Sechs Gründe warum NCache ist besser als Redis
Aufgezeichnetes Webinar
Von Iqbal Khan
Erfahren Sie, wie Redis und NCache auf Merkmalsebene miteinander vergleichen. Das Ziel dieses Webinars ist es, Ihnen den Vergleich der beiden Produkte einfacher und schneller zu machen.
Das Webinar umfasst Folgendes:
- Unterschiedliche Produktfunktionsbereiche.
- Welche Unterstützung tun Redis und NCache in jedem Funktionsbereich bereitstellen?
- Was sind die Stärken von NCache übrig Redis und umgekehrt?
NCache ist ein beliebter Open Source (Apache 2.0-Lizenz) verteilter In-Memory-Cache für .NET. NCache wird häufig für das Zwischenspeichern von Anwendungsdaten, die Speicherung des ASP.NET-Sitzungszustands und die Freigabe von Laufzeitdaten im Pub/Sub-Stil über Ereignisse verwendet.
Redis ist auch ein beliebter Open Source (BSD-Lizenz) In-Memory-Datenstrukturspeicher, der als Datenbank, Cache und Nachrichtenbroker verwendet wird. Redis ist unter Linux sehr beliebt, hat aber in letzter Zeit auf Azure Aufmerksamkeit erregt, da Microsoft es bewirbt.
Überblick
Hallo zusammen, mein Name ist Iqbal Khan und ich bin Technologie-Evangelist bei Alachisoft. Alachisoft ist ein Softwareunternehmen mit Sitz in der San Francisco Bay Area und Hersteller des beliebten NCache Produkt, das ein verteilter Open-Source-Cache für .NET ist. Alachisoft ist auch der Hersteller von NosDB, die eine Open-Source-keine SQL-Datenbank für .NET ist. Heute werde ich über sechs Gründe sprechen, warum NCache ist besser als Redis für .NET-Anwendungen. Redis, wie Sie wissen, wird von entwickelt Redis Labs und wurde von Microsoft für Azure ausgewählt. Der Hauptgrund für die Auswahl war das Redis bietet Unterstützung für mehrere Plattformen und viele verschiedene Sprachen, während NCache konzentriert sich ausschließlich auf .NET. Also lasst uns anfangen.
Verteilter Cache
Bevor ich auf die Vergleiche eingehe, möchte ich Ihnen zunächst eine kurze Einführung geben, was verteiltes Caching ist und warum Sie es brauchen und welches Problem es löst. Verteiltes Caching wird tatsächlich verwendet, um die Skalierbarkeit Ihrer Anwendungen zu verbessern. Wie Sie wissen, können Sie, wenn Sie eine Webanwendung oder Webdienstanwendung oder eine beliebige Serveranwendung haben, weitere Server auf der Anwendungsebene hinzufügen. Normalerweise ermöglichen die Anwendungsarchitekturen dies sehr nahtlos. Auf der Datenbankebene ist dies jedoch nicht möglich, insbesondere wenn Sie eine relationale Datenbank oder ältere Mainframe-Daten verwenden. Sie können das ohne SQL tun. Aber wissen Sie, in den meisten Fällen müssen Sie aus technischen und geschäftlichen Gründen relationale Datenbanken verwenden.
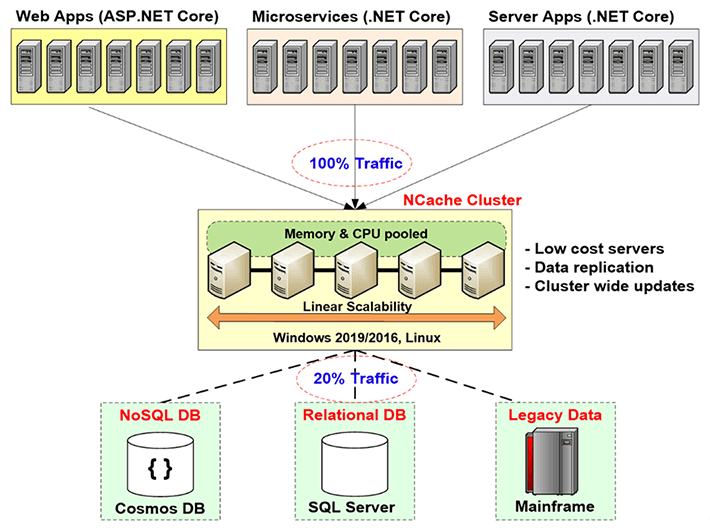
Sie müssen also diesen Skalierbarkeitsengpass lösen, den relationale Datenbanken oder ältere Mainframes durch verteiltes Caching verursachen, und zwar durch Erstellen einer Caching-Ebene zwischen der Anwendungsebene und der Datenbank. Diese Caching-Ebene besteht aus zwei oder mehr Servern. Dies sind in der Regel Low-Cost-Server. Im Falle von NCache, ist die typische Konfiguration ein Dual-CPU-Quad-Core-Computer mit 16 bis 32 GB RAM und ein bis zwei Netzwerkkarten mit einer Geschwindigkeit von 1 bis 10 Gigabit. Diese Caching-Server bilden im Falle von einen TCP-basierten Cluster NCache und um die Ressourcen all dieser Server in einer logischen Kapazität zusammenzufassen. Auf diese Weise können Sie, wenn Sie wachsen, die Anwendungsebene, sagen wir, wenn Sie immer mehr Datenverkehr oder immer mehr Transaktionslast haben, mehr Server auf der Anwendungsebene hinzufügen. Sie können auch weitere Server auf der Caching-Ebene hinzufügen. Normalerweise halten Sie ein Verhältnis von 4 zu 1 oder 5 zu 1 zwischen der Anwendungsebene und der Caching-Ebene aufrecht.
Aus diesem Grund wird der verteilte Cache niemals zu einem Engpass. Sie können also hier mit dem Zwischenspeichern von Anwendungsdaten beginnen und den Datenverkehr zur Datenbank reduzieren. Das Ziel ist, dass etwa 80 % Ihres Datenverkehrs in den Cache gehen und etwa 20 % des Datenverkehrs, normalerweise Ihre Aktualisierungen, in die Datenbank gehen. Und wenn Sie das tun, steht Ihre Anwendung nie vor einem Skalierbarkeitsengpass.
Allgemeine Verwendung von verteiltem Cache
Okay, unter Berücksichtigung des Vorteils eines verteilten Cachings, lassen Sie uns über die verschiedenen Anwendungsfälle sprechen, die Sie kennen, die verschiedenen Situationen, in denen Sie einen verteilten Cache verwenden können.
Zwischenspeichern von Anwendungsdaten
Nummer eins ist das Zwischenspeichern von Anwendungsdaten, das ist dasselbe wie das, was ich gerade erklärt habe, wo Sie Daten zwischenspeichern, die sich in Ihrer Datenbank befinden, damit Sie die Leistung und Skalierbarkeit verbessern können. Das Wichtigste, was Sie beim Zwischenspeichern von Anwendungsdaten beachten sollten, ist, dass Ihre Daten jetzt an zwei Orten vorhanden sind. Es existiert in Ihrer Datenbank, die die Master-Datenquelle ist, und es existiert auch in der Caching-Ebene, und wenn das passiert, müssen Sie vor allem bedenken, dass die größte Sorge, die kommt, ist, wissen Sie , wird der Cache veraltet sein? Wird der Cache eine ältere Version der Daten haben, obwohl sich die Daten in der Datenbank geändert haben? Wenn diese Situation eintritt, haben Sie natürlich ein großes Problem, und viele Menschen speichern aus Angst vor Datenintegritätsproblemen nur schreibgeschützte Daten. Nun, die schreibgeschützten Daten sind eine sehr kleine Teilmenge der gesamten Daten, die Sie zwischenspeichern sollten, und es sind etwa zehn bis fünfzehn Prozent der Daten.
