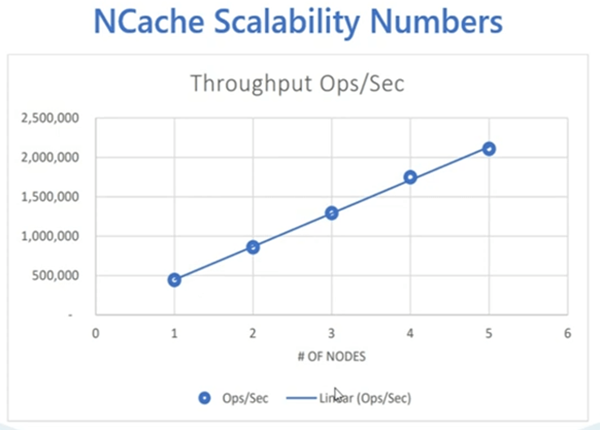
NCache ist sehr skalierbar, wenn Sie weitere Server hinzufügen NCache ermöglicht es Ihnen, immer mehr Anfragen aus zu bearbeiten NCache Cluster. Wir haben diese Tests kürzlich in unserer QA-Umgebung durchgeführt. Wir nutzen unser AWS-Labor, in dem wir die Auslastung weiter erhöht und auch immer mehr Server und bis zu 5 hinzugefügt haben NCache Server, was eine sehr regelmäßige Konfiguration für unseren verteilten Cache ist. Wir konnten 2 Millionen Anfragen pro Sekunde erreichen, und das war ein steigender Trend, bei dem wir, wenn wir mehr Server hinzufügten, dem Cache-Cluster mehr Kapazität hinzufügten. Bei einer durchschnittlichen Objektgröße von 1 Kilobyte ist das auch die Leistung, die Sie erwarten können NCache und mit besserer Hardware können Sie diese Zahlen sogar erweitern und einen besseren Leistungsdurchsatz erzielen NCache. Übrigens diese Benchmarks gibt es a Whitepaper und einem Video Demonstration auch auf unserer Website veröffentlicht. Also auch das kann man sich mal anschauen.
Einige Bereitstellungsdetails. Wie würde eine typische Bereitstellung von NCache wird aussehen.
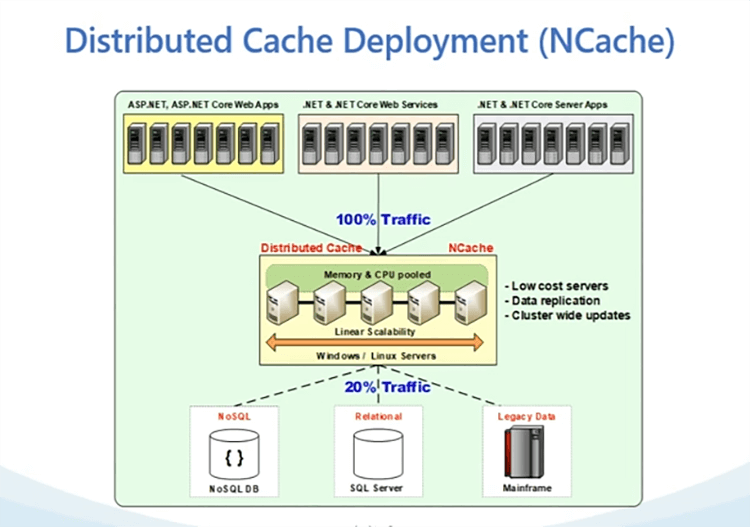
Hier ist eine Single-Site-Bereitstellung von NCache. Wie Sie sehen können, haben wir einen einzigen Standort und in Ihrem Fall, was wir über den WAN-Replikationsaspekt sprechen, hätten wir offensichtlich mehr als eine Bereitstellung, wir hätten ein separates Rechenzentrum, wo wir auch hätten NCache und bereitgestellte Anwendungen.
Lassen Sie uns also mit unserer verteilten Cache-Bereitstellung, wie im Diagramm gezeigt, darüber sprechen, wie eine typische Bereitstellung aussieht. Wir haben also wieder ein Team von Servern. Das Diagramm zeigt 4 bis 5 Server, auf denen Ihr Cache-Cluster gehostet wird, und wie Sie sehen können, befindet er sich zwischen Ihrer Anwendung und Ihrer Datenbank. Die Idee dabei ist, dass Sie diese Quellen in Kombination miteinander verwenden, für das Objekt-Caching, aber für das Session-Caching wird der Cache Ihre Hauptdatenquelle. So können alle Ihre Sitzungen in gespeichert werden NCache und Sie müssen nirgendwo anders hingehen. Ein sehr flexibles Bereitstellungsmodell ist verfügbar. NCache kann vor Ort gehostet werden. Dies können physische oder virtuelle Boxen sein. Es könnte auch in der Cloud sein. Es kann sich um eine Public oder Private Cloud handeln. Es könnte sich auch um Azure AWS handeln, da wir Marketplace-Images für diese beiden Cloud-Anbieter zur Verfügung haben. Aber im Allgemeinen jeder Server, der Windows oder Linux hat und nur Voraussetzung dafür ist NCache ist .NET bzw .NET Core Rahmen. Das sind also Vorraussetzungen. Es ist nur .NET und .NET Core welche NCache braucht als Voraussetzung Wenn das verfügbar ist, NCache ist sehr flexibel, um sowohl auf Windows- als auch auf Linux-Umgebungen bereitgestellt zu werden, und wie gesagt, es könnte auch jede Umgebung sein, es könnte sein, Sie können Docker verwenden und Sie können auch hosten NCache im Kubernetes-Cluster und das eröffnet viele andere Plattformen. Sie können es in OpenShift verwenden. Sie können es im Azure Kubernetes-Dienst verwenden. Sie wissen schon, der Elastic Kubernetes-Service. Also, all diese Plattformen sind ausgestattet und NCache ist für den Einsatz auf all diesen Plattformen gerüstet.
Es gibt zwei Bereitstellungsoptionen. Einer ist, dass Sie mit dem dedizierten Cache-Tier gehen, wie im Diagramm gezeigt, und der zweite ist, und dass Ihre Anwendungen auf separaten Boxen und dediziert ausgeführt werden NCache läuft auf einer separaten dedizierten Ebene. Wir haben auch einen gemeinsamen Tier-Ansatz zur Verfügung, auf dem Sie auch laufen können NCache neben Ihren Bewerbungsboxen. Also überall dort, wo Ihre Anwendungen gehostet werden NCache kann darüber gehostet werden. Also, ich glaube, das ist ziemlich einfach. In einer Bereitstellung mit mehreren Rechenzentren hätten Sie mehr als ein Rechenzentrum und Sie hätten die gleiche Bereitstellung für NCache auch auf das andere Rechenzentrum, das wir in den nächsten Folien behandeln werden, und übrigens, wenn es irgendwelche Fragen gibt, können Sie diese Frage jederzeit in unserem Fragen und Antworten-Tab posten und Zack und ich werden, wissen Sie, eine behalten Halten Sie Ausschau nach all den Fragen, die gepostet werden, und wir werden all diese Fragen sehr gerne für Sie beantworten. Apropos Fragen, da Sie es gerade erwähnt haben, möchte ich eine hervorheben, nun, es war sehr einfach, dass Sie jetzt Kubernetes erwähnten. Die Frage war also, wir werden über Bridges sprechen und dies im Allgemeinen, gibt es Betriebssystemanforderungen für all dies? Kannst du das unter Linux ausführen? Absolut. NCache ist sehr flexibel. Wie Sie sehen können, sogar auf unserem Bereitstellungsdiagramm. Du kannst sehen NCache wird auf Windows- und Linux-Servern unterstützt. Auf Linux-Servern brauchen Sie also nur .NET Core Veröffentlichung von NCache und wir haben sowohl einen Server als auch einen Client dafür. Also, wenn Sie laufen wollen NCache Server auf .NET unter Linux mit .NET Core das ist möglich und dann können Ihre Anwendungen immer unsere verwenden .NET Core veröffentlichen und sowohl unter Windows als auch unter Linux bereitstellen, also ja. Fantastisch. Ich lasse Sie den Rest durchgehen und werde später auf die Fragen eingehen.
Multi-Rechenzentrums-Bereitstellung von NCache
Als nächstes werden wir über die Bereitstellung von Multi-Rechenzentren sprechen NCache. Nun, wenn Ihre Anwendung in mehreren Rechenzentren bereitgestellt wird, oder es könnte sein, dass Sie einen aktiven Standort haben und wir dann einen passiven Standort für DR-Szenarien haben. Beispielsweise fällt die aktive Site aus und Ihre Anwendung muss immer betriebsbereit sein, wenn es sich um eine unternehmenskritische Anwendung handelt, ist sie wichtig für Ihr Unternehmen. Eine Ausfallzeit auf Standortebene ist etwas, das sich auf Ihr Geschäft auswirken würde.
NCache Cluster ist so konzipiert, dass er bereits mit Hochverfügbarkeits- und Datenzuverlässigkeitsfunktionen ausgestattet ist. Wenn also auf einer einzelnen Site-Ebene ein oder zwei Server ausfallen, z. B. wenn Sie einen Server verlieren, NCache ist dafür gerüstet, diesen Ausfall problemlos zu bewältigen. Aber heute sprechen wir darüber, was passiert, wenn wir einen Ausfall auf Site-Ebene bekommen? Oder wir müssen die Website zu Wartungszwecken herunterfahren, wobei die gesamte Website heruntergefahren ist. Also sind alle Server down. NCache ist sogar für dieses Szenario gerüstet, und das wollen wir heute behandeln. Lassen Sie uns also darüber sprechen, warum wir eine WAN-Replikation benötigen.

Wenn Ihre Anwendungen Hochverfügbarkeit benötigen, kann ein einzelner Standort in der Regel zu einem Single Point of Failure werden. Wenn Ihre Website ausfällt, verlieren Sie alle Daten und es kann möglicherweise zu Ausfallzeiten bei den Benutzern Ihrer Anwendung kommen, was sich auf Ihr Geschäft auswirken könnte, das haben wir bereits festgestellt. Multiregionale Apps sind langsam, wenn sie über das WAN miteinander kommunizieren müssen. Sie haben beispielsweise ein Rechenzentrum bereitgestellt, Ihre Anwendung wird in einem Rechenzentrum in der US-Region bereitgestellt, und dann haben Sie eine andere Anwendung, die in Europa oder einer anderen Region, beispielsweise in Asien, bereitgestellt wird. Wenn sich Ihre Anwendungsdatenbanken also in einem der Rechenzentren befinden, muss die Remote-Site in diesem Fall über das Netzwerk gehen. Ihre Netzwerkgeschwindigkeit würde sich also auf die Latenz für diese andere Site auswirken. Sie wissen, dass Sie zur Bewältigung dieses Szenarios Ihre Datenquellen normalerweise auch über das WAN replizieren, und genau das empfehlen wir NCache auch das NCache repliziert werden soll. Aber wenn man bedenkt, dass Sie eine gemeinsame Datenquelle haben, muss der Remote-Standort über das WAN gehen, und das könnte sich möglicherweise auf die Leistung auswirken, da die Daten für diesen Standort nicht lokal sind. Die Entfernung zwischen den Rechenzentren würde sich auch auf Ihren Durchsatz auswirken . Es gibt nur so viele Daten, die Sie zwischen Standorten übertragen können. Das kann also Ihre Kapazität zur Bearbeitung von Anfragen einschränken.
Dies sind also zwei Probleme, wenn Sie über multiregionale Apps verfügen und beide Apps aktiv sind. Die Datenreplikation auf Anforderungsebene ist ebenfalls teuer. Beispielsweise replizieren Sie nicht die gesamte Datenbank und haben eine Datenquelle, die sich in einem Rechenzentrum befindet. Nun, eine Anfrage, die an unseren entfernten Standort, einen entfernten geografischen Standort, an Ihre Datenbank geht. Eine Replikation auf Anforderungsebene für alle Daten, Sie wissen schon, Anforderungseinheit, die zu unserer Datenquelle gelangt, das wird extrem teuer sein und eine Menge Bandbreite und Ressourcen verschlingen. Sie benötigen also einen aktiven Mechanismus, bei dem Sie Daten lokal verfügbar haben, und deshalb benötigen Sie unbedingt eine WAN-Replikation des Caches. Damit Ihre Daten von einem Rechenzentrum über das Netzwerk zum anderen Standort repliziert werden.
Einige Anwendungsfälle. Warum, wissen Sie, wo genau können Sie die WAN-Replikation einsetzen?
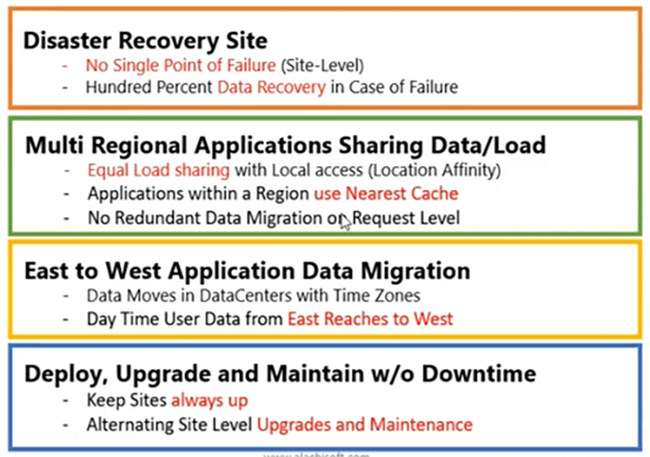
Die häufigste, auf die wir stoßen, ist die Disaster-Recovery-Site. Sie haben eine aktive Website, die Ihrem wichtigsten geschäftlichen Anwendungsfall dient. Dort wird Ihr Datenverkehr generiert und verarbeitet. Was ist, wenn die gesamte Website ausfällt? Sie brauchen eine Fallback-Option, richtig. Auf dieser DR-Site sollten also bereits Daten verfügbar sein. Andernfalls wären diese Datenanforderungen nicht gehandhabt worden, wenn es zu der Site zurückkehren müsste, die bereits heruntergefahren ist, richtig. Sie müssen also Daten auf der DR-Site verfügbar machen, damit sie bereits einsatzbereit ist. Sie müssen nur Ihren Datenverkehr auf diese DR-Site verlagern. Sie sollten nichts anderes tun, sondern Ihren Datenverkehr einfach an die Disaster-Recovery-Site weiterleiten, und es sollte mit demselben Leistungswert und denselben Leistungsmatrizen funktionieren, die Sie mit der aktiven Site hatten. Mit Hilfe von ist also eine 100%ige Datenwiederherstellung im Fehlerfall möglich NCache WAN-Replikation.
Multiregionale Anwendungen können sowohl Daten teilen als auch laden. Jetzt mit Active-Active-Sites, wenn Sie eine Region in den USA und eine in einem anderen Teil der Welt haben, z. B. Europa oder Asien. Wenn Sie möchten, dass Anfragen von einem Rechenzentrum basierend auf der Standortaffinität behandelt werden sollen, können Sie dies erreichen. Jetzt können Benutzer aus Asien eine Verbindung zu einer Site innerhalb dieser Region herstellen, die dieser Region am nächsten liegt, und sie können den Cache dort auch verwenden, und dieser Cache ist mit dem anderen Cache in der US-Region synchronisiert. Also, jeder Benutzer, der abprallt. Beispielsweise müssen Sie Überlauf verwalten oder Kapazität verteilen. Einige der Benutzer müssen jetzt in die US-Region wechseln, da die Region Asien vollständig erstickt ist, also können Sie das immer tun. Auf Site-Ebene können Sie also Ihre Anforderung basierend auf der Kapazität, die diese Site zu diesem Zeitpunkt und zu diesem Zeitpunkt verarbeitet, ausgleichen. Da Cache-Daten bereits über Rechenzentren hinweg repliziert werden und wir darüber sprechen werden, wie dies erreicht werden kann, können Ihre multiregionalen Anwendungen ihre Anwendungsdaten effizient gemeinsam nutzen und auch die Anforderungslast teilen, und sie können auch eine gleichmäßige Lastverteilung haben . Es erfolgt keine redundante Datenmigration. Es basiert nur darauf, dass die Anfrage von einem Rechenzentrum zum anderen springt, und Sie können diese Daten immer aus dem Cache abrufen, der dort bereits verbunden ist.
Die Migration von Anwendungsdaten von Ost nach West ist ein weiterer Anwendungsfall. Zum Beispiel starten die asiatischen Märkte früher als die westlichen Märkte, richtig. Ihr Datentrend folgt also normalerweise von Ost nach West. So kann Ihr östlicher Standort unseren Cache eingerichtet haben und mit der Zeitzone werden Daten zwischen Rechenzentren in die westliche Region verschoben und erreichen den Westen. Wenn Sie also Daten über Rechenzentren repliziert haben, die Cache-Daten, könnte die westliche Region alle Daten nutzen, die aus der östlichen Region verfügbar gemacht werden. Sie können also die Datenmigration von Ost nach West zur Verfügung stellen, und der Wartungsanwendungsfall ist der dritte.
Viertens, wo wir Upgrades bereitstellen und ohne Ausfallzeiten warten können. Das wird zu einem sehr dringenden Anwendungsfall, mit NCache auch. Das heißt, wenn Sie ein Upgrade planen, können Sie Upgrades zwischen älteren und neueren Versionen durchführen, indem Sie unsere Bridge-Topologie verwenden. Wo ältere Daten, Versionsdaten auf die neuere Version mit Live-Upgrade-Funktion übertragen werden können. Es könnte z. B. zwischen Standorten sein, Sie können einen Standort verwenden und Daten aktiv auf den passiven Standort replizieren, und Sie können ein Upgrade durchführen, einen neuen Code bereitstellen, die Leistung aufrechterhalten, den aktiven Standort warten und Sie haben alle Daten zur Verfügung gestellt und Ihre Datenverkehr kann für diese Angelegenheit an die passive Site geleitet werden. So können beide Standorte immer ohne Ausfallzeiten und ohne Verlust von Anwendungsdaten betriebsbereit sein.
NCache Bridge für die WAN-Replikation
Reden wir also darüber, wie man damit umgeht? Der Name der Funktion lautet NCache Brücke. Es ist Teil desselben Produkts. Sie benötigen dafür keine separate Installation. NCache Enterprise ist ausgestattet mit NCache Brückentopologie und lass uns darüber reden.
Also, unser Cache, NCache Mit der Bridge-Funktion können Sie den Cache über Rechenzentren hinweg replizieren.

Es basiert auf einem asynchronen Replikationsmodell. Auf der Anwendungsseite kommt es zu keinerlei Leistungseinbußen. Ihre Cache-Anwendungen sind aktiv mit dem Cache in einem Rechenzentrum verbunden. Sie haben beispielsweise Clients hier und dann können Sie eine Brücke erstellen, die auch eine Aktiv-Passiv-Warteschlange ist und die Daten asynchron an die anderen Standorte überträgt.
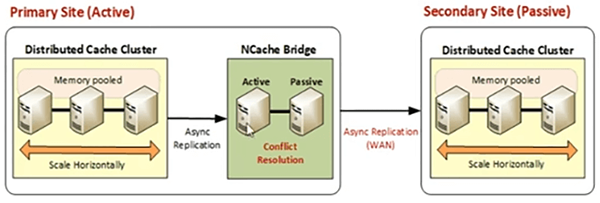
Es basiert also auf asynchroner Replikation, sodass es bei der Replikation von Daten zu keinen Leistungseinbußen kommt. Es ist sehr zuverlässig. Es ist fehlertolerant. Verbindungsabbrüche werden automatisch erkannt. Es verbindet sich automatisch wieder. Es sind automatische Wiederholungsoptionen verfügbar, so dass Bridge auch in der Aktiv-Passiv-Warteschlange gesichert wird.