Der wahre Vorteil liegt darin, dass Sie damit beginnen können, Transaktionsdaten zwischenzuspeichern. Das sind Ihre Kunden, Ihre Aktivitäten, Ihr Verlauf, wissen Sie, alle Arten von Daten, die zur Laufzeit erstellt werden und sich sehr häufig ändern, Sie müssen diese Daten immer noch zwischenspeichern, aber Sie müssen sie so speichern, dass der Cache immer bleibt frisch. Das ist also der erste Anwendungsfall, und wir werden darauf zurückkommen.
ASP.NET-spezifisches Caching
Der zweite Anwendungsfall ist das ASP.NET-spezifische Caching, bei dem Sie den Sitzungsstatus, den Ansichtsstatus und, wenn Sie nicht über das MVC-Framework und eine Seitenausgabe verfügen, zwischenspeichern. In dieser Situation speichern Sie den Sitzungsstatus, da ein Cache ein viel schnellerer und besser skalierbarer Speicher ist als Ihre Datenbank, in der Sie andernfalls diese Sitzungen oder die anderen von Microsoft bereitgestellten Optionen und in diesem Fall die Daten zwischenspeichern würden vorübergehend. Vorübergehend bedeutet, dass es vorübergehender Natur ist. Es wird nur für einen kurzen Zeitraum benötigt, danach werfen Sie es einfach weg und die Daten existieren nur noch im Cache. Der Cache ist der Hauptspeicher. In diesem Anwendungsfall besteht die Sorge also nicht darin, dass der Cache mit der Datenbank synchronisiert werden muss, sondern die Sorge besteht darin, dass Sie einige der Daten verlieren, wenn ein Cache-Server ausfällt. Denn es handelt sich ausschließlich um In-Memory-Speicher, und der Speicher ist, wie Sie wissen, flüchtig. Ein guter verteilter Cache muss also intelligente Replikationsstrategien bieten. Damit Sie alle Daten auf mehr als einem Server haben. Wenn ein Server ausfällt, verlieren Sie keine Daten, aber die Replikation ist mit Kosten verbunden, Leistungskosten. Die Replikation muss also superschnell sein, und das ist was NCache tut übrigens.
Gemeinsame Nutzung von Laufzeitdaten
Der dritte Anwendungsfall ist der Anwendungsfall Laufzeitdatenfreigabe, bei dem Sie den Cache im Wesentlichen als Datenfreigabeplattform verwenden. Daher sind viele verschiedene Anwendungen mit dem Cache verbunden und können Daten in einem Pub/Sub-Modell gemeinsam nutzen. Eine Anwendung produziert also die Daten, legt sie in den Cache, löst ein Ereignis aus und andere Anwendungen, die Interesse an diesem Ereignis angemeldet haben, werden benachrichtigt, damit sie diese Daten nutzen können. Es gibt also auch andere Veranstaltungen. Es gibt schlüsselbasierte Ereignisse, Ereignisse auf Cache-Ebene, es gibt eine kontinuierliche Abfragefunktion, die NCache verfügt über. Es gibt also eine Reihe von Möglichkeiten, wie Sie einen verteilten Cache verwenden können NCache um Daten zwischen verschiedenen Anwendungen auszutauschen. Auch in diesem Fall werden die Daten zwar aus Daten in der Datenbank erstellt, aber die Form, in der sie geteilt werden, kann nur im Cache existieren. Sie müssen also sicherstellen, dass der Cache Daten repliziert. Die Bedenken sind also die gleichen wie beim ASP.NET-Caching. Das sind also die drei Anwendungsfälle, die für einen verteilten Cache üblich sind. Bitte denken Sie an diese Anwendungsfälle, wenn ich die Funktionen vergleiche NCache bietet welche Redis nicht.
Grund 1 – Cache frisch halten
Also, der erste Grund, warum Sie verwenden sollten NCache übrig Redis ist das, NCache bietet Ihnen sehr leistungsstarke Funktionen, um den Cache frisch zu halten. Wie wir darüber gesprochen haben, wenn Sie den Cache nicht aktuell halten können, sind Sie gezwungen, schreibgeschützte Daten zwischenzuspeichern, und wenn Sie dann schreibgeschützte Daten zwischenspeichern, ist das nicht der wirkliche Vorteil. Sie müssen also in der Lage sein, so ziemlich alle Ihre Daten zwischenzuspeichern. Sogar Daten, die sich alle 10-15 Sekunden ändern.
Absolute Verfallsdaten / Gleitende Verfallsdaten
Der erste Weg, den Cache frisch zu halten, ist also die Verfallszeit. Ablauf ist etwas, das beides NCache und Redis versorgen. So gibt es zum Beispiel einen absoluten Ablauf, bei dem Sie dem Cache mitteilen, dass diese Daten nach 10 Minuten oder 2 Minuten oder 1 Minute ablaufen sollen. Nach dieser Zeit entfernt der Cache diese Daten aus dem Cache und Sie machen eine Vermutung, Sie sagen, Sie wissen, ich denke, es ist sicher, diese Daten so lange im Cache zu behalten, weil ich nicht glaube, dass dies der Fall sein wird Änderung in der Datenbank. Basierend auf dieser Vermutung weisen Sie den Cache also an, die Daten ablaufen zu lassen.
So sieht Expiration aus. Ich werde dir nur etwas zeigen. Im Falle von NCache, wenn Sie installieren NCache Übrigens, weißt du, es gibt dir ein paar Proben. Eines der Beispiele heißt Grundoperationen, die ich hier geöffnet habe. Lassen Sie mich Ihnen also kurz die grundlegenden Vorgänge erläutern, wie eine typische .NET-Anwendung verwendet wird NCache sieht aus wie.
Sie verlinken mit NCache zur Laufzeit NCache.Web-Assembly verwenden Sie dann die NCache.Laufzeit Namensraum, NCache.Web.Caching Namespace und dann zu Beginn Ihrer Anwendung verbinden Sie sich mit dem Cache. Alle Caches sind benannt.
using System;
using Alachisoft.NCache.Runtime;
using Alachisoft.NCache.Web.Caching;
using Alachisoft.NCache.sample.data;
namespace BasicOperations
{
public class BasicOperations
{
public static void Main(string[] args)
{
try
{
//Initialize cache via 'initializeCache' using 'Cache Name'
//to be initialized.
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Another method to add item(s) to cache is via CacheItem object
Customer customer = new Customer();
customer.Name = "David Johnes";
customer.Age = 23;
customer.Gender = "Male";
customer.ContactNo = "12345-6789";
customer.Address = "Silicon Valley, Santa Clara, California";
DateTime calendar = new DateTime();
calendar.AddMinutes(1);
//Adding item with an absolute expiration of 1 minute
cache.Add("Customer:DavidJohnes", customer, calendar, Cache.NoSlidingExpiration, CacheItemPriority.Normal);
Customer cachedCustomer = (Customer) cache.Get("Customer:DavidJohnes");
...Wenn Sie wissen möchten, wie Sie einen Cache erstellen, sehen Sie sich bitte unsere an Einstiegsvideo. Das ist auf unserer Website verfügbar. Aber nehmen wir an, Sie haben sich mit diesem Cache verbunden, also haben Sie einen Cache-Handle. Jetzt erstellen Sie Ihre Daten, die aus einer Reihe von Objekten bestehen, und dann tun Sie es cache.Hinzufügen. cache.Hinzufügen hat einen Schlüssel, der eine Zeichenfolge ist, und den tatsächlichen Wert, der Ihr Objekt ist, und dann geben Sie in diesem Fall einen absoluten Ablauf von einer Minute an. Sie sagen also, dass dieses Objekt in einer Minute ablaufen soll, und indem Sie sagen, dass Sie es sagen NCache um dieses Objekt ablaufen zu lassen. So funktioniert das Ablaufen, was natürlich, wie gesagt, Redis bietet Ihnen auch.
Cache mit Datenbank synchronisieren
Aber das Problem mit dem Ablauf ist, dass Sie eine Vermutung anstellen, die möglicherweise nicht korrekt ist, möglicherweise nicht genau. Was ist also, wenn sich die Daten vor dieser einen Minute vor den von Ihnen angegebenen fünf Minuten ändern? An dieser Stelle benötigen Sie also diese andere Funktion namens Cache mit der Datenbank synchronisieren. Dies ist die Funktion, die NCache hat und Redis hat nicht.