Es gibt also einen Active Bridge-Server und dann gibt es auch noch einen Passive Bridge-Server. Wenn der Active Bridge-Server ausfällt, würde der Passive alle Replikationsvorgänge ohne Verzögerungen aufnehmen und starten. Es ist sehr einfach einzurichten, Sie brauchen keine Code-Änderungen, Sie brauchen keine zusätzlichen Installationen. Es ist Teil desselben Produkts, Enterprise, und bietet seine eigene Überwachungs- und Verwaltungsunterstützung, die in dasselbe integriert ist NCache Enterprise Produkt und es unterstützt mehrere Topologien, die ich als nächstes behandeln werde.
Wir haben also drei Haupttopologien.

Wir haben Aktiv-Passiv. Wo wir eine aktive Seite haben und dann haben wir eine passive Seite. Die passive Site nimmt auch Client-Anforderungen entgegen, aber der Datenfluss verläuft von aktiv nach passiv. Wenn Sie also DR-Standortanforderungen haben, können Sie einen Standort verwenden, um aktiv zu sein, mit der Bridge verbunden zu sein, und dann können Sie einen anderen Standort passiv haben. Die aktive Seite überträgt Daten an die passive Seite. Es handelt sich also um eine Einwegübertragung. Der Begriff „passiv“ bedeutet im Wesentlichen, dass der passive Standort keine Daten zurück zum aktiven Standort überträgt. Es läuft noch und Sie haben Client-Anwendungen, die davon profitieren. Es ist also nichts, was auf jeden Fall gestoppt wird. Die Ost-West-Migration kann mit aktiv passiv erreicht werden. Ihre Wartung und ein Upgrade-Anwendungsfall können mit Hilfe von Aktiv-Passiv behandelt werden.
Die Aktiv-Aktiv-Topologie liegt vor, wenn Sie eine Anwendung an zwei verschiedenen geografischen Standorten bereitgestellt haben und Daten von Standort 1 auf Standort 2 und die Daten von Standort 2 auf Standort 1 verfügbar gemacht werden sollen Geografische Standorte können Sie auf aktiv-aktiv zielen, wo Sie Benutzer haben, die in beiden Rechenzentren aktiv sind. Clients sind mit beiden Rechenzentren verbunden, und es findet eine bidirektionale Replikation zwischen zwei verschiedenen Standorten statt, und dann haben wir eine 3-, 2+- oder 3+-Aktiv-Aktiv-Topologie, bei der wir einen primären Gebotsserver haben, der jedoch Daten an alle überträgt Sites und diese Sites übertragen auch Daten zurück zu jeder anderen Site. Daher muss ein Update auf alle Rechenzentren angewendet werden und umgekehrt.
Also, hier ist unser Aktiv-Passiv.
Darin haben wir eine Brücke, die eine Warteschlange ist, die auch aktiv-passiv ist. Wir haben Cache-Cluster auf Standort 1, der nur Client-Anfragen bearbeitet. Wir haben hier 3 Server. Es ist mit der Brücke verbunden. Bridge befindet sich auch auf einem der Standorte. Oder in einigen Fällen können Sie eine aktive Bridge auf Standort 1 und einen passiven Bridge-Server auf Standort 2 haben. Das ist auch möglich, aber wir empfehlen normalerweise, dass Sie die Bridge auf einen der Standorte in Ihrer Bereitstellungsarchitektur verschieben. Die zweite Seite ist eine passive Seite und läuft noch einmal passiv. Es ist nur so, dass der passive Standort keine Daten zurück zum aktiven repliziert. Es ist eine Datenübertragung in eine Richtung und das ist alles, was es bedeutet, wenn wir sagen, dass dies eine passive Seite ist. Sie können hier im Wesentlichen Client-Anwendungen ausführen und es ist auch in diesem Zustand voll funktionsfähig. Es handelt sich also um eine aktiv-passive Replikation von Daten. Wenn also dieser Server ausfällt, wird das passive automatisch aktiviert. Es sind keine Codeänderungen erforderlich. Ich zeige Ihnen, wie Sie Bridge konfigurieren, sobald wir mit unserem praktischen Teil fortfahren. Es ist also ziemlich einfach.
Eine Frage kam herein und es hat mit diesem Aktiv-Passiv zu tun, es geht hauptsächlich darum, wenn Sie eine aktive und eine passive Seite haben, wie machen Sie die passive Seite aktiviert? Handelt es sich um einen manuellen Vorgang? Ist die Seite gestoppt? Wie machst du das? Okay, also, wenn ich diese Frage richtig verstanden habe, die passive Seite in Bezug darauf, wie wir sie aktivieren? Es ist bereits aktiviert. Es wird ausgeführt, und wenn wir diese Website herunterfahren oder den Datenverkehr hierher verschieben möchten, ist es Ihre Anwendungsverkehrslast, die Sie auf diese Website verschieben müssen. Sie haben hier also Anwendungsserver, Sie haben hier Anwendungsserver, alle Daten, die Sie haben, werden hierher übertragen, und die Benutzer dieser Site können die Daten aus dem Cache selbst zur Verfügung stellen. Jetzt können Sie Ihren Datenverkehr immer auf die passive Seite leiten und erhalten alle zur Verfügung gestellten Daten. Es sind also keine Schritte erforderlich, um es zu aktivieren. Wenn Sie jedoch möchten, dass diese Site ebenfalls mit der Übertragung von Daten an die aktive Site beginnt, können Sie sie mit unseren GUI-Tools aktivieren. Wenn Sie also in Bezug auf die Replikation Daten zurück zum aktiven replizieren möchten, können Sie dies immer aktiv machen, und dies ist ein Laufzeitprozess. Sie können das also mit nur einer Zeile, mit einem Klick im GUI-Tool erreichen, oder Sie können unser PowerShell-Tool verwenden, um dies zu erreichen. Aber wenn sich Ihre Frage darauf bezieht, den passiven Knoten aktiv zu machen. Wenn es einen manuellen Schritt gibt, damit sich Client-Anwendungen damit verbinden und Daten verwenden können, wird es bereits ausgeführt. Ihre Anwendungen beginnen damit, es zu verwenden, wenn Sie damit beginnen, Datenverkehr an diesen Cache-Cluster zu leiten. Also innerhalb Ihres Load Balancers. Sie schalten diese Site aus und leiten Ihren gesamten Datenverkehr an die verfügbare Site weiter, die bereits eingerichtet ist und ausgeführt wird, und Sie können alle Daten, die repliziert werden, abrufen/nutzen.
Also, aktiv-aktiv, es basiert wieder auf demselben Prinzip. Wo wir Brücken auf einem der Standorte haben.
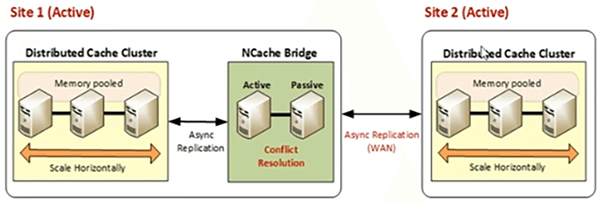
Wir haben Cache 1, Cache 2. Beide Sites sind aktiv und sogar die passive Topologie kann aktiv gemacht werden, indem Sie mit der rechten Maustaste klicken und sie aktiv machen, und in diesem Fall werden Daten vom Cache der Site 1 an Site 2 übertragen, asynchron von Cache zu Bridge und von Bridge zu Cache und dann in ähnlicher Weise überträgt Site 2 auch Daten zurück zu Site 1.
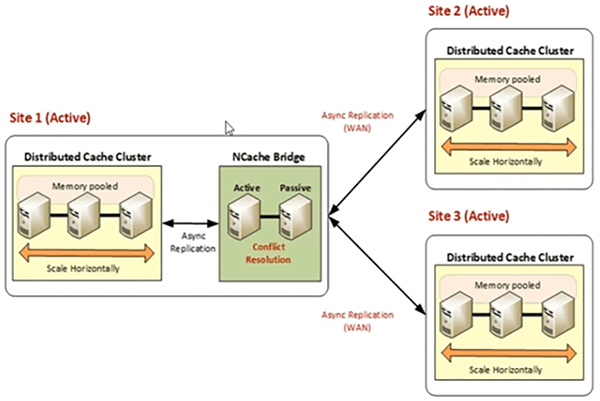
3+ Aktiv-Aktiv-Rechenzentren, wo wir drei oder mehr aktiv-aktiv haben, wo wir eine der Seiten als Bridge-Server haben. Wir können auch eine Fallback-Site für Bridge haben. Wir können auch einen Backup-Bridge-Standort haben. Aber im Allgemeinen hätten wir eine der Sites, die hosten würden, die Bridge hosten würden, und dann überträgt diese Site Daten an andere Sites, und in ähnlicher Weise überträgt Site 2 Daten an Site 1 über Bridge und an Site 3. Und für aktiv -aktiv, wir haben eine zeitbasierte Konfliktlösung, also gewinnt die letzte Aktualisierung. Alle von uns verwendeten Datenstrukturen sind konfliktfrei. Dies sind konfliktfreie Datentypen. Es gibt keine Race-Conditions oder bekannte Probleme mit der Datenkonsistenz, da das letzte Update allgemein auf den Cache-Cluster angewendet wird. So, NCache verwaltet, ob zwei Updates für denselben Schlüssel eingehen, NCache würde dies auswerten und Ihnen auch ermöglichen, Ihre eigene Konfliktlösung zu erstellen, wenn dies erforderlich ist. Es wird also als Teil von verwaltet NCache Topologien.
Hier ist also ein kurzer Blick auf unsere Bridge-Konfigurationen.

Wir haben NCache Brückenkonfig. NCache Bridge ist der Name und dann haben wir LondonCache Umgebung 1, sodass Sie auch mehrere Caches mit demselben Namen haben können. NewYorkCache und diese verbunden sind.