Damit NCache tut das auf verschiedene Weise. Nummer zuerst ist SQL-Abhängigkeit. SQL-Abhängigkeit ist eine Funktion von SQL Server über ADO.NET, bei der Sie im Grunde eine SQL-Anweisung angeben und SQL Server mitteilen und sagen, wissen Sie, bitte überwachen Sie diesen Datensatz, und wenn sich dieser Datensatz ändert, bedeutet dies, dass eine Zeile hinzugefügt wird , aktualisiert oder gelöscht, die diesen Datensatzkriterien entspricht, benachrichtigen Sie mich bitte. Die Datenbank sendet Ihnen also eine Datenbankbenachrichtigung und Sie können dann entsprechende Maßnahmen ergreifen. Also der Weg NCache ist das, NCache wird die SQL-Abhängigkeit verwenden, und es gibt auch eine Oracle-Abhängigkeit, die dasselbe mit Oracle macht. Beide arbeiten mit Datenbankereignissen. So, NCache verwendet die SQL-Abhängigkeit. Lassen Sie mich Ihnen diesen Code hier zeigen. Also werde ich nur zum SQL-Abhängigkeitscode gehen. Auch hier verlinken Sie auf die gleiche Weise mit einigen der Baugruppen. Sie erhalten den Cache-Handle, und jetzt, wo Sie Sachen hinzufügen, werde ich einfach dazu übergehen, zur Definition gehen. Nun, da Sie diese Daten hinzufügen, geben Sie als Teil des Hinzufügens eine SQL-Abhängigkeit an. Die Cache-Abhängigkeit ist also eine NCache Klasse, die eine Verbindungszeichenfolge zu Ihrer Datenbank übernimmt. Es dauert eine SQL-Anweisung. Nehmen wir also an, in diesem Fall sagen Sie: Ich möchte, dass die SQL-Anweisung lautet, dass die Produkt-ID diese ID ist. Da Sie also ein Produktobjekt zwischenspeichern, gleichen Sie es mit der entsprechenden Zeile in der Produkttabelle ab. Also, du sagst, du sagst es NCache um mit dem SQL-Server zu sprechen und die SQL-Abhängigkeit zu verwenden, damit der SQL-Server diese Anweisung überwachen kann und wenn sich diese Daten ändern, der SQL-Server benachrichtigt NCache.
Jetzt ist der Cache-Server also zu einem Client Ihrer Datenbank geworden. Der Cache-Server hat also Ihren SQL-Server gebeten, mich zu benachrichtigen, wenn sich dieser Datensatz ändert, und wenn sich dieser Datensatz ändert, benachrichtigt der SQL-Server den Cache-Server und die NCache Der Server entfernt dieses Element dann aus dem Cache, und der Grund dafür ist, dass Sie es nach dem Entfernen beim nächsten Mal nicht mehr im Cache finden und gezwungen sind, es aus der Datenbank zu holen. Also, so erfrischt man es irgendwie. Es gibt eine andere Möglichkeit, das Element automatisch neu zu laden, über die ich gleich sprechen werde.
Die SQL-Abhängigkeit erlaubt es also NCache Um den Cache wirklich mit der Datenbank zu synchronisieren, und mit Oracle-Abhängigkeit funktioniert es genauso, außer dass es mit Oracle anstelle von SQL Server funktioniert. Die SQL-Abhängigkeit ist wirklich mächtig, aber auch gesprächig. Nehmen wir also an, wenn Sie 10,000 Elemente oder 100,000 Elemente haben, erstellen Sie 100,000 SQL-Abhängigkeiten, was die Leistung der SQL Server-Datenbank beeinträchtigt, da die SQL Server-Datenbank für jede SQL-Abhängigkeit eine Datenstruktur und den Server erstellt um diese Daten zu überwachen, und das ist ein zusätzlicher Overhead.
Wenn Sie also viele Daten zu synchronisieren haben, ist es vielleicht besser, nur auf die DB-Abhängigkeit zu setzen. DB-Abhängigkeiten ist unsere eigene Funktion, bei der statt einer SQL-Anweisung und Datenbankereignissen NCache tatsächlich zieht die Datenbank. Es gibt eine spezielle Tabelle, die Sie erstellen und die heißt NCache DB synchronisieren und dann ändern Sie Ihre Trigger, sodass Sie ein Flag in einer Reihe aktualisieren, das diesem zwischengespeicherten Element entspricht, und dann NCache zieht diese Tabelle von Zeit zu Zeit, sagen wir, standardmäßig alle 15 Sekunden oder so, und dann können Sie, wissen Sie, wenn es eine Zeile findet, die geändert wurde, die entsprechenden zwischengespeicherten Elemente aus dem Cache ungültig machen. Also können beide und natürlich die DB-Abhängigkeit auf jeder Datenbank funktionieren. Es ist nicht nur SQL-Server, Oracle, sondern auch, wenn Sie eine DB2- oder MySQL- oder andere Datenbanken haben.
Durch die Kombination dieser Funktionen können Sie sich also wirklich darauf verlassen, dass Ihr Cache immer mit der Datenbank synchronisiert wird und Sie so ziemlich alle Daten zwischenspeichern können. Es gibt eine dritte Möglichkeit, nämlich eine gespeicherte CLR-Prozedur, sodass Sie tatsächlich eine gespeicherte CLR-Prozedur implementieren können. Von dort aus können Sie eine machen NCache Forderung. Dazu rufen Sie die gespeicherte Prozedur aus dem Datenbanktrigger auf. Nehmen wir an, Sie haben eine Kundentabelle und Sie haben einen Update-Trigger oder einen Delete-Trigger oder sogar einen Add-Trigger. Bei einem CLR-Verfahren können Sie auch neue Daten hinzufügen. Das ist also die CLR-Prozedur, die vom Trigger aufgerufen wird und die CLR-Prozedur macht NCache Anrufe und auf diese Weise haben Sie so ziemlich die Datenbank, die die Daten hinzufügt oder die Daten zurück in den Cache aktualisiert.
Diese drei verschiedenen Möglichkeiten ermöglichen es also NCache mit der Datenbank synchronisiert werden, und dies ist ein wirklich wichtiger Grund für die Verwendung NCache übrig Redis weil Redis zwingt Sie, nur Ablaufzeiten zu verwenden, was nicht ausreicht. Es macht Sie wirklich angreifbar oder zwingt Sie, schreibgeschützte Daten zwischenzuspeichern.
Cache mit nicht relationaler Datenbank synchronisieren
Sie können den Cache auch mit einer nicht relationalen Datenbank synchronisieren. Wenn Sie also eine Legacy-Datenbank, einen Mainframe, haben, können Sie eine benutzerdefinierte Abhängigkeit haben, bei der es sich um Ihren Code handelt, der auf dem Cache-Server von Zeit zu Zeit ausgeführt wird NCache ruft Ihren Code auf, um Ihre Datenquelle zu überwachen, und Sie können möglicherweise Webmethoden aufrufen oder andere Dinge tun, um die benutzerdefinierte Datenquelle zu überwachen, und auf diese Weise können Sie das zwischengespeicherte Element mit Datenänderungen in dieser benutzerdefinierten Datenquelle synchronisieren. Die Synchronisierung der Datenbank ist also ein sehr wichtiger Grund, warum Sie sie verwenden sollten NCache übrig Redis denn jetzt cachen Sie praktisch alle Daten. Während im Falle von Redis Sie werden gezwungen sein, Daten zwischenzuspeichern, die entweder schreibgeschützt sind oder bei denen Sie sehr sicher Vermutungen anstellen können Ablauf.
Grund 2 – SQL-Suche
Grund Nummer zwei, okay. Nehmen wir an, Sie haben jetzt begonnen, die Synchronisierung mit der Datenbankfunktion zu verwenden, und jetzt können Sie praktisch viele Daten zwischenspeichern. Je mehr Daten Sie zwischenspeichern, desto mehr sieht der Cache aus wie eine Datenbank, und wenn Sie dann nur die Möglichkeit haben, Daten basierend auf Schlüsseln abzurufen, was ist was Redis wirkt dann sehr einschränkend. Sie müssen also in der Lage sein, andere Dinge zu tun. Sie müssen also in der Lage sein, Daten intelligent zu finden. NCache bietet Ihnen eine Reihe von Möglichkeiten, Daten zu gruppieren und Daten entweder basierend auf Objektattributen oder basierend auf Gruppen und Untergruppen zu finden, oder Sie können Tags, Namens-Tags zuweisen. All dies sind also verschiedene Möglichkeiten, wie Sie Sammlungen von Daten zurückerhalten können. Wenn Sie zum Beispiel eine SQL-Abfrage ausgeben würden, lassen Sie mich Ihnen zeigen, sagen wir, ich gehe hier eine SQL-Abfrage. Also möchte ich gehen und, sagen wir, alle Kunden finden, bei denen customer.city New York ist. Also, ich gebe einen SQL-Status aus, ich sage Kunden auswählen, wissen Sie, mein vollständiger Namensraum, Kunde, wo this.City Fragezeichen ist und in dem Wert, den ich New York als Wert angeben werde und wann ich Wenn Sie diese Abfrage ausgeben, erhalte ich eine Sammlung der Kundenobjekte zurück, die diesen Kriterien entsprechen.
Das sieht jetzt also sehr nach einer Datenbank aus. Das bedeutet also, dass Sie tatsächlich damit beginnen können, Daten zwischenzuspeichern. Sie können ganze Datensätze zwischenspeichern, insbesondere Nachschlagetabellen oder andere Referenzdaten, bei denen Ihre Anwendung verwendet wurde, um SQL-Abfragen gegen die in der Datenbank zu stellen, und die gleiche Art von SQL-Abfragen, für die Sie absetzen können NCache. Die einzige Einschränkung besteht darin, dass Joins im Fall von ausgeführt werden können NCache aber bei vielen davon müssen Sie die Gelenke nicht wirklich machen. SQL-Suche macht den Cache sehr benutzerfreundlich, um wirklich zu suchen und die Daten zu finden, nach denen Sie suchen.
Gruppierung und Untergruppierung Lassen Sie mich Ihnen das am Beispiel der Gruppierung zeigen. Hier können Sie beispielsweise eine Reihe von Objekten hinzufügen und Sie können sie alle hinzufügen. Sie fügen sie also als Gruppe hinzu. Also, das ist der Schlüssel, der Wert, hier ist der Gruppenname, hier ist der Untergruppenname und dann können Sie später sagen, geben Sie mir alles, was zur Elektronikgruppe gehört. Dies gibt Ihnen eine Sammlung zurück und Sie können die Sammlung durchlaufen, um Ihre Sachen zu erhalten.
namespace GroupsAndTags
{
public class Groups
{
public static void RunGroupsDemo()
{
try
{
Console.WriteLine();
Cache cache = NCache.InitializeCache("mypartitionedcache");
cache.Clear();
//Adding item in same group
//Group can be done at two levels
//Groups and Subgroups.
cache.Add("Product:CellularPhoneHTC", "HTCPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneNokia", "NokiaPhone", "Electronics", "Mobiles");
cache.Add("Product:CellularPhoneSamsung", "SamsungPhone", "Electronics", "Mobiles");
cache.Add("Product:ProductLaptopAcer", "AcerLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopHP", "HPLaptop", "Electronics", "Laptops");
cache.Add("Product:ProductLaptopDell", "DellLaptop", "Electronics", "Laptops");
cache.Add("Product:ElectronicsHairDryer", "HairDryer", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsVaccumCleaner", "VaccumCleaner", "Electronics", "SmallElectronics");
cache.Add("Product:ElectronicsIron", "Iron", "Electronics", "SmallElectronics");
// Getting group data
IDictionary items = cache.GetGroupData("Electronics", null); // Will return nine items since no subgroup is defined;
if (items.Count > 0)
{
Console.WriteLine("Item count: " + items.Count);
Console.WriteLine("Following Products are found in group 'Electronics'");
IEnumerator itor = items.Values.GetEnumerator();
while (itor.MoveNext())
{
Console.WriteLine(itor.Current.ToString());
}
Console.WriteLine();
}Sie können die Schlüssel auch basierend auf der Gruppe abrufen. Sie können auch andere Dinge basierend auf der Gruppe tun. Gruppen und Tags funktionieren also auf ähnliche Weise. Namensschilder sind auch dasselbe wie Tags, außer dass es sich um ein Schlüsselwertkonzept handelt. Nehmen wir also an, wenn Sie Freiformtext zwischenspeichern und wirklich einige der Metadaten des Textes indexieren möchten, können Sie das Schlüsselwertkonzept mit den Namens-Tags verwenden und auf diese Weise einmal alle Tags und Namens-Tags gruppieren, die Sie haben dann können Sie diese in SQL-Abfragen einschließen.
Sie können auch ausstellen LINQ-Abfragen. Wenn Sie mit LINQ vertrauter sind, können Sie LINQ-Abfragen ausgeben. Nehmen wir zum Beispiel im Fall von LINQ an, hier ist Ihre NCache. Also würdest du eine machen NCache Abfrage mit einem Produktobjekt. Es gibt Ihnen eine Abfragbar -Schnittstelle und dann können Sie eine LINQ-Abfrage wie bei jeder Objektsammlung ausführen und tatsächlich den Cache durchsuchen.
do
{
Console.WriteLine("\n\n1> from product in products where product.ProductID > 10 select product;");
Console.WriteLine("2> from product in products where product.Category == 4 select product;");
Console.WriteLine("3> from product in products where product.ProductID < 10 && product.Supplier == 1 select product;");
Console.WriteLine("x> Exit");
Console.Write("?> ");
select = Console.ReadLine();
switch (select)
{
case "1":
try
{
var result1 = from product in products
where product.ProductID > 10
select product;
if (result1 != null)
{
PrintHeader();
foreach (Product p in result1)
{
Console.WriteLine("ProductID : " + p.ProductID);
}
}
else
{
Console.WriteLine("No record found.");
}
}Wenn Sie also diese Abfrage ausführen, wenn Sie diese Abfrage ausführen, geht sie tatsächlich zur Caching-Ebene und durchsucht Ihre Objekte. Die Ihnen zur Verfügung stehende Schnittstelle ist also sehr einfach, auf sehr benutzerfreundliche Weise, aber hinter den Kulissen wird tatsächlich der gesamte Cache-Cluster zwischengespeichert oder durchsucht. Der zweite Grund ist also, dass Sie den Cache durchsuchen können, Sie können Daten nach Gruppen und Untergruppen, Tags und benannten Tags gruppieren und es ermöglicht, Daten auf benutzerfreundliche Weise zu finden, was etwas ist, in dem keine dieser Funktionen vorhanden ist Redis.
Datenindizierung Ein weiterer Aspekt davon ist, dass, wenn Sie auf der Grundlage dieser Attribute suchen, es unbedingt erforderlich ist, dass der Cache Indizes erstellt, er erstellt Indizes für diese Attribute. Andernfalls ist es ein extrem langsamer Prozess, diese Dinge zu finden. So, NCache ermöglicht Ihnen die Datenindizierung zu erstellen. Beispielsweise werden alle Gruppen und Untergruppen, Tags und Namens-Tags automatisch indiziert, aber Sie können auch Indizes für Ihre Objekte erstellen. So könnten Sie beispielsweise einen Index für Ihr Kundenobjekt auf das Attribut Stadt erstellen. Also das Stadtattribut, weil Sie wissen, dass Sie nach dem Stadtattribut suchen werden. Sie sagen, ich möchte dieses Attribut indizieren und so NCache wird es indizieren.