Hands-on-Demo NCache
Also, lassen Sie mich Ihnen das alles in Aktion zeigen, wie man eine Brücke konfiguriert? Wie man damit anfängt und dann zeigen wir Ihnen Anwendungen für Objekt-Caching und Sitzungs-Caching. Bevor Sie darauf eingehen, Ron, ich hatte gerade auf der vorherigen Folie mit dem Code eine Frage, und die Frage ist, welche Codeänderungen erforderlich sind, um die Brücke einzurichten. Müssen sie Code schreiben, damit die Daten über die Bridge repliziert werden? Gar nicht. Wir brauchen keinen Code. Es ist nur eine Konfiguration. Sie haben also Cache 1 in Rechenzentrum 1 und Cache 2 in Rechenzentrum 2. Sie konfigurieren einfach Bridge und alle Daten, die bereits von Ihren Anwendungen hinzugefügt werden NCache, wird automatisch über Bridge repliziert. Es liegt also in der Verantwortung von Bridge, die gesamte Replikation zu übernehmen. Sie müssen keinen expliziten Code schreiben, um Daten über Rechenzentren hinweg zu replizieren, und wenn wir von den Datentypen sprechen, der Konfliktlösung, das ist etwas, das auch standardmäßig implementiert ist, was zeitbasiert ist, aber wenn Sie Ihren eigenen implementieren möchten Konfliktlösung, wenn Ihre Geschäftsanforderungen darin bestehen, dass Sie Objekte auswerten, falls mehrere Aktualisierungen eingehen, können Sie in diesem Fall diese Schnittstelle implementieren. Aber was die Replikation von Daten anbelangt, so liegt die Verantwortung bei Bridge. Sie müssen dafür keinen Code schreiben.
Caches erstellen
Also, lass mich schnell anfangen, ich werde es tun einen Cache erstellen.
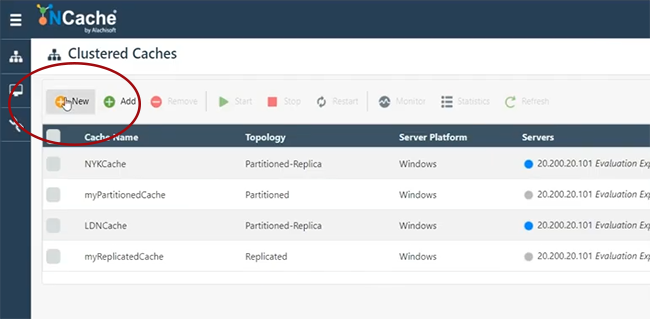
Nehmen wir an, ich nenne site1cache oder lasse mich hier tatsächlich SiteOneCache verwenden. Dies soll Ihnen nur eine Vorstellung davon geben, wie Sie schnell loslegen und die Brücke erstellen können. Ich werde alles standardmäßig beibehalten, weil NCache Architektur deckt all diese Details ab.
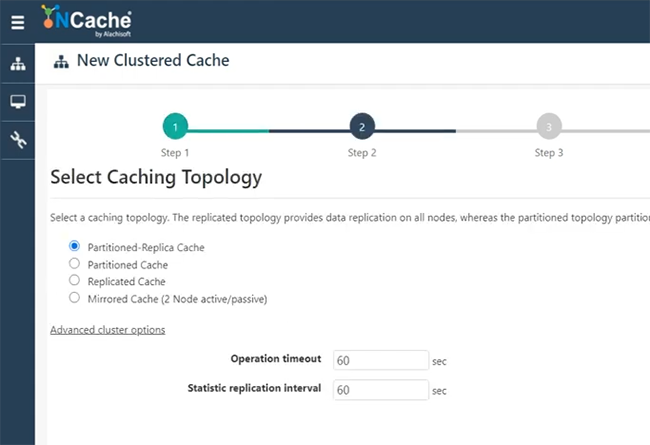
Also werde ich sie schnell durchgehen. Partition des Replikatcaches, beliebiger Cluster. Asynchrone Replikation der Topologie. Ich werde 101 wählen und mal sehen, ob ich 102 wählen kann, falls das verfügbar ist. Das sind meine beiden Server, um die Bridge zu hosten. Ich werde alle diese Standardeinstellungen beibehalten. Starten Sie dies und starten Sie auch automatisch. Beenden. Mein Cache befindet sich also auf 101 und 102, der erstellt werden soll. Mal sehen, wie es läuft, und dann werde ich weitermachen und einen weiteren Cache erstellen, der sich auf separaten Servern befinden würde, und dann werde ich die Bridge hosten und Ihnen zeigen, wie das alles funktionieren würde. Recht. Wir haben also SiteOneCache vollständig konfiguriert. Wie man sieht, ging es auch los.
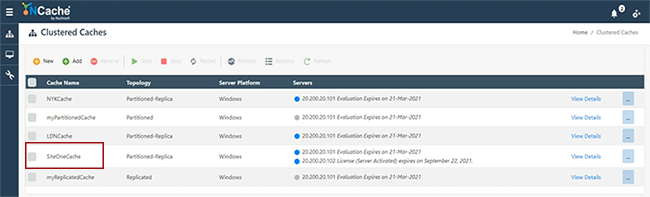
Jetzt werde ich fortfahren und tatsächlich einen anderen Cache erstellen, nämlich SiteTwoCache. Ich denke, das kann ich gebrauchen. Ich habe früher damit rumgespielt. Halten Sie alles einfach und dieses Mal werde ich einen separaten Satz von Servern angeben, so dass wir dies insgesamt als separate Site darstellen. Behalten Sie alles als Standard bei und übrigens ermöglicht Ihnen unsere Bridge die Fernverwaltung aller Sites, von den Verwaltungs- und Finanztools können Sie tatsächlich alle Sites zusammen mit Bridge von einem zentralen Ort aus verwalten. Also, wenn Sie Netzwerkzugriff haben. Wenn zwischen Ihrem SiteOne und SiteTwo eine WAN-Verbindung verfügbar ist, können Sie im Wesentlichen alles verwalten. Wir haben hier also SiteTwoCache. SiteOneCache gleich hier. 101 102 repräsentiert SiteOneCache. 107 und 108 repräsentieren SiteTwoCache. Nun, und diese werden ebenfalls gestartet.
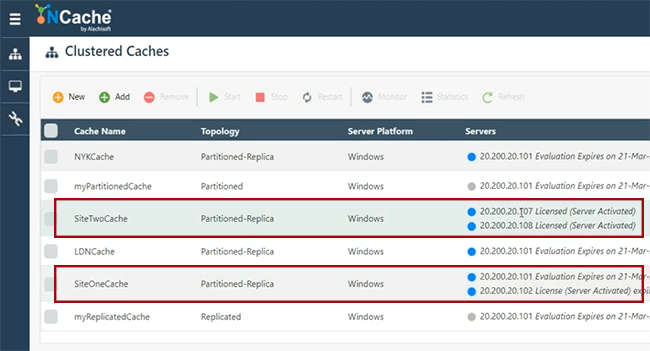
Wenn ich auf Statistiken klicke, sehen Sie, dass hier noch keine Objekte hinzugefügt wurden. Daten werden nicht in SiteOneCache oder SiteTwoCache hinzugefügt, also sind wir gut. Ich würde das einfach ausführen. Ich glaube, ich habe ein Berechtigungsproblem, um diesen Zähler zu überprüfen. Ich denke, ich kann, okay. Sie können also sehen, dass noch keine Artikel verfügbar sind. Diese beiden Caches verbinde ich nun mit Hilfe einer Bridge, die ich als nächstes konfiguriere.
Erstellen Sie eine Brücke
Also, hier werden wir eine Brücke bauen.
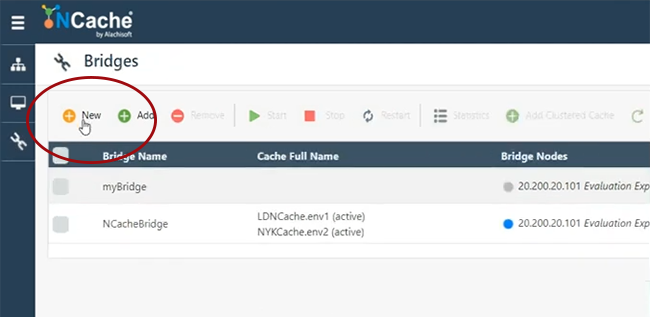
Also, ich werde nur sagen NCacheDemoBridge.
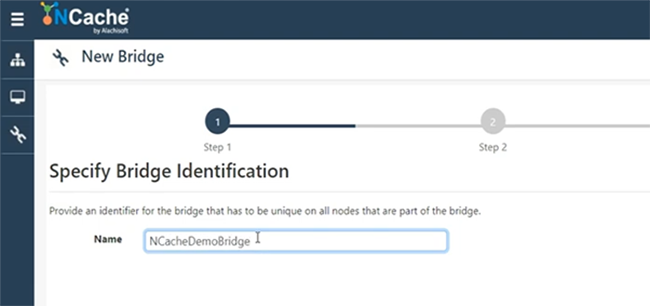
Sie können sich einen beliebigen Namen ausdenken, und die Bridge kann sich auf jedem Server befinden. Zum Beispiel auf 107. Lassen Sie mich einfach meine Box geben, los geht's. Lassen Sie mich also einfach eine Brücke auf 101 und 102 erstellen. Ich habe Berechtigungsprobleme. Lassen Sie mich also einfach sehen, ob ich 107 hinzufügen kann, ansonsten verwende ich nur einen Server für die Bridge. Dazu müssen bestimmte Ports geöffnet werden. Ich denke also, dass auf meiner Maschine alle diese Ports offen sind. Lassen Sie mich also vorerst nur 101 verwenden. Ein Server ist gut genug. Der Backup-Server ist nicht vorhanden, aber wir können ihn jederzeit hinzufügen, und ich behalte alles als Standard bei und wähle „Fertig stellen“. Die Bridge automatisch starten, wenn sie hochfährt, das ist auch eine Möglichkeit, und wenn ich dann auf der Bridge auf Details anzeigen klicke, zum Beispiel, wenn ich genau hier klicke, würde das alle Bridge-Einstellungen öffnen, die wir haben. Hier können Sie angeben, Sie können der Bridge bei Bedarf weitere Knoten hinzufügen und Sie können auch weitere Caches hinzufügen, die aktiv oder passiv fungieren würden. Wenn ich also auf Hinzufügen klicke, lässt es mich aus irgendeinem Grund nicht wirklich hinzufügen. Bitte bei mir tragen. Ich kann eine Frage einschleichen, während wir warten. Klar, bitte weitermachen. Klar, ja, einer ist gerade aufgetaucht. Es ist ziemlich einfach, es hat damit zu tun, wie Sie eine sichere Datenübertragung gewährleisten? Wir haben Verschlüsselungsfunktionen verfügbar. Wenn Sie also die Verschlüsselung oder Sicherheit auf Cache-Ebene aktiviert haben, wird Bridge dies befolgen. Also wird jede Übertragung, die zwischen CacheOne und CacheTwo übertragen wird, verschlüsselt, wenn Sie Verschlüsselung und Sicherheit ausgeschaltet haben, eingeschaltet. Wir haben also auch AES-, DES- und FIPS-konforme Verschlüsselungsanbieter. Wir haben auch TLS 1.2 unterstützt. Wir haben also sowohl Transport Level Security als auch Payload Level Security Verschlüsselungsfunktionen. Sie können diese Funktionen also nutzen.
Caches zur Bridge hinzufügen
In Ordnung, also wähle ich einen der Caches aus, SiteOneCache genau hier, richtig. Also kann ich wählen, ob es aktiv oder passiv sein soll. Ich gehe mit Active und wähle Finish.
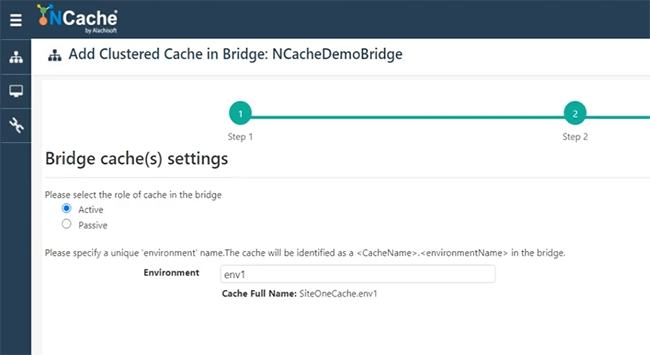
SiteOneCache wird also unter der Brücke hinzugefügt. Jetzt werde ich den zweiten Cache hinzufügen, der aus der Box 107 stammt. Ich hoffe, dass ich den Service Control Manager öffnen kann. Ich bin. Wählen Sie es aus, SiteTwoCache. Lass es uns wieder aktiv machen. Wenn Sie sich für „Passiv“ entscheiden, wird es ein Cache von Standort eins zu Standort zwei sein, aber wenn Sie sich für „aktiv“ entscheiden, erfolgt die Datenreplikation zwischen Standort eins zu Standort zwei und Standort zwei zu Standort eins. Wählen wir Finish.
Bridge-Statistiken überwachen
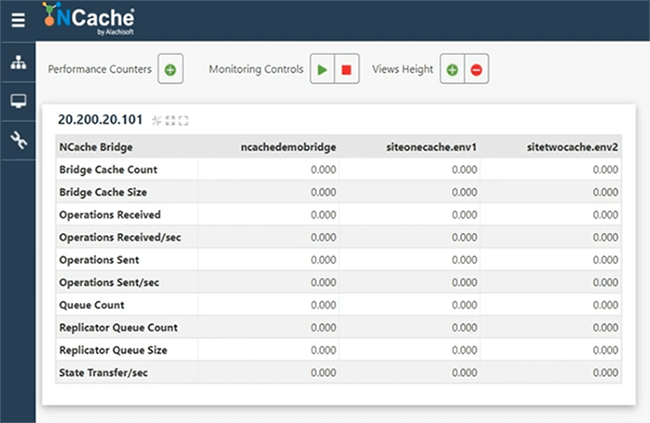
Sie können also auch Bridge-Zähler überprüfen. Wenn ich zum Beispiel genau hierher komme und von hier aus die Statistik der Brücke öffne, kann ich immer auch die Zähler der Brücke sehen. Lassen Sie mich zuerst damit beginnen. Aus irgendeinem Grund ist das System nicht sehr reaktionsschnell, also haben Sie bitte etwas Geduld und lassen Sie mich das Statistikfenster öffnen. Hier ist also unsere Brücke. Es wird noch nichts repliziert, weil wir überhaupt keine Last haben.
Ich werde also nur eine Last simulieren, indem ich ein Stresstest-Tool namens siteonecache ausführe.
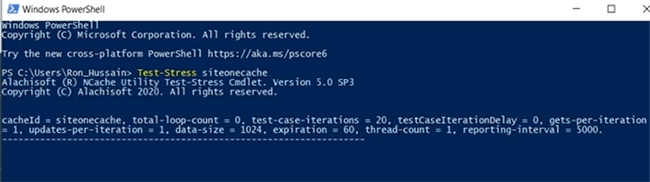
Da wir Zähler zur Verfügung haben, hätten wir einen Client angeschlossen und würden mit der Simulation beginnen. Obwohl wir dies nur für SiteOneCache ausgeführt haben, sobald es eine Verbindung herstellt. Bitte haben Sie Geduld mit mir. Lassen Sie mich also den Monitor öffnen, um zu überprüfen, ob er tatsächlich mit dem Cache verbunden ist oder nicht. Ich denke, es ist. Bridge hat also einige Aktivitäten, was darauf hindeutet, dass Bridge jetzt Anfragen entgegennimmt. Die Umgebung ist heute etwas träge. Ich entschuldige mich dafür, aber lassen Sie uns überprüfen, wie es geht. Okay, da Bridge Aktivität zeigt. Die Größe des Bridge-Cache wächst, empfangene und dann empfangene Operationen pro Sekunde zeigen Aktivität. Das bedeutet also im Wesentlichen, dass Daten standortübergreifend repliziert werden. Los geht's. Wir haben hier also SiteOneCache.
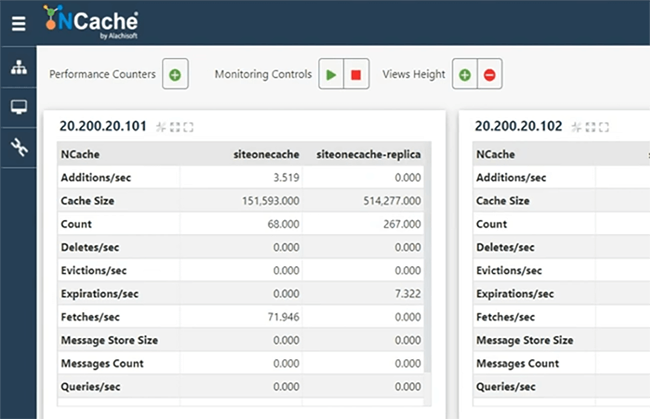
Wenn wir die öffnen, lassen Sie mich tatsächlich in unsere Demoumgebung einloggen, damit wir von dort aus die richtige Ansicht der Zähler sehen. Ich denke, das sollte uns auch helfen, alle Probleme im Zusammenhang mit Berechtigungen zu überprüfen, da es sehr lange dauert, dies tatsächlich zu laden, und ich auch keine Zähleraktivitäten sehen kann. Gut. Lassen Sie mich also diesen Webmanager hier starten. Los geht's. Obwohl es früher keine Zähler angezeigt hat, kann der Webmanager auf dem lokalen Bildschirm, aber als ich mich von diesem Server aus bei SiteTwoCache anmeldete, alle Zähler vollständig sehen. Wir haben also gezählt, dass aktiv repliziert wird. Ich habe nie ein Stress-Tool in zwei Caches ausgeführt, aber es ruft hier aktiv Daten ab. Wenn ich das jetzt stoppe oder sogar weiter laufen lasse, kann ich jetzt auch ein Belastungstool für SiteTwoCache ausführen und das würde Daten auch zurück zu meinem SiteOneCache replizieren. Damit sind unsere Tests abgeschlossen. Ich denke, ich sollte auch in dieser Umgebung Remote-In haben, damit wir die Aktivität in beiden Umgebungen separat sehen können. Also benutze ich einfach Siteonecache von hier, Bridge von hier und Sitetwocache von dort drüben.
Als nächstes werde ich einige anwendungsbezogene Anwendungsfälle behandeln. Also, lassen Sie es mich bitte wissen, wenn es irgendwelche Fragen gibt? Es ist nur eine ziemlich grundlegende Frage, aber es ging hauptsächlich darum, welche Umgebungen wir unterstützen? Auch hier weiß ich, dass Sie vorhin ein paar erwähnt haben, aber ich dachte, Sie könnten sie einfach alle auflisten. Wie gesagt, die einzige Voraussetzung dafür NCache ist .NET bzw .NET Core. Sie können NCache in Windows- und Linux-Umgebungen, wo immer sie verfügbar sind. Es könnte vor Ort sein, es könnte eine Cloud-Umgebung sein, es könnte Azure, AWS, Google Cloud oder irgendetwas anderes sein. Es könnte sich auch um eine gehostete Umgebung handeln. Es ist in Docker über Docker Container verfügbar und Sie können Docker-Images verwenden, um Ihren Cache und Ihre Anwendungen zu hosten. Kubernetes wird ebenfalls unterstützt. OpenShift, Kubernetes Service, erwähnt Azure Kubernetes Service, Elastic Kubernetes Service. Wo immer Sie also Docker verwenden können, können Sie auch verwenden NCache da drüben und es läuft nur auf eine einfache Tatsache hinaus, dass, wenn Sie haben .NET Core oder .NET installiert, das ist die einzige Voraussetzung dafür NCache und NCache kann im Wesentlichen auf all diesen Plattformen und auf all diesen Servern ausgeführt werden.