Grund 3 – Serverseitiger Code
Der Grund Nummer drei ist das mit NCache Sie können tatsächlich serverseitigen Code schreiben. Also, was ist dieser serverseitige Code und warum ist das so wichtig? Schauen wir uns das an. Es ist Read-Through, Write-Through, Write-Behind und Cache Loader. So, durchlesen ist im Wesentlichen Ihr Code, den Sie implementieren und der auf dem Cache-Server ausgeführt wird. Lassen Sie mich Ihnen also zeigen, wie ein Durchlesen aussieht. Wenn Sie also beispielsweise eine implementieren IReadThruProvider Schnittstelle.
public void LoadFromSource(string key, out ProviderCacheItem cacheItem)
{
cacheItem = new ProviderCacheItem(sqlDatasource.LoadCustomer(key));
cacheItem.ResyncItemOnExpiration = true;
cacheItem.ResyncProviderName = sqlDatasource.ConnString;
}
/// <summary>
/// Perform tasks like allocating resources or acquiring connections
/// </summary>
/// <param name="parameters">Startup paramters defined in the configuration</param>
/// <param name="cacheId">Define for which cache provider is configured</param>
public void Init(IDictionary parameters, string cacheId)
{
object connString = parameters["connstring"];
sqlDatasource = new SqlDatasource();
sqlDatasource.Connect( connString == null ? "" : connString.ToString() );
}
/// <summary>
/// Perform tasks associated with freeing, releasing, or resetting resources.
/// </summary>
public void Dispose()
{
sqlDatasource.DisConnect();
}Diese Schnittstelle hat drei Methoden. Es gibt eine Init-Methode, die aufgerufen wird, wenn der Cache startet, und deren Zweck es ist, Ihren Read-Through-Handler mit Ihrer Datenquelle zu verbinden, und es gibt eine Methode namens dispose, die aufgerufen wird, wenn der Cache gestoppt wird, und auf diese Weise können Sie die Verbindung zu Ihrer Datenquelle trennen und es gibt eine load from source-Methode, die Ihnen den Schlüssel übergibt und eine Ausgabe eines Cache-Elements erwartet, eines Provider-Cache-Elementobjekts. Jetzt können Sie den Schlüssel verwenden, um zu bestimmen, welches Objekt Sie aus Ihrer Datenbank abrufen müssen. Der Schlüssel könnte also, wie gesagt, Kunde sein, Kunden-ID 1000. Er sagt Ihnen also, dass der Objekttyp Kunde ist, der Schlüssel die Kunden-ID und der Wert 1000. Wenn Sie also solche Formate verwenden, können Sie Folgendes tun: Auf dieser Grundlage können Sie fortfahren und Ihren Datenzugriffscode erstellen.
Dieser Read-Through-Handler läuft also tatsächlich auf den Cache-Servern. Sie stellen diesen Code also tatsächlich auf allen Cache-Servern bereit. Im Falle von NCache es ist ziemlich nahtlos. Sie können dies über eine tun NCache Manager-Tool. Sie stellen diesen Read-Through-Handler also auf den Cache-Servern bereit, und dieser Read-Through-Handler wird vom Cache aufgerufen. Nehmen wir an, Ihre Anwendung erledigt das Cache.Get und dieses Element befindet sich nicht im Cache. NCache ruft Ihren Read-Through-Handler auf. Ihr Read-Through-Handler geht zu Ihrer Datenbank, ruft dieses Element ab und gibt es zurück NCache. NCache legt es in den Cache und gibt es dann an die Anwendung zurück. Die Anwendung hat also das Gefühl, dass sich die Daten immer im Cache befinden. Auch wenn es sich nicht im Cache befindet, kann der Cache jetzt die Daten aus Ihrer Datenbank abrufen. Das ist der erste Vorteil des Durchlesens.
Der zweite Vorteil des Read-Through ist, wann die Ablaufzeiten eintreten. Nehmen wir an, Sie hatten ein absolutes Ablaufdatum. Sie haben gesagt, dass dieses Element in 5 Minuten oder in 2 Stunden ablaufen soll, zu diesem Zeitpunkt können Sie es erkennen, anstatt dieses Element aus dem Cache zu entfernen NCache um dieses Element automatisch neu zu laden, indem der Read-Through-Handler aufgerufen wird. Und das Neuladen bedeutet, dass das Element niemals aus dem Cache entfernt wird. Es wird nur aktualisiert, und das ist wirklich wichtig, weil viele der Referenz-Nachschlagetabellen viele Transaktionen haben, die diese Daten nur lesen, und wenn diese Daten auch nur für einen kurzen Zeitraum entfernt werden, viele Transaktionen gegen die Datenbank erstellt, um diese Daten gleichzeitig abzurufen. Wenn Sie es also einfach im Cache aktualisieren könnten, ist es viel besser. Das ist also ein Anwendungsfall.
Der zweite Anwendungsfall betrifft die Datenbanksynchronisierung. Wenn also die Datenbanksynchronisierung stattfindet und dieses Element entfernt wird, warum laden Sie es nicht erneut aus der Datenbank, anstatt es zu entfernen, und das war's NCache Wille. Sie können konfigurieren NCache, sodass beim Einsetzen der Datenbanksynchronisierung die NCache Anstatt dieses Element aus dem Cache zu entfernen, ruft es Ihren Read-Through-Handler auf, um eine neue Kopie davon neu zu laden. Auch hier wird das Element auf die gleiche Weise wie beim Ablaufdatum nie entfernt. Es wird nie aus dem Cache entfernt. Das Durchlesen ist also eine wirklich leistungsstarke Funktion.
Ein weiterer Vorteil des Durchlesens besteht darin, dass es Ihre Anwendungen vereinfacht, da Sie sich immer mehr bewegen, wenn Sie Code in der Caching-Schicht speichern und wenn Sie mehrere Anwendungen haben, die auf dieselben Daten zugreifen, müssen sie nur a Cache.Get. Eine Cache.Get ist ein sehr einfacher Aufruf, der dann eine richtige ADO.NET-Codierung durchführt.
Durchlesen vereinfacht also Ihren Anwendungscode. Es stellt auch sicher, dass der Cache immer über die Daten verfügt. Es führt ein automatisches Neuladen bei Ablauf und Datenbanksynchronisierungen durch.
Die nächste Funktion ist Write-Through. Write-Through funktioniert genauso wie Read-Through, außer dass es zum Aktualisieren dient. Lassen Sie mich Ihnen zeigen, wie das Durchschreiben aussieht. Das war also durchgelesen. Lassen Sie mich einfach durchschreiben. Sie implementieren also einen Write-Through-Handler. Auch hier haben Sie eine Init-Methode. Sie haben eine Dispose-Methode, genau wie Read-Through, aber jetzt haben Sie eine Write-to-Datasource-Methode und eine Bulk-Write-to-Datasource-Methode. Das ist also etwas, das sich vom Durchlesen unterscheidet.
//region IWriteThruProvider Members
public OperationResult WriteToDataSource(WriteOperation operation)
{
bool result = false;
OperationResult operationResult = new OperationResult(operation, OperationResult.Status.Failure);
Customer value = (Customer)operation.ProviderCacheItem.Value;
if (value.GetType().Equals(typeof(Customer)))
{
result= XmlDataSource.SaveCustomer((Customer)value);
}
if (result) operationResult.DSOperationStatus = OperationResult.Status.Success;
return operationResult;
}
public OperationResult[] WriteToDataSource(WriteOperation[] operation)
{
throw new Exception("The method or operation is not implemented.");
}Also, im Fall von Write-Through, wissen Sie, erhalten Sie das Objekt und die Operation auch und diese Operation könnte ein Add sein, es könnte ein Update sein oder es könnte ein Delete sein, richtig. Denn du könntest a Cache.Add, Cache.Insert, Cache.Delete, und all dies führt dazu, dass ein Write-Through-Aufruf getätigt wird. Dieser kann nun gehen und die Daten in der Datenbank aktualisieren.
Wenn Sie eine Massenoperation, eine Massenaktualisierung durchführen, kann auch eine Massenaktualisierung der Datenbank durchgeführt werden. Das Durchschreiben hat also auch die gleichen Vorteile wie das Durchlesen, da es die Anwendung vereinfachen kann, da es immer mehr Persistenzcode in die Caching-Ebene verschiebt.