Beispielanwendung ausführen
Lassen Sie mich also tatsächlich laufen, obwohl ich diese Brücke hier benutze, habe ich eine andere Brücke, die verfügbar ist. Lassen Sie mich also eine andere Anwendung ausführen, die genau hier ist. Es ist eine Webanwendung mit Lastenausgleich. Wir haben es so konzipiert, dass wir eine Anfrage an ein Rechenzentrum weiterleiten können und wenn dieses Rechenzentrum ausfällt, die nachfolgende Anfrage an das andere Rechenzentrum gehen würde. Das würde Ihnen also im Wesentlichen einen Überblick darüber geben, wie Sie die Notfallwiederherstellung verwalten können, falls Sie dies getan haben NCache Bridge eingeschaltet und Sie erhalten alle Ihre Daten zur Verfügung gestellt.
Also, zuerst würde ich das von hier aus ausführen, wo wir es haben, lassen Sie mich das einfach von diesem Fenster aus öffnen, genau hier. Lassen Sie mich also mit dem Objekt-Caching-Beispiel beginnen. Also gut, lass mich einfach diesen Londo leitennCache Probe und lassen Sie mich dann auch die andere verfügbare Probe öffnen. Ich fange also mit Visual Studio an. Ausführen der Proben. Sobald diese Beispiele ausgeführt werden, würde ich Ihnen zeigen, dass Sie im Wesentlichen Objekt-Caching verwenden und Anfragen zwischen Rechenzentren nach Bedarf weiterleiten können.
Das würde Ihnen also eine visuelle Darstellung von Daten geben, die von einem Rechenzentrum hinzugefügt und von einem anderen abgerufen werden und umgekehrt über unsere Brücke. Okay, also, hier wird ein Londo benutztnCache die ich hier konfiguriert habe. Wenn ich es dir ganz schnell zeige. Wir haben also einen LondonCache und wir haben NewYorkCache. Also, zwei Caches, die zwei Rechenzentren darstellen, und dann haben wir eine Brücke, die ist NCache Brücke. Es hat LondonCache als CacheOne aktiv und NYCache als zweites. Also werde ich die Brücke vorerst stoppen. Ich zeige Ihnen diese beiden Caches separat und dann werde ich einige Daten simulieren und Ihnen zeigen, wie das im Cache funktioniert. Also, lassen Sie es laufen und sobald es geladen ist und dies NYKCache verwendet, lassen Sie mich das auch einfach hochfahren. Jetzt, da Sie wissen, wie Sie die Brücke konfigurieren, ist es sehr einfach, diese beiden Caches miteinander zu verbinden, indem Sie das Verwaltungstool auf einer beliebigen Box ausführen und diese Brücke konfigurieren können. Bitte haben Sie Geduld mit mir. Es würde einige Instanzen in Gang setzen. Es ist heute schrecklich langsam, ich entschuldige mich dafür. Das eingebaute Ereignis wurde also fertiggestellt, also würde es das in Kürze simulieren. Richtig, das ist also unsere Main.aspx und darin lade ich nur einige Objekte in den Cache. Das ist alles, was ich tue. Zum Beispiel innerhalb von, rechts, also, wenn ich Ihnen Main.aspx zeige, lädt es tatsächlich einige der Objekte in den Cache. Die Idee hier ist also, dass wir die Website der Region London und dann die Region New York erreichen und dann zeige ich Ihnen, wie Sie Daten synchronisieren, die aus der Region London mit New York und umgekehrt hinzugefügt wurden, und eine visuelle Darstellung würde alles sehr gut machen deutlicher im Vergleich. Wir haben also beide Seiten am Laufen. Lassen Sie mich nur eine hier und die andere hier öffnen. Nun, wenn ich sagen wir mal 10 Elemente hinzufüge, was es erlaubt. 10 Artikel werden hinzugefügt. Wenn ich aus demselben Cache abrufe, wird angezeigt, dass diese Daten aus der Region UK hinzugefügt wurden und UK-Kunden genau hier angezeigt werden.
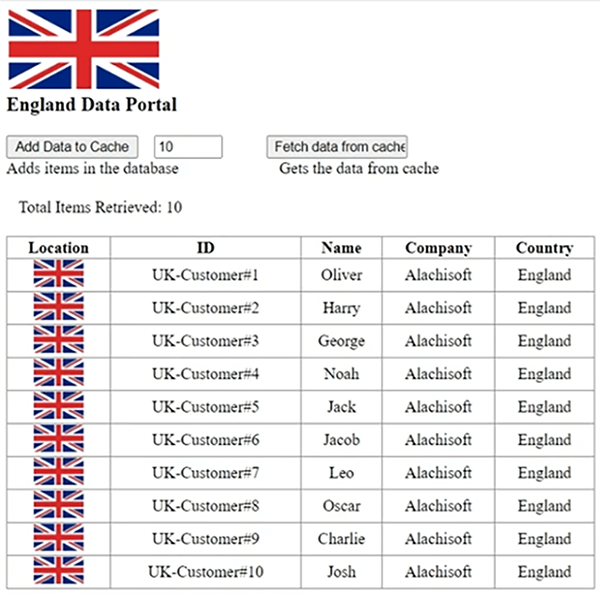
Wenn ich Daten aus dem Portal in London, USA, hinzufüge, werden in ähnlicher Weise 10 Elemente hinzugefügt, und Sie sehen dann alle diese 10 Elemente, aber was ist, wenn der Benutzer zurückspringt und Daten aus beiden Regionen gleichzeitig verfügbar gemacht werden müssen? Das ist also noch nicht möglich. Lassen Sie mich hier noch 5 weitere Artikel hinzufügen, damit dies zahlenmäßig anders ist. Wir haben also ungefähr 15 Artikel hier und 10 Artikel hier. Also, mit nur einem Klick entfernt, wenn ich diese Brücke einfach einschalte, richtig, und Statistiken öffne, repliziert die Brücke als Erstes tatsächlich alle Daten, die sich bereits in den Caches befinden.
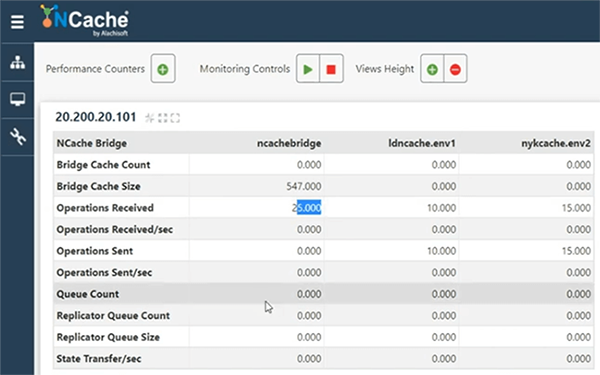
Caches sind also bereits verbunden, sobald wir mit der Bridge begonnen haben. Wir haben eine Brücke repliziert und 25 Artikel repliziert. Genau das haben wir hinzugefügt. Also, wenn ich die Schalter von öffne, lass mich das Londo öffnennCache, sowie NewYorkCache & offene Statistiken. Aus irgendeinem Grund dauert dies einige Zeit, aber irgendwann wird es geöffnet. Jetzt haben wir hier Statistiken.
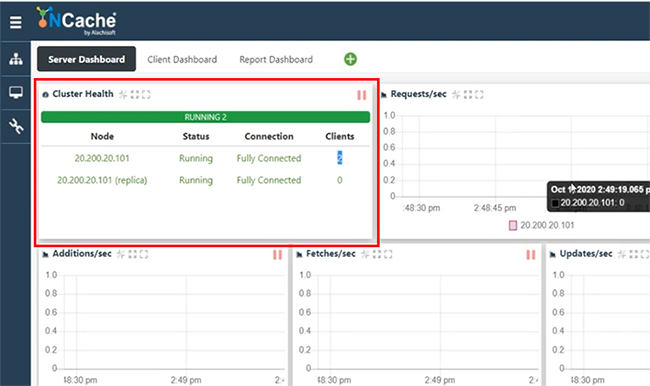
Wir haben Clients verbunden und wir haben den Zählwert, der genau hier angezeigt wird. Es zeigt also ungefähr 25 Elemente an, und das sehen Sie auch im NewYorkCache. Nun zurück zu meiner Anwendung, ich würde dieselbe Anwendung weiterlaufen lassen, aber dieses Mal würde ich nur Daten von hier abrufen und erwarte, alle Elemente im Cache zu sehen. Also alle 25 Elemente, London sowie US-Elemente, die hier abgerufen werden, weil replizierte Daten von CacheOne zu CacheTwo und von CacheTwo zu CacheOne überbrückt werden. Also, 15 Items hier werden jetzt mit 10 weiteren Items zu 25 Items zusammengefügt und wenn ich Daten aus dem Cache, dem USCache hole, sehe ich auch alle Items in der US-Region. Es ist also wieder eine Zwei-Wege-Übertragung. Es könnten mehr als zwei sein. Es könnte aktiv-passiv sein. Wo eine Übertragung in eine Richtung oder aktiv-aktiv erfolgen kann, wie in der Beispielanwendung gezeigt.
Nun, jeder neue Artikel, der hinzugefügt wird, sagen wir, 20 weitere hinzugefügte Artikel, sagen wir, und Sie holen von hier, Sie erhalten 45 Artikel, und wenn ich diese Artikel von hier hole, würden Sie 45 Artikel hier sehen. Es ist also augenblicklich. Alle hier hinzugefügten Elemente hier, sagen wir, fügen Daten hinzu, die die Anzahl von 45 auf 68 erhöhen würden, aber wenn ich Daten von hier abrufe, werden dieselben Elemente von hier verfügbar gemacht. Sehen Sie also, wie schnell es bei der Replikation von Daten zwischen verschiedenen Standorten ist. Also, diese beiden Caches sind es, und diese Caches laufen auch auf mehreren Servern, während wir hier sprechen. Damit ist unsere Objekt-Caching-Demonstration abgeschlossen.
Replikation von ASP.NET-Sitzungen über Rechenzentren hinweg
Lassen Sie mich Ihnen auch zeigen, wie Sie damit umgehen, wenn Sie ASP.NET-Sitzungen verwenden. In Multi-Sites können Sie, wie Sie wissen, auch ASP.NET-Sitzungen haben. Wenn dies beispielsweise über einen Load Balancer erfolgt, würde ich einfach einige Elemente hinzufügen, das ist eine separate Anwendung. Wir haben zwei Webserver, Site One Webserver und Site Two Webserver, die dieselbe Anwendung in Rechenzentren hosten. Also werde ich nur einige Elemente hinzufügen. Also, sobald es hinzugefügt wird, und lassen Sie mich die Brücke tatsächlich noch einmal stoppen. Wenn ich den Warenkorb ansehe. Wir haben also ein Element hinzugefügt. Angenommen, Sie fügen weitere Elemente hinzu. Wir haben also einige Artikel zur Verfügung gestellt. Wenn ich jetzt zu IIS gehe, wissen Sie, der London Site. Lassen Sie mich auch damit anfangen, richtig. Bringen Sie hierher zurück, Sie haben, ich hoffe wirklich, dass es London Site als Priorität trifft. Wir haben dort drüben keine Elemente, also sehen wir uns an, wo es endet, und dann verbinden wir die Brücke und zeigen Ihnen, dass alle Daten, die Sie von Site One hinzufügen, auf Site Two verfügbar sind und umgekehrt. Die erste Anfrage ist normalerweise langsam. Ich habe gerade die Anwendung gestartet, los geht's. Wenn wir also hier angekommen sind, erhalten wir 0 Artikel zurück. Diese beiden Sites sind also nicht synchron, obwohl Ihre Benutzersitzung von einer Site zur anderen springt, wenn wir die Site starten oder stoppen.
Jetzt würde ich einfach auf der Brücke drehen, auf den gleichen Linien, wie wir es vorher getan haben. Recht. Also, es würde laufen und es wird starten. Wieder werde ich Statistiken sehen. Also, 69 Items sind da, wissen Sie, das sind vom vorherigen Test. Aber jetzt, wenn ich auf meine Seite hier zurückkomme. Recht. Lasst uns noch einmal von vorne anfangen. Wir haben einige Artikel hinzugefügt. Machen wir weiter so. Nun zufälligerweise, wenn diese oder aufgrund eines Stromausfalls ausfällt oder Sie sie herunterfahren, wenn ich die Londoner Site herunterfahre, ist die einzige Site, Sie wissen schon, die New Yorker Site noch in Betrieb, also, wenn ich Klicken Sie einfach auf Warenkorb anzeigen, dieselben Datenelemente werden vom US-Portal zur Verfügung gestellt und es wurden Daten von der britischen Website hinzugefügt. Sie können also sehen, dass Daten von einer Site zur anderen weitergeleitet werden, und Ihr Benutzer erhält die Daten trotzdem zurück. Wenn jetzt sogar die Site wieder online wird, wissen Sie, wäre sie wieder in der Lage, alle Sitzungsdaten aus dem Cache abzurufen.
Multisite-ASP.NET-Sitzungen
Ebenso haben wir ASP.NET-Sitzungen mit mehreren Standorten. Das ist eine separate Funktion. Daher empfehlen wir Bridge für Ihre Objekt-Caching-Szenarien, in denen viele Datenübertragungen hinter den Kulissen zwischen zwei Caches stattfinden, und wir haben dies sowohl für das Objekt-Caching als auch für das Sitzungs-Caching gesehen.

Aber für das Sitzungs-Caching haben wir auch einen Anwendungsfall für das Caching von ASP.NET-Sitzungen mit mehreren Standorten. Also, wenn ich die Brücke nicht benutze. Ich kann diese beiden Sites immer noch miteinander verknüpfen, und zwar über eine separate Funktion, die verfügbar ist, und dafür werde ich einfach die Brücke stoppen. Sobald es aufhört, werde ich hierher zurückkommen. Lassen Sie mich nur den Inhalt löschen, damit wir von vorne beginnen, und das ist eigentlich eine bessere Möglichkeit, Ihren Cache für das Session-Caching zu synchronisieren. Aus diesem Grund handelt es sich bei Sitzungen um sehr transaktionale Daten. Sie möchten also nicht, dass Ihre Sitzungsdaten repliziert werden, obwohl Ihr Benutzer nicht von einer Site zur anderen springt, richtig. Also, wenn sich Ihr Benutzer hauptsächlich auf einer Site befindet und weil es sich um einen menschlichen Benutzer mit ASP.NET-Sitzungen handelt. In diesem Fall handelt es sich also um transiente Transaktionsdaten, die auf der anderen Website nicht benötigt werden. Es basiert nur auf dem Benutzer, der dort ist, und wenn Sie am Ende Ihren Benutzer von einer Site zur anderen ändern, könnte dies mit einer On-Demand-Replikation von Daten verwaltet werden. Sie müssen nicht alle Sitzungsdaten replizieren. Zum Beispiel tritt ein Überlauf auf, wenn eine Site mehr ist und mehr Kapazität erreicht als eine andere und Sie möchten, dass Benutzer mit Überlauf zur anderen Site wechseln und für sie bereits ein Sitzungsobjekt hier erstellt wurde. Sie brauchen dort also nicht alle Sitzungen. Sie benötigen nur Sitzungen dieses bestimmten Benutzers. Um diesem Szenario gerecht zu werden, empfehlen wir daher nicht, die Brücke einzuschalten.
Dafür haben wir ein weiteres Feature namens NCache Multi-Site-Sitzung. Mit Multi-Region ASP.NET Sessions State Provider können Sie all dies tatsächlich erreichen, ohne Bridge zu verwenden.
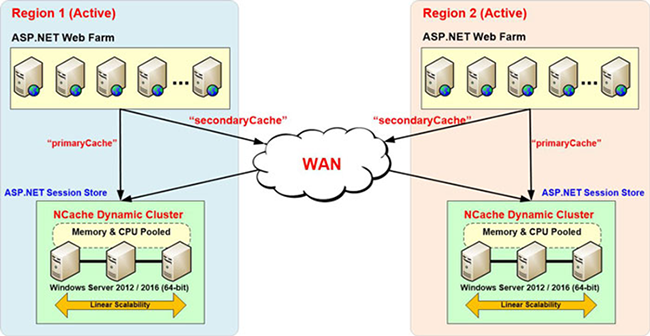
Sie haben also einen Site-XNUMX-Cache, der Sitzungen hat, und wir haben Site-XNUMX-Cache und Site-XNUMX hat eine primäre Cache-Adresse und dann die Backup-Cache-Adresse über die Region hinweg, und in ähnlicher Weise hat Site-XNUMX-Cache ein Primär- und ein Backup-Konzept. Wenn also ein Benutzer von einer Site zur anderen springt, gehen Ihre Cache-Clients, die Ihre Anwendungsserver sind, bei Bedarf zur anderen Site und sie erhalten die von dort bereitgestellten Sitzungsdaten und alles, was sie benötigen, sind Informationen zum anderen Site-Cache , zum Beispiel haben wir einen primären Cache und einen sekundären Cache, London, New York, und Sie können mehrere Backup-Caches haben. Falls also ein Benutzer aus London auf die Website in New York springt, würde er zurück zu Londo gehennCache und die Daten abholen und dort aufbewahren würde und um zu demonstrieren, dass ich wieder mit einer Cache-Anwendung beginnen würde. Zum Beispiel füge ich hier einige Daten hinzu, auch hier verwende ich LondonCache. Fügen Sie hier Artikel hinzu. Denken Sie daran, dass ich den Inhalt im Cache geleert habe, also haben wir hier keine Gegenstände und lassen Sie mich ebenso einfach das Londo öffnennCache Statistiken. Wir haben hier also keine Artikel, bis die erste Anfrage eintrifft. Sagen wir, hinzufügen. Wir haben also zwei Artikel, natürlich mit demselben Namen. Hier wird also eine Sitzung erstellt. Es ist noch nicht auf der New Yorker Website repliziert, aber wir haben die Multi-Site-Sitzungsfunktion aktiviert. Wir brauchen dafür keine Brücke, weil wir möchten, dass die Sitzungsreplikation nach Bedarf durchgeführt wird. Wir haben diese Konfigurationen vorgenommen, bei denen wir den primären Cache und den sekundären Cache haben und dann den Sitzungszustandsanbieter angeschlossen haben.
Es basiert also nur auf den Einstellungen des Sitzungsstatusanbieters, NCache ist in der Lage, den Anwendungsfall für Multi-Site-Sitzungen ohne die Verwendung von Bridge zu handhaben, und es ist nach Bedarf, so dass es in Bezug auf Sitzungsdaten viel effizienter ist. Also, was ich jetzt tun würde, ist, ich würde die Sitzungsanfrage an eine andere Site zurückschicken, indem ich zu IIS gehe, und ich würde die Londoner Site vollständig stoppen. Den Cache würde ich natürlich am Laufen halten und wenn ich das jetzt hole. Zunächst würde es die Daten von der US-Site abrufen. Die gleichen Gegenstände würden von dort aus zur Verfügung gestellt, und sobald es fertig ist, würde ich weitere Gegenstände hinzufügen und das Londo mitbringennCache online sichern. Es handelt sich also um eine On-Demand-Replikation, die ich versuche zu demonstrieren. Mal sehen, wie es läuft. Nehmen wir an, lassen Sie mich einige Elemente hinzufügen. Lassen Sie mich also diese Seite wieder online stellen. Da klebt es an der Londoner Seite. Nun, da ich den US-Benutzer zurück auf die Londoner Seite gebracht habe, wollen wir sehen, wie es läuft. Daher werden die gleichen Elemente auch vom Standort London zur Verfügung gestellt, und die Datenelemente wurden aus der US-Region hinzugefügt. Wenn ich hier weitere Artikel hinzufüge, könnte ich diese Artikel auch hier hinzufügen. Lassen Sie mich diesen Fehler noch einmal simulieren, indem ich diese Site stoppe, und sehen wir, ob sie auch auf die andere Seite springt. Ich denke, es gab früher einige konfigurationsbezogene Probleme, aber jetzt, wo diese Site gestoppt wird. Lassen Sie mich nur den Warenkorb anzeigen. Ich nehme an, los geht's. Dieselbe Sitzung wird jetzt also von der US-Site zur Verfügung gestellt, und denken Sie daran, dass ich hier keine Bridge für diese Funktion konfiguriert habe, es ist nur die Multi-Site-Sitzung. Brücke wird gestoppt. Es repliziert immer noch Daten, aber es ist auf Abruf. Damit ist es eigentlich komplett.