Aber es gibt auch eine Write-Behind-Funktion, die eine Variation von Write-Through ist. Beim Write-Behind aktualisieren Sie im Grunde den Cache und der Cache aktualisiert dann Ihre Datenquelle asynchron. Im Grunde aktualisiert es es später. Ihre Bewerbung muss also nicht warten.
Write-Behind beschleunigt Ihre Anwendung wirklich. Denn Datenbankaktualisierungen sind nicht so schnell wie Cache-Aktualisierungen. Sie können also ein Write-Through mit Write-Behind-Funktion verwenden und der Cache wird sofort aktualisiert. Ihre Anwendung geht zurück und macht ihre Sache, und dann wird das Write-Through in einer Write-Behind-Methode aufgerufen und es geht und aktualisiert die Datenbank, und natürlich wird die Anwendung benachrichtigt, wenn die Datenbankaktualisierung fehlschlägt.
Wenn also eine Warteschlange erstellt wird, besteht das Risiko, dass diese Warteschlange verloren geht, wenn dieser Server ausfällt. Nun, im Falle von NCache Die Write-Behind-Warteschlange wird auch auf mehr als einen Server repliziert, und auf diese Weise geht Ihre Write-Behind-Warteschlange nicht verloren, wenn ein Cache-Server ausfällt. Also, so ist es NCache sorgt für eine hohe Verfügbarkeit. Write-Through und Write-Behind sind also sehr mächtige Funktionen. Sie vereinfachen den Anwendungscode und beschleunigen die Anwendung auch im Falle von Write-Behind, da Sie nicht auf die Aktualisierung der Datenbank warten müssen.
Die dritte Funktion ist der Cache-Loader. Es gibt viele Daten, die Sie lieber vorab in den Cache laden würden, damit Ihre Anwendungen nicht auf die Datenbank zugreifen müssen. Wenn Sie keine Cache-Loader-Funktion haben, müssen Sie diesen Code jetzt schreiben. Nun, Sie müssen diesen Code nicht nur schreiben, sondern ihn auch irgendwo als Prozess ausführen. Es ist das Laufen als Prozess, der wirklich komplizierter wird. Im Falle eines Cache Loaders registrieren Sie also einfach Ihren Cache. Sie implementieren eine Cache-Loader-Schnittstelle, bei der Sie Ihren Code registrieren NCache, NCache ruft Ihren Code auf, wenn der Cache gestartet wird, und auf diese Weise können Sie sicherstellen, dass der Cache immer mit so vielen Daten vorgeladen ist.
Diese drei Funktionen Read-Through, Write-Through, Write-Behind und Cached Loader sind also nur sehr mächtige Funktionen NCache hat. Redis hat keine derartigen Funktionen. Also ggf Redis Sie verlieren all diese Fähigkeit, dass NCache sieht etwas anderes vor.
Grund 4 – Client-Cache (Near Cache)
Grund Nummer vier ist Client-Cache. Der Client-Cache ist eine sehr leistungsfähige Funktion. Es ist wirklich ein lokaler Cache, der sich auf Ihrem Anwendungsserver befindet, aber es ist kein isolierter Cache. Es ist lokal für Ihre Anwendung. Es kann In-Proc sein. Dieser Client-Cache könnte also Objekte sein, die auf Ihrem Heap und im Falle von aufbewahrt werden NCache wenn Sie die In-Proc-Option wählen, die NCache behält die Daten und Objektform bei. Nicht in serialisierter Form, im Client-Cache. Im geclusterten Cache hält es es in einer serialisierten Form. Aber im Client-Cache hält es es in einer Objektform. Wieso den? Sie müssen es also nicht jedes Mal, wenn Sie es abrufen, in ein Objekt deserialisieren. So beschleunigt es die Abrufe oder bekommt viel mehr.
Ein Client-Cache ist eine sehr mächtige Funktion. Es ist ein Cache über einem Cache. Eines der Dinge, die Sie verlieren, wenn Sie von einem eigenständigen In-Proc-Cache zu einem verteilten Cache wechseln, ist, dass der Cache in einem verteilten Cache die Daten in einem separaten Prozess aufbewahrt, sogar auf einem separaten Server, und es gibt einen Interprozess Kommunikation läuft, findet eine Serialisierung und Deserialisierung statt, die Ihre Leistung verlangsamt. Im Vergleich zu einem In-Proc-Cache für Objektformulare ist ein verteilter Cache also mindestens zehnmal langsamer. Mit einem Client-Cache erhalten Sie also das Beste aus beiden Welten. Denn wenn Sie keinen Client-Cache haben, wenn Sie nur einen eigenständigen isolierten Cache hatten, gibt es viele andere Probleme mit der Größe des Caches. Was ist, wenn dieser Prozess ausfällt? Dann verlieren Sie den Cache und wie halten Sie den Cache mit Änderungen auf mehreren Servern synchronisiert? All diese Probleme werden von behandelt NCache in seinem Client-Cache.
Sie profitieren also von diesem eigenständigen In-Proc-Cache, sind aber mit dem Caching-Cluster verbunden. Was auch immer in diesem Client-Cache aufbewahrt wird, befindet sich also auch im Clustered-Cache, und wenn einer der Clients es hier aktualisiert, benachrichtigt die Caching-Schicht den Client-Cache. Damit es sofort loslegen und sich selbst aktualisieren kann. Auf diese Weise stellen Sie also sicher, dass Ihr Client-Cache immer mit dem Caching-Tier synchronisiert wird, das dann mit der Datenbank synchronisiert wird.
Also, im Falle von NCache Ein Client-Cache ist etwas, das einfach ohne zusätzliche Programmierung eingesteckt wird. Sie führen die API-Aufrufe so durch, als würden Sie mit der Caching-Ebene sprechen, und der Client-Cache wird einfach in eine Konfigurationsänderung eingesteckt, und ein Client-Cache bietet Ihnen eine 10-mal schnellere Leistung. Dies ist eine Funktion, die Redis hat nicht. Also trotz aller Leistungsansprüche das Redis hat, wissen Sie, sie sind ein schnelles Produkt, aber so ist es NCache. So, NCache ist Kopf an Kopf in der Leistung mit Redis ohne den Client-Cache. Aber wenn Sie den Client-Cache aktivieren, NCache ist 10 mal schneller. Das ist also der eigentliche Vorteil der Verwendung eines Client-Cache. Das ist also Grund Nummer vier für die Verwendung NCache übrig Redis.
Grund 5 – Unterstützung für mehrere Rechenzentren
Grund Nummer fünf ist das NCache bietet einen Multi-Datacenter-Support. Wissen Sie, wenn Sie heutzutage eine Anwendung mit hohem Datenverkehr haben, sind die Chancen sehr hoch, dass Sie diese entweder bereits in mehreren Rechenzentren ausführen, entweder für Disaster Recovery DR oder für zwei Aktiv-Aktiv-Rechenzentren für den Lastausgleich oder eine Kombination aus DR und Lastausgleich , wissen Sie, oder vielleicht sein geografischer Lastenausgleich. Sie wissen also, Sie haben vielleicht ein Rechenzentrum in London und New York oder Sie kennen Tokio oder so etwas, um den regionalen Datenverkehr zu bewältigen. Wann immer Sie über mehrere Rechenzentren verfügen, bieten die Datenbanken eine Replikation, da Sie ohne diese nicht mehrere Rechenzentren haben könnten. Denn Ihre Daten sind in mehreren Rechenzentren gleich. Wenn die Daten damals nicht dieselben waren, wissen Sie, es ist ein separates, gibt es kein Problem, aber in vielen Fällen sind die Daten dieselben und dann nicht nur das, sondern Sie möchten in der Lage sein, einen Teil des Datenverkehrs von einem abzuladen Rechenzentrum nahtlos mit dem anderen zu verbinden. Wenn also die Datenbank über Rechenzentren hinweg repliziert wird, warum dann nicht der Cache? Redis bietet keine derartigen Funktionen, NCache bietet sehr leistungsstarke Funktionen.