Für Objekt-Caching und weniger Transaktionsdaten, Referenzdaten und statische Daten empfehlen wir, dass Sie Bridge aktivieren und die Vorteile der aktiven Replikation zwischen Rechenzentren nutzen, aber die Sitzung ist ein transaktionaler Anwendungsfall, der Lese- und Schreibanforderungen, Sie wissen schon, eine Kombination hat. Es ist also sehr schwer, während Sie Daten von einem Rechenzentrum in das andere aktualisieren, da sich die Daten im primären Rechenzentrum bereits geändert haben und der Sitzungsbenutzer nicht von einem Rechenzentrum zum anderen springt. Es wäre zu einem bestimmten Zeitpunkt nur auf einer Seite. Sie benötigen also keine aktive Datenreplikation. Sie können eine On-Demand-Replikation haben. Wenn es von Region eins zu Region zwei springt, sollten Sie in der Lage sein, die Sitzungsdaten von dort abzurufen, und wenn es zurück zu Region eins springt, sollten Sie wieder in der Lage sein, die bereitgestellten Sitzungsdaten abzurufen, und dafür empfehlen wir Ihnen die Verwendung unsere Multi-Site-Session-Funktion ohne Bridge.
Es gibt einige erweiterte Funktionen, die ich schnell besprechen würde.
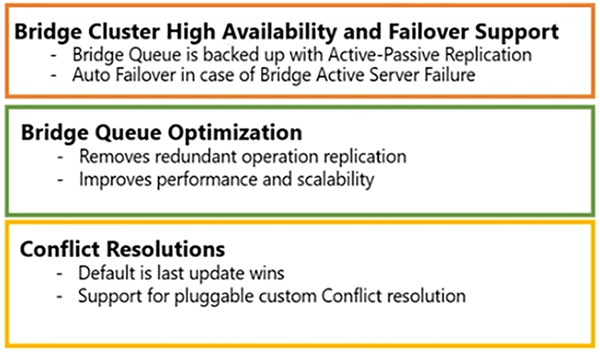
Bridge ist hochverfügbar. Die Failover-Unterstützung ist integriert, ein Ausfall des Bridge-Servers verursacht keine Ausfallzeit. Die Bridge-Warteschlange ist sehr optimiert. Es ist schnell. Zusätzlich können Sie einige Warteschlangenoptimierungsfunktionen aktivieren, die es weiter optimieren würden.

Konfliktlösung ist darin eingebaut. Letztes Update gewinnt, aber wenn Sie Ihre eigene Konfliktlösung implementieren möchten, können Sie einen Handler verwenden und sich bei registrieren NCache. Diese Schnittstelle kann also aufgerufen werden, falls es zu einem Konflikt zwischen zwei Schlüsseln kommt, bei dem zwei Aktualisierungen gleichzeitig stattfinden. So, NCache würde Ihnen die Kontrolle geben und Sie können die Version dieses Elements überprüfen und entscheiden, welches gewinnt.
Umgang mit Katastrophen zur Laufzeit. Zack fragte zunächst, wie man die passive Site aktiv macht, Sie müssen nur den Datenverkehr an die passive Seite leiten.

Wenn die Active-Site jemals ausfällt und es keine Ausfallzeit gibt, erfolgt eine automatische Neusynchronisierung, wenn Active wieder hochfährt. Bei Aktiv-Aktiv wird der Datenverkehr an beide Seiten geleitet. Ein Ausfall einer Website hätte keine Auswirkungen, Sie müssen den Datenverkehr nur zurück zum aktiven leiten, und wenn der aktive wieder online geht, wird die erneute Synchronisierung automatisch durchgeführt. Es gibt keine Verzögerungen, kein manuelles Eingreifen erforderlich. In zwei plus oder drei oder mehr Aktiv-Aktiv-Fällen, wenn die aktive Site ohne Bridge ausfällt, müssen Sie nur den Datenverkehr zu einer anderen Site verwenden, und es würde keine Ausfallzeit oder Datenverlust geben. Für den Fall, dass der aktive Standort der Brücke ausfällt, zum Beispiel, wenn wir hier einen Brückenstandort haben.
Wenn dies ausfällt, haben wir auch eine Option für eine Backup-Bridge-Site. Sie können diese Bridge-Site also aktivieren und dafür die Backup-Bridge angeben, um die Replikation aufzunehmen. Die Replikation würde also anhalten, wenn die gesamte Bridge-Site ausfällt, aber wir haben auch die Option einer Backup-Bridge-Site.
Daher möchte ich diese Aspekte ganz schnell behandeln. Ich denke das sollte erstmal reichen. Bisher noch Fragen? Zack, du kannst es hier abholen. Sicher, ich weiß, wir laufen hier in den letzten ein oder zwei Minuten, also werde ich nur eine Frage einwerfen, die zu dem kam, was Sie gerade überarbeitet haben. Es hatte mit Konfliktlösung zu tun, und ich glaube, die Frage ist, was sind die Beispiele für Konfliktlösung, wo wir sie umsetzen müssten? Okay. In der Regel wird der Großteil Ihrer Konfliktlösung standardmäßig behandelt, ohne dass Sie etwas implementieren müssen. Die zeitbasierte Konfliktlösung ist alles, was Sie brauchen. Mit der Erwartung, dass Sie Active-Active-Sites betreiben und Daten von einem Rechenzentrum zum anderen benötigen, benötigen Sie Updates von einem Rechenzentrum zum anderen. Das letzte Update gewinnt also. Aber für den Fall, dass die Daten spezifischer sind und Sie den Wert der Daten haben möchten, würde dies bestimmen, welches Objekt in der Bridge aufbewahrt werden soll. Beispielsweise gibt es eine bestimmte Version oder bestimmte Informationen oder eine bestimmte Sequenznummer innerhalb der Objektdefinition, beispielsweise gibt es ein Versionsattribut eines Objekts. Wenn es also einen Konflikt gibt, möchten Sie nicht, dass dieses Objekt übersehen wird. Sie überprüfen dieses Objekt also durch den Code, überprüfen die Version, welche beibehalten werden muss, also basierend auf der letzten Version oder der neuesten Version im Vergleich zur Zeit, die versionbasiert sein könnte. Es könnte sogar auf dem Wert des Objekts basieren. Beispielsweise gibt es einen Datenbankeintrag und Sie haben ein Objekt, das diese Datenbank darstellt und das eine modifizierte Zeit hat. Das ist also nicht die Aktualisierung des Caches, es ist eine Aktualisierung der Datenbank, aber diese Aktualisierungszeit ist zufällig Teil dieses Objekts, und wenn dieses Objekt zuerst hinzugefügt wurde und dann ein anderes Objekt überschreibt, möchten Sie nicht, dass die letzte Aktualisierung erfolgt die Datenbank verloren gehen, richtig? Wenn sich also etwas im Objekt befindet und Sie eine Entscheidung basierend auf den Attributwerten treffen müssen, müssen Sie die Konfliktlösung dafür selbst implementieren. Aber wie gesagt, der Großteil der Konfliktlösung wird standardmäßig über unsere Zeitbasis-Standardoption abgewickelt. Welches Update auch immer zuletzt kommt, wird als neuestes Update auf das Element angewendet, und dies geschieht nur. Denken Sie daran, dass diese Konfliktlösungslogik nur ins Spiel kommt, wenn zwei Updates gleichzeitig in die Warteschlange auf der Brücke hinzugefügt werden. Richtig, Bridge erhält also zwei Updates gleichzeitig. Also, welche soll man wählen? Site eins hat ein Element hinzugefügt oder aktualisiert, und Site zwei hat dasselbe Element ebenfalls hinzugefügt oder aktualisiert. Also muss Bridge jetzt entscheiden, welche im Cache oder in der Warteschlange bleiben soll, und das wird auch auf Standort eins und Standort zwei repliziert. Denn man muss den anderen gewinnen. Die zeitbasierte Konfliktlösung ist also standardmäßig implementiert, und das würde Sie durch die meisten Ihrer Fälle bringen.
Ich überlasse es Ihnen, gibt es noch etwas, das wir besprechen? Ich denke, wir sind gut. Was den Inhalt betrifft. Okay. Die Vorführung ist abgeschlossen. In Ordnung, wir rennen hier in letzter Minute los, also vielen Dank an alle, die herausgekommen sind. Wenn Sie Fragen zu diesem speziellen Webinar haben, senden Sie uns einfach eine E-Mail an support@alachisoft.com Besuchen Sie auf jeden Fall unsere Website und laden Sie eine kostenlose 2-monatige Testversion herunter NCache Enterprise und verwenden Sie es in Ihrer Umgebung. Wenn Sie Hilfe beim Onboarding benötigen, können Sie sich an wenden support@alachisoft.com und wenn Sie weitere Fragen haben, ob Sie kaufen möchten NCache oder um Lizenzinformationen zu erhalten, wenden Sie sich bitte an sales@alachisoft.com.