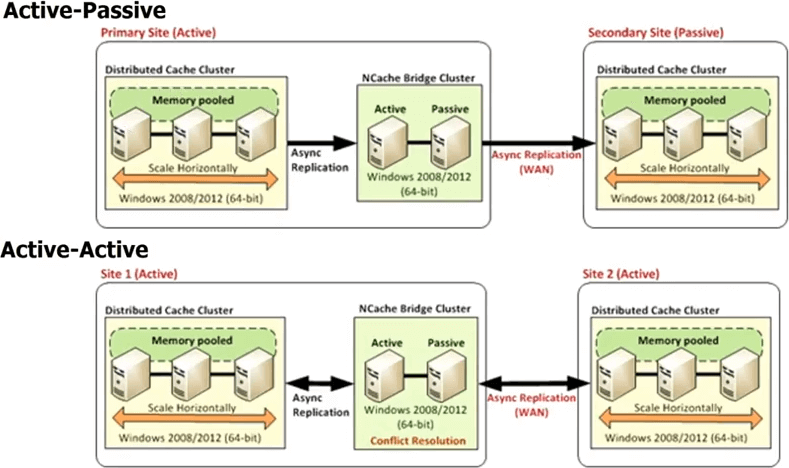
Also, im Falle von NCache Sie haben jedes Rechenzentrum, das einen eigenen Cache-Cluster haben wird, aber es gibt einen Brückentopologie zwischen. Diese Brücke verbindet im Wesentlichen die Cache-Cluster in jedem Rechenzentrum, sodass Sie asynchron replizieren können. Sie können also eine Aktiv-Passiv-Bridge haben, wo dies ein aktives Rechenzentrum ist, ist dies passiv. Sie können auch eine Aktiv-Aktiv-Brücke haben, und wir veröffentlichen auch mehr als zwei Aktiv-Aktiv- oder Aktiv-Passiv-Konfigurationen für Rechenzentren, bei denen Sie beispielsweise drei oder vier Rechenzentren haben können und der Cache auf alle repliziert wird entweder auf eine aktiv-aktive Weise oder auf eine aktiv-passive Weise. Da die Aktualisierungen asynchron durchgeführt werden oder die Replikation asynchron erfolgt ist, besteht in einem Aktiv-Aktiv-Modus die Möglichkeit eines Konflikts, dass dasselbe Element in beiden Rechenzentren aktualisiert wurde.
Damit NCache bietet zwei unterschiedliche Mechanismen zur Handhabung dieser Konfliktlösung. Eine heißt Last Update Wins. Das zuletzt aktualisierte Element wird auf beide Stellen angewendet. Angenommen, Sie aktualisieren hier ein Element, ein anderer Benutzer aktualisiert das Element hier. Beide beginnen nun mit der Ausbreitung zum anderen Cache. Wenn sie also zur Brücke kommen, stellt die Brücke fest, dass sie an beiden Stellen aktualisiert wurden. Dann überprüft es also den Zeitstempel, und je nachdem, welcher Zeitstempel der letzte war, wendet es dieses Update auf den anderen Standort an und verwirft das Update, das von dem anderen Standort vorgenommen wurde. Auf diese Weise gewinnt also die aktiv-aktive letzte Aktualisierung die Konfliktlösung. Wenn Ihnen das nicht ausreicht, können Sie einen Konfliktlösungshandler implementieren. Das ist dein Code. Die Bridge ruft also im Falle eines Konflikts Ihren Code auf, übergibt beide Kopien der Objekte, sodass Sie eine inhaltsbasierte Analyse durchführen können und dann basierend auf dieser Analyse bestimmen können, welches Objekt für die Aktualisierung geeigneter ist auf beide Rechenzentren angewendet werden. Die gleiche Regel gilt, wenn Sie sogar mehr als zwei Rechenzentren haben.
Also, ein Multi-Rechenzentrum-Unterstützung ist eine sehr mächtige Funktion NCache gibt Ihnen aus der Box. Sobald Sie kaufen NCache, es ist alles da, Redis nicht und wenn Sie entweder planen, mehrere Rechenzentren zu haben oder wenn Sie einfach nur die Flexibilität haben möchten, selbst wenn Sie heute nicht mehrere Rechenzentren haben, aber Sie die Flexibilität haben möchten, in der Lage zu sein, zu mehreren Rechenzentren zu gehen, würden Sie das tun heute eine Datenbank kaufen, die keine Replikation unterstützt? Wahrscheinlich nicht, selbst wenn Sie nur ein Rechenzentrum haben. Warum sollten Sie sich also für den Cache entscheiden, der die WAN-Replikation nicht unterstützt? Dies ist also eine sehr mächtige Funktion von NCache.
Bisher haben wir also hauptsächlich über Features gesprochen, die ein guter verteilter Cache haben muss. NCache, weißt du, glänzt. Es gewinnt zweifellos Redis. Redis ist ein sehr einfacher einfacher Cache.
Grund 6 – Plattform & Technologie (für .NET Apps)
.NET & Windows vs. Linux
Grund Nummer sechs ist wahrscheinlich einer der wichtigsten Gründe für Sie, nämlich Plattform und Technologie. Wenn Sie eine .NET-Anwendung haben, möchten Sie am liebsten den vollständigen .NET-Stack haben. Ich bin mir sicher, dass Sie in den meisten Fällen .NET mit Java oder Windows mit Linux nicht mischen möchten. In einigen Fällen können Sie das vielleicht tun, aber in den meisten Fällen bevorzugen Leute, die .NET-Anwendungen entwickeln, die Windows-Plattform und ziehen es vor, wenn möglich, ihren gesamten Stack auf .NET zu haben. Brunnen, Redis ist kein .NET-Produkt. Es ist ein Linux-basiertes Produkt, das in C/C++ entwickelt wurde.

Lassen Sie mich Ihnen wenig zeigen. Hier ist die Redis Labs-Website, die das Unternehmen herstellt Redis. Wenn Sie auf die Download-Seite gehen, werden Sie sehen, dass sie Ihnen nicht einmal eine Windows-Option geben. Trotz der Tatsache, dass Microsoft sie für Azure ausgewählt hat, haben sie also absolut nicht die Absicht, Windows zu unterstützen. Also soweit Redis Labs ist besorgt, Redis ist nur für Linux. Microsoft Open Technology Group hat portiert Redis weiter zu Windows. Es gibt also eine Windows-Version von Redis erhältlich. Es ist Open Source und wird nicht unterstützt, aber wissen Sie, es ist fehlerhaft und instabil, und der Beweis liegt im Pudding, dass Microsoft es selbst nicht in Azure verwendet. Also, die Redis das Sie in Azure verwenden, ist eigentlich ein Linux-basiertes Redis und nicht die Windows-Basis. Also, wenn Sie integrieren möchten Redis In Ihrem Anwendungsstapel werden Sie Öl mit Wasser mischen, wissen Sie. Während im Falle von NCache alles ist natives .NET. Sie haben Windows. Sie haben 100 % .NET. NCache wurde in Cis (C#) entwickelt. Es ist für Windows Server 2012 R2 zertifiziert und jedes Mal, wenn eine neue Version des Betriebssystems kommt, wird es dafür zertifiziert. Wissen Sie, wir werden das ASP ziemlich bald starten.NET Core Unterstützung. Wir haben also offiziell einen .NET-Client. Wir haben auch offiziell einen Java-Client. Also, ich denke, wenn Sie verwenden NCache und wieder NCache ist auch quelloffen. Also, wenn Sie das Geld nicht haben, gehen Sie mit der Open-Source-Version von NCache. Wenn Ihr Projekt jedoch wichtig ist, entscheiden Sie sich für die Enterprise-Version, die Ihnen mehr Funktionen bietet und beides unterstützt. Aber ich würde Ihnen wärmstens empfehlen, es zu verwenden NCache wenn Sie eine .NET-Anwendung für die Kombination aus .NET und Windows haben.
On-Premises-Support
Der zweite Vorteil, dass NCache Wenn Sie sich nicht in der Cloud befinden, sagen wir, Sie haben sich nicht entschieden, in die Cloud zu wechseln, hosten Sie Ihre eigene Anwendung, also ist sie im Wesentlichen lokal. Es befindet sich also in Ihrem eigenen Rechenzentrum Redis die von Microsoft verfügbar ist, ist nur in Azure verfügbar. Also, alles, was lokal ist, also gibt es eine Redis die lokal verfügbar ist von Redis Labs, aber das ist nur Linux und die einzige On-Premises-Lösung unter Windows ist die Open Source, die ohne Support und die fehlerhafte und instabile und die so fehlerhafte, dass Microsoft sie selbst nicht in Azure verwendet.

Während im Falle von NCache Sie können entweder weiterhin die kostenlose Open Source verwenden, die natürlich nicht unterstützt wird, wenn Sie das Geld nicht haben. Aber es ist alles natives .NET oder wenn Sie ein Projekt haben, das für Ihr Unternehmen wichtig ist, dann von der Enterprise Edition das hat mehr Funktionen und kommt mit Support und es ist eine unbefristete Lizenz. Es ist ziemlich erschwinglich, es zu besitzen, und wir bieten Ihnen auch 24 x 7 Support, falls das für Sie wichtig ist.
Daher wird es lokal vollständig unterstützt. Die meisten unserer Kunden, die High-End-Kunden sind, verwenden immer noch NCache in einer On-Premises-Situation. NCache ist seit mehr als 10 Jahren auf dem Markt. Es ist also ein wirklich stabiles Produkt.
Cloud-Unterstützung
Was die Cloud-Unterstützung betrifft, Redis Sie erhalten ein Servicemodell in der Cloud, das Microsoft implementiert hat Redis Service. Brunnen, Redis service bedeutet, dass Sie keinen Zugriff auf die Cache-Server haben. Weißt du, es ist eine Blackbox für dich. Es gibt keinen serverseitigen Code. Also, all das Read-Through, Write-Through, Write-Behind, der Cache Loader, die benutzerdefinierten Abhängigkeiten und ein Haufen anderer Dinge, mit denen Sie nichts anfangen können Redis. Wissen Sie, Sie haben nur die grundlegende Client-API, und wie gesagt, wissen Sie, auf Azure gibt Ihnen Microsoft die Redis als Dienstleistung.
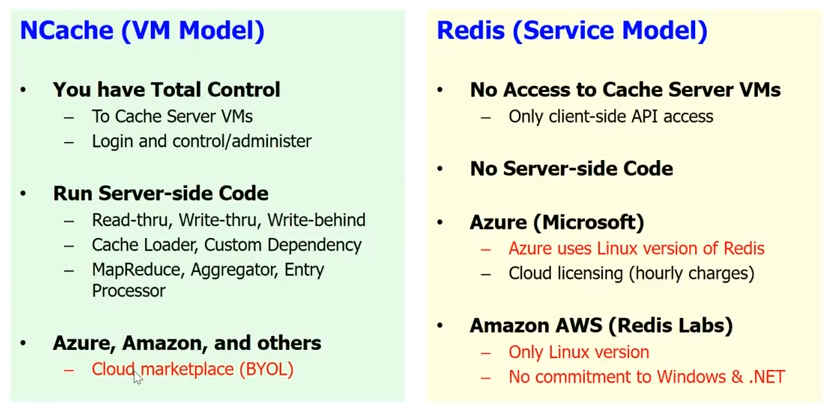
NCache, haben wir absichtlich ein VM-Modell ausgewählt. Weil wir möchten, dass sich der Cache in der Nähe Ihrer Anwendung befindet, und wir möchten, dass Sie die vollständige Kontrolle über den Cache haben. Das ist sehr wichtig, denn wir haben langjährige Erfahrung und wissen, dass unsere Kunden sehr sensibel sind. Sogar ein kleiner, sagen wir mal, wenn man den nutzt Redis als Dienst und Sie müssen jedes Mal einen zusätzlichen Hop machen, um zum Cache zu gelangen, das macht nur den ganzen Zweck eines Caches zunichte. Während im Falle von NCache Sie können es als Teil der VM haben. Sie können den Client-Cache haben. Es ist wirklich in Ihre Anwendungsbereitstellung eingebettet. Sie können also den gesamten serverseitigen Code ausführen.
NCache läuft auch weiter Azure. Es läuft weiter Amazon AWS und auch andere führende Cloud-Plattformen im BYOL-Modell. Sie erhalten also im Grunde Ihre VM. Eigentlich hast du die NCache auf dem Marktplatz. Du bekommst ein NCache VM und Sie kaufen die Lizenz bei uns und beginnen mit der Nutzung NCache.
Also sehr unterschiedliche Herangehensweisen. Dies ist jedoch der Ansatz, der beabsichtigt ist, wenn Ihre Anwendung wirklich wichtig ist und Sie die Anwendung in allen Aspekten kontrollieren und sich nicht darauf verlassen müssen, dass jemand anderes einen Teil Ihrer Infrastruktur auf Anwendungsebene verwaltet. Es ist eine Sache, VMs und die darunter liegende Hardware zu verwalten, aber wenn Sie anfangen, immer weiter nach oben zu gehen, verlieren Sie diese Kontrolle und natürlich im Falle von Caching, im Falle von NCache, es ist nicht nur diese Kontrolle, sondern auch viele Funktionen, die Sie verlieren würden, wenn Sie sich für das Servicemodell entscheiden würden.
Grund Nummer 6 ist also die Plattformtechnologie. Für .NET-Anwendungen NCache ist eine viel geeignetere Option als Redis. Ich sage nicht Redis ist eine schlechte Option, aber ich denke für .NET-Anwendungen NCache ist eine viel überlegenere Option als Redis.
NCache Geschichte
Lassen Sie mich Ihnen nur eine kurze Geschichte von geben NCache. NCache gibt es seit Mitte 2005. Das sind also die 11 Jahre, weißt du, NCache ist auf dem Markt gewesen. Es ist der älteste .NET-Cache auf dem Markt. Januar 2015 wurden wir Open Source. Wir haben also jetzt eine Apache 2.0-Lizenz. Unser Enterprise Edition basiert auf unserer Open Source. Die Open Source ist also eine stabile, zuverlässige Version. Es hat viele Funktionen. Natürlich hat Enterprise mehr Funktionen, aber Open Source ist ein sehr brauchbares Produkt. Die grundlegende Sache ist, wenn Sie nicht das Geld haben, gehen Sie zu Open Source. Wenn Ihre Geschäftsanwendung wichtig ist und Sie das Budget haben, entscheiden Sie sich für die Enterprise Edition. Es kommt mit Unterstützung und bietet Ihnen auch mehr Funktionen.
Wir haben Hunderte von Kunden, so ziemlich in jeder Branche möglich, die Caching benötigt. Wir haben also Kunden aus der Finanzbranche, wir haben Walmart und andere Einzelhandelsunternehmen. Wir haben Fluggesellschaften, wir haben die Versicherungsbranche, Auto/Automobil, quer durch alle Branchen.
Das ist das Ende meines Vortrags. Bitte fahren Sie fort und laden Sie die Enterprise Edition von herunter NCache. Lassen Sie mich Sie tatsächlich auf unsere Website führen. Gehen Sie also im Wesentlichen zu Download-Seite und ich würde Ihnen wärmstens empfehlen, die Enterprise Edition herunterzuladen. Auch wenn Sie letztendlich die Open-Source-Edition verwenden möchten, laden Sie die Enterprise Edition herunter. Es handelt sich um eine voll funktionsfähige 30-Tage-Testversion, die wir problemlos verlängern und damit spielen können.
Wenn Sie fortfahren und die Open Source herunterladen möchten, fahren Sie fort und laden Sie die Open Source herunter. Sie können auch zu GitHub gehen und sehen NCache auf GitHub. Bitte kontaktieren Sie uns, wenn Sie möchten, dass wir wie a personalisierte Demo. Sprechen Sie vielleicht über Ihre Anwendungsarchitektur, beantworten Sie Ihre Fragen. Vielen Dank, dass Sie sich diesen Vortrag angesehen haben